集中型コンピューティングの時代は終わりました。AIトレーニングは「コンピュータルーム」から「ネットワーク」へと移行しています。
- 核心观点:低通信算法实现分布式AI训练。
- 关键要素:
- DiLoCo算法减少通信量500倍。
- 联邦优化解耦本地与全局计算。
- 成功预训练数十亿参数模型。
- 市场影响:降低AI训练门槛,促进行业民主化。
- 时效性标注:长期影响
元々はEgor Shulgin、 Gonka Protocolによって投稿されました
AI技術の急速な発展は、学習プロセスを単一の物理的場所の限界まで押し進め、研究者は根本的な課題に直面せざるを得なくなりました。それは、(コンピュータルームの同じ廊下内ではなく)大陸に分散した数千台のプロセッサをどのように連携させるかということです。その答えは、より効率的なアルゴリズム、つまり通信を削減することで機能するアルゴリズムにあります。この変化は、連合最適化のブレークスルーによって推進され、DiLoCoのようなフレームワークに結実しました。これにより、組織は標準的なインターネット接続を介して数十億のパラメータを持つモデルを学習できるようになり、大規模な共同AI開発の新たな可能性を切り開きます。
1. 出発点: データセンターでの分散トレーニング
現代のAIトレーニングは本質的に分散型です。データ、パラメータ、計算量の増加によってモデルのパフォーマンスが大幅に向上し、数十億のパラメータを持つ基本モデルを単一のマシンでトレーニングすることは不可能になることが広く認識されています。デフォルトのソリューションは「集中型分散型」モデルです。これは、数千台のGPUを一箇所に収容する専用データセンターを構築し、NVIDIAのNVLinkやInfiniBandなどの超高速ネットワークで相互接続するものです。これらの特殊な相互接続技術は標準的なネットワークよりも桁違いに高速であり、すべてのGPUを統合されたシステムとして動作させることを可能にします。
この環境では、最も一般的なトレーニング戦略はデータ並列化であり、データセットを複数のGPUに分割します。(パイプライン並列化やテンソル並列化など、モデル自体を複数のGPUに分割する他のアプローチもあります。これは最大規模のモデルのトレーニングに必要ですが、実装はより複雑になります。)ミニバッチ確率的勾配降下法(SGD)を使用したトレーニング手順の仕組みは次のとおりです(Adamオプティマイザーにも同じ原理が適用されます)。
- 複製と分散:モデルのコピーを各GPUにロードします。トレーニングデータを小さなバッチに分割します。
- 並列コンピューティング:各 GPU は異なるミニバッチを独立して処理し、勾配 (モデル パラメータが調整される方向) を計算します。
- 同期と集約:すべての GPU が作業を一時停止し、勾配を共有して平均化し、単一の統合された更新を生成します。
- 更新:この平均更新を各 GPU のモデルのコピーに適用し、すべてのコピーが同一のままであることを確認します。
- 繰り返し:次の小さなバッチに移動して、もう一度開始します。
本質的には、これは並列計算と強制同期の継続的なサイクルです。各トレーニングステップの後に行われる継続的な通信は、データセンター内の高価な高速接続によってのみ実現可能です。この頻繁な同期への依存は、集中型分散トレーニングの特徴です。データセンターという「温室」を離れるまで、完璧に動作します。
2. 壁にぶつかる:巨大なコミュニケーションのボトルネック
最大規模のモデルを学習させるには、組織は驚異的な規模のインフラを構築する必要があり、多くの場合、複数の都市や大陸にまたがる複数のデータセンターが必要になります。こうした地理的な隔たりは大きな障壁となります。データセンター内ではうまく機能する段階的な同期アルゴリズムのアプローチは、グローバル規模に拡張すると機能しなくなります。
問題はネットワーク速度にあります。データセンター内では、InfiniBandは400Gbps以上の速度でデータを転送できます。一方、遠距離のデータセンターを接続する広域ネットワーク(WAN)は、通常1Gbpsに近い速度で動作します。この数桁もの違いがあるパフォーマンスギャップは、距離とコストという根本的な制約に起因しています。小規模バッチSGDが想定するほぼ瞬時の通信は、この現実とは相容れません。
この差異は深刻なボトルネックを生み出します。各ステップの後にモデルパラメータを同期させる必要がある場合、強力なGPUはほとんどの時間アイドル状態となり、データが低速ネットワークをゆっくりと移動するのを待ちます。その結果、AIコミュニティは、エンタープライズサーバーからコンシューマーハードウェアに至るまで、世界中に分散された膨大なコンピューティングリソースを活用できていません。これは、既存のアルゴリズムが高速で集中化されたネットワークを必要とするためです。これは、膨大な未活用のコンピューティングパワーの蓄積を意味します。
3. アルゴリズム変換:連合最適化
頻繁な通信が問題なら、解決策は通信を減らすことです。このシンプルな洞察は、連合学習(Federated Learning)の技術を活用したアルゴリズムの転換の基盤となりました。連合学習はもともと、プライバシーを保護しながら、エンドデバイス(携帯電話など)上の分散データを用いてモデルを学習することに重点を置いた分野です。その中核となるアルゴリズムであるFederated Averaging (FedAvg)は、各デバイスが更新を送信する前に複数の学習ステップをローカルで実行できるようにすることで、必要な通信回数を桁違いに削減できることを示しました。
研究者たちは、同期間隔の間により独立した作業を行うという原理が、地理的に分散した環境におけるパフォーマンスのボトルネックを解決する完璧な解決策であることに気づきました。これが、ローカル計算とグローバル通信を分離するデュアルオプティマイザーアプローチを採用したFederated Optimization (FedOpt)フレームワークの誕生につながりました。
フレームワークは、2 つの異なるオプティマイザーを使用して動作します。
- 内部オプティマイザー(標準SGDなど)は各マシン上で実行され、ローカルデータスライスに対して複数の独立したトレーニングステップを実行します。各モデルレプリカはそれぞれ独立して大きな進歩を遂げます。
- 外部オプティマイザーは、頻度の低いグローバル同期を処理します。複数のローカルステップの後、各ワーカーノードはモデルパラメータの合計変化を計算します。これらの変化は集計され、外部オプティマイザーはこの平均化された更新を使用して、次のエポックに向けてグローバルモデルを調整します。
このデュアルオプティマイザーアーキテクチャは、学習のダイナミクスを根本的に変化させます。全ノード間での頻繁な段階的な通信ではなく、一連の拡張された独立した計算期間と、それに続く単一の集約更新へと変化します。プライバシー研究に端を発するこのアルゴリズムの転換は、低速ネットワークでの学習を可能にするための重要なブレークスルーをもたらします。問題は、これを大規模言語モデルに適用できるかどうかです。
以下は、フェデレーション最適化フレームワークの図です。ローカルトレーニングと定期的なグローバル同期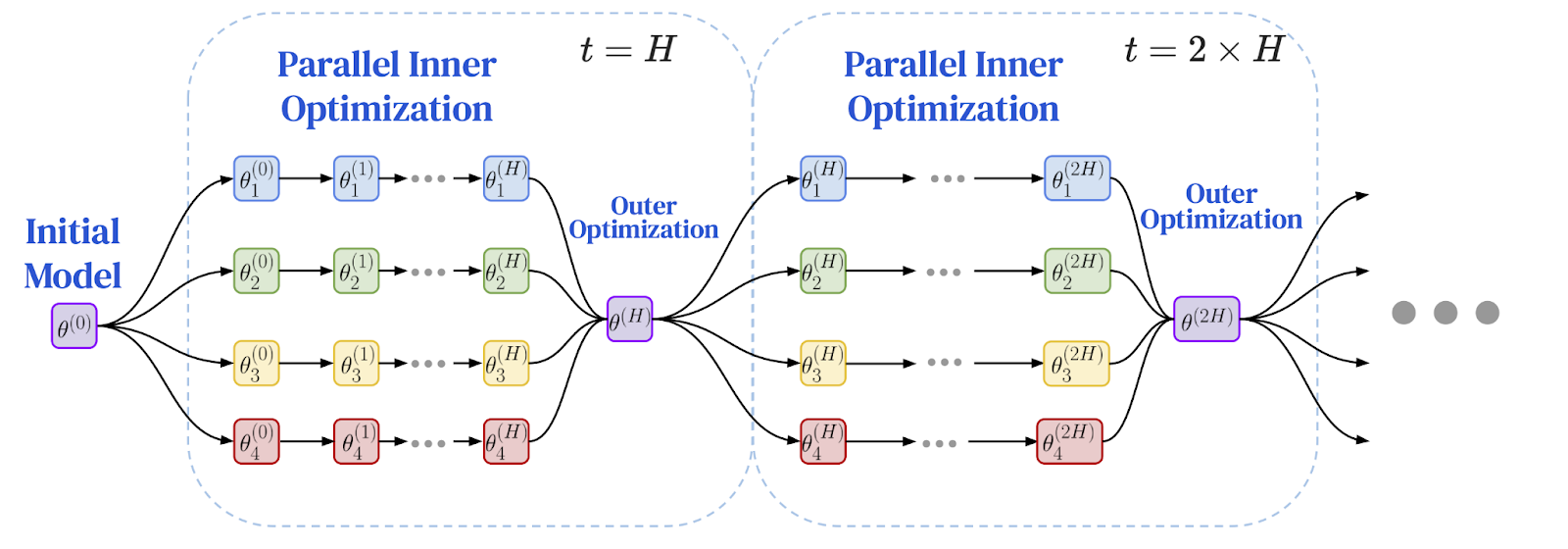
画像出典:Charles, Z., et al. (2025). 「コミュニケーション効率の高い言語モデルトレーニングは信頼性と堅牢性を兼ね備えてスケールする:DiLoCoのスケーリング則」arXiv:2503.09799
4. ブレークスルー:DiLoCoが大規模展開で実現可能性を証明
その答えは、大規模言語モデルにおける連合最適化の実用的実現可能性を示すDiLoCo(Distributed Low Communication)アルゴリズムです。DiLoCoは、低速ネットワーク上で最新のTransformerモデルを学習するための、特別に調整されたスキームを提供します。
- 内部オプティマイザー:大規模言語モデル向けの最先端のオプティマイザーである AdamW は、各ワーカー ノードで複数のローカル トレーニング ステップを実行します。
- 外部オプティマイザー:頻度の低いグローバル更新を処理する強力でよく理解されているアルゴリズムである Nesterov Momentum。
初期実験では、DiLoCo は、ノード間通信を最大 500 倍削減しながら、完全に同期されたデータセンター トレーニングのパフォーマンスに匹敵できることが示され、インターネット経由で大規模なモデルをトレーニングする実現可能性が実証されました。
この画期的な成果は急速に注目を集めました。オープンソース実装であるOpenDiLoCoは、オリジナルの結果を再現し、Hivemindライブラリを用いてアルゴリズムを真のピアツーピアフレームワークに統合することで、この技術へのアクセス性を高めました。この勢いは最終的に、 PrimeIntellect 、 Nous Research 、 FlowerLabsといった組織による大規模な事前学習の成功へとつながり、通信量の少ないアルゴリズムを用いてインターネット経由で数十億パラメータのモデルの事前学習に成功したことを実証しました。これらの先駆的な取り組みにより、DiLoCoスタイルの学習は、有望な研究論文から、中央集権的なプロバイダーの外で基礎モデルを構築するための実証済みの手法へと変貌を遂げました。
5. フロンティア探査:先端技術と未来研究
DiLoCoの成功は、その効率性とスケールのさらなる向上に焦点を当てた新たな研究の波を促しました。この手法の成熟における重要なステップは、 DiLoCoのスケーリング則の開発でした。このスケーリング則は、DiLoCoの性能がモデルサイズに応じて予測どおりかつ堅牢にスケーリングすることを確立しました。これらのスケーリング則は、モデルが大きくなるにつれて、適切に調整されたDiLoCoは、一定の計算予算で従来のデータ並列学習よりも優れた性能を発揮し、使用する帯域幅も桁違いに少なくなることを予測しています。
1,000億を超えるパラメータを持つモデルを扱うために、研究者たちはDiLoCoXなどの技術を用いてDiLoCo設計を拡張してきました。DiLoCoXは、デュアルオプティマイザアプローチとパイプライン並列処理を組み合わせたものです。DiLoCoXは、標準的な1Gbpsネットワーク上で1,070億パラメータのモデルを事前学習することを可能にします。さらに、ストリーミングDiLoCo (通信と計算をオーバーラップさせることでネットワーク遅延を隠蔽する)や非同期アプローチ(単一の低速ノードがシステム全体のボトルネックとなるのを防ぐ)といった改良点があります。
アルゴリズムの中核でもイノベーションが起きている。Muonのような新しい内部最適化装置の研究は、モデルの更新をパフォーマンスの低下がごくわずかで2ビットに圧縮できる変種であるMuLoCoにつながっており、データ転送を8分の1に削減している。おそらく最も野心的な研究方向は、インターネット上でのモデル並列処理であり、これはモデル自体を異なるマシンに分割するものである。この分野における初期の研究、例えばSWARM並列処理では、低速ネットワークで接続された異機種混在で信頼性の低いデバイス間にモデルレイヤーを分散させるフォールトトレラントな手法が開発された。こうした概念を基に、 Pluralis Researchなどのチームは、地理的に分散したGPU上で異なるレイヤーがホストされている数十億パラメータのモデルをトレーニングする可能性を実証し、標準的なインターネット接続のみで接続された分散型の消費者向けハードウェア上でモデルをトレーニングする道を開いた。
6. 信頼の課題:オープンネットワークにおけるガバナンス
トレーニングが管理されたデータセンターからオープンで許可のないネットワークに移行すると、根本的な問題が浮上します。それは信頼です。中央集権を持たない真に分散化されたシステムでは、参加者は他者から受け取った更新が正当なものであることをどのように検証できるでしょうか?悪意のある行為者がモデルに悪意を込めたり、怠惰な行為者が未完了の作業に対して報酬を請求したりするのをどのように防ぐことができるでしょうか?このガバナンスの問題こそが、最後のハードルとなるのです。
防御策の一つはビザンチンフォールトトレランスです。これは分散コンピューティングの概念であり、一部の参加者が故障したり、悪意のある行動を積極的に行ったりしても機能するシステムを設計することを目的としています。集中型システムでは、サーバーが堅牢な集約ルールを適用して悪意のある更新を破棄できます。これは、中央集約機能が存在しないピアツーピア環境では実現が困難です。その代わりに、各誠実なノードが近隣ノードからの更新を評価し、どのノードを信頼し、どのノードを破棄するかを決定する必要があります。
もう一つのアプローチは、信頼を検証に置き換える暗号技術です。初期のアイデアの一つは学習証明( Proof -of-Learning)で、参加者が必要な計算を行ったことを証明するためにトレーニングのチェックポイントを記録することを提案しています。ゼロ知識証明(ZKP)などの他の技術では、ワーカーノードは基礎となるデータを公開することなく、必要なトレーニングステップを正しく実行したことを証明できますが、現在の大規模インフラモデルのトレーニング検証においては、その計算コストが依然として課題となっています。
展望:新たなAIパラダイムの夜明け
壁に囲まれたデータセンターからオープンなインターネットへの移行は、AIの開発方法に大きな変化をもたらしました。私たちは集中型の学習の物理的な限界から出発し、高価な同一場所に配置されたハードウェアへのアクセスが進歩の鍵となっていました。これが通信のボトルネックとなり、分散ネットワークを介した大規模なモデルの学習を非現実的なものにしていました。しかし、この壁を突破したのはケーブルの高速化ではなく、より効率的なアルゴリズムでした。
DiLoCoによって具体化された、連合最適化に根ざしたこのアルゴリズムの転換は、通信頻度の低減が鍵となることを示しています。このブレークスルーは、スケーリング則の確立、通信の重複、新たな最適化手法の探索、さらにはインターネットを介したモデル自体の並列化など、様々な手法によって急速に進展しています。多様な研究者や企業からなるエコシステムによって数十億パラメータのモデルの事前学習に成功したことは、この新しいパラダイムの威力を証明しています。
堅牢な防御と暗号検証によって信頼の課題が解決されるにつれ、その道筋は明確になりつつあります。分散型トレーニングは、エンジニアリングソリューションから、よりオープンで協調的、そしてアクセスしやすいAIの未来を支える基盤へと進化しています。これは、強力なモデルを構築する能力が少数の巨大テクノロジー企業に限定されるのではなく、世界中に分散され、あらゆる人々の集合的なコンピューティングパワーと知恵が解き放たれる世界の到来を告げています。
参考文献
McMahan, HB, et al. (2017).分散データからの通信効率の高いディープネットワーク学習. 人工知能と統計に関する国際会議 (AISTATS).
Reddi, S., et al. (2021).適応型連合最適化. 国際学習表現会議 (ICLR).
Jia, H., et al. (2021).学習証明:定義と実践. IEEE セキュリティとプライバシーシンポジウム.
Ryabinin, Max, et al. (2023).群並列処理:大規模モデルのトレーニングは驚くほど通信効率が高い. 国際機械学習会議 (ICML).
Douillard, A., et al. (2023). DiLoCo: 言語モデルの分散型低通信トレーニング.
Jaghouar, S.、Ong, JM、および Hagemann, J. (2024)。 OpenDiLoCo: グローバルに分散された低コミュニケーション トレーニングのためのオープンソース フレームワーク。
Jaghouar, S., et al. (2024).基礎モデルの分散型トレーニング:INTELLECT-1を用いたケーススタディ.
Liu, B., et al. (2024).言語モデルのための非同期ローカルSGDトレーニング.
Charles, Z., et al. (2025).コミュニケーション効率の高い言語モデル学習は信頼性と堅牢性をもってスケールする:DiLoCoのスケーリング則。
Douillard, A., et al. (2025).重複通信によるストリーミングDiLoCo:分散型フリーランチの実現に向けて.
Psycheチーム (2025). AIの民主化:Psycheネットワークアーキテクチャ. Nous Researchブログ.
Qi, J., et al. (2025). DiLoCoX: 分散型クラスター向けの低通信量大規模トレーニングフレームワーク.
Sani, L., et al. (2025). Photon: フェデレーテッドLLM事前トレーニング. 機械学習とシステムに関する会議 (MLSys) の議事録.
Thérien, B., et al. (2025). MuLoCo: MuonはDiLoCoの実用的な内部最適化器です。
Long, A., et al. (2025).プロトコルモデル:通信効率の高いモデル並列処理による分散トレーニングのスケーリング.