
Xiaomi và MiniMax đồng loạt tung đòn lớn, cuộc chiến định giá Agent chính thức khai màn
- Quan điểm cốt lõi: Hai mô hình Agent lớn do công ty AI Trung Quốc MiniMax và Xiaomi phát hành gần đây, với mức giá API thấp hơn đáng kể so với các mô hình hàng đầu thế giới, đã đạt được hiệu suất tương đương, đại diện cho hai con đường phát triển công nghệ khác nhau: "tiến hóa tự lặp" và "tham số quy mô lớn".
- Yếu tố then chốt:
- Ưu thế giá cả nổi bật: Giá đầu ra API của MiniMax M2.7 và MiMo V2-Pro lần lượt là 1.2 USD/triệu tokens và 3 USD/triệu tokens, chỉ bằng 1/21 và 1/8 so với Claude Opus (25 USD).
- Hiệu suất đạt đến hàng đầu: Trong các đánh giá Agent chủ lưu như SWE-bench, hai mô hình này có hiệu suất chênh lệch rất nhỏ so với các mô hình hàng đầu thế giới (như Claude Sonnet, GPT-5.3-Codex), tạo thành "khoảng cách kéo giá-hiệu suất".
- Lộ trình công nghệ hoàn toàn khác biệt: MiMo V2-Pro áp dụng lộ trình "sức mạnh tạo nên kỳ tích" với tham số siêu nghìn tỷ, tăng cường xử lý ngữ cảnh dài; M2.7 thì tập trung vào cơ chế "tiến hóa tự lặp", nâng cao năng lực thông qua vòng lặp tối ưu hóa tự chủ.
- Chiến lược lặp khác biệt: MiniMax áp dụng lặp tần suất cao với bước nhỏ chạy nhanh (khoảng 49 ngày/phiên bản), trong khi Xiaomi lựa chọn lặp chu kỳ dài với sự nhảy vọt lớn về tham số và kiến trúc.
- Chiến lược phát hành sáng tạo: MiMo V2-Pro đã thử nghiệm mù trên nền tảng OpenRouter trong 8 ngày với tư cách là mô hình ẩn danh "Hunter Alpha", thu hút lượng lớn lượt gọi nhờ hiệu suất và giá cả rồi đứng đầu bảng xếp hạng, sau đó mới tiết lộ danh tính.
Vào ngày 18 và 19 tháng 3, hai công ty Trung Quốc đã lần lượt công bố các mô hình lớn (LLM) hướng Agent của riêng họ. Công ty khởi nghiệp AI trong nước MiniMax ra mắt M2.7, trong khi đội ngũ mô hình lớn MiMo thuộc Xiaomi ra mắt V2-Pro. Cả hai mô hình đều lọt vào top đầu toàn cầu trên bảng xếp hạng Agent benchmark, nhưng giá API đầu ra của chúng lần lượt chỉ bằng 1/21 và 1/8 so với Claude Opus 4.6.
Hai công ty ra bài trong cùng một tuần, nhưng những lá bài trong tay họ hoàn toàn khác nhau. Chúng đại diện cho hai con đường công nghệ hoàn toàn khác biệt, đặt cược vào hai tương lai khác nhau của kỷ nguyên Agent.
Cùng một kỳ thi, học phí chỉ bằng 1/17
Trước tiên, hãy xem xét sự so sánh trực quan nhất.
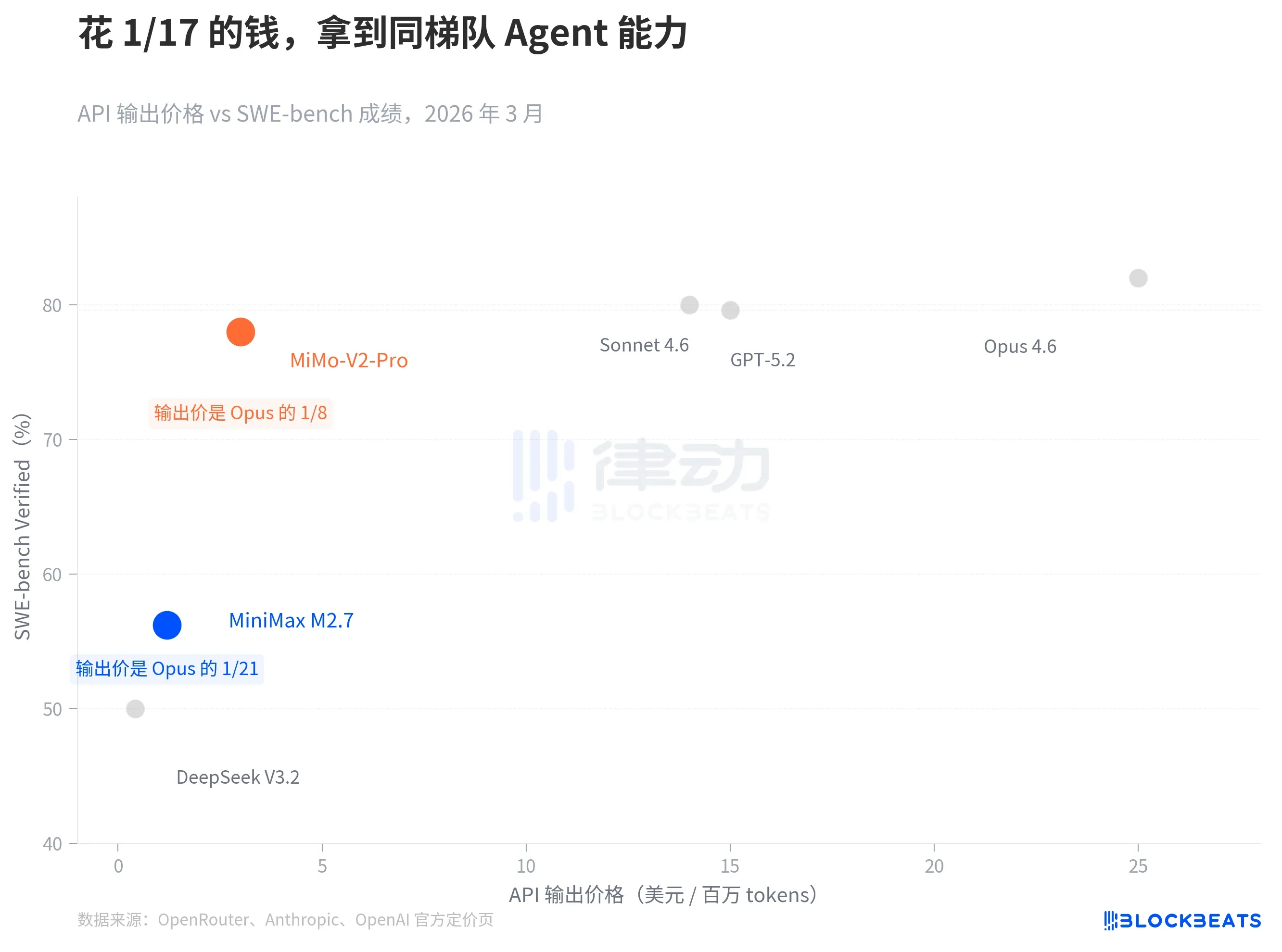
Theo dữ liệu từ OpenRouter và các trang định giá chính thức của các công ty, tính theo giá API đầu ra (trên mỗi triệu tokens), MiniMax M2.7 là 1.2 USD, MiMo-V2-Pro là 3 USD. Để tham chiếu, giá đầu ra của Claude Opus 4.6 là 25 USD, GPT-5.2 là 14 USD, và Claude Sonnet 4.6 là 15 USD.
Khoảng cách về giá là theo cấp số nhân, nhưng khoảng cách về năng lực thì không. Trên SWE-bench Verified (benchmark phổ biến nhất hiện nay để đo lường khả năng kỹ thuật mã), MiMo-V2-Pro đạt 78%, Sonnet 4.6 đạt 79.6%, chênh lệch chưa đến hai điểm phần trăm. Thành tích SWE-Pro của M2.7 là 56.22%, ngang bằng với GPT-5.3-Codex. Trên VIBE-Pro (khả năng giao hàng dự án end-to-end), M2.7 đạt 55.6%, gần bằng mức của Opus 4.6.
Điểm mấu chốt của biểu đồ này không nằm ở việc ai cao ai thấp - các hệ thống benchmark của các bên không hoàn toàn đồng nhất, cần thận trọng khi so sánh trực tiếp. Trọng tâm nằm ở "khoảng cách kéo giá-hiệu suất": các mô hình Agent trong nước đã len lỏi vào cùng một dải năng lực, nhưng đứng ở các phân khúc giá hoàn toàn khác nhau.
Ngàn tỷ tham số vs Tự tiến hóa
Giá cả chỉ là bề nổi. Hai công ty đã đưa ra hai lá bài nền tảng hoàn toàn khác biệt.
MiMo-V2-Pro đi theo con đường "sức mạnh tạo nên kỳ tích". Theo thông báo chính thức của Xiaomi, V2-Pro có tổng số tham số vượt quá 1 nghìn tỷ, với 42B tham số được kích hoạt, hỗ trợ ngữ cảnh siêu dài lên đến 1 triệu tokens. Đổi mới cốt lõi của nó là cơ chế chú ý hỗn hợp Hybrid Attention, điều chỉnh tỷ lệ giữa chú ý cửa sổ trượt (SWA) và chú ý toàn cục (GA) thành 7:1 - trong khi thế hệ trước V2-Flash là 5:1. Kiến trúc này giúp mô hình ổn định hơn trong các tình huống Agent xử lý tài liệu dài, gọi song song nhiều công cụ. Trên PinchBench (đánh giá khả năng gọi công cụ của Agent), MiMo-V2-Pro đạt 84%.
M2.7 đi theo một con đường hoàn toàn khác. Theo blog công nghệ chính thức được MiniMax công bố vào ngày 18 tháng 3, số lượng tham số của M2.7 không được tiết lộ, nhưng nó thể hiện một cơ chế "tự lặp tiến hóa": mô hình tự chạy hơn 100 vòng lặp tối ưu hóa, bao gồm phân tích đường đi thất bại, lập kế hoạch sửa đổi, sửa đổi kiến trúc mã của chính nó, chạy đánh giá, rồi lặp lại, cuối cùng đạt được cải thiện hiệu suất 30% trên tập đánh giá nội bộ. Trong 22 câu hỏi khó của MLE Bench Lite (đánh giá độ khó cuộc thi học máy), M2.7 giành được 9 huy chương vàng, 5 bạc, 1 đồng, với tỷ lệ huy chương trung bình là 66.6%.

Xét từ năm chiều, hai con đường hướng đến những ưu thế hoàn toàn khác nhau: MiMo-V2-Pro chiếm ưu thế rõ rệt về độ dài ngữ cảnh và chiều kỹ thuật mã, trong khi M2.7 tạo khoảng cách về khả năng tự động hóa văn phòng và tự lặp. Theo cùng một blog công nghệ của MiniMax, M2.7 đạt ELO 1495 trên GDPval-AA (đánh giá xử lý tài liệu văn phòng), đứng đầu trong các mô hình mã nguồn mở, và duy trì tỷ lệ tuân thủ kỹ năng 97% trong bài kiểm tra MM-Claw bao phủ hơn 40 kỹ năng phức tạp.
Bốn phiên bản trong năm tháng
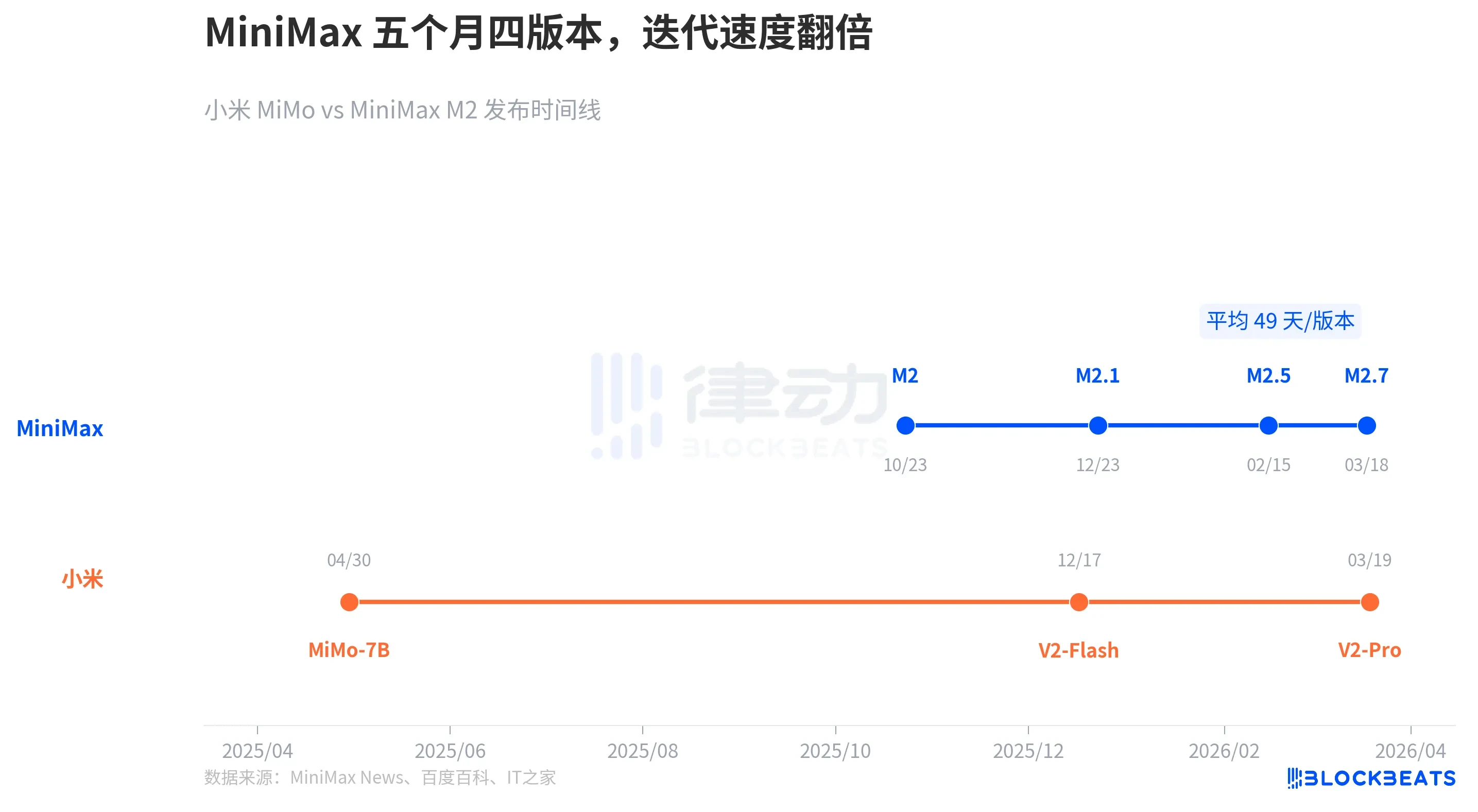
Hai công ty không chỉ khác nhau về con đường công nghệ mà còn khác biệt hoàn toàn về nhịp độ lặp.
Theo hồ sơ công bố công khai, từ khi ra mắt M2 vào tháng 10/2025 đến khi ra mắt M2.7 vào tháng 3/2026, MiniMax đã lặp lại bốn phiên bản trong vòng năm tháng, trung bình mỗi 49 ngày một phiên bản lớn. Trong đó, khoảng cách từ M2.5 đến M2.7 chỉ khoảng 30 ngày.
Nhịp độ của Xiaomi MiMo thì khác: ra mắt MiMo-7B (mô hình suy luận mã nguồn mở 7B tham số) vào tháng 4/2025, V2-Flash (tổng 309B tham số) vào tháng 12 cùng năm, và V2-Pro (tổng 1T tham số) vào tháng 3/2026. Mỗi thế hệ có bước nhảy vọt lớn hơn về quy mô tham số, nhưng khoảng cách giữa các phiên bản cũng dài hơn.
MiniMax chọn cách chạy nước rút từng bước nhỏ, mỗi lần lặp không quá lớn nhưng tần suất cực cao, và cơ chế tự lặp của M2.7 vốn được thiết kế cho "tiến hóa liên tục". Xiaomi chọn cách tích lũy lực rồi tung đòn mạnh, mỗi phiên bản đều là một bước nhảy vọt lớn về quy mô tham số và kiến trúc.
Ẩn danh 8 ngày, đứng đầu OpenRouter
Ngoài con đường công nghệ, chiến lược ra mắt của Xiaomi cũng phá vỡ thông lệ ngành.
Theo Reuters, vào ngày 11 tháng 3, một mô hình ẩn danh có tên Hunter Alpha xuất hiện trên nền tảng tổng hợp API lớn nhất thế giới OpenRouter. Không có sự bảo trợ thương hiệu, không có sự kiện ra mắt, không có blog công nghệ. Giá API của nó cực thấp, nhưng hiệu suất lại mạnh mẽ một cách bất ngờ.
Cộng đồng bắt đầu suy đoán về nguồn gốc của nó. Theo Republic World và nhiều phương tiện truyền thông công nghệ, phỏng đoán phổ biến nhất là DeepSeek V4, vì trưởng nhóm MiMo Luo Fuli trước đây từng nghiên cứu tại DeepSeek. Lượng gọi tăng nhanh chóng, tổng lượng gọi trong thời gian ẩn danh vượt 1 nghìn tỷ tokens, đứng đầu bảng xếp hạng tuần của OpenRouter.
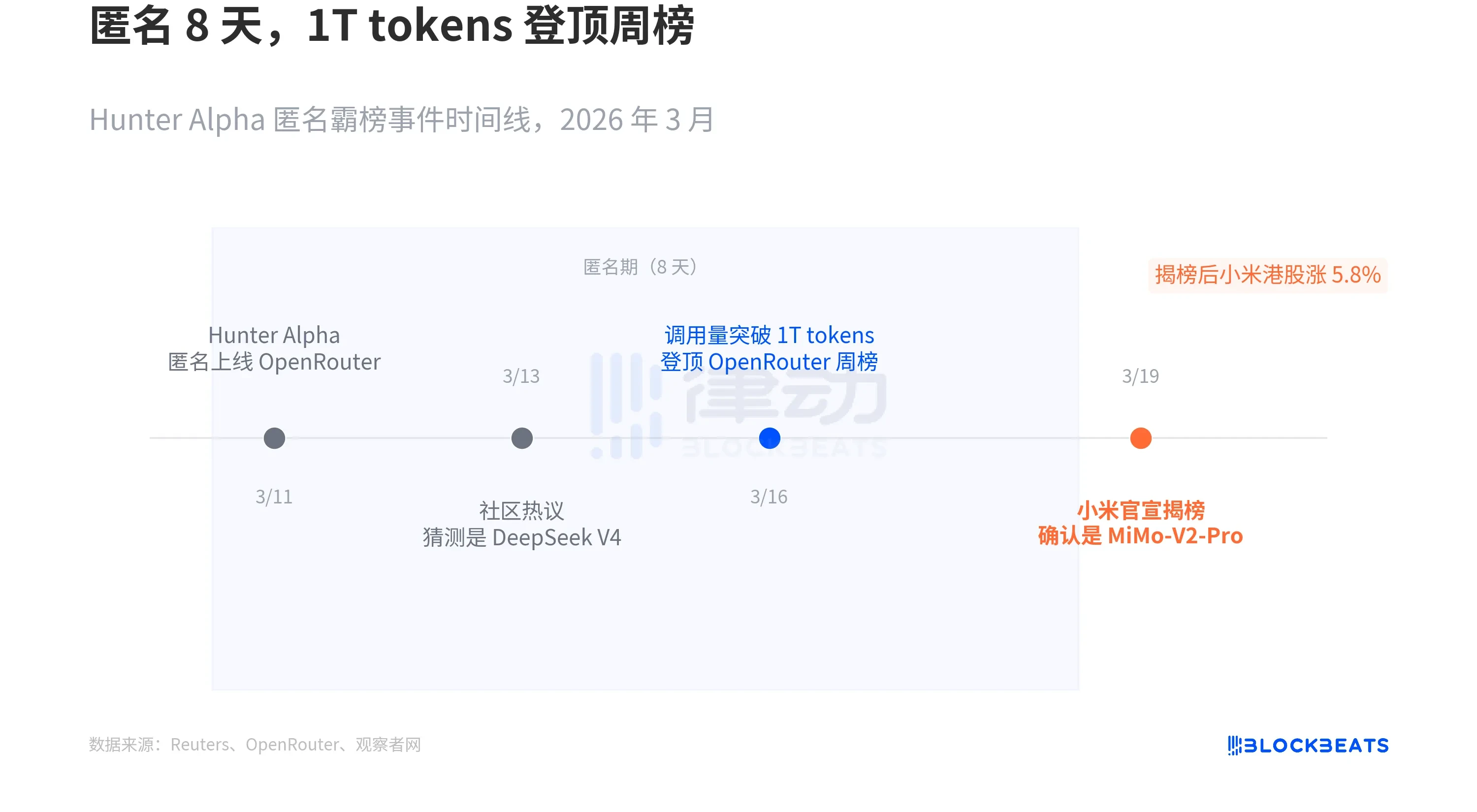
Vào rạng sáng ngày 19 tháng 3, Xiaomi tiết lộ: Hunter Alpha chính là MiMo-V2-Pro. Theo cùng bài báo của Reuters, sau khi tiết lộ, cổ phiếu Xiaomi trên sàn Hong Kong từng tăng tới 5.8%.
Đây là lần đầu tiên một mô hình lớn trong nước chứng minh bản thân trên nền tảng toàn cầu bằng phương thức thử nghiệm mù hoàn toàn. Không dựa vào thương hiệu, không dựa vào tuyên truyền, dùng 8 ngày để để các nhà phát triển bỏ phiếu bằng chân.


