
The World Cup has only been running for a few days, yet some AI prediction models are already hailed as geniuses, while others have failed miserably.
- Core Opinion: Multiple AI large language models (such as Qwen, Copilot, ChatGPT, etc.) have been used to predict World Cup match results, with varying degrees of accuracy. Qwen impressed on the first day by correctly predicting the exact score and a red card risk; Copilot and ChatGPT showed some highlights but were too conservative in identifying upsets and draws. This shows that AI can serve as a reference but is still far from providing definitive answers.
- Key Elements:
- Qwen accurately predicted the opening match score of Mexico 2-0 South Africa, as well as the red card risk. It also correctly forecasted South Korea's comeback victory over the Czech Republic 2-1, creating a "script-like" narrative that significantly boosted attention on AI predictions.
- Copilot's full tournament schedule predictions had some highlights (such as Brazil 1-1 Morocco), but clearly failed in cases like Australia defeating Turkey and Japan holding the Netherlands to a draw. This exposed its overly conservative judgment regarding underdog teams.
- ChatGPT's analysis logic was sound, offering well-reasoned predictions for the opening match. However, it also failed to correctly identify upsets such as Qatar drawing with Switzerland or the Netherlands being held to a draw by Japan, both of which deviated from expected team strength.
- Models like Gemini, Grok, and Claude showed varied performance in single match predictions. For example, Gemini correctly predicted the opening match score, while Grok and Claude did not pick the exact score. With limited sample data, it's difficult to rank them definitively.
オリジナル:Odaily 星球日報(@OdailyChina)
著者:Asher(@Asher_ 0210)

今回のワールドカップで最も熱い場所は、スタジアムの中だけではありません。
ワールドカップ関連の予測イベントの熱気が高まるにつれ、多くのユーザーが実際の資金を投じて取引に参加し始めています。誰が勝つのか、何対何のスコアか、番狂わせはあるのか、レッドカードは出るのか、どの選手が得点するのか――こうした、元々ファンが試合前に雑談していた話題が、今では一つひとつ取引可能な予測イベントに分解されています。
そして、予測が取引になると、ユーザーに必要なのは感情や直感だけではありません。オッズの変動、チームの状態、負傷情報、過去の対戦成績、市場センチメント――これらすべてが取引前の参考情報となります。その過程で、AIモデルがワールドカップの予測シーンに頻繁に持ち込まれるようになりました。
千問、ChatGPT、Gemini、Claude、DeepSeek、Qwen、Copilotといった大規模言語モデルは、「どのチームが勝ちそうか」という質問に答えるだけでなく、スコアの予想、番狂わせの可能性、レッドカードのリスク、キープレイヤーのパフォーマンス、試合の流れの分析まで提供できます。予測市場の参加者にとって、AIによる試合前のシミュレーションは、オッズ、ニュース、チームデータ、市場センチメントに加わる新たな参考材料となりつつあります。
とはいえ、予測は最終的に試合そのものに立ち返る必要があります。
ワールドカップが正式に開幕し、最初の数試合の結果が続々と出始めています。ユーザーが試合前に補助判断として利用していたAI分析も、ようやく照合できる答えが現れました。スコアは当たったのか、番狂わせは事前に予見されていたのか、レッドカード、土壇場での決勝点、試合の流れといった細部は、どれだけモデルに捉えられていたのか。
最初に注目を集めたのは、意外にも千問
ワールドカップ初日で最も話題になったのは、間違いなく千問でしょう。
開幕戦のメキシコ対南アフリカ戦で、千問は試合前にメキシコの2-0勝利を予測しました。試合終了後、スコアは実際に2-0で決着。さらに注目すべきは、試合中に計3枚のレッドカードが出たことで、これも千問が試合前に指摘した「南アフリカの守備の荒さから、早い段階で退場者が出るリスク」という分析とほぼ一致していました。

メキシコの勝利を予想したこと自体は、それほど驚くべきことではありません。開催国の一つであるメキシコは、もともと有利と見られていました。しかし、千問が今回的中させたのは、より具体的な試合の細部でした。2-0というスコア、南アフリカのレッドカードリスク、そして試合中盤以降に徐々に広がっていく点差です。
続く韓国対チェコ戦では、千問は韓国の2-1勝利を予測しました。
この試合は試合前の予想が難しいものでした。チェコにはフィジカルの強さ、セットプレーの脅威、そしてヨーロッパのチーム特有のビッグマッチでの経験がありました。試合展開も一方的ではなく、チェコが先制し、韓国が同点に追いつき、試合は1-1のまま長い膠着状態が続きました。終盤になってようやく韓国が決勝点を挙げ、スコアは2-1で決着しました。
これにより、千問の予測はより「シナリオを読んでいる」感を強めました。勝敗の判断は戦力差で可能かもしれませんし、スコアの予想には運の要素も含まれます。しかし、レッドカード、逆転、終盤の決勝点といった試合の過程の細部を捉えていたことで、人々は「これは只者ではない」と感じ始めました。初日の2試合を終え、千問はAIによるワールドカップ予測への注目度を一気に高めました。
Copilot:神がかり的な的中もあれば、明らかな失敗も
試合前、USA TodayはCopilotに今回のワールドカップ全104試合を予測させました。これまでに終了した試合を見る限り、この予測には見事な的中と明らかな失敗の両方が含まれています。
その中でも、特に際立った予測が3試合ありました。
開幕戦のメキシコ対南アフリカ戦では、Copilotはメキシコの2-0勝利を予測し、最終スコアは見事に一致しました。韓国対チェコ戦では韓国の2-1勝利を予測し、これも実際の結果と一致しました。そして、ブラジル対モロッコ戦では1-1の引き分けを予測し、結果的にブラジルはモロッコに引き分けに持ち込まれました。
特にブラジル1-1モロッコの予測は、価値の高いものでした。ブラジルは言うまでもなく伝統的な強豪であり、戦力も注目度もトップクラスです。前回大会でベスト4に入ったモロッコとはいえ、ブラジルを相手に試合前から引き分けを予想するのは、決して安全な選択とは言えません。ところが試合が終わってみれば、ブラジルは白星スタートを切れず、モロッコもビッグマッチでの粘り強さを発揮。Copilotのこの予測はまさに「神がかり的」でした。
しかし、Copilotの問題点もすぐに明らかになりました。
Copilotはカナダが2-1でボスニア・ヘルツェゴビナに勝利すると予測しましたが、実際は1-1の引き分け。スイスが1-0でカタールに勝利すると予測しましたが、スイスも引き分けに終わりました。アメリカが2-0でパラグアイに勝利すると予測しましたが、方向性は合っていたものの、実際のスコアは4-1で、攻撃力が明らかに過小評価されていました。
より明らかな失敗は、いくつかの番狂わせや強豪チームが苦戦した試合で発生しました。
トルコ対オーストラリア戦では、Copilotはトルコの2-1勝利を予測しましたが、オーストラリアが2-0で番狂わせの勝利を収めました。エクアドル対コートジボワール戦では、エクアドルの2-1勝利を予測しましたが、コートジボワールが1-0で勝利。オランダ対日本戦では、オランダの2-1勝利を予測しましたが、日本が2度追いつき、最終的に2-2の引き分け。スウェーデン対チュニジア戦では1-1を予測しましたが、スウェーデンが5-1で大勝しました。
Copilotはメキシコ、韓国、ブラジルの具体的なスコアを的中させたことから、単に人気チームに従った答えを出しているわけではないことがわかります。しかし、オーストラリアがトルコに勝利、カタールがスイスに引き分け、日本がオランダに引き分けたといった試合は、番狂わせや引き分けの判断において依然として保守的であることを露呈しました。
ChatGPT:分析はしっかりしているが、番狂わせの捕捉は不十分
Copilotの全試合予測とは対照的に、ChatGPTはどちらかと言うと「試合前分析型のプレイヤー」です。
開幕戦の予測では、ChatGPTはメキシコの2-0勝利を予測し、最終スコアは的中しました。その理由付けも比較的詳細で、メキシコのホームアドバンテージ、最近の調子、南アフリカの攻撃力不足、そしてメキシコシティの高海拔とホームの雰囲気などの要素が挙げられていました。この予測では、ChatGPTは結果を出しただけでなく、その背後にある判断ロジックも試合結果と合致していました。
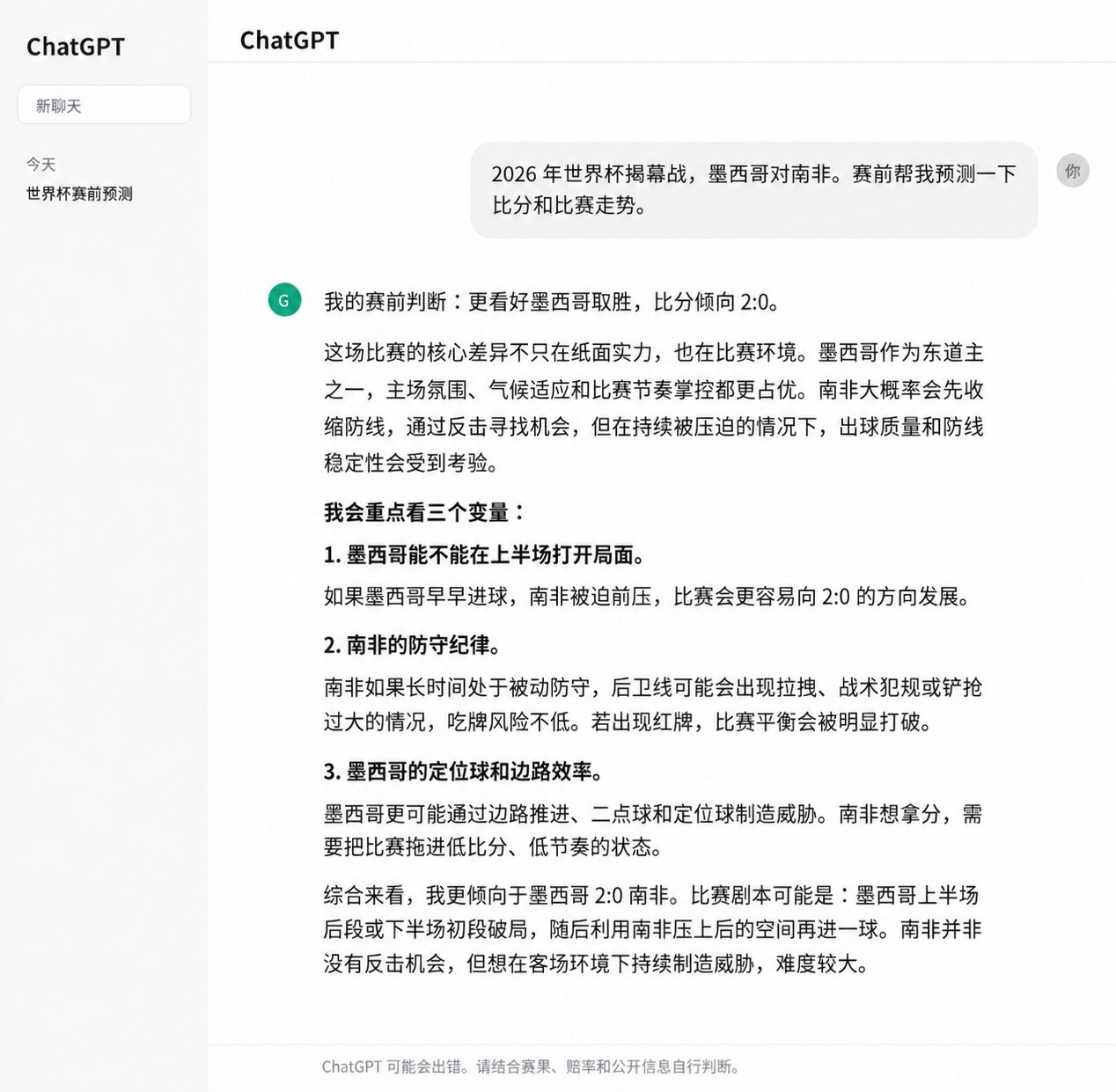
しかし、ワールドカップの全試合予測となると、ChatGPTの安定性はそれほど高くありませんでした。メキシコの2-0勝利とブラジル1-1モロッコを的中させ、スコットランド、ドイツ、スウェーデンなど数試合の勝敗方向も当てました。ですが、韓国2-1チェコ、カタール1-1スイス、オーストラリア2-0トルコ、日本2-2オランダといった試合では、ChatGPTの判断は全て戦力で勝ると見られるチームの勝利を予測していました。例えば、スイスがカタールに勝つ、トルコがオーストラリアに勝つ、オランダが日本に小勝する、といった具合です。
ChatGPTに予測能力がないわけではありません。チーム力、ホーム環境、最近の調子などを明確に分析でき、一部の試合ではスコアを的中させることもできます。しかし、これまでの結果を見ると、「なぜ人気チームの方が合理的か」を説明するのは得意ですが、どの試合が人気チームの想定シナリオから外れる可能性があるかを事前に見極めるのは苦手なようです。
Gemini、Grok、Claude:同じ試合でも、モデルによって異なるシナリオ
千問、Copilot、ChatGPT以外にも、ソーシャルメディア上で同じ試合を複数のモデルに入力して事前予測をさせるユーザーがいます。
開幕戦のメキシコ対南アフリカ戦を例に、あるブロガーがChatGPT、Gemini、Grok、Claudeの4つのAIモデルを同時にテストし、試合前の予測をさせました。その結果、ChatGPTとGeminiは共にメキシコの2-0勝利を予測し、最終スコアは的中。Grokはメキシコの2-1勝利、Claudeはメキシコの3-1勝利を予測し、いずれもメキシコの勝利は当てていましたが、具体的なスコアは外しました。
この開幕戦の予測では、異なるモデルが3種類の異なる「シナリオ」を描き出しました。ChatGPT GoとGemini Proは実際の試合に近く、メキシコ優勢、南アフリカ攻撃力不足、最終的に完封負けという内容。Grokはより開かれたスコアを予想し、南アフリカが反撃で得点すると見ていました。Claude Sonnetはメキシコの攻撃力をより高く評価し、3-1といった大味な結果を予測しました。
まとめ
現時点で振り返り可能なAI予測サンプルはまだ限られており、どのモデルが最も「サッカーに詳しい」かを断定的に判断することはできません。
しかし、既に終了した数試合だけ見ても、違いは現れ始めています。千問は現時点で最も印象的で、初日にメキシコ2-0南アフリカ、韓国2-1チェコを連続で的中させ、さらにレッドカードリスクや試合の流れも捉えており、小サンプルながら非常に輝かしいパフォーマンスを見せました。ただし、今後も継続的に的中できるかは、さらなる試合での検証が必要です。
CopilotとChatGPTは、どちらも具体的なスコアを的中させる輝かしい場面がありましたが、共通の問題点も明らかになりました。それは、オーストラリアがトルコに勝利、カタールがスイスに引き分け、日本がオランダに引き分けたといった、戦力差から外れた試合に対する判断が依然として鈍いことです。
Gemini、Grok、Claudeなどのモデルについては、現時点で公開されているサンプルは単一試合やソーシャルメディア上の比較に集中しており、参考価値はあるものの、すぐに順位付けするのは適切ではありません。
AIはワールドカップ予測市場のユーザーにとって一つの参考材料になりつつありますが、まだ正解には程遠い存在です。今後、Odaily星球日報も各モデルの試合前予測を継続的に収集し、試合の進行に合わせて検証を続けていきます。どのモデルが単に開幕戦で運が良かっただけなのか、どのモデルが本当に多くの試合で結果に耐えうるのか。


