
โมเดล AI ที่ใหญ่กว่าไม่ดีกว่าใช่ไหม การวิเคราะห์ที่ครอบคลุมของโซลูชันทางเทคนิคแบบจำลอง การลดขนาด
ChatGPT นำไปสู่ความนิยมทั่วโลกสำหรับโมเดลขนาดใหญ่ บริษัท อินเทอร์เน็ตตกอยู่ใน สงครามของโมเดลหลายร้อยรุ่น และแม้กระทั่ง การมีส่วนร่วม: โมเดลขนาดใหญ่ที่แต่ละ บริษัท เปิดตัวนั้นใหญ่กว่ารุ่นก่อนและขนาดพารามิเตอร์ก็กลายเป็น การแสดงผาดโผนในการประชาสัมพันธ์ และเกือบทั้งหมดอยู่ในหลักหมื่นล้าน แสนล้าน หรือมากกว่าล้านล้านด้วยซ้ำ
อย่างไรก็ตาม บางคนแย้งว่าสภาพที่เป็นอยู่นี้ไม่ใช่แนวทางการพัฒนาที่ยั่งยืน Sam Altman ผู้ก่อตั้ง OpenAI กล่าวว่าต้นทุนการพัฒนา GPT-4 เกิน 100 ล้านดอลลาร์สหรัฐ ตามรายงานที่ตีพิมพ์โดยนิตยสาร Analytics India ระบุว่า OpenAI จะใช้เงินประมาณ 700,000 ดอลลาร์สหรัฐต่อวันเพื่อใช้บริการปัญญาประดิษฐ์ ChatGPT ในเวลาเดียวกัน LLM ยังแสดงความกังวลเกี่ยวกับการใช้พลังงาน และ Google รายงานว่าการฝึกอบรม PaLM ใช้พลังงานประมาณ 3.4 กิโลวัตต์-ชั่วโมงในเวลาประมาณสองเดือน ซึ่งเทียบเท่ากับการใช้พลังงานต่อปีของบ้านประมาณ 300 หลังในสหรัฐฯ
ดังนั้น เนื่องจากขนาดของโมเดลยังคงเพิ่มขึ้นอย่างต่อเนื่อง Julien Simon หัวหน้าผู้เผยแพร่ข่าวของ HuggingFace จึงกล่าวว่า เล็กลงย่อมดีกว่า ในความเป็นจริงหลังจากที่ขนาดพารามิเตอร์ถึงระดับหนึ่งการเพิ่มพารามิเตอร์มักจะไม่ได้ปรับปรุงผลกระทบของแบบจำลองอย่างมีนัยสำคัญ เมื่อพิจารณาถึงการปฏิบัติจริงและความประหยัดแบบจำลอง การลดขนาด เป็นทางเลือกที่หลีกเลี่ยงไม่ได้เนื่องจากเมื่อเปรียบเทียบกับพารามิเตอร์ขนาดใหญ่ผลประโยชน์ส่วนเพิ่มที่ลดลงของขนาด และต้นทุนการใช้ทรัพยากรจำนวนมากมักไม่คุ้มค่า ยิ่งไปกว่านั้น โมเดลขนาดใหญ่จะสร้างปัญหามากมายให้กับแอปพลิเคชันเนื่องจากมีขนาดใหญ่ เช่น ไม่สามารถ Deploy บน Edge Devices ได้ และสามารถให้บริการแก่ผู้ใช้ได้เฉพาะในรูปแบบ Cloud เท่านั้น อย่างไรก็ตาม หลายครั้งเราต้อง Deploy โมเดลนี้ บน Edge Node เพื่อให้บริการแก่ผู้ใช้ บริการส่วนบุคคล
หากโมเดล AI ต้องการปรับปรุงอย่างต่อเนื่อง นักพัฒนาจะต้องระบุวิธีบรรลุประสิทธิภาพที่สูงขึ้นโดยใช้ทรัพยากรน้อยลง ไม่ว่าจะในแวดวงวิชาการหรืออุตสาหกรรม การบีบอัดโมเดลขนาดใหญ่ถือเป็นประเด็นร้อนมาโดยตลอด และปัจจุบันมีเทคโนโลยีมากมายที่กำลังดำเนินการดังกล่าว บทความนี้จะแนะนำวิธีการบีบอัดโมเดลทั่วไปโดยย่อ 4 วิธี ได้แก่ การหาปริมาณ การตัด การแบ่งปันพารามิเตอร์ และการกลั่นกรองความรู้ เพื่อช่วยให้คุณเข้าใจวิธีการบีบอัดโมเดลโดยสัญชาตญาณ
1. พื้นฐานทางทฤษฎีของการลดขนาดแบบจำลอง: การลดลงเล็กน้อย ของขนาดพารามิเตอร์
หากเราเปรียบเทียบแบบจำลองกับ ถัง ข้อมูลกับ แอปเปิ้ล และข้อมูลที่มีอยู่ในข้อมูลกับ น้ำแอปเปิ้ล ดังนั้นกระบวนการฝึกแบบจำลองขนาดใหญ่สามารถเข้าใจได้ว่าเป็นกระบวนการเติมน้ำแอปเปิ้ลใน ถัง. . ยิ่งแอปเปิ้ลมากก็ยิ่งมีไซเดอร์มากขึ้น และเราต้องการถังที่ใหญ่กว่าเพื่อเก็บไซเดอร์ การเกิดขึ้นของโมเดลขนาดใหญ่ก็เหมือนกับการสร้างถังขนาดใหญ่ขึ้นซึ่งมีความจุที่มากกว่าในการเก็บน้ำแอปเปิ้ลได้เพียงพอ
หากมีแอปเปิ้ลมากเกินไปและน้ำแอปเปิ้ลมากเกินไปจะทำให้เกิด ล้น กล่าวคือ โมเดลมีขนาดเล็กเกินไปที่จะเรียนรู้ความรู้ทั้งหมดในชุดข้อมูล เราเรียกสถานการณ์นี้ว่า underfitting นั่นคือ โมเดลไม่สามารถเรียนรู้การกระจายข้อมูลจริงได้ หากมีแอปเปิ้ลน้อยเกินไปและน้ำแอปเปิ้ลน้อยเกินไป จะทำให้ ไม่เพียงพอ หากคุณ บีบบังคับ ที่ฝากข้อมูลโดยเพิ่มเวลาการฝึกของโมเดล จะส่งผลให้มีสิ่งเจือปนในน้ำผลไม้เพิ่มขึ้น ส่งผลให้ประสิทธิภาพของโมเดลลดลง เราเรียกสถานการณ์นี้ว่า การสวมมากเกินไป ซึ่งเป็นปัญหาทั่วไป เกิดจากรูปแบบการเรียนรู้ข้อมูลมากเกินไป ความเสื่อมทางเพศ ดังนั้นจึงเป็นเรื่องสำคัญมากที่จะต้องจับคู่ขนาดโมเดลกับขนาดข้อมูล
แม้ว่าตัวอย่างข้างต้นจะชัดเจน แต่ก็ทำให้เกิดความเข้าใจผิดได้ง่าย เช่น ถัง 1 ลิตรสามารถบรรจุน้ำแอปเปิ้ลได้ 1 ลิตร และถัง 2 ลิตรสามารถบรรจุได้ 2 ลิตร (เช่น 1) แต่ในความเป็นจริง ข้อมูลที่พารามิเตอร์สามารถเก็บได้นั้นไม่ได้เพิ่มขึ้นเป็นเส้นตรงกับขนาดของพารามิเตอร์ แต่มีแนวโน้มที่จะเติบโต ลดลงเล็กน้อย (เช่น ⁵⁵⁵⁵⁶))
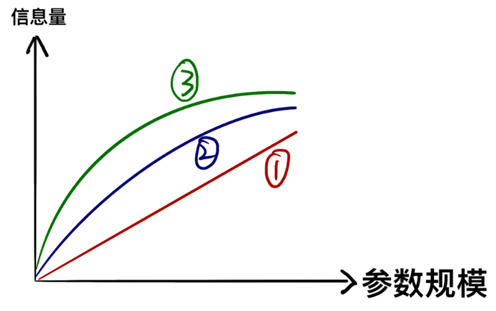
กล่าวอีกนัยหนึ่ง ความสามารถพิเศษที่แสดงโดยแบบจำลองขนาดใหญ่นั้นเกิดจากการที่ได้เรียนรู้ ความรู้โดยละเอียด มากมาย และพารามิเตอร์ที่ใช้ใน ความรู้โดยละเอียด นั้นมีมากมายมหาศาล เมื่อเราได้เรียนรู้ความรู้ส่วนใหญ่ในข้อมูลแล้ว เราจำเป็นต้องเพิ่มพารามิเตอร์เพิ่มเติมหากเรายังคงเรียนรู้ความรู้ที่มีรายละเอียดมากขึ้นต่อไป หากเรายอมสละความแม่นยำ ละเลยข้อมูลรายละเอียดบางส่วน หรือตัดพารามิเตอร์ที่ระบุข้อมูลโดยละเอียด ขนาดของพารามิเตอร์ก็จะลดลงได้มาก และนี่คือพื้นฐานทางทฤษฎีและแนวคิดหลักของโมเดลการลดความอ้วนในแวดวงวิชาการและ อุตสาหกรรม
2. การหาปริมาณ - วิธีลดน้ำหนักที่ ง่ายและหยาบ ที่สุด
ในคอมพิวเตอร์ ยิ่งค่าความแม่นยำของตัวเลขสูงเท่าใด ก็ยิ่งต้องการพื้นที่จัดเก็บข้อมูลมากขึ้นเท่านั้น หากความแม่นยำของพารามิเตอร์ของแบบจำลองสูงมาก (ความเข้าใจโดยสัญชาตญาณคือมีตัวเลขหลายหลักหลังจุดทศนิยม) เราก็สามารถลดความแม่นยำลงได้โดยตรงเพื่อให้ได้การบีบอัดแบบจำลองซึ่งเป็นแนวคิดหลักของการหาปริมาณ พารามิเตอร์ของรุ่นทั่วไปคือ 3 2 บิต หากเราตกลงที่จะลดความแม่นยำของโมเดลลงเหลือ 8 บิต เราสามารถลดพื้นที่เก็บข้อมูลลงได้ 75%
พื้นฐานทางทฤษฎีของวิธีการนี้เป็นความเห็นพ้องต้องกันในโรงเรียนการหาปริมาณ: แบบจำลองที่ซับซ้อนและมีความแม่นยำสูงเป็นสิ่งจำเป็นในระหว่างการฝึกอบรม เนื่องจากเราจำเป็นต้องบันทึกการเปลี่ยนแปลงการไล่ระดับสีเล็กน้อยระหว่างการปรับให้เหมาะสม แต่ไม่จำเป็นในระหว่างการให้เหตุผล ดังนั้นการหาปริมาณจึงสามารถลดได้เพียง พื้นที่ที่แบบจำลองครอบครองโดยไม่ลดความสามารถในการให้เหตุผลมากเกินไป
3. การตัดแต่งกิ่ง - วิธีการกำจัดพารามิเตอร์ การผ่าตัด
โมเดลขนาดใหญ่มีขนาดใหญ่และมีโครงสร้างที่ซับซ้อน และมีพารามิเตอร์และโครงสร้างจำนวนมากที่มีการใช้งานเพียงเล็กน้อยหรือไม่มีเลยผสมอยู่ภายใน หากเราสามารถระบุชิ้นส่วนที่ไม่มีประโยชน์ได้อย่างแม่นยำที่สุดเท่าที่จะเป็นไปได้และกำจัดออก เราก็สามารถลดขนาดของโมเดลในขณะที่ยังคงฟังก์ชันการทำงานไว้ได้
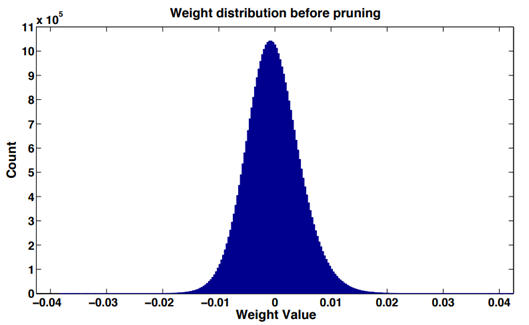
ในโครงข่ายประสาทเทียมส่วนใหญ่โดยทำสถิติฮิสโตแกรมกับค่าน้ำหนักของเลเยอร์เครือข่าย (ชั้น Convolution หรือชั้นที่เชื่อมต่อกันอย่างสมบูรณ์) พบว่าการกระจายค่าน้ำหนักหลังการฝึกจะอยู่ที่ประมาณการกระจายแบบปกติหรือส่วนผสมของค่าปกติหลายค่า การแจกแจงใกล้เคียงกัน มีค่าน้ำหนักค่อนข้างมากสำหรับ 0 ซึ่งเป็นปรากฏการณ์ ความกระจัดกระจายของน้ำหนัก
ค่าสัมบูรณ์ของค่าน้ำหนักถือได้ว่าเป็นตัวชี้วัดความสำคัญ ยิ่งค่าน้ำหนักมากเท่าใดก็ยิ่งมีส่วนสนับสนุนในเอาท์พุตโมเดลมากขึ้นเท่านั้น ตรงกันข้าม มันไม่สำคัญ ผลกระทบต่อความแม่นยำของโมเดลหลังการลบ มีขนาดค่อนข้างเล็ก
ในเวลาเดียวกัน ในเครือข่ายระดับลึก มีเซลล์ประสาทจำนวนมากที่เปิดใช้งานได้ยาก รายงานเรื่อง Network Trimming: A Data-Driven Neuron Pruning Approach to Efficient Deep Architecture ได้ศึกษาสถิติง่ายๆ และพบว่าไม่ว่าจะป้อนข้อมูลรูปภาพประเภทใดก็ตาม เซลล์ประสาทจำนวนมากใน CNN มีการเปิดใช้งานต่ำมาก ผู้เขียนยืนยันว่าเซลล์ประสาทที่เป็นศูนย์มีแนวโน้มที่จะซ้ำซ้อนและสามารถลบออกได้โดยไม่ส่งผลกระทบต่อความแม่นยำโดยรวมของเครือข่าย เราเรียกสถานการณ์นี้ว่า การกระจัดกระจายของการเปิดใช้งาน
ดังนั้น ตามคุณลักษณะข้างต้นของโครงข่ายประสาทเทียม เราจึงสามารถปรับแต่งและเพิ่มประสิทธิภาพโครงสร้างต่างๆ เพื่อลดขนาดของแบบจำลองได้
4. การแชร์พารามิเตอร์ - มองหาทางเลือกเล็กๆ ให้กับโมเดลที่ซับซ้อน
โครงข่ายประสาทเทียมคือความเหมาะสมของการกระจายข้อมูลจริง ซึ่งเป็นฟังก์ชันหลัก หากเราสามารถค้นหาฟังก์ชันที่มีประสิทธิภาพเท่ากันแต่ขนาดพารามิเตอร์เล็กลง เพื่อให้อินพุตเดียวกันสามารถมีเอาต์พุตที่คล้ายกันได้ ขนาดพารามิเตอร์ก็จะลดลงตามธรรมชาติ
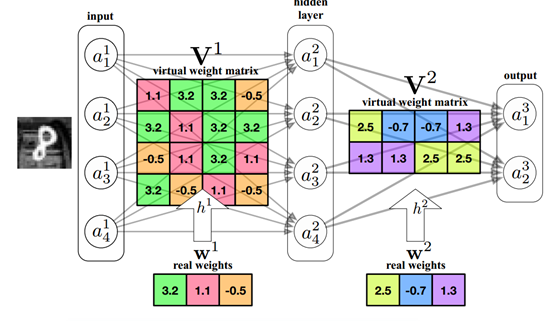
ในด้านเทคนิค เรามักจะใช้อัลกอริธึม PCA สำหรับการลดขนาดเพื่อค้นหาการแมปอาร์เรย์มิติสูงในมิติต่ำ หากเราพบการแมปมิติต่ำของเมทริกซ์พารามิเตอร์แบบจำลอง เราสามารถลดจำนวนพารามิเตอร์ไปพร้อมๆ กับรับประกันประสิทธิภาพ
มีวิธีการแบ่งปันพารามิเตอร์ที่หลากหลายอยู่แล้ว เช่น การจัดกลุ่มน้ำหนักเฉลี่ย K การจำแนกแบบสุ่มโดยใช้วิธีแฮช จากนั้นจึงประมวลผลน้ำหนักของกลุ่มเดียวกัน
5. การกลั่นกรองความรู้ - นักเรียนทดแทนครู
เนื่องจากโมเดลใหญ่มีความรู้มากมาย เราจะปล่อยให้โมเดลใหญ่ สอน โมเดลเล็ก เพื่อให้โมเดลเล็กมีความสามารถเหมือนกับโมเดลใหญ่ได้หรือไม่? นี่คือแนวคิดหลักของการกลั่นกรองความรู้
โมเดลขนาดใหญ่ที่เรามีอยู่อยู่แล้วเรียกว่าโมเดลครู ณ จุดนี้ เราสามารถใช้ Teacher model เพื่อควบคุม Student model เพื่อเรียนรู้ความรู้เกี่ยวกับ Teacher model ได้
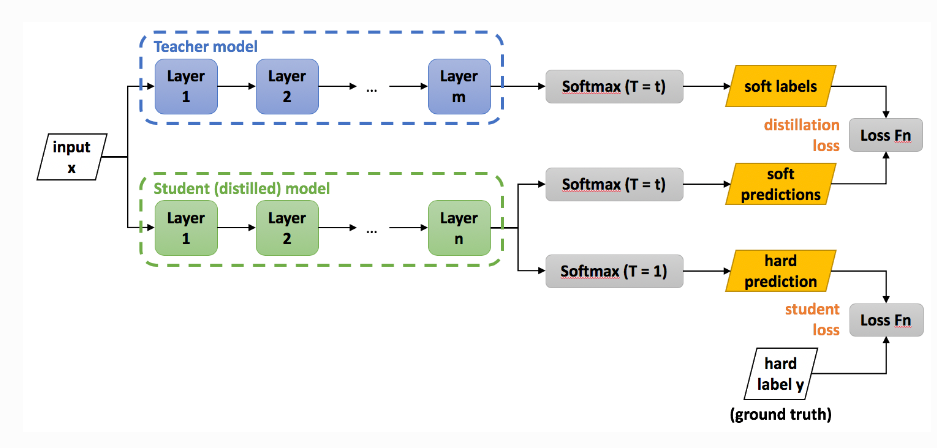
สามวิธีแรกเปลี่ยนพารามิเตอร์หรือโครงสร้างของโมเดลดั้งเดิมไม่มากก็น้อย ในขณะที่การกลั่นกรองความรู้เทียบเท่ากับการฝึกโมเดลขนาดเล็กขึ้นใหม่ จึงสามารถรักษาฟังก์ชันของโมเดลดั้งเดิมได้ดีกว่าวิธีอื่น ๆ แต่ความแม่นยำบางส่วนหายไป
บทสรุป
ไม่มีวิธีการแบบครบวงจรสำหรับการบีบอัดโมเดล สำหรับรุ่นต่างๆ โดยทั่วไปจะพยายามใช้วิธีการบีบอัดหลายวิธีเพื่อให้เกิดความสมดุลระหว่างขนาดและความแม่นยำ ปัจจุบันโมเดลขนาดใหญ่ที่เราใช้นั้นถูกใช้งานบนคลาวด์ทั้งหมดและเรามีสิทธิ์ที่จะเรียกแต่ไม่ได้เป็นเจ้าของ ท้ายที่สุด โมเดลขนาดใหญ่ดังกล่าวไม่สามารถจัดเก็บในเครื่องได้ ดูเหมือนว่า ใครๆ ก็ต่างก็มีโมเดลขนาดใหญ่ ความฝันที่ไม่สามารถบรรลุได้ อย่างไรก็ตาม เมื่อเรามองย้อนกลับไปในอดีต เมื่อคอมพิวเตอร์ถือกำเนิดขึ้นในทศวรรษ 1940 ผู้คนเห็น เครื่องจักรยักษ์ใหญ่ ขนาดใหญ่และหิวโหยเช่นนี้ ไม่มีใครคาดเดาได้ว่าจะกลายเป็นคอมพิวเตอร์ของทุกคนในทุกวันนี้ในทศวรรษต่อมา ทุกวันทั้งหมด เครื่องมือ ในทำนองเดียวกัน ด้วยการพัฒนาเทคโนโลยีการบีบอัดโมเดล การเพิ่มประสิทธิภาพโครงสร้างโมเดล และการเพิ่มประสิทธิภาพของฮาร์ดแวร์แบบก้าวกระโดด เรายังคาดหวังว่าในอนาคต โมเดลขนาดใหญ่จะไม่ ใหญ่ อีกต่อไป แต่จะกลายเป็นเครื่องมือส่วนตัวที่ทุกคนสามารถทำได้ เป็นเจ้าของ.
อ้างอิง:
https://blog.csdn.net/shentanyue/article/details/83539359
https://zhuanlan.zhihu.com/p/102038521
https://arxiv.org/abs/1607.03250
https://arxiv.org/abs/1806.09228
https://arxiv.org/abs/1504.04788
คำชี้แจงลิขสิทธิ์: หากคุณต้องการพิมพ์ซ้ำ คุณสามารถสื่อสารกับผู้ช่วยของเราบน WeChat ได้ หากคุณพิมพ์ซ้ำหรือทำความสะอาดต้นฉบับโดยไม่ได้รับอนุญาต
ข้อสงวนสิทธิ์: ตลาดมีความเสี่ยง ดังนั้นการลงทุนจึงต้องระมัดระวัง ขอให้ผู้อ่านปฏิบัติตามกฎหมายและข้อบังคับท้องถิ่นอย่างเคร่งครัดเมื่อพิจารณาความคิดเห็น ความเห็น หรือข้อสรุปในบทความนี้ เนื้อหาข้างต้นไม่ถือเป็นคำแนะนำในการลงทุนใดๆ


