
분산형 AI 추론의 핵심 과제: 전체 네트워크에 "부정행위"를 하지 않는다는 것을 어떻게 증명할 것인가?
- 核心观点:去中心化LLM需验证节点模型真实性。
- 关键要素:
- GPU非确定性导致输出比较困难。
- 经济机制惩罚作弊,声誉归零。
- 三种验证方案防范模型替换攻击。
- 市场影响:提升去中心化AI网络可信度。
- 时效性标注:中期影响。
Gonka 프로토콜의 공동 창립자 Anastasia Matveeva의 원본 기사
이전 글 에서는 LLM을 활용한 분산 추론에서 보안과 성능 간의 근본적인 갈등을 살펴보았습니다. 오늘은 그 약속을 이행하고 핵심 질문을 깊이 있게 살펴보겠습니다. 개방형 네트워크에서 노드가 주장하는 모델을 실제로 실행하고 있는지 어떻게 확인할 수 있을까요?
01. 검증이 왜 이렇게 어려운가요?
검증 메커니즘을 이해하기 위해 추론을 수행할 때 Transformer의 내부 프로세스를 살펴보겠습니다. 입력 토큰이 처리됨에 따라 모델의 최종 계층은 어휘집의 각 토큰에 대한 정규화되지 않은 원시 점수인 로짓(logit)을 생성합니다. 이 로짓은 소프트맥스 함수를 사용하여 확률로 변환되어 모든 가능한 다음 토큰에 대한 확률 분포를 형성합니다. 각 생성 단계에서 이 분포에서 토큰을 샘플링하여 시퀀스를 계속 생성합니다.
잠재적인 공격 벡터와 구체적인 검증 구현에 대해 알아보기 전에 먼저 검증 자체가 왜 어려운지 이해해야 합니다.
문제의 근원은 GPU의 비결정성에 있습니다. 부동 소수점 정밀도와 같은 문제로 인해 동일한 모델과 입력을 사용하더라도 하드웨어나 기기에 따라 출력이 약간씩 다를 수 있습니다.
GPU의 비결정성으로 인해 출력 토큰 시퀀스를 직접 비교하는 것은 의미가 없습니다. 따라서 Transformer의 내부 계산 과정을 살펴볼 필요가 있습니다. 자연스러운 선택은 출력 계층, 즉 모델 어휘에 대한 확률 분포를 비교하는 것입니다. 동일한 시퀀스의 확률 분포를 비교하고 있음을 보장하기 위해, 검증 절차에서는 검증자가 실행기에서 생성된 정확히 동일한 토큰 시퀀스를 완전히 재현한 다음 이러한 확률 분포를 단계별로 비교해야 합니다. 이 과정을 통해 모델의 진위를 증명하는 검증 인증서가 생성됩니다.
하지만 확률적 행동은 미묘한 균형을 요구합니다. 끈질긴 부정행위자를 처벌하는 동시에, 운이 없고 낮은 확률의 결과를 내는 정직한 노드에 의도치 않게 피해를 입히지 않도록 해야 합니다. 임계값을 너무 높게 설정하면 좋은 플레이어를 실수로 죽일 수 있고, 너무 낮게 설정하면 나쁜 플레이어를 처벌에서 제외할 수 있습니다.
02. 부정행위의 경제학: 이점과 위험
잠재적 이점: 엄청난 유혹
가장 직접적인 공격은 "모델 교체"입니다. Qwen3-32B 모델에 네트워크 구축에 막대한 컴퓨팅 파워가 필요하다고 가정할 때, 합리적인 노드라면 "훨씬 작은 Qwen2.5-3B 모델을 몰래 실행해서 절약된 컴퓨팅 파워의 차액을 챙기면 어떨까?"라고 생각할 수도 있습니다.
30억 개의 매개변수 모델을 320억 개의 매개변수 모델로 위장하면 컴퓨팅 파워 비용을 10배나 절감할 수 있습니다. 검증 시스템을 속일 수 있다면, 저렴한 컴퓨팅 파워로 결과를 제공하면서 고품질 컴퓨팅 파워에 대한 대가를 받는 것과 마찬가지입니다.
더욱 정교한 공격자는 양자화 기법을 사용하여 FP8 정밀도로 실행한다고 주장하지만 실제로는 INT4 양자화를 사용할 수 있습니다. 성능 차이는 크지 않을 수 있지만, 비용 절감 효과는 상당할 수 있으며, 출력 결과도 간단한 검증을 통과할 만큼 유사할 수 있습니다.
더 복잡한 수준에서는 사전 채우기 공격(pre-filling attack)도 있습니다. 이 공격은 공격자가 마치 네트워크가 예상하는 전체 모델에서 생성된 것처럼 값싼 모델의 출력에 대한 증명을 생성할 수 있도록 합니다. 작동 방식은 다음과 같습니다.
예를 들어, 특정 매개변수 집합을 사용하여 Qwen3-235B를 배포하기 위해 체인에서 합의가 이루어집니다.
1. 실행자는 Qwen2.5-3B를 사용하여 `[안녕하세요, 안녕하세요, 안녕하세요]` 시퀀스를 생성합니다.
2. 실행자는 동일한 토큰에 대해 단일 전방 패스를 통해 Qwen3-235B 증명을 계산합니다. `[{Hello: 0.9, Hi: 0.05, Hey: 0.05}, ...]`.
3. 집행자는 Qwen3-235B의 확률을 증거로 제출하며, 추론이 Qwen3-235B에서 나왔다고 주장합니다.
이 경우 확률은 올바른 모델에서 도출되므로 타당해 보이지만, 실제 시퀀스 생성 과정은 훨씬 저렴합니다. 이론적으로 전체 모델도 작은 모델과 동일한 출력을 생성할 수 있으므로, 검증 관점에서는 결과가 완전히 타당해 보일 수 있습니다.
잠재적 손실: 더 비쌈
시스템을 속이면 상당한 이득을 얻을 수 있지만, 잠재적 손실 또한 그만큼 큽니다. 부정행위자에게 진짜 과제는 단 한 번의 검증을 통과하는 것이 아니라, 장기간에 걸쳐 체계적으로 탐지를 피하는 것입니다. 그렇게 함으로써 계산에 대한 "할인"이 네트워크가 부과할 수 있는 페널티를 초과하게 됩니다.
Gonka 네트워크에서 우리는 정교한 경제 억제 메커니즘을 설계했습니다.
- 모든 사람이 검증자입니다. 각 노드는 가중치에 따라 네트워크 추론의 일부를 검증합니다.
- 평판 시스템: 새로운 노드의 평판 값은 0이며, 모든 추론은 검증됩니다. 지속적인 정직한 참여를 통해 평판은 증가하고 검증 빈도는 1%로 감소할 수 있습니다.
- 페널티 메커니즘: 부정행위가 적발되면 평판이 0으로 초기화되고, 이를 회복하는 데 약 30일이 소요됩니다.
- 에포크 정산: 약 24시간의 에포크 내에 통계적으로 유의미한 횟수로 부정행위가 적발될 경우, 해당 에포크 전체에 대한 모든 보상이 몰수됩니다.
즉, 컴퓨팅 파워의 50%를 절약하려는 부정행위자는 결국 얻은 이익의 100%를 잃게 될 수 있습니다. 이러한 "손실 대비 이익" 위험은 부정행위를 경제적으로 무익하게 만듭니다. 검증 메커니즘을 통해 우리가 해결하고자 하는 문제는 모든 의심스러운 추론을 포착하는 것이 아니라, 정직한 참여자의 평판을 손상시키지 않으면서도 충분히 높은 확률로 부정행위자를 지속적으로 포착할 수 있는 선을 긋는 것입니다.
03. 사기꾼을 잡는 방법? 세 가지 검증 방법
그렇다면 이러한 공격을 어떻게 포착할 수 있을까요? 문제는 두 부분으로 나눌 수 있습니다. 1) 증명의 분포가 주장된 모델에서 생성된 분포와 유사한지 확인하는 것, 2) 출력 텍스트가 제출된 증명을 기반으로 실제로 생성되었는지 확인하는 것입니다.
옵션 1: 확률 분포 비교(핵심 기초)
실행자가 추론 출력(예: `[Hello, world, how, are, you]`)을 생성하면, 최종 출력과 출력 시퀀스의 각 위치에 대한 상위 K개의 확률(예: 첫 번째 위치에 대한 `[{Hello: 0.9, Hi: 0.05, Hey: 0.05}, ...]` 등)을 포함하는 검증 인증서를 기록합니다. 그런 다음 검증자는 모델이 정확히 동일한 토큰 시퀀스를 따르도록 강제하고 각 위치에서 확률 간의 정규화된 거리 d_i를 계산합니다.
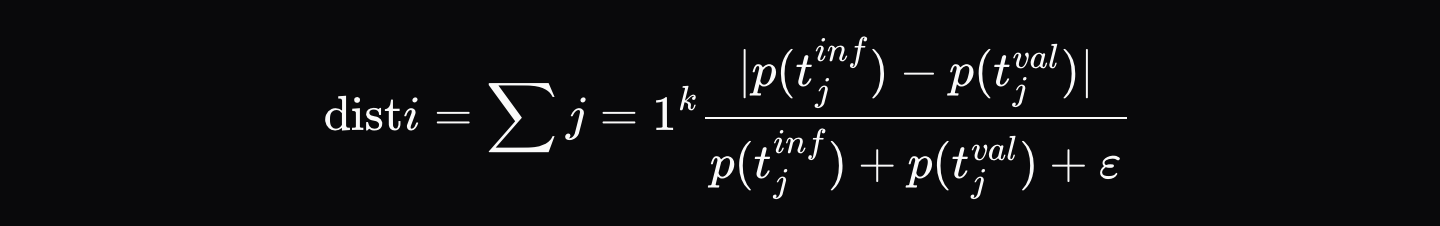
여기서 \( p_{\text{artifact},ij} \)는 추론 저장소의 해당 위치에서 j번째로 가능성이 높은 토큰의 확률이고, \( p_{\text{validator},ij} \)는 검증자 분포에서 동일한 토큰의 확률입니다.
최종 거리 측정 기준은 각 토큰의 거리 합계의 평균입니다.
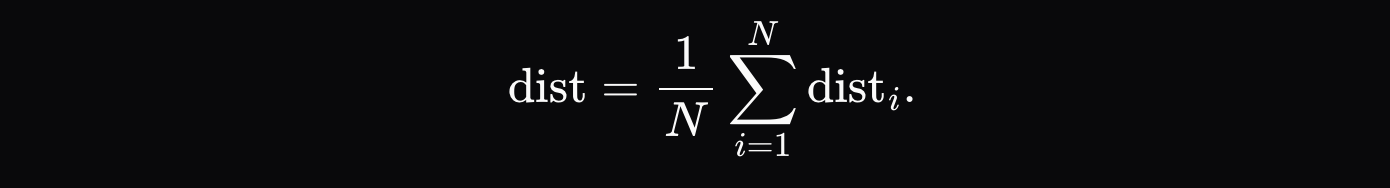
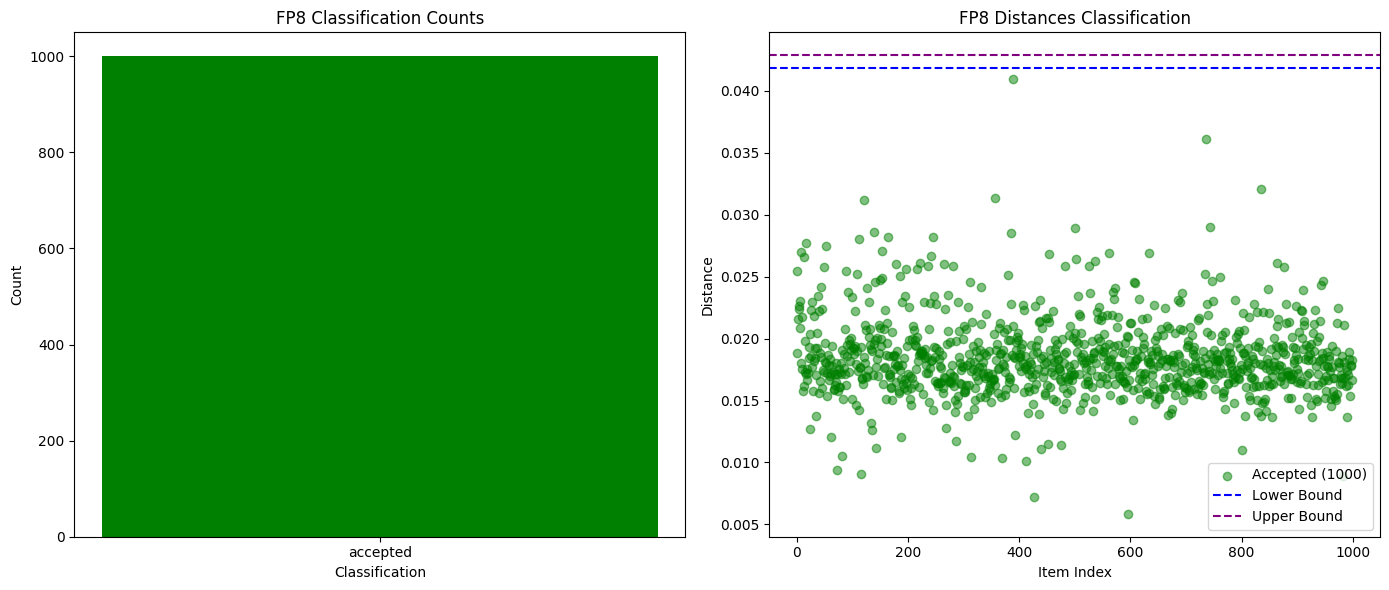
상위 K개의 확률을 비교하는 것만으로도 완전히 다른 모델, 심지어 동일 모델의 다른 양자화 버전을 포착하는 데 충분했습니다. 아래 차트에서 볼 수 있듯이, Qwen3-32B FP8과 INT4 양자화 버전을 비교 테스트한 결과, 오탐지율이 0%인 99%의 사기 탐지율을 달성했습니다. 다른 모델의 확률 분포도 충분히 달랐기 때문에 단일 에포크 내에서 부정행위를 쉽게 탐지할 수 있었고, 정직한 참여자는 안전하게 보호되었습니다.
다음 그림은 Qwen3-32B FP8(정직)과 INT4 양자화(사기)에 대한 성공 및 실패 검증 수를 비교합니다.
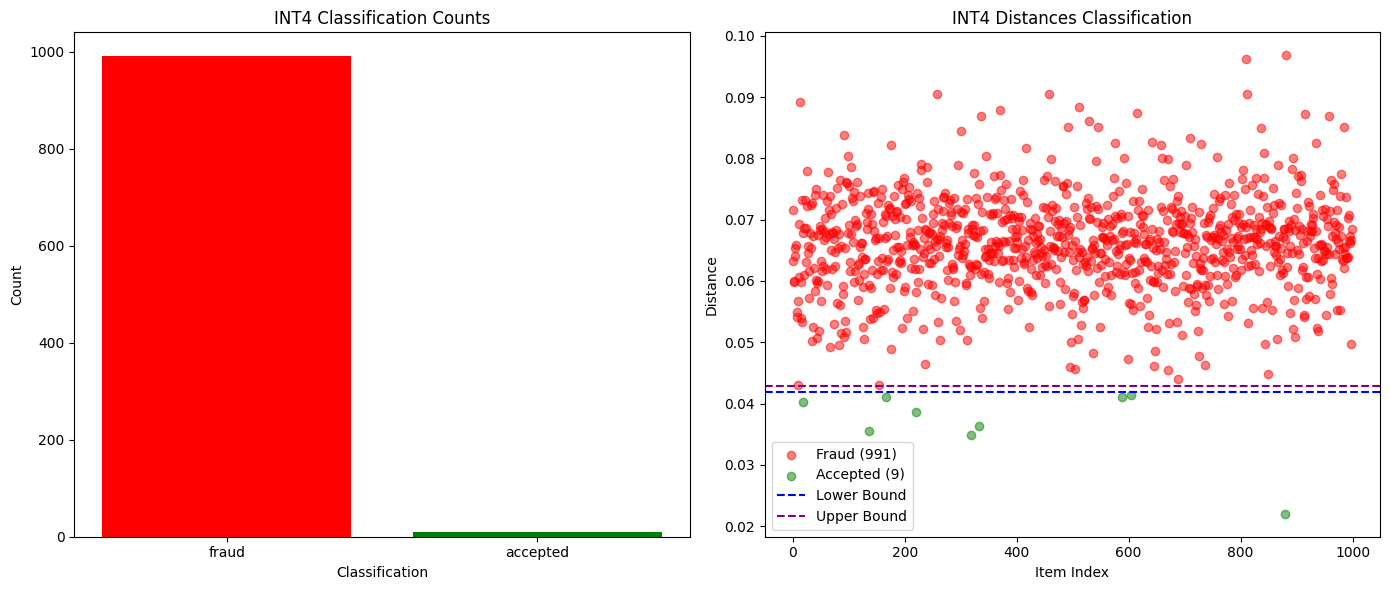
다음 그림은 시퀀스 길이에 따른 Qwen3-32B FP8(정직) 대 INT4 양자화(사기)의 확률 분포 거리 변화를 보여줍니다.
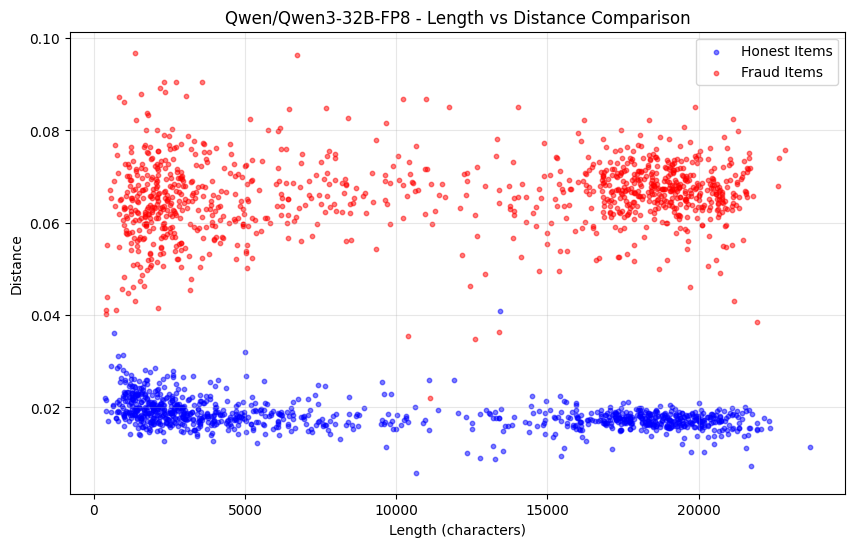
그러나 이 접근법의 단점은 사전 채우기 공격(prefilling attack)을 차단하지 못한다는 것입니다. 확률이 전체 모델의 분포와 일치하더라도 시퀀스가 더 작은 모델을 통해 생성된 경우, 이러한 상황을 포착할 수 있는 몇 가지 추가 방법이 있습니다.
솔루션 2: 혼란 탐지(사전 채우기 공격 방어)
증거가 올바른 모델에서 나왔는지 확인하는 것 외에도, 출력 텍스트가 증거의 확률 분포에서 나왔을 가능성이 "있는지"도 확인합니다.
시퀀스가 다른 모델에 의해 생성된 경우, 해당 모델의 확률 분포 대비 복잡도가 비정상적으로 높아질 것입니다. 테스트 결과, Qwen2.5-7B와 Qwen2.5-3B 사전 입력 공격 간의 복잡도 차이는 상당했습니다.
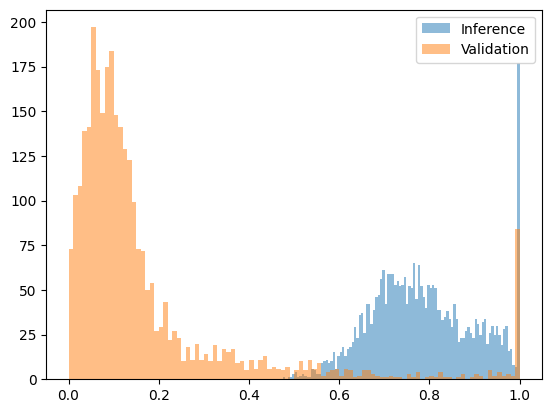
사전 채우기 공격을 잡는 가장 직관적인 방법은 복잡성을 확인하는 것입니다. 주장된 모델에서 증명이 생성되었는지 확인하는 것 외에도 출력 텍스트가 제출된 배포에서 생성될 가능성이 있는지도 확인할 수 있습니다.
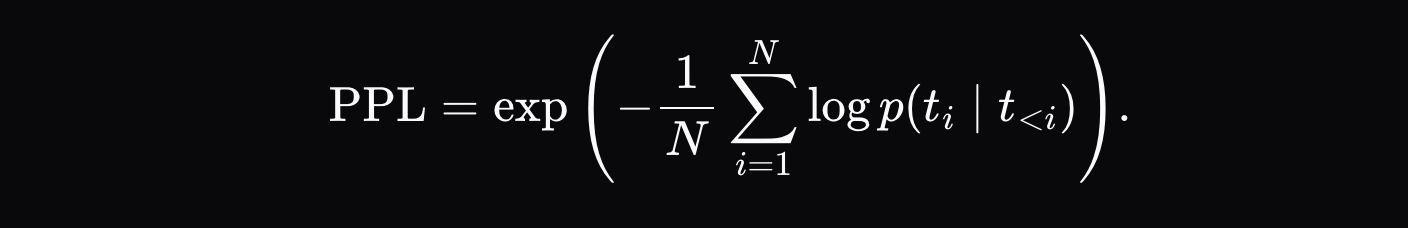
복잡도가 너무 높으면 시퀀스가 다른 모델에서 생성되었을 가능성이 높음을 나타냅니다. 이 접근법은 상당히 다른 모델을 사용하는 공격을 방어하는 데 효과적입니다. Qwen2.5-3B에서 생성되었지만 Qwen2.5-7B에서 생성되었다고 주장하는 시퀀스를 테스트했을 때, 복잡도 차이가 충분히 커서 명확한 임계값을 설정할 수 있었습니다. 아래 그림은 [0, 1] 구간에 맞춰 변환된 복잡도 함수를 보여줍니다. 여기서 7B 모델의 출력은 대부분 0.2 미만인 반면, 사전 채워진 공격(7B 모델 확률을 갖는 3B 모델 출력)의 출력은 모두 0.4 이상입니다.
다음 그림은 Qwen2.5-7B(정직) 대 Qwen2.5-3B 사전 채워진 공격(사기)의 변환 후의 혼란 함수를 보여줍니다.
그러나 퍼플렉시티 검출은 유사한 모델과 동일 모델의 서로 다른 양자화 버전을 비교할 때 한계가 있습니다. 예를 들어, Qwen2.5-7B Base의 w8a16 양자화 버전과 w8a8 양자화 버전을 비교할 때 유의미한 차이가 나타나지 않았습니다.
다음 그림은 Qwen2.5-7B w8a16(정직) 대 w8a8 양자화(사기) 변환 후의 복잡도 함수를 보여줍니다.
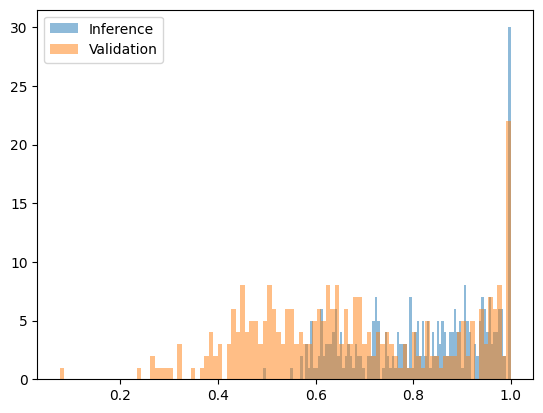
다행히도, 유사 모델을 공격에 사용하는 것은 일반적으로 경제적으로 타당하지 않습니다. 주장하는 모델의 70~90%에 해당하는 비용이 드는 모델을 실행하고, 실제 모델에 대한 점수 계산까지 더한다면, 실제 모델만 실행하는 것보다 실제로 더 많은 컴퓨팅 리소스를 소모할 수 있습니다.
정직한 참여자가 생성한 단일 저확률 출력은 해당 참여자의 평판을 크게 떨어뜨리지 않는다는 점에 유의해야 합니다. 이 저확률 출력이 해당 참여자에게 지속적이지 않은 경우, 즉 무작위 통계적 이상치일 경우, 해당 참여자는 에포크 종료 시 전체 보상을 받게 됩니다.
솔루션 3: RNG 시드 바인딩(결정적 솔루션)
가장 근본적인 해결책은 출력 시퀀스를 난수 생성기 시드에 연결하는 것입니다.
실행자는 요청에서 파생된 결정론적 시드(예: `run_seed = SHA256(user_seed || inference_id_from_chain)`)를 사용하여 RNG를 초기화합니다. 검증 증거에는 이 시드와 확률 분포가 포함됩니다.
검증자는 동일한 시드를 사용하여 시퀀스가 실제로 주장된 모델의 확률 분포에서 나온 것인지, 동일한 출력이 재생성되는지 검증합니다. 이를 통해 결정론적인 "예/아니요" 답변을 제공하고, 사전 채우기 공격을 완전히 제거하며, 검증 비용은 전체 추론보다 훨씬 낮습니다.
04. 전망: 분산형 AI 미래를 향하여
우리는 분산형 AI의 미래에 대한 확고한 믿음을 바탕으로 이러한 관행과 성찰을 공유합니다. AI 모델이 우리 삶에 점점 더 깊이 스며들면서, 모델 출력을 특정 매개변수에 연결해야 할 필요성은 더욱 커질 것입니다.
Gonka 네트워크가 선택한 검증 방식은 실제로 실행 가능한 것으로 입증되었으며, 해당 구성 요소는 AI 추론의 진위성을 검증해야 하는 다른 시나리오에서도 재사용될 수 있습니다.
탈중앙화 AI는 단순한 기술적 진화가 아니라 생산 관계의 변혁입니다. 개방된 환경에서 알고리즘과 경제적 메커니즘을 통해 근본적인 신뢰 문제를 해결하고자 합니다. 앞으로의 길은 멀지만, 우리는 이미 확고한 진전을 이루었습니다.


