중앙집중형 컴퓨팅 파워 시대는 끝났다: AI 훈련은 '컴퓨터실'에서 '네트워크'로 이동하고 있다
- 核心观点:低通信算法实现分布式AI训练。
- 关键要素:
- DiLoCo算法减少通信量500倍。
- 联邦优化解耦本地与全局计算。
- 成功预训练数十亿参数模型。
- 市场影响:降低AI训练门槛,促进行业民主化。
- 时效性标注:长期影响
원래 게시자: Egor Shulgin, Gonka Protocol
AI 기술의 급속한 발전은 학습 프로세스를 단일 물리적 공간의 한계까지 밀어붙였습니다. 연구자들은 근본적인 과제에 직면하게 되었습니다. 바로 대륙에 분산된 수천 개의 프로세서를 (컴퓨터실의 같은 복도가 아닌) 어떻게 조율할 것인가 하는 문제입니다. 해답은 더욱 효율적인 알고리즘, 즉 통신을 최소화하는 알고리즘에 있습니다. 연합 최적화 분야의 획기적인 발전으로 주도되고 DiLoCo와 같은 프레임워크로 정점을 찍은 이러한 변화는 기업들이 표준 인터넷 연결을 통해 수십억 개의 매개변수를 가진 모델을 학습할 수 있게 함으로써 대규모 협업 AI 개발의 새로운 가능성을 열어줍니다.
1. 시작점: 데이터 센터에서의 분산 훈련
현대 AI 학습은 본질적으로 분산되어 있습니다. 데이터, 매개변수, 그리고 연산의 크기를 늘리면 모델 성능이 크게 향상되어 단일 머신에서 수십억 개의 매개변수를 가진 기본 모델을 학습하는 것이 불가능하다는 것이 널리 알려져 있습니다. 기본적인 해결책은 "중앙 집중형 분산" 모델입니다. 즉, 수천 개의 GPU를 한 곳에 수용하는 전용 데이터 센터를 구축하고 NVIDIA의 NVLink 또는 InfiniBand와 같은 초고속 네트워크로 상호 연결하는 것입니다. 이러한 특수 상호 연결 기술은 표준 네트워크보다 훨씬 빠르므로 모든 GPU가 하나의 응집력 있는 통합 시스템으로 작동할 수 있습니다.
이 환경에서 가장 일반적인 학습 전략은 데이터 병렬 처리로, 데이터 세트를 여러 GPU에 분할하는 방식입니다. (파이프라인 병렬 처리나 텐서 병렬 처리와 같이 모델 자체를 여러 GPU에 분할하는 다른 방식도 있습니다. 이는 대규모 모델을 학습하는 데 필수적이지만, 구현이 더 복잡합니다.) 미니 배치 확률적 경사 하강법(SGD)을 사용하는 학습 단계의 작동 방식은 다음과 같습니다(Adam 옵티마이저에도 동일한 원리가 적용됩니다).
- 복제 및 배포: 각 GPU에 모델 사본을 로드합니다. 훈련 데이터를 작은 배치로 나눕니다.
- 병렬 컴퓨팅: 각 GPU는 서로 다른 미니 배치를 독립적으로 처리하고 모델 매개변수가 조정되는 방향인 그래디언트를 계산합니다.
- 동기화 및 집계: 모든 GPU는 작업을 일시 중지하고, 그래디언트를 공유하고, 평균을 내어 단일 통합 업데이트를 생성합니다.
- 업데이트: 이 평균 업데이트를 각 GPU의 모델 복사본에 적용하여 모든 복사본이 동일하게 유지되도록 합니다.
- 반복: 다음 작은 배치로 이동하여 다시 시작합니다.
본질적으로 이는 병렬 계산과 강제 동기화의 연속적인 순환입니다. 각 훈련 단계 후 발생하는 지속적인 통신은 데이터 센터 내의 값비싼 고속 연결을 통해서만 가능합니다. 이러한 빈번한 동기화에 대한 의존성은 중앙 집중식 분산 훈련의 특징입니다. 데이터 센터의 "온실"을 벗어날 때까지 완벽하게 작동합니다.
2. 벽에 부딪히다: 대규모 커뮤니케이션 병목 현상
대규모 모델을 학습시키려면 이제 기업들은 엄청난 규모의 인프라를 구축해야 하며, 이는 종종 여러 도시나 대륙에 걸쳐 여러 데이터 센터를 필요로 합니다. 이러한 지리적 분리는 상당한 장벽을 초래합니다. 단일 데이터 센터 내에서 효과적으로 작동하는 단계별 동기화 알고리즘 방식은 전 세계 규모로 확장되면 제대로 작동하지 않습니다.
문제는 네트워크 속도에 있습니다. 데이터 센터 내에서 InfiniBand는 400Gb/s 이상의 속도로 데이터를 전송할 수 있습니다. 반면, 멀리 떨어진 데이터 센터를 연결하는 광역 네트워크(WAN)는 일반적으로 1Gbps에 가까운 속도로 작동합니다. 이러한 성능 차이는 몇 자릿수에 달하며, 이는 거리와 비용의 근본적인 한계에서 비롯됩니다. 소규모 배치 SGD가 가정하는 거의 즉각적인 통신은 이러한 현실과 상충됩니다.
이러한 불균형은 심각한 병목 현상을 야기합니다. 각 단계마다 모델 매개변수를 동기화해야 할 때, 고성능 GPU는 대부분의 시간 동안 유휴 상태로 남아 데이터가 느린 네트워크를 통해 천천히 전송되기를 기다립니다. 결과적으로 AI 커뮤니티는 기업용 서버에서 소비자용 하드웨어에 이르기까지 전 세계에 분산된 방대한 컴퓨팅 리소스를 활용할 수 없게 됩니다. 기존 알고리즘은 고속 중앙 집중식 네트워크를 필요로 하기 때문입니다. 이는 막대한 미개발 컴퓨팅 자원이 남아 있음을 의미합니다.
3. 알고리즘 변환: 연합 최적화
잦은 통신이 문제라면, 해결책은 통신 횟수를 줄이는 것입니다. 이 간단한 통찰력은 연합 학습(federated learning) 기술을 활용하는 알고리즘 전환의 토대를 마련했습니다. 연합 학습은 원래 개인 정보를 보호하면서 최종 기기(예: 휴대폰)의 분산 데이터를 기반으로 모델을 학습하는 데 중점을 둔 분야입니다. 핵심 알고리즘인 연합 평균화 (FedAvg)는 각 기기가 업데이트를 전송하기 전에 로컬에서 여러 학습 단계를 수행할 수 있도록 함으로써 필요한 통신 횟수를 획기적으로 줄일 수 있음을 보여주었습니다.
연구자들은 동기화 간격 사이에 더 독립적인 작업을 수행하는 원리가 지리적으로 분산된 환경에서 성능 병목 현상을 해결하는 완벽한 해결책임을 깨달았습니다. 이는 로컬 계산과 글로벌 통신을 분리하기 위해 이중 최적화 기법을 채택한 Federated Optimization (FedOpt) 프레임워크의 등장으로 이어졌습니다.
프레임워크는 두 가지 다른 최적화 프로그램을 사용하여 작동합니다.
- 내부 옵티마이저(예: 표준 SGD)는 각 머신에서 실행되어 로컬 데이터 슬라이스에 대해 여러 개의 독립적인 학습 단계를 수행합니다. 각 모델 복제본은 자체적으로 상당한 진전을 보입니다.
- 외부 옵티마이저는 드물게 발생하는 전역 동기화를 처리합니다. 여러 로컬 단계를 거친 후, 각 워커 노드는 모델 매개변수의 총 변경 사항을 계산합니다. 이러한 변경 사항은 집계되고, 외부 옵티마이저는 이 평균화된 업데이트를 사용하여 다음 에포크를 위한 전역 모델을 조정합니다.
이 이중 최적화 아키텍처는 학습의 역학을 근본적으로 변화시킵니다. 모든 노드 간의 빈번한 단계별 통신 대신, 일련의 확장되고 독립적인 계산 기간 후 단일 집계 업데이트가 이루어지는 방식입니다. 개인정보 보호 연구에서 비롯된 이러한 알고리즘적 변화는 느린 네트워크에서 학습을 가능하게 하는 중요한 돌파구를 제공합니다. 문제는 이것이 대규모 언어 모델에도 적용될 수 있을까 하는 것입니다.
다음은 연방 최적화 프레임워크의 다이어그램입니다: 로컬 학습 및 주기적 글로벌 동기화 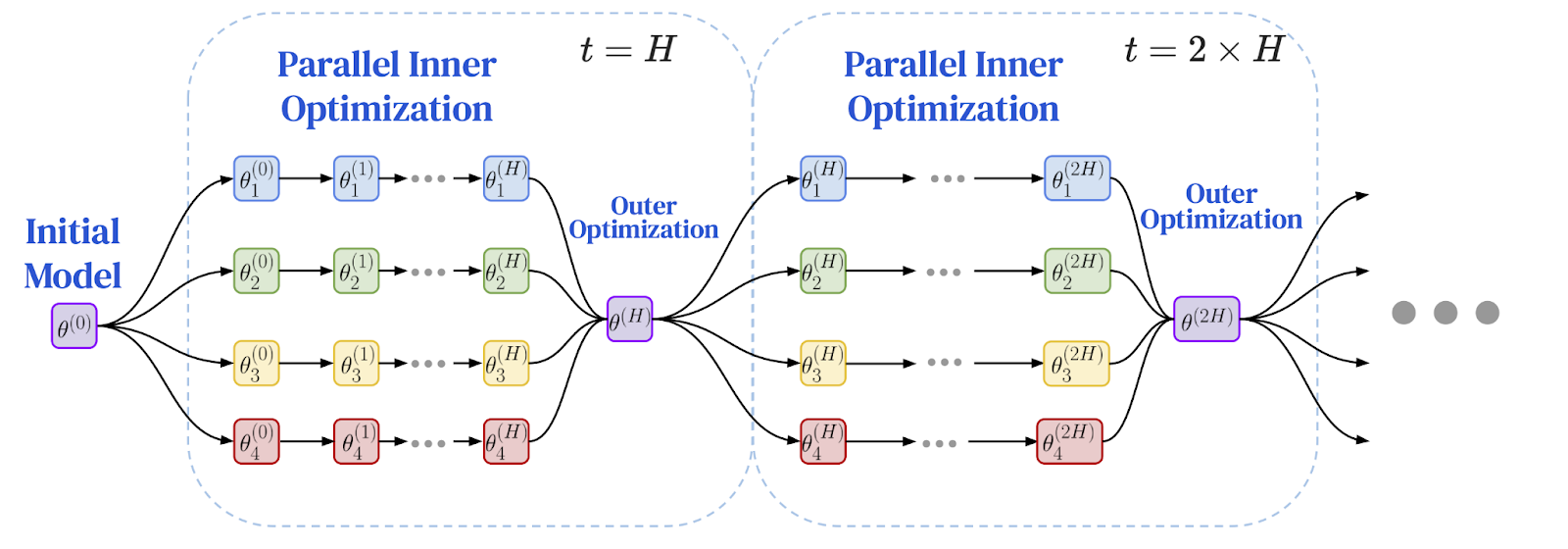
이미지 출처: Charles, Z. 외 (2025). "소통 효율적인 언어 모델 학습의 신뢰성 있고 견고한 확장: DiLoCo를 위한 확장 법칙." arXiv:2503.09799
4. 획기적인 성과: DiLoCo는 규모 확장 가능성을 입증했습니다.
그 해답은 DiLoCo(Distributed Low Communication) 알고리즘에서 찾을 수 있는데, 이는 대규모 언어 모델에 대한 연합 최적화의 실질적인 타당성을 보여줍니다. DiLoCo는 느린 네트워크에서 최신 Transformer 모델을 학습하기 위해 특별히 세심하게 조정된 방식을 제공합니다.
- 내부 최적화: 대규모 언어 모델을 위한 최첨단 최적화 프로그램인 AdamW는 각 작업자 노드에서 여러 개의 로컬 학습 단계를 실행합니다.
- 외부 최적화: Nesterov Momentum은 드물게 발생하는 글로벌 업데이트를 처리하는 강력하고 이해하기 쉬운 알고리즘입니다.
초기 실험 결과, DiLoCo는 노드 간 통신을 최대 500배까지 줄이는 동시에 완전 동기화 데이터 센터 학습 성능과 맞먹는 성능을 보이는 것으로 나타났습니다. 이는 인터넷을 통해 대규모 모델을 학습하는 것이 가능하다는 것을 보여줍니다.
이 획기적인 발전은 빠르게 주목을 받았습니다. 오픈소스 구현체인 OpenDiLoCo는 원래 결과를 재현하고 Hivemind 라이브러리를 사용하여 알고리즘을 진정한 P2P(peer-to-peer) 프레임워크에 통합함으로써 기술의 접근성을 높였습니다. 이러한 추진력은 궁극적으로 PrimeIntellect , Nous Research , FlowerLabs 와 같은 기관들의 대규모 사전 학습 노력으로 이어졌으며, 저통신 알고리즘을 사용하여 인터넷을 통해 수십억 개의 매개변수를 가진 모델의 성공적인 사전 학습을 입증했습니다. 이러한 선구적인 노력 덕분에 DiLoCo 방식의 학습은 유망한 연구 논문에서 중앙 집중식 제공업체 외부에서 기반 모델을 구축하는 검증된 방법으로 탈바꿈했습니다.
5. 프런티어 탐험: 첨단 기술과 미래 연구
DiLoCo의 성공은 효율성과 규모를 더욱 개선하는 데 중점을 둔 새로운 연구 흐름을 촉진했습니다. 이 방법의 발전에 있어 핵심 단계는 DiLoCo 스케일링 법칙 의 개발이었는데, 이는 DiLoCo의 성능이 모델 크기에 따라 예측 가능하고 견고하게 확장된다는 것을 보여줍니다. 이러한 스케일링 법칙은 모델이 커짐에 따라 잘 조정된 DiLoCo가 고정된 계산 예산으로 기존 데이터 병렬 학습보다 훨씬 적은 대역폭을 사용하면서도 더 나은 성능을 낼 수 있음을 예측합니다.
1,000억 개가 넘는 매개변수를 가진 모델을 처리하기 위해 연구진은 DiLoCo 설계를 확장하여 듀얼 옵티마이저 방식과 파이프라인 병렬 처리를 결합한 DiLoCoX 와 같은 기술을 적용했습니다. DiLoCoX를 사용하면 표준 1Gbps 네트워크에서 1,070억 개의 매개변수를 가진 모델을 사전 학습할 수 있습니다. 추가적인 개선 사항으로는 스트리밍 DiLoCo (통신과 연산을 중첩하여 네트워크 지연 시간을 숨김)와 비동기 방식 (단일 느린 노드가 전체 시스템의 병목 현상을 발생시키지 않도록 방지)이 있습니다.
알고리즘의 핵심에서도 혁신이 일어나고 있습니다. Muon과 같은 새로운 내부 최적화 프로그램에 대한 연구는 MuLoCo 로 이어졌습니다. MuLoCo는 모델 업데이트를 성능 손실 없이 2비트로 압축하여 데이터 전송을 8배 줄이는 변형입니다. 아마도 가장 야심찬 연구 방향은 인터넷을 통한 모델 병렬 처리일 것입니다. 이는 모델 자체를 여러 머신에 분할하는 것을 포함합니다. SWARM 병렬 처리 와 같은 이 분야의 초기 연구에서는 느린 네트워크로 연결된 이기종 및 신뢰할 수 없는 디바이스에 모델 계층을 분산하기 위한 내결함성 방법을 개발했습니다. 이러한 개념을 바탕으로 Pluralis Research 와 같은 팀은 지리적으로 다양한 GPU에 여러 계층이 호스팅되는 수십억 개의 매개변수 모델을 학습할 가능성을 보여주었고, 표준 인터넷 연결로만 연결된 분산형 소비자 하드웨어에서 모델을 학습할 수 있는 문을 열었습니다.
6. 신뢰의 도전: 개방형 네트워크의 거버넌스
훈련이 통제된 데이터 센터에서 개방적이고 허가 없는 네트워크로 이동함에 따라, 근본적인 문제, 즉 신뢰 문제가 발생합니다. 중앙 기관이 없는 진정한 분산 시스템에서, 참여자들은 다른 사람들로부터 받은 업데이트의 신뢰성을 어떻게 확인할 수 있을까요? 악의적인 행위자가 모델을 오염시키거나, 게으른 행위자가 완료하지 않은 작업에 대한 보상을 요구하는 것을 어떻게 방지할 수 있을까요? 이러한 거버넌스 문제가 마지막 장애물입니다.
한 가지 방어선은 비잔틴 장애 허용(Byzantine fault tolerance) 입니다. 이는 분산 컴퓨팅의 개념으로, 일부 참여자가 실패하거나 악의적인 행위를 하더라도 작동할 수 있는 시스템을 설계하는 것을 목표로 합니다. 중앙 집중식 시스템에서는 서버가 강력한 집계 규칙을 적용하여 악성 업데이트를 삭제할 수 있습니다. 하지만 중앙 집계자가 없는 P2P 환경에서는 이러한 방식을 구현하기가 더 어렵습니다. 대신, 각 정직한 노드는 이웃 노드의 업데이트를 평가하여 어떤 업데이트를 신뢰할지, 어떤 업데이트를 삭제할지 결정해야 합니다.
또 다른 접근법은 신뢰를 검증으로 대체하는 암호화 기술을 포함합니다. 초기 아이디어 중 하나는 학습 증명 (Proof-of-Learning)으로, 참여자가 필요한 연산을 투자했음을 증명하기 위해 훈련 체크포인트를 기록하도록 제안합니다. 영지식 증명(ZKP)과 같은 다른 기술은 작업자 노드가 기본 데이터를 공개하지 않고 필요한 훈련 단계를 올바르게 수행했음을 증명할 수 있도록 합니다. 하지만 현재의 높은 연산 비용은 오늘날 대규모 인프라 모델의 훈련 검증에 여전히 어려운 문제로 남아 있습니다.
전망: 새로운 AI 패러다임의 새벽
폐쇄형 데이터 센터에서 개방형 인터넷으로의 전환은 AI 개발 방식에 있어 중대한 변화를 의미합니다. 우리는 중앙 집중식 학습의 물리적 한계에서 출발했는데, 그 과정에서는 값비싼 공동 배치 하드웨어에 대한 접근성에 따라 학습이 진행되었습니다. 이로 인해 통신 병목 현상이 발생했고, 분산 네트워크에서 대규모 모델을 학습하는 것이 불가능해졌습니다. 그러나 이 장벽은 더 빠른 케이블이 아니라, 더 효율적인 알고리즘에 의해 무너졌습니다.
연합 최적화에 기반하고 DiLoCo를 통해 구현된 이러한 알고리즘 변화는 통신 빈도를 줄이는 것이 핵심임을 보여줍니다. 이러한 획기적인 발전은 스케일링 법칙 확립, 통신 중첩, 새로운 옵티마이저 탐색, 심지어 인터넷을 통한 모델 자체의 병렬화까지 다양한 기술을 통해 빠르게 발전하고 있습니다. 다양한 연구자와 기업 생태계를 통해 수십억 개의 매개변수를 가진 모델을 성공적으로 사전 학습시킨 것은 이 새로운 패러다임의 힘을 입증합니다.
강력한 방어 체계와 암호화 검증을 통해 신뢰 문제가 해결됨에 따라, 그 길은 점점 명확해지고 있습니다. 분산형 학습은 단순한 엔지니어링 솔루션에서 더욱 개방적이고 협력적이며 접근성이 뛰어난 AI 미래의 근간으로 진화하고 있습니다. 이는 강력한 모델을 구축하는 능력이 더 이상 소수의 거대 기술 기업에만 국한되지 않고 전 세계적으로 분산되어 모든 사람의 집단적 컴퓨팅 능력과 지혜를 발휘하는 세상을 예고합니다.
참고문헌
McMahan, HB 외 (2017). 분산형 데이터를 활용한 딥러닝 네트워크의 통신 효율적 학습 . 인공지능 및 통계 국제 학술대회(AISTATS).
Reddi, S. 외 (2021). 적응형 연합 최적화 . 학습 표현 국제 학술 대회(ICLR).
Jia, H. 외 (2021). 학습 증명: 정의와 실제 . IEEE 보안 및 개인정보보호 심포지엄.
Ryabinin, Max 외 (2023). 군집 병렬 처리: 대규모 모델 학습은 놀라울 정도로 통신 효율이 높을 수 있다 . 국제 기계 학습 학회(ICML).
Douillard, A. 외 (2023). DiLoCo: 언어 모델의 분산형 저소통 학습 .
Jaghouar, S., Ong, JM, & Hagemann, J. (2024). OpenDiLoCo: 전 세계적으로 분산된 낮은 의사소통 교육을 위한 오픈 소스 프레임워크 .
Jaghouar, S. 외 (2024). 기초 모델의 분산 학습: INTELLECT-1을 활용한 사례 연구 .
Liu, B. 외 (2024). 언어 모델링을 위한 비동기 로컬 SGD 훈련 .
Charles, Z. 외 (2025). 의사소통에 효율적인 언어 모델 학습을 위한 안정적이고 견고한 스케일링: DiLoCo 스케일링 법칙 .
Douillard, A. 외 (2025). 중복 통신을 통한 DiLoCo 스트리밍: 분산형 무료 점심을 향하여 .
프시케 팀. (2025). AI 민주화: 프시케 네트워크 아키텍처 . Nous Research 블로그.
Qi, J. 외 (2025). DiLoCoX: 분산형 클러스터를 위한 저통신 대규모 훈련 프레임워크 .
Sani, L. 외 (2025). Photon: 연합 LLM 사전 훈련 . 기계 학습 및 시스템 학회(MLSys) 논문집.
Thérien, B. 외 (2025). MuLoCo: Muon은 DiLoCo를 위한 실용적인 내부 최적화 도구입니다 .
Long, A. 외 (2025). 프로토콜 모델: 통신 효율적 모델 병렬 처리를 통한 분산형 학습 확장 .