
SemiAnalysis:NVIDIA Rubinプラットフォームの光と影
- コア見解:SemiAnalysisは対照的な二つの分析を発表。NVIDIAの2027会計年度下半期の業績は、HBM4の供給ボトルネック解消により市場予想を上回る一方で、フラッグシップ製品であるRubin Ultraは技術的理由により大幅に縮小され、これはカスタムASICによるCUDAエコシステムの侵食を反映していると指摘。
- 主要要素:
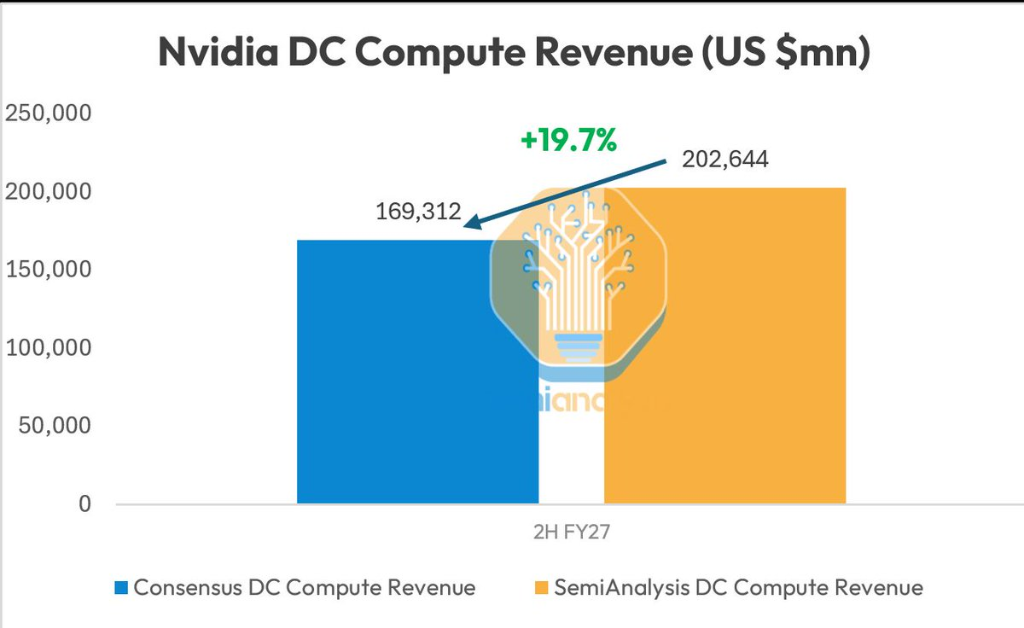
- SemiAnalysisは、NVIDIAの2027会計年度下半期のデータセンター売上高がウォール街のコンセンサス予想を約20%上回ると予測。主な原動力は、RubinプラットフォームにおけるHBM4の供給問題とフロントエンドウェーハ生産能力の確保が解決されたことにある。
- SemiAnalysisの予測モデルは、サプライチェーンにおける一次調査に基づいており、材料、ウェーハ、部品、サーバー、そしてクラウドサービス事業者の調達データを網羅。従来の証券会社の保守的な予想とは一線を画す。
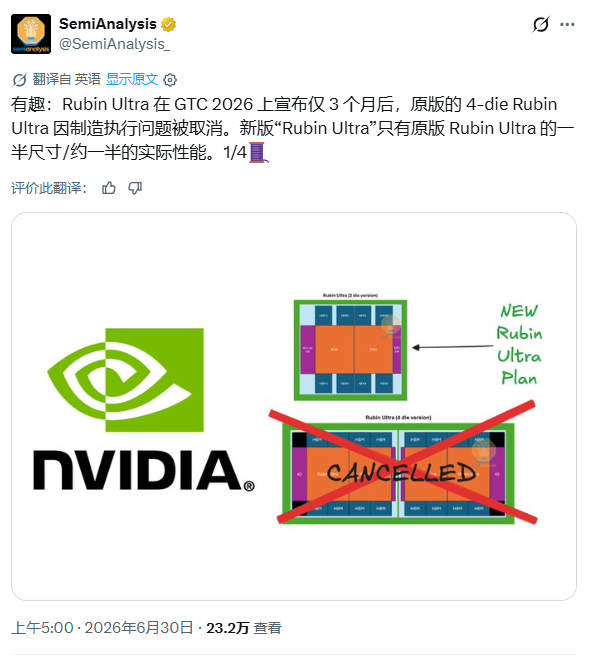
- NVIDIAが当初計画していた4チップ構成のRubin Ultraは、GTC 2026での発表から約3ヶ月後に中止。新しいバージョンは規模が半分、性能も半分となり、その理由は先端パッケージングの製造難易度に関連している。
- NVIDIAの競争環境が変化:ハイパースケールクラウド事業者やAI企業(Anthropicなど)が、自社開発のASIC(Google TPU、Amazon Trainiumなど)をトレーニングと推論に採用し、CUDAの堀を侵食している。
- AnthropicはすでにTPU、Trainium、そしてNVIDIA GPUを組み合わせたマルチプラットフォームアーキテクチャを構築。Claudeモデルのトレーニングと推論は、徐々にGPUからTPUとTrainiumへと移行しつつある。
原文出典:WallStreetCN
半導体調査機関SemiAnalysisは相次いで2つの分析を発表し、NVIDIAの将来にチャンスと課題が共存する「氷と火」の両面を描き出した。
SemiAnalysisが6月30日にXプラットフォームで発表した最新予測によると、NVIDIAの2027会計年度下半期のデータセンター向けコンピューティング事業の売上高は、ウォール街のコンセンサス予想を約20%上回る見込みだ。この楽観的な判断の核となる根拠は、これまでRubinプラットフォームの大量出荷を制約していたHBM4メモリの供給問題が解決されたことにあり、同時に前工程のウェハー生産能力も確保されており、下半期の業績爆発に向けた実質的な障害が取り除かれた。
しかし、同日朝、SemiAnalysisは別の悪材料を開示した。NVIDIAのオリジナル版4チップ構成のRubin Ultraが、GTC 2026での発表から約3ヶ月後にキャンセルされ、新版「Rubin Ultra」のサイズは当初の半分に縮小され、実質的な性能も半減した。
一方では供給ボトルネック解消による売上高の楽観的な上方修正、他方では旗艦製品の縮小による技術ロードマップへの悲觀的な修正——SemiAnalysisによるこれら2つの正反対の判断は、業績実現力と技術的堀という2つの側面から、NVIDIAに対して全く異なるナラティブの座標軸を定めた。
HBM4のボトルネック解消、Rubinプラットフォーム下半期の本格量産に期待
SemiAnalysisは自社のAccelerator Modelを通じて最新の予測を発表し、NVIDIAは今年下半期に大規模な生産拡大局面を迎えるとしている。
同機関は、Rubinプラットフォームの力強い牽引により、2027会計年度下半期のNVIDIAのデータセンター向けコンピューティング事業の収益は市場コンセンサス予想を約20%上回ると予測する。これまでRubinの進捗に影響を与えていたHBM4問題は現在解決されており、前工程ウェハーの供給も事前に確保されている。これは、かつて遅延していたRubinプラットフォームが急速な立ち上げ段階に入ることを意味する。
SemiAnalysisは特に、その予測ロジックは伝統的な売り方アナリストのものとは大きく異なると指摘する。多くのウォール街機関は比較的保守的な収益予測を立てる傾向があり、企業が後で「予想を上回る」パフォーマンスを出す余地を残している。一方、SemiAnalysisの結論は、より産業チェーンにおける現場調査に基づいており、実際の市場動向に可能な限り近づけるよう努めている。
同機関のAccelerator Modelは、チェーン全体を網羅する情報クロス検証システムを構築しており、データソースは材料サプライヤー、ウェハー製造、主要部品、サーバーOEMなどのサプライチェーン各段階をカバーする。同時に、ハイパースケールクラウドプロバイダーや最先端AIラボの実際の調達・導入状況と組み合わせ、需給関係を多角的に検証する。
注目すべきは、このモデルはNVIDIAに焦点を当てるだけでなく、Broadcom、AMD、MediaTek、MarvellなどのAIチップメーカーもカバーしており、HBM Modelと組み合わせてAIコンピューティングパワーチェーン全体の進化を継続的に追跡している点である。
CUDAの堀が浸食、Rubin Ultra縮小はカスタムASICの台頭を映す
しかし、これに先立ち、SemiAnalysisがRubin Ultraに関して発表した別のコメントが市場で広く議論を呼んだ。
同機関によると、NVIDIAが当初4つのコンピューティングチップ設計を計画していたRubin Ultraは、今年のGTCでの発表から約3ヶ月後に当初の計画を変更し、新版の規模は当初の設計から大幅に縮小された。その理由は、先進パッケージングの製造難易度に関係している。
SemiAnalysisは、注目すべきはRubin Ultraの縮小自体ではなく、この出来事が映し出す産業競争構造の変化であると考える。同機関は、過去1年間でNVIDIAにとって最大の競争圧力はもはやAMDなどの従来のGPUメーカーだけではなく、ますます多くのハイパースケールクラウドプロバイダーやAIモデル企業がカスタムASICを採用し、トレーニングや推論などの特定のシナリオに特化した専用チップシステムを構築し始めている点にあると指摘する。
例えば、Anthropicは現在、Google TPU、Amazon Trainium、NVIDIA GPUで構成されるマルチプラットフォームのコンピューティングアーキテクチャを形成している。その中で、多くのClaudeモデルのトレーニングはTPUプラットフォームで実行され、Claude Codeの推論はますますTrainium上に展開され、一方NVIDIA GPUは最先端研究などの汎用コンピューティングタスクをより多く担っている。SemiAnalysisは、1年前にはTPUとTrainiumが現在の規模に成長することは想像もできなかったが、今やCUDAの堀はゆっくりと浸食されつつあると指摘する。


