
การวิเคราะห์เชิงลึกของการใช้เหตุผล AI แบบกระจายอำนาจ: วิธีการสร้างสมดุลระหว่างความปลอดภัยและประสิทธิภาพ
- 核心观点:去中心化AI推理可打破算力垄断。
- 关键要素:
- 利用闲置GPU算力降低AI成本。
- 区块链记录确保推理可验证。
- 声誉机制平衡安全与性能。
- 市场影响:挑战中心化云服务商定价权。
- 时效性标注:中期影响。
ผู้เขียนต้นฉบับ: Anastasia Matveeva - ผู้ร่วมก่อตั้ง Gonka Protocol
สารบัญ
- “การกระจายอำนาจ” ที่แท้จริง
- บล็อคเชนและการพิสูจน์การใช้เหตุผล
- มันทำงานจริงอย่างไร
- การแลกเปลี่ยนความปลอดภัยและประสิทธิภาพ
- เพิ่มประสิทธิภาพพื้นที่
ตอนที่เราเริ่มสร้าง Gonka เรามีวิสัยทัศน์ว่า จะเป็นอย่างไรหากใครก็ตามสามารถรัน AI inference และได้รับค่าตอบแทน? จะเป็นอย่างไรหากเราสามารถใช้ประโยชน์จากพลังการประมวลผลที่ไม่ได้ใช้ทั้งหมด แทนที่จะพึ่งพาผู้ให้บริการแบบรวมศูนย์ราคาแพง?
ภูมิทัศน์ AI ในปัจจุบันถูกครอบงำโดยผู้ให้บริการคลาวด์รายใหญ่เพียงไม่กี่ราย ได้แก่ AWS, Azure และ Google Cloud ซึ่งควบคุมโครงสร้างพื้นฐาน AI ส่วนใหญ่ของโลก การรวมศูนย์นี้ก่อให้เกิดปัญหาร้ายแรงที่พวกเราหลายคนเคยประสบมาโดยตรง การควบคุมโครงสร้างพื้นฐาน AI โดยบริษัทเพียงไม่กี่รายหมายความว่าพวกเขาสามารถกำหนดราคาตามอำเภอใจ เซ็นเซอร์แอปพลิเคชันที่ไม่พึงประสงค์ และสร้างจุดล้มเหลวเพียงจุดเดียวได้ เมื่อ API ของ OpenAI ล่ม แอปพลิเคชันนับพันก็หยุดทำงานไปด้วย เมื่อ AWS ประสบปัญหาขัดข้อง อินเทอร์เน็ตครึ่งหนึ่งก็หยุดทำงาน
แม้แต่เทคโนโลยีล้ำสมัยที่ "มีประสิทธิภาพ" ก็ยังไม่ถูก Anthropic เคยกล่าวไว้ก่อนหน้านี้ว่าการฝึกอบรม Claude 3.5 Sonnet มีค่าใช้จ่าย "หลายสิบล้านดอลลาร์" และแม้ว่า Claude Sonnet 4 จะพร้อมใช้งานทั่วไปแล้ว แต่ Anthropic ยังไม่ได้เปิดเผยค่าใช้จ่ายในการฝึกอบรม ก่อนหน้านี้ Dario Amodei ซีอีโอของบริษัทคาดการณ์ไว้ว่าค่าใช้จ่ายในการฝึกอบรมสำหรับแบบจำลองล้ำสมัยจะสูงถึง 1 พันล้านดอลลาร์ และแบบจำลองชุดต่อไปจะมีมูลค่าหลายพันล้านดอลลาร์ การรันอนุมานบนแบบจำลองเหล่านี้มีค่าใช้จ่ายไม่ต่างกัน สำหรับแอปพลิเคชันที่ใช้งานในระดับปานกลาง การรันอนุมาน LLM เพียงครั้งเดียวอาจมีค่าใช้จ่ายหลายร้อยถึงหลายพันดอลลาร์ต่อวัน
ในขณะเดียวกัน โลกก็มีพลังประมวลผลมหาศาลที่ยังไม่ได้ใช้งาน (หรือถูกนำไปใช้อย่างไร้ความหมาย) ลองนึกภาพนักขุด Bitcoin ที่ใช้ไฟฟ้าเพื่อแก้ปริศนาแฮชที่ไร้ค่า หรือศูนย์ข้อมูลที่ทำงานต่ำกว่าขีดความสามารถ แล้วถ้าพลังประมวลผลนี้สามารถนำมาใช้กับสิ่งที่มีคุณค่าอย่างแท้จริง เช่น การอนุมานด้วย AI จะเป็นอย่างไร
แนวทางแบบกระจายศูนย์สามารถรวมพลังการประมวลผล ลดอุปสรรคด้านเงินทุน และลดปัญหาคอขวดจากซัพพลายเออร์รายเดียว แทนที่จะพึ่งพาบริษัทขนาดใหญ่เพียงไม่กี่แห่ง เราสามารถสร้างเครือข่ายที่ใครก็ตามที่มี GPU สามารถเข้าร่วมและรับค่าตอบแทนจากการรัน AI inference ได้
เราทราบดีว่าการสร้างโซลูชันแบบกระจายศูนย์ที่ใช้งานได้จริงนั้นมีความซับซ้อนอย่างยิ่ง ตั้งแต่กลไกฉันทามติ โปรโตคอลการฝึกอบรม ไปจนถึงการจัดสรรทรัพยากร มีองค์ประกอบมากมายนับไม่ถ้วนที่ต้องประสานงานกัน วันนี้ ผมขอเน้นเพียงประเด็นเดียว นั่นคือ การรันอนุมานในหลักสูตร LLM เฉพาะทาง มันยากขนาดไหนกันเชียว?
การกระจายอำนาจที่แท้จริงคืออะไร?
เมื่อเราพูดถึงการอนุมาน AI แบบกระจายศูนย์ เราหมายถึงสิ่งที่เฉพาะเจาะจงมาก ไม่ใช่แค่การมีโมเดล AI ทำงานบนเซิร์ฟเวอร์หลายตัวเท่านั้น แต่หมายถึงการสร้างระบบที่ทุกคนสามารถเข้าร่วม มีส่วนร่วมกับพลังการประมวลผล และได้รับรางวัลจากการทำงานที่ซื่อสัตย์สุจริต
ข้อกำหนดสำคัญคือระบบต้องไม่ น่าเชื่อถือ ซึ่งหมายความว่าคุณไม่จำเป็นต้องไว้วางใจบุคคลหรือบริษัทใดบริษัทหนึ่งให้รันระบบได้อย่างถูกต้อง หากคุณปล่อยให้คนแปลกหน้าบนอินเทอร์เน็ตรันโมเดล AI ของคุณ คุณต้องมีการรับประกันทางการเข้ารหัสว่าพวกเขากำลังทำสิ่งที่พวกเขาอ้างว่าทำอยู่จริง (อย่างน้อยก็มีความน่าจะเป็นสูงเพียงพอ)
ข้อกำหนดแบบไม่ต้องไว้วางใจนี้มีความหมายที่น่าสนใจหลายประการ ประการแรก หมายความว่าระบบจะต้อง สามารถตรวจสอบได้ นั่นคือ คุณต้องสามารถพิสูจน์ได้ว่ามีการใช้แบบจำลองและพารามิเตอร์เดียวกันเพื่อสร้างผลลัพธ์ที่กำหนด ซึ่งเป็นสิ่งสำคัญอย่างยิ่งสำหรับสัญญาอัจฉริยะที่ต้องตรวจสอบว่าการตอบสนองของ AI ที่ได้รับนั้นถูกต้องตามกฎหมาย
แต่มีความท้าทายอยู่อย่างหนึ่ง คือ ยิ่งเพิ่มการตรวจสอบมากเท่าไหร่ ระบบทั้งหมดก็จะยิ่งช้าลงเท่านั้น เนื่องจากการตรวจสอบใช้พลังงานของเครือข่าย หากคุณไว้วางใจทุกคนอย่างเต็มที่ ก็ไม่จำเป็นต้องใช้เหตุผลในการยืนยัน และประสิทธิภาพการทำงานก็แทบจะเทียบเท่ากับผู้ให้บริการแบบรวมศูนย์ แต่ถ้าคุณไม่ไว้วางใจใครเลยและต้องตรวจสอบทุกอย่างตลอดเวลา ระบบก็จะทำงานช้าอย่างมากและไม่สามารถแข่งขันกับโซลูชันแบบรวมศูนย์ได้
นี่คือข้อขัดแย้งหลักที่เรากำลังพยายามแก้ไข: การค้นหาสมดุลที่เหมาะสมระหว่าง ความปลอดภัยและประสิทธิภาพการทำงาน
บล็อคเชนและการพิสูจน์การใช้เหตุผล
แล้วเราจะตรวจสอบได้อย่างไรว่ามีคนรันโมเดลและพารามิเตอร์ที่ถูกต้อง? บล็อกเชนจึงกลายเป็นตัวเลือกที่ชัดเจน แม้จะมีความท้าทายในตัว แต่ก็ยังคงเป็นวิธีที่น่าเชื่อถือที่สุดที่เรารู้จักในการสร้างบันทึกเหตุการณ์ที่ไม่เปลี่ยนแปลง
แนวคิดพื้นฐานค่อนข้างตรงไปตรงมา เมื่อมีคนใช้การอนุมาน พวกเขาจำเป็นต้องแสดงหลักฐานว่าตนใช้แบบจำลองที่ถูกต้อง หลักฐานนี้จะถูกบันทึกไว้ในบล็อกเชน เพื่อสร้างบันทึกถาวรที่ป้องกันการปลอมแปลง ซึ่งทุกคนสามารถตรวจสอบได้
ปัญหาคือบล็อกเชนนั้นช้ามาก ช้ามากจริงๆ ถ้าเราพยายามบันทึกทุกขั้นตอนการใช้เหตุผลไว้บนบล็อกเชน ปริมาณข้อมูลมหาศาลจะล้นเครือข่ายอย่างรวดเร็ว ข้อจำกัดนี้เองที่ผลักดันการตัดสินใจหลายอย่างของเราในการออกแบบเครือข่าย Gonka
เมื่อออกแบบเครือข่ายและพิจารณาการประมวลผลแบบกระจาย มีหลายกลยุทธ์ให้เลือกใช้ คุณสามารถแบ่งแบบจำลองออกเป็นหลายโหนด หรือเก็บแบบจำลองทั้งหมดไว้ในโหนดเดียวได้หรือไม่ ข้อจำกัดหลักมาจากแบนด์วิดท์เครือข่ายและความเร็วของบล็อกเชน เพื่อให้โซลูชันของเราเป็นไปได้ เราจึงเลือกที่จะติดตั้งแบบจำลองเต็มรูปแบบบนโหนดเดียว แม้ว่าสิ่งนี้อาจเปลี่ยนแปลงได้ในอนาคต การทำเช่นนี้กำหนดข้อกำหนดขั้นต่ำสำหรับการเข้าร่วมเครือข่าย เนื่องจากแต่ละโหนดต้องการพลังการประมวลผลและหน่วยความจำที่เพียงพอสำหรับการทำงานของแบบจำลองทั้งหมด อย่างไรก็ตาม แบบจำลองยังคงสามารถแบ่งออกได้ระหว่าง GPU หลายตัวที่อยู่ในโหนดเดียวกัน ทำให้เรามีความยืดหยุ่นภายใต้ข้อจำกัดของโหนดเดียว เราใช้ vLLM ซึ่งช่วยให้สามารถปรับแต่งพารามิเตอร์การทำงานแบบขนานของเทนเซอร์และไปป์ไลน์เพื่อประสิทธิภาพสูงสุด
มันทำงานจริงอย่างไร
ดังนั้น เราจึงตกลงกันว่าแต่ละโหนดจะโฮสต์แบบจำลองที่สมบูรณ์และดำเนินการอนุมานอย่างเต็มรูปแบบ จึงไม่จำเป็นต้องประสานงานระหว่างหลายเครื่องระหว่างการคำนวณจริง บล็อกเชนนี้ใช้เพื่อการเก็บบันทึกข้อมูลเท่านั้น เราบันทึกเฉพาะธุรกรรมและสิ่งประดิษฐ์ที่ใช้สำหรับการตรวจสอบการอนุมานเท่านั้น การคำนวณจริงจะเกิดขึ้นนอกเครือข่าย
เราต้องการให้ระบบกระจายศูนย์ โดยไม่มีจุดศูนย์กลางเพียงจุดเดียวที่ส่งคำขออนุมานไปยังโหนดเครือข่าย ในทางปฏิบัติ ผู้เข้าร่วมแต่ละคนจะปรับใช้โหนดอย่างน้อยสองโหนด ได้แก่ โหนดเครือข่ายและโหนดเหตุผล (ML) หนึ่งโหนดหรือมากกว่า โหนดเครือข่ายมีหน้าที่รับผิดชอบการสื่อสาร (รวมถึงโหนดเชนที่เชื่อมต่อกับบล็อกเชนและโหนด API ที่จัดการคำขอของผู้ใช้) ขณะที่โหนด ML ของคุณดำเนินการอนุมาน LLM
เมื่อคำขออนุมานมาถึงเครือข่าย คำขอนั้นจะไปถึงโหนด API หนึ่งโหนด (ซึ่งทำหน้าที่เป็น "ตัวแทนถ่ายโอน") ซึ่งจะสุ่มเลือก "ผู้ดำเนินการ" (โหนด ML จากผู้เข้าร่วมรายอื่น) เพื่อประหยัดเวลาและประมวลผลข้อมูลบล็อกเชนแบบขนานกับการคำนวณ LLM จริง ตัวแทนถ่ายโอน (TA) จะส่งคำขออินพุตไปยังผู้ดำเนินการก่อน และบันทึกอินพุตบนเชนในขณะที่โหนด ML ของผู้ดำเนินการกำลังดำเนินการอนุมาน เมื่อการคำนวณเสร็จสิ้น ผู้ดำเนินการจะส่งเอาต์พุตไปยังโหนด API ของ TA ในขณะที่โหนดเชนของตัวเองจะบันทึกอาร์ทิแฟกต์การตรวจสอบบนเชน โหนด API ของ TA จะส่งเอาต์พุตกลับไปยังไคลเอ็นต์ ซึ่งจะถูกบันทึกบนเชนเช่นกัน แน่นอนว่าบันทึกเหล่านี้ยังคงส่งผลต่อข้อจำกัดแบนด์วิดท์ของเครือข่ายโดยรวม
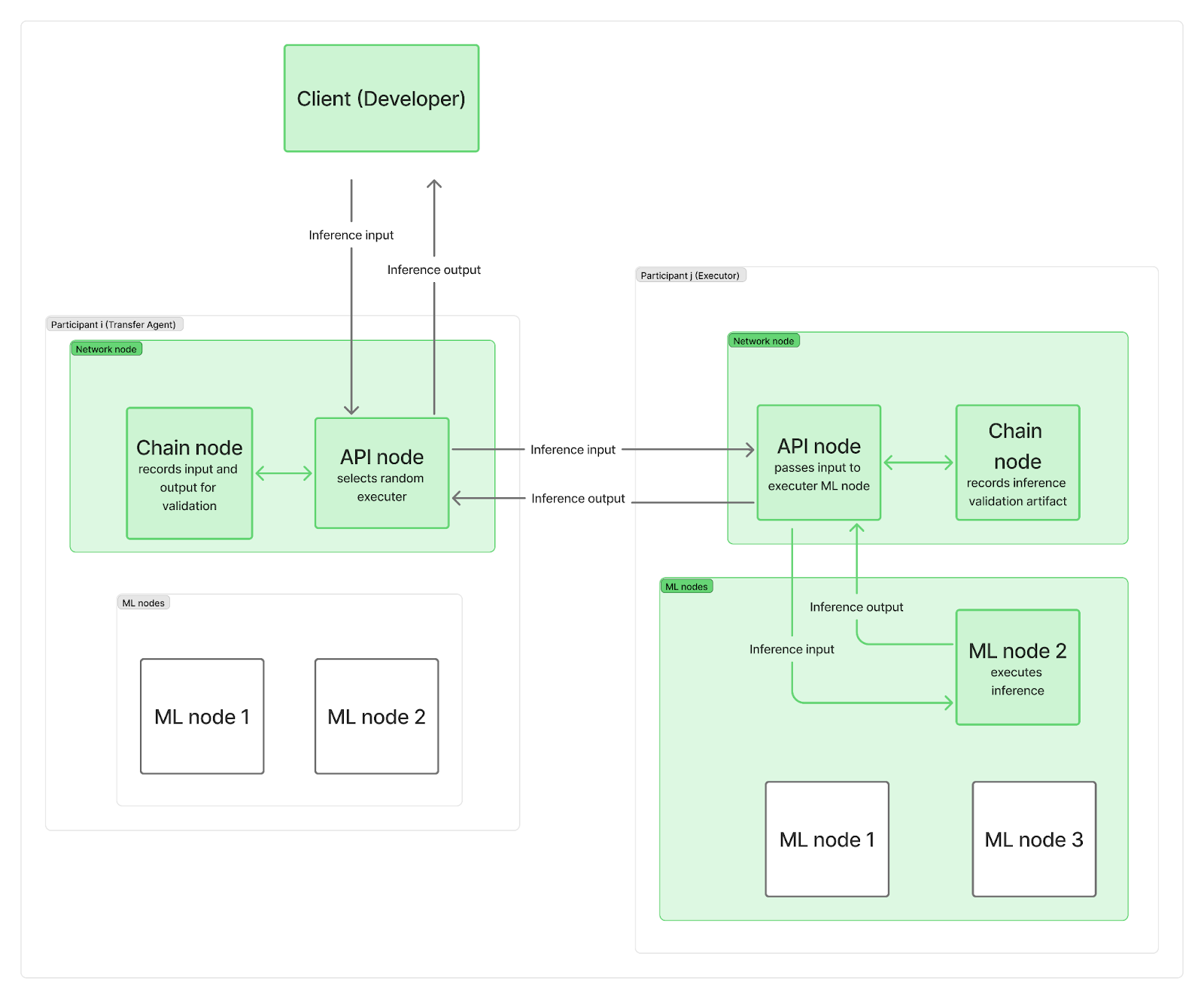
อย่างที่คุณเห็น การบันทึกข้อมูลบนบล็อกเชนไม่ได้ทำให้การเริ่มต้นการคำนวณอนุมานช้าลง หรือลดเวลาที่ใช้ในการส่งผลลัพธ์สุดท้ายกลับไปยังไคลเอนต์ การตรวจสอบความถูกต้องว่าการอนุมานเสร็จสมบูรณ์หรือไม่นั้นจะเกิดขึ้นในภายหลังควบคู่ไปกับการอนุมานอื่นๆ หากผู้ดำเนินการถูกจับได้ว่าโกง พวกเขาจะสูญเสียรางวัลตลอดยุค และไคลเอนต์จะได้รับการแจ้งเตือนและได้รับเงินคืน
คำถามสุดท้ายคือ: สิ่งประดิษฐ์ประกอบด้วยอะไรบ้าง และเราตรวจสอบเหตุผลของเราบ่อยเพียงใด
การแลกเปลี่ยนความปลอดภัยและประสิทธิภาพ
ความท้าทายพื้นฐานคือความปลอดภัยและประสิทธิภาพการทำงานมีความขัดแย้งกัน
หากคุณต้องการความปลอดภัยสูงสุด คุณจำเป็นต้องตรวจสอบทุกอย่าง แต่นั่นก็ช้าและมีค่าใช้จ่ายสูง หากคุณต้องการประสิทธิภาพสูงสุด คุณจำเป็นต้องไว้วางใจทุกคน แต่นั่นมีความเสี่ยงและเปิดช่องให้คุณถูกโจมตีได้หลายรูปแบบ
หลังจากลองผิดลองถูกและปรับแต่งพารามิเตอร์หลายครั้ง เราพบแนวทางที่พยายามสร้างสมดุลระหว่างสองประเด็นนี้ เราต้องปรับปริมาณการตรวจสอบ ระยะเวลาในการตรวจสอบ และวิธีที่จะทำให้กระบวนการตรวจสอบมีประสิทธิภาพมากที่สุดเท่าที่จะเป็นไปได้อย่างรอบคอบ หากตรวจสอบมากเกินไป ระบบก็จะใช้งานไม่ได้ หากตรวจสอบน้อยเกินไป ระบบก็จะไม่มีความปลอดภัย
การรักษาระบบให้มีขนาดเล็กเป็นสิ่งสำคัญอย่างยิ่ง เรารักษาระบบนี้ไว้โดยการจัดเก็บค่าความน่าจะเป็นของโทเค็น ถัดไป k อันดับแรก เราใช้ค่าเหล่านี้เพื่อวัดความน่าจะเป็นที่เอาต์พุตที่กำหนดนั้นถูกสร้างขึ้นโดยแบบจำลองและพารามิเตอร์ที่อ้างสิทธิ์ และเพื่อตรวจจับความพยายามในการดัดแปลงใดๆ เช่น การใช้แบบจำลองขนาดเล็กลงหรือแบบจำลองเชิงปริมาณ ด้วยความมั่นใจที่เพียงพอ เราจะอธิบายการใช้งานขั้นตอนการตรวจสอบการอนุมานโดยละเอียดเพิ่มเติมในโพสต์อื่น
ในขณะเดียวกัน เราจะตัดสินใจได้อย่างไรว่าควรตรวจสอบอนุมานใดและไม่ตรวจสอบอนุมานใด เราเลือกใช้วิธีการแบบอิงชื่อเสียง เมื่อมีผู้เข้าร่วมใหม่เข้าร่วมเครือข่าย ชื่อเสียงของพวกเขาจะเป็น 0 และ อนุมานทั้งหมด 100% จะต้องได้รับการยืนยันโดยผู้เข้าร่วมอย่างน้อยหนึ่งคน หากพบปัญหา กลไกฉันทามติจะกำหนดในที่สุดว่าอนุมานของคุณได้รับการอนุมัติ หรือชื่อเสียงของคุณจะลดลง และคุณอาจถูกเตะออกจากเครือข่าย เมื่อชื่อเสียงของคุณเพิ่มขึ้น จำนวนอนุมานที่ต้องตรวจสอบจะลดลง และในที่สุดอนุมาน 1% อาจถูกเลือกแบบสุ่มสำหรับการตรวจสอบ วิธีการแบบไดนามิกนี้ช่วยให้เรารักษาเปอร์เซ็นต์การตรวจสอบโดยรวมให้อยู่ในระดับต่ำ ในขณะเดียวกันก็จับผู้เข้าร่วมที่พยายามโกงได้อย่างมีประสิทธิภาพ
เมื่อสิ้นสุดแต่ละยุค ผู้เข้าร่วมจะได้รับรางวัลตามสัดส่วนน้ำหนักในเครือข่าย งานต่างๆ ก็มีการถ่วงน้ำหนักเช่นกัน ดังนั้นรางวัลจึงควรเป็นสัดส่วนกับทั้งน้ำหนักและปริมาณงานที่เสร็จสมบูรณ์ ซึ่งหมายความว่าเราไม่จำเป็นต้องจับและลงโทษผู้โกงทันที เพียงแค่จับพวกเขาให้ได้ภายในยุคก่อนที่จะแจกรางวัลก็เพียงพอแล้ว
แรงจูงใจทางเศรษฐกิจเป็นตัวขับเคลื่อนการแลกเปลี่ยนนี้มากพอๆ กับพารามิเตอร์ทางเทคนิค การทำให้การโกงมีค่าใช้จ่ายสูงและการมีส่วนร่วมอย่างซื่อสัตย์ทำกำไรได้ ช่วยให้เราสามารถสร้างระบบที่การเลือกที่สมเหตุสมผลคือการมีส่วนร่วมอย่างซื่อสัตย์
เพิ่มประสิทธิภาพพื้นที่
หลังจากสร้างและทดสอบมาหลายเดือน เราได้สร้างระบบที่ผสานรวมข้อดีด้านการบันทึกข้อมูลและความปลอดภัยของบล็อกเชนเข้าด้วยกัน พร้อมกับประสิทธิภาพการอนุมานแบบ Single-Shot ของผู้ให้บริการแบบรวมศูนย์ ความตึงเครียดพื้นฐานระหว่างความปลอดภัยและประสิทธิภาพนั้นมีอยู่จริง และไม่มีวิธีแก้ปัญหาที่สมบูรณ์แบบ มีเพียงการแลกเปลี่ยนที่แตกต่างกัน
เราเชื่อว่าเมื่อเครือข่ายขยายตัวขึ้น จะมีโอกาสอย่างแท้จริงในการแข่งขันกับผู้ให้บริการแบบรวมศูนย์ ในขณะที่ยังคงรักษาการควบคุมชุมชนแบบกระจายศูนย์ไว้ได้อย่างสมบูรณ์ นอกจากนี้ยังมีช่องว่างอีกมากสำหรับการเพิ่มประสิทธิภาพในขณะที่เครือข่ายกำลังพัฒนา หากคุณสนใจที่จะเรียนรู้เกี่ยวกับกระบวนการนี้ โปรดไปที่ GitHub และเอกสารประกอบของเรา เข้าร่วมการสนทนาบน Discord และเข้าร่วมเครือข่ายด้วยตัวคุณเอง
เกี่ยวกับ Gonka.ai
Gonka คือเครือข่ายแบบกระจายศูนย์ที่ออกแบบมาเพื่อมอบพลังการประมวลผล AI ที่มีประสิทธิภาพ เป้าหมายการออกแบบคือการเพิ่มประสิทธิภาพการใช้พลังการประมวลผล GPU ทั่วโลกให้สูงสุดเพื่อจัดการเวิร์กโหลด AI ที่สำคัญ ด้วยการขจัดระบบเกตเวย์แบบรวมศูนย์ Gonka จึงช่วยให้นักพัฒนาและนักวิจัยเข้าถึงทรัพยากรการประมวลผลได้โดยไม่ต้องขออนุญาต ขณะเดียวกันก็มอบโทเค็น GNK ดั้งเดิมให้กับผู้เข้าร่วมทุกคน
Gonka ได้รับการบ่มเพาะโดย Product Science Inc. ผู้พัฒนา AI สัญชาติอเมริกัน ก่อตั้งโดยพี่น้องตระกูล Liberman ผู้คร่ำหวอดในวงการ Web 2 และอดีตผู้อำนวยการฝ่ายผลิตภัณฑ์หลักของ Snap Inc. บริษัทประสบความสำเร็จในการระดมทุน 18 ล้านดอลลาร์ในปี 2023 จากนักลงทุน ได้แก่ Coatue Management ซึ่งเป็นนักลงทุนใน OpenAI, Slow Ventures ซึ่งเป็นนักลงทุนใน Solana, K5, Insight และ Benchmark Partners ผู้ร่วมก่อตั้งโครงการในช่วงแรก ๆ ได้แก่ ผู้นำที่มีชื่อเสียงในวงการ Web 2-Web 3 เช่น 6 Blocks, Hard Yaka, Gcore และ Bitfury
เว็บไซต์อย่างเป็นทางการ | Github | X | Discord | เอกสารเผยแพร่ | แบบจำลองเศรษฐกิจ | คู่มือผู้ใช้


