
SignalPlus: オートエンコーダー (オートエンコーダー)
原作者:スティーブン・ワン

序文
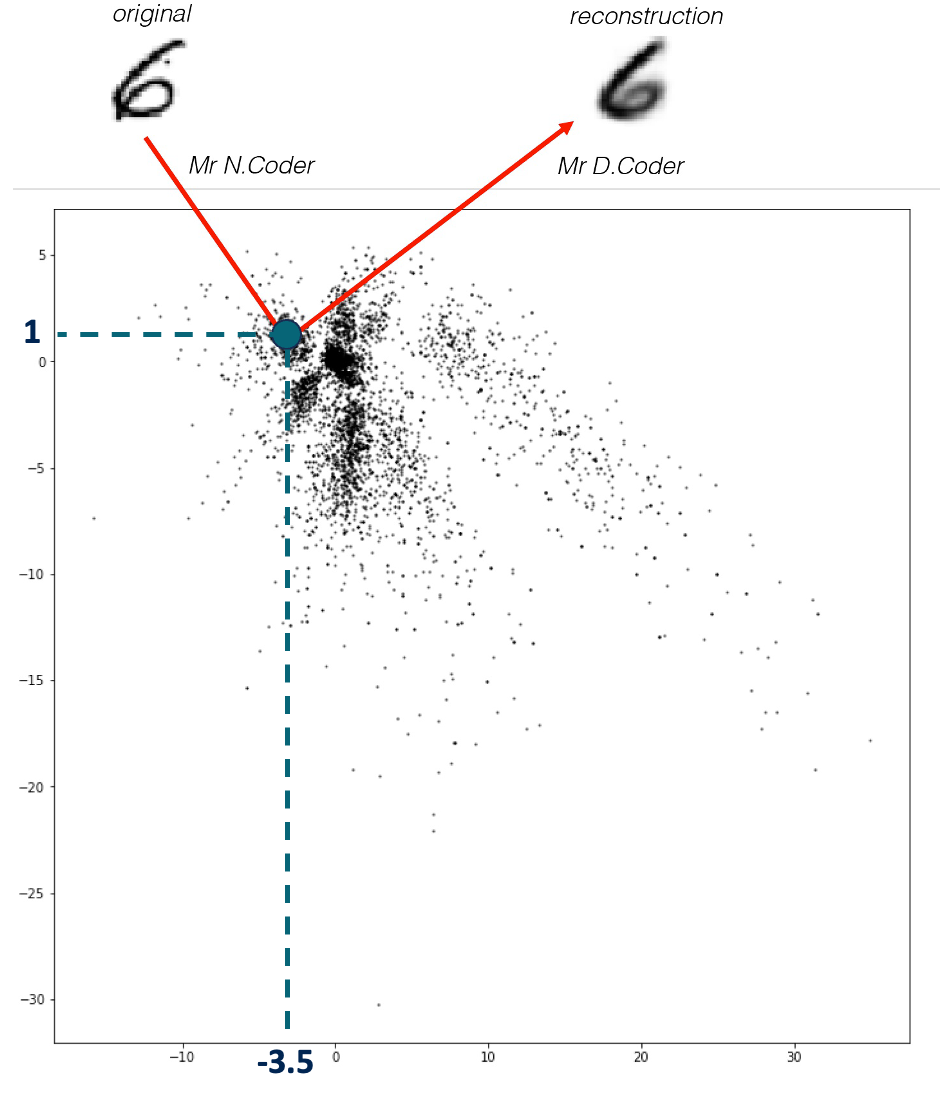
2 人の兄弟、N.コーダーと D.コーダーはアート ギャラリーを経営しています。ある週末、彼らは特に奇妙な展覧会を開催しました。壁が 1 つしかなく、物理的なアートがなかったためです。新しい絵画を受け取ると、N.Coder はその絵画を表すマークとして壁の場所を選択し、元のアートワークを捨てます。顧客がその絵画を見たいと依頼したとき、D.Coder は壁の関連するマークの座標のみを使用してアートワークを再現しようと試みました。
展示壁面は下の写真の通りで、黒い点一つ一つがN.Coderが配置したマークであり、絵画を表しています。 N.Coder は、壁の座標 [-3.5, 1] にある数字の 6 の元の絵を再構築しました。
下の図はさらに例を示したもので、上の行の数字はオリジナルの写真、中段の座標は N.Coder が壁に掛けた場所の座標、下の行は D.Coder によって復元された作品です。座標に基づいて。

D.Coder がその絵画のみを使用して元の絵画を再構築できるように、N.Coder は展示壁上の各絵画の対応する座標をどのように決定するのかという疑問が生じます。長年の「訓練」を経てマーカーの配置を徐々に「習得」し、作品を再構築した二人の兄弟は、再構築の品質が低いために返金を要求する顧客による興行収入の損失を注意深く監視していたことが判明した。この収益の損失を最小限に抑えながら再構築します。上の写真の元の画像と再構成の比較からわかるように、2 人の兄弟間の慣らし運転はかなり良好です。アートを見に来た顧客が、D.コーダーの再作成された絵画が見に来たオリジナルの作品と大きく異なると苦情を言うことはめったにありません。
ある日、N.コーダーは展示の壁を見て、現在は何も描かれていない壁の部分を、D.コーダーに再構築させたらどんな作品ができるだろうかという大胆なアイデアを思いつきました。成功すれば、100%自分たちの原画展を開催できる。それを考えると興奮したので、D.Coder はこれまでマークされていない座標をランダムに選択しました (赤い点) を再構築した結果を次の図に示します。
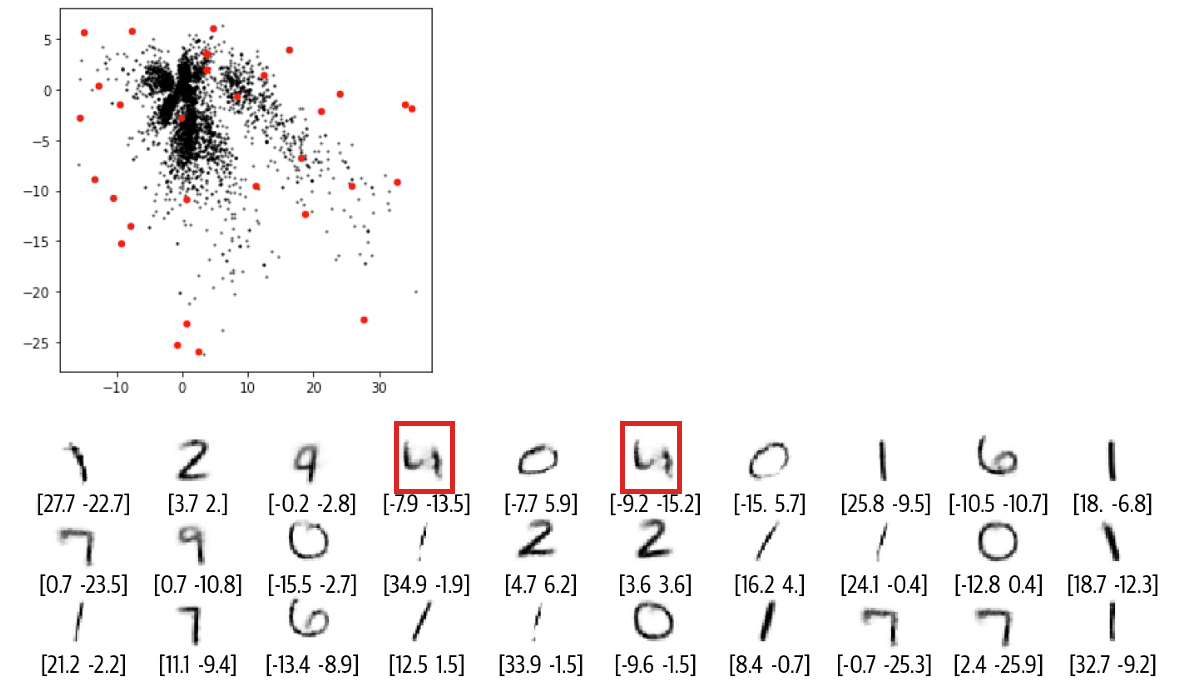
ご覧のとおり、復元は悪く、数字が何であるかさえわからないものもあります。では、何が問題だったのでしょうか?コーダー兄弟はどのようにしてソリューションを改善できたのでしょうか?
1. オートエンコーダー
序文の話は実は例え話ですオートエンコーダ(autoencoder)、D.Coder は encoder として音訳されます。エンコーダ、それが行うことは画像を座標に変換することであり、N.Coder はデコーダーとして音訳されます。デコーダ、それが行うことは、座標を画像に復元することです。前のセクションで 2 人の兄弟によって監視された収入損失は、実際にはモデルのトレーニングで使用される損失関数です。
話は話なので、オートエンコーダの厳密な説明を見てみましょう。オートエンコーダは本質的には次のようなニューラル ネットワークです。
1つエンコーダ(エンコーダ): 高次元データを低次元表現ベクトルに圧縮するために使用されます。
1つデコーダ(デコーダ): 低次元表現ベクトルを高次元データに復元するために使用されます。
処理は下図のようになります. 元の入力データは高次元の画像データです. 画像は多くの画素を含むため高次元ですが, 表現ベクトルは低次元の表現ベクトルです. 2次元ベクトル [この例で使用されている [-2.0、-0.5] は低次元です。
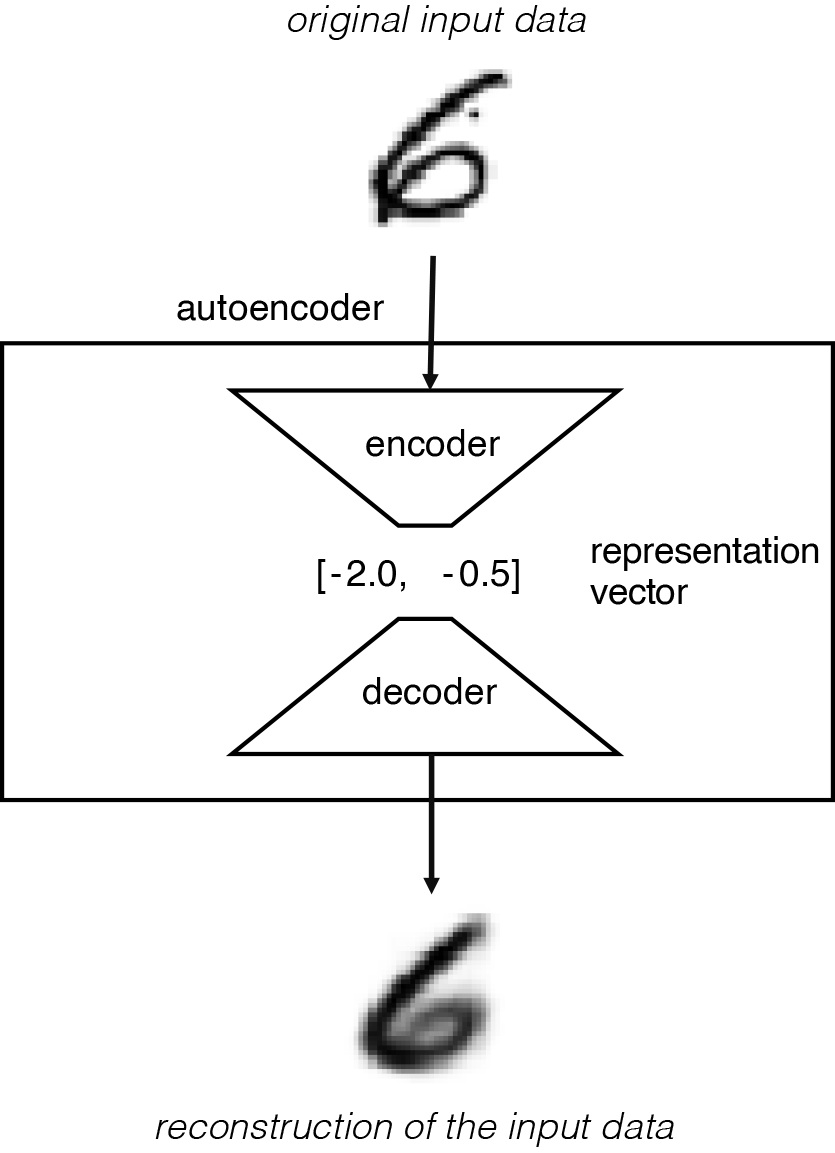
ネットワークは、元の入力と、エンコーダとデコーダを通過した後の入力の再構築との間の損失を最小限に抑えるエンコーダとデコーダの重みを見つけるようにトレーニングされます。表現ベクトルは、元の画像を低次元の潜在空間に圧縮します。選択によって潜在空間(潜在空間) の場合、その点をデコーダに渡すことで新しい画像を生成できるはずです。デコーダは潜在空間内の点を表示可能な画像に変換する方法を学習しているためです。
序文の説明では、N.Coder と D.Coder は、2 次元の潜在空間 (壁) を表すベクトルを使用して各画像をエンコードします。 2 次元を使用する理由は、潜在空間を視覚化するためであり、実際には、画像内のより大きなニュアンスをより自由に捉えるために、通常、潜在空間は 2 次元よりも高くなります。
2. モデル分析
2.1 最初の会議
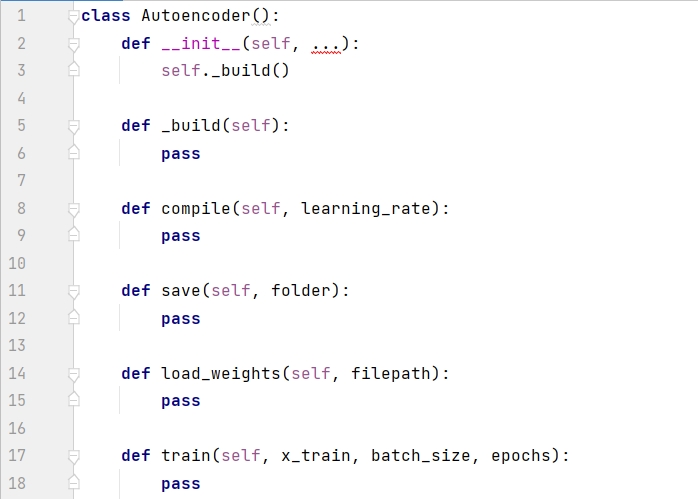
一般に、以下の Autoencoder クラスなど、モデルのクラスを別のファイルに作成するのが最善です。これにより、他のプロジェクトがこのクラスを柔軟に呼び出すことができます。次のコードは、最初に Autoencoder のフレームワークを示しています。__init__() はコンストラクターです。モデルは _build() を呼び出して作成されます。compile() 関数はオプティマイザーの設定に使用されます。save() 関数はモデルの保存に使用されます。 .load_weights() 関数は次回モデルを使用するときに重みをロードするために使用され、train() 関数はモデルをトレーニングするために使用されます。
構築関数には、8 つの必須パラメータと 2 つのデフォルト パラメータが含まれています。input_dim は画像の次元、z_dim は潜在空間の次元です。残りの 6 つの必須パラメータは、フィルタ (フィルタ) の数と、エンコーダとデコーダのフィルタリングです。カーネル サイズ (kernel_size)、ストライド サイズ (strides)。
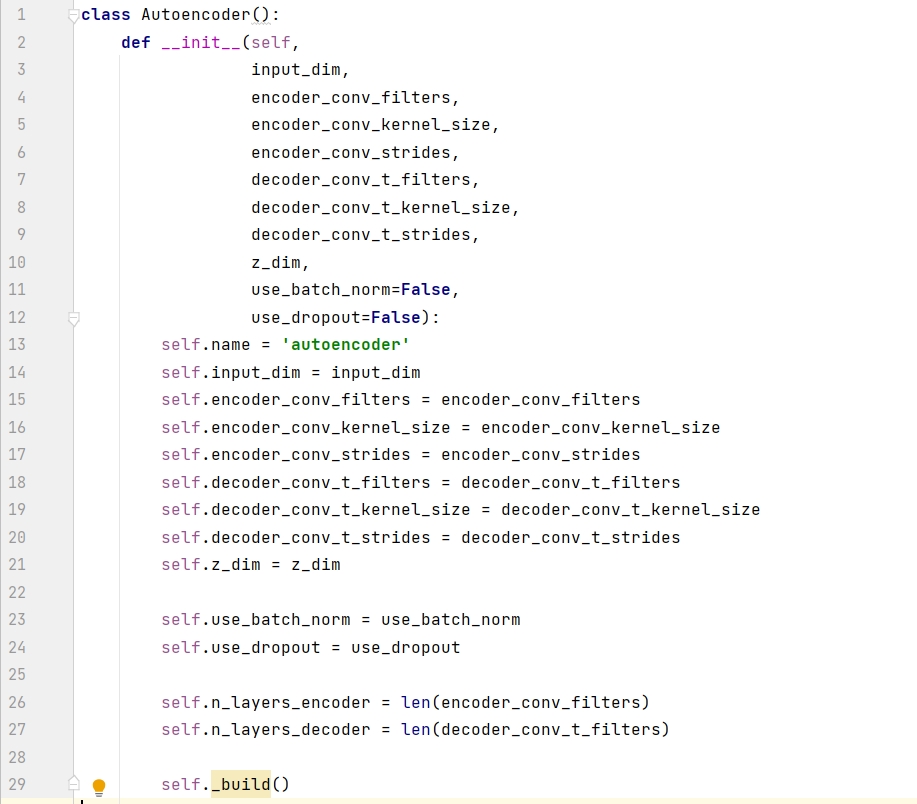
コンストラクター関数を使用してオートエンコーダーを作成し、AE という名前を付けます。入力データは白黒画像で、その次元は (28, 28, 1)、潜在空間は 2D 平面であるため、z_dim = 2 となります。また、6 つのパラメータの値はいずれも のサイズです。4 リストの場合、エンコード モデルとデコード モデルの両方に次のものが含まれます。4 層。
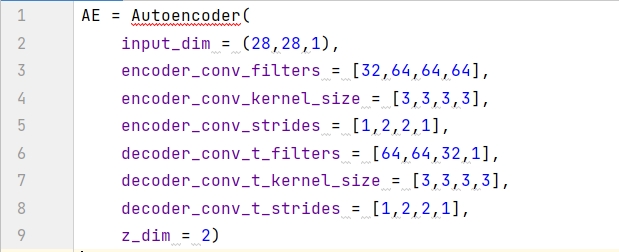
AutoEncoder クラスで _build() 関数を定義して、エンコーダーとデコーダーを構築し、その 2 つを接続します。コード フレームワークは次のとおりです (次の 3 つのセクションで 1 つずつ分析します)。

次の 2 つのセクションでは、オートエンコーダーのエンコード モデルとデコード モデルを 1 つずつ分析します。
2.2 コーディングモデル
エンコーダのタスクは、入力イメージを潜在空間内の点に変換することです。_build() 関数でのエンコード モデルの具体的な実装は次のとおりです。

コードについては以下で説明します。
行 2 ~ 3 では、エンコーダーへの入力として画像を定義します。
5 行目から 17 行目では、畳み込み層を順番に積み重ねます。
行 19 は x の形状を記録します。K.int_shape の戻り値はタプル (None、7、7、64) です。0 番目の要素はサンプル サイズです。データ形状 (7、7、64) を返すには [1:] を使用します。 64)。
行 20 は、最後の畳み込み層を 1D ベクトルに平坦化します。
21 行目の高密度層は、このベクトルをサイズ z_dim の別の 1D ベクトルに変換します。
行 22 では、エンコーダー モデルを構築し、Model() 関数の入力パラメーター encoder_input と encoder_output をそれぞれ決定します。
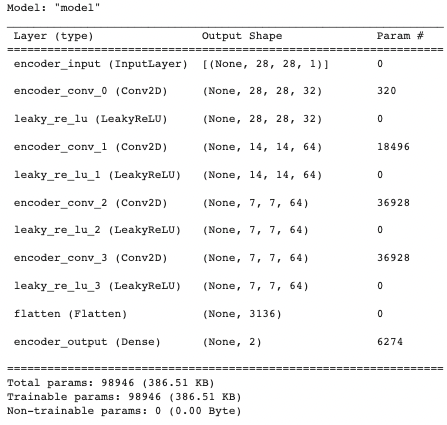
summary() 関数を使用して、エンコード モデルの情報を出力します。この情報は、各レイヤーの名前の種類 (レイヤー (type))、出力形状 (Output Shape)、パラメーターの数 (Param #) を記述するために使用されます。

2.3 デコードモデル
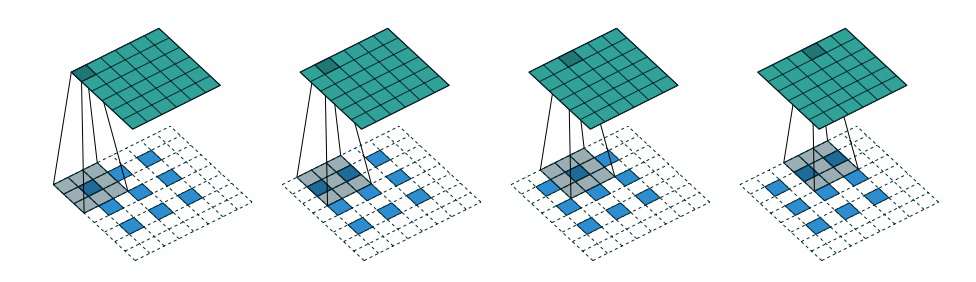
デコーダはエンコーダの鏡像ですが、畳み込み層を使用する代わりに畳み込み転置層を使用して構築されている点が異なります。ストライドが 2 に設定されている場合、畳み込み層は画像の高さと幅を毎回半分にし、畳み込み転置層は画像の高さと幅を 2 倍にします。具体的な操作については下図を参照してください。
_build() 関数でのデコーダーの具体的な実装は次のとおりです。
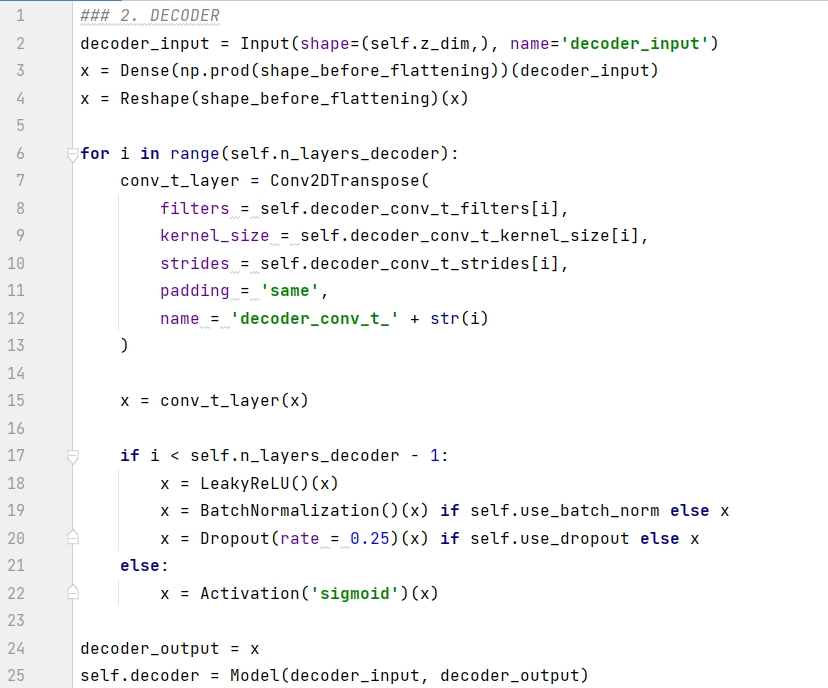
コードについては以下で説明します。
行 1 は、エンコーダーの出力をデコーダーの入力として定義します。
行 2 ~ 3 は、1D ベクトルを形状 (7, 7, 64) のテンソルに再形成します。
6 行目から 15 行目は、畳み込み転置層を順番に積み重ねます。
7行目から22行目:
最後のレイヤーの場合は、シグモイド関数を使用して変換すると、結果はピクセルとして 0 ~ 1 になります。
最後の層ではない場合は、関数 Leaky relu を使用して変換し、バッチ正規化とランダムなドロップアウト処理を追加します。
行 24 ~ 25 はデコーダ モデルを構築し、Model() 関数の入力パラメータ decoder_input と decoder_output をそれぞれ決定します。前者はエンコーダの出力、つまり潜在空間内の点であり、後者は再構成されたものです。画像。
summary() 関数を使用して、デコード モデル情報を出力します。


2.4 直列接続
エンコーダーとデコーダーを同時にトレーニングするには、2 つを接続する必要があります。

コードについては以下で説明します。
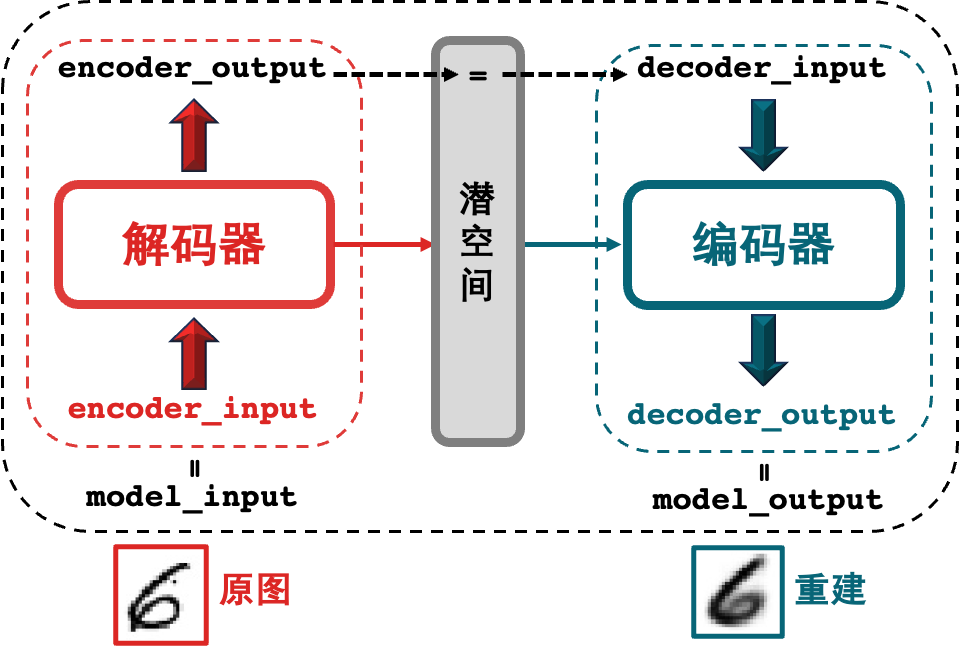
1 行目では、encoder_input をモデル全体の入力 model_input として使用します (中間積 encoder_output はエンコーダーの出力です)。
行 2 は、デコーダーの出力をモデル全体の出力 model_output として使用します (デコーダーの入力はエンコーダーの出力です)。
行 3 では、オートエンコーダー モデルを構築し、Model() 関数の入力パラメーター model_input と model_output をそれぞれ決定します。
百聞は一見にしかず。
2.5 トレーニングモデル
モデルを構築した後は、損失関数を定義してオプティマイザーをコンパイルするだけです。損失関数は通常、平均二乗誤差 (RMSE) として選択されます。 compile() 関数の実装は次のようになります。Adam オプティマイザーを使用し、学習率を 0.0005 に設定します。


fit() 関数を使用してモデルをトレーニングし、バッチ サイズを 32 に設定し、エポックを 200 に設定します。コードは次のとおりです。


テスト セットからランダムに 10 個を選択して、効果を確認します。
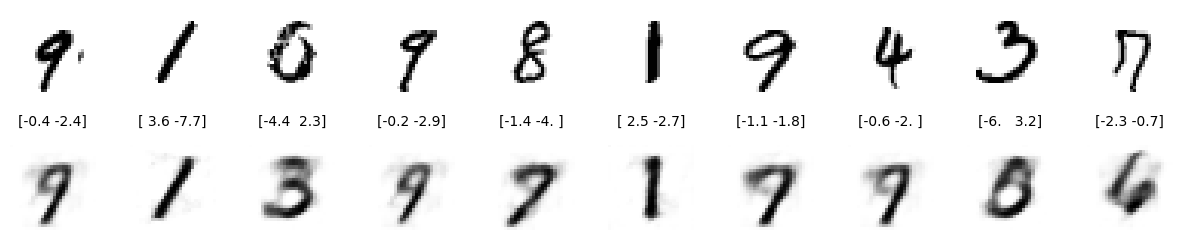
10 枚の画像のうち、適切な再構成結果が得られたのは 4 枚だけです。
3. 3 つの大きな欠陥
モデルがトレーニングされた後、潜在空間内の画像を視覚化できます。モデル内のエンコーダーによってテスト セットで生成された座標は、2D 散布図に表示されます。
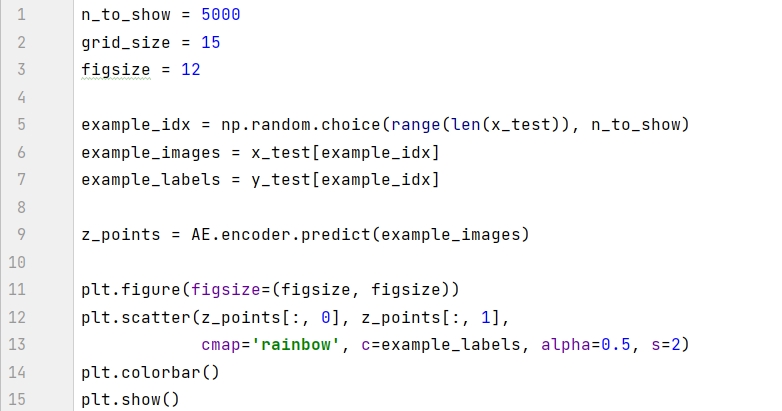
この図には注目に値する 3 つの現象があります。
赤い 9 のように小さな領域を占める数字もあれば、紫の 0 のように大きな領域を占める数字もあります。
グラフ内の点は (0, 0) に対して非対称です。たとえば、x 軸には正の値の点よりも負の値の点の方が多く、x =-15 に達する点もあります。
上の画像の左上隅のように、ドットがほとんど含まれていない色の間に大きなギャップがあります。
上記の 3 つの大きな欠陥により、潜在空間からのサンプリングが非常に困難になります。
欠陥 1 では、数字 9 が 0 よりも大きな領域を占めるため、9 をサンプリングする方が簡単です。
欠陥 2 については、技術的には、平面上の任意の点をサンプリングできます。しかし、それぞれの数値の分布は不確実であり、分布が対称的でない場合、無作為抽出は困難になります。
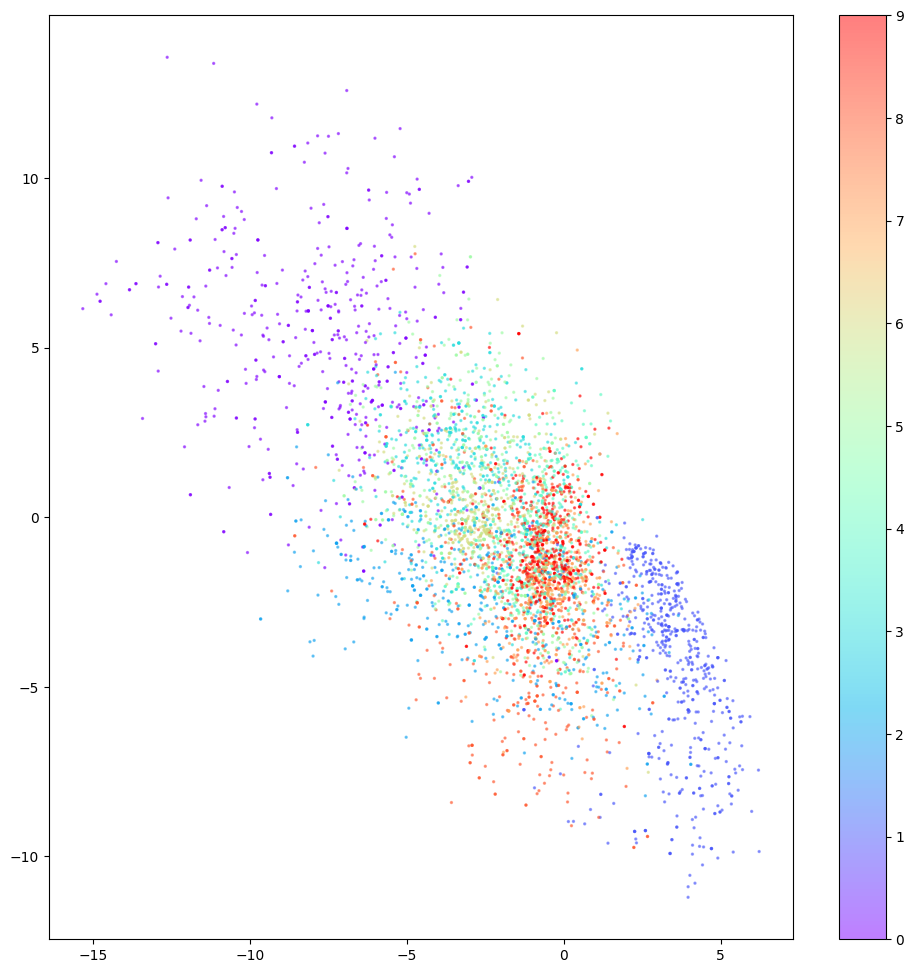
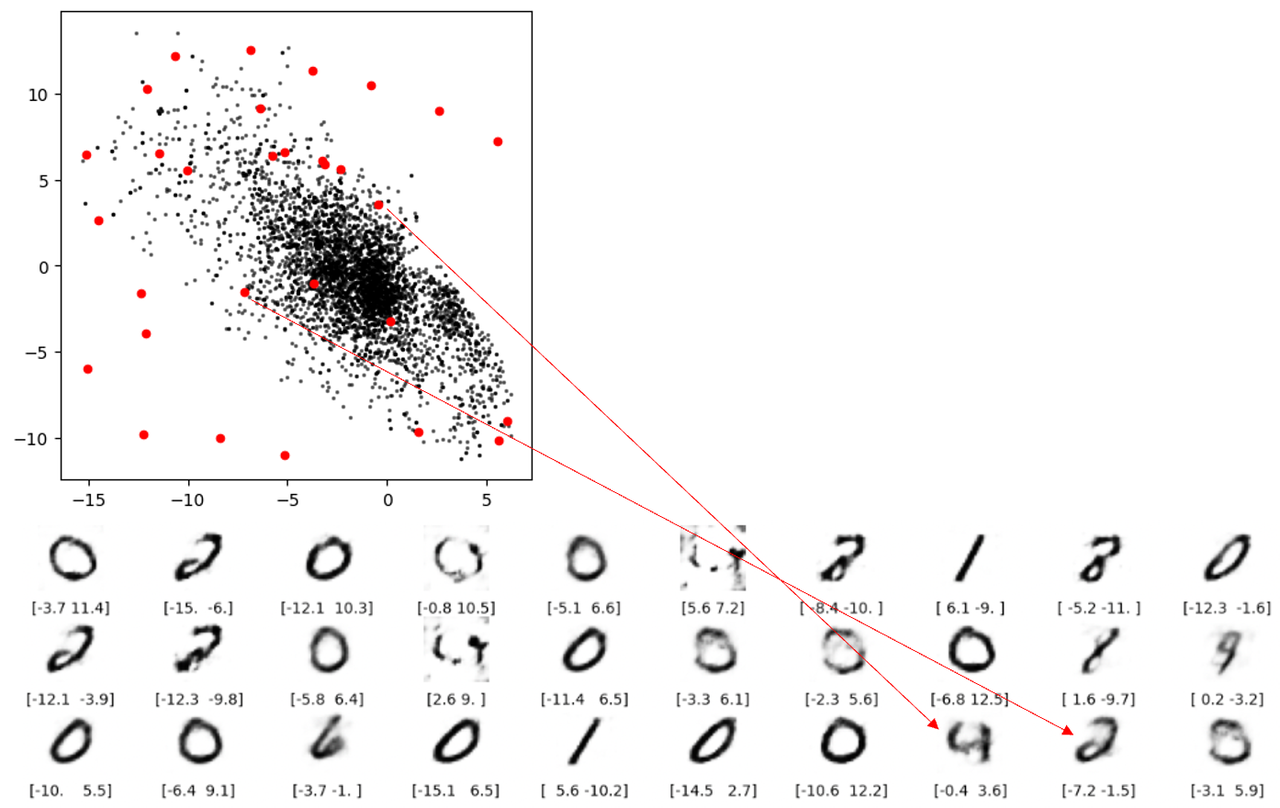
欠陥 3 に関しては、下の図から、潜在空間の空白からいくつかのまともな数値を再構成できないことがわかります。
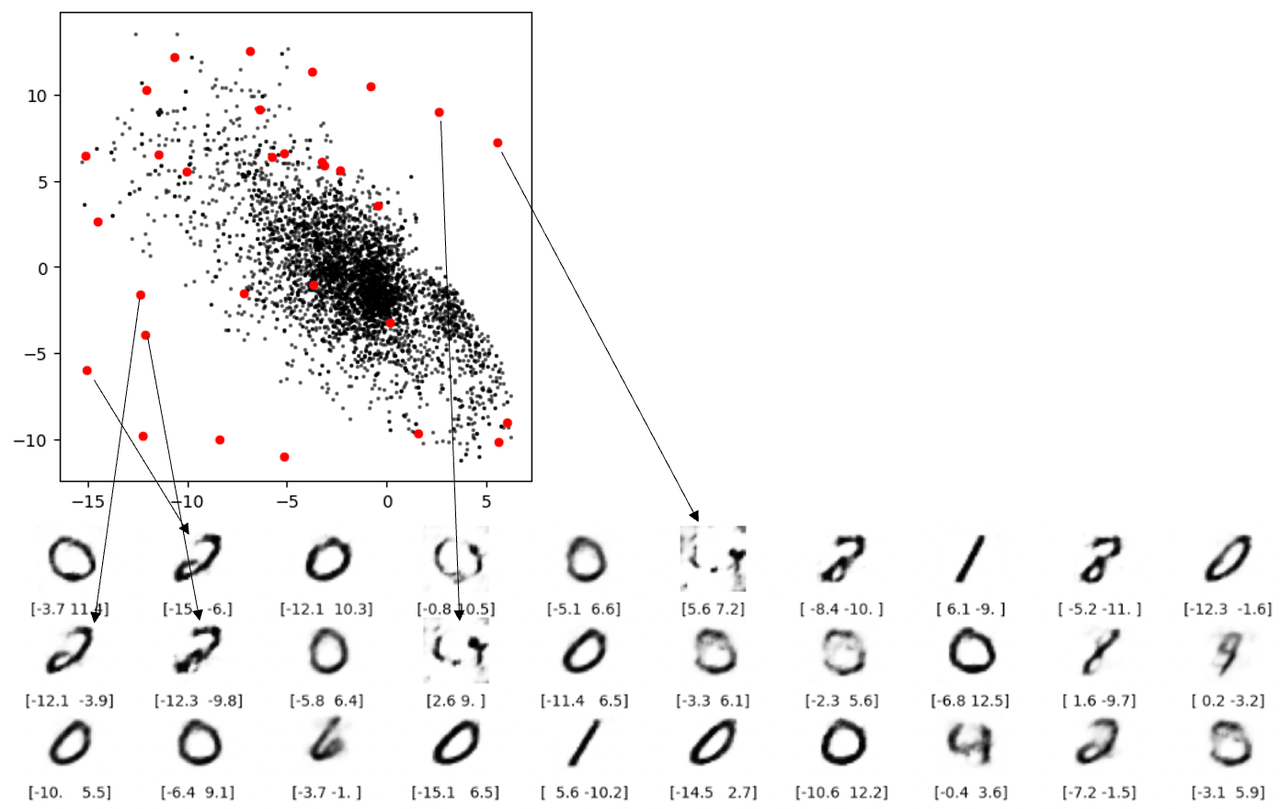
欠点 3: 空白の場合、再構成で数値が得られないことは簡単に理解できますが、下図の 2 本の赤い線で表される再構成は懸念されます。どちらのポイントもマージン内にはありませんが、それでもまともな数値にデコードできません。根本的な理由は、オートエンコーダーが、生成された潜在空間が連続的であるという保証を強制していないことです。たとえば、(2,-2) が満足のいく数値 4 を生成できたとしても、モデルには点が連続していることを保証するメカニズムがありません。 (2.1, – 2.1 ) も満足のいく数値 4 を生成します。
要約する
オートエンコーダーは特徴のみを必要とし、ラベルは必要ありません。データを再構築するために使用される教師なし学習モデルです。このモデルは生成モデルですが、前のセクションで述べた 3 つの主要な欠陥から、この生成モデルは低次元の白黒数値には適しておらず、高次元のカラー面の効果はさらに悪くなるでしょう。
このオートエンコーダー フレームワークは優れていますが、強力なオートエンコーダーを生成するには、これら 3 つの欠陥をどのように解決すればよいでしょうか。これは次の記事の内容ですが、変分オートエンコーダ (Variational AutoEncoder, VAE)。

ChatGPT 4.0 のプラグイン ストアで SignalPlus を検索すると、リアルタイムの暗号化情報を取得できます。最新情報をすぐに受け取りたい場合は、Twitter アカウント @SignalPlus_Web 3 をフォローするか、WeChat グループ (アシスタント WeChat を追加: SignalPlus 123)、Telegram グループ、および Discord コミュニティに参加して、より多くの友人と通信し、交流してください。
SignalPlus Official Website:https://www.signalplus.com


