ยุคแห่งพลังการประมวลผลแบบรวมศูนย์สิ้นสุดลงแล้ว: การฝึกอบรม AI กำลังย้ายจาก "ห้องคอมพิวเตอร์" ไปสู่ "เครือข่าย"
- 核心观点:低通信算法实现分布式AI训练。
- 关键要素:
- DiLoCo算法减少通信量500倍。
- 联邦优化解耦本地与全局计算。
- 成功预训练数十亿参数模型。
- 市场影响:降低AI训练门槛,促进行业民主化。
- 时效性标注:长期影响
โพสต์ดั้งเดิมโดย Egor Shulgin, Gonka Protocol
การพัฒนาอย่างรวดเร็วของเทคโนโลยี AI ได้ผลักดันกระบวนการฝึกอบรมให้ก้าวข้ามขีดจำกัดของสถานที่ทางกายภาพแห่งใดแห่งหนึ่ง บังคับให้นักวิจัยต้องเผชิญกับความท้าทายพื้นฐาน นั่นคือ จะประสานงานหน่วยประมวลผลหลายพันตัวที่กระจายอยู่ทั่วทุกทวีป (แทนที่จะอยู่ภายในโถงทางเดินเดียวกันของห้องคอมพิวเตอร์) ได้อย่างไร คำตอบอยู่ที่อัลกอริทึมที่มีประสิทธิภาพมากขึ้น ซึ่งทำงานโดยการลดการสื่อสาร การเปลี่ยนแปลงนี้ ซึ่งขับเคลื่อนโดยความก้าวหน้าในการปรับแต่งประสิทธิภาพแบบรวมศูนย์ และจุดสุดยอดในกรอบการทำงานอย่าง DiLoCo ช่วยให้องค์กรต่างๆ สามารถฝึกอบรมโมเดลที่มีพารามิเตอร์นับพันล้านตัวผ่านการเชื่อมต่ออินเทอร์เน็ตมาตรฐาน ซึ่งเปิดโอกาสใหม่ๆ สำหรับการพัฒนา AI ร่วมกันในวงกว้าง
1. จุดเริ่มต้น: การฝึกอบรมแบบกระจายในศูนย์ข้อมูล
การฝึกอบรม AI สมัยใหม่มีการกระจายตัวโดยเนื้อแท้ เป็นที่สังเกตกันอย่างกว้างขวางว่าการเพิ่มขนาดของข้อมูล พารามิเตอร์ และการคำนวณช่วยปรับปรุงประสิทธิภาพของแบบจำลองอย่างมีนัยสำคัญ ทำให้ไม่สามารถฝึกอบรมแบบจำลองพื้นฐาน (ที่มีพารามิเตอร์หลายพันล้านรายการ) บนเครื่องเดียวได้ โซลูชันเริ่มต้นของอุตสาหกรรมคือแบบจำลอง "แบบกระจายศูนย์": การสร้างศูนย์ข้อมูลเฉพาะที่มี GPU หลายพันตัวอยู่ในสถานที่เดียว เชื่อมต่อกันด้วยเครือข่ายความเร็วสูงพิเศษ เช่น NVLink ของ NVIDIA หรือ InfiniBand เทคโนโลยีการเชื่อมต่อเฉพาะทางเหล่านี้มีความเร็วมากกว่าเครือข่ายมาตรฐานหลายเท่า ทำให้ GPU ทั้งหมดทำงานเป็นระบบที่เชื่อมโยงกันอย่างเหนียวแน่น
ในสภาพแวดล้อมนี้ กลยุทธ์การฝึกที่ใช้กันมากที่สุดคือการประมวลผลข้อมูลแบบขนาน ซึ่งเกี่ยวข้องกับการแบ่งชุดข้อมูลออกเป็น GPU หลายตัว (มีวิธีการอื่นๆ เช่น การประมวลผลข้อมูลแบบขนานไปป์ไลน์ หรือการประมวลผลข้อมูลแบบขนานเทนเซอร์ ซึ่งแบ่งแบบจำลองออกเป็น GPU หลายตัว วิธีนี้จำเป็นสำหรับการฝึกฝนแบบจำลองขนาดใหญ่ที่สุด แม้ว่าจะซับซ้อนกว่าในการใช้งาน) ต่อไปนี้คือวิธีการทำงานของขั้นตอนการฝึกโดยใช้การไล่ระดับความชันแบบสุ่มแบบมินิแบตช์ (SGD) (หลักการเดียวกันนี้ใช้กับตัวเพิ่มประสิทธิภาพ Adam):
- ทำซ้ำและแจกจ่าย: โหลดสำเนาของแบบจำลองลงใน GPU แต่ละตัว แบ่งข้อมูลการฝึกอบรมออกเป็นชุดย่อยๆ
- การประมวลผลแบบคู่ขนาน: GPU แต่ละตัวจะประมวลผลมินิแบตช์ที่แตกต่างกันอย่างอิสระ และคำนวณการไล่ระดับ ซึ่งเป็นทิศทางที่พารามิเตอร์ของโมเดลได้รับการปรับ
- ซิงโครไนซ์และรวม: GPU ทั้งหมดหยุดการทำงาน แบ่งปันการไล่ระดับ และหาค่าเฉลี่ยเพื่อสร้างการอัปเดตแบบรวมครั้งเดียว
- อัปเดต: ใช้การอัปเดตเฉลี่ยนี้กับสำเนาโมเดลของ GPU แต่ละตัว เพื่อให้แน่ใจว่าสำเนาทั้งหมดยังคงเหมือนกัน
- ทำซ้ำ: ย้ายไปยังชุดเล็กถัดไปและเริ่มต้นใหม่อีกครั้ง
โดยพื้นฐานแล้ว นี่คือวงจรการประมวลผลแบบขนานและการซิงโครไนซ์แบบบังคับที่ต่อเนื่อง การสื่อสารอย่างต่อเนื่องที่เกิดขึ้นหลังจากแต่ละขั้นตอนการฝึกอบรมจะเป็นไปได้เฉพาะกับการเชื่อมต่อความเร็วสูงที่มีราคาแพงภายในศูนย์ข้อมูลเท่านั้น การพึ่งพาการซิงโครไนซ์บ่อยครั้งนี้เป็นเอกลักษณ์เฉพาะของการฝึกอบรมแบบกระจายศูนย์ ระบบนี้ทำงานได้อย่างราบรื่นจนกระทั่งออกจาก "เรือนกระจก" ของศูนย์ข้อมูล
2. การชนกำแพง: คอขวดการสื่อสารขนาดใหญ่
เพื่อฝึกอบรมโมเดลขนาดใหญ่ที่สุด องค์กรต่างๆ จำเป็นต้องสร้างโครงสร้างพื้นฐานขนาดใหญ่อย่างน่าตกใจ ซึ่งมักต้องใช้ศูนย์ข้อมูลหลายแห่งในเมืองหรือทวีปต่างๆ การแบ่งแยกทางภูมิศาสตร์เช่นนี้สร้างอุปสรรคสำคัญ วิธีการเชิงอัลกอริทึมแบบทีละขั้นตอนและซิงโครไนซ์กัน ซึ่งทำงานได้ดีภายในศูนย์ข้อมูลนั้นอาจล้มเหลวเมื่อขยายไปสู่ระดับโลก
ปัญหาอยู่ที่ความเร็วของเครือข่าย ภายในศูนย์ข้อมูล InfiniBand สามารถส่งข้อมูลด้วยความเร็ว 400 Gb/s หรือมากกว่า ในทางกลับกัน เครือข่ายบริเวณกว้าง (WAN) ที่เชื่อมต่อศูนย์ข้อมูลที่อยู่ห่างไกลมักจะทำงานด้วยความเร็วเกือบ 1 Gbps ช่องว่างด้านประสิทธิภาพนี้ซึ่งมีขนาดใหญ่มาก เกิดจากข้อจำกัดพื้นฐานด้านระยะทางและต้นทุน การสื่อสารแบบทันทีทันใดที่ SGD ขนาดเล็กคาดการณ์ไว้นั้นขัดแย้งกับความเป็นจริงนี้
ความแตกต่างนี้ก่อให้เกิดปัญหาคอขวดที่รุนแรง เมื่อจำเป็นต้องซิงโครไนซ์พารามิเตอร์ของแบบจำลองหลังจากแต่ละขั้นตอน GPU ที่ทรงพลังมักจะไม่ได้ทำงานตลอดเวลา รอให้ข้อมูลค่อยๆ เคลื่อนผ่านเครือข่ายที่ช้า ผลที่ตามมาคือ ชุมชน AI ไม่สามารถใช้ประโยชน์จากทรัพยากรการประมวลผลจำนวนมหาศาลที่กระจายอยู่ทั่วโลก ตั้งแต่เซิร์ฟเวอร์ขององค์กรไปจนถึงฮาร์ดแวร์ของผู้บริโภค เนื่องจากอัลกอริทึมที่มีอยู่ต้องการเครือข่ายความเร็วสูงแบบรวมศูนย์ นี่จึงเป็นเสมือนแหล่งพลังการประมวลผลมหาศาลที่ยังไม่ถูกใช้ประโยชน์
3. การแปลงอัลกอริทึม: การเพิ่มประสิทธิภาพแบบรวม
หากการสื่อสารบ่อยครั้งเป็นปัญหา ทางออกก็คือการสื่อสารให้น้อยลง ข้อมูลเชิงลึกง่ายๆ นี้ได้วางรากฐานสำหรับการเปลี่ยนแปลงอัลกอริทึมที่อาศัยเทคนิคจากการเรียนรู้แบบรวมศูนย์ ซึ่งเดิมทีมุ่งเน้นไปที่โมเดลการฝึกอบรมข้อมูลแบบกระจายศูนย์บนอุปกรณ์ปลายทาง (เช่น โทรศัพท์มือถือ) ขณะเดียวกันก็รักษาความเป็นส่วนตัวไว้ อัลกอริทึมหลักที่ เรียกว่า Federated Averaging (FedAvg) แสดงให้เห็นว่าการอนุญาตให้อุปกรณ์แต่ละเครื่องดำเนินการฝึกอบรมหลายขั้นตอนภายในเครื่องก่อนที่จะส่งการอัปเดต จะช่วยลดจำนวนรอบการสื่อสารที่จำเป็นลงได้อย่างมาก
นักวิจัยตระหนักว่าหลักการของการทำงานที่เป็นอิสระมากขึ้นระหว่างช่วงเวลาการซิงโครไนซ์เป็นวิธีแก้ปัญหาที่สมบูรณ์แบบสำหรับการแก้ไขปัญหาคอขวดด้านประสิทธิภาพในสภาพแวดล้อมที่กระจายตัวทางภูมิศาสตร์ สิ่งนี้นำไปสู่การเกิดขึ้นของเฟรมเวิร์ก Federated Optimization (FedOpt) ซึ่งใช้วิธีการเพิ่มประสิทธิภาพแบบคู่เพื่อแยกการประมวลผลแบบโลคัลออกจากการสื่อสารแบบโกลบอล
กรอบงานนี้ทำงานโดยใช้ตัวเพิ่มประสิทธิภาพสองตัวที่แตกต่างกัน:
- ตัวเพิ่มประสิทธิภาพภายใน (เช่น SGD มาตรฐาน) ทำงานบนเครื่องแต่ละเครื่อง โดยดำเนินการฝึกอบรมหลายขั้นตอนอิสระบนข้อมูลเฉพาะเครื่อง แบบจำลองแต่ละแบบจำลองมีความก้าวหน้าอย่างมากในตัวเอง
- ตัวเพิ่มประสิทธิภาพภายนอกจะจัดการกับการซิงโครไนซ์ทั่วโลกแบบไม่บ่อยครั้ง หลังจากผ่านขั้นตอนภายในหลายขั้นตอน แต่ละโหนดเวิร์กเกอร์จะคำนวณการเปลี่ยนแปลงทั้งหมดในพารามิเตอร์โมเดล การเปลี่ยนแปลงเหล่านี้จะถูกรวบรวม และตัวเพิ่มประสิทธิภาพภายนอกจะใช้การอัปเดตเฉลี่ยนี้เพื่อปรับโมเดลทั่วโลกสำหรับยุคถัดไป
สถาปัตยกรรมแบบ dual-optimizer นี้เปลี่ยนแปลงพลวัตของการเทรนนิ่งโดยพื้นฐาน แทนที่จะมีการสื่อสารแบบทีละขั้นตอนบ่อยครั้งระหว่างทุกโหนด มันจะกลายเป็นชุดของช่วงเวลาการประมวลผลที่ขยายออกไปและเป็นอิสระต่อกัน ตามด้วยการอัปเดตรวมเพียงครั้งเดียว การเปลี่ยนแปลงอัลกอริทึมนี้ ซึ่งเกิดจากการวิจัยความเป็นส่วนตัว ถือเป็นความก้าวหน้าที่สำคัญยิ่งสำหรับการเปิดใช้งานการเทรนนิ่งบนเครือข่ายที่ช้า คำถามคือ: สามารถนำไปใช้กับโมเดลภาษาขนาดใหญ่ได้หรือไม่
ต่อไปนี้เป็นแผนภาพของกรอบการทำงานการเพิ่มประสิทธิภาพแบบรวมศูนย์: การฝึกอบรมในพื้นที่และการซิงโครไนซ์ทั่วโลกเป็นระยะ 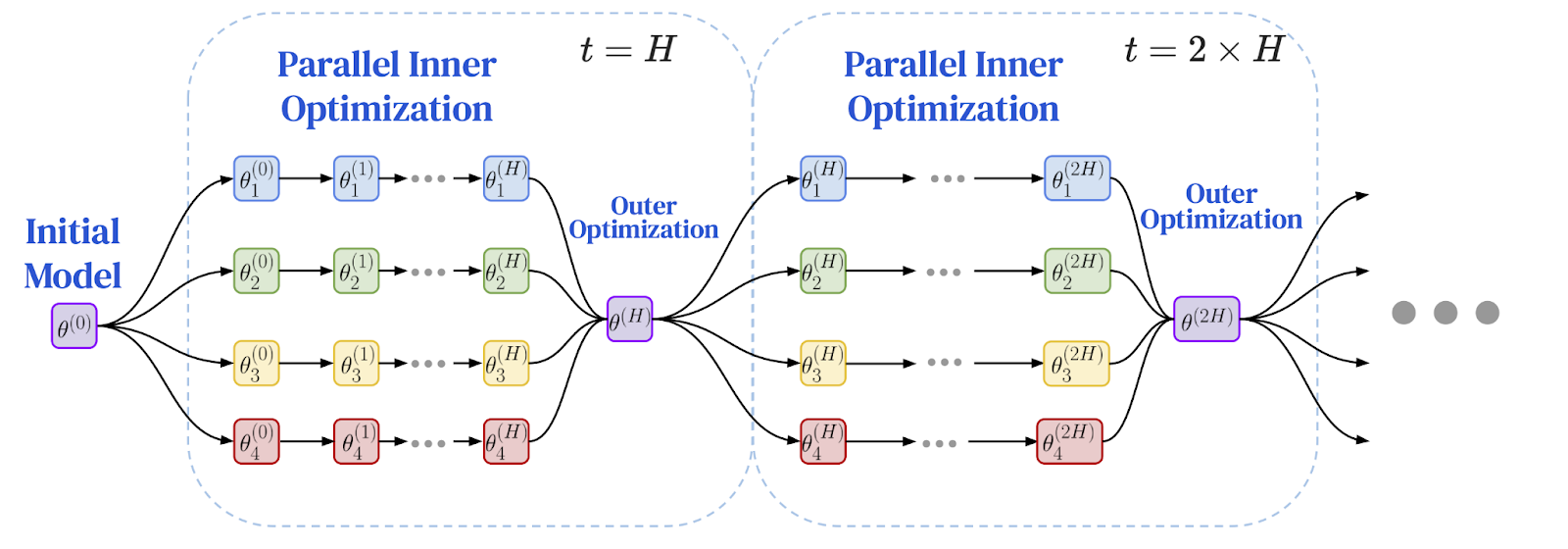
ที่มาของภาพ: Charles, Z. และคณะ (2025). "การฝึกอบรมโมเดลภาษาที่มีประสิทธิภาพในการสื่อสารปรับขนาดได้อย่างน่าเชื่อถือและแข็งแกร่ง: กฎการปรับขนาดสำหรับ DiLoCo" arXiv:2503.09799
4. ความก้าวหน้า: DiLoCo พิสูจน์ความเป็นไปได้ในระดับขนาดใหญ่
คำตอบมาในรูปแบบของอัลกอริทึม DiLoCo (Distributed Low Communication) ซึ่งแสดงให้เห็นถึงความเป็นไปได้ในทางปฏิบัติของการปรับแต่งแบบรวมศูนย์สำหรับแบบจำลองภาษาขนาดใหญ่ DiLoCo นำเสนอรูปแบบเฉพาะที่ปรับแต่งมาอย่างดีสำหรับการฝึกแบบจำลอง Transformer สมัยใหม่บนเครือข่ายที่ช้า:
- ตัวเพิ่มประสิทธิภาพภายใน: AdamW ซึ่งเป็นตัวเพิ่มประสิทธิภาพอันล้ำสมัยสำหรับโมเดลภาษาขนาดใหญ่ รันขั้นตอนการฝึกอบรมภายในหลายขั้นตอนบนโหนดเวิร์กเกอร์แต่ละโหนด
- ตัวเพิ่มประสิทธิภาพภายนอก: Nesterov Momentum เป็นอัลกอริทึมอันทรงพลังและเข้าใจง่ายที่จัดการการอัปเดตทั่วโลกที่ไม่บ่อยครั้ง
การทดลองเบื้องต้นแสดงให้เห็นว่า DiLoCo สามารถเทียบเท่ากับประสิทธิภาพของการฝึกอบรมศูนย์ข้อมูลแบบซิงโครนัสเต็มรูปแบบในขณะที่ลดการสื่อสารระหว่างโหนดลงได้ถึง 500 เท่า แสดงให้เห็นถึงความเป็นไปได้ในการฝึกอบรมโมเดลขนาดใหญ่ผ่านทางอินเทอร์เน็ต
ความก้าวหน้าครั้งนี้ได้รับความสนใจอย่างรวดเร็ว การนำ OpenDiLoCo ไปใช้งานในรูปแบบโอเพนซอร์ส ได้จำลองผลลัพธ์ดั้งเดิมและผสานรวมอัลกอริทึมเข้ากับเฟรมเวิร์กแบบเพียร์ทูเพียร์อย่างแท้จริงโดยใช้ไลบรารี Hivemind ทำให้เทคโนโลยีนี้เข้าถึงได้ง่ายขึ้น แรงผลักดันนี้นำไปสู่ความพยายามในการฝึกอบรมเบื้องต้นขนาดใหญ่ที่ประสบความสำเร็จโดยองค์กรต่างๆ เช่น PrimeIntellect , Nous Research และ FlowerLabs ซึ่งแสดงให้เห็นถึงความสำเร็จในการฝึกอบรมเบื้องต้นสำหรับแบบจำลองหลายพันล้านพารามิเตอร์ผ่านอินเทอร์เน็ตโดยใช้อัลกอริทึมที่มีการสื่อสารต่ำ ความพยายามอันล้ำสมัยเหล่านี้ได้เปลี่ยนโฉมการฝึกอบรมแบบ DiLoCo จากงานวิจัยที่มีแนวโน้มดี ไปสู่วิธีการที่ได้รับการพิสูจน์แล้วสำหรับการสร้างแบบจำลองพื้นฐานนอกเหนือจากผู้ให้บริการแบบรวมศูนย์
5. การสำรวจขอบเขต: เทคโนโลยีขั้นสูงและการวิจัยในอนาคต
ความสำเร็จของ DiLoCo ได้กระตุ้นให้เกิดงานวิจัยใหม่ ๆ ที่มุ่งเน้นการปรับปรุงประสิทธิภาพและขนาดของมันให้ดียิ่งขึ้น ก้าวสำคัญในการพัฒนาวิธีการนี้คือการพัฒนา กฎการปรับขนาด DiLoCo ซึ่งพิสูจน์ให้เห็นว่าประสิทธิภาพของ DiLoCo สามารถปรับขนาดได้อย่างคาดการณ์และมั่นคงตามขนาดของแบบจำลอง กฎการปรับขนาดเหล่านี้คาดการณ์ว่าเมื่อแบบจำลองมีขนาดใหญ่ขึ้น DiLoCo ที่ปรับแต่งมาอย่างดีจะมีประสิทธิภาพเหนือกว่าการฝึกแบบขนานข้อมูลแบบดั้งเดิมภายใต้งบประมาณการคำนวณคงที่ ในขณะที่ใช้แบนด์วิดท์น้อยลงหลายเท่า
เพื่อจัดการกับแบบจำลองที่มีพารามิเตอร์มากกว่า 100 พันล้านพารามิเตอร์ นักวิจัยได้ขยายการออกแบบ DiLoCo ด้วยเทคนิคต่างๆ เช่น DiLoCoX ซึ่งผสานรวมวิธีการเพิ่มประสิทธิภาพแบบคู่ขนานเข้ากับกระบวนการทำงานแบบขนานของไปป์ไลน์ DiLoCoX ช่วยให้สามารถฝึกแบบจำลองที่มีพารามิเตอร์ 107 พันล้านพารามิเตอร์ล่วงหน้าบนเครือข่ายมาตรฐาน 1 Gbps การปรับปรุงเพิ่มเติมประกอบด้วย การสตรีม DiLoCo (ซึ่งซ้อนทับการสื่อสารและการคำนวณเพื่อซ่อนความหน่วงของเครือข่าย) และ แนวทางแบบอะซิงโครนัส (ซึ่งป้องกันไม่ให้โหนดเดียวที่ช้ากลายเป็นคอขวดสำหรับทั้งระบบ)
นวัตกรรมยังเกิดขึ้นที่แกนกลางของอัลกอริทึม การวิจัยเกี่ยวกับออปติไมเซอร์ภายในแบบใหม่ เช่น Muon ได้นำไปสู่ MuLoCo ซึ่งเป็นตัวแปรที่อนุญาตให้บีบอัดการอัปเดตแบบจำลองให้เหลือ 2 บิต โดยสูญเสียประสิทธิภาพเพียงเล็กน้อย ทำให้การถ่ายโอนข้อมูลลดลง 8 เท่า ทิศทางการวิจัยที่ทะเยอทะยานที่สุดน่าจะเป็นการจำลองแบบขนานบนอินเทอร์เน็ต ซึ่งเกี่ยวข้องกับการแยกแบบจำลองออกไปยังเครื่องต่างๆ งานวิจัยในระยะแรกในด้านนี้ เช่น การจำลองแบบขนาน SWARM ได้พัฒนาวิธีการที่ทนทานต่อความผิดพลาดสำหรับการกระจายเลเยอร์แบบจำลองไปยังอุปกรณ์ที่ต่างกันและไม่น่าเชื่อถือซึ่งเชื่อมต่อกันด้วยเครือข่ายที่ช้า จากแนวคิดเหล่านี้ ทีมวิจัยอย่าง Pluralis Research ได้แสดงให้เห็นถึงความเป็นไปได้ในการฝึกแบบจำลองที่มีพารามิเตอร์หลายพันล้านตัว โดยที่เลเยอร์ต่างๆ โฮสต์อยู่บน GPU ที่มีความหลากหลายทางภูมิศาสตร์ ซึ่งเป็นการเปิดทางไปสู่การฝึกแบบจำลองบนฮาร์ดแวร์สำหรับผู้บริโภคแบบกระจายที่เชื่อมต่อด้วยการเชื่อมต่ออินเทอร์เน็ตมาตรฐานเท่านั้น
6. ความท้าทายด้านความน่าเชื่อถือ: การกำกับดูแลในเครือข่ายเปิด
เมื่อการฝึกอบรมเปลี่ยนจากศูนย์ข้อมูลที่มีการควบคุมไปสู่เครือข่ายเปิดที่ไม่ต้องขออนุญาต ปัญหาพื้นฐานก็เกิดขึ้น นั่นคือ ความน่าเชื่อถือ ในระบบที่กระจายอำนาจอย่างแท้จริงและไม่มีหน่วยงานกลาง ผู้เข้าร่วมจะตรวจสอบได้อย่างไรว่าการอัปเดตที่ได้รับจากผู้อื่นนั้นถูกต้องตามกฎหมาย จะป้องกันไม่ให้ผู้ไม่หวังดีเข้ามาทำลายโมเดล หรือป้องกันไม่ให้ผู้ไม่เอาไหนมาอ้างสิทธิ์รางวัลสำหรับงานที่ไม่เคยทำสำเร็จได้อย่างไร ปัญหาการกำกับดูแลนี้คืออุปสรรคสุดท้าย
แนวป้องกันหนึ่งคือ Byzantine fault tolerance ซึ่งเป็นแนวคิดจากการประมวลผลแบบกระจายที่มุ่งออกแบบระบบที่สามารถทำงานได้แม้ผู้เข้าร่วมบางรายจะล้มเหลวหรือกระทำการอันมีเจตนาร้าย ในระบบรวมศูนย์ เซิร์ฟเวอร์สามารถใช้กฎการรวมข้อมูลที่แข็งแกร่งเพื่อลบการอัปเดตที่เป็นอันตราย ซึ่งทำได้ยากกว่าในสภาพแวดล้อมแบบเพียร์ทูเพียร์ที่ไม่มีตัวรวบรวมส่วนกลาง ในทางกลับกัน แต่ละโหนดที่ซื่อสัตย์จะต้องประเมินการอัปเดตจากโหนดข้างเคียง และตัดสินใจว่าจะเชื่อถือหรือลบการอัปเดตใด
อีกแนวทางหนึ่งเกี่ยวข้องกับ เทคนิคการเข้ารหัส ที่แทนที่ความน่าเชื่อถือด้วยการตรวจสอบยืนยัน แนวคิดแรกเริ่มหนึ่งคือ Proof -of-Learning ซึ่งเสนอให้ผู้เข้าร่วมบันทึกจุดตรวจสอบการฝึกฝนเพื่อพิสูจน์ว่าพวกเขาได้ลงทุนกับการคำนวณที่จำเป็นแล้ว เทคนิคอื่นๆ เช่น Zero-Knowledge Proofs (ZKPs) ช่วยให้โหนดเวิร์กเกอร์สามารถพิสูจน์ได้ว่าได้ดำเนินการตามขั้นตอนการฝึกที่จำเป็นอย่างถูกต้องโดยไม่เปิดเผยข้อมูลพื้นฐาน แม้ว่าต้นทุนการคำนวณในปัจจุบันยังคงเป็นความท้าทายสำหรับการตรวจสอบการฝึกฝนแบบจำลองโครงสร้างพื้นฐานขนาดใหญ่ในปัจจุบัน
แนวโน้ม: รุ่งอรุณของกระบวนทัศน์ AI ใหม่
การเดินทางจากศูนย์ข้อมูลแบบมีกำแพงกั้นไปสู่อินเทอร์เน็ตแบบเปิด ถือเป็นการเปลี่ยนแปลงครั้งสำคัญในวิธีการสร้าง AI เราเริ่มต้นจากขีดจำกัดทางกายภาพของการฝึกอบรมแบบรวมศูนย์ ซึ่งความก้าวหน้าขึ้นอยู่กับการเข้าถึงฮาร์ดแวร์ราคาแพงที่ตั้งอยู่ในสถานที่เดียวกัน สิ่งนี้นำไปสู่ปัญหาคอขวดในการสื่อสาร ซึ่งเป็นกำแพงที่ทำให้การฝึกอบรมโมเดลขนาดใหญ่บนเครือข่ายแบบกระจายไม่สามารถทำได้จริง อย่างไรก็ตาม กำแพงนี้ไม่ได้ถูกทำลายด้วยสายเคเบิลที่เร็วขึ้น แต่เกิดจากอัลกอริทึมที่มีประสิทธิภาพมากขึ้น
การเปลี่ยนแปลงอัลกอริทึมนี้ ซึ่งมีรากฐานมาจากการหาค่าเหมาะที่สุดแบบรวมศูนย์และถูกนำไปใช้โดย DiLoCo แสดงให้เห็นว่าการลดความถี่ในการสื่อสารเป็นกุญแจสำคัญ ความก้าวหน้าครั้งสำคัญนี้กำลังก้าวหน้าอย่างรวดเร็วด้วยเทคนิคที่หลากหลาย ได้แก่ การกำหนดกฎเกณฑ์การปรับขนาด การสื่อสารแบบซ้อนทับ การสำรวจตัวเพิ่มประสิทธิภาพใหม่ๆ และแม้แต่การนำแบบจำลองมาเปรียบเทียบกันผ่านอินเทอร์เน็ต ความสำเร็จในการฝึกอบรมแบบจำลองพารามิเตอร์หลายพันล้านรายการล่วงหน้าโดยนักวิจัยและบริษัทต่างๆ ในระบบนิเวศที่หลากหลาย เป็นเครื่องพิสูจน์ถึงพลังของกระบวนทัศน์ใหม่นี้
เมื่อความท้าทายด้านความน่าเชื่อถือได้รับการแก้ไขผ่านระบบป้องกันที่แข็งแกร่งและการตรวจสอบการเข้ารหัส เส้นทางก็เริ่มชัดเจนขึ้น การฝึกอบรมแบบกระจายศูนย์กำลังพัฒนาจากโซลูชันทางวิศวกรรมไปสู่เสาหลักแห่งอนาคต AI ที่เปิดกว้าง ร่วมมือกัน และเข้าถึงได้มากขึ้น นี่คือการประกาศถึงโลกที่ความสามารถในการสร้างแบบจำลองอันทรงพลังไม่ได้จำกัดอยู่แค่บริษัทเทคโนโลยียักษ์ใหญ่เพียงไม่กี่แห่งอีกต่อไป แต่กระจายไปทั่วโลก ปลดปล่อยพลังการประมวลผลและภูมิปัญญาของทุกคน
อ้างอิง
McMahan, HB และคณะ (2017). การเรียนรู้เครือข่ายเชิงลึกที่มีประสิทธิภาพในการสื่อสารจากข้อมูลแบบกระจายศูนย์ . การประชุมนานาชาติว่าด้วยปัญญาประดิษฐ์และสถิติ (AISTATS)
Reddi, S. และคณะ (2021). Adaptive Federated Optimization . การประชุมนานาชาติเรื่องการนำเสนอการเรียนรู้ (ICLR)
Jia, H. และคณะ (2021). Proof-of-Learning: คำจำกัดความและการปฏิบัติ . การประชุมเชิงปฏิบัติการ IEEE ด้านความปลอดภัยและความเป็นส่วนตัว
Ryabinin, Max และคณะ (2023). การประมวลผลแบบขนานของ Swarm: การฝึกโมเดลขนาดใหญ่สามารถสื่อสารได้อย่างมีประสิทธิภาพอย่างน่าประหลาดใจ . การประชุมนานาชาติว่าด้วยการเรียนรู้ของเครื่อง (ICML)
Douillard, A. และคณะ (2023). DiLoCo: การฝึกอบรมแบบจำลองภาษาที่สื่อสารต่ำแบบกระจาย
Jaghouar, S., Ong, JM, & Hagemann, J. (2024) OpenDiLoCo: กรอบงานโอเพ่นซอร์สสำหรับการฝึกอบรมการสื่อสารต่ำแบบกระจายทั่วโลก
Jaghouar, S. และคณะ (2024). การฝึกอบรมแบบกระจายอำนาจของโมเดลพื้นฐาน: กรณีศึกษาด้วย INTELLECT-1
Liu, B. และคณะ (2024). การฝึกอบรม SGD ท้องถิ่นแบบอะซิงโครนัสสำหรับการสร้างแบบจำลองภาษา
Charles, Z. และคณะ (2025). การฝึกอบรมโมเดลภาษาที่มีประสิทธิภาพในการสื่อสารปรับขนาดได้อย่างน่าเชื่อถือและแข็งแกร่ง: กฎการปรับขนาดสำหรับ DiLoCo
Douillard, A. และคณะ (2025). การสตรีม DiLoCo ที่มีการสื่อสารแบบทับซ้อน: สู่อาหารกลางวันฟรีแบบกระจาย
ทีม Psyche (2025) การทำให้ AI เป็นประชาธิปไตย: สถาปัตยกรรมเครือข่าย Psyche บล็อกวิจัยของเรา
Qi, J. และคณะ (2025). DiLoCoX: กรอบการฝึกอบรมขนาดใหญ่ที่มีการสื่อสารต่ำสำหรับคลัสเตอร์แบบกระจายอำนาจ
Sani, L. และคณะ (2025). Photon: การฝึกอบรมเบื้องต้นสำหรับหลักสูตร Federated LLM . รายงานการประชุมเรื่องการเรียนรู้ของเครื่องจักรและระบบ (MLSys)
Thérien, B. และคณะ (2025). MuLoCo: Muon เป็นตัวเพิ่มประสิทธิภาพภายในที่ใช้งานได้จริงสำหรับ DiLoCo
Long, A. และคณะ (2025). โมเดลโปรโตคอล: การปรับขนาดการฝึกอบรมแบบกระจายอำนาจด้วยการประมวลผลคู่ขนานของโมเดลที่มีประสิทธิภาพในการสื่อสาร