
Xの新アルゴリズムが明らかに:「いいね」はほぼ無価値、この行動の価値は150倍に
- 核心的な視点:X(旧Twitter)が新バージョンの推薦アルゴリズム「Phoenix」をオープンソース化。その核心的な変化は、人手で定義された特徴に依存する旧アルゴリズムから、完全にAI大規模言語モデル(Grok transformer)によって駆動されるモードへと転換し、ユーザーの15種類のインタラクション行動を予測することでコンテンツを順位付けするものであり、これはコンテンツ配信の根本的なロジックを大きく変えるものである。
- 重要な要素:
- アルゴリズムアーキテクチャの革新:新バージョンのPhoenixは手作業による特徴量エンジニアリングを完全に廃止し、代わりにGrok transformerモデルを使用し、ユーザーの履歴行動シーケンス(例:いいね、返信、ブロック)に基づいてコンテンツを予測・推薦する。
- コンテンツ順位付けメカニズム:アルゴリズムは、ユーザーがコンテンツに対して起こす可能性のある15種類のポジティブ(例:返信、リツイート)およびネガティブ(例:通報、ブロック)行動の確率を予測し、重み付けして合計することで総合スコアを算出し、コンテンツの順位を決定する。
- クリエイター戦略の変化:旧バージョンの「ベストな投稿時間」などのテクニックは無効化され、クリエイターは積極的にコメントに返信すること(非常に高い重み)が奨励され、ユーザーのブロックなどのネガティブ行動を引き起こすことを避け、外部リンクは本文ではなくコメント欄に配置することが推奨される。
- 透明性と限界:今回のオープンソース化により、完全なシステムアーキテクチャとロジックが提供されたが、具体的な重みパラメータ、モデルの内部パラメータ、および学習データは公開されておらず、「完全な透明性」にはまだ距離がある。
原文著者:David、深潮 TechFlow
1月20日の午後、Xが新バージョンの推薦アルゴリズムをオープンソース化しました。
Muskの付けた返信がなかなか面白い:「このアルゴリズムがバカげていることは分かっているし、まだ大幅な改良が必要だ。しかし、少なくとも我々がリアルタイムで改善に奮闘している様子を見ることができる。他のソーシャルプラットフォームはこんなことはできないだろう。」
この言葉には二つの意味がある。一つはアルゴリズムに問題があることを認めること、もう一つは「透明性」を売りにすることだ。
これはXが二度目にアルゴリズムをオープンソース化したことになる。2023年のバージョンのコードは3年間更新されておらず、すでに実際のシステムからかけ離れていた。今回は完全に書き直され、コアモデルが従来の機械学習からGrok transformerに変更され、公式の説明では「手作業による特徴量エンジニアリングを完全に排除した」とされている。
分かりやすく言うと:以前のアルゴリズムはエンジニアが手動でパラメータを調整していたが、今はAIが直接あなたのインタラクション履歴を見て、あなたのコンテンツを推薦するかどうかを決める。
コンテンツクリエイターにとって、これは以前の「何時に投稿するのがベストか」「どんなタグを付ければフォロワーが増えるか」といったような占い的な手法が通用しなくなる可能性があることを意味する。
我々もオープンソース化されたGithubリポジトリを調べてみたが、AIの支援のもと、コードの中に確かにいくつかのハードロジックが隠されており、掘り下げる価値があることが分かった。
アルゴリズムロジックの変化:手動定義から、AIによる自動判断へ
まず新旧バージョンの違いをはっきりさせておこう。そうしないと、後の議論が混乱しやすい。
2023年にTwitter(現X)がオープンソース化したバージョンはHeavy Rankerと呼ばれ、本質的には従来の機械学習だった。エンジニアは数百の「特徴量」を手動で定義する必要があった:この投稿に画像はあるか、投稿者のフォロワー数はいくつか、投稿時間から現在までの経過時間はどれくらいか、投稿にリンクは含まれているか...など。
そして各特徴量に重みを付け、様々な組み合わせを試して、どの組み合わせが効果的かを調べていた。
今回オープンソース化された新バージョンはPhoenixと呼ばれ、アーキテクチャが全く異なる。よりAI大モデルに依存するアルゴリズムと理解してよい。コアはGrokのtransformerモデルを使用しており、ChatGPTやClaudeが使用している技術と同じ種類だ。
公式READMEドキュメントには率直にこう書かれている:「We have eliminated every single hand-engineered feature。」(我々は手作業で設計された特徴量を一つ残らず排除した。)
従来のように手作業でコンテンツの特徴を抽出するルールは、一つも残さず、すべて削除された。
では現在、このアルゴリズムは何を基準にコンテンツの良し悪しを判断するのか?
答えはあなたの行動シーケンスによる。あなたが過去に何に「いいね」したか、誰に返信したか、どの投稿で2分以上滞在したか、どのようなアカウントをブロックしたか。Phoenixはこれらの行動をtransformerに与え、モデル自身に法則を学習させ、要約させる。
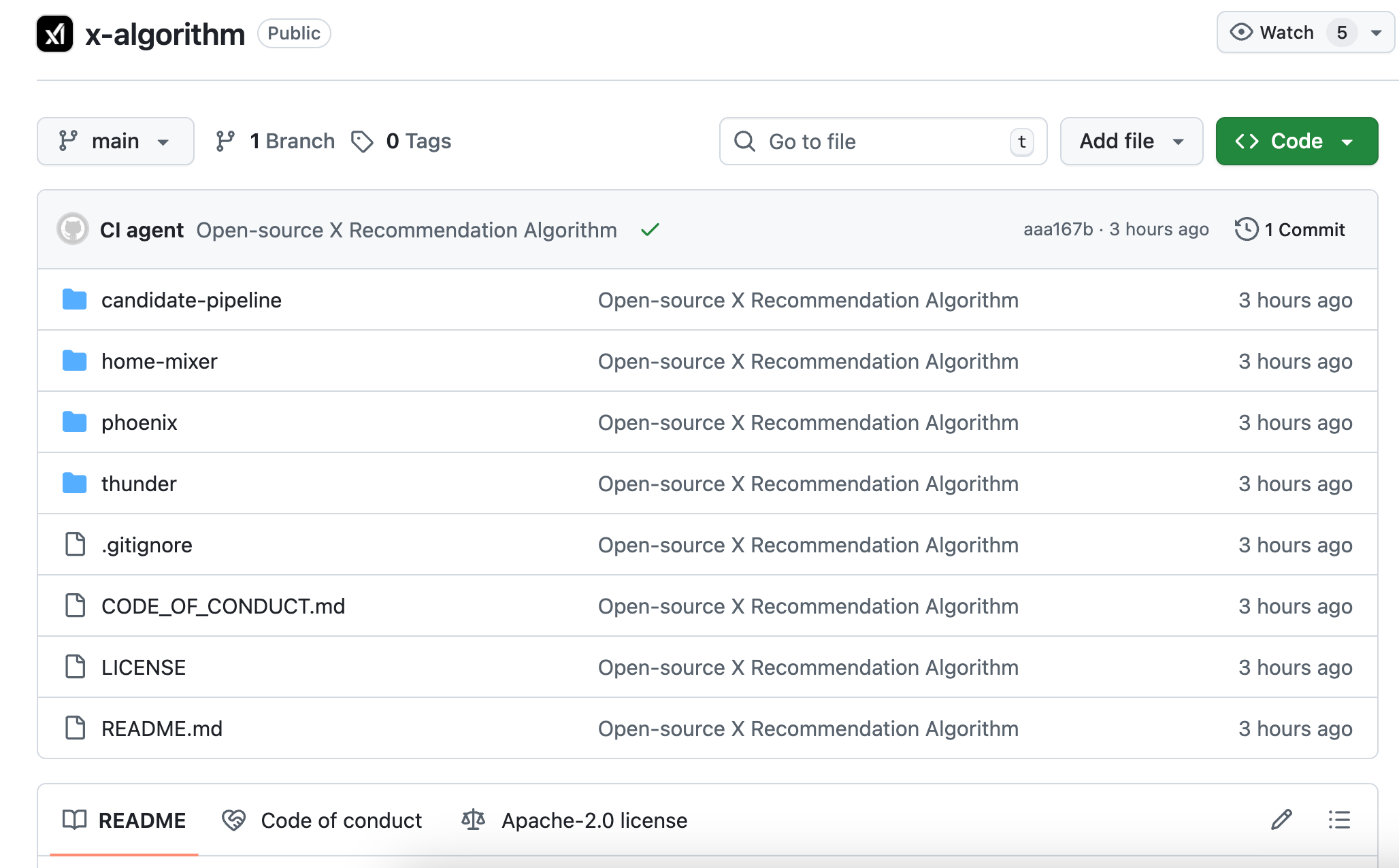
例えて言うなら:旧アルゴリズムは手作業で作成された採点表のようで、各項目にチェックを入れて点数を計算する。
新アルゴリズムはあなたのすべての閲覧履歴を見たAIのようで、直接あなたが次に見たいものを推測する。
クリエイターにとって、これは二つのことを意味する:
第一に、以前の「ベストな投稿時間」「ゴールデンタグ」のようなテクニックの参考価値が低下する。なぜなら、モデルはもはやこれらの固定された特徴量を見ず、各ユーザーの個人の嗜好を見るからだ。
第二に、あなたのコンテンツが推薦されるかどうかは、ますます「あなたのコンテンツを見た人がどのように反応するか」に依存するようになる。この反応は15種類の行動予測として定量化されており、次の章で詳しく説明する。
アルゴリズムはあなたの15種類の反応を予測している
Phoenixは推薦待ちの投稿を取得すると、現在のユーザーがこのコンテンツを見たときに生じる可能性のある15種類の行動を予測する:
- ポジティブ行動:例:いいね、返信、リツイート、引用リツイート、投稿をクリック、著者のプロフィールをクリック、動画の半分以上を視聴、画像を展開、共有、一定時間以上滞在、著者をフォロー
- ネガティブ行動:例:「興味なし」をクリック、著者をブロック、著者をミュート、通報
各行動は予測確率に対応する。例えば、モデルはあなたがこの投稿に「いいね」する確率が60%、この著者をブロックする確率が5%などと判断する。
そしてアルゴリズムは単純なことを行う:これらの確率にそれぞれの重みを掛け、合計して総合スコアを得る。
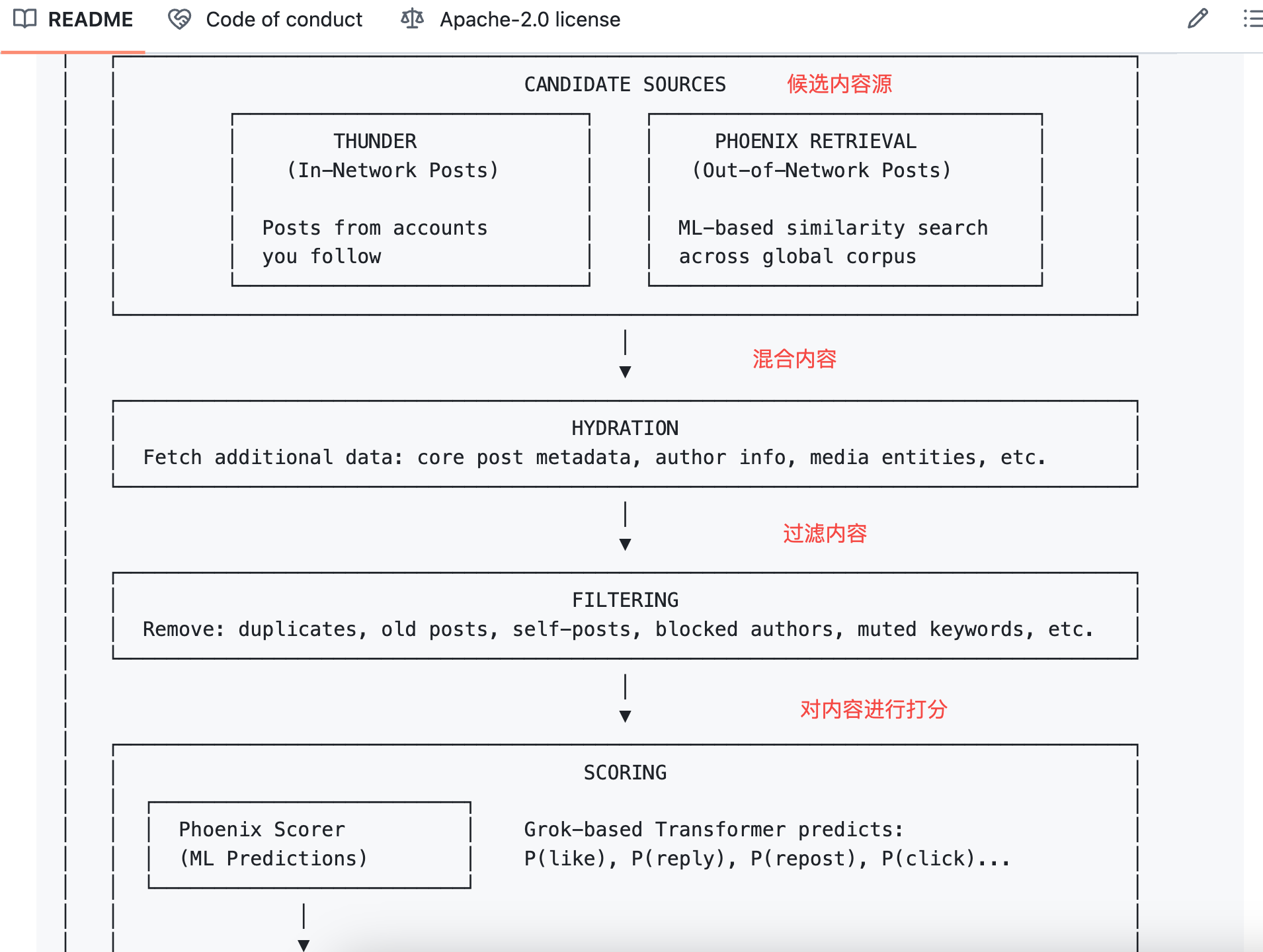
式は次のようになる:
最終スコア = Σ ( 重み × P(行動) )
ポジティブ行動の重みは正の数、ネガティブ行動の重みは負の数だ。
総合スコアが高い投稿が上位に表示され、低い投稿は沈んでいく。
式から離れて、率直に言えば:
現在、コンテンツの良し悪しは、もはやコンテンツ自体がどれだけ良く書かれているかによって決まるわけではない(もちろん可読性や利他性は拡散の基礎ではある)。むしろ、より多くは「このコンテンツがあなたにどのような反応を引き起こすか」によって決まる。アルゴリズムは投稿自体の質を気にせず、あなたの行動だけを気にする。
この考え方でいくと、極端な場合、低俗だが人々に返信して文句を言わせずにはいられない投稿のスコアが、質は高いが誰もインタラクションしない投稿よりも高くなる可能性がある。このシステムの根本的なロジックはおそらくそういうものだ。
ただし、新しくオープンソース化されたバージョンのアルゴリズムでは、具体的な行動の重みの数値は公開されていない。しかし、2023年のバージョンでは公開されていた。
旧バージョンの参考:1回の通報 = 738回のいいね
次に、23年のデータセットを掘り下げてみよう。古いものではあるが、様々な行動がアルゴリズムの目にどれだけの「価値」の差があるかを理解するのに役立つ。
2023年4月5日、Xは確かにGitHubで一連の重みデータを公開した。
数字を直接見てみよう:
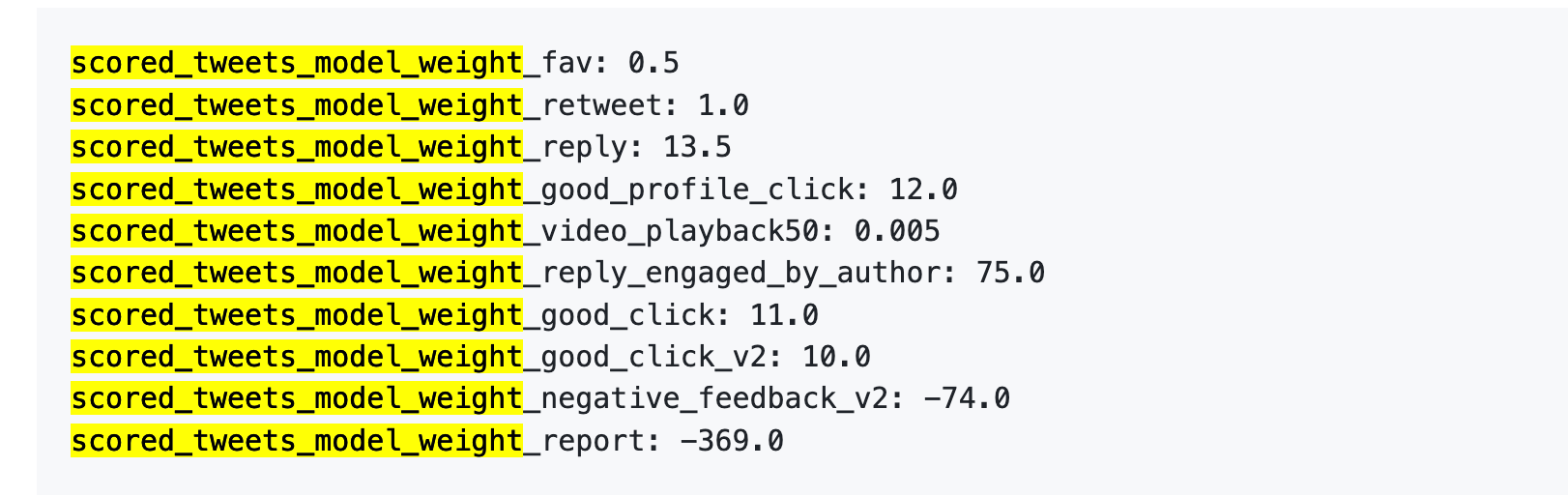
もっと分かりやすく翻訳すると:
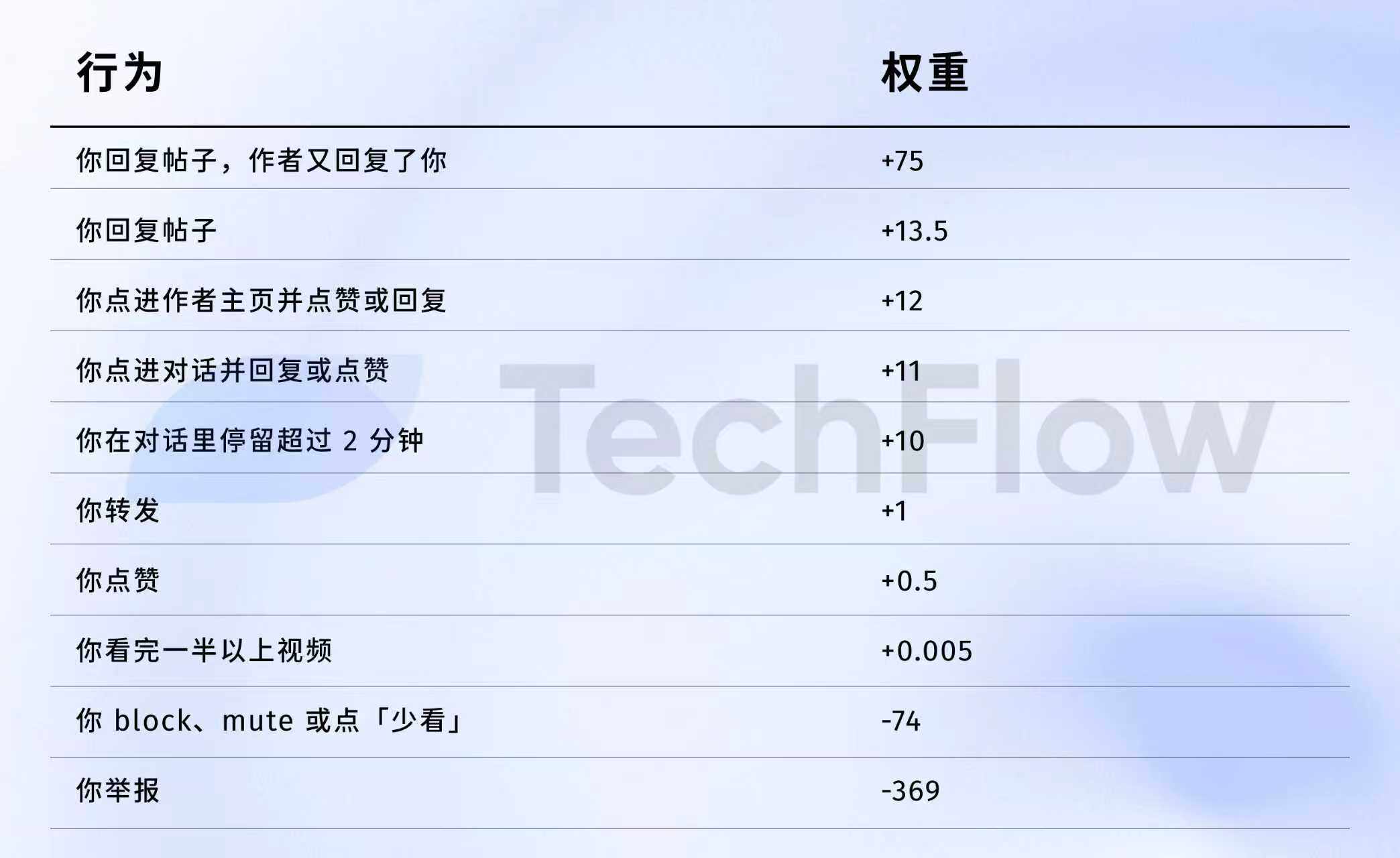
データソース:旧バージョン GitHub twitter/the-algorithm-ml リポジトリ、クリックすると元のアルゴリズムを閲覧可能
いくつかの数字は細かく見る価値がある。
第一に、「いいね」はほとんど価値がない。 重みはわずか0.5で、すべてのポジティブ行動の中で最低だ。アルゴリズムの目には、1回の「いいね」の価値はほぼゼロに等しい。
第二に、会話のインタラクションこそがハードカレンシーだ。 「あなたが返信し、著者もあなたに返信する」の重みは75で、「いいね」の150倍だ。アルゴリズムが最も見たいのは一方的な「いいね」ではなく、行き来する会話だ。
第三に、ネガティブフィードバックの代償は極めて高い。 1回のブロックまたはミュート(-74)を相殺するには148回の「いいね」が必要だ。1回の通報(-369)を相殺するには738回の「いいね」が必要だ。そしてこれらのマイナス点はあなたのアカウントの信頼スコアに累積され、以降のすべての投稿の配信に影響する。
第四に、動画の完視聴率の重みが信じられないほど低い。 わずか0.005で、ほとんど無視できるレベルだ。これはTikTokと鮮明な対照をなしており、あのプラットフォームは完視聴率をコア指標としている。
公式は同じ文書の中でこうも書いている:「The exact weights in the file can be adjusted at any time... Since then, we have periodically adjusted the weights to optimize for platform metrics.」(ファイル内の正確な重みはいつでも調整可能である...それ以来、我々はプラットフォームの指標を最適化するために定期的に重みを調整してきた。)
重みはいつでも調整可能であり、実際に調整されてきた。
新バージョンでは具体的な数値は公開されていないが、READMEに書かれているロジックの枠組みは同じだ:ポジティブは加点、ネガティブは減点、加重合計。
具体的な数字は変わったかもしれないが、桁数の関係はおそらくそのまま残っている。あなたが他人のコメントに返信することは、100個の「いいね」を受けるよりも有用だ。人にブロックされたいと思わせることは、誰もインタラクションしないことよりも悪い。
これを知った後、我々クリエイターは何ができるか
Twitter(X)の新旧のアルゴリズムコードを掘り下げ、合わせて考えると、いくつか実行可能な結論を抽出できる。
1. あなたにコメントした人に返信する。 重み表では「著者がコメント者に返信する」が最高得点項目(+75)で、ユーザーが一方的に「いいね」するよりも150倍高い。コメントを求めるように言っているわけではない。誰かがコメントしたら返信しよう。たとえ「ありがとう」と一言返すだけでも、アルゴリズムは記録する。
2. 人にスワイプで去りたいと思わせない。 1回のブロックによるネガティブな影響を相殺するには148回の「いいね」が必要だ。論争を呼ぶコンテンツは確かにインタラクションを引き起こしやすいが、もしそのインタラクションの方法が「この人うるさい、ブロックしよう」というものなら、あなたのアカウントの信頼スコアは持続的に損なわれ、以降のすべての投稿の配信に影響する。論争を呼ぶトラフィックは両刃の剣だ。他人を傷つける前にまず自分を傷つける。
3. 外部リンクはコメント欄に置く。 アルゴリズムはユーザーをサイト外に導出したくない。本文にリンクを含めると重みが下がる、この点はMusk自身が公に言及している。トラフィックを導きたいなら、本文にはコンテンツを書き、リンクは最初のコメントに投げ込もう。
4. 連続投稿をしない。 新バージョンのコードにはAuthor Diversity Scorerというものがあり、同じ著者が連続して出現する投稿の重みを下げる役割を果たす。設計意図はユーザーのフィードをより多様にすることであり、副作用として、あなたが10回連続で投稿するよりも、1回を精選して投稿する方が効果的だ。
6. 「ベストな投稿時間」はもうない。 旧バージョンのアルゴリズムには「投稿時間」という手動の特徴量があったが、新バージョンではあっさり削除された。Phoenixはユーザーの行動シーケンスだけを見て、投稿が何時に行われたかは見ない。「火曜日の午後3時に投稿するのが最も効果的」といった攻略ガイドの参考価値はますます低くなっている。
以上がコードレベルで読み取れるものだ。
他にも、Xの公開文書から来る加点・減点項目がある:ブルーチェック認証にはボーナスがある、すべて大文字は重みが下がる、センシティブなコンテンツは80%のリーチ率削減を引き起こす。これらの


