
アンバー グループ: ゼロ知識証明の包括的な解釈
出典: アンバー・グループ

出典: アンバー・グループ
1 はじめに
ゼロ知識証明を使用すると、一方の当事者が追加情報を明らかにすることなく、もう一方の当事者に対して信頼性を証明できます。したがって、すべての詳細を隠しながらプライバシーを保護し、取引の正当性を検証するために使用できます。 STARK や SNARK など、特定のゼロ知識プロトコルがゼロ知識証明の検証に便利であることが重要です。これらのプロトコルはより小さなプルーフを生成し、そのようなプルーフの検証ははるかに高速になります。これはリソースに制約のあるブロックチェーンに適しており、暗号通貨業界のスケーラビリティの問題に対処する場合に特に重要です。これとは別に、ゼロ知識テクノロジーの他の使用例には次のものがあります。
DID (分散型 ID) - アカウントまたはエンティティが特定の情報を持っていることを証明するため"特徴"特徴
、シスモ、ファーストバッチなど
コミュニティ ガバナンス - 匿名投票用。このユースケースは、実証され広く採用された後、現実世界のガバナンスに拡張できます。
財務諸表 – 企業は、正確な財務数値を開示せずに、特定の基準への準拠を証明できます。
……
クラウド サービスの整合性 - クラウド サービス プロバイダーがミッションをより適切に遂行できるように支援する
典型的なゼロ知識システム
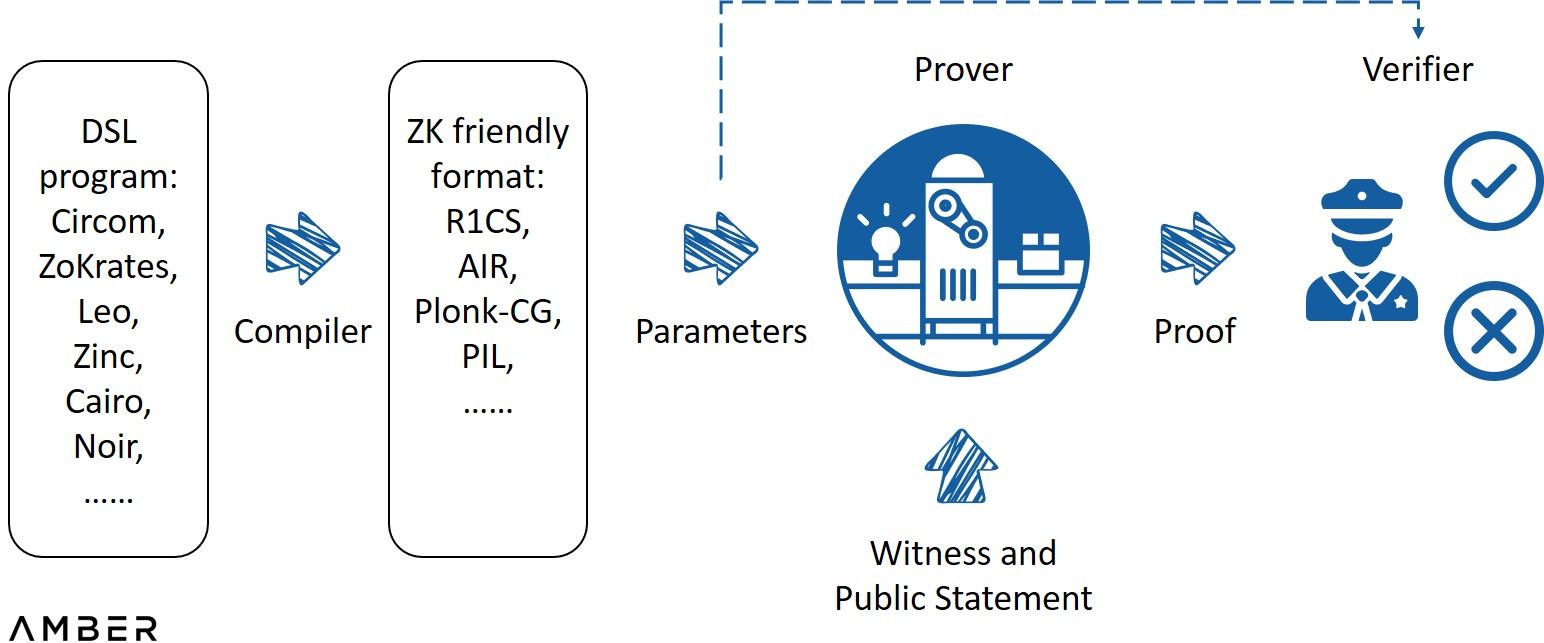
画像の説明
出典: ZK ホワイトボード セッション - モジュール 1、Dan Boneh 教授執筆
Marlin、Plonky2、Halo2 など、いくつかの優れた証明システムがリリースされています。プルーフ システムが異なれば、生成されるプルーフのサイズ、検証に必要な時間、信頼できるセットアップが必要かどうかなどの特性に重点が置かれます。数年間の探求の結果、ステートメントがどれほど複雑であっても、一定の証明サイズ (数百バイト) と短い検証時間 (ミリ秒) を達成することが可能になりました。
ただし、証明生成の複雑さは算術ループのサイズにほぼ比例するため、難易度は元のタスクの数百倍になる場合もあります。証明者は少なくともループを読んで評価する必要があるため、これには数秒から数分、場合によっては数時間かかる場合があります。高い計算能力と長い証明時間は、ゼロ知識技術の進歩と大規模な応用に対する主な障害となってきました。
ハードウェア アクセラレーションはボトルネックの解消に役立ちます。アルゴリズムまたはソフトウェアの最適化を使用して、複数のタスクを最適なハードウェアに分散し、相互に補完します。
このレポートは、読者が市場の状況、ゼロ知識テクノロジーがマイニング市場に与える影響、および潜在的な機会を理解するのに役立つことを目的としています。レポートは 3 つの部分で構成されます。
エピローグ
エピローグ
最初のレベルのタイトル
2. ユースケース
ゼロ知識のユースケースを列挙すると、市場がどのように進化しているかを説明するのに役立ちます。カテゴリが異なればニーズも異なるため、ハードウェアの供給も関係します。このセクションの最後では、ZKP と PoW (特にビットコイン) を簡単に比較します。
2.1 新しいブロックチェーンとその差別化された要件
ゼロ知識技術を使用した現在新興のブロックチェーンは、ハードウェア アクセラレーションの主な需要側であり、スケーリング ソリューションとプライバシー保護ブロックチェーンに大別できます。ゼロ知識ロールアップまたはボリションは、オフチェーンでトランザクションを実行し、「calldata」関数を介して簡潔な検証証明を送信します。プライバシー保護ブロックチェーンは ZKP を使用して、ユーザーがトランザクションの詳細を開示することなく、開始されたトランザクションの正当性を保証できるようにします。
これらのブロックチェーンは、さまざまな証明システムを使用することで、証明サイズ、検証時間、信頼できる設定などの特性をトレードオフします。たとえば、Plonk によって生成された証明は一定の証明サイズ (約 400 バイト) と検証時間 (約 6 ミリ秒) を持ちますが、依然として共通の信頼できるセットアップが必要です。対照的に、Stark は信頼できるセットアップを必要としませんが、その証明サイズ (~80KB) と検証時間 (~10ms) は最適ではなく、ループ サイズとともに増加します。他のシステムにも長所と短所があります。これらの証明システム間のトレードオフは、計算量の「重心」の変化につながります。
具体的には、現在の証明システムは一般に、PIOP (Polynomial Interactive Proof of Prophecy) + PCS (Polynomial Commitment Scheme) として説明できます。前者は証明者が検証者を説得するために使用する合意されたプログラムと考えることができ、後者はプログラムが破られないことを保証するために数学的手法を使用します。 PCS が銃、PIOP が弾丸のようなものです。プロジェクト関係者は、必要に応じて PIOP を変更し、さまざまな PCS から選択できます。パラダイムのゲオルギオス・コンスタントプロス氏の著書ハードウェアアクセラレーションに関するレポート
で説明したように、証明の生成に必要な時間は主に、MSM (多重スカラー倍算アルゴリズム) と FFT (高速フーリエ変換) という 2 つのクラスの計算タスクに依存します。ただし、固定パラメータを使用する代わりに、異なる PIOP を確立し、異なる PCS から選択すると、FFT または MSM の計算が異なります。 Stark を例にとると、Stark が使用する PCS は、KZG や IPA で使用される楕円曲線ではなく、Liso コードに基づく FRI (Fast Reed-Solomon Code Proximity Interaction Proof) であるため、全体的に完全に独立しています。プルーフ生成プロセスには、MSM が関与します。以下の表に各証明システムの計算量を大まかに整理しましたが、1) システム全体の正確な計算量を見積もることは困難である、2) 通常、プロジェクト当事者は実装中に必要に応じてシステムを修正します。 。
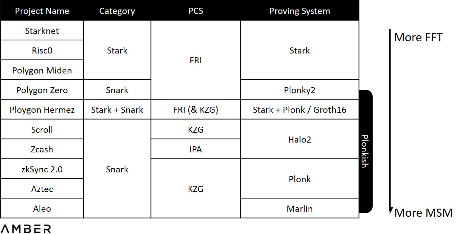
各種証明システムの計算量
上記の状況により、プロジェクト関係者は独自のハードウェア タイプの好みを持つことになります。 GPU (グラフィックス プロセッシング ユニット) は、その供給量の多さと開発の容易さにより、現在最も広く使用されています。さらに、GPU のマルチコア構造は、MSM の並列計算に非常に便利です。ただし、FPGA (フィールド プログラマブル ゲート アレイ) は FFT の処理に優れている可能性があります。これについてはパート II で詳しく説明します。 Starknet や Hermez など、Stark を使用するプロジェクトでは、さらに FPGA が必要になる場合があります。
上記から導き出されるもう 1 つの結論は、このテクノロジーはまだ初期段階にあり、標準化されたソリューションや有力なソリューションが欠けているということです。また、特定のアルゴリズム専用の ASIC (特定用途向け集積回路) を完全に使用するには時期尚早かもしれません。そのため、開発者は中間点を模索していますが、これについては後で詳しく説明します。
2.2 トレンドと新しいパラダイム
2.2.1 より複雑なステートメント冒頭に挙げたユースケースを踏まえると、ゼロ知識は暗号業界や現実世界でさらに多くの用途があり、より複雑な証明が可能になり、その中には現在の証明システムに準拠する必要さえないものもあると予想されます。 PIOP と PCS を使用する代わりに、プロジェクト関係者は、自分たちに最も適した新しいプリミティブを開発できます。また、MPC (安全なマルチパーティ計算) などの他の分野では、一部の作品にゼロ知識プロトコルを採用することで、その有用性が大幅に向上します。イーサリアムは最近、プロトダンクシャーディングをホストすることも計画していますKZGの信頼できるセッティングセレモニー将来的には、データの可用性サンプリングを処理するために Danksharding のフルバージョンをさらに実装する予定です。偶数楽観的ロールアップ将来的にはZKPの採用も可能
セキュリティを向上させ、紛争処理時間を短縮するため。多くの人はゼロナレッジを広範な暗号通貨業界内の別の分野と見なすかもしれませんが、私たちはゼロナレッジを業界の複数の問題点に対処するテクノロジーとして見るべきだと考えています。
一方で、さまざまなシステムや顧客にサービスを提供するために、ハードウェア アクセラレーションは将来的により柔軟で多用途になるでしょう。
。クライアント バージョンを提供することは、このタイプの dapp にとって簡単な解決策ですが、ダウンロードする必要があるため、一部の潜在的なユーザーが失われる可能性があり、クライアントは現在の拡張機能ウォレットやその他のツールには適していません。もう 1 つの解決策は、プルーフの生成を部分的にアウトソーシングすることです。第 7 回ゼロ知識サミットで発表した Pratyush Mishra 氏この方法
アウトソーシングされたプルーフ生成
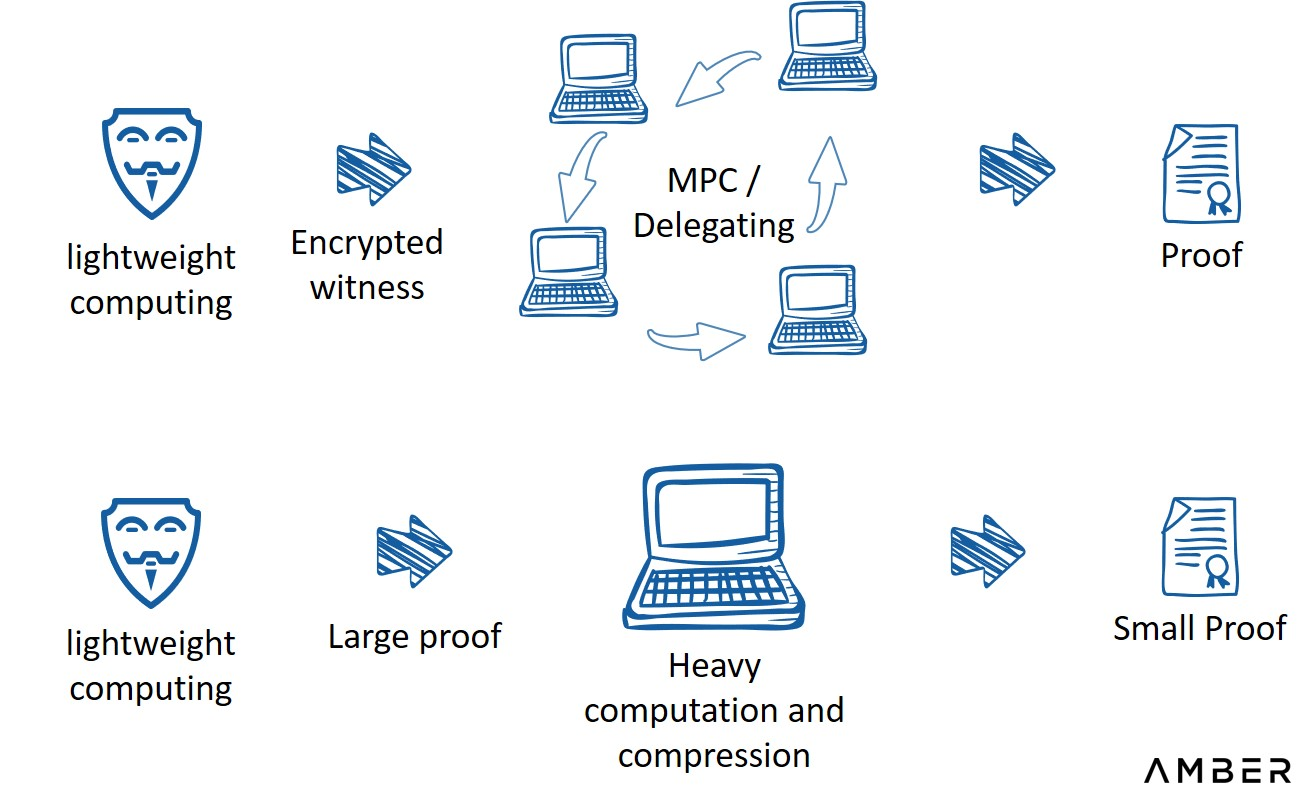
画像の説明
出典: 第 7 回ゼロ知識サミット、アレオのプラテュシュ・ミシュラ氏提供
2.3 PoWマイニングとの比較
ZKP を新しい形式の PoW と考え、アクセラレーション ハードウェアを新しいタイプのマイニング マシンとみなすのは自然ですが、ZKP の生成は、目的と市場構造の点で PoW マイニングとは根本的に異なります。
2.3.1 電力競争と効用計算
Rates-are-Odds (Aleo):ブロック報酬と取引手数料を獲得するために、ビットコインマイナーはノンスを反復して、実際にはコンセンサスにのみ関係する十分に小さいハッシュ値を見つけます。対照的に、ZKP の生成は、情報圧縮やプライバシー保護などの実用性を実現するために必要なプロセスであり、コンセンサスに責任を負いません。この区別は、ZKP の潜在的に広範な参加と報酬分配モデルに影響を与えます。以下に 3 つの既存の設計をリストし、マイナーが ZKP 生成をどのように調整するかを示します。
Winner-Dominates(Polygon Hermez):Aleo の経済モデル設計は、ビットコインや他の PoW プロトコルの経済モデル設計に最も近いです。そのコンセンサスメカニズムPoSW(Concise Proof of Work)では依然としてマイナーが効果的なランダム値を見つける必要がありますが、検証プロセスは主に、ランダム値と状態ルートのハッシュ値を入力として使用するSNARKプルーフの繰り返し生成に基づいています。このプロセスは、特定のラウンドで生成された証明ハッシュ値が十分に小さくなるまで継続されます。単位時間内に処理できる検証の数によって報酬を獲得できる確率がおおよそ決まるため、この PoW のようなメカニズムを Rates-are-Odds モデルと呼びます。このモデルでは、マイナーは多数のコンピューティング マシンを蓄えることで、報酬を受け取る可能性を高めます。Polygon Hermez はより単純なモデルを採用しています。彼らによると公文書
Party-Thresholds (Scroll):コンテンツの観点から見ると、2 つの主なプレーヤーは注文者とアグリゲーターであり、注文者はすべてのトランザクションを収集して新しい L2 バッチに前処理し、アグリゲーターは検証の意図を指定し、証明を生成するために競合します。特定のバッチについて、最初にプルーフを送信したアグリゲーターが、注文者が支払う料金を受け取ります。最先端の構成とハードウェアを備えたアグリゲーターが、地理的な分布、ネットワークの状態、検証戦略に関係なく、優位性を発揮する可能性があります。
Scroll は、その設計を「レイヤー 2 プルーフ アウトソーシング」と説明しており、一定量の暗号通貨をステーキングするマイナーがプルーフを生成するために恣意的に選択されます。選択されたマイナーは、指定された時間内に証明を提出する必要があります。そうしないと、次のエポックでの選択確率が低くなります。間違った証拠を提出すると罰金が科せられます。当初、Scroll はおそらく、安定性を向上させるために十数個のマイナーと連携し、独自の GPU も実行することになるでしょう。そして、時間の経過とともに、プロセス全体を分散化する予定です。この分散実装時間ノードをパラメータとして使用して、効率と分散の間の Scroll の重心の調整を測定します。 Starkware もこのカテゴリに分類される可能性があります。長期的には、適時に証明を完了する能力を持つマシンのみが証明生成に参加できます。これらのコーディネートされたデザインにはそれぞれ異なる焦点があります。私たちは、Aleo が最も分散性が高く、Hermez が最も効率的で、Scroll が参加の障壁が最も低いと予想しています。
しかし、上記の設計に基づくと、ゼロ知識ハードウェアの軍備競争がすぐに起こる可能性は低いです。
2.3.2 静的アルゴリズムと進化的アルゴリズム
単純で静的なPoW市場と比較して、ZKPの違いはより分散化された動的な市場構造に貢献すると信じています。私たちは、ZKP の生成をサービスとして考えることを提案します (一部のスタートアップでは、ZK-as-a-Service と命名しています)。ZKP の生成は目的ではなく目的への手段です。この新しいパラダイムは、最終的には新しいビジネス モデルまたは収益モデルにつながります。これについては、最後のセクションで詳しく説明します。その前に、複数の解決策を見てみましょう。
最初のレベルのタイトル
3. 解決策
CPU (中央処理装置) は汎用コンピュータの主要チップであり、マザーボード上のさまざまなコンポーネントに命令を分配する役割を果たします。ただし、CPU は複数のタスクを迅速に処理するように設計されているため、処理速度が制限されるため、GPU、FPGA、および ASIC は、同時タスクや特定の特定のタスクを処理する際のアシスタントとして使用されることがよくあります。このセクションでは、それらの特徴、最適化プロセス、現状、市場に焦点を当てます。
3.1 GPU: 現在最も一般的に使用されているハードウェアpippengerGPU は元々、コンピューター グラフィックスを操作し、画像を処理するために設計されましたが、その並列構造により、コンピューター ビジョン、自然言語処理、スーパーコンピューティング、PoW マイニングなどの分野で優れた選択肢となっています。 GPU は、いわゆる「」を利用することで、MSM と FFT、特に MSM を高速化できます。
」アルゴリズムを使用すると、GPU の開発プロセスは FPGA や ASIC よりもはるかに簡単になります。
GPU での高速化の考え方は非常にシンプルです。これらの計算要求の高いタスクを CPU から GPU にオフロードします。エンジニアはこれらの部分を CUDA または OpenCL に書き換えます。CUDA は、Nvidia GPU での一般的なコンピューティングのために Nvidia によって開発された並列コンピューティング プラットフォームおよびプログラミング モデルです。CUDA の競合相手は、Apple と Khronos Group によって開発されたヘテロジニアス コンピューティングです。標準の OpenCL を提供するため、ユーザーはもはやNVIDIA GPU に限定されます。これらのコードはコンパイルされ、GPU 上で直接実行されます。さらに高速化するために、開発者は次のこともできます。
(1) データ転送コスト (特に CPU と GPU の間) を削減するには、できるだけ高速なストレージを使用し、低速なストレージを使用してメモリを最適化します。
(2) ハードウェアの使用率を向上させ、ハードウェアを可能な限りフル稼働させるために、マルチプロセッサ間の作業のバランスを改善し、マルチコアの同時実行性を構築し、タスクにリソースを合理的に割り当てることにより、実行構成を最適化します。
つまり、作業プロセス全体を並列化するために最善を尽くしたいと考えています。同時に、前の項目の結果に後者の項目が依存するような逐次実行処理も極力避けるべきである。
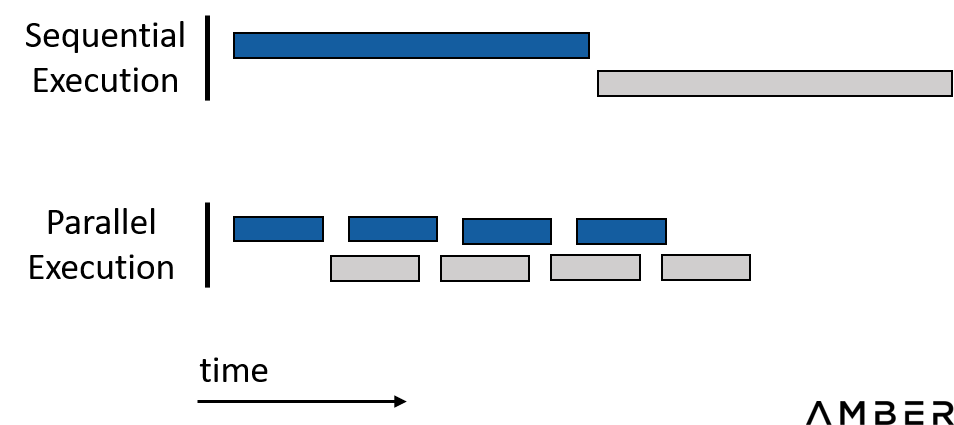
並列化で時間を節約

GPU アクセラレーションによる設計フロー
3.1.1 巨大な開発者グループと開発の利便性FPGA や ASIC とは異なり、GPU 開発にはハードウェア設計が含まれません。 CUDA または OpenCL にも大規模な開発者コミュニティがあります。開発者は、オープン ソース コードに基づいて独自の修正バージョンを迅速に構築できます。たとえば、2020 年にリリースされた Filecoin。 Supranational も最近、全体的な加速をオープンソース化しました解決解決
、これはおそらく現時点でこの種のオープンソース ソリューションの中で最良のものです。この利点は、MSM や FFT を超えた作業を考慮するとさらに顕著になります。確かにプルーフの生成はこれら 2 つの項目が大半を占めていますが、他の部分も依然として約 20% を占めています (出典:Sin7Y のホワイトペーパー
)、そのため、MSM と FFT を高速化するだけでは、証明時間の短縮には限定的な効果があります。この 2 つの項目の計算時間が一瞬に短縮されたとしても、合計の所要時間は元の時間の 5 分の 1 にすぎません。また、これは新たに出現し進化している枠組みであるため、この比率が将来どのように変化するかを予測することは困難です。 FPGA を再構成する必要があり、実稼働用に ASIC も再設計する必要がある可能性があることを考慮すると、ヘテロジニアス コンピューティング ジョブを高速化するには GPU の方が便利です。
3.1.2 余剰GPU
GPUチップの市場シェア
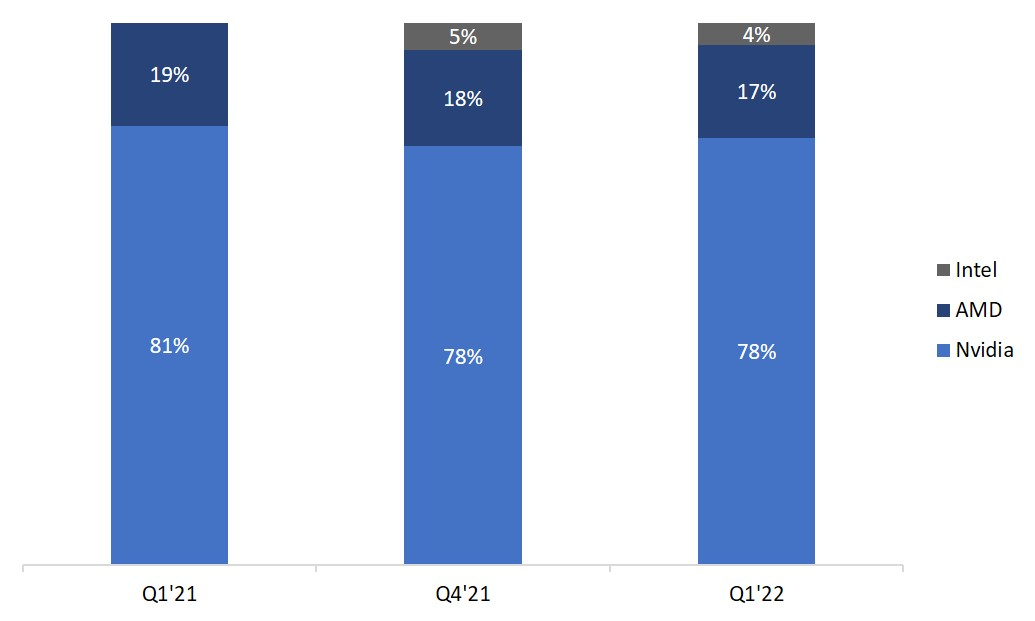
画像の説明
出典: ジョン・ペディ調査特にマイニングについては、控えめに見積もってください。イーサリアムの合併
イーサリアムのハッシュレート
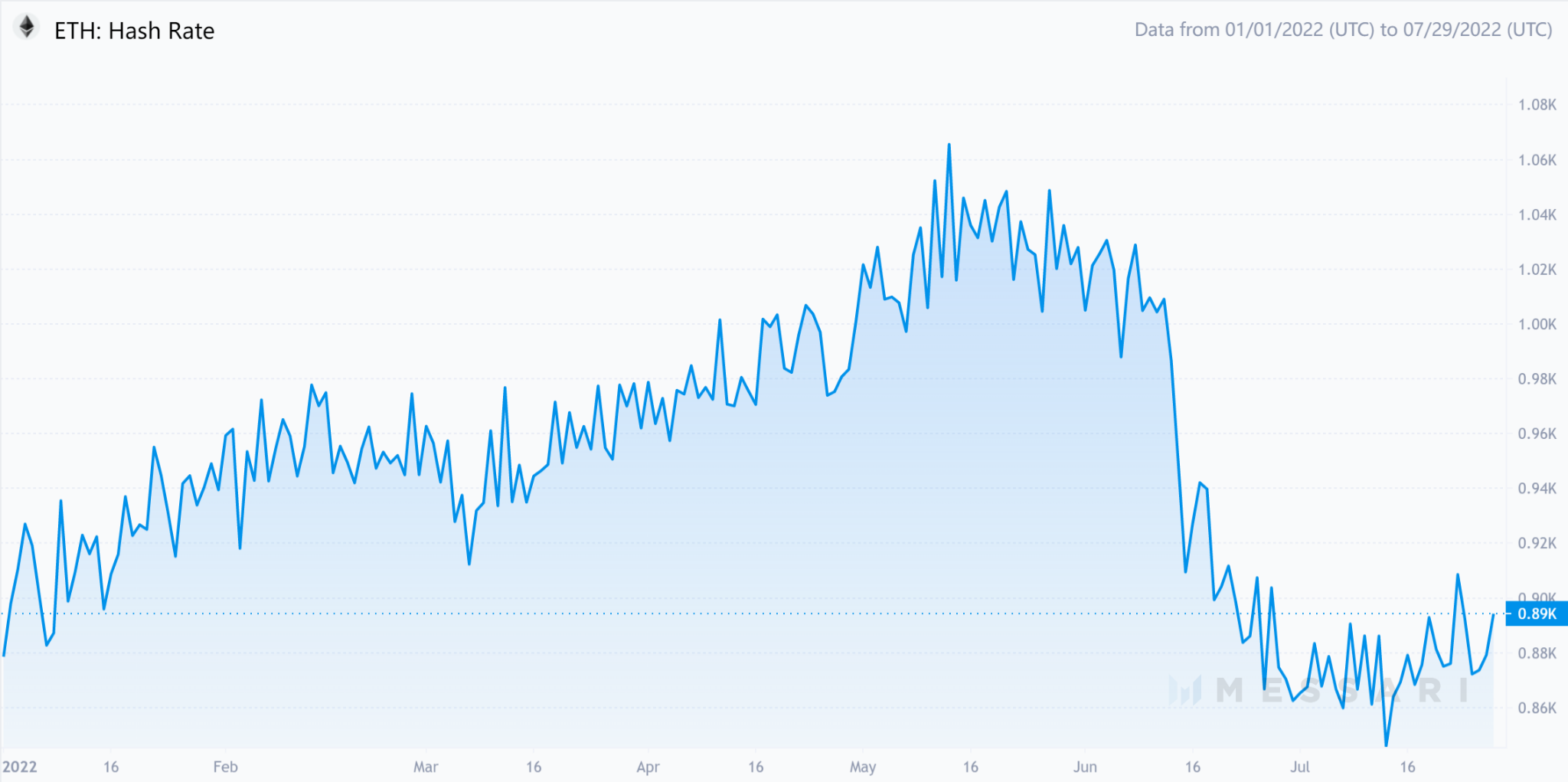
画像の説明
出典: メッサーリ
3.2 FPGA: コストと効率のバランス
FPGA は、プログラム可能な構造を備えた集積回路です。 FPGA チップ内の回路はハードエッチングされていないため、設計者は必要に応じて何度でも再プログラムできます。一方で、これにより ASIC の高い製造コストが効果的に削減されます。一方で、ハードウェア リソースの使用は GPU よりも柔軟であるため、FPGA はさらなる高速化と省電力化の可能性を秘めています。たとえば、GPU 上で最適化された FFT を実装することは可能ですが、データを頻繁にシャッフルすると、GPU と CPU の間で大量のデータ転送が発生します。ただし、シャッフルは完全にランダムではなく、組み込みロジックを回路設計に直接プログラムすることで、FPGA はタスクをより高速に実行できるようになります。
FPGA で ZKP アクセラレーションを実現するには、さらにいくつかの手順が必要です。まず、C/C++ で書かれた特定の証明システムのリファレンス実装が必要です。そして、より高次のデジタル論理回路を記述するためには、この実装をHDL(Hardware description Language)で記述する必要があります。
次に、デバッグをシミュレートして入力波形と出力波形を表示し、コードが期待どおりに実行されているかどうかを確認する必要があります。このステップは、最も多くの実装が必要となるステップです。エンジニアはプロセス全体を必要とするわけではありませんが、2 つの出力を比較するだけで軽微なエラーを特定できます。次に、シンセサイザーは、HDL をゲートやフリップフロップなどの要素を含む実際の回路設計に変換し、その設計をデバイス アーキテクチャおよびよりアナログ解析に適用します。回路が適切に機能することが確認されたら、最終的にプログラミング ファイルが作成され、FPGA デバイスにロードされます。
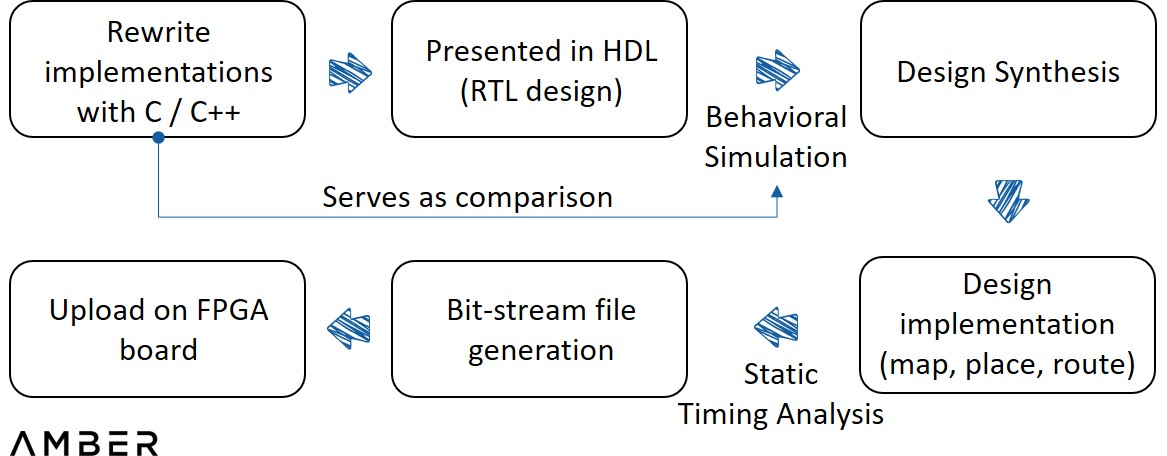
FPGA設計フロー
3.2.1 現在の障壁と不完全なインフラストラクチャー
GPU でのモジュール最適化作業の一部は再利用できますが、いくつかの新しい課題にも直面しています。
(1) より高いメモリセキュリティとより優れたクロスプラットフォーム互換性を実現するために、ほとんどのゼロ知識オープンソース実装は長い間 Rust で書かれてきましたが、ほとんどの FPGA 開発ツールはハードウェア エンジニアにとってより馴染みのある C/C++ で書かれています。の。チームは、これらの実装を実装する前に、書き直すかコンパイルする必要がある場合があります。
(2) これらの実装を作成する場合、ソフトウェア エンジニアは、既存の開発サポートを通じてハードウェア アーキテクチャにマッピングできる限られた範囲の C/C++ オープン ソース ライブラリ内のコードのみを選択できます。
(3) ソフトウェア エンジニアとハードウェア エンジニアが独立して完了できる作業に加えて、詳細な最適化を完了するには緊密な協力も必要です。たとえば、アルゴリズムにいくつかの変更を加えると、以前と同じ役割を確実に果たしながら、多くのハードウェア リソースが節約されますが、この最適化はハードウェアとソフトウェアの理解に基づいています。つまり、AI や他の成熟した分野とは異なり、ZKP の高速化を達成するには、エンジニアは学習してゼロから構築する必要があります。幸いなことに、さらなる進歩が見られました。たとえば、インゴンヤマ最近の論文
PipeMSM は で提案されており、FPGA または ASIC 上で MSM を高速化する方法です。
3.2.2 複占市場
FPGA市場は典型的な複占市場である
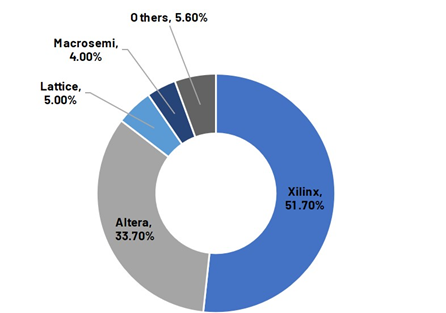
画像の説明
出典: フロスト&サリバン
エンジニアは、単一の FPGA では複雑な ZKP 生成に十分なハードウェア リソースを提供できないため、検証には複数のカードを同時に使用する必要があることに気づきました。完全な設計であっても、AWS やその他のベンダーが提供する既存の標準 FPGA クラウド製品は理想的ではありません。さらに、高速化ソリューションを提供するスタートアップ企業は、AWS などにカスタム ハードウェアをホストさせるには規模が小さすぎることが多く、独自のサーバーを実行するリソースもありません。大規模なマイナーと協力するか、Web3 ネイティブのクラウド サービス プロバイダーと協力する方が良い選択かもしれません。ただし、鉱山会社の社内エンジニアも高速化ソリューションを開発する可能性が高いことを考慮すると、この提携は微妙になる可能性があります。
3.3 ASIC: 最終兵器
ASIC は、特定の目的のためにカスタマイズされた集積回路 (IC) チップです。通常、エンジニアは依然として HDL を使用して、FPGA を使用するのと同様の方法で ASIC のロジックを記述しますが、FPGA の回路は数千の構成可能なブロックを接続することによって作成されるのに対し、最終回路はシリコン内に永続的に描画されます。企業は、Nvidia、Intel、AMD からハードウェアを調達するのではなく、回路設計から製造、テストに至るプロセス全体を自社で管理する必要があります。 ASIC は特定の機能に制限されますが、その代わりにリソース割り当てと回路設計に関して設計者に最大限の自由度を与えるため、ASIC はパフォーマンスとエネルギー効率の点で大きな可能性を秘めています。設計者は、意図した用途に基づいてドアの正確な数を設計したり、さまざまなモジュールのサイズを変更したりするだけで、スペース、電力、機能の無駄を排除できます。
設計プロセスの観点から見ると、FPGA と比較して、ASIC は HDL の作成と統合の 2 つのステップの間にスライス前の検証 (および DFT) を追加する必要があり、実装前にフロアプランニングが必要です。前者はエンジニアが高度なシミュレーション ツールを使用して仮想環境で設計をテストするもので、後者はチップ内のブロックのサイズ、形状、位置を決定するために使用されます。設計が実現したら、すべてのファイルはテストテープ出力のために TSMC や Samsung などのファウンドリに送信されます。テストが成功すると、プロトタイプは組み立てとテストのために送られます。
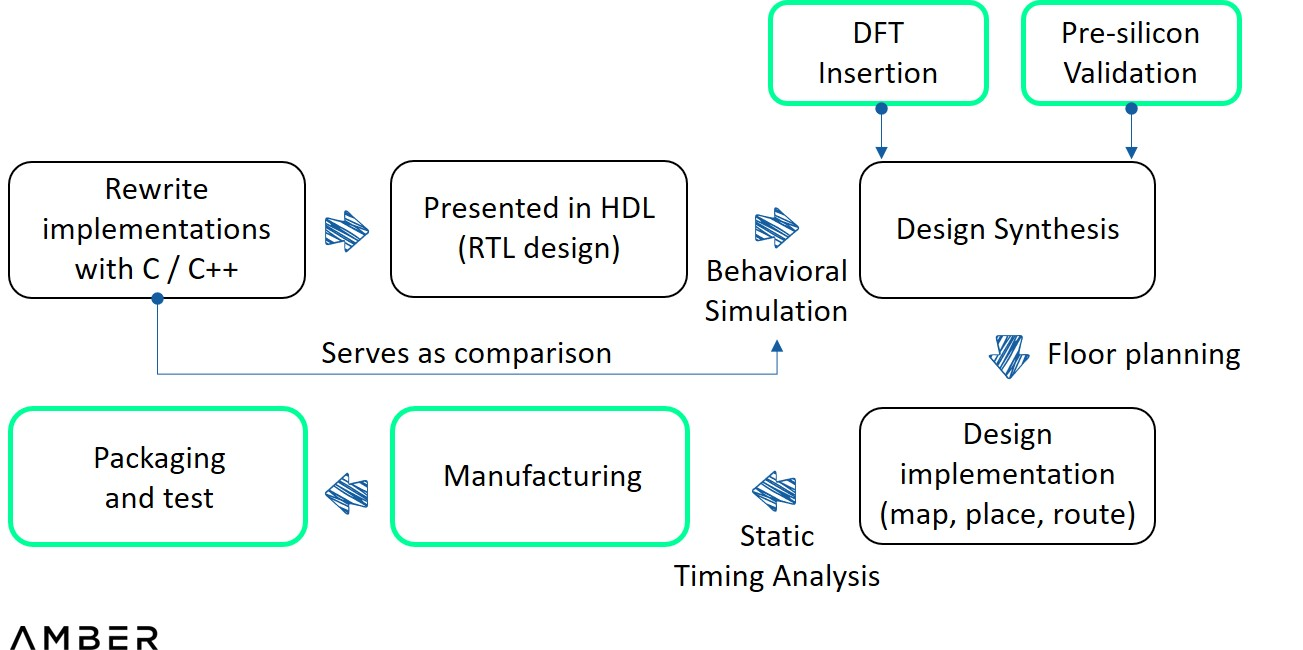
ASIC設計フロー
3.3.1 ゼロ知識分野で比較的一般的な ASIC
ASIC に対するよくある批判は、アルゴリズムが変わると以前のチップはまったく役に立たなくなるというものですが、必ずしもそうである必要はありません。
偶然にも、ASIC の開発を計画している私たちが話を聞いた企業の中で、特定の実証システムやプロジェクトに全力で取り組んでいた企業はありませんでした。代わりに、ASIC 上でいくつかのプログラム可能なモジュールを開発し、これらのモジュールを通じてさまざまな証明システムを処理し、MSM タスクと FFT タスクのみを ASIC に割り当てることを好みます。これは、特定のプロジェクトの特定のチップには最適ではありませんが、短期的には、特定のタスク向けに設計するよりも、パフォーマンスを犠牲にして汎用性を高めたほうが良い場合があります。
3.3.1 高額だが非経常的なコスト
ASIC の設計プロセスは FPGA よりもはるかに複雑であるだけでなく、製造プロセスにも多くの時間と費用がかかります。スタートアップ企業は、テープアウトについてファウンドリに直接連絡することも、ディストリビューターを通じて連絡することもできます。実際に執行が開始されるまでには3か月以上かかる場合があります。テープアウトの主なコストはレチクルとウェーハから発生します。レチクルは、シリコンの薄いスライスであるウェーハ上にパターンを作成するために使用されます。スタートアップ企業は通常、レチクルとウエハの製造コストを他のプロジェクト関係者と分担できるMPW(マルチプロジェクトウエハ)を選択します。ただし、プロセスと選択するチップの数によっては、テープアウトのコストは控えめに見積もっても数百万ドルになります。テープアウト、組み立て、テストはまだ数か月かかります。それが実現できれば、いよいよ量産の準備を始めることができる。しかし、テストで何か問題が発生した場合、デバッグと障害解析に計り知れない時間がかかり、再度タップアウトが必要になります。初期設計から量産までには数千万の資金が必要で、約18カ月かかる。これらのコストの大部分は非経常的なものであるという事実をご安心ください。さらに、ASIC は高性能であり、エネルギーとスペースを節約できます。これは非常に重要であり、価格も比較的低い場合があります。
以下に、さまざまなハードウェア ソリューションの一般的な評価を示します。
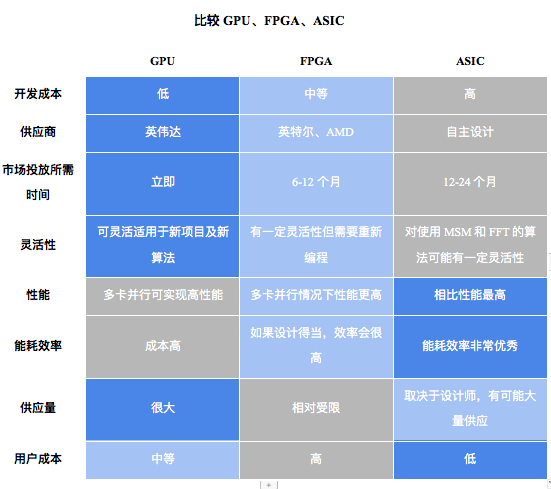
画像の説明
出典: アンバー
利用可能なビジネス モデルをより直観的に理解するために、潜在的な市場プレーヤーをすべて以下のグラフに示しました。アクター間には相互関係や複雑な関係がある可能性があるため、機能ごとにのみ分類します。
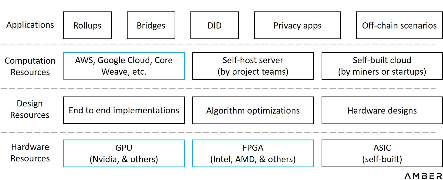
ハードウェアアクセラレーション機能層
ゼロ知識はまだ大規模に適用されておらず、迅速なソリューションを構築するには長いプロセスがかかるでしょう。次のターニングポイントは何になるのか、楽しみに待ちましょう。建設業者と投資家にとって重要な疑問は、この転換点がいつ来るかということだ。
ありがとう
技術的な詳細をすべて理解するのに協力してくれた Weikeng Chen (DZK)、Ye Zhang (Scroll)、Kelly (Supranational)、Omer (Ingonyama) に特別に感謝します。この研究に洞察を提供してくれた Kai (ZKMatrix)、Slobodan (Ponos)、Elias と Chris (Inaccel)、Heqing Hon (Accseal)、およびその他の多くの方々にも感謝します。
免責事項
ここに含まれる情報 (「情報」) は、概要形式で情報提供のみを目的として提供されており、網羅的なものではありません。これらの資料は、有価証券または製品の売買の提案または提案の勧誘ではなく、またそれらを意図したものでもありません。そのような情報は提供されるものではなく、投資アドバイスを提供するものとみなされるべきではありません。これらの資料は、潜在的な投資家の特定の投資目的、財務状況、または特定のニーズを考慮していません。明示的か黙示的かを問わず、マテリアルの公平性、正確性、正確性、合理性、完全性に関していかなる約束や保証も行われません。当社はこの資料を更新することを約束しません。潜在的な投資家は、これを自らの判断や調査の代替として考慮すべきではありません。潜在的な投資家は、必要と思われる範囲で、法務、規制、税務、ビジネス、投資、財務および会計のアドバイザーに相談し、ご自身の判断とアドバイザーのアドバイスに基づいて投資に関する意思決定を行う必要があります。


