
砸崩存储股900亿美元的谷歌AI论文,被指控实验造假
- 核心的な見解:GoogleのAIメモリ圧縮技術「TurboQuant」に関する論文が、比較実験における不公平性、先行研究の不十分な引用、および性能優位性の歪曲の疑いで学術界に論争を引き起こし、その市場プロモーションは直接的に世界のストレージチップセクターに激しい変動をもたらした。
- 重要な要素:
- 核心的な論争の主張:論文は、RaBitQアルゴリズムとの重要な技術的関連性を十分に説明しておらず、速度比較において、RaBitQにはシングルコアCPUのPythonスクリプトを使用した一方で、自社技術にはA100 GPUを使用しており、不公平な比較を構成していると指摘された。
- 市場の激しい反応:Googleの公式ブログがこの論文をプロモートした後、市場はAIメモリ需要の減少を懸念し、Micron、SanDiskなどのストレージチップ株の時価総額が単日で9000億ドル以上蒸発した。
- 技術的貢献は事実:独立したコミュニティによる検証は、TurboQuantアルゴリズムの圧縮効果が基本的に事実であり、数学的レベルでの貢献が実在することを示している。
- 機関アナリストによる反論:Morgan Stanleyなどの機関アナリストは、この技術が特定のキャッシュ(KV Cache)のみを圧縮する通常の効率改善に過ぎず、効率向上がむしろより大規模なAI導入を刺激し、最終的にはメモリ需要を増加させる可能性があると指摘している。
- 伝達チェーンのリスクが顕在化:この出来事は、既存の学術論文を市場向けのナラティブに再包装する際に、実験バイアスや表現の問題が存在する場合、金融市場に大きな衝撃を与えるシステミック・リスクを浮き彫りにした。
原文著者:深潮 TechFlow
Googleが「AIのメモリ使用量を1/6に圧縮」と称する論文が先週、Micron、SanDiskなどのグローバルなストレージチップ株の時価総額9000億ドル以上の蒸発を引き起こした。
しかし、論文発表からわずか2日後、アルゴリズムが「圧倒した」とされる比較対象であるチューリッヒ工科大学のポスドク研究員、高健揚氏が万字の公開書簡を発表し、Googleチームが実験で競合手法をシングルコアCPUのPythonスクリプトでテストした一方、自社手法にはA100 GPUを使用し、投稿前に問題を指摘されながらも修正を拒否したと告発した。Zhihuでの閲覧数は迅速に400万を突破し、Stanford NLPの公式アカウントが転載し、学界と市場が同時に揺れ動いた。
この論争の核心的な問題は複雑ではない:Googleが公式に大規模に宣伝し、直接的に世界的なチップセクターのパニック売りを引き起こしたAIトップカンファレンス論文が、体系的に先行研究を歪曲し、意図的に作られた不公平な実験を通じて、虚偽の性能優位性の物語を構築したのか?
TurboQuantが行ったこと:AIの「下書き用紙」を元の6分の1の厚さに圧縮
大規模言語モデルが回答を生成する際、計算しながら以前に計算した内容を参照する必要がある。これらの中間結果は一時的にVRAMに保存され、業界では「KV Cache」(キー・バリューキャッシュ)と呼ばれる。会話が長くなるほど、この「下書き用紙」は厚くなり、VRAM消費量が増大し、コストも高くなる。
Google研究チームが開発したTurboQuantアルゴリズムの核心的な売りは、この下書き用紙を元の1/6に圧縮しつつ、精度損失ゼロ、推論速度最大8倍向上を謳うことだ。論文は2025年4月に学術プレプリントサーバーarXivで初公開され、2026年1月にAI分野のトップカンファレンスICLR 2026に採録、3月24日にGoogle公式ブログで再包装・宣伝された。
技術的側面では、TurboQuantのアプローチは簡単に言えば:まず数学的変換を用いて乱雑なデータを統一フォーマットに「洗い」、次に事前計算された最適圧縮テーブルで個別に圧縮し、最後に1ビットの誤り訂正機構で圧縮による計算誤差を修正する。コミュニティによる独立実装はその圧縮効果が基本的に事実であることを検証しており、アルゴリズムレベルでの数学的貢献は実在する。
論争はTurboQuantが使えるかどうかではなく、Googleがそれが「競合を遥かに凌駕する」ことを証明するために、何をしたかにある。
高健揚氏の公開書簡:三つの告発、いずれも核心を突く
3月27日午後10時、高健揚氏はZhihuに長文を投稿し、同時にICLR公式査読プラットフォームOpenReviewに正式コメントを提出した。高氏はRaBitQアルゴリズムの筆頭著者であり、このアルゴリズムは2024年にデータベース分野のトップカンファレンスSIGMODに発表され、同じ種類の問題——高次元ベクトルの効率的な圧縮——を解決するものだ。
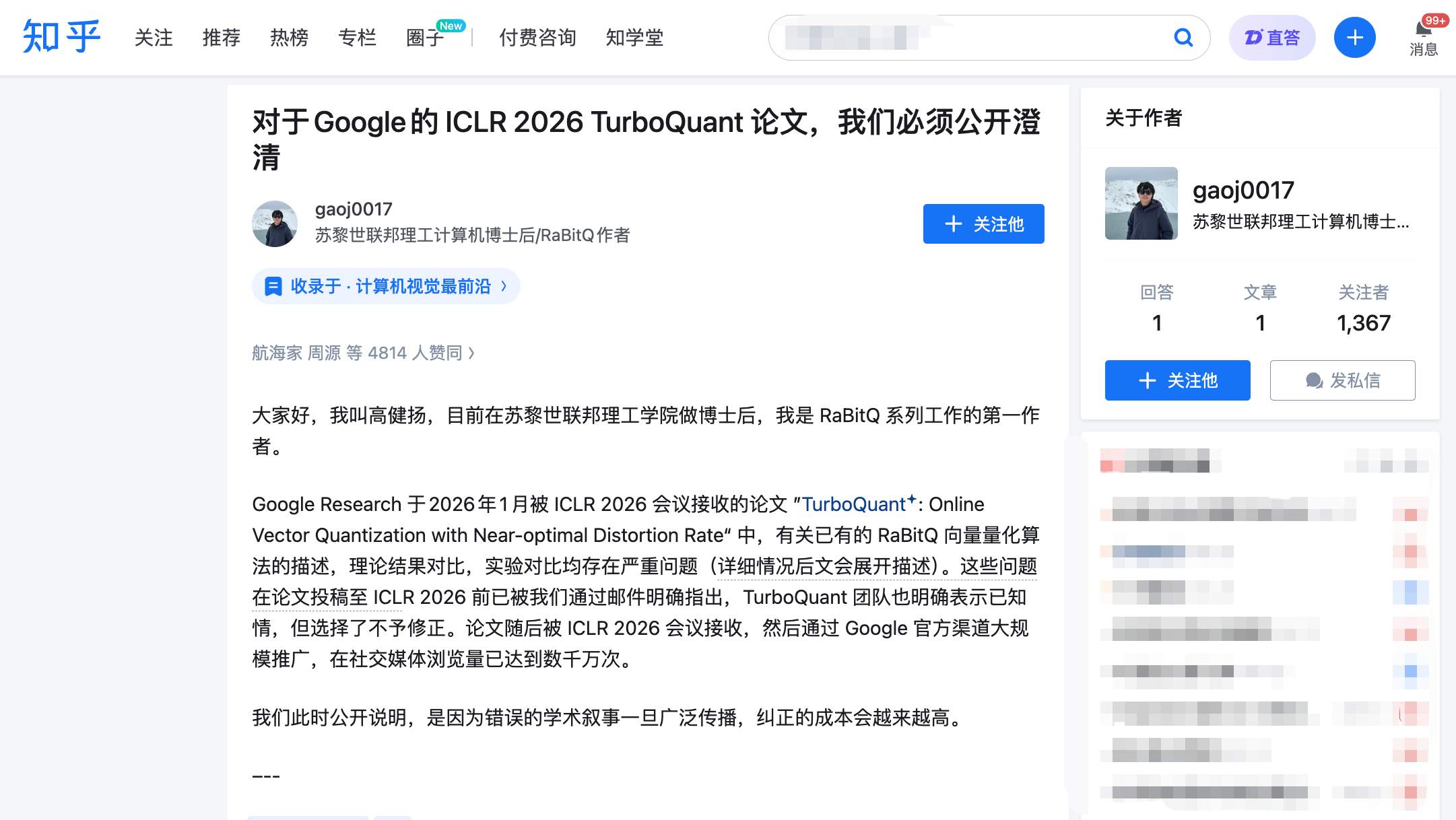
彼の告発は三つに分かれており、それぞれにメール記録とタイムラインが裏付けられている。
告発一:他者の核心的手法を使用しながら、全文で言及しない。
TurboQuantとRaBitQの技術的核心には、決定的に重要な共通ステップがある:データを圧縮する前に、まずデータに「ランダム回転」を施す。この操作の役割は、元々不規則に分布していたデータを予測可能な均一分布に変え、圧縮の難易度を大幅に下げることだ。これは二つのアルゴリズムで最も核心的で、最も類似した部分である。
TurboQuantの著者自身も査読返答でこの点を認めているが、論文の全文を通じてこの方法とRaBitQとの関連性を正面から説明することはなかった。さらに重要な背景は:TurboQuantの第二著者であるMajid Daliri氏が2025年1月、自発的に高健揚氏のチームに連絡し、RaBitQのソースコードを基に書き直したPython版のデバッグを手伝ってほしいと依頼したことだ。メールには再現手順とエラー情報が詳細に記述されており——言い換えれば、TurboQuantチームはRaBitQの技術的詳細を熟知していた。
ICLRの匿名査読者も独立して両者が同じ技術を使用していると指摘し、十分な議論を求めた。しかし最終版論文では、TurboQuantチームは議論を補足しないばかりか、原本の本文中にあったRaBitQへの(すでに不完全な)記述を付録に移動させた。
告発二:根拠なく相手の理論を「次善」と称する。
TurboQuant論文はRaBitQに直接「理論的に次善」(suboptimal)というレッテルを貼り、その理由としてRaBitQの数学的分析が「比較的粗雑」であることを挙げた。しかし高健揚氏は、RaBitQの拡張版論文がその圧縮誤差が数学的に最適限界に達していることを厳密に証明していると指摘する——この結論は理論計算機科学のトップカンファレンスで発表されている。
2025年5月、高健揚氏のチームは複数回のメールでRaBitQ理論の最適性について詳細に説明した。TurboQuant第二著者のDaliri氏は、全著者に伝えたことを確認した。しかし論文は最終的に「次善」という表現を残したままで、反論論拠は一切示さなかった。
告発三:実験比較で「片手で相手を縛り、もう片手で刀を持つ」。
これは全文で最も破壊力のある告発だ。高健揚氏は、TurboQuant論文が速度比較実験で二重の不公平条件を重ねたと指摘する:
第一に、RaBitQ公式は最適化されたC++コード(デフォルトでマルチスレッド並列処理をサポート)を提供しているが、TurboQuantチームはこれを使用せず、自身が翻訳したPython版でRaBitQをテストした。第二に、RaBitQをテストする際にはシングルコアCPUを使用しマルチスレッドを無効化した一方、TurboQuantにはNVIDIA A100 GPUを使用した。
この二つの条件が重なった効果は:読者が目にする結論は「RaBitQはTurboQuantより数桁遅い」だが、この結論の前提がGoogleチームが競合の手足を縛った上で競走させたことにあるとは知りようがない。論文ではこれらの実験条件の差異が十分に開示されていなかった。
Googleの反応:「ランダム回転は汎用技術、すべての論文を引用することは不可能」
高健揚氏の開示によれば、TurboQuantチームは2026年3月のメール返信で次のように述べたという:「ランダム回転とJohnson-Lindenstrauss変換の使用は、すでにこの分野の標準技術であり、これらの方法を使用したすべての論文を引用することは不可能です。」
高健揚氏のチームは、これは論点のすり替えだと考える:問題はランダム回転を使用したすべての論文を引用するかどうかではなく、RaBitQが全く同じ問題設定の下で、この方法をベクトル圧縮と組み合わせ、その最適性を証明した最初の研究であり、TurboQuant論文は両者の関係を正確に記述すべきだったということだ。
Stanford NLP Groupの公式Xアカウントが高健揚氏の声明を転載した。高健揚氏のチームはすでにICLR OpenReviewプラットフォームに公開コメントを投稿し、ICLR大会議長及び倫理委員会に正式な苦情を提出、今後さらにarXivに詳細な技術報告を公開する予定だ。
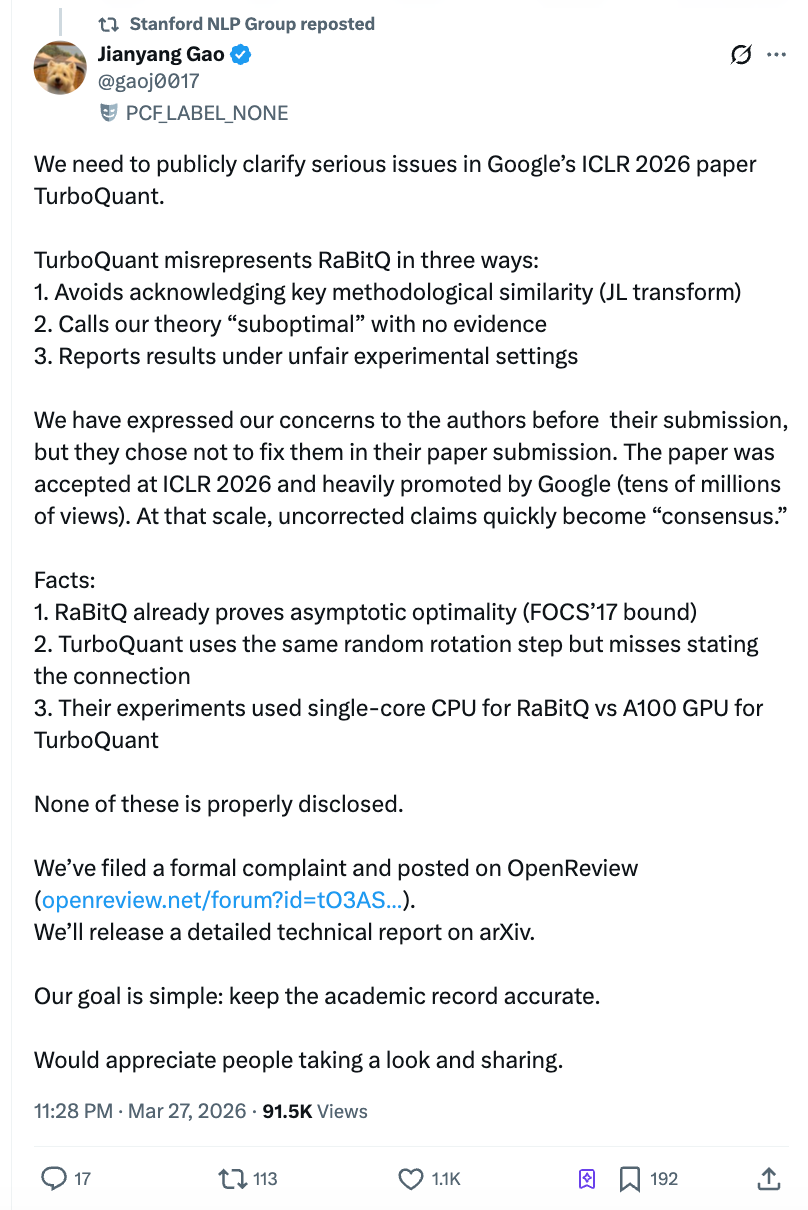
独立系技術ブロガーのDario Salvati氏は分析の中で比較的中立的な評価を下している:TurboQuantは数学的方法において確かに真の貢献があるが、RaBitQとの関係は論文が述べるよりもはるかに密接である。
9000億ドルの時価総額蒸発:論文論争と市場パニックの重なり
この学術論争が発生したタイミングは極めて微妙だ。Googleが3月24日に公式ブログでTurboQuantを発表した後、世界的なストレージチップセクターは激しい売りに襲われた。CNBCなど複数メディアの報道によれば、Micron Technologyは6営業日連続で下落し、累計下落率は20%を超え;SanDiskは単日で11%下落;韓国のSK Hynixは約6%下落、Samsung Electronicsは約5%下落、日本のKioxiaは約6%下落した。市場のパニックロジックは単純明快だった:ソフトウェア圧縮がAI推論のメモリ要求を6分の1に削減できるなら、ストレージチップの需要見通しは構造的に下方修正されるだろう。
Morgan StanleyのアナリストJoseph Moore氏は3月26日のリサーチノートでこのロジックに反論し、MicronとSanDiskの「オーバーウェイト」評価を維持した。Moore氏は、TurboQuantが圧縮するのはKV Cacheという特定タイプのキャッシュに過ぎず、全体のメモリ使用量ではなく、「通常の生産性向上」と位置づけた。Wells FargoのアナリストAndrew Rocha氏も同様にJevonsのパラドックスを引用し、効率向上によるコスト削減はむしろより大規模なAI導入を刺激し、最終的にはメモリ需要を押し上げる可能性があると指摘した。
古い論文、新しい包装:AI研究から市場ストーリーへの伝達チェーンのリスク
技術ブロガーのBen Pouladian氏の分析によれば、TurboQuant論文は2025年4月にすでに公開されており、新規研究ではない。3月24日にGoogleが公式ブログで再包装・宣伝したが、市場はそれを全く新しいブレークスルーとして価格形成した。この「古い論文、新しい発表」という宣伝戦略は、論文に存在する可能性のある実験バイアスと相まって、AI研究が学術論文から市場ストーリーへと伝達されるチェーンにおけるシステミック・リスクを浮き彫りにしている。
AIインフラ投資家にとって、ある論文が「数桁」の性能向上を達成したと主張する時、まず問うべきはベンチマーク比較の条件が公平であるかどうかだ。
高健揚氏のチームは、問題の正式な解決に向けて引き続き推進することを明確に表明している。Google側は、公開書簡の具体的な告発に対してはまだ正式な回答を行っていない。


