
分散型 AI 推論の中心的な課題: ネットワーク全体に対して「不正行為」をしていないことをどのように証明するか。
- 核心观点:去中心化LLM需验证节点模型真实性。
- 关键要素:
- GPU非确定性导致输出比较困难。
- 经济机制惩罚作弊,声誉归零。
- 三种验证方案防范模型替换攻击。
- 市场影响:提升去中心化AI网络可信度。
- 时效性标注:中期影响。
Gonka Protocol の共同創設者、Anastasia Matveeva による元の記事
前回の記事では、LLMを用いた分散推論におけるセキュリティとパフォーマンスの根本的な緊張関係について考察しました。本日は、その約束を果たし、核心的な疑問に迫ります。オープンネットワークにおいて、ノードが主張するモデルと全く同じモデルを実際に実行していることを、どのようにして真に検証するのでしょうか?
01. 検証はなぜ難しいのでしょうか?
検証メカニズムを理解するために、Transformerが推論を実行する際の内部プロセスを振り返ってみましょう。入力トークンが処理されると、モデルの最終層はロジット(語彙内の各トークンの正規化されていない生のスコア)を生成します。これらのロジットはその後、ソフトマックス関数を用いて確率に変換され、すべての可能な次のトークンに対する確率分布を形成します。各生成ステップでは、この分布からトークンがサンプリングされ、シーケンスの生成を継続します。
潜在的な攻撃ベクトルと特定の検証実装について詳しく説明する前に、まず検証自体がなぜ難しいのかを理解する必要があります。
問題の根本はGPUの非決定性にあります。同じモデルと入力であっても、浮動小数点精度などの問題により、異なるハードウェア、あるいは同じデバイス上でもわずかに異なる出力が生成される可能性があります。
GPUの非決定性により、出力トークンシーケンスを直接比較することは無意味です。そのため、Transformerの内部計算プロセスを検証する必要があります。自然な選択肢は、出力層、つまりモデルの語彙全体の確率分布を比較することです。同じシーケンスの確率分布を比較していることを確認するために、検証手順では、検証者が実行者によって生成された全く同じトークンシーケンスを完全に再現し、それらの確率分布を段階的に比較する必要があります。このプロセスにより、モデルの信頼性を証明する検証証明書が生成されます。
しかし、確率的な行動には微妙なバランスが求められます。常習的な不正行為者を罰する一方で、単に運が悪く低確率の出力しか生成しない正直なノードに意図せず損害を与えてしまうことも避けなければなりません。閾値を高く設定しすぎると、善良なプレイヤーを誤って殺してしまう可能性があり、逆に低く設定しすぎると、悪質なプレイヤーを見逃してしまう可能性があります。
02. 不正行為の経済学:メリットとリスク
潜在的なメリット: 大きな誘惑
最も直接的な攻撃は「モデルの置き換え」です。ネットワークの展開にQwen3-32Bモデルに大量の計算能力が必要だと仮定すると、合理的なノードは「はるかに小型のQwen2.5-3Bモデルを密かに実行し、節約した計算能力の差を懐に入れたらどうなるだろうか?」と考えるかもしれません。
30億パラメータのモデルを320億パラメータのモデルとして偽装することで、計算能力にかかるコストを桁違いに削減できる可能性があります。検証システムを欺くことができれば、高品質な計算能力に対して報酬を受け取りながら、安価な計算能力で結果を出すのと同じことになります。
より高度な攻撃者は量子化技術を用いて、FP8精度で実行できると主張しながら、実際にはINT4量子化を使用する可能性があります。パフォーマンスの違いはそれほど大きくないかもしれませんが、コスト削減は依然として大きく、出力は簡単な検証を通過できるほど似ている可能性があります。
より複雑なレベルでは、事前充填攻撃も存在します。この攻撃により、攻撃者は安価なモデルの出力を、あたかもネットワークが期待する完全なモデルによって生成されたかのように証明することができます。これは以下のように機能します。
たとえば、特定のパラメータセットを使用して Qwen3-235B をデプロイするというコンセンサスがチェーン上で達成されます。
1. 実行者は Qwen2.5-3B を使用して、シーケンス `[Hello, world, how, are, you]` を生成します。
2. 実行者は、単一のフォワードパスを介して、これらとまったく同じトークンの Qwen3-235B 証明を計算します: `[{Hello: 0.9, Hi: 0.05, Hey: 0.05}, ...]`。
3. 遺言執行者は、Qwen3-235Bの確率を証拠として提出し、その推論はQwen3-235Bから導かれると主張します。
この場合、確率は正しいモデルから得られるため、一見正当に見えますが、実際のシーケンス生成プロセスははるかに安価です。完全なモデルでも理論的には小さなモデルと同じ出力を生成することが可能であるため、検証の観点からは結果が完全に正当に見える可能性があります。
潜在的損失:より高価
システムを不正に操作することで大きな利益を得られる一方で、潜在的な損失も同様に甚大です。不正行為者にとって真の課題は、単一の検証を通過することではなく、長期間にわたって体系的に検出を回避し、計算処理で得られる「割引」がネットワークが課すペナルティを上回ることです。
ゴンカネットワークでは、洗練された経済抑制メカニズムを設計しました。
- 誰もが検証者:各ノードは重みに応じてネットワーク推論の一部を検証する
- 評判システム:新規ノードの評判値は0で、すべての推論は検証されます。誠実な参加を継続することで評判は高まり、検証頻度を1%まで下げることができます。
- ペナルティメカニズム: 不正行為が発覚した場合、評判はゼロにリセットされ、再構築には約 30 日かかります。
- エポック決済: 約 24 時間のエポック内で、統計的に有意な回数の不正行為が発覚した場合、エポック全体の報酬はすべて没収されます。
これは、計算能力を50%節約しようとした不正行為者が、最終的に得た利益の100%を失う可能性があることを意味します。この「損失が利益を上回る」リスクにより、不正行為は経済的に不利益となります。私たちの検証メカニズムで解決を目指す問題は、疑わしい推論をすべて検出することではなく、誠実な参加者の評判を損なうことなく、十分な確率で不正行為者を一貫して検出できる境界線を引くことです。
03. 不正行為者を捕まえるには?3つの検証方法
では、これらの攻撃をどのように捉えるのでしょうか?問題は2つの部分に分けられます。1) 証明内の分布が、主張されたモデルによって生成された分布に近いことを検証すること。2) 出力テキストが提出された証明に基づいて実際に生成されたことを確認することです。
オプション1: 確率分布の比較(コアファンデーション)
実行者が推論出力(例:[Hello, world, how, are, you])を生成すると、最終出力と出力シーケンスの各位置における上位K個の確率(例:最初の位置は[{Hello: 0.9, Hi: 0.05, Hey: 0.05}, ...]など)を含む検証証明書を記録します。検証者はモデルを全く同じトークンシーケンスに追従させ、各位置における確率間の正規化距離 \( d_i \) を計算します。
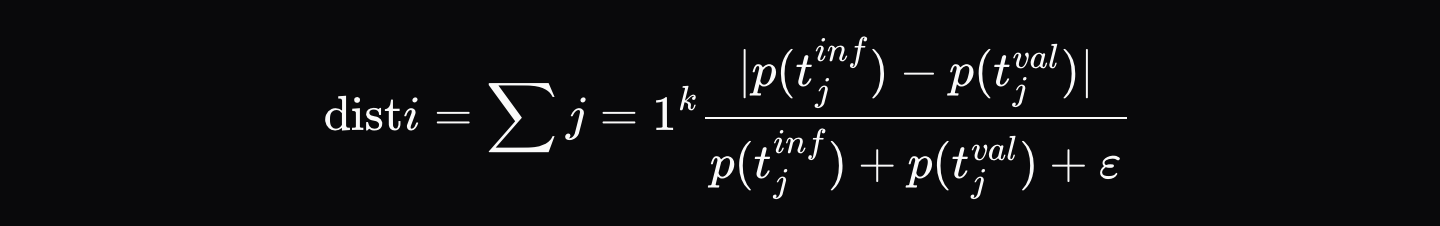
ここで、\( p_{\text{artifact},ij} \) は推論リポジトリ内のその位置にある j 番目に可能性の高いトークンの確率であり、\( p_{\text{validator},ij} \) はバリデータ分布内の同じトークンの確率です。
最終的な距離メトリックは、各トークンの距離の平均合計です。
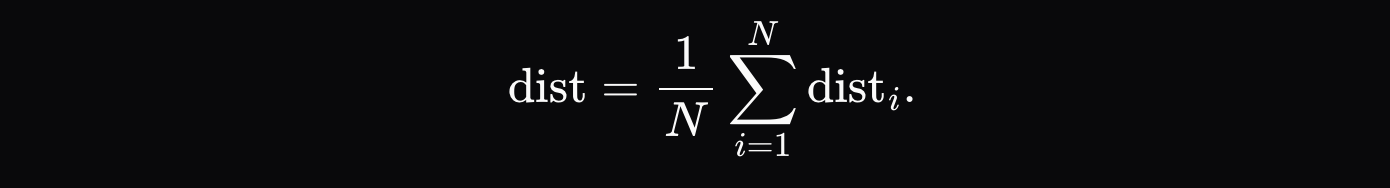
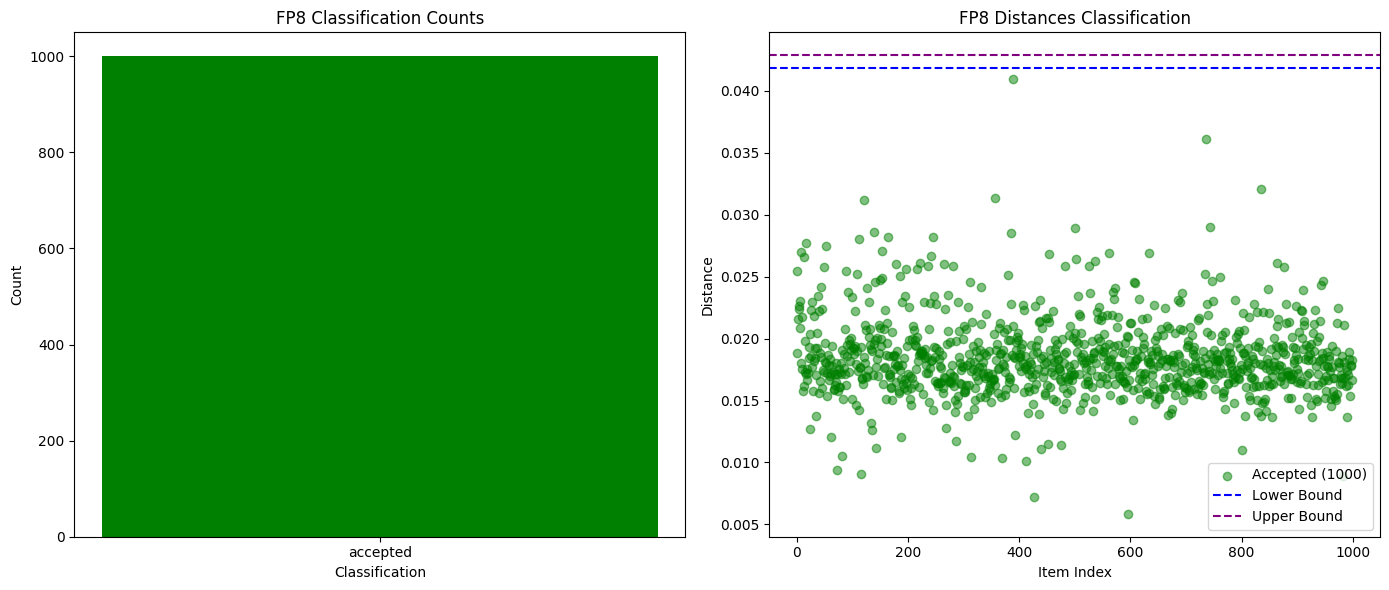
上位K個の確率を比較するだけで、全く異なるモデル、あるいは同じモデルの異なる量子化バージョンでさえも検出するのに十分であることが証明されました。下のグラフに示すように、Qwen3-32B FP8とINT4の量子化バージョン間でテストを行ったところ、誤検知ゼロで99%の不正検出率を達成しました。他のモデルの確率分布も十分に異なっていたため、不正行為は1エポック内で容易に検出できましたが、正直な参加者は安全でした。
次の図は、Qwen3-32B FP8 (正直) と INT4 量子化 (不正) の成功した検証と失敗した検証の数を比較したものです。
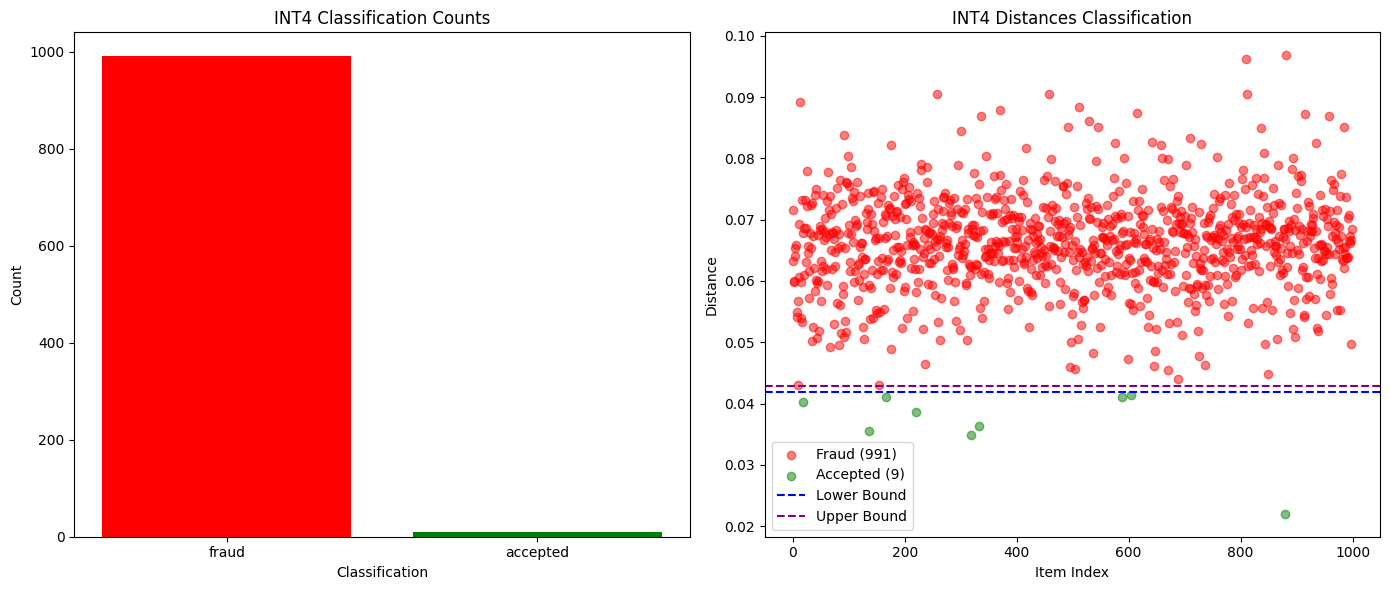
次の図は、シーケンスの長さの関数として、Qwen3-32B FP8(正直)とINT4量子化(不正)の確率分布距離の変化を示しています。
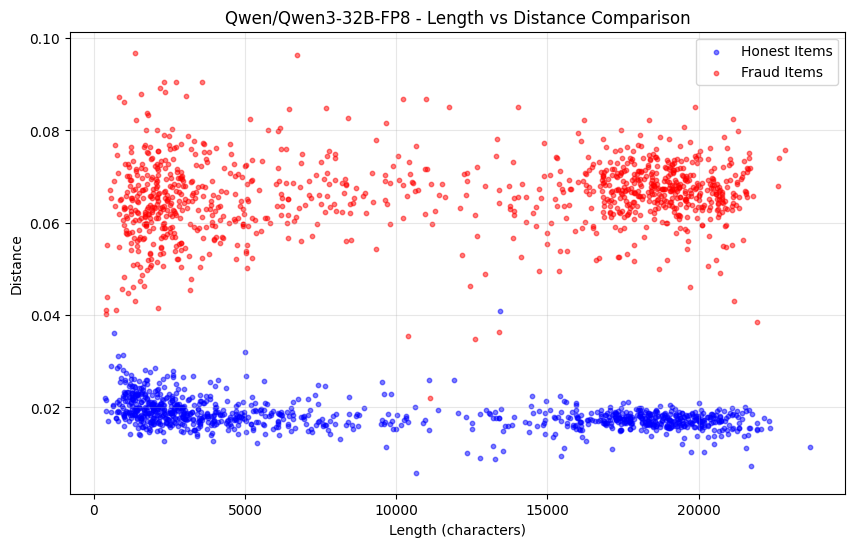
しかし、このアプローチだけでは、事前充填攻撃から保護されないという欠点があります。確率が完全なモデルの分布と一致しているにもかかわらず、シーケンスが小規模なモデルによって生成された場合、この状況を捕捉するための追加の方法がいくつかあります。
解決策2: 困惑検出(事前入力攻撃に対する防御)
証拠が正しいモデルからのものであることを確認するだけでなく、出力テキストが証拠の確率分布から「おそらく」得られるかどうかも確認します。
シーケンスが異なるモデルによって生成された場合、主張されているモデルの確率分布に対するパープレキシティは異常に高くなります。テストでは、Qwen2.5-7BとQwen2.5-3Bの事前入力攻撃のパープレキシティの差は顕著でした。
事前入力攻撃を捕捉する最も直感的な方法は、困惑度をチェックすることです。つまり、証明が要求されたモデルによって生成されたことを確認するだけでなく、出力テキストが送信された分布から生成された可能性があるかどうかもチェックできます。
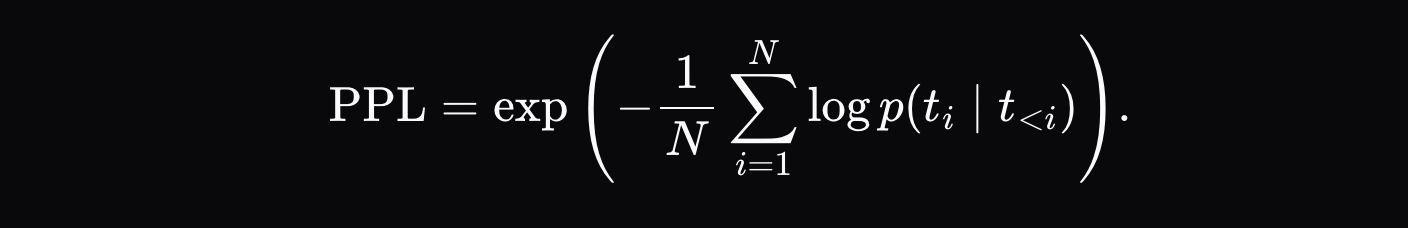
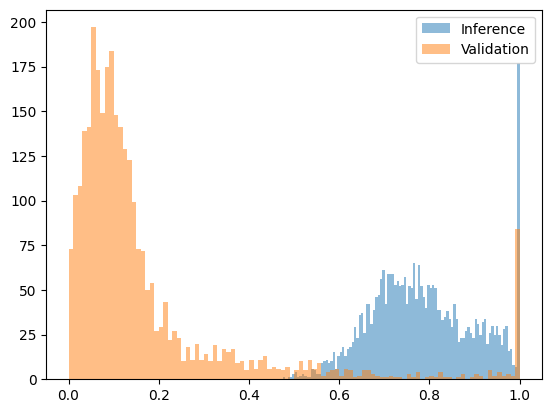
パープレキシティが高すぎる場合、そのシーケンスは別のモデルによって生成された可能性が高いことを示します。このアプローチは、大きく異なるモデルを用いた攻撃に対する防御に有効です。Qwen2.5-3Bによって生成されたシーケンスをQwen2.5-7Bから生成されたと主張されているシーケンスをテストしたところ、パープレキシティの差は十分に大きく、明確な閾値を設定できました。下の図は、区間[0, 1]に適合した変換されたパープレキシティ関数を示しています。7Bモデルの出力はほとんどが0.2を下回っていますが、事前入力された攻撃(7Bモデルの確率を持つ3Bモデルの出力)の出力はすべて0.4を超えています。
次の図は、Qwen2.5-7B (正直) と Qwen2.5-3B 事前入力攻撃 (詐欺) の変換後の困惑度関数を示しています。
しかし、類似モデルや同一モデルの異なる量子化バージョンを比較する場合、パープレキシティ検出には限界があります。例えば、Qwen2.5-7B Baseのw8a16とw8a8の量子化バージョンを比較した場合、有意な差は見られません。
次の図は、Qwen2.5-7B w8a16 (正直) と w8a8 量子化 (不正) の変換後の困惑度関数を示しています。
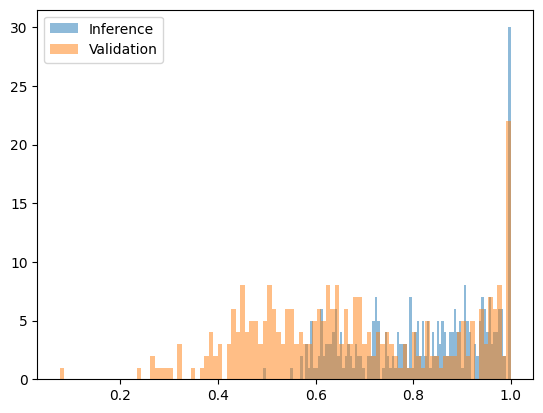
幸いなことに、攻撃に類似モデルを使用することは、通常、経済的に意味がありません。主張されているモデルの70~90%のコストで、さらに真のモデルとのスコア計算まで行うモデルを実行すると、真のモデルのみを実行する場合よりも多くの計算リソースを費やす可能性があります。
誠実な参加者が生成した低確率の出力が1回だけであっても、その参加者の評判を著しく低下させることはないことに注意することが重要です。この低確率の出力がその参加者にとって永続的でない場合、つまり単なるランダムな統計的外れ値である場合、その参加者はエポック終了時に報酬全額を受け取ります。
ソリューション3: RNGシードバインディング(決定論的ソリューション)
これは最も根本的な解決策です。出力シーケンスを乱数ジェネレータのシードに結び付けます。
実行者は、リクエストから導出された決定論的なシード(例:`run_seed = SHA256(user_seed || inference_id_from_chain)`)を使用してRNGを初期化します。検証証拠には、このシードと確率分布が含まれます。
検証者は同じシードを用いて、シーケンスが実際に主張されたモデルの確率分布から来ている場合、同じ出力が再現されることを検証します。これにより、決定論的な「はい/いいえ」の回答が得られ、事前入力攻撃が完全に排除され、検証コストは完全推論よりもはるかに低くなります。
04. 展望:分散型AIの未来に向けて
私たちがこれらの実践と考察を共有するのは、分散型AIの未来への揺るぎない信念に基づくものです。AIモデルが私たちの生活にますます浸透するにつれて、モデルの出力を特定のパラメータに結び付ける必要性はますます高まっていくでしょう。
Gonkaネットワークが選択した検証スキームは実際に実行可能であることが証明されており、そのコンポーネントは AI 推論の信頼性を検証する必要がある他のシナリオでも再利用できます。
分散型AIは単なる技術進化ではなく、生産関係の変革です。オープンな環境におけるアルゴリズムと経済メカニズムを通じて、根本的な信頼の問題に対処しようと試みています。道のりは長いですが、私たちはすでに着実な前進を遂げています。


