
Meta sells computing power, Palantir complains, Zhipu becomes a Silicon Valley darling – The AI Capex narrative needs a new angle
- Core Thesis: The capital expenditure narrative in the AI industry is shifting from an aggregate "supply shortage" to a structural "utilization mismatch." Companies are starting to evaluate the actual returns on their computing power investments, and Meta's consideration of leasing idle computing power is a signal of this shift.
- Key Elements:
- Meta's potential move to lease AI computing power has raised market concerns about the sustainability of capital expenditure. However, the revenue of the three major cloud providers (AWS, Google Cloud, Azure) continues to grow strongly, and their cost guidance is rising rather than falling, indicating that aggregate demand has not collapsed.
- The computing power market is becoming stratified: top-tier cloud providers can continue to raise prices due to certainty (e.g., AWS GPU reserved instances saw a 20% price increase), while model companies and mid-tier computing power utilization face greater scrutiny. Companies are beginning to break down procurement based on task value.
- Enterprise AI adoption has entered a "cost-accounting" phase. A UBS survey shows that approximately 60% of surveyed companies are compressing their token expenditure. Palantir's CEO criticized the token billing model as a "wealth tax," emphasizing a shift from consumption-based to outcome-based pricing.
- Open-source models (e.g., Zhipu's GLM-5.2) are becoming a tool for enterprises to reduce AI spending. A case study from Coinbase shows that by switching the default model and optimizing operations, AI costs were halved while token usage continued to grow exponentially.
- Computing power mismatch is a key issue: Meta is considering selling its spare computing power on one hand, yet on the other hand, it struggles to purchase sufficient top-tier model capabilities from Google, highlighting a structural contradiction between assets and demand.
The AI market is experiencing another violent correction, this time because Meta mentioned it might sell its excess AI computing power.
If this news had come out three years ago, probably no one would have found it strange. Cloud computing has always been a business of slicing up servers and selling them to others. Amazon, Microsoft, and Google have been doing this for years. New cloud providers like CoreWeave and Nebius also follow this path, turning Nvidia chips into collateral for financing, and then using that financing to acquire more chips.
But when it comes to Meta, things take on a different flavor.
Meta hasn't understood computing power this way in the past. It buys chips, builds data centers, secures electricity and land—all for its own models, its advertising system, its recommendation feeds, and for the superintelligence that Zuckerberg speaks of as drawing ever nearer. It’s not a cloud provider. It never made money by renting out its machines to others.
A company that once said, "I need as many machines as possible because the future will consume them," now says, "If these machines are temporarily underutilized, we can sell access to others."
This doesn't directly prove an oversupply of computing power, but it’s also not something to be dismissed lightly.
On the day of the stock market crash, Palantir CEO Alex Karp appeared on CNBC and ranted at the camera for nearly twenty minutes.
He was originally there to discuss Palantir's new partnership with Nvidia, but he quickly turned the conversation towards the token-based pricing models of OpenAI and Anthropic. He said CEOs privately complain to him that current enterprise AI adoption involves "paying for tokens that create no value while having to hand over their data." He even described the increasingly expensive model bills as a wealth tax imposed on businesses.

For the past two years, the main discussion was about who dared to spend, who spent fastest, and who could pile up data centers first. But now the question is gradually changing. Once the machines are bought, who can keep them running at full capacity?
Meta's statement hasn't materialized into an official business yet. According to public reports, there's an internal direction called Meta Compute, which might involve selling raw computing power, or like Amazon Bedrock, offering different models on its infrastructure to developers. Zuckerberg previously mentioned at a shareholder meeting that external companies ask almost weekly if they can purchase their API services or buy a portion of their compute, and are willing to pay a price higher than Meta's cost.
He also added a caveat back then. They hadn't done it yet because Meta believed it could still use that computing power itself.
If they need it, renting it out is an option. If they don't need it, renting it out becomes a painkiller for the balance sheet.
This is precisely where the judgment becomes hardest. Meta might simply be creating a window in its construction rhythm to sell off temporarily idle resources. Or, it might be signaling to investors that a hundred-billion-dollar scale of AI spending cannot be sustained indefinitely by a distant promise of superintelligence, and that a nearer revenue stream must be found first.
Both interpretations are plausible.
Demand Hasn't Disappeared; It's Just Becoming Selective
Capex is the core narrative for AI, without exception. Much like the liquidity flood of 2021, the expectation for Capex is continuous growth. As long as the liquidity keeps flowing, all the branches the market is speculating on will rise together. So when people heard Meta was preparing to sell computing power, the first reaction for many was: AI capex is about to collapse. The big companies have finally admitted they bought too much, and the semiconductor party is over.
That's too simplistic a conclusion.
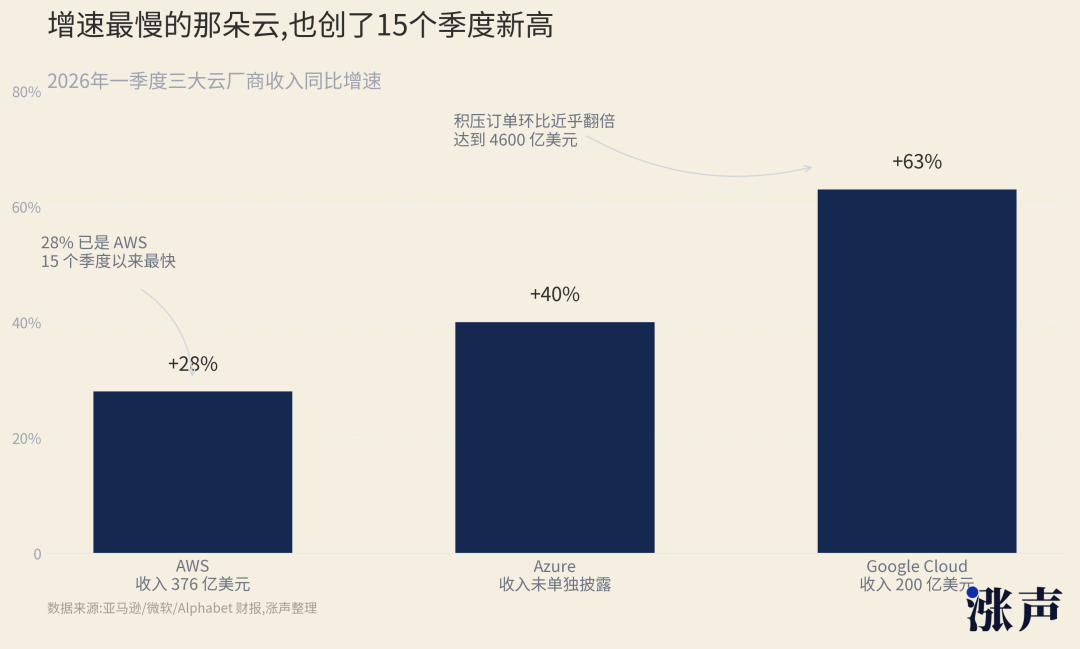
Public data doesn't yet support such a clear-cut verdict. AWS's Q1 revenue grew 28%, reaching $37.6 billion—a rare period of fast growth in recent years. Google Cloud's Q1 growth was even stronger, reaching $20 billion in revenue. Microsoft Azure is also still running at around 40% growth.
Amazon is still saying its annual capital expenditure could reach $200 billion. Alphabet raised its 2026 capital expenditure guidance to $180-$190 billion. Meta itself also raised its full-year capital expenditure to $125-$145 billion.
These numbers don't look like a collapse in demand.
They look more like a divergence.
The position of cloud providers differs from that of model companies. Cloud providers sell roads. As long as there is traffic on the road, they get paid, regardless of who built the vehicles. OpenAI, Anthropic, enterprise clients, government clients, and startups all ultimately have to land on some data center, some chip, some network, and some electricity contract.
That's why the top three clouds can remain strong.
AWS even raised prices for an AI cloud service at the end of June—its service that allows customers to reserve GPUs in advance. AWS increased the price of this service by about 20% starting in July. It had already raised it by about 15% in January. This is not an action seen in a weak demand environment.
When scarcity exists, the seller raises prices.
But model companies may not all be so comfortable.
The assets of model companies are more demanding. Computing power doesn't generate revenue just by sitting there. It needs to be continuously filled by smarter models, higher-frequency users, and more expensive enterprise workflows. Only when a model is good enough will users tolerate queues, limits, price increases, and increasingly complex subscription tiers.
This is also why Anthropic is seen by the market as a different kind of company. It's not because it's cheap, but because users are willing to entrust it with expensive tasks. Writing code, modifying systems, running long tasks, connecting to enterprise workflows—once these tasks truly enter a production environment, they consume far more tokens than casual conversation.
The trouble for strong models is not having enough machines.
The trouble for weak models is nobody cares about the machines.
Both troubles involve computing power, but they are not the same thing.
The xAI line has a similar scent. Grok hasn't formed a clear enterprise mindset like the strongest models, yet part of the computing power within Musk's ecosystem can flow to Anthropic. This move is more sobering than any slogan. Machines don't care about founders; they only care about who can keep them running at full capacity.
The relationship between Google and Meta also shows things aren't so simple. In June, news emerged that Google had restricted Meta's use of Gemini because the computing power Meta wanted to buy exceeded what Google could provide, even impacting some of Meta's internal AI projects. A company is considering selling computing power on one hand, but on the other hand, it can't buy enough top-tier model capabilities for certain tasks.
This isn't a traditional case of oversupply.
This is a mismatch. Because the bills have started to become glaring.
Cloud providers can keep raising prices because they sell certainty. What customers need is the guarantee of getting GPUs within a certain time frame, a stable data center, and an infrastructure that won't break down in the middle of the night.
But once enterprise customers get the computing power, their problems aren't over.
They still have to take that bill to the CFO. The CFO won't ask how many tokens you used. He will ask how much money those tokens saved the company, how much extra revenue they generated, and how many mistakes they prevented.
At the Enterprise Level, Tokens Become an Electricity Meter
This brings us back to Karp's interview at the beginning.
He characterized much of what many AI companies sell to enterprises as overselling. The day before the show, Palantir posted a nine-point statement on X about so-called AI sovereignty, specifically calling out the "tokenmaxxing" model. This term is hard to translate directly, but its meaning is straightforward: treating token consumption as progress, burning cash as utilization, and the bill as productivity.
Karp put frontier labs like OpenAI and Anthropic on the spot. His point wasn't that enterprises shouldn't use the best models, but that they shouldn't hand over their data, processes, and business judgment, only to be billed an increasingly large sum based on consumption.
Palantir wants to sell something different. Not a universal chat interface, not a single API, but integrating data, approval processes, permissions, operational rules, and AI into the same business system. What the client pays for isn't "how many times AI was used," but whether a specific production line, a risk control process, or a government task has genuinely been transformed.
The people who actually control the money in enterprises are starting to wake up.
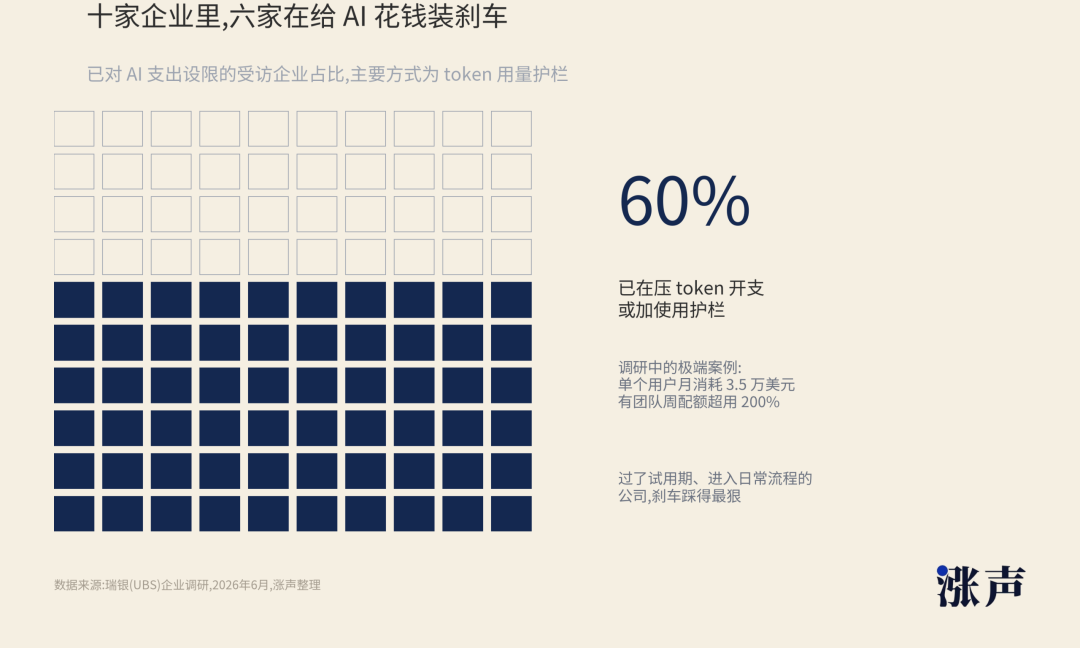
UBS recently spoke with enterprise IT executives, and one direction is very clear. Many enterprises aren't stopping AI use; they're putting brakes on AI spending. About 60% of surveyed companies are curbing token expenditure and adding usage guardrails, especially those that have moved past the trial phase and are integrating AI into daily processes.
This is also a very interesting reversal.
After AI transitions from a toy to a tool, spending becomes harder. During the toy phase, bosses were willing to allocate budgets because everyone feared missing out. During the tool phase, the CFO asks who it saved labor hours for, who it sold more goods for, and who it reduced risk for.
On this ledger, tokens don't look like revenue.
They look more like an electricity meter.
Of course, you could say a fast-spinning meter means the factory is running. But you could also say the meter is spinning too fast while output isn't rising, indicating something is wrong with the machine.
AI agents amplify this problem. A Codex study by OpenAI and several universities contains some startling data. In the first half of 2026, Codex's active users grew more than fivefold; output tokens for some internal OpenAI roles surged, with median monthly output tokens for legal roles being 13 times higher than in November 2025, and for research roles, over 50 times higher.
Another study puts it even more starkly. Agentic coding tasks can consume up to 1000 times more tokens than regular code chat and code reasoning. Token consumption for the same task can vary by 30 times between different runs.
This is the true foundation of today's computing power crunch.
It's not that people are asking chatbots a few more questions.
It's that software is beginning to resemble a group of small workers who repeatedly read files, execute commands, modify code, fail, restart, fail again, and restart again. They don't take lunch breaks, but every step consumes tokens.
When tokens become an electricity meter, whoever owns the power plant holds the power. But whoever wastes the electricity will also be the first to face scrutiny.
As the Bill Thickens, Cheaper Models Find Their Niche
Once the CFO starts looking at this electricity meter, the next step is almost instinctive.
He will ask which tasks absolutely require the strongest model and which tasks only need a model that is "good enough."
That's when open-source models like GLM, Kimi, DeepSeek, and Qwen cease to be just tech news. They become bargaining tools on the enterprise procurement table.
Even Marc Andreessen of top-tier Silicon Valley VC a16z said many AI practitioners already regard Zhipu's GLM-5.2 as one of the first Chinese models capable of matching or even surpassing leading US public models on most tasks. This judgment may not be the final verdict, but it gives enterprises leverage.
Coinbase provides a more concrete example. Brian Armstrong said the company switched its default AI model to open-source models like GLM 5.2 and Kimi 2.7. Combined with model routing, caching, and context pruning, token usage continues to grow exponentially, but the company's AI expenditure has been cut by nearly half.
The impact of this statement lies in the fact that, for the first time, enterprises can purchase model capabilities in a modular way.
The toughest tasks still go to the most expensive models. Routine tasks like summarization, customer service, information extraction, templated code, and internal knowledge base Q&A are handled by cheaper models and local deployments.
Open-source models don't necessarily have to win the entire battlefield.
They just need to convince the procurement department that not every kilowatt-hour of electricity needs to be paid at a luxury mansion's rate.
And here, Meta selling computing power is no longer an isolated piece of news.
It's telling the same story as Palantir's critique of tokens and Coinbase's shift to open-source models: the AI spending chain is starting to break apart. The upstream sells certainty, the midstream sells results, and the downstream compresses unit prices. Every layer is still growing, but every layer is also starting to be asked: is this money well spent?
The Hardest Part Isn't Buying Machines; It's Keeping Them Running
For the past two years, the easiest story to tell in the AI industry was the lack of resources.
Not enough GPUs, not enough electricity, not enough data centers, not enough engineers, not enough cloud capacity to run the models. This story was too smooth. When things are scarce, everyone instinctively charges ahead. Stake your claim first, sign the power contract first, buy the chips first, get the machines racked first.
During the resource grab, people don't tend to do the fine math.
Because the cost of being late seems much greater.
But Meta's news pushes another issue to the forefront. Once the machines are bought, they don't automatically become a good business just because they're expensive. They need work every day. They need customers willing to pay. They need models to run them at capacity. They need applications to convert the cost into revenue.
This is utilization rate.
The term "utilization rate" sounds cold, but it's actually quite brutal. It doesn't ask if you have a future; it asks if your machine worked today. It doesn't care about your press release or whether you bought the most expensive GPU. It only looks at one thing: has this money turned into a sustainable cash flow?
Cloud providers have a relatively easier time answering this question. They've always sold infrastructure. AWS, Google Cloud, and Azure sell roads, electricity, and server rooms. Whether clients need to train models, run inference, or host applications, it all ends up on some cloud.
So they can remain strong.
Strong model companies also have their own answer. If the model is powerful enough, users will queue up, enterprises will integrate it, and developers will adjust their workflows around it. In this case, computing power isn't inventory; it's a bottleneck. The more machines, the more they can scale.
The hardest position is the middle layer.
They have machines, they have stories, they have model teams, and they have large budgets. But their model isn't at the forefront, their product hasn't become a daily habit, and developers aren't willing to change their workflows for it. For this type of company, computing power can transform from a weapon into inventory with just one failed model launch or one wave of user migration.
Inventory isn't necessarily useless.
But inventory must be discounted, rented out, or find new uses.
This is what makes Meta selling computing power so glaring. It doesn't prove Meta failed, nor does it prove AI demand has vanished. It simply allows the market to see, for the first time, that AI infrastructure can encounter the same problems as an ordinary factory.
The factory has been built. Where are the orders?
Computing Power Hasn't Vanished; It's Starting to Stratify
So, the best way to understand this isn't "oversupply of computing power."
That term is too crude.
A more accurate description is that computing power is starting to stratify.
At the very top layer, it remains tight. The strongest models, the best clouds, the most stable GPU clusters are still being fought over. AWS's services can raise prices because certainty itself has a price. Clients aren't just buying GPUs; they're buying the guarantee that a specific set of machines will be available on a specific day, at a specific hour.
The middle layer is starting to feel awkward. It might not be bad, but it isn't scarce enough. It can run models, do inference, and be sold to external clients. But clients will compare prices, negotiate, and ask why they shouldn't use a cheaper model, or someone else's cloud, or why this set of machines is worth that specific price.
The bottom layer will be gradually squeezed by open-source models and cost optimization. Enterprises won't always call upon the most expensive model for routine tasks. They will implement routing, caching, context compression, and tier models into different grades.
Demand has grown up.
Children spend money without looking at the bill; adults do. As AI enters the enterprise, it will go through this process too. During the pilot phase, everyone fears missing out; during the scaling phase, everyone starts doing the math.
Once the math is done, the industry chain will no longer be as uniform as it was in the early days.
Some will continue to raise prices because they sell irreplaceable certainty. Some will switch to selling results because clients don't want to pay for consumption itself. Some will be forced to lower prices because adequate substitutes have appeared. Some will rent out their machines because having idle machines looks worse on the books than renting them out cheaply.
When these things happen simultaneously, the industry will appear contradictory.
<

