
Web3-AI 트랙 파노라마 보고서: 기술 논리, 시나리오 적용 및 상위 프로젝트에 대한 심층 분석
작성자: Geekcartel
AI 서사에 대한 열기가 계속 뜨거워지면서 이 트랙에 더욱 더 많은 관심이 집중되고 있다. Geekcartel은 Web3-AI 트랙의 기술 논리, 애플리케이션 시나리오 및 대표 프로젝트에 대한 심층 분석을 수행하여 이 분야의 포괄적인 개요 및 개발 동향을 제공합니다.
1. Web3-AI: 기술적 논리 및 신흥시장 기회 분석
1.1 Web3와 AI의 통합 논리: Web-AI 트랙을 정의하는 방법
지난해 Web3 업계에서는 AI 내러티브가 큰 인기를 끌었고 AI 프로젝트는 비가 내린 뒤 버섯처럼 솟아올랐습니다. AI 기술과 관련된 프로젝트는 많지만 일부 프로젝트는 제품의 특정 부분에만 AI를 사용합니다. 기본 토큰 경제는 AI 제품과 실질적으로 관련이 없으므로 해당 프로젝트는 이 기사에 포함되지 않습니다. 토론에서.
이 기사의 초점은 생산 관계 문제를 해결하기 위해 블록체인을 사용하고 생산성 문제를 해결하기 위해 AI를 사용하는 프로젝트에 있습니다. 이러한 프로젝트는 자체적으로 AI 제품을 제공하며 생산 관계 도구로서 Web3 경제 모델을 기반으로 합니다. 우리는 이러한 유형의 프로젝트를 Web3-AI 트랙으로 분류합니다. 독자들이 Web3-AI 트랙을 더 잘 이해할 수 있도록 Geekcartel은 AI의 개발 프로세스와 과제, 그리고 Web3와 AI의 결합이 어떻게 문제를 완벽하게 해결하고 새로운 애플리케이션 시나리오를 만들 수 있는지 소개할 것입니다.
1.2 AI 개발 프로세스 및 과제: 데이터 수집부터 모델 추론까지
AI 기술은 컴퓨터가 인간의 지능을 시뮬레이션, 확장 및 향상시킬 수 있는 기술입니다. 이를 통해 컴퓨터는 언어 번역 및 이미지 분류부터 얼굴 인식, 자율 주행 및 기타 응용 시나리오에 이르기까지 다양하고 복잡한 작업을 수행할 수 있습니다.
인공지능 모델을 개발하는 과정에는 일반적으로 데이터 수집 및 데이터 전처리, 모델 선택 및 조정, 모델 훈련 및 추론과 같은 주요 단계가 포함됩니다. 간단한 예로, 고양이와 개의 이미지를 분류하는 모델을 개발하려면 다음이 필요합니다.
데이터 수집 및 데이터 전처리: 공개 데이터세트를 사용할 수도 있고, 실제 데이터를 직접 수집할 수도 있습니다. 그런 다음 각 이미지에 카테고리(고양이 또는 개)를 지정하여 라벨이 정확한지 확인하세요. 이미지를 모델이 인식할 수 있는 형식으로 변환하고, 데이터 세트를 훈련 세트, 검증 세트, 테스트 세트로 나눕니다.
모델 선택 및 튜닝: CNN(컨볼루션 신경망)과 같이 이미지 분류 작업에 더 적합한 적절한 모델을 선택합니다. 다양한 요구에 따라 모델 매개변수 또는 아키텍처를 조정합니다. 일반적으로 모델의 네트워크 수준은 AI 작업의 복잡성에 따라 조정될 수 있습니다. 이 간단한 분류 예에서는 더 얕은 네트워크 수준이면 충분할 수 있습니다.
모델 훈련: GPU, TPU 또는 고성능 컴퓨팅 클러스터를 사용하여 모델을 훈련할 수 있습니다. 훈련 시간은 모델 복잡성과 컴퓨팅 능력의 영향을 받습니다.
모델 추론: 모델 학습 파일을 모델 가중치라고도 합니다. 추론 프로세스는 학습된 모델을 사용하여 새 데이터를 예측하거나 분류하는 프로세스를 의미합니다. 이 과정에서 모델의 분류 효과를 테스트하기 위해 테스트 세트나 새로운 데이터를 사용할 수 있습니다. 일반적으로 모델의 유효성을 평가하기 위해 정확도, 재현율, F 1 점수와 같은 지표가 사용됩니다.
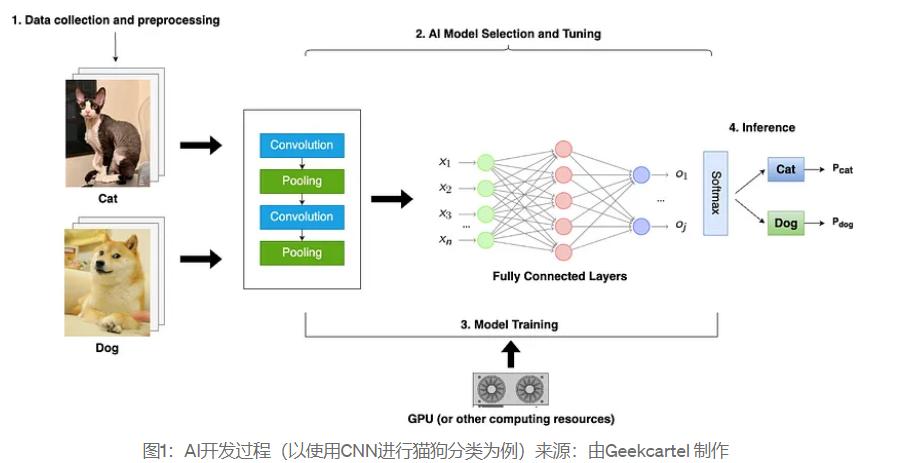
그림에서 볼 수 있듯이, 데이터 수집 및 데이터 전처리, 모델 선택 및 튜닝, 훈련을 거친 후 테스트 세트에 대해 훈련된 모델을 추론하면 고양이와 개의 예측값 P(확률)가 산출됩니다. 즉, 모델이 추론하는 것은 다음과 같습니다. 고양이나 개가 될 확률.
훈련된 AI 모델은 다양한 애플리케이션에 추가로 통합되어 다양한 작업을 수행할 수 있습니다. 이 예시에서는 고양이와 개를 분류하는 AI 모델을 모바일 애플리케이션에 통합할 수 있으며, 사용자는 고양이나 개 사진을 업로드하여 분류 결과를 얻을 수 있습니다.
그러나 중앙 집중식 AI 개발 프로세스에는 다음과 같은 시나리오에서 몇 가지 문제가 있습니다.
사용자 개인 정보 보호: 중앙 집중식 시나리오에서 AI 개발 프로세스는 일반적으로 불투명합니다. 사용자 데이터는 자신도 모르게 도난당하여 AI 훈련에 사용될 수 있습니다.
데이터 소스 획득: 소규모 팀이나 개인이 특정 분야(의료 데이터 등)의 데이터를 획득하는 경우 해당 데이터가 오픈 소스가 아니라는 제한에 직면할 수 있습니다.
모델 선택 및 튜닝: 소규모 팀의 경우 도메인별 모델 리소스를 확보하거나 모델 튜닝에 많은 비용을 지출하기 어렵습니다.
컴퓨팅 성능 확보: 개인 개발자와 소규모 팀의 경우 높은 GPU 구입 비용과 클라우드 컴퓨팅 성능 임대 비용이 상당한 재정적 부담이 될 수 있습니다.
AI 자산 소득: 데이터 주석 작업자는 자신의 노력에 맞는 소득을 얻지 못하는 경우가 많으며, AI 개발자의 연구 결과도 필요한 구매자와 연결하기 어렵습니다.
중앙 집중식 AI 시나리오에 존재하는 과제는 Web3와 결합하여 해결할 수 있습니다. Web3는 새로운 생산 관계로서 새로운 유형의 생산성을 나타내는 AI에 자연스럽게 적응하여 기술과 생산 능력의 동시 발전을 촉진합니다.
1.3 Web3와 AI의 시너지 효과: 역할 변화와 혁신적인 애플리케이션
Web3와 AI의 결합은 사용자 주권을 강화하고 사용자에게 개방형 AI 협업 플랫폼을 제공하며 사용자가 Web2 시대의 AI 사용자에서 참여자로 전환하여 누구나 소유할 수 있는 AI를 만들 수 있습니다. 동시에 Web3 세계와 AI 기술의 통합은 더욱 혁신적인 애플리케이션 시나리오와 게임플레이를 창출할 수도 있습니다.
Web3 기술을 기반으로 AI의 개발과 적용은 새로운 협력 경제 시스템을 가져올 것입니다. 사람들의 데이터 프라이버시가 보장되고, 데이터 크라우드소싱 모델이 AI 모델의 발전을 촉진하며, 사용자가 많은 오픈 소스 AI 리소스를 사용할 수 있으며, 공유 컴퓨팅 성능을 저렴한 비용으로 얻을 수 있습니다. 분산형 협업 크라우드소싱 메커니즘과 개방형 AI 시장의 도움으로 공정한 소득 분배 시스템을 달성하여 더 많은 사람들이 AI 기술 발전을 촉진하도록 동기를 부여할 수 있습니다.
Web3 시나리오에서 AI는 여러 트랙에 긍정적인 영향을 미칠 수 있습니다. 예를 들어, AI 모델은 스마트 계약에 통합되어 시장 분석, 보안 탐지, 소셜 클러스터링 및 기타 기능과 같은 다양한 애플리케이션 시나리오에서 작업 효율성을 향상시킬 수 있습니다. 제너레이티브 AI를 통해 사용자는 AI 기술을 활용해 자신만의 NFT를 만드는 등 '아티스트'의 역할을 경험할 수 있을 뿐만 아니라 GameFi에서 풍부하고 다양한 게임 장면과 흥미로운 인터랙티브 경험을 만들어낼 수 있습니다. 풍부한 인프라는 원활한 개발 경험을 제공합니다. AI 전문가이든 AI 분야에 진출하려는 초보자이든 이 세계에서 적합한 입구를 찾을 수 있습니다.
2. Web3-AI 생태 프로젝트 레이아웃 및 아키텍처 해석
우리는 주로 Web3-AI 트랙에서 41개 프로젝트를 연구하고 이러한 프로젝트를 여러 수준으로 나누었습니다. 인프라 계층, 중간 계층 및 응용 프로그램 계층을 포함하여 각 계층의 분할 논리는 아래 그림에 나와 있습니다. 다음 장에서는 몇 가지 대표적인 프로젝트에 대해 심층 분석을 실시하겠습니다.
인프라 레이어는 AI 라이프사이클 전체를 지원하는 컴퓨팅 자원과 기술 아키텍처를 다루고, 중간 레이어는 인프라와 애플리케이션을 연결하는 데이터 관리, 모델 개발, 검증 추론 서비스를 포함한다. 사용자.
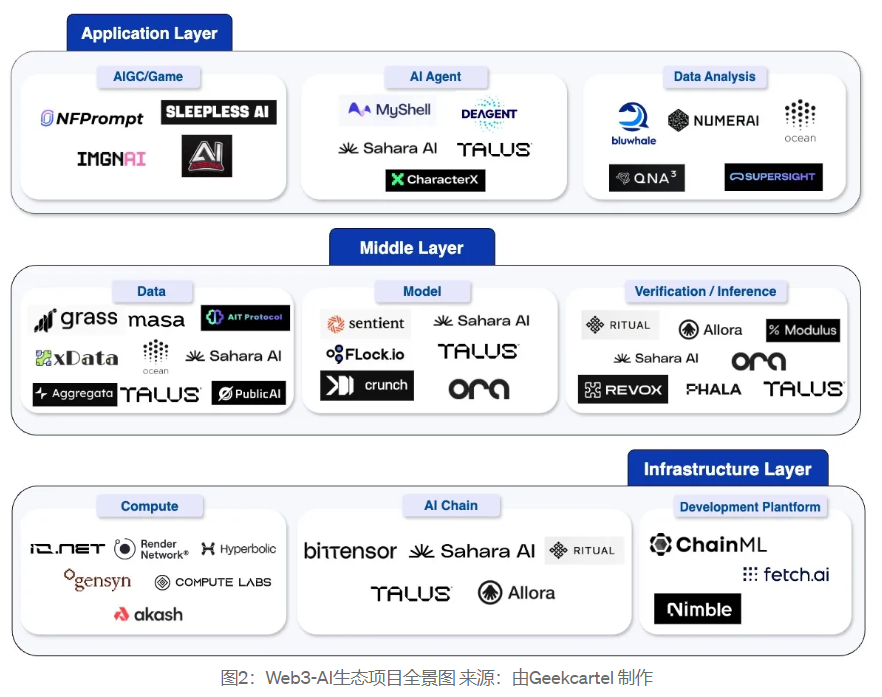
인프라 계층:
인프라 계층은 AI 수명주기의 기초입니다. 이 기사에서는 컴퓨팅 성능, AI 체인 및 개발 플랫폼을 인프라 계층으로 분류합니다. AI 모델의 훈련 및 추론을 가능하게 하고 사용자에게 강력하고 실용적인 AI 애플리케이션을 제공하는 것은 이러한 인프라의 지원입니다.
분산 컴퓨팅 네트워크: AI 모델 훈련을 위한 분산 컴퓨팅 성능을 제공하여 컴퓨팅 리소스의 효율적이고 경제적인 활용을 보장할 수 있습니다. 일부 프로젝트는 분산형 컴퓨팅 파워 시장을 제공하며, 사용자는 IO.NET 및 Hyperbolic과 같이 컴퓨팅 파워를 임대하거나 저렴한 비용으로 컴퓨팅 파워를 공유하여 수익을 얻을 수 있습니다. 또한 일부 프로젝트에서는 토큰화 프로토콜을 제안한 Compute Labs와 같은 새로운 게임플레이를 파생시켰습니다. GPU 엔터티를 대표하는 NFT를 구매하면 사용자는 다양한 방식으로 컴퓨팅 파워 임대에 참여하여 수익을 얻을 수 있습니다.
AI 체인: 블록체인을 AI 라이프사이클의 기초로 사용하여 온체인 및 오프체인 AI 리소스의 원활한 상호 작용을 달성하고 산업 생태계의 발전을 촉진합니다. 체인의 분산형 AI 시장은 데이터, 모델, 에이전트 등의 AI 자산을 거래할 수 있으며 Sahara AI와 같은 프로젝트를 대표하는 AI 개발 프레임워크 및 지원 개발 도구를 제공합니다. AI Chain은 또한 다양한 분야에서 AI 기술의 발전을 촉진할 수 있습니다. 예를 들어 Bittensor는 혁신적인 서브넷 인센티브 메커니즘을 통해 다양한 AI 유형의 서브넷 경쟁을 촉진합니다.
개발 플랫폼: 일부 프로젝트는 AI 에이전트 개발 플랫폼을 제공하고 Fetch.ai 및 ChainML과 같은 AI 에이전트 트랜잭션을 구현할 수도 있습니다. 원스톱 도구는 개발자가 Nimble과 같은 프로젝트로 대표되는 AI 모델을 보다 쉽게 생성, 교육 및 배포하는 데 도움이 됩니다. 이러한 인프라는 Web3 생태계에서 AI 기술의 광범위한 적용을 촉진합니다.
중간층:
이 계층에는 AI 데이터, 모델, 추론 및 검증이 포함됩니다. Web3 기술을 사용하면 작업 효율성이 높아집니다.
데이터: 데이터의 품질과 양은 모델 학습의 효율성에 영향을 미치는 핵심 요소입니다. Web3 세계에서는 데이터 크라우드소싱과 협업 데이터 처리를 통해 리소스 활용도를 최적화하고 데이터 비용을 절감할 수 있습니다. 사용자는 데이터 자율성을 갖고 개인 정보 보호 기능을 갖춘 데이터를 판매하여 부도덕한 판매자의 데이터 도난을 방지하고 높은 수익을 올릴 수 있습니다. 데이터 수요자에게 이러한 플랫폼은 광범위한 선택과 매우 저렴한 비용을 제공합니다. Grass와 같은 대표적인 프로젝트는 사용자 대역폭을 활용하여 웹 데이터를 크롤링하고, xData는 사용자 친화적인 플러그인을 통해 미디어 정보를 수집하고 사용자가 트윗 정보를 업로드하도록 지원합니다.
또한 일부 플랫폼에서는 도메인 전문가나 일반 사용자가 이미지 주석 및 데이터 분류와 같은 데이터 전처리 작업을 수행할 수 있습니다. 이러한 작업에는 전문 지식을 갖춘 금융 및 법률 작업을 위한 데이터 처리가 필요할 수 있습니다. 협업적 크라우드소싱. Sahara AI와 같은 AI 시장의 대표자는 다양한 분야의 데이터 작업을 수행하며 여러 분야의 데이터 시나리오를 다룰 수 있으며 AIT Protocolt는 인간-기계 협업을 통해 데이터에 레이블을 지정합니다.
모델: 앞서 언급한 AI 개발 프로세스에서는 다양한 유형의 요구 사항이 적합한 모델과 일치해야 합니다. 이미지 작업에 일반적으로 사용되는 모델은 CNN 및 GAN입니다. 텍스트 작업의 경우 Yolo 시리즈를 선택할 수 있습니다. , RNN 및 Transformer와 같은 모델이 일반적입니다. 물론 특정 모델이나 일반 모델도 있습니다. 복잡성이 다른 작업에는 다양한 모델 깊이가 필요하며 모델을 조정해야 하는 경우도 있습니다.
일부 프로젝트는 사용자가 크라우드소싱을 통해 다양한 유형의 모델을 제공하거나 모델을 공동으로 교육할 수 있도록 지원합니다. 예를 들어 Sentient는 사용자가 모델 최적화를 위해 신뢰할 수 있는 모델 데이터를 저장 계층 및 배포 계층에 배치할 수 있도록 하는 모듈식 설계를 사용합니다. 고급 AI 알고리즘과 컴퓨팅 프레임워크가 내장되어 있으며 협업 교육 기능이 있습니다.
추론 및 검증: 모델이 훈련된 후에는 분류, 예측 또는 기타 특정 작업을 직접 수행하는 데 사용할 수 있는 모델 가중치 파일이 생성됩니다. 추론 프로세스에는 일반적으로 추론 모델의 소스가 올바른지, 악의적인 행위가 있는지 확인하는 검증 메커니즘이 수반됩니다. Web3 추론은 일반적으로 스마트 계약에 통합되고 호출 모델을 통해 추론될 수 있습니다. 일반적인 검증 방법에는 ZKML, OPML 및 TEE와 같은 기술이 포함됩니다. ORA 온체인 AI 오라클(OAO)과 같은 대표적인 프로젝트들은 AI 오라클의 검증 가능한 레이어로 OPML을 소개했으며, ORA의 공식 웹사이트에서도 ZKML과 opp/ai(OPML과 결합된 ZKML)에 대한 연구를 언급했습니다.
애플리케이션 계층:
이 레이어는 주로 사용자를 직접 대면하는 애플리케이션을 위한 것으로, AI와 Web3를 결합하여 보다 흥미롭고 혁신적인 게임플레이를 만듭니다. 이 기사에서는 주로 AIGC(AI 생성 콘텐츠), AI 에이전트 및 데이터 분석 프로젝트를 분류합니다.
AIGC: AIGC는 Web3의 NFT, 게임 및 기타 트랙으로 확장될 수 있습니다. 사용자는 Prompt(사용자가 제공하는 프롬프트 단어)를 통해 텍스트, 이미지 및 오디오를 직접 생성할 수 있으며 게임 내에서 자신의 선호도에 따라 사용자 정의도 생성할 수 있습니다. 게임 플레이. NFPrompt와 같은 NFT 프로젝트를 통해 사용자는 AI를 통해 NFT를 생성하고 시장에서 거래할 수 있습니다. Sleepless와 같은 게임을 통해 사용자는 자신의 선호도에 맞게 대화를 통해 가상 파트너의 캐릭터를 형성할 수 있습니다.
AI 에이전트(AI Agent): 자율적으로 업무를 수행하고 의사결정을 내릴 수 있는 인공지능 시스템을 말한다. AI 에이전트는 일반적으로 다양한 환경에서 복잡한 작업을 수행하기 위해 감지하고, 추론하고, 학습하고, 행동하는 능력을 갖추고 있습니다. 언어 번역, 언어 학습, 이미지를 텍스트로 변환 등과 같은 일반적인 AI 에이전트는 Web3 시나리오에서 거래 로봇, 밈 밈, 온체인 보안 감지 등을 생성할 수 있습니다. 예를 들어, MyShell은 AI 에이전트 플랫폼으로서 교육 및 학습, 가상 동반자, 거래 에이전트 등 다양한 유형의 에이전트를 제공합니다. 또한 사용자 친화적인 에이전트 개발 도구도 제공하므로 코딩 없이 자신만의 에이전트를 구축할 수 있습니다.
데이터 분석: 관련 분야의 AI 기술과 데이터베이스를 통합하여 데이터 분석, 판단, 예측 등을 실현할 수 있습니다. Web3에서는 사용자가 시장 데이터, 스마트 머니 역학 등을 분석하여 사용자의 투자 판단을 지원할 수 있습니다. 토큰 예측은 Web3의 고유한 응용 시나리오이기도 합니다. Ocean과 같은 대표적인 프로젝트는 공식적으로 토큰 예측에 대한 장기적인 과제를 설정했으며 사용자 참여를 장려하기 위해 다양한 주제에 대한 데이터 분석 작업도 공개할 예정입니다.
3. Web3-AI 트랙의 최첨단 프로젝트에 대한 파노라마 분석
일부 프로젝트에서는 Web3와 AI를 결합할 가능성을 모색하고 있습니다. GeekCartel은 이 트랙의 대표 프로젝트를 정리하여 모두가 WEB3-AI의 매력을 경험하고, 해당 프로젝트가 어떻게 Web3와 AI의 통합을 실현하고 새로운 비즈니스 모델과 경제적 가치를 창출하는지 이해하도록 이끌 것입니다.
Sahara AI: 협력 경제 전용 AI 블록체인 플랫폼
Sahara AI는 AI 데이터, 모델, 에이전트 및 컴퓨팅 성능과 같은 모든 범위의 AI 리소스를 포괄하는 포괄적인 AI 블록체인 플랫폼을 구축하는 데 전념하고 있습니다. 기본 아키텍처는 플랫폼의 협업 경제를 보호합니다. . 블록체인 기술과 고유한 개인 정보 보호 기술을 통해 AI 개발 주기 전반에 걸쳐 AI 자산의 분산된 소유권과 거버넌스를 보장하고 공정한 인센티브 분배를 달성합니다. 팀은 AI와 Web3에 대한 깊은 배경 지식을 갖고 있어 이 두 분야를 완벽하게 통합할 수 있으며, 최고 투자자들에게도 선호를 받고 있으며 해당 트랙에서 큰 잠재력을 보여주었습니다.
Sahara AI는 전통적인 AI 분야에서 자원과 기회의 불평등한 분배를 깨뜨리기 때문에 Web3에만 국한되지 않습니다. 분산화를 통해 컴퓨팅 성능, 모델 및 데이터를 포함한 AI의 핵심 요소는 더 이상 중앙화된 거대 기업에 의해 독점되지 않습니다. 모든 사람은 이 생태계에서 이익을 얻고 팀워크의 힘과 열정을 얻을 수 있는 적절한 위치를 찾을 수 있습니다. .
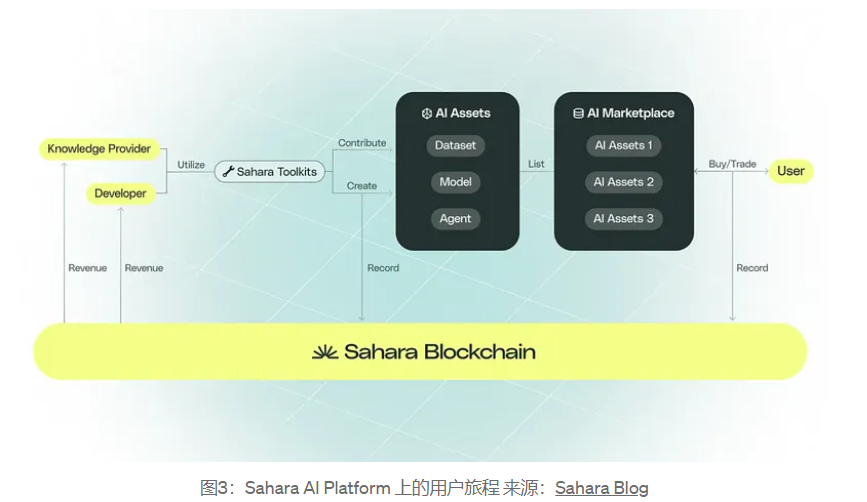
그림에서 볼 수 있듯이 사용자는 Sahara AI가 제공하는 툴킷을 사용하여 자신의 데이터 세트, 모델, AI 에이전트 및 기타 자산을 기여하거나 생성할 수 있으며 이러한 자산을 AI 시장에 배치하여 수익을 얻을 수도 있습니다. 플랫폼 인센티브. 소비자 AI 자산은 주문형으로 거래될 수 있습니다. 동시에 이러한 거래 정보는 Sahara Chain에 기록됩니다. 블록체인 기술과 개인 정보 보호 조치는 기여 추적, 데이터 보안 및 보상의 공정성을 보장합니다.
Sahara AI의 경제 시스템에서 위에서 언급한 개발자, 지식 제공자 및 소비자의 역할 외에도 사용자는 AI를 지원하기 위한 자금과 리소스(GPU, 클라우드 서버, RPC 노드 등)를 제공하는 투자자 역할을 할 수도 있습니다. 자산 개발 및 배포는 네트워크의 안정성을 유지하는 운영자 역할과 블록체인의 보안 및 무결성을 유지하는 검증자 역할을 할 수도 있습니다. 사용자가 Sahara AI 플랫폼에 어떻게 참여하는지에 관계없이 기여도에 따라 보상과 수입을 받게 됩니다.
Sahara AI 블록체인 플랫폼은 온체인 및 오프체인 인프라를 갖춘 계층화된 아키텍처를 기반으로 구축되어 사용자와 개발자가 전체 AI 개발 주기에 효과적으로 기여하고 혜택을 누릴 수 있도록 합니다. Sahara AI 플랫폼의 아키텍처는 4개 계층으로 나뉩니다.
애플리케이션 레이어
애플리케이션 계층은 사용자 인터페이스와 주요 상호 작용 지점 역할을 하며 사용자 경험을 향상시키기 위한 기본 내장 툴킷과 애플리케이션을 제공합니다.
기능적 구성 요소:
Sahara ID — 사용자의 AI 자산에 대한 안전한 액세스를 보장하고 사용자 기여를 추적합니다.
Sahara Vault — 무단 액세스 및 잠재적 위협으로부터 AI 자산의 개인 정보 보호 및 보안을 보호합니다.
Sahara Agent - 역할 조정(사용자 행동 및 습관에 맞는 상호 작용), 평생 학습, 다중 모드 인식(다양한 유형의 데이터 처리 가능) 및 다중 도구 실행 기능을 갖추고 있습니다.
대화형 구성 요소:
Sahara Toolkit — 기술 사용자와 비기술 사용자가 AI 자산을 생성하고 배포할 수 있도록 지원합니다.
Sahara AI Marketplace — AI 자산 게시, 수익화 및 거래를 위해 유연한 라이선스와 다양한 수익화 옵션을 제공합니다.
트랜잭션 레이어
Sahara AI의 트랜잭션 레이어는 Sahara 블록체인을 사용합니다. 이 L1은 플랫폼에 관리 소유권, 속성 및 AI 관련 트랜잭션 프로토콜을 갖추고 있어 AI 자산의 주권과 출처를 유지하는 데 핵심적인 역할을 합니다. Sahara Blockchain은 혁신적인 Sahara AI Native Precompilation(SAP)과 Sahara Blockchain Protocol(SBP)을 통합하여 AI 수명주기 전반에 걸쳐 필수 작업을 지원합니다.
SAP는 블록체인의 기본 실행 수준에 내장된 기능으로 각각 AI 훈련/추론 프로세스에 중점을 둡니다. SAP는 오프체인 AI 훈련/추론 프로세스를 호출, 기록 및 검증하는 데 도움을 주어 Sahara AI 플랫폼 내에서 개발된 AI 모델의 신뢰성과 신뢰도를 보장하고 모든 AI 추론의 투명성, 검증 가능성 및 추적성을 보장합니다. 같은 시간. 동시에 SAP를 통해 더 빠른 실행 속도, 더 낮은 컴퓨팅 오버헤드 및 가스 비용을 달성할 수 있습니다.
SBP는 AI 자산과 계산 결과가 투명하고 안정적으로 처리되도록 스마트 계약을 통해 AI 전용 프로토콜을 구현합니다. AI 자산 등록, 라이선스(액세스 제어), 소유권 및 귀속(기여 추적)과 같은 기능이 포함됩니다.
데이터 레이어
Sahara AI의 데이터 레이어는 AI 라이프사이클 전반에 걸쳐 데이터 관리를 최적화하도록 설계되었습니다. 이는 실행 계층을 다양한 데이터 관리 메커니즘에 연결하고 온체인 및 오프체인 데이터 소스를 원활하게 통합하는 중요한 인터페이스 역할을 합니다.
데이터 구성요소: 온체인 및 오프체인 데이터를 포함합니다. 온체인 데이터에는 AI 자산의 메타데이터, 소유권, 약속 및 인증 등이 포함됩니다. 데이터 세트, AI 모델 및 보충 정보는 오프체인에 저장됩니다.
데이터 관리: Sahara AI의 데이터 관리 솔루션은 고유한 암호화 체계를 통해 전송 중 및 저장 중에 데이터가 보호되도록 보장하는 일련의 보안 조치를 제공합니다. AI 라이선스 SBP와 협력하여 엄격한 액세스 제어 및 검증 가능성을 달성하는 동시에 개인 도메인 스토리지를 제공하여 사용자의 민감한 데이터에 대한 보안 기능을 강화할 수 있습니다.
실행 계층
실행 계층은 Sahara AI 플랫폼의 오프체인 AI 인프라로, 트랜잭션 계층 및 데이터 계층과 원활하게 상호 작용하여 AI 계산 및 기능과 관련된 프로토콜을 실행하고 관리합니다. 실행 작업에 따라 데이터 계층에서 데이터를 안전하게 추출하고 최적의 성능을 위해 컴퓨팅 리소스를 동적으로 할당합니다. 복잡한 AI 작업은 다양한 추상화 간의 효율적인 상호 작용을 촉진하도록 설계된 특별히 설계된 프로토콜 세트를 통해 조정되며 기본 인프라는 고성능 AI 컴퓨팅을 지원하도록 설계되었습니다.
인프라: Sahara AI의 실행 계층 인프라는 빠른 효율성, 탄력성 및 고가용성과 같은 기능을 통해 고성능 AI 컴퓨팅을 지원하도록 설계되었습니다. AI 계산, 자동 확장 메커니즘 및 내결함성 설계의 효율적인 조정을 통해 높은 트래픽 및 오류 조건에서도 시스템이 안정적이고 신뢰할 수 있는 상태를 유지하도록 보장합니다.
추상화: 핵심 추상화는 데이터 세트, 모델, 컴퓨팅 리소스 및 기타 리소스의 추상화를 포함하여 Sahara AI 플랫폼에서 AI 작업의 기초를 형성하는 기본 구성 요소입니다. 더 높은 수준의 기능을 실현할 수 있는 Vault 및 에이전트 뒤에 있는 실행 인터페이스입니다.
프로토콜: 추상 실행 프로토콜은 Vault와의 상호 작용, 에이전트 상호 작용 및 조정, 컴퓨팅 협업 등을 수행하는 데 사용됩니다. 협업 컴퓨팅 프로토콜은 여러 참가자 간의 공동 AI 모델 개발 및 배포를 실현할 수 있으며 컴퓨팅 리소스 기여를 지원합니다. 실행 계층에는 PEFT(낮은 컴퓨팅 비용 기술 모듈), 개인 정보 보호 컴퓨팅 모듈 및 사기 방지 컴퓨팅 모듈도 포함됩니다.
Sahara AI가 구축하고 있는 AI 블록체인 플랫폼은 포괄적인 AI 생태계를 실현하는 데 전념하고 있습니다. 그러나 이 원대한 비전은 실현 과정에서 강력한 기술, 리소스 지원 및 지속적인 최적화와 반복이 필요한 많은 과제에 필연적으로 직면하게 됩니다. 성공적으로 구현된다면 Web3-AI 분야를 지원하는 주춧돌이 될 것이며 Web2-AI 실무자들의 마음 속에 이상적인 정원이 될 것으로 예상됩니다.
팀 정보:
Sahara AI 팀은 뛰어나고 창의적인 구성원들로 구성되어 있습니다. 공동 창립자인 Sean Ren은 올해의 삼성 AI 연구원, MIT TR Innovator Under 35 및 Forbes 30 Under 30을 수상했습니다. . 명예를 기다리고 있습니다. 공동 창립자인 Tyler Zhou는 캘리포니아 대학교 버클리 캠퍼스를 졸업하고 Web3에 대한 깊은 이해를 갖고 있으며 AI 및 Web3 분야의 경험을 바탕으로 글로벌 인재 팀을 이끌고 있습니다.
Sahara AI 창립 이후 이 팀은 Microsoft, Amazon, MIT, Snapchat, Character AI 등을 포함한 최고의 기업으로부터 수백만 달러의 수익을 창출했습니다. 현재 Sahara AI는 30개 이상의 기업 고객에게 서비스를 제공하고 있으며 전 세계적으로 200,000명 이상의 AI 트레이너를 보유하고 있습니다. Sahara AI의 빠른 성장으로 인해 점점 더 많은 참여자가 공유 경제 모델에 기여하고 혜택을 누릴 수 있게 되었습니다.
자금 조달 정보:
올해 8월 현재 사하라랩스는 4,300만 달러를 성공적으로 모금했다. 최근 자금 조달 라운드는 Pantera Capital, Binance Labs 및 Polychain Capital이 공동으로 주도했습니다. 또한 마더슨그룹(Motherson Group), 앤트로픽(Anthropic), 누스리서치(Nous Research), 미드저니(Midjourney) 등 AI 분야 선구자들의 지지를 받아왔다.
Bittensor: 서브넷 경쟁에서 영감을 받은 새로운 게임플레이
Bittensor 자체는 AI 제품이 아니며 AI 제품이나 서비스를 생산하거나 제공하지도 않습니다. Bittensor는 AI 상품 생산자에게 경쟁이 치열한 인센티브 구조를 제공하여 생산자가 지속적으로 AI 품질을 최적화할 수 있도록 하는 경제 시스템입니다. Web3-AI의 초기 프로젝트인 Bittensor는 출시 이후 시장의 큰 관심을 받았습니다. CoinMarketCap 데이터에 따르면 10월 17일 현재 시장 가치는 42억 6천만 달러를 초과했으며, FDV(완전 희석 가치)는 120억 달러를 초과했습니다.
Bittensor는 많은 서브넷 네트워크로 연결된 네트워크 아키텍처를 구축합니다. AI 상품 생산자는 맞춤형 인센티브와 다양한 사용 사례를 갖춘 서브넷을 생성할 수 있습니다. 다양한 서브넷은 기계 번역, 이미지 인식 및 생성, 대규모 언어 모델 등과 같은 다양한 작업을 담당합니다. 예를 들어 Subnet 5는 Midjourney와 같은 AI 이미지를 생성할 수 있습니다. 뛰어난 작업을 완료하면 TAO(Bittensor의 토큰)로 보상을 받게 됩니다.
인센티브 메커니즘은 Bittensor의 기본 구성 요소입니다. 이는 서브넷 마이너의 동작을 주도하고 서브넷 유효성 검사기 간의 합의를 제어합니다. 각 서브넷에는 고유한 인센티브 메커니즘이 있습니다. 서브넷 채굴자는 작업 실행을 담당하며 검증자는 서브넷 채굴자의 결과를 평가합니다.
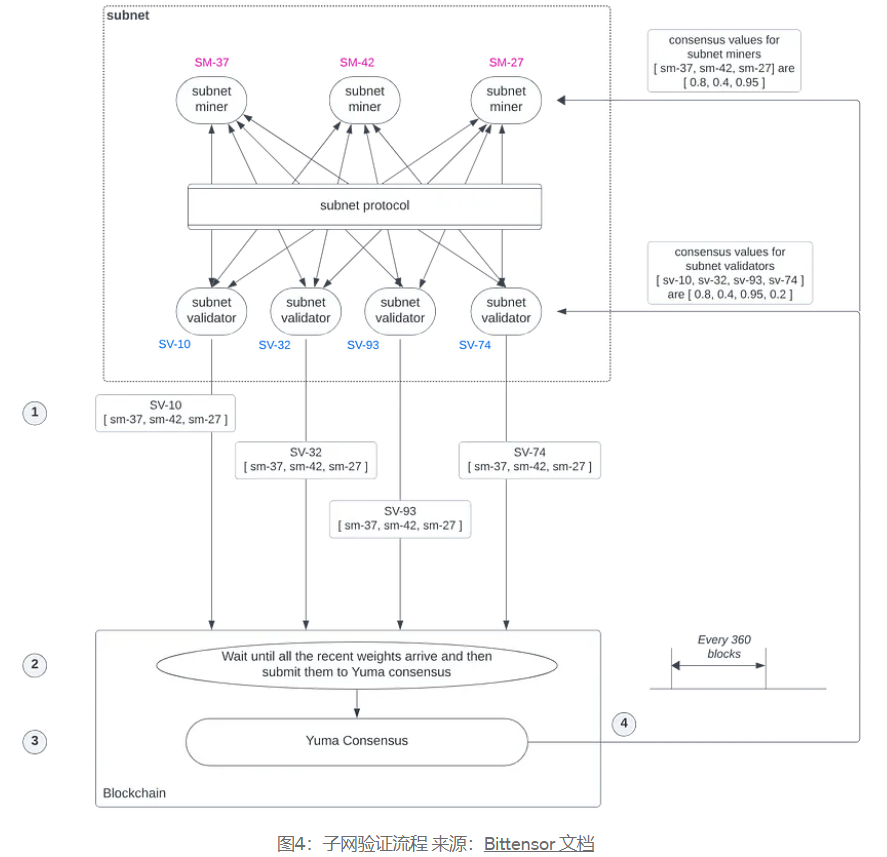
그림에 표시된 대로 예제를 사용하여 서브넷 마이너와 서브넷 유효성 검사기 간의 워크플로를 보여줍니다.
그림에서 세 개의 서브넷 채굴기는 각각 UID 37, 42, 27에 해당하고, 네 개의 서브넷 유효성 검사기는 각각 UID 10, 32, 93, 74에 해당합니다.
각 서브넷 유효성 검사기는 가중치 벡터를 유지합니다. 벡터의 각 요소는 서브넷 채굴자에게 할당된 가중치를 나타내며, 이는 채굴자의 작업 완료에 대한 서브넷 유효성 검사기의 평가를 기반으로 결정됩니다. 각 서브넷 유효성 검사기는 이 가중치 벡터를 기준으로 모든 서브넷 채굴자의 순위를 매기고 독립적으로 작동하여 채굴자 순위 가중치 벡터를 블록체인에 전송합니다. 일반적으로 각 서브넷 유효성 검사기는 100~200개 블록마다 업데이트된 순위 가중치 벡터를 블록체인에 전송합니다.
블록체인(하위 텐서)은 특정 서브넷의 모든 서브넷 유효성 검사기의 최신 순위 가중치 벡터가 블록체인에 도착할 때까지 기다립니다. 그런 다음 이러한 순위 가중치 벡터로 구성된 순위 가중치 행렬은 체인의 Yuma 합의 모듈에 대한 입력으로 제공됩니다.
온체인 Yuma 합의는 이 가중치 매트릭스와 해당 서브넷의 UID와 관련된 스테이크 양을 사용하여 보상을 계산합니다.
Yuma 합의는 TAO의 합의 분포를 계산하고 새로 발행된 보상 TAO를 UID와 연결된 계정에 배포합니다.
서브넷 검증자는 언제든지 순위 가중치 벡터를 블록체인에 전송할 수 있습니다. 그러나 서브넷의 Yuma 합의 주기는 최신 가중치 매트릭스를 사용하여 360블록마다(즉, 블록당 12초를 기준으로 4320초 또는 72분) 시작됩니다. 서브넷 유효성 검사기의 순위 가중치 벡터가 360블록 주기 후에 도착하면 해당 가중치 벡터는 다음 Yuma 합의 주기 시작 시 사용됩니다. TAO 보상은 각 주기가 끝날 때 배포됩니다.
Yuma 합의는 Bittensor가 공정한 노드 분배를 달성하기 위해 사용하는 핵심 알고리즘입니다. 이는 PoW와 PoS 요소를 결합한 하이브리드 합의 메커니즘입니다. 비잔틴 내결함성 합의 메커니즘과 유사하게, 네트워크에 대다수의 정직한 검증자가 있는 경우 결국 합의를 통해 올바른 결정에 도달할 수 있습니다.
루트 네트워크는 서브넷 0인 특수 서브넷입니다. 기본적으로 서브넷의 모든 서브넷 검증인 중 지분이 가장 많은 64개의 서브넷 검증인이 루트 네트워크의 검증인입니다. 루트 네트워크 검증자는 각 서브넷의 출력 품질을 기준으로 평가 및 순위가 지정되며, 64개 검증자의 평가 결과가 요약되고 Yuma Consensus 알고리즘을 통해 최종 방출 결과가 얻어지며 각 서브넷은 새로 할당됩니다. TAO에서 보낸 최종 결과입니다.
Bittensor의 서브넷 경쟁 모델은 AI 제품의 품질을 향상시켰지만 몇 가지 과제에도 직면해 있습니다. 우선, 서브넷 소유자가 설정한 인센티브 메커니즘은 채굴자의 수입을 결정하고 채굴자의 근로 동기에 직접적인 영향을 미칠 수 있습니다. 또 다른 문제는 검증인이 각 서브넷에 대한 토큰 할당을 결정하지만 Bittensor의 장기적인 생산성에 도움이 되는 서브넷을 선택하기 위한 명확한 인센티브가 부족하다는 것입니다. 이 설계로 인해 유효성 검사기는 관계가 있는 서브넷이나 추가적인 이점을 제공하는 서브넷을 선택하는 쪽으로 편향될 수 있습니다. 이 문제를 해결하기 위해 Opentensor Foundation의 기여자들은 BIT 001: 동적 TAO 솔루션을 제안했습니다. 이는 시장 메커니즘을 사용하여 모든 TAO 약속자가 경쟁할 서브넷 토큰 할당을 결정하도록 제안합니다.
팀 정보:
공동 창립자인 Ala Shaabana는 워털루 대학의 박사후 연구원이며 컴퓨터 과학 분야의 학문적 배경을 가지고 있습니다. 또 다른 공동 창업자인 제이콥 로버트 스티브스(Jacob Robert Steeves)는 캐나다 사이먼 프레이저 대학교를 졸업하고 10년 가까이 머신러닝 연구 경험이 있으며 구글에서 소프트웨어 엔지니어로 근무했다.
자금 조달 정보:
OpenTensor Foundation으로부터 재정적 지원을 받는 것 외에도 Bittensor는 Bittensor를 지원하는 비영리 조직입니다. 또한, 커뮤니티 발표에서는 잘 알려진 암호화폐 VC인 Pantera와 Collab Money가 TAO 토큰의 보유자가 되었으며 프로젝트의 생태학적 발전을 위해 더 많은 지원을 제공할 것이라고 발표했습니다. 다른 주요 투자자로는 Digital Current Group, Polychain Capital, FirstMark Capital, GSR 등을 포함한 잘 알려진 투자 기관 및 시장 조성자가 있습니다.
Talus: Move 기반의 온체인 AI 에이전트 생태계
Talus Network는 AI 에이전트를 위해 특별히 설계된 MoveVM을 기반으로 구축된 L1 블록체인입니다. 이러한 AI 에이전트는 사전 정의된 목표에 따라 결정을 내리고 조치를 취하여 원활한 체인 간 상호 작용을 달성하고 검증 가능합니다. 사용자는 Talus가 제공하는 개발 도구를 사용하여 AI 에이전트를 신속하게 구축하고 이를 스마트 계약에 통합할 수 있습니다. Talus는 또한 AI 모델, 데이터, 컴퓨팅 파워와 같은 리소스에 대한 개방형 AI 시장을 제공합니다. 사용자는 다양한 형태로 참여하고 자신의 기여와 자산을 토큰화할 수 있습니다.
Talus의 고유한 기능은 병렬 실행 및 보안 실행 기능입니다. Move 생태계에서 자본 승인과 고품질 프로젝트의 확장으로 Talus의 Move 기반 보안 실행과 AI 에이전트 통합 스마트 계약이라는 두 가지 하이라이트가 시장에서 광범위한 관심을 끌 것으로 예상됩니다. 동시에 Talus가 지원하는 다중 체인 상호 작용은 AI 에이전트의 효율성을 향상시키고 다른 체인에서 AI의 번영을 촉진할 수도 있습니다.
공식 트위터 정보에 따르면 Talus는 최근 최초의 완전한 온체인 자율 AI 에이전트 프레임워크인 Nexus를 출시했습니다. 이는 Talus에게 분산형 AI 기술 분야에서 선두주자 이점을 제공하고 빠르게 발전하는 블록체인 산업에서 경쟁 우위를 제공합니다. .Chain AI는 시장에서 중요한 경쟁력을 제공합니다. Nexus는 개발자가 Talus 네트워크에서 AI 기반 디지털 보조 장치를 만들 수 있도록 지원하여 검열 저항, 투명성 및 구성 가능성을 보장합니다. 중앙 집중식 AI 솔루션과 달리 Nexus를 통해 소비자는 맞춤형 지능형 서비스를 즐기고 디지털 자산을 안전하게 관리하며 상호 작용을 자동화하고 일상적인 디지털 경험을 향상시킬 수 있습니다.
온체인 에이전트를 위한 최초의 개발자 툴킷인 Nexus는 차세대 소비자 암호화 AI 애플리케이션을 구축하기 위한 기반을 제공합니다. Nexus는 개발자가 사용자 의도를 실행하고 Talus 체인에서 서로 통신할 수 있는 에이전트를 만드는 데 도움이 되는 일련의 도구, 리소스 및 표준을 제공합니다. 그중 Nexus Python SDK는 AI와 블록체인 개발 간의 격차를 해소하여 AI 개발자가 스마트 계약 프로그래밍을 배우지 않고도 쉽게 시작할 수 있도록 해줍니다. Talus는 사용자 친화적인 개발 도구와 다양한 인프라를 제공하여 개발자가 혁신할 수 있는 이상적인 플랫폼이 될 것을 약속합니다.
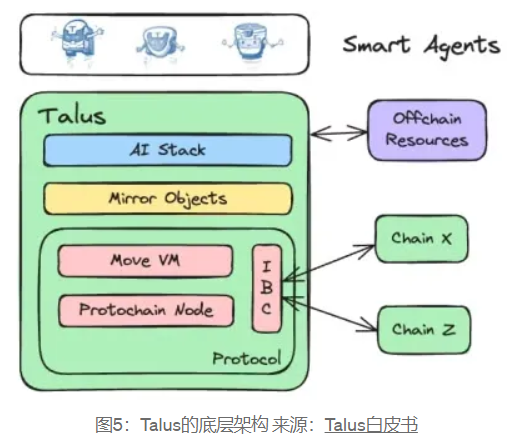
그림 5에서 볼 수 있듯이 Talus의 기본 아키텍처는 모듈식 설계를 기반으로 하며 오프체인 리소스 및 다중 체인 상호 작용의 유연성을 갖추고 있습니다. Talus의 독특한 디자인을 기반으로 번영하는 온체인 지능형 에이전트 생태계가 형성됩니다.
프로토콜은 Talus의 핵심이며 합의, 실행 및 상호 운용성을 위한 기반을 제공합니다. 이를 기반으로 오프체인 리소스와 크로스체인 기능을 활용하기 위해 온체인 지능형 에이전트를 구축할 수 있습니다.
Protochain 노드: Cosmos SDK 및 CometBFT를 기반으로 하는 PoS 블록체인 노드입니다. Cosmos SDK는 모듈식 설계와 높은 확장성 기능을 갖추고 있습니다. CometBFT는 비잔틴 내결함성 합의 알고리즘을 기반으로 하며 고성능과 낮은 대기 시간 특성을 가지며 강력한 보안과 오류를 제공합니다. 허용 오차는 일부 노드가 실패하거나 악의적으로 동작하더라도 정상적으로 계속 작동할 수 있습니다.
Sui Move 및 MoveVM: Sui Move를 스마트 계약 언어로 사용하는 Move 언어의 설계는 재진입 공격, 개체 소유권에 대한 액세스 제어 확인 누락, 예상치 못한 산술 오버플로/언더플로와 같은 심각한 취약점을 제거하여 본질적으로 보안을 강화합니다. Move VM의 아키텍처는 효율적인 병렬 처리를 지원하므로 Talus는 보안이나 무결성을 잃지 않고 여러 트랜잭션을 동시에 처리하여 확장할 수 있습니다.
IBC(블록체인 간 통신 프로토콜):
상호 운용성: IBC는 서로 다른 블록체인 간의 원활한 상호 운용성을 촉진하여 스마트 에이전트가 여러 체인에서 데이터 또는 자산을 상호 작용하고 활용할 수 있도록 합니다.
크로스체인 원자성: IBC는 특히 금융 애플리케이션이나 복잡한 워크플로우에서 지능형 에이전트가 수행하는 작업의 일관성과 신뢰성을 유지하는 데 중요한 기능인 크로스체인 원자성 트랜잭션을 지원합니다.
샤딩을 통한 확장성: IBC는 스마트 에이전트가 여러 블록체인에서 작동할 수 있도록 하여 샤딩을 통해 간접적으로 확장성을 지원합니다. 각 블록체인은 트랜잭션의 하위 집합을 처리하는 샤드로 볼 수 있으므로 단일 체인의 부하가 줄어듭니다. 이를 통해 지능형 에이전트는 보다 분산되고 확장 가능한 방식으로 작업을 관리하고 수행할 수 있습니다.
맞춤화 가능성 및 전문화: IBC를 사용하면 다양한 블록체인이 특정 기능이나 최적화에 집중할 수 있습니다. 예를 들어 지능형 에이전트는 결제 처리를 위한 빠른 거래를 위해 하나의 체인을 사용하고 기록 보관을 위한 안전한 데이터 저장 전용 체인을 사용할 수 있습니다.
보안 및 격리: IBC는 체인 간 보안 및 격리를 유지하므로 민감한 작업이나 데이터를 처리하는 스마트 에이전트에 유용합니다. IBC는 체인 간 통신 및 거래에 대한 안전한 검증을 보장하므로 스마트 에이전트는 보안을 손상시키지 않고 서로 다른 체인 간에 자신있게 작동할 수 있습니다.
거울 물체:
온체인 아키텍처에서 오프체인 세계를 표현하기 위해 미러 개체는 주로 리소스 고유성 표시 및 증명, 오프체인 리소스 거래성, 소유권 인증서 표시 또는 소유권 검증 가능성과 같은 AI 리소스를 확인하고 연결하는 데 사용됩니다. .
미러 개체에는 모델 개체, 데이터 개체, 계산 개체 등 세 가지 유형의 미러 개체가 포함됩니다.
모델 객체: 모델 소유자는 전용 모델 레지스트리를 통해 AI 모델을 생태계에 도입하여 오프체인 모델을 체인으로 변환할 수 있습니다. 모델 객체는 소유권, 관리 및 수익 창출 프레임워크를 직접 구축하여 모델의 본질과 기능을 캡슐화합니다. 모델 객체는 추가적인 미세 조정 프로세스를 통해 기능을 강화하거나 필요한 경우 특정 요구 사항을 충족하기 위해 광범위한 교육을 통해 완전히 재구성할 수 있는 유연한 자산입니다.
데이터 객체: 데이터(또는 데이터 세트) 객체는 누군가가 소유한 고유한 데이터 세트의 디지털 표현으로 존재합니다. 이 개체는 생성, 전송, 라이센스 부여 또는 공개 데이터 소스로 변환될 수 있습니다.
계산 객체: 구매자가 객체 소유자에게 계산 작업을 제안하면 소유자는 계산 결과와 해당 증명을 제공합니다. 구매자는 약속을 해독하고 결과를 확인하는 데 사용할 수 있는 키를 보유합니다.
AI 스택:
Talus는 지능형 에이전트 개발 및 오프체인 리소스와의 상호 작용을 지원하기 위해 SDK 및 통합 구성 요소를 제공합니다. AI 스택에는 Oracle과의 통합도 포함되어 있어 지능형 에이전트가 의사 결정 및 대응을 위해 오프체인 데이터를 활용할 수 있습니다.
체인의 스마트 에이전트:
Talus는 자율적으로 작동하고, 의사 결정을 내리고, 거래를 실행하고, 온체인 및 오프체인 리소스와 상호 작용할 수 있는 지능형 에이전트의 경제 시스템을 제공합니다.
지능형 에이전트는 자율성, 사회적 능력, 반응성 및 주도성을 갖습니다. 자율성을 통해 사람의 개입 없이 작동할 수 있고, 사회적 기능을 통해 다른 에이전트 및 인간과 상호 작용할 수 있으며, 반응성을 통해 환경 변화를 감지하고 신속하게 대응할 수 있습니다. (Talus는 에이전트가 청취자를 통해 온체인 및 오프체인 이벤트에 대응할 수 있도록 지원합니다.) , 사전 대응성을 통해 목표, 예측 또는 예상되는 미래 상태에 따라 조치를 취할 수 있습니다.
Talus가 제공하는 일련의 지능형 에이전트를 위한 개발 아키텍처 및 인프라 외에도 Talus에 구축된 AI 에이전트는 AI 추론의 투명성과 신뢰성을 보장하기 위해 여러 유형의 검증 가능한 AI 추론(opML, zkML 등)도 지원합니다. Talus는 온체인과 오프체인 리소스 간의 다중 체인 상호 작용 및 매핑 기능을 실현할 수 있는 AI 에이전트를 위해 특별히 설계된 일련의 시설을 보유하고 있습니다.
Talus가 출시한 온체인 AI 에이전트 생태계는 AI 및 블록체인과의 통합 기술 개발에 큰 의미가 있지만 여전히 구현이 어렵습니다. Talus의 인프라는 AI 에이전트 개발에 있어 유연성과 상호 운용성을 지원하지만, Talus 체인에서 실행되는 AI 에이전트가 점점 더 많아짐에 따라 이러한 에이전트 간의 상호 운용성과 효율성이 사용자 요구를 충족할 수 있는지 여부는 아직 밝혀지지 않았습니다. Talus는 현재 아직 프라이빗 테스트 네트워크 단계에 있으며 지속적으로 개발 및 업데이트되고 있습니다. 탈루스는 향후 체인 내 AI 에이전트 생태계의 더욱 발전을 촉진할 수 있을 것으로 기대된다.
팀 정보:
Mike Hanono는 Talus Network의 창립자이자 CEO입니다. 그는 University of Southern California에서 산업 및 시스템 공학 학사 학위와 응용 데이터 과학 석사 학위를 취득했으며, University of Pennsylvania의 Wharton Business School 프로젝트에 참여했으며 데이터 분석, 소프트웨어 개발 및 개발 분야에서 광범위한 경험을 보유하고 있습니다. 프로젝트 관리.
자금 조달 정보:
올해 2월 Talus는 Polychain Capital이 주도하고 Dao 5, Hash 3, TRGC, WAGMI Ventures, Inception Capital 등이 참여하여 300만 달러의 1차 자금 조달을 완료했습니다. 엔젤 투자자는 주로 Nvidia, IBM, 파란색 7. 상징적 자본과 렌더 네트워크.
ORA: 온체인 검증 가능한 AI의 초석
ORA의 제품 OAO(온체인 AI 오라클)는 오프체인 AI 추론 결과를 체인에 도입할 수 있는 opML을 사용하는 세계 최초의 AI 오라클입니다. 이는 스마트 계약이 OAO와 상호 작용하여 체인에서 AI 기능을 구현할 수 있음을 의미합니다. 또한 ORA의 AI 오라클은 IMO(초기 모델 출시)와 원활하게 통합되어 전체 프로세스 온체인 AI 서비스를 제공할 수 있습니다.
ORA는 기술과 시장 모두에서 선도적 이점을 갖고 있습니다. 이더리움의 무신뢰 AI 오라클로서, 앞으로는 더욱 혁신적인 AI 애플리케이션 시나리오가 등장할 것으로 예상됩니다. 이제 개발자는 ORA에서 제공하는 모델을 사용하여 스마트 계약에서 분산 추론을 구현하고 Ethereum, Arbitrum, Optimism, Base, Polygon, Linea 및 Manta에서 검증 가능한 AI dApp을 구축할 수 있습니다. ORA는 AI 추론을 위한 검증 서비스를 제공하는 것 외에도 오픈소스 모델의 기여를 촉진하기 위해 모델 배포 서비스(IMO)도 제공합니다.
ORA의 두 가지 주요 제품은 IMO(Initial Model Release)와 OAO(On-Chain AI Oracle)입니다. 이 두 제품은 온체인 AI 모델 획득과 AI 추론 검증을 달성하기 위해 완벽하게 조화를 이룹니다.
IMO는 오픈 소스 AI 모델의 소유권을 토큰화하여 장기적인 오픈 소스 기여를 장려하며, 토큰 보유자는 체인에서 모델을 사용하여 생성된 수익의 일부를 받게 됩니다. ORA는 또한 AI 개발자에게 자금을 제공하고 커뮤니티 및 오픈 소스 기여자에게 인센티브를 제공합니다.
OAO는 체인에 검증 가능한 AI 추론을 제공합니다. ORA는 AI 오라클을 위한 검증 레이어로 opML을 도입했습니다. OP 롤업의 워크플로우와 유사하게 검증인 또는 모든 네트워크 참가자는 챌린지 기간 동안 결과를 확인할 수 있습니다. 챌린지가 성공하면 오류 결과가 챌린지 기간 후에 체인에 업데이트되며 결과는 최종적이고 변경할 수 없습니다. .
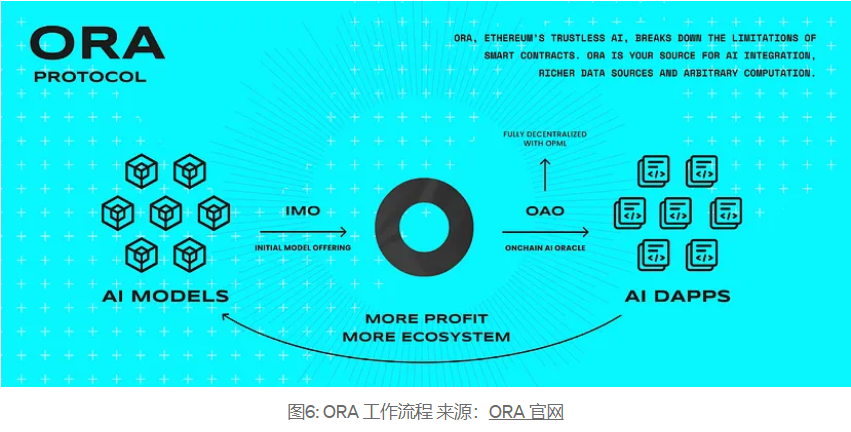
검증 가능하고 분산화된 오라클 네트워크를 구축하려면 블록체인 결과의 계산 유효성을 보장하는 것이 중요합니다. 이 프로세스에는 계산의 신뢰성과 사실을 보장하는 증명 시스템이 포함됩니다.
이를 위해 ORA는 세 가지 인증 시스템 프레임워크를 제공합니다.
AI Oracle의 opML(현재 ORA의 AI oracle은 이미 opML을 지원함)
keras 2c ircom용 zkML(성숙한 고성능 zkML 프레임워크)
zkML의 개인정보 보호와 opML의 확장성을 결합한 zk+opML은 opp/ai를 통해 미래 온체인 AI 솔루션을 구현합니다.
opML:
ORA가 발명하고 개발한 opML(Optimistic Machine Learning)은 기계 학습과 블록체인 기술을 결합합니다. 유사한 낙관적 롤업 원칙을 활용함으로써 opML은 분산된 방식으로 계산 효율성을 보장합니다. 이 프레임워크는 AI 계산의 온체인 검증을 허용하여 투명성을 높이고 기계 학습 추론에 대한 신뢰를 높입니다.
보안과 정확성을 보장하기 위해 opML은 다음과 같은 사기 방지 메커니즘을 사용합니다.
결과 제출: 서비스 제공자(제출자)는 오프체인에서 기계 학습 계산을 수행하고 결과를 블록체인에 제출합니다.
검증 기간: 검증자(또는 도전자)는 제출된 결과의 정확성을 검증하기 위해 미리 정의된 기간(챌린지 기간)을 갖습니다.
분쟁 해결: 검증인이 결과가 잘못된 것을 발견하면 대화형 분쟁 게임을 시작합니다. 논쟁 게임은 오류가 발생한 정확한 계산 단계를 효과적으로 식별합니다.
온체인 검증: 논쟁의 여지가 있는 계산 단계만 사기 방지 가상 머신(FPVM)을 통해 온체인으로 검증되므로 리소스 사용량이 최소화됩니다.
마무리: 챌린지 진행 중에 분쟁이 제기되지 않거나 분쟁이 해결되면 결과가 블록체인에서 마무리됩니다.
ORA가 도입한 opML을 사용하면 최적화된 환경에서 오프체인 계산을 수행할 수 있으며 분쟁 중에는 가장 작은 데이터만 온체인에서 처리됩니다. 영지식 기계 학습(zkML)에 필요한 값비싼 증명 생성을 피하고 계산 비용을 줄이세요. 이 방법은 기존 온체인 방법으로는 달성하기 어려운 대규모 계산을 처리할 수 있습니다.
케라스 2c ircom(zkML):
zkML은 영지식 증명을 사용하여 온체인에서 기계 학습 추론 결과를 검증하는 증명 프레임워크입니다. 개인 정보 보호로 인해 훈련 및 추론 중에 개인 데이터와 모델 매개 변수를 보호하여 개인 정보 보호 문제를 해결할 수 있습니다. zkML의 실제 계산은 오프체인에서 완료되고 온체인에서는 결과의 유효성만 검증하면 되므로 체인의 계산 부하가 줄어듭니다.
ORA가 구축한 Keras 2C ircom은 최초의 전투 테스트를 거친 고급 zkML 프레임워크입니다. Ethereum Foundation ESP Grant Proposal [FY 23 – 1290]에 따른 주요 zkML 프레임워크에 대한 벤치마크 테스트에 따르면 Keras 2C ircom과 그 기본 circcomlib-ml은 다른 프레임워크보다 성능이 더 뛰어난 것으로 입증되었습니다.
opp/ai(opML + zkML):
ORA는 또한 개인 정보 보호를 위한 영지식 기계 학습(zkML)과 효율성 향상을 위한 낙관적 기계 학습(opML)을 통합하여 온체인 AI 맞춤형 하이브리드 모델을 생성하는 OPP/AI(Optimistic Privacy-Preserving AI on Blockchain)를 제안했습니다. 기계 학습(ML) 모델을 전략적으로 분할함으로써 opp/ai는 계산 효율성과 데이터 개인 정보 보호의 균형을 유지하여 안전하고 효율적인 온체인 AI 서비스를 가능하게 합니다.
opp/ai는 개인 정보 보호 요구 사항에 따라 ML 모델을 여러 하위 모델로 나눕니다. zkML 하위 모델은 민감한 데이터 또는 독점 알고리즘의 구성 요소를 처리하는 데 사용되며 영지식 증명을 사용하여 실행되어 데이터 및 모델의 기밀성을 보장합니다. opML 하위 모델은 개인 정보 보호보다 효율성을 우선시하는 구성 요소에 사용됩니다. 최대 효율성을 위해 opML의 낙관적 접근 방식을 사용하여 실행합니다.
요약하자면, ORA는 opML, zkML 및 opp/ai(opML과 zkML 결합)의 세 가지 인증 프레임워크를 혁신적으로 제안합니다. 다양한 인증 프레임워크는 데이터 개인 정보 보호 및 컴퓨팅 효율성을 향상시키고 블록체인 애플리케이션에 더 큰 이점을 제공합니다.
최초의 AI 오라클인 ORA는 엄청난 잠재력과 폭넓은 상상력을 갖고 있습니다. ORA는 기술의 장점을 입증하는 수많은 연구와 결과를 발표했습니다. 그러나 AI 모델의 추론 과정은 특정 복잡성과 검증 비용을 안고 있습니다. 온체인 AI의 추론 속도가 사용자 요구를 충족할 수 있는지 여부는 검증이 필요한 문제가 되었습니다. 시간을 검증하고 사용자 경험을 지속적으로 최적화한 후에 이러한 AI 제품은 체인에서 Dapp의 효율성을 향상시키는 훌륭한 도구가 될 수 있습니다.
팀 정보:
공동 창립자인 Kartin은 애리조나 대학교에서 컴퓨터 과학을 전공했으며 Tiktok에서 기술 리더로, Google에서 소프트웨어 엔지니어로 근무했습니다.
수석 과학자 Cathie는 University of Southern California에서 컴퓨터 과학 석사 학위를, 홍콩 대학에서 심리학 및 신경 과학 박사 학위를 취득했으며 Ethereum Foundation에서 zkML 연구원이었습니다.
자금 조달 정보:
올해 6월 26일 ORA는 2천만 위안의 자금 조달을 완료했다고 발표했습니다. 투자 기관으로는 Polychain Capital, HF 0, Hashkey Capital, SevenX Ventures 및 Geekcartel이 있습니다.
Grass: AI 모델의 데이터 레이어
Grass는 공용 네트워크 데이터를 AI 데이터 세트로 변환하는 데 중점을 둡니다. Grass의 네트워크는 사용자의 개인 정보를 수집하지 않고 인터넷에서 데이터를 긁어내기 위해 사용자의 초과 대역폭을 사용합니다. 이러한 유형의 네트워크 데이터는 다른 많은 산업 분야의 인공 지능 모델 및 운영 개발에 필수적입니다. 사용자는 노드를 실행하고 Grass 포인트를 얻을 수 있으며, Grass에서 노드를 실행하는 것은 Chrome 확장 프로그램에 가입하고 설치하는 것만큼 쉽습니다.
Grass는 AI 수요자와 데이터 제공자를 연결하여 "win-win" 상황을 조성합니다. 간단한 설치 작업과 향후 에어드롭 기대치가 사용자 참여를 크게 촉진하여 수요자에게 더 많은 데이터 소스를 제공한다는 것이 장점입니다. 데이터 제공자로서 사용자는 복잡한 설정이나 작업을 수행할 필요가 없으며 사용자가 인지하지 못하는 사이에 데이터 캡처, 정리 및 기타 작업을 수행할 수 있습니다. 또한 장비에 대한 특별한 요구 사항이 없으므로 사용자의 참여 임계값이 낮아지고 초대 메커니즘도 효과적으로 더 많은 사용자가 빠르게 참여할 수 있도록 촉진합니다.
Grass는 분당 수천만 개의 웹 요청에 도달하기 위해 데이터 스크래핑 작업을 수행해야 하기 때문입니다. 이를 위해서는 L1이 제공할 수 있는 것보다 더 많은 처리량이 필요하며, Grass 팀은 지난 3월 사용자와 빌더가 데이터 출처를 확인할 수 있도록 지원하는 방법으로 Rollup을 구축할 계획을 발표했습니다. ZK 프로세서를 통해 검증을 위해 메타데이터를 일괄 처리할 계획이며, 각 데이터 세트의 메타데이터에 대한 증명은 솔라나의 정산 레이어에 저장되어 데이터 원장을 생성할 예정입니다.
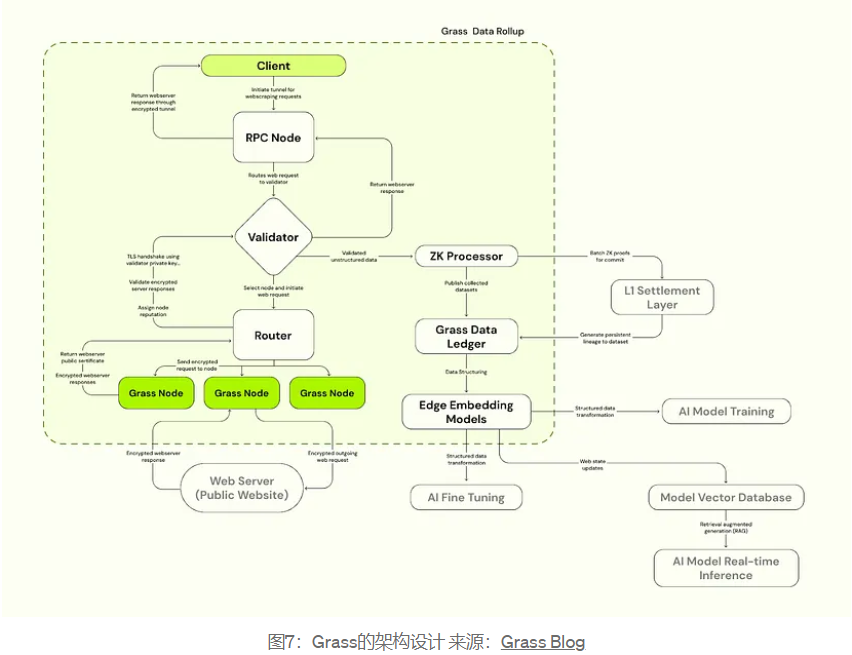
그림에 표시된 대로 고객은 유효성 검사기를 통과하고 결국 Grass 노드로 라우팅되는 웹 요청을 수행하여 웹 페이지 요청에 응답하여 해당 데이터를 크롤링하고 반환할 수 있습니다. ZK 프로세서의 목적은 Grass 네트워크에서 스크랩된 데이터 세트의 출처를 문서화하는 데 도움을 주는 것입니다. 이는 노드가 네트워크를 크롤링할 때마다 자신에 대한 식별 정보를 공개하지 않고도 보상을 받을 수 있음을 의미합니다. 수집된 데이터는 데이터 원장에 포함된 후 AI 훈련을 위한 그래프 임베딩 모델(Edge Embedding)을 통해 정리 및 구조화됩니다.
요약하자면, Grass를 사용하면 사용자는 초과 대역폭을 제공하고 네트워크 데이터를 캡처하여 개인 정보를 보호하면서 소극적 소득을 얻을 수 있습니다. 이러한 설계는 사용자에게 경제적 이익을 제공할 뿐만 아니라 AI 기업이 대량의 실제 데이터를 얻을 수 있는 분산형 방식을 제공합니다.
Grass는 사용자 참여 문턱을 크게 낮춰 사용자 참여 향상에 도움이 되지만, 실제 사용자의 참여와 '울깡패'의 유입으로 대량의 스팸 정보가 유입될 수 있으며, 이로 인해 스팸 정보가 증가할 수 있다는 점을 프로젝트 팀에서는 고려해야 합니다. 데이터 처리 부담. 따라서 프로젝트 당사자는 진정으로 가치 있는 데이터를 얻기 위해 합리적인 인센티브 메커니즘과 가격 데이터를 설정해야 합니다. 이는 프로젝트 당사자와 사용자 모두에게 중요한 영향을 미치는 요소입니다. 사용자가 에어드랍 할당에 대해 혼란스럽거나 불공정한 경우 프로젝트 측에 불신을 갖게 되어 프로젝트의 합의와 개발에 영향을 미칠 수 있습니다.
팀 정보:
창립자인 Dr. Andrej는 캐나다 요크대학교에서 컴퓨팅 및 응용수학을 전공했습니다. 최고 기술 책임자 Chris Nguyen은 다년간의 데이터 처리 경험을 갖고 있으며, 그가 설립한 데이터 회사는 IBM Cloud Embedded Excellence Award, Enterprise Technology Top 30, Forbes Cloud 100 Rising Stars 등 여러 상을 수상했습니다.
자금 조달 정보:
Grass는 2023년 12월 Polychain Capital과 Tribe Capital이 주도하는 350만 달러의 시드 라운드 자금 조달을 완료한 Wynd Network 팀이 출시한 첫 번째 제품입니다. Bitscale, Big Brain, Advisors Anonymous, Typhon V, Mozaik 등이 투자에 참여합니다. . 이전에는 No Limit Holdings가 Pre-see 자금조달 라운드를 주도했으며 총 자금조달 금액은 미화 450만 달러에 달했습니다.
올해 9월 그래스는 Hack VC가 주도하고 폴리체인(Polychain), 델파이 디지털(Delphi Digital), 브레반 하워드 디지털(Brevan Howard Digital), 래티스 펀드 등이 참여하는 시리즈 A 파이낸싱을 완료했다. 파이낸싱 금액은 공개되지 않았다.
IO.NET: 분산형 컴퓨팅 자원 플랫폼
IO.NET은 솔라나에 분산형 GPU 네트워크를 구축하여 전 세계의 유휴 네트워크 컴퓨팅 리소스를 집계합니다. 이를 통해 AI 엔지니어는 더 저렴한 비용으로 더 접근하기 쉽고 유연한 방식으로 필요한 GPU 컴퓨팅 리소스를 얻을 수 있습니다. ML 팀은 분산 GPU 네트워크에서 모델 교육 및 추론 제공 워크플로를 구축할 수 있습니다.
IO.NET은 유휴 컴퓨팅 파워를 가진 사용자에게 소득을 제공할 뿐만 아니라 소규모 팀이나 개인의 컴퓨팅 파워 부담을 크게 줄여줍니다. 솔라나는 높은 처리량과 효율적인 실행 효율성을 통해 GPU 네트워크 스케줄링에 고유한 이점을 갖고 있습니다.
IO.NET은 출시 이후 최고의 기관들로부터 많은 관심과 선호를 받아왔습니다. 코인마켓캡(CoinMarketCap)에 따르면 10월 17일 현재 토큰의 시장 가치는 미화 2억 2천만 달러를 넘어섰고, FDV는 미화 14억 7천만 달러를 넘어섰습니다.
IO.NET의 핵심 기술 중 하나는 Ray의 전용 포크를 기반으로 하는 IO-SDK입니다. (Ray는 대량의 계산을 처리하기 위해 OpenAI에서 기계 학습과 같은 AI 및 Python 애플리케이션을 클러스터로 확장하는 데 사용되는 오픈 소스 프레임워크입니다.) Ray의 기본 병렬 처리를 활용하는 IO-SDK는 Python 기능을 병렬화할 수 있으며 PyTorch 및 TensorFlow와 같은 주류 ML 프레임워크와의 통합도 지원합니다. 인메모리 스토리지를 통해 작업 간 빠른 데이터 공유가 가능해 직렬화 지연이 제거됩니다.

제품 구성 요소:
IO 클라우드: 필요에 따라 분산형 GPU 클러스터를 배포 및 관리하도록 설계되었으며 IO-SDK와 원활하게 통합되어 AI 및 Python 애플리케이션 확장을 위한 포괄적인 솔루션을 제공합니다. GPU/CPU 리소스의 배포 및 관리를 단순화하는 동시에 컴퓨팅 성능을 제공합니다. 방화벽, 액세스 제어, 모듈식 설계를 통해 잠재적인 위험을 줄이고 다양한 기능을 격리하여 보안을 강화합니다.
IO Worker: 사용자는 이 웹 애플리케이션 인터페이스를 통해 GPU 노드 작업을 관리할 수 있습니다. 컴퓨팅 활동 모니터링, 온도 및 전력 소비 추적, 설치 지원, 보안 조치 및 수익 프로필과 같은 기능이 포함됩니다.
IO Explorer: 주로 사용자에게 GPU 클라우드의 모든 측면에 대한 포괄적인 통계 및 시각화를 제공하여 사용자가 네트워크 활동, 주요 통계, 데이터 포인트 및 보상 거래를 실시간으로 볼 수 있도록 합니다.
IO ID: 사용자는 지갑 주소 활동, 지갑 잔액, 청구 수입 등을 포함한 개인 계정 상태를 볼 수 있습니다.
IO 코인: 사용자가 IO.NET의 토큰 상태를 볼 수 있도록 지원합니다.
BC 8.AI: IO.NET에서 지원하는 AI 그림 생성 웹사이트입니다. 사용자는 텍스트에서 그림까지 AI 생성 프로세스를 구현할 수 있습니다.
IO.NET은 암호화폐 채굴기의 유휴 컴퓨팅 성능, Filecoin 및 Render와 같은 프로젝트 및 기타 유휴 컴퓨팅 성능을 사용하여 백만 개 이상의 GPU 리소스를 집계하므로 인공 지능 엔지니어 또는 팀이 필요에 따라 GPU 컴퓨팅 서비스를 사용자 정의하고 구매할 수 있습니다. 전 세계의 유휴 컴퓨팅 리소스를 활용하여 컴퓨팅 능력을 제공하는 사용자는 자신의 수입을 토큰화할 수 있습니다. IO.NET은 리소스 활용을 최적화할 뿐만 아니라 높은 컴퓨팅 비용을 줄이고 더 넓은 범위의 AI 및 컴퓨팅 애플리케이션을 촉진합니다.
분산형 컴퓨팅 성능 플랫폼인 IO.NET은 사용자 경험, 풍부한 컴퓨팅 성능 리소스, 리소스 예약 및 모니터링에 중점을 두어야 합니다. 이는 분산형 컴퓨팅 성능 트랙에서 승리하기 위한 중요한 칩입니다. 그러나 이전에도 리소스 스케줄링 문제를 두고 논란이 있었고 일부에서는 리소스 스케줄링과 사용자 주문 간의 불일치에 대해 의문을 제기했습니다. 이 문제의 진위 여부를 확신할 수는 없지만, 관련 프로젝트에서는 이러한 측면의 최적화와 사용자 경험 개선에 주의를 기울여야 함을 상기시켜 줍니다. 사용자의 지원이 없으면 정교한 제품은 단지 꽃병일 뿐입니다.
팀 정보:
창립자 Ahmad Shadid는 이전에 WhalesTrader의 정량적 시스템 엔지니어였으며 한때 Ethereum Foundation의 기고자이자 멘토였습니다. 최고 기술 책임자 Gaurav Sharma는 이전에 Amazon의 수석 개발 엔지니어, eBay의 설계자, Binance의 엔지니어링 부서에서 근무했습니다.
자금 조달 정보:
2023년 5월 1일, 미화 1,000만 달러의 시드 자금 조달을 완료했다고 공식 발표되었습니다.
2024년 3월 5일 Hack VC, Multicoin Capital, 6th Man Ventures, M 13, Delphi Digital, Solana Labs, Aptos Labs, Foresight Ventures, Longhash가 주도하는 3천만 달러 규모의 시리즈 A 자금 조달을 완료했다고 발표했습니다. SevenX, ArkStream, Animoca Brands, Continue Capital, MH Ventures, Sandbox Games 등이 참여했습니다.
MyShell: 소비자와 창작자를 연결하는 AI 에이전트 플랫폼
MyShell은 소비자, 제작자 및 오픈 소스 연구원을 연결하는 분산형 AI 소비자 계층입니다. 사용자는 플랫폼에서 제공하는 AI 에이전트를 사용하거나 MyShell 개발 플랫폼에서 자체 AI 에이전트 또는 애플리케이션을 구축할 수 있습니다. MyShell은 사용자가 AI 에이전트를 자유롭게 거래할 수 있는 오픈 마켓을 제공합니다. MyShell의 AIApp 스토어에서는 가상 동반자, 거래 도우미, AIGC 유형 에이전트를 포함한 다양한 유형의 AI 에이전트를 볼 수 있습니다.
MyShell은 ChatGPT와 같은 다양한 유형의 AI 챗봇에 대한 낮은 임계값 대안으로 광범위한 AI 기능 플랫폼을 제공하여 사용자가 AI 모델 및 에이전트를 사용할 수 있는 임계값을 낮추어 사용자가 포괄적인 AI 경험을 얻을 수 있도록 합니다. 예를 들어, 사용자는 Claude를 문서 구성 및 쓰기 최적화에 사용하고 Midjourney를 사용하여 고품질 이미지를 생성할 수 있습니다. 일반적으로 이를 위해서는 사용자가 다양한 플랫폼에 여러 계정을 등록하고 일부 서비스에 대한 수수료를 지불해야 합니다. MyShell은 매일 무료 AI 할당량을 제공하는 원스톱 서비스를 제공하며, 사용자는 반복적으로 등록하고 결제할 필요가 없습니다.
또한 일부 AI 제품은 일부 지역에서 제한이 있지만 MyShell 플랫폼에서는 사용자가 일반적으로 다양한 AI 서비스를 원활하게 사용할 수 있어 사용자 경험이 크게 향상됩니다. MyShell의 이러한 장점은 사용자 경험을 위한 이상적인 선택이 되어 사용자에게 편리하고 효율적이며 원활한 AI 서비스 경험을 제공합니다.
MyShell 생태계는 세 가지 핵심 구성 요소를 기반으로 구축되었습니다.
자체 개발된 AI 모델: MyShell은 사용자가 직접 사용할 수 있는 AIGC 및 대규모 언어 모델을 포함한 여러 오픈 소스 AI 모델을 개발했습니다. 공식 Github에서 더 많은 오픈 소스 모델을 찾을 수도 있습니다.
개방형 AI 개발 플랫폼: 사용자는 AI 애플리케이션을 쉽게 구축할 수 있습니다. MyShell 플랫폼을 사용하면 제작자는 다양한 모델을 활용하고 외부 API를 통합할 수 있으며 기본 개발 워크플로와 모듈식 툴킷을 통해 아이디어를 기능적인 AI 애플리케이션으로 신속하게 변환하여 혁신을 가속화할 수 있습니다.
공정한 인센티브 생태: MyShell의 인센티브 방법은 사용자가 개인 취향에 맞는 콘텐츠를 만들도록 장려합니다. 제작자는 자신이 만든 앱을 사용하여 기본 플랫폼 보상을 받을 수 있을 뿐만 아니라 소비자로부터 자금도 받을 수 있습니다.
MyShell의 워크샵에서는 사용자가 세 가지 모드로 AI 로봇을 구축할 수 있음을 볼 수 있습니다. 전문 개발자와 일반 사용자 모두 클래식 모드를 사용하여 개발 모드에 필요한 모델 매개변수와 지침을 설정할 수 있습니다. 사용자는 자신의 모델 파일을 업로드하고 ShellAgent 모드를 사용하여 코드 없는 형태로 AI 로봇을 구축할 수 있습니다.
MyShell은 분산화 개념과 AI 기술을 결합하여 소비자, 창작자 및 연구자를 위한 개방적이고 유연하며 공정한 인센티브 생태계를 제공하기 위해 최선을 다하고 있습니다. 자체 개발한 AI 모델, 개방형 개발 플랫폼 및 다양한 인센티브 방법을 통해 사용자에게 아이디어와 요구 사항을 실현할 수 있는 풍부한 도구와 리소스를 제공합니다.
MyShell은 다양한 고품질 모델을 통합하고 있으며 팀은 사용자 경험을 개선하기 위해 계속해서 많은 AI 모델을 개발하고 있습니다. 그러나 MyShell을 사용할 때 여전히 몇 가지 문제에 직면합니다. 예를 들어 일부 사용자는 일부 모델의 중국어 지원을 개선해야 한다고 보고했습니다. 그러나 MyShell 코드 저장소를 살펴보면 팀이 지속적으로 업데이트 및 최적화하고 있으며 커뮤니티의 피드백을 적극적으로 듣고 있음을 알 수 있습니다. 지속적인 개선을 통해 앞으로도 사용자 경험이 더 좋아질 것이라고 믿습니다.
팀 정보:
공동 창업자인 Zengyi Qin은 음성 알고리즘 연구에 집중하고 있으며 MIT에서 박사 학위를 취득했습니다. 그는 칭화대학교에서 학사 학위를 취득하는 동안 많은 주요 컨퍼런스 논문을 발표했습니다. 그는 또한 로봇 공학, 컴퓨터 비전 및 강화 학습 분야에서 전문적인 경험을 갖고 있습니다. 또 다른 공동 창업자인 Ethan Sun은 옥스퍼드 대학교에서 컴퓨터 공학을 전공하고 AR+AI 분야에서 다년간의 업무 경험을 갖고 있습니다.
자금 조달 정보:
2023년 10월 560만 달러의 시드 라운드 파이낸싱. INCE Capital을 필두로 Hashkey Capital, Folius Ventures, SevenX Ventures, OP Crypto 등도 참여했습니다.
2024년 3월, 최신 Pre-A 자금 조달 라운드에서 미화 1,100만 달러의 자금을 지원 받았습니다. 이번 자금 조달은 Dragonfly가 주도했으며 Delphi Digital, Bankless Ventures, Maven 11 Capital, Nascent, Nomad, Foresight Ventures, Animoca Ventures, OKX Ventures 및 GSR이 참여했습니다. 또한 이번 자금 조달은 Balaji Srinivasan, Illia Polosukhin, Casey K. Caruso 및 Santiago Santos와 같은 엔젤 투자자들의 지원도 받았습니다.
올해 8월, Binance Labs는 6번째 시즌 인큐베이션 프로그램을 통해 MyShell에 대한 비공개 투자를 발표했습니다.
4. 시급히 해결해야 할 과제와 고려사항
트랙이 아직 초기 단계에 있지만 실무자는 프로젝트 성공에 영향을 미치는 몇 가지 중요한 요소를 고려해야 합니다. 고려해야 할 영역은 다음과 같습니다.
AI 자원의 수요와 공급 균형: Web3-AI 생태 프로젝트에서는 AI 자원의 수요와 공급 균형을 달성하고 실제 요구와 기여 의지를 갖춘 더 많은 사람들을 유치하는 방법이 매우 중요합니다. 예를 들어, 모델, 데이터, 컴퓨팅 능력이 필요한 사용자는 Web2 플랫폼에서 AI 리소스를 얻는 데 익숙할 수 있습니다. 동시에 Web3-AI 생태계에 기여하기 위해 AI 리소스 공급자를 유치하고 리소스를 얻기 위해 더 많은 수요자를 유치하며 AI 리소스의 합리적인 매칭을 달성하는 방법도 업계가 직면한 과제 중 하나입니다.
데이터 과제: 데이터 품질은 모델 훈련 효과에 직접적인 영향을 미칩니다. 데이터 수집 및 데이터 전처리 과정에서 데이터 품질을 보장하고 Wool 사용자가 가져온 대량의 정크 데이터를 선별하는 것은 데이터 프로젝트가 직면한 중요한 과제가 될 것입니다. 프로젝트 당사자는 과학적인 데이터 품질 관리 방법을 사용하고 데이터 처리 효과를 보다 투명하게 입증하여 데이터의 신뢰성을 높일 수 있으며 이는 데이터 수요자에게도 더욱 매력적일 것입니다.
보안 문제: Web3 산업에서는 악의적인 행위자가 AI 자산의 품질에 영향을 미치는 것을 방지하고 AI 자원의 보안을 보장하기 위해 블록체인 및 개인 정보 보호 기술을 통해 AI 자산의 온체인 및 오프체인 상호 작용을 구현하는 것이 필요한 고려 사항입니다. 데이터와 모델로. 일부 프로젝트 당사자가 솔루션을 제안했지만 해당 분야는 아직 구축 단계에 있습니다. 기술이 지속적으로 향상됨에 따라 더 높고 입증된 안전 표준이 달성될 것으로 예상됩니다.
사용자 경험:
Web2 사용자는 일반적으로 전통적인 운영 경험에 익숙하지만 Web3 프로젝트에는 일반적으로 복잡한 스마트 계약, 분산형 지갑 및 기타 기술이 수반되므로 일반 사용자에게는 더 높은 임계값이 있을 수 있습니다. 업계에서는 더 많은 Web2 사용자를 Web3-AI 생태계로 끌어들이기 위해 사용자 경험과 교육 시설을 더욱 최적화하는 방법을 고려해야 합니다.
Web3 사용자의 경우 효과적인 인센티브 메커니즘과 지속적으로 운영되는 경제 시스템을 구축하는 것이 장기적인 사용자 유지와 건강한 생태계 발전을 촉진하는 열쇠입니다. 동시에 Web3 분야의 효율성을 높이기 위해 AI 기술의 활용을 극대화하고, AI와 결합된 더 많은 애플리케이션 시나리오와 게임 플레이를 혁신할 수 있는 방법을 고민해야 합니다. 이는 생태학적으로 건강한 발달에 영향을 미치는 핵심 요소입니다.
Internet+의 발전 추세가 계속 진화하면서 우리는 수많은 혁신과 변화가 일어나는 것을 목격했습니다. 현재 다양한 분야의 시나리오가 AI와 결합되어 미래를 내다보면 AI+ 시대가 곳곳에서 피어나고 우리의 삶의 방식을 완전히 바꿀 수도 있습니다. Web3와 AI의 통합은 데이터의 소유권과 통제권이 사용자에게 반환되어 AI가 더욱 투명하고 신뢰할 수 있게 된다는 것을 의미합니다. 이러한 통합 추세는 더욱 공정하고 개방적인 시장 환경을 조성하고 각계각층에서 효율성 향상과 혁신적인 발전을 촉진할 것으로 기대됩니다. 우리는 더 나은 AI 솔루션을 만들기 위해 업계 구축자들이 함께 협력하기를 기대합니다.
참고자료
https://ieeeexplore.ieee.org/abstract/document/9451544
https://docs.ora.io/doc/oao-onchain-ai-oracle/introduction
https://saharalabs.ai/
https://saharalabs.ai/blog/sahara-ai-raise-43m
https://bittensor.com/
https://docs.bittensor.com/yuma-consensus
https://docs.bittensor.com/emissions#emission
https://twitter.com/myshell_ai
https://twitter.com/SubVortexTao
https://foresightnews.pro/article/detail/49752
https://www.ora.io/
https://docs.ora.io/doc/imo/introduction
https://github.com/ora-io/keras2c ircom
https://arxiv.org/abs/2401.17555
https://arxiv.org/abs/2402.15006
https://x.com/OraProtocol/status/1805981228329513260
https://x.com/getgrass_io
https://www.getgrass.io/blog/grass-the-first-ever-layer-2-data-rollup
https://wynd-network.gitbook.io/grass-docs/architecture/overview#edge-embedding-models
http://IO.NET
https://www.ray.io/
https://www.techflowpost.com/article/detail_17611.html
https://myshell.ai/
https://www.chaincatcher.com/article/2118663
감사의 말
이 새로운 인프라 패러다임에 대해서는 아직 수행해야 할 연구와 작업이 많이 있으며, 이 기사에서 다루지 않은 영역도 많습니다. 관련 연구주제에 관심이 있으시면 클로이에게 연락주세요.
이 기사에 대한 통찰력 있는 의견과 피드백을 주신 Severus와 JiaYi에게 깊은 감사를 드립니다. 마지막으로 방송에 출연해주신 지아이 고양이님께 감사드립니다.


