
「もうより良いモデルは必要ない」:Redditのホットポストに見るAIの現在地
- 核心的な見解:Anthropicが発表したClaude Fable 5モデルはベンチマークテストで大幅にリードしているものの、ユーザーの間では性能過剰、コスト高、そしてセーフティガードにより大半のリクエストが拒否されていることから、「十分派」と「高度タスク派」の間で激しい議論が巻き起こっている。
- 重要な要素:
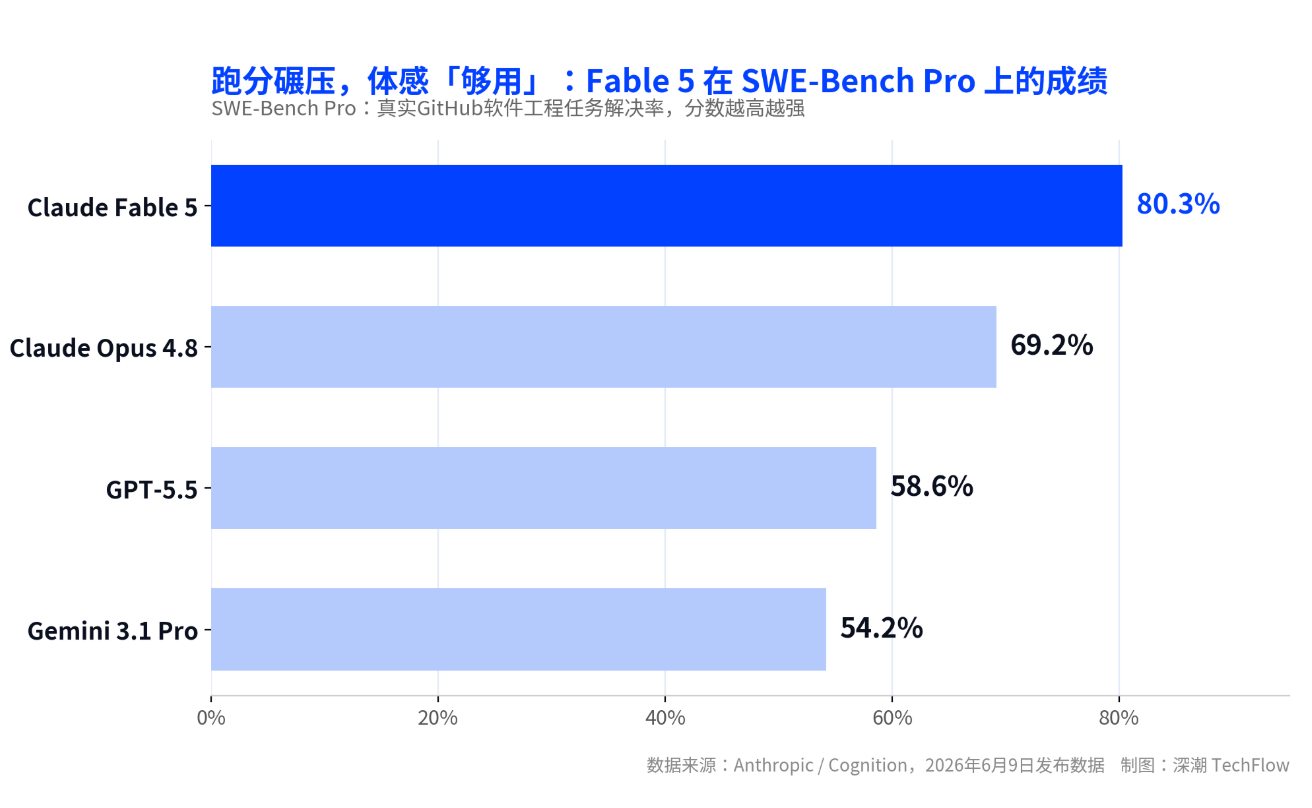
- Claude Fable 5はSWE-Bench Proベンチマークテストで80.3%のスコアを記録し、GPT-5.5を20ポイント以上リードしているが、API価格(入力トークン100万あたり10ドル)は前世代のOpus 4.8の約2倍となっている。
- 主流のユーザー感情は「モデル疲れ」であり、現在の旗艦モデル(Opus 4.8など)で日常業務は十分であり、Fableの性能向上はトークンコストの高騰と低い投資対効果をもたらすと見なされている。
- セーフティガードが最大の不満点となっている:ユーザーからは、セキュリティ関連のリクエスト(コードレビューなど)の最大90%が拒否され、Opusにダウングレードして処理されるケースもあり、有料ユーザーのユーザビリティ体験が著しく損なわれているとの報告が上がっている。
- 反対意見としては、Fableは高エネルギー物理学シミュレーションや超長文コンテキストといった複雑なタスクにおいて「昼夜の差」ほどの性能向上を見せており、日常的なモデルではなく「プランナー兼修正者」としての役割に適しているという指摘がある。
- 「公開AI凍結論」を唱えるコメントも見られる:一般ユーザーがアクセスできるモデルは停滞する一方、企業や政府はより強力な非公開モデル(例えば一般公開されないMythos 5)を持つようになる可能性があると指摘されている。
原文著者:星期五、深潮 TechFlow
Anthropic が提出したのは、紙面上では非の打ち所がない成績表だった。
6 月 9 日にリリースされた Claude Fable 5 は、同社初の一般公開となる Mythos 級モデルであり、実際のソフトウェアエンジニアリングタスクベンチマーク SWE-Bench Pro で 80.3% を記録。前世代の旗艦モデル Opus 4.8 を約 11 ポイント、GPT-5.5 を 20 ポイント以上上回った。
しかし、ユーザーの反応は冷や水を浴びせるものだった。
リリースから 3 日後、r/artificial セクション(週間アクセス数 30.5 万)に投稿されたホットなスレッドのタイトルは次の通りだ。「Claude Fable で気付いた、もうこれ以上のモデルは必要ないと。」投稿者の Axi0m-22 は、Fable をセキュリティ研究や日常業務にしばらく使った後、すぐに Opus でコードを書き、Haiku で雑務を処理する元の使い方に戻したという。彼はこう例えた。iPhone 14 を持って iPhone 17 の発表を見ているようなものだ。「新しい方が良いのは分かっているけど、思うのは『まあ、これで十分だ』ということだ。」
高評価エリアは「十分派」が占拠:モデルに対する美的疲労が主流の感情に
最も支持されたコメントは 42 の「いいね」を獲得した。「より大きなコンテキストウィンドウ以外は、Opus 4.5 からもう、より強力なモデルが必要だとは思わなくなった。」
別のユーザー hyprlab の発言は 13 の「いいね」を得た。「トークンをより多く消費するモデルに変えても、自分のワークフローにメリットが見えない。Opus 4.8 のハイインテンシティモードで十分快適だ。」
この種の発言の背後には、共通するコストの計算がある。
Fable 5 の API 価格は、入力トークン 100 万あたり 10 ドルで、Opus 4.8 の約 2 倍に相当する。ユーザー siromega37 は率直に言う。「トークン消費は増えるが、投資収益率はない。私たちはプラトー(停滞期)に差し掛かっており、バブルはやがて弾けるだろうと思う。」
ユーザー hobopwnzor は、より体系的な解釈を加えた。「しばらく S 字カーブの頂点にいる。最近の進歩は主にツール呼び出しや周辺エンジニアリングによるものであり、モデル自体の能力によるものではない。」
安全ガードレールが最大の不満点に:「用途の 90% が拒否される」
「十分」がまだ感情的なものに過ぎないとすれば、安全ガードレールに対する不満は具体的なプロダクト問題だ。
Anthropic の公式説明によると、Fable 5 は一部の機関のみに開放されている Mythos 5 と同一の基盤モデルを共有している。違いは Fable に安全分類器が搭載されている点だ。サイバーセキュリティなどのハイリスク領域に関わるリクエストはブロックされ、代わりに Opus 4.8 が応答する。同社はこの仕組みはやや控えめに調整されており、平均して 5% 未満のセッションでトリガーされ、無害なリクエストを誤って拒否することもあると説明している。
この Reddit スレッドでは、トリガー率の体感は明らかに 5% をはるかに上回っている。17 の「いいね」を獲得したユーザー jradoff は、Fable に自身のコードのセキュリティをチェックさせようとしたところ、「セキュリティ関連のことになると、基本的にほとんど処理を拒否する」ため、Opus にフォールバックされたと述べている。別の 12 の「いいね」を得たコメントはさらに辛辣だ。「使おうと思ったことの 90% が拒否されるなら、役に立たないも同然だ。」
有料ユーザーの不満はさらに大きい。月額 200 ドルプランの購読者 kaitava はこう書いている。「2 倍の使用料を払っているのに、セキュリティレビューをやらせようとしたら Opus に格下げされた。これで全てが嫌になった。OpenAI が追いついてくるのを待つだけだ。」
能力の飛躍を謳う旗艦製品にとって、「安全性のために支払うユーザビリティの代償」は、ユーザーが購入を決断するかどうかの核となる変数になりつつある。
反対意見:ヘビーユーザーの体感は「雲泥の差」
ホットなスレッドには反対者もいる。その反対者のプロフィールは極めて明確だ。タスクが重ければ重いほど、評価は高い。
ユーザー Phylaras のコメントは 15 の「いいね」を獲得した。「Fable は私にとって決定的な違いを生んだ。巨大なコンテキストウィンドウを必要とする複雑なタスクで、これまで見つけられなかったエラーを拾い出してくれた。」自ら高エネルギー物理シミュレーションを行っていると語るユーザーは、一つのシミュレーションモデルが往々にして 8000 から 1 万行のコードと何百もの相互作用するモデルで構成されていると述べ、「自律的に連続作業ができ、環境の詳細を理解できるモデルは、私にとって非常に待ち望んでいたものだ」と語った。
最も激しい反論はユーザー Navetz からのものだ。「正直に言って、このモデルを使ったことがある人なら、このスレッドの内容は狂気の沙汰に思えるだろう。私にとっては、まるで別人のように賢くなった。使い続けて止まらない。技術に詳しくない友人にはこう説明している。大学のバスケ選手からいきなり NBA のスタメンに変わったようなものだと。」
折衷的な使い方を提案する声もあった。ユーザー ready-eddy は、Fable を日常的な「構築者」ではなく、「計画者兼修正者」として使うことを提案し、費用を気にしないのであれば別だが、と付け加えた。別のコメントは、よりマニュアル的なまとめ方をしている。表計算を Fable に処理させるのはモデルの選択を誤っており、16 のエージェントが関与する複雑なタスクを Haiku に実行させるのも同様に誤っている。「生まれつき悪いモデルは存在しない。間違ったシナリオで使われたモデルがあるだけだ。」
ベンチマークスコアと体感の乖離が進む中、公開 AI は今後もより強力になるのか
この議論の中で最も興味深いコメントの一つが、話題をプロダクトから業界構造へと移した。
ユーザー KedMcJenna は「公開 AI の凍結説」を提唱した。一般の人が触れられるモデルは、現在の水準付近に永久に留まる可能性がある一方、企業や政府のエリートは引き続き、より強力な非公開モデルを入手できるだろう。「私たちが知っているのは Mythos までだが、おそらくそれ以上に強力で、決して耳にすることのないモデルが存在する。」
このコメントは一つの事実を指し示している。Mythos 5 は確かに一般公開されておらず、現在は Project Glasswing 計画を通じてサイバー防衛機関や重要インフラ企業にのみ提供されている。
ベンチマークスコアと世論の反応を総合的に見れば、結論は矛盾しない。
ベンチマークテストが測定するのは能力の上限であり、Reddit の高評価エリアが反映しているのは日常的な需要の天井である。大多数のユーザーのタスクが Opus 4.6 の時代にすでに満たされていたのであれば、より強力なモデルは、物理シミュレーションや超長文コンテキストといった極端なシナリオでのみその価値を証明できる。モデルメーカーが直面しているのは、もはや「できるかできないか」の問題ではなく、「誰がそれを必要とし、いくら払う意思があり、どれだけの安全上の摩擦を許容できるか」という問題なのである。
リリースから 3 日、Fable 5 はベンチマークランキングと世論の場で、全く異なる二つの成績表を受け取った。どちらの評価が真実に近いかは、Anthropic が今後どれだけ迅速に安全分類器を調整できるか、そしてヘビーユーザーが財布でどのような投票を行うかにかかっている。


