
분산형 AI 추론에 대한 심층 분석: 보안과 성능의 균형을 맞추는 방법
- 核心观点:去中心化AI推理可打破算力垄断。
- 关键要素:
- 利用闲置GPU算力降低AI成本。
- 区块链记录确保推理可验证。
- 声誉机制平衡安全与性能。
- 市场影响:挑战中心化云服务商定价权。
- 时效性标注:中期影响。
원저자: Anastasia Matveeva - Gonka Protocol 공동 창립자
목차
- 진정한 "분권화"
- 블록체인과 추론 증명
- 실제로 어떻게 작동하는지
- 보안 및 성능 균형
- 공간 최적화
Gonka를 개발하기 시작했을 때, 우리는 다음과 같은 비전을 가지고 있었습니다. 누구나 AI 추론을 실행하고 그에 대한 대가를 받을 수 있다면 어떨까요? 값비싼 중앙 집중식 공급업체에 의존하는 대신, 사용하지 않는 컴퓨팅 파워를 모두 활용할 수 있다면 어떨까요?
현재 AI 환경은 소수의 대형 클라우드 제공업체가 주도하고 있습니다. AWS, Azure, Google Cloud가 전 세계 AI 인프라의 대부분을 장악하고 있습니다. 이러한 중앙 집중화는 우리 중 많은 사람들이 직접 경험한 심각한 문제를 야기합니다. 소수의 기업이 AI 인프라를 통제한다는 것은 그들이 임의로 가격을 책정하고, 바람직하지 않은 애플리케이션을 검열하며, 단일 장애 지점을 만들 수 있음을 의미합니다. OpenAI의 API가 다운되었을 때 수천 개의 애플리케이션이 작동 중단되었습니다. AWS에 장애가 발생했을 때 인터넷의 절반이 작동을 멈췄습니다.
"효율적인" 최첨단 기술조차도 저렴하지 않습니다. Anthropic은 이전에 Claude 3.5 Sonnet 학습 비용이 "수천만 달러"라고 밝혔으며, Claude Sonnet 4는 현재 일반에 출시되었지만 아직 학습 비용은 공개하지 않았습니다. Anthropic의 CEO인 Dario Amodei는 이전에 최첨단 모델의 학습 비용이 10억 달러에 육박할 것이며, 향후 추가될 모델은 수십억 달러에 달할 것이라고 예측했습니다. 이러한 모델에서 추론을 실행하는 데도 비용이 많이 듭니다. 적당히 활성화된 애플리케이션의 경우, 단일 LLM 추론 실행 비용은 하루에 수백 달러에서 수천 달러에 달할 수 있습니다.
한편, 세상에는 엄청난 양의 컴퓨팅 파워가 유휴 상태이거나 무의미하게 사용되고 있습니다. 비트코인 채굴자들이 쓸모없는 해시 퍼즐을 풀기 위해 전기를 소모하거나, 데이터 센터가 용량 부족으로 운영되는 상황을 생각해 보세요. 이러한 컴퓨팅 파워를 AI 추론처럼 진정으로 가치 있는 분야에 사용할 수 있다면 어떨까요?
분산형 접근 방식은 컴퓨팅 파워를 통합하여 자본 장벽을 낮추고 단일 공급업체의 병목 현상을 줄일 수 있습니다. 소수의 대기업에 의존하는 대신, GPU를 보유한 누구나 참여하고 AI 추론을 수행하는 대가로 수익을 얻을 수 있는 네트워크를 구축할 수 있습니다.
실행 가능한 분산형 솔루션을 구축하는 것은 엄청나게 복잡할 것이라는 것을 알고 있습니다. 합의 메커니즘부터 훈련 프로토콜, 자원 할당까지, 조율해야 할 부분이 셀 수 없이 많습니다. 오늘은 특정 LLM에 대한 추론 실행이라는 한 가지 측면에 집중해 보겠습니다. 얼마나 어려운 일일까요?
진정한 분권화란 무엇인가?
분산형 AI 추론에 대해 이야기할 때, 우리는 매우 구체적인 의미를 갖습니다. 단순히 여러 서버에서 AI 모델을 실행하는 것이 아니라, 누구나 참여하여 컴퓨팅 파워를 기여하고 정직한 작업에 대한 보상을 받을 수 있는 시스템을 구축하는 것입니다.
핵심 요건은 시스템이 신뢰할 수 있어야 한다는 것입니다. 즉, 시스템을 제대로 운영하기 위해 특정 개인이나 회사를 신뢰할 필요가 없다는 뜻입니다. 인터넷상의 낯선 사람에게 AI 모델을 실행하게 한다면, 그들이 주장하는 대로 (적어도 충분히 높은 확률로) 실제로 실행된다는 암호화된 보장이 필요합니다.
이러한 신뢰 없는 요구 사항은 몇 가지 흥미로운 의미를 갖습니다. 첫째, 시스템이 검증 가능 해야 합니다. 즉, 주어진 출력을 생성하는 데 동일한 모델과 동일한 매개변수가 사용되었음을 증명할 수 있어야 합니다. 이는 수신하는 AI 응답의 적법성을 검증해야 하는 스마트 계약에 특히 중요합니다.
하지만 한 가지 문제가 있습니다. 검증을 더 많이 추가할수록 네트워크 전력이 검증에 소모되어 전체 시스템 속도가 느려집니다. 모든 사람을 완전히 신뢰한다면 검증 추론이 필요 없고 성능도 중앙 집중식 제공업체와 거의 동일합니다. 하지만 아무도 신뢰하지 않고 항상 모든 것을 검증한다면 시스템은 엄청나게 느려지고 중앙 집중식 솔루션과 경쟁력을 잃게 됩니다.
이것이 바로 우리가 해결하기 위해 노력해 온 핵심적인 모순입니다. 보안과 성능 간의 올바른 균형을 찾는 것입니다.
블록체인과 추론 증명
그렇다면 누군가가 올바른 모델과 매개변수를 실행했는지 실제로 어떻게 확인할 수 있을까요? 블록체인은 당연한 선택입니다. 블록체인 자체의 어려움은 있지만, 불변하는 이벤트 기록을 생성하는 가장 신뢰할 수 있는 방법으로 남아 있습니다.
기본 아이디어는 매우 간단합니다. 누군가 추론을 실행할 때 올바른 모델을 사용했다는 증거를 제시해야 합니다. 이 증거는 블록체인에 기록되어 누구나 확인할 수 있는 영구적이고 변조 불가능한 기록을 생성합니다.
문제는 블록체인이 느리다는 것입니다. 정말, 정말 느립니다. 추론의 모든 단계를 체인에 기록하려고 한다면, 엄청난 양의 데이터가 네트워크를 빠르게 마비시킬 것입니다. 이러한 제약은 Gonka 네트워크를 설계할 때 많은 결정을 내리는 데 영향을 미쳤습니다.
네트워크를 설계하고 분산 컴퓨팅을 고려할 때, 여러 가지 전략을 선택할 수 있습니다. 모델을 여러 노드에 분산할 수 있을까요, 아니면 전체 모델을 단일 노드에 유지할 수 있을까요? 주요 제약은 네트워크 대역폭과 블록체인 속도에서 비롯됩니다. 저희는 솔루션을 실현 가능하게 만들기 위해 전체 모델을 단일 노드에 배치하기로 했지만, 이는 향후 변경될 수 있습니다. 각 노드는 전체 모델을 실행하기에 충분한 컴퓨팅 파워와 메모리가 필요하므로 네트워크 참여에 대한 최소 요건이 있습니다. 하지만 동일한 노드에 속한 여러 GPU에 모델을 분산할 수 있으므로, 단일 노드의 제약 조건 내에서 어느 정도 유연성을 확보할 수 있습니다. 최적의 성능을 위해 텐서 및 파이프라인 병렬 처리 매개변수를 사용자 지정할 수 있는 vLLM을 사용합니다.
실제로 어떻게 작동하는지
따라서 각 노드가 완전한 모델을 호스팅하고 완전한 추론을 실행하여 실제 계산 과정에서 여러 머신 간의 조정이 필요 없도록 하는 데 동의했습니다. 블록체인은 기록 보관용으로만 사용됩니다. 추론 검증에 사용되는 거래 및 아티팩트만 기록합니다. 실제 계산은 오프체인에서 수행됩니다.
추론 요청을 네트워크 노드로 전달하는 단일 중앙 지점 없이 시스템을 분산화하고자 합니다. 실제로 각 참여자는 최소 두 개의 노드, 즉 네트워크 노드와 하나 이상의 추론(ML) 노드를 배치합니다. 네트워크 노드는 통신(블록체인에 연결하는 체인 노드와 사용자 요청을 관리하는 API 노드 포함)을 담당하며, ML 노드는 LLM 추론을 수행합니다.
추론 요청이 네트워크에 도착하면 API 노드 중 하나("전송 에이전트" 역할)에 도달하여 무작위로 "실행자"(다른 참여자의 ML 노드)를 선택합니다. 시간을 절약하고 실제 LLM 계산과 블록체인 로깅을 병렬화하기 위해, 전송 에이전트(TA)는 먼저 입력 요청을 실행자에게 전송하고 실행자의 ML 노드가 추론을 실행하는 동안 입력을 체인상에 기록합니다. 계산이 완료되면 실행자는 출력을 TA의 API 노드로 전송하고, 실행자의 자체 체인 노드는 검증 아티팩트를 체인상에 기록합니다. TA의 API 노드는 출력을 클라이언트로 다시 전송하고, 이 역시 체인상에 기록됩니다. 물론 이러한 기록은 여전히 전체 네트워크 대역폭 제약에 영향을 미칩니다.
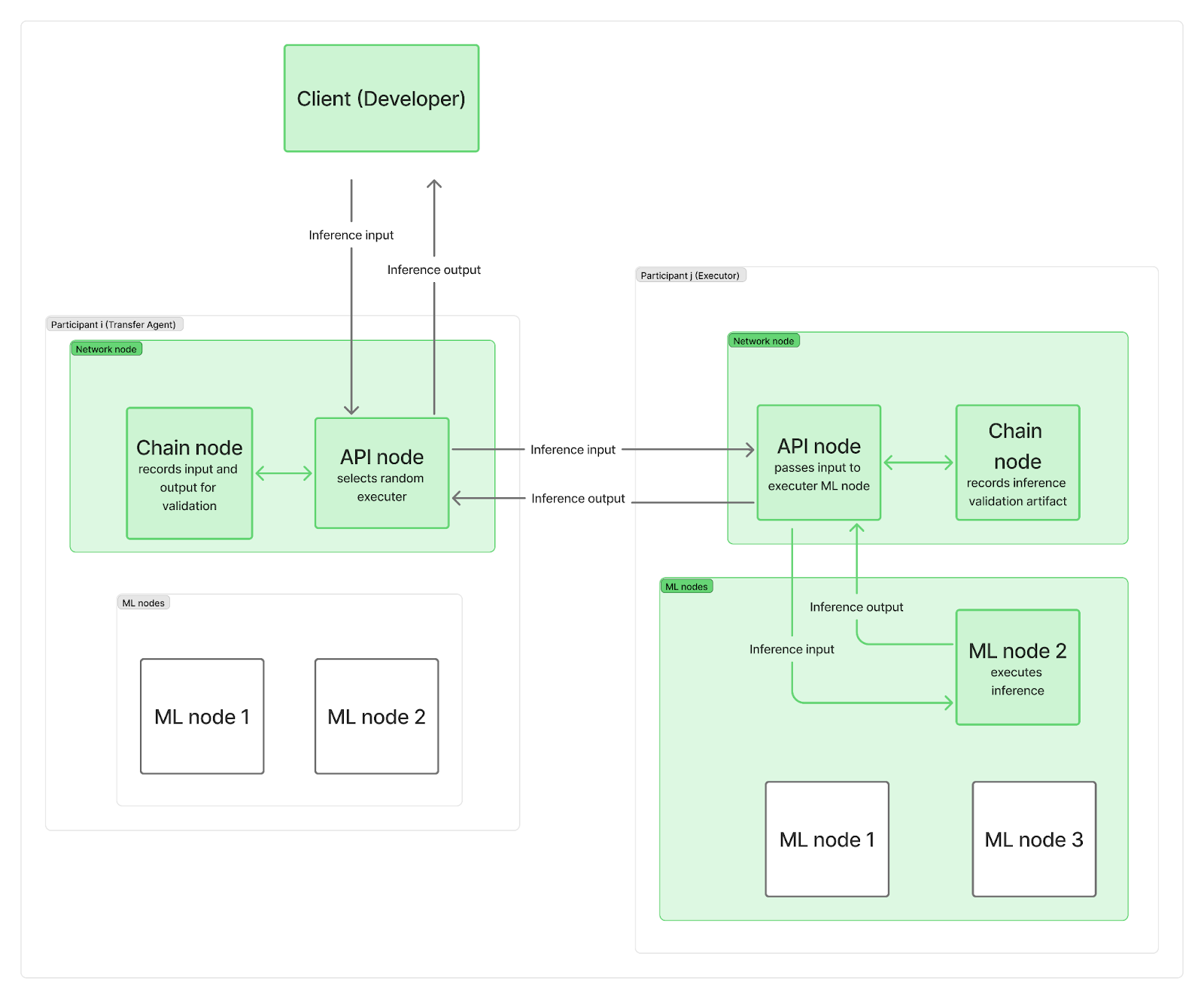
보시다시피, 블록체인 기록은 추론 계산 시작이나 최종 결과가 클라이언트에게 반환되는 데 걸리는 시간을 늦추지 않습니다. 추론이 정직하게 완료되었는지 여부에 대한 검증은 다른 추론과 병행하여 나중에 수행됩니다. 실행자가 부정행위를 저지른 것으로 적발되면 해당 에포크의 보상 전체를 잃게 되며, 클라이언트는 알림을 받고 환불을 받습니다.
마지막 질문은 다음과 같습니다. 유물에는 무엇이 포함되어 있습니까? 그리고 우리는 얼마나 자주 추론을 검증합니까?
보안 및 성능 균형
근본적인 문제는 보안과 성능이 서로 상충된다는 것입니다.
최고의 보안을 원한다면 모든 것을 검증해야 합니다. 하지만 느리고 비용이 많이 듭니다. 최고의 성능을 원한다면 모든 사람을 신뢰해야 합니다. 하지만 이는 위험하고 온갖 공격에 노출될 수 있습니다.
몇 번의 시행착오와 매개변수 조정 끝에, 저희는 이 두 가지 고려 사항의 균형을 맞추는 접근법을 찾아냈습니다. 검증의 양, 검증 시점, 그리고 검증 프로세스를 최대한 효율적으로 만드는 방법을 신중하게 조정해야 했습니다. 검증이 너무 많으면 시스템을 사용할 수 없게 되고, 검증이 너무 적으면 시스템이 불안정해집니다.
시스템을 가볍게 유지하는 것이 매우 중요합니다. 상위 k개의 다음 토큰 확률을 저장하여 이를 유지합니다. 이를 사용하여 주어진 출력이 실제로 주장된 모델과 매개변수에 의해 생성되었을 가능성을 측정하고, 더 작거나 양자화된 모델을 사용하는 등의 변조 시도를 충분한 신뢰도로 포착합니다. 추론 검증 절차의 구현에 대해서는 다른 게시물에서 더 자세히 설명하겠습니다.
동시에, 어떤 추론을 검증하고 어떤 추론을 검증하지 않을지는 어떻게 결정할까요? 저희는 평판 기반 접근 방식을 선택했습니다. 새로운 참여자가 네트워크에 가입하면 평판은 0이 되고, 추론의 100%는 최소 한 명의 참여자에 의해 검증되어야 합니다 . 문제가 발견되면 합의 메커니즘을 통해 추론 승인 여부가 결정되며, 그렇지 않으면 평판이 하락하여 네트워크에서 추방될 수 있습니다. 평판이 높아질수록 검증이 필요한 추론의 수는 감소하고, 결국에는 추론의 1%만이 검증을 위해 무작위로 선택될 수 있습니다. 이러한 역동적인 접근 방식을 통해 전체 검증 비율을 낮게 유지하면서 부정행위를 시도하는 참여자를 효과적으로 포착할 수 있습니다.
각 에포크가 끝날 때마다 참여자들은 네트워크 내 가중치에 비례하여 보상을 받습니다. 작업에도 가중치가 적용되므로 보상은 가중치와 완료된 작업량에 비례할 것으로 예상됩니다. 즉, 부정행위자를 즉시 적발하여 처벌할 필요가 없습니다. 보상을 분배하기 전에 에포크 내에 적발하는 것으로 충분합니다.
기술적 변수만큼이나 경제적 인센티브도 이러한 상충 관계를 좌우합니다. 부정행위를 값비싸게 만들고 정직한 참여를 수익성 있게 만듦으로써, 우리는 정직한 참여가 합리적인 선택이 되는 시스템을 만들 수 있습니다.
공간 최적화
수개월에 걸친 구축 및 테스트 끝에, 저희는 블록체인의 기록 보관 및 보안 이점을 결합하면서도 중앙 집중식 제공업체의 단일 추론 성능에 근접하는 시스템을 구축했습니다. 보안과 성능 사이의 근본적인 갈등은 실재하며, 완벽한 해결책은 없고 서로 상충되는 부분만 있을 뿐입니다.
네트워크가 확장됨에 따라, 완전한 탈중앙화 커뮤니티 제어를 유지하면서 중앙 집중식 제공업체와 경쟁할 수 있는 실질적인 기회가 있다고 생각합니다. 또한, 네트워크가 발전함에 따라 최적화의 여지도 상당히 있습니다. 이 과정에 대해 자세히 알아보고 싶으시다면 GitHub 및 관련 문서를 방문하시고, Discord에서 토론에 참여하시거나, 직접 네트워크에 참여해 주세요.
Gonka.ai 소개
Gonka는 효율적인 AI 컴퓨팅 파워를 제공하도록 설계된 탈중앙화 네트워크입니다. Gonka의 설계 목표는 글로벌 GPU 컴퓨팅 파워를 최대한 활용하여 의미 있는 AI 워크로드를 완료하는 것입니다. 중앙화된 게이트키퍼를 제거함으로써 Gonka는 개발자와 연구자에게 컴퓨팅 리소스에 대한 허가 없는 접근을 제공하는 동시에 모든 참여자에게 GNK 토큰을 보상으로 제공합니다.
Gonka는 미국 AI 개발사 Product Science Inc.에서 인큐베이팅되었습니다. 웹 2 업계 베테랑이자 Snap Inc.의 전 핵심 제품 책임자였던 Libermans 형제가 설립한 이 회사는 2023년 OpenAI 투자자 Coatue Management, Solana 투자자 Slow Ventures, K5, Insight, Benchmark Partners 등의 투자자들로부터 1,800만 달러를 성공적으로 유치했습니다. 이 프로젝트의 초기 참여자로는 6 Blocks, Hard Yaka, Gcore, Bitfury 등 웹 2-웹 3 분야의 유명 기업들이 있습니다.


