
如何に Claude の Dynamic Workflows を使い、深層研究を行うか
- 核心的見解:Claude Code の Dynamic Workflows(動的ワークフロー)は、6種類の構造化されたスケジューリングパターン(ルーティング、並列処理、対抗検証など)を内蔵することで、AI研究プロセスを「スマートな対話」から「自動化された研究フレームワーク」へとアップグレードさせます。これにより、従来のAI調査における目標の逸脱、早期停止、文脈の汚染といった核心的な欠陥を効果的に解決します。しかし、人間の深層研究を完全に代替するには、検証メカニズム、分野横断的思考、極限的な情報凝縮などの分野において、継続的な改善が必要です。
- 重要要素:
- 動的ワークフローの核心は、AIがタスク実行前に自動的にワークフローを設計する点にあり、問題の分解、信頼性評価、クロス削除、目標指向型の出力といった段階を含み、従来のスキルが持つ収束性や意思決定指向の欠如を補完します。
- 6つのパターンには、ルーティング(精密な振り分け)、分割と統合(並列処理による高速化)、対抗検証(自己評価バイアスの排除)、生成とフィルタリング(多様性の中からの選択)、トーナメント(競合による順位付け)、ループ(適応的な反復)が含まれ、複雑な研究のスケジューリングをカバーします。
- 対抗検証モードは、構造的にAIがユーザーに迎合する「確証バイアス」を排除します。独立したエージェントが反証的に結論を検証しますが、検証者がワークフローを誤った方向に導くことを避けるため、検証は再現可能な事実に基づくべきであり、単なる意見に基づくべきではありません。
- 筆者が自作した deep-research システムと比較して、公式ワークフローは問題の分解、情報の信頼性評価、投票ベースのクロス削除、および常に元の目標に焦点を当てた出力を追加しており、冗長な対話回数を大幅に削減します(十数回から3~4回へ)。
- AIには依然として3つの大きな限界があります。ブロックチェーン技術などの最先端分野では、デフォルトで遅延のある公式ドキュメントに依存し、オンチェーンの事実データを参照しないこと。分野横断的な深い思考が不足しており、主流の思考モデルは全く新しい課題に対処しにくいこと。ソリューションの検証にはコストとメカニズムのトレードオフの考慮が必要であり、汎用性と矛盾すること。
- 極限的な情報凝縮は、対象読者の背景知識を正確に理解することに依存しており、AIが「擬人化された平易な表現」と「洗練された専門的な要約」を自動的に切り替えることは困難です。これは人間の研究者にしか代替できない領域です。
この3年間で、私はAIを活用した業界調査なしではいられなくなり、そのために一連のスキルや補助システムを構築し、情報の選別、整理、関連付け、検証、蓄積を行ってきました。
そして今週、Claude Codeのダイナミックワークフローを深く体験して初めて、「人間は大きな時代の流れに逆らうべきではない」という言葉の真の意味を理解しました。
改めて考えてみます:AI時代において、人間が行うべき深いリサーチとは何か、そして私とAIの協調・補完関係をどのように構築するべきか。
一、調査の落とし穴から始めよう
技術調査を行うことは、実は落とし穴に満ちた行為です(人間にとってもAIにとっても)。なぜなら、調査を始めると大量の情報を受け取り、情報や意見が増えるほど、結論は曖昧になっていくからです。そのため、常に目標そのものに立ち返ることを理解する必要があります。
これこそが、これまでAIが十分に優れていなかった点です。注意と連想の観点から見ると、AIは人間よりも現在の情報量に囚われやすく、真に価値のある分野横断的な連想が苦手です。
もちろん、AIが優れている点はその実行力です。エージェントの形で情報を階層的に探し、整理し、要約することができ、細部のロスを完全に回避できます。
この半年間、私はほとんど外部に公众号(WeChat公式アカウント)を発信していませんが、業界の主要な戦場はほぼすべて網羅的に注目し、研究してきました。そして、このインプットとアウトプットを支えているのは、自身のディープリサーチシステムです。
先週、Claude CodeがDynamic Workflowsという機能をリリースしたのを受けて、互いに競わせてみようと思いました。このデフォルトの能力が、私自身のシステムを完全に凌駕できるのかどうかを。
二、Dynamic Workflowsとは何か
Dynamic Workflows(動的ワークフロー)の核心的な考え方は次の通りです:タスクを実行する前に、まずAIがそのタスクを完了するためにどのようなワークフローを使うべきかを自律的に設計し、その後で実行を開始する。
これは、以前私たちが使っていた「計画モード」や「スキル」とは本質的に異なります。計画モードはタスクをより細かく分割しますが、必ずしも合理的なワークフローに沿っているとは限らず、プロンプトの指定がなければ、検収指標が追加されることはほとんどありません(これはリサーチにとって極めて重要です)。同様に、プロンプトが設定されている場合にのみ、AIはより適切にハーネスルール(検証ルール)を事前設定することができます。
しかし、動的ワークフローは、検収ロジック、結果の収束、対抗検証といった要素を自動的に組み込みます。
トリガー方法は非常に簡単で、cc内で/deep-research を使用し、そこに調査テンプレートやエントリー資料を提供するだけです。動的ワークフローの機能だけを個別に使用したい場合は、プロンプトで指示するか、単に「ultracode」と伝えます。使用前に注意点として、トークン消費量は通常の数十倍になります。
三、内蔵された6つのワークフローモード
動的ワークフローの基盤は、公式がまとめた6つのコアスケジューリングモードです。これが、通常の対話/エージェント/スキルよりも強力な理由です。
実際、この6つのモードの背後には、たった2つの核心的な問題しかありません:タスクをどのように分解するか?結果をどのように統合するか? 6つに分かれているのは、本質的にこの2つの要素の組み合わせです。
3.1 ルーティングモード(Classify-And-Act)
まず1つのエージェントがタスクのタイプを判別し、そのタスクを最も適した専門エージェントに振り分けて処理させます。核心的なロジックはルーティングの選択ロジックであり、並列処理や反復処理ではありません。1つのタスクは1つのパスのみを辿り、他のパスは全く実行されません。
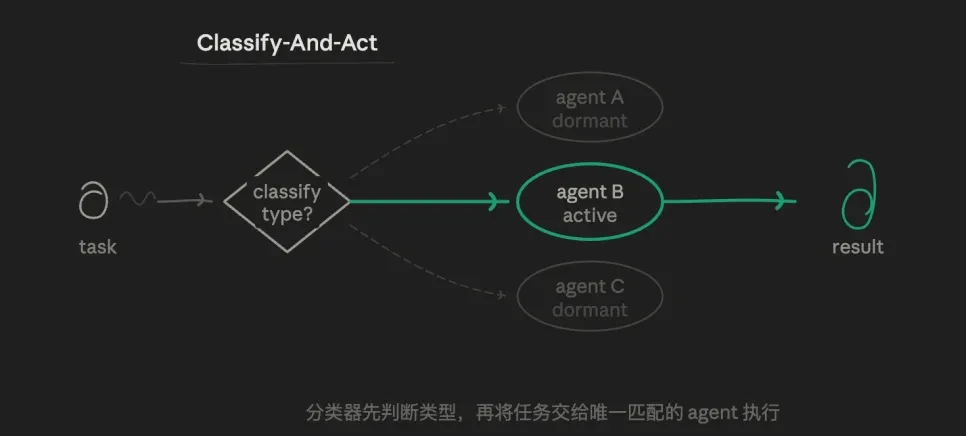
例えば、私は3つのサブエージェントロールを事前に設定できます:データを厳密に検証する分析エージェント、執筆が得意なアウトプットエージェント、穴を専門的に見つけるチャレンジエージェント。ルーティング層が、現在のサブタスクがどのエージェントに適しているかを判断し、1つのエージェントに全てを任せることはありません。
このモードの価値は、精度と効率性にあります。各エージェントのプロンプトは高度に独立しており、他の目標に干渉されることなく、垂直的で深い探索が可能です。トークン消費は最小限で、応答速度は最速です。責任範囲が非常に明確です。
欠点も顕著で、境界が曖昧なタスク(例えば「技術的な問題であり、同時にアカウントの問題でもある」ようなケース)の処理能力が弱いことです。
3.2 分割統合(Fan-out & Merge)
これも私が最もよく使うモードです。核心的なロジックは並列処理+統合です。タスクをN個の独立したサブタスクに分割して同時に実行し、全てが完了したら一括で統合します。

利点は速度と分離性です。総所要時間は最も遅いサブタスクとほぼ同じであり、全てのサブタスクの合計時間ではありません。各サブタスクは独立したコンテキストを持ち、互いに干渉せず、あるサブタスクのノイズが他のサブタスクを汚染することもありません。
弱点は、トークンコストが逐次処理のN倍になることと、統合層(Synthesize)自体にも難しさがあることです。N方向からの構造が一貫しない出力をどのように融合するかは、設計上の課題です。サブタスクの分割が適切でないと、漏れや重複が発生する可能性があります。
3.3 対抗検証(Adversarial Verification)
核心的なロジックは検証です。同じ結論に対して、複数のエージェントに「反論」の観点から挑戦させ、過半数の票を得た場合のみ合格とします。
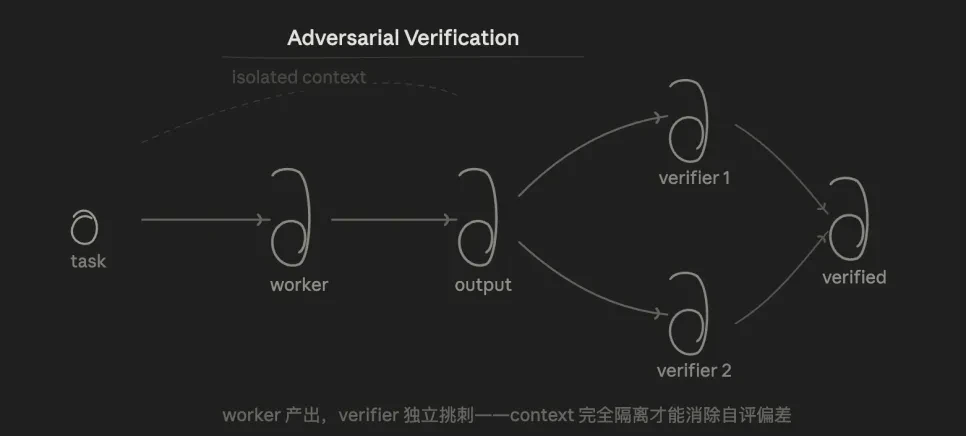
利点は、検証エージェント(Verifier)がワーカーエージェント(Worker)の思考プロセスを知らず、結果のみを見るため、構造的に「モデルに自身のコードをチェックさせる」際の自己評価バイアスを排除できることです。
このモードは、私が長年悩まされてきた問題を解決してくれます。私たちはしばしば口語的な表現でAIと会話しますが、AIは私たちの期待に沿うように回答する傾向があり、「確証バイアス」が生じやすくなります。対抗検証を用いることで、AIに反例を探すことを強制し、データや実験に基づいて検証させ、あなたの考えに迎合するのを防ぎます。
しかし、検証において、もし検証エージェントが誤った判断を下した場合、ワーカーエージェントを誤った方向に導き、検証エージェントに迎合させてしまう可能性があります。そのため、優先的には再現可能な事実に基づくべきであり、意見に頼るべきではありません。
冗談めかして言えば、AIに問題を見つけさせると、無限に問題を見つけ出します。そのため、問題を見つける範囲を制限する必要があります。
3.4 生成とフィルタリング(Generate & Filter)
核心的なロジックは発散させてから収束させることです。意図的に過剰な候補を生成し、ルーブリック(評価基準)を用いて本質的なものだけに絞り込み、信頼度の高い結果のみを出力します。

1つのエージェントに「まあまあ」の答えを1つ出力させるよりも、10個生成させてから検証層で選別した方が良い、という考え方です。したがって、利点は多様性にあります。複数のジェネレーター(Generator)が異なる戦略やプロンプトを用いることで、人間が事前に予想しにくい解法を生み出し、フィルタリングのステップによって最終出力の品質が高度に集中します。
弱点は、フィルター(Filter)のルーブリックの品質が最終的な効果を直接決定することです。ルーブリックの設計を誤ると、プロセス全体が台無しになります。
適したシナリオは、事前に正解がわからない場合、複数の可能性から最適なものを選びたい場合、多様性が明確に求められる場合です。
Fanout-And-Synthesizeとは表面的に似ているだけです:両者とも「マルチパスの並列処理 → 単一の出力」であり、最も混同されやすいものです。
重要な違いは意図にあります。Fanoutの各パスはタスクの異なる部分を処理し、結果は相互補完的であり、統合時に全てのパスが貢献します。一方、Generate-And-Filterの各パスは同じタスクを処理し、結果は競合的であり、統合時には大部分が破棄されます。前者は「パズル」であり、後者は「美しさを競う」ものです。
3.5 トーナメントモード(Tournament)
核心的なロジックは競争による淘汰です。N個のエージェントがそれぞれ独立して同じタスクを実行し、ペアワイズ(pairwise)比較によるラウンドごとの淘汰を経て、最終的に最適解を選出します。

これは以前、私が手動で行っていたことです。同じコード変更に対して2、3のバージョンを実行し、AIにどちらが良いかを比較させていました。今ではこれをワークフロー内に直接組み込むことができます。
利点は評価の安定性です。ペアワイズ比較(「AとBではどちらが良いか?」)は、絶対評価(「Aにスコアを付けてください」)よりもはるかに安定しており、評価基準の変動という問題を排除できます。複数回の競争を経た結果、最終的に勝者の信頼性は高くなります。
Generate-And-Filterとも表面的に似ています:両者とも複数の候補から最適なものを選びます。重要な違いは選抜メカニズムにあります。Tournamentはペアワイズジャッジ(pairwise judge)による比較を使用し、「候補同士を競わせる」ものです。ルーブリックが定量化しにくく、判断が本質的に相対的である場合に、より信頼性が高くなります。
3.6 ループモード(Loop)
核心的なロジックは適応的イテレーションです。絶えず試行し、障害に遭遇するとエラー情報を収集し、コンテキストを補完し、再試行を続け、検収条件を満たすまで繰り返します。

本質的には、AIのランダム性に対抗するものです。何度か試せば、より良い結果に巡り合う可能性が高まります。しかし、より洗練された方法は、対抗検証と組み合わせ、各ループをより多くの情報を持って実行させることであり、単なるランダム性に頼るのではありません。
利点は、作業量が未知のタスクに対する処理能力です。他の5つのモードはタスクの範囲が確定していることを前提としていますが、Loop Until Doneは「作業が何ラウンド必要かわからない」状況を処理できる唯一のモードです。
弱点は、潜在的な制御不能のリスクです。停止条件の設計が悪いと無限ループに陥る可能性があります。各ラウンドのエージェントは新しいコンテキストを持ち、ラウンドをまたいで状態を蓄積することはできません(明示的にファイルに書き出す場合を除く)。
四、自作スキルと公式ワークフローの対決
動的ワークフローが登場する前、私は独自のディープリサーチ(deep-research)システムを設計していました。そのスキルのロジックはおおよそ次のようなものでした:
- 単純な情報だけを与える(例えば、某プロジェクトが新機能をリリースしたなど)
- AIに関連する全ての資料を検索させる:公式ドキュメント、ソースコード、市場の世論
- 情報を意味のある要約に圧縮する
- 複数のエージェントロールが対抗分析を行い、レポートを生成する
- 自動重複排除を行う(マルチエージェントの内容は重複率が高いため)
しばらく使ってみて、結構使いやすいと感じていました。しかし、根本的な欠点がありました:目標指向による収束が欠けていることです。
また、たとえ第5ステップの重複排除があっても、価値のある情報が削除されてしまうことがよくありました。重複排除をしなければ、スキルは簡単に万字超の長文を生成し、情報は豊富ですが、「この件があなたにとって何の関係があるのか、あなたはどうすべきか」を直接教えてくれません。
しかし、研究とは「意思決定」に資するためのものです。だからこそ、多くのスキルは研究そのもので止まってしまい、80点まではいっても、最も重要な20点が欠けてしまうのです。
その結果、AIが初步的な研究を完了した後も、さらに10回の思考と対話を重ね


