
Bittensor の解釈: 1 月は 400% 増加、AI + 暗号化トラックのダークホース
原作者:ノワー
オリジナル編集:ルフィ、フォーサイトニュース
関連ニュース:
TAO (Bittensor) の流通市場価値は 15 億米ドルを超え、市場価値の点で仮想通貨の上位 50 位にランクされました

友達の皆さん、お久しぶりです。皆さんも、仮想通貨分野における最近のポジティブな価格動向を楽しんでいただけたでしょうか。良い報酬を得るために、私は人工知能暗号化プロジェクト Bittensor に関する正式なレポートを書くことにしました。私は仮想通貨の専門家ではないので、人工知能についてはあまり詳しくないと思われるかもしれません。しかし実際には、私は自由時間の多くを暗号通貨以外の AI 研究に費やしており、過去 3 ~ 4 か月にわたって AI 分野の重要なアップデート、進歩、既存のインフラストラクチャに精通してきました。
ツイートの中には不正確な表現や分析が不足しているものもあったが、記録を正したいと思う。この記事を読めば、Bittensor について予想以上に詳しく知ることができるでしょう。これは少し長いレポートですが、言葉を重ねるつもりはありませんでしたが、これは主に多数の写真とスクリーンショットによるものです。概要を得るために ChatGPT に記事を入力しないでください。私はこれらに多くの時間を費やしていますが、それではストーリー全体を理解することはできません。
このレポートを書いているとき、友人(たまたまクリプトツイッターのKOL)が「AI + 暗号通貨 = 金融の未来」と言いました。この記事を読むときは、この点に留意してください。
人工知能は、暗号通貨が世界を征服し始めるためのパズルの最後のピースなのでしょうか、それとも私たちの目標に向けた小さな一歩にすぎないのでしょうか?答えを見つけるのはあなた次第ですが、私はただ考える材料を提供しているだけです。
背景情報
Bittensor 氏の言葉によれば、Bittensor は本質的に、統一されたトークン システムの下に位置する多数の分散型商品市場または「サブネットワーク」を記述するための言語です。その目標は、デジタル市場の力を社会で最も重要なデジタル商品に誘導することです。
Bittensor の使命は、独自のインセンティブ メカニズムと高度なサブネットワーク アーキテクチャを通じて、「OpenAI のような巨大企業のみが達成できる」以前のモデルと競合できる分散型ネットワークを構築することです。 Bittensor は、相互運用可能な部品の完全なシステム、つまりチェーン上での人工知能機能の普及を促進するためにブロックチェーンの助けを借りて構築されたマシンとして最もよく想像されます。
Bittensor ネットワークを管理する 2 つの主要なプレーヤーは、マイナーとバリデータです。マイナーは、報酬の分配と引き換えに、事前トレーニングされたモデルをネットワークに送信する個人です。バリデーターは、これらのモデル出力の有効性と精度を確認し、ユーザーに返す最も正確な出力を選択する責任があります。たとえば、Bittensor ユーザーが AI チャットボットに派生商品や歴史的事実に関する簡単な質問に答えるようにリクエストした場合、その質問は、Bittensor ネットワークで現在実行されているノードの数に関係なく答えられます。
ユーザーが Bittensor ネットワークと対話する手順は、次のように簡単に説明されます。ユーザーはバリデーターにクエリを送信し、バリデーターはそれをマイナーに伝播し、バリデーターはマイナー出力をランク付けし、最高ランクのマイナー出力が送信されます。ユーザーに戻ります。
すべてとてもシンプルです。
通常、インセンティブを通じてモデルは最高の出力を提供し、Bittensor はマイナーが互いに競争して、より洗練された、正確で高性能なモデルを導入して TAO (Bittensor エコロジー トークン) のより大きなシェアを獲得する正のフィードバック ループを作成します)。よりポジティブなユーザーエクスペリエンスを促進します。
バリデーターになるには、ユーザーは TAO の最初の 64 所有者の 1 人であり、Bittensor のサブネットワーク (さまざまな形式の人工知能へのアクセスを提供する独立した経済市場) のいずれかに UID を登録する必要があります。たとえば、サブネット 1 はテキスト プロンプトによるラベル予測に重点を置き、サブネット 5 は画像生成に重点を置いています。 2 つのサブネットワークは、タスクが大きく異なり、異なるパラメーター、精度、その他の特定の機能を必要とする可能性があるため、異なるモデルを使用する場合があります。
Bittensor のアーキテクチャのもう 1 つの重要な側面は、Bittensor が利用できるリソースをサブネット ネットワーク全体に分散する CPU に似た Yuma コンセンサス メカニズムです。 Yuma は、オフチェーンでインテリジェンスを送信および促進する機能が追加された、PoW と PoS のハイブリッドとして説明されています。 Yuma は Bittensor のネットワークの大部分を支えていますが、サブネットワークは Yuma のコンセンサスに参加するか依存しないかを選択できます。詳細は複雑かつ曖昧で、さまざまなサブネットと対応する Github が存在するため、一般的な理解を求めるだけの場合は、Yuma コンセンサスへのトップダウン アプローチを知っていれば十分です。

しかし、モデルについてはどうでしょうか?
一般に信じられていることに反して、Bittensor は独自のモデルをトレーニングしません。これは非常に高価なプロセスであり、大規模な AI ラボや研究組織のみが行うことができ、長い時間がかかる場合があります。 Bittensor にモデル トレーニングが含まれているかどうかについて絶対的な答えを出そうとしましたが、決定的な結論は得られていません。

分散型トレーニングメカニズムは発音が少し難しいですが、理解するのは難しくありません。 Bittensor バリデーターは、「Falcon Refined Web 6 T-Token のラベルなしデータセット上でマイナーが生成したモデルを評価する継続的なゲームをプレイする」という任務を負っており、タイムスタンプと他のモデルと比較した損失という 2 つの基準に基づいて各モデルを評価します。損失関数は、特定の種類のシミュレーションにおける予測値と実際の値の差を記述するために使用される機械学習用語であり、入力データとモデル出力を考慮したエラーまたは不正確さの程度を表します。
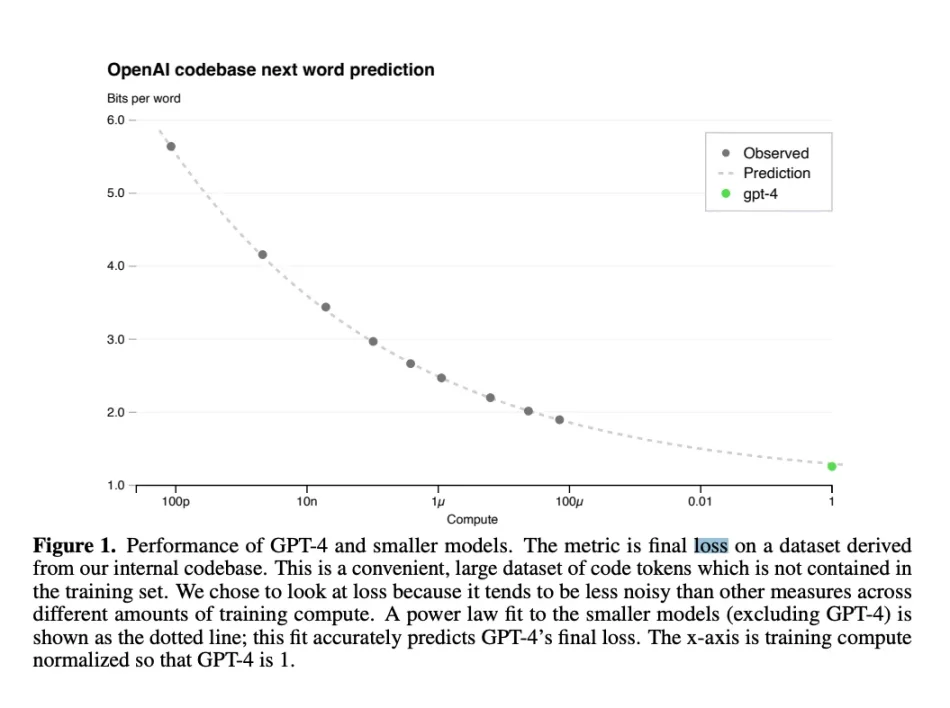
損失関数に関しては、昨日 Discord から取得した SN 9 (関連するサブネットワーク) の最新のパフォーマンスを示します。最小損失が必ずしも平均損失を意味するわけではないことに注意してください。
「Bittensor 自体がモデルをトレーニングしない場合、他に何ができるでしょうか?!」
実際、大規模言語モデル (LLM) の「作成」プロセスは、トレーニング、微調整、および文脈学習 (少し推論を追加) という 3 つの主要な段階に分かれています。
基本的な定義に進む前に、LLM に関する Sequoia Capital の 2023 年 6 月の記事を見てみましょう。報告「通常、LLM API の使用に加えて、15% の企業がカスタム言語モデルをゼロから構築するか、オープンソース ライブラリに基づいて構築しました。カスタム モデルのトレーニングは、わずか数か月前に比べて大幅に増加しました。これには、コンピューティングが必要です」 Hugging Face、Replicate、Foundry、Tecton、Weights Biases、PyTorch、Scale などの人気企業のスタック、モデル ハブ、ホスティング、トレーニング フレームワーク、実験追跡などを提供しています。」
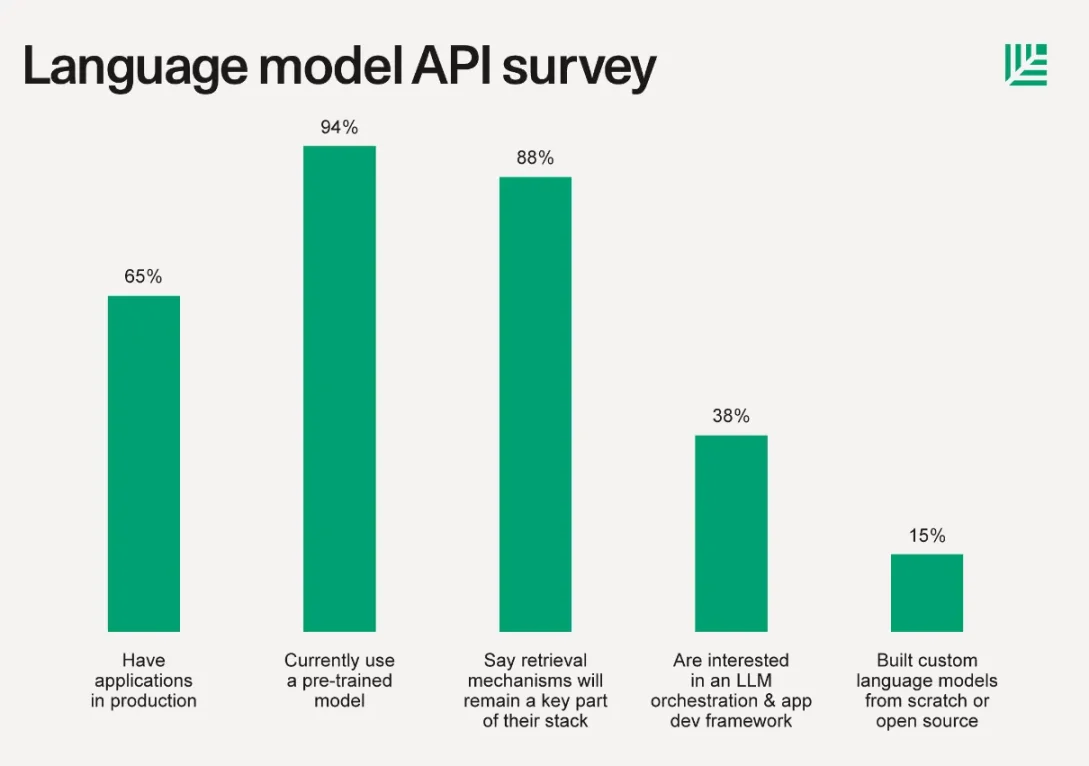
モデルをゼロから構築するのは気の遠くなる作業であり、調査対象となった創業者とチームの 85% はそれに取り組むことに消極的でした。ほとんどのスタートアップや独立系開発者が、外部アプリケーションやソフトウェアベースのサービスで大規模な言語モデルのみを活用したい場合、セルフホスティング、結果の追跡、複雑なトレーニング シナリオの作成またはインポート、その他のさまざまなタスクの作業負荷は大変です。 AI 業界の 99% にとって、GPT-4 や Llama 2 に匹敵するものを作成することは実現不可能です。
これが、Hugging Face のようなプラットフォームが非常に人気がある理由です。Web サイトから既にトレーニング済みのモデルをダウンロードできるためです。これは、AI 業界の人々にとって非常に馴染みのある一般的なプロセスです。
微調整はより困難ですが、特定の分野で大規模な言語モデルベースのアプリケーションやサービスを提供したい人に適しています。これは、さまざまな弁護士固有のデータや例に基づいて微調整されたモデルを備えたチャットボットを開発している法律サービスのスタートアップである可能性があります。あるいは、バイオテクノロジー関連の可能性のある情報に特に基づいてモデルを開発しているバイオテクノロジーのスタートアップの情報が微調整されている可能性があります。

目的が何であれ、微調整とは、モデルに個性や専門知識をさらに組み込んで、モデルをより適切に、より正確にタスクを実行できるようにすることです。便利でカスタマイズしやすいことは否定できませんが、a16z であっても難しいことに誰もが同意します。考える:

Bittensor は実際にはモデルをトレーニングしませんが、独自のモデルをネットワークに送信するマイナーは、何らかの形でモデルを微調整していると主張していますが、この情報は一般には公開されていません (または、少なくとも検証するのは困難です)。マイナーは、競争上の優位性を守るためにモデルの構造と機能を秘密にしていますが、一部はアクセス可能です。
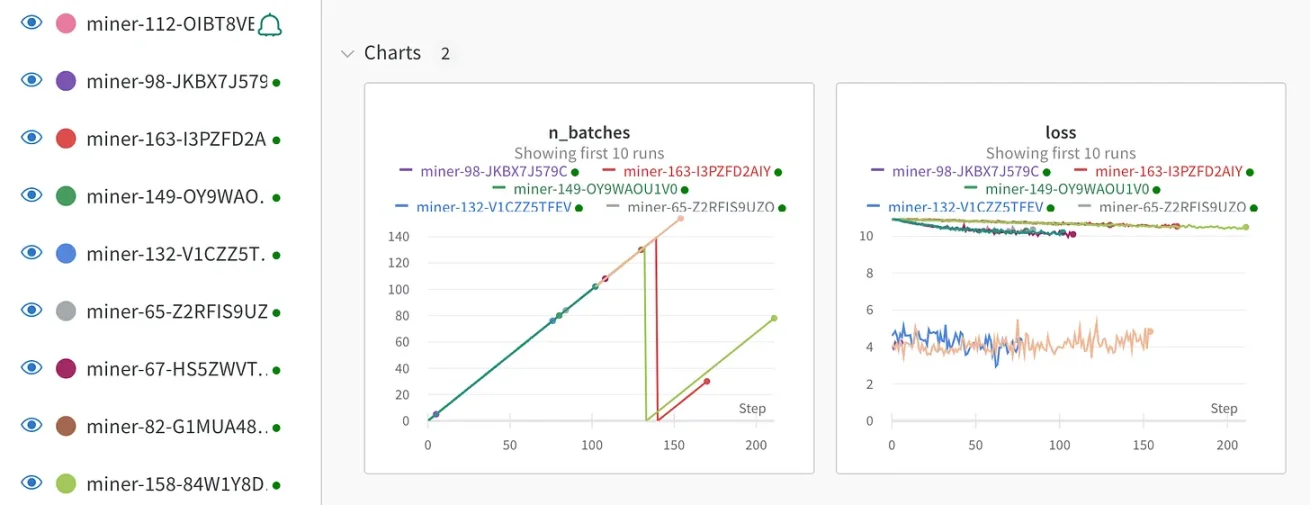
簡単な例を考えてみましょう。賞金 100 万ドルのコンテストに参加しており、誰が最も優れた LLM を持っているかを競い合っている場合、競合他社がすべて GPT-2 を使用している場合、自分が GPT を使用していることを明らかにしますか? -4?実際の状況はこの例で示すよりも複雑ですが、それほど違いはありません。マイナーは出力精度に基づいて報酬を受け取るため、微調整するモデルが少ないマイナーや平均パフォーマンスが低いモデルよりも有利になります。
文脈学習については以前に言及しましたが、おそらくこれが Bittensor 以外の情報として取り上げる最後の部分になりますが、文脈学習は、言語モデルをガイドしてより望ましい出力を達成するための広義のプロセスです。推論は、モデルが入力を評価するときに継続的に実行されるプロセスであり、そのトレーニングの結果は出力ラベルの精度に影響を与える可能性があります。トレーニングにはコストがかかりますが、モデルの作成時にチームが指定したトレーニング レベルにモデルが到達する準備ができている場合にのみ発生します。推論は常に行われており、推論プロセスを促進するためにさまざまな追加サービスが使用されます。
ビテンソルのステータス
背景を踏まえて、Bittensor サブネットのパフォーマンス、現在の機能、将来の計画について詳しく説明します。正直に言うと、このトピックに関する質の高い記事を見つけるのは困難です。幸いなことに、Bittensor コミュニティのメンバーがいくつかのメッセージを私に送ってくれましたが、それでも意見を形成するには多大な労力がかかりました。私は答えを探して彼らの Discord に潜んでいました。その過程で、メンバーになってから 1 か月ほど経ちましたが、どのチャンネルも見ていないことに気づきました(Discord はまったく使用せず、Telegram と Slack をよく使います)。
とにかく、私は Bittensor の最初のビジョンが何であったかを調べてみることにしました。以前のレポートで見つけた内容は次のとおりです。

これについては次の数段落で説明しますが、構成可能性の理論は成り立ちません。このトピックについてはいくつかの研究が行われています。前のスクリーンショットは、Bittensor ネットワークを疎混合モデルとして定義したものです (この概念は 2017 年の研究です)紙提出済み)。
Bittensor には非常に多くのサブネットワークがあるため、このレポートで 1 つのセクション全体をサブネットワークに捧げる必要があると感じました。信じられないかもしれませんが、これらは Web の有用性にとって極めて重要であり、すべてのテクノロジーを支えているにもかかわらず、Bittensor の Web サイトには、これらとその仕組みを説明する専用のセクションがありません。 Twitterでも聞いてみましたが、サブネットの秘密は何時間もDiscordにたむろして各サブネットの操作を自力で覚えた人にしか理解できないようです。目の前の仕事が膨大であったにもかかわらず、私はいくつかの仕事をしました。
サブネット 1 (sn 1 と略されることが多い) は、Bittensor ネットワーク内で最大のサブネットであり、テキスト生成サービスを担当します。 SN 1 の上位 10 バリデーター (他のサブネットでも同じ上位 10 ランキングを使用しています) には、約 400 万の TAO ステークがあり、次に SN 5 (イメージ生成を担当) があり、約 385 万の TAO プレッジがあります。ちなみに、このデータはすべて次のサイトで入手できます。TaoStatsで見つかりました。
マルチモーダル サブネットワーク (sn 4) には約 340 万の TAO があり、sn3 (データ スクレイピング) には約 340 万の TAO があり、sn 2 (マルチモーダル) には約 370 万の TAO があります。最近急速に成長しているもう 1 つのサブネットワークは sn 11 です。これはテキスト トレーニングを担当しており、sn 1 と同数の TAO 誓約を持っています。
Sn 1 は、マイナーおよびバリデーターのアクティビティの点でも絶対的なリーダーであり、アクティブなバリデーターは 40/128 人以上、アクティブなマイナーは 991/1024 人を超えています。実際、Sn 11 にはすべてのサブネットの中で最も多くのマイナーが存在し、その数は 2017/2048 です。以下のグラフは、過去 1 か月半のサブネット登録コストを示しています。
現在のサブネット登録コストは 182.12 TAO で、10 月のピーク時の 7,800 TAO から大幅に減少していますが、この数字が正確であるかどうかは完全にはわかりません。いずれにせよ、22 を超えるサブネットワークが登録されており、Bittensor への注目が高まっているため、やがてさらに多くのサブネットワークが登録されることになるでしょう。これらのサブネットワークの中には、普及に時間がかかるものもあるようです。
他のサブネットワークに関する限り、sn 9 はトレーニング専用の優れたサブネットワークです。

以下は Bittensor の説明ですクロールサブネットの指示:

サブネットワーク モデルは非常にユニークで、専門家の混合 (MoE) と呼ばれる機械学習研究における一般的な手法の一例です。この手法では、モデルがタスク全体を割り当てられるのではなく、部分に分割され、個別のラベルが付けられます。 Bittensor は統一モデルではなく、実際には半ランダムな方法でクエリされるモデルのネットワークであるため、これは私にとって興味深いものです。このプロセスの例は、受信ユーザーによってクエリされた上位 10 位のマイナーをランダムにサンプリングする sn 1 に基づいて構築された製品である BitAPI です。特定のサブネットワークには数十、場合によっては数百のマイナーが存在する可能性がありますが、最もパフォーマンスの高いモデルにはより大きな報酬が与えられます。
現在のところ、複数のモデルを組み合わせたり複合したりして機能を追加または「スタック」することは現実的ではなく、これは大規模な言語モデルの仕組みではありません。私はコミュニティ メンバーと議論しようとしましたが、現状では Bittensor は統一されたモデルのコレクションの一例ではなく、異なる機能を持つモデルのネットワークにすぎないことに注意することが重要だと思います。
Bittensor を ML モデルにアクセスできるオンチェーンオラクルと比較する人もいます。 Bittensor は、ブロックチェーンのコア ロジックをサブネットワークの検証から分離し、モデルをオフチェーンで実行して、より多くのデータとより高い計算コストに対応することで、より強力なモデルを実現します。オンチェーンで実行される唯一のプロセスは推論であることを思い出してください。以下を参照してくださいコンテンツBitensor の説明をご覧ください。
コミュニティの多くの人々は、実際には人工知能と暗号通貨の相互作用の方法を変えようとして前進しているだけなのに、Bittensor が世界を変えようとしていると皆を説得しようとすることに集中しすぎていると思います。モデルをアップロードするマイナーのネットワーク全体を非常にスマートなスーパーコンピューターに変換できる可能性は低いです。機械学習はそのように機能しません。入手可能な最高のパフォーマンスと最も高価なモデルであっても、汎用人工知能 (AGI) の定義を達成するにはまだ何年もかかります。
機械学習コミュニティが反復を続け、新しい機能が実装されるにつれて、AGI の定義は変わることがよくありますが、基本的な考え方は、AGI は人間とまったく同じように推論、思考、学習できるということです。核心的な謎は、科学者が人間を意識と自由意志を持った存在として分類しているという事実から生じているが、強力なニューラルネットワークシステムはもちろん、人間においてそれを定量化することは困難である。
現状では、サブネットワークは AI ベースのアプリケーションに関連するさまざまなタスクを分解する独自の方法であり、Bittensor ネットワークのこれらのコア機能を利用したいビルダーを引き付けるのはコミュニティとチームの責任です。
ここで、Bittensor が暗号通貨以外の機械学習の分野でも非常に効率的であることも付け加えておく価値があります。 Opentensor と Cerebras は、今年 7 月には BTLM-3 b-8 k オープンソース LLM をリリースしました。それ以来、BTLM は Hugging Face で 16,000 回以上ダウンロードされ、非常に好評を博しています。
BTLM の軽量アーキテクチャにより、BTLM-3 b は Mistral-7 b や MPT-30 b と同じカテゴリで上位にランクされ、「VRAM ごとに最高のモデル」になるという人もいます。以下は、BTLM-3 b が適切な評価を受けたモデルとそのデータ アクセシビリティ分類をリストした同じツイートのグラフです。
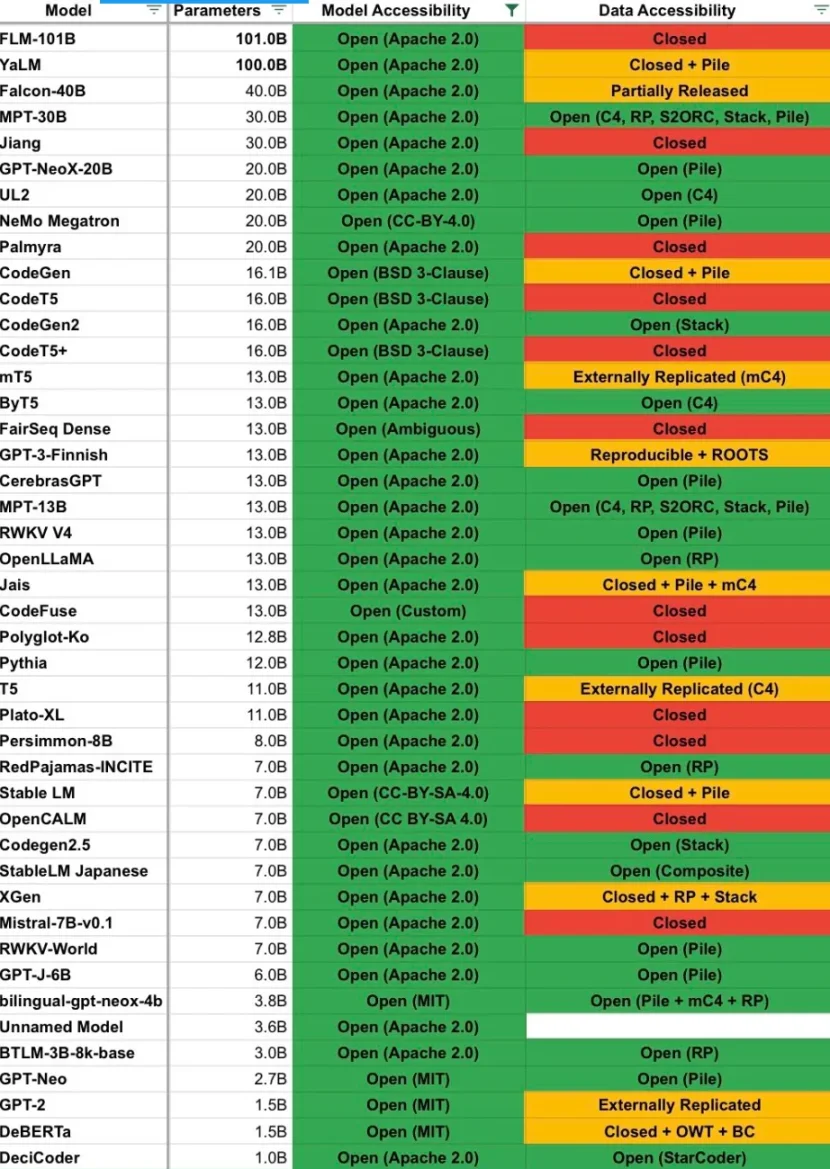
私は Twitter で、Bittensor は AI 研究を促進するようなことは何もしていないと言いました。ですから、ここで自分の間違いを認めるのは当然だと思います。また、BTLM-3 b は安価でほとんどのハードウェアで高速に動作するため、検証に使用される場合もあると聞いています。
TAOは何に使われますか?
心配しないでください、トークンを忘れたわけではありません。
Bittensor はビットコインから多くのインスピレーションを得ていますが、OG 教科書のゲームプレイからも引き出しており、非常によく似たトークン経済構造、つまり最大 2,100 万 TAO と 1,050 万ブロックごとの半減メカニズムを組み込んでいます。この記事の執筆時点で、流通している TAO の数は約 560 万、市場価値はほぼ 8 億ドルです。 TAO の配布は極めて公平であると考えられており、この Bittensor報告初期の支援者はトークンを受け取っていないことを指摘し、信頼性を検証することは困難ですが、私たちは情報源を信頼しています。
TAO は、Bittensor ネットワークの報酬トークンとアクセス トークンの両方であり、TAO 保有者は、ステークしたり、ガバナンスに参加したり、TAO を使用して Bittensor ネットワーク上にアプリケーションを構築したりできます。 1 TAO は 12 秒ごとに鋳造され、新しく鋳造されたトークンはマイナーとバリデーターに均等に分配されます。
私の意見では、TAOのトークンエコノミクスは、半減によってリリース量を減らすとマイナー間の競争が激化し、自然にモデルの品質が向上し、全体的なユーザーエクスペリエンスが向上する世界を容易に想像します。ただし、ここには問題もあります。それは、報酬が少ないと逆効果となり、激しい競争を呼び込む代わりに、導入されるモデルや競合するマイナーの数が停滞することにつながるということです。
TAO のトークンのユーティリティ、価格の見通し、成長の原動力についてはいくらでも説明できますが、前述のレポートはこれに関して非常に良い仕事をしています。仮想通貨ツイッターのほとんどは、Bittensor と TAO の背後に非常に確固たる物語があることをすでに確立しており、現時点で私が付け加えられることは何もありません。外部の観点から見ると、これらはかなり健全なトークン経済学であり、何もおかしなことではないと言えます。ただし、TAOはまだほとんどの取引所に上場されていないため、現在TAOを購入するのは非常に困難であることを言及しておく必要があります。この状況は1〜2か月以内に変わる可能性があり、BinanceがTAOをすぐに上場しない場合は非常に驚くでしょう。
見通し
私は間違いなくビッテンソールのファンであり、彼らがその大胆な使命を実現することを願っています。 Bittensor Paradigm のチームとして記事で述べたように、ビットコインとイーサリアムは金融へのアクセスを民主化し、完全に許可のないデジタル市場のアイデアを現実にするため、革命的です。 Bitensor も例外ではなく、広大なインテリジェント ネットワークで人工知能モデルを民主化することを目指しています。私のサポートにもかかわらず、彼らが達成したいことにはまだ程遠いことは明らかであり、それは暗号通貨で構築されたほとんどのプロジェクトに当てはまります。これは短距離走ではなくマラソンです。
Bittensor が最前線であり続けたいのであれば、スパース ハイブリッド モデル アーキテクチャ、MoE のアイデア、分散型でインテリジェンスを複合化する概念の可能性を拡大しながら、マイナー間の友好的な競争とイノベーションを推進し続ける必要があります。これらすべてを単独で実行することは十分に困難ですが、暗号化を組み合わせるとさらに困難になります。
ビッテンソールの前途はまだ長い。ここ数週間でTAOに関する議論が増えてきましたが、暗号通貨コミュニティのほとんどはBittensorが現在どのように機能するかを完全に認識していないと思います。簡単な解決策のない明白な疑問がいくつかあります。その中には、a) 高品質の大規模推論が可能かどうか、b) ユーザーを惹きつける問題、c) 複合大規模言語の目標を追求するのは理にかなっているかどうかなどがあります。モデル。
信じられないかもしれませんが、分散型通貨の物語をサポートすることは実際には非常に困難ですが、ETFの噂によりそれは少し容易になっています。
反復して相互に学習するインテリジェント モデルの分散型ネットワークを構築するというと、あまりにもうますぎるように聞こえますが、その理由の 1 つは、実際にそうなっているということです。バックグラウンド ウィンドウと大規模な言語モデルの現在の制約内では、AGI を使用しても最適なモデルさえも制限されるレベルに達するまで、モデルが何度も自らを改善することは不可能です。それでも、新しい経済的インセンティブと組み込みの構成可能性を備えた分散型 LLM ホスティング プラットフォームとして Bittensor を構築することは、単なるポジティブなことではなく、実際、現時点での暗号通貨における最もクールな実験の 1 つであると私は考えています。
AI システムに金銭的インセンティブを組み込むことには課題があり、マイナーやバリデーターが何らかの形でシステムを悪用しようとした場合、ケースバイケースでインセンティブを調整するとビッテンソール氏は述べた。これは、トークンのリリースが 90% 減少した今年 6 月の例です。

これはブロックチェーン システムでは完全に予想されることなので、ビットコインやイーサリアムがそのライフサイクル全体を通じて 100% 完璧であるなどというふりはしないでください。
歴史的に、暗号通貨の採用は部外者にとって飲み込むのが難しい薬であり、人工知能も同様に、あるいはそれ以上に物議を醸してきた。この 2 つを組み合わせると、誰にとってもユーザーの成長とアクティビティを維持するのに時間がかかります。 Bittensor が最終的に複合大規模言語モデルの目標を達成できれば、これは非常に重要なことになる可能性があります。


