
AI 正在製造新的「資訊窮人」?
- 核心觀點:AI 讓答案變得廉價且易於取得,但真正稀缺的已變為「判斷答案的能力」。新的資訊窮人並非被排斥在 AI 之外的人,而是擁有答案卻缺乏判斷力、無法將其轉化為機會的人,這導致了基於教育、經驗與權限的新一輪不平等。
- 關鍵要素:
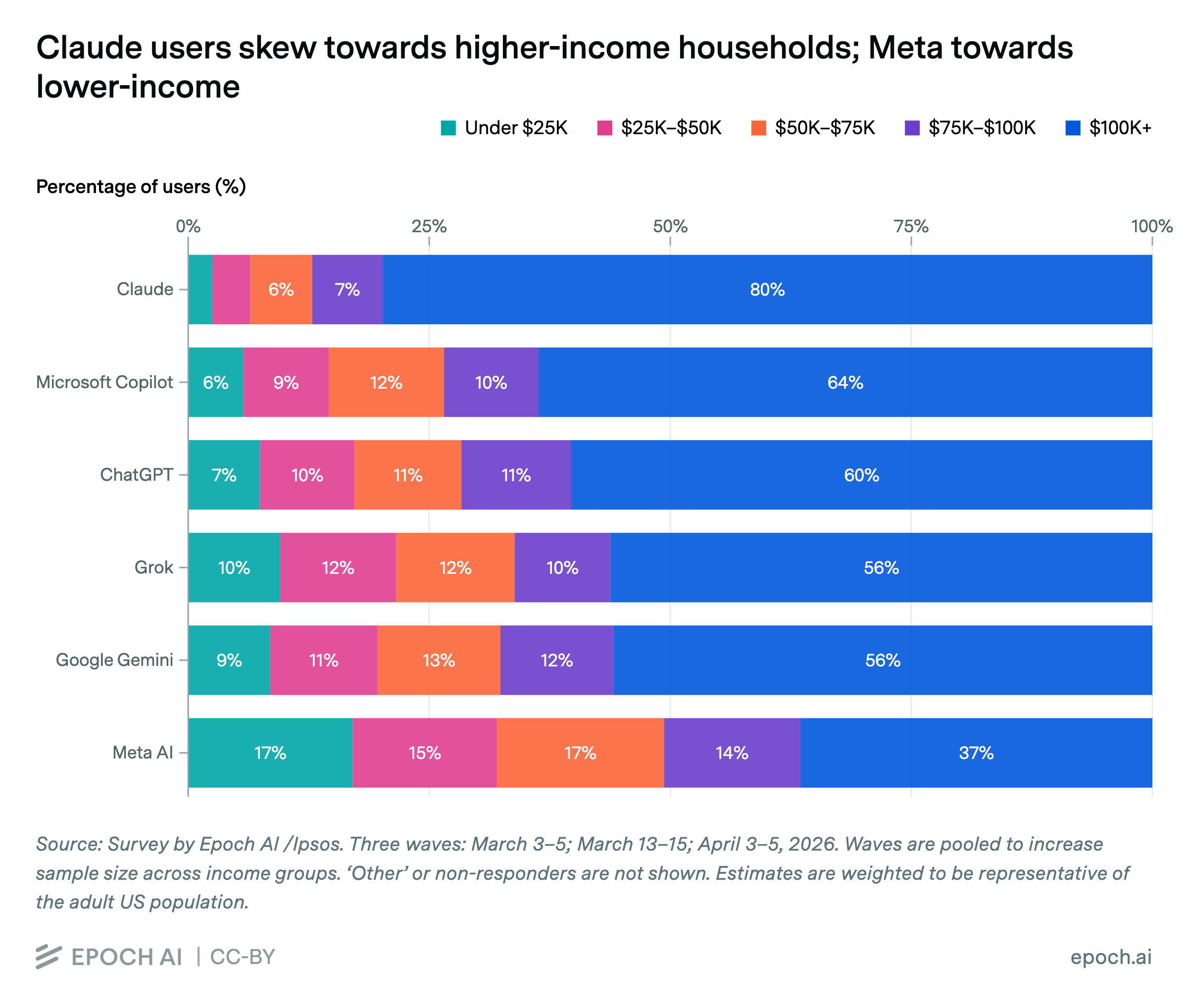
- 入口分流:Epoch AI 調查顯示,Claude 用戶中約 80% 來自年收入 10 萬美元以上家庭,而 Meta AI 用戶中 32% 來自年收入 5 萬美元以下家庭,折射出不同工具的入口與價格壁壘正在篩選用戶。
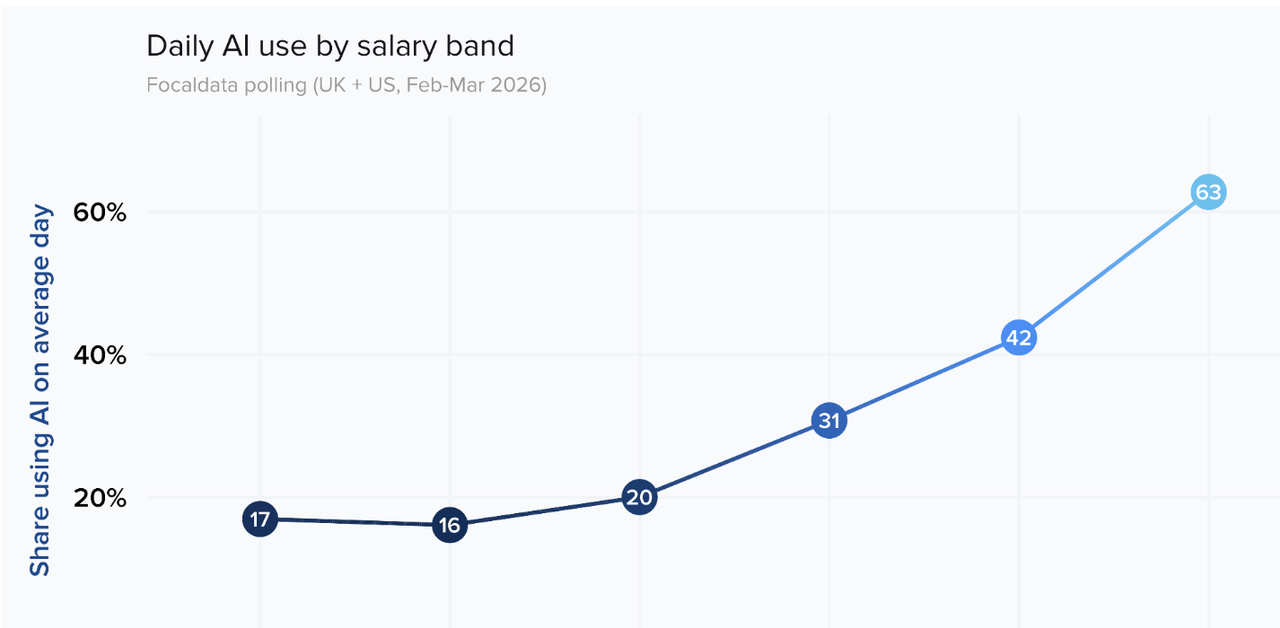
- 職場使用鴻溝:英美勞動力調查(2026年)指出,最高薪資檔勞動者中 63% 在日常使用 AI,而最低檔僅為 16%-17%。真正驅動使用的因素並非薪資,而是年齡、資歷與培訓。
- 培訓缺失:截至 2026 年初,僅 14% 的員工接受過正式 AI 培訓,三分之二從未受過任何培訓。AI 培訓本質是權限分配,決定誰能進入生產力增長軌道。
- 判斷力為王:AI 的最重度使用者是資歷 2-10 年的員工,而非最年輕者。AI 的價值高度依賴使用者已有的經驗與判斷力,缺乏判斷力者易對輸出照單全收,反而阻礙自身成長。
- 平權效應的局限:實驗顯示 AI 對低技能者提升幅度更大,但現實數據卻顯示採用、場景與判斷力本就不平等。技術可在實驗室縮小差距,卻可能在現實中擴大差距。
- 結構性不平等:AI 擁有平權的技術特性,卻運行在不平等的社會結構中。其影響覆蓋所有依賴判斷與語言的工作,分化速度可能更快、深度更深,紅利不會同時到來。
The cruelest thing about AI is not that it denies answers to the poor.
On the contrary, it gives answers to everyone.
It provides students with essay frameworks, employees with email templates, entrepreneurs with business plans, and ordinary people with legal explanations, investment advice, and career planning. Answers have never been so cheap, so abundant, and so convincing.
But therein lies the problem: when answers are available to all, what becomes truly scarce is not the answers themselves, but the ability to judge them.
The new information poor are not those locked out of AI, but those who already have answers yet lack the ability to judge them or the means to turn those answers into real opportunities.

I. The Information Gap in the AI Era
The information poor of the internet era were those excluded from the network. The solution seemed clear: connect cables,普及 devices, and improve literacy. The search engine era was slightly more complex, requiring skill in keyword refinement, source screening, credibility assessment, and preferably some English proficiency. But the barriers were visible and quantifiable.
The information gap in the AI era has a fundamentally different structure.
Large language models are not search engines; they directly generate conclusions for you. You no longer need to "find" answers—they are organized into fluent paragraphs, clear steps, and confident tones, delivered right to your screen. On the surface, the barrier has drastically lowered. But hidden within is a cold structure: as answers become cheap, errors become equally cheap; and the ability to discern "whether this answer is trustworthy" becomes rarer and more valuable than ever before.
Every previous wave of general-purpose technology followed the same logic: new technology first rewards those who already possess complementary capital. The printing press benefited the literate first. Computers benefited those who knew office software and programming. The internet benefited those with strong English skills and search proficiency. AI's complementary capital includes educational background, domain expertise, critical thinking, organizational authority, payment ability, and the most difficult to quantify—judgment.
New technology rarely rewards those who need it most first. It usually rewards those best positioned to leverage it.
II. The First Divide: The Path to AI
The first crack of inequality appears before you even open an application.
In April 2026, the AI research institute Epoch AI, in collaboration with polling firm Ipsos, released a survey of approximately 5,000 American adults. The three-round questionnaire asked a seemingly simple question: Which AI services have you used in the past week? But the answers didn't just show product preferences; they revealed a map woven from income, access points, and distribution.
Among Claude's weekly active users, about 80% came from households with annual incomes over $100,000. For Meta AI users, this proportion was only 37%. Conversely, about 32% of Meta AI users came from households earning under $50,000, compared to just 7% for Claude.
These numbers matter not because they prove "the rich use premium AI, the poor use free AI." That is the most superficial reading. More worth asking is: why do different people encounter different AIs in their daily lives?
One person asks AI to pair leftovers into a dinner, brighten a photo's background, or polish a text message. Another person asks AI to organize client interviews, compare supplier quotes, or identify weak assumptions in a report. Both invoke the same technology. But one invocation ends at convenience; the other enters a cycle of income, position, and bargaining power.
The difference isn't just in the users, but crucially in the access points. Using Claude requires actively searching, comparing products, understanding capability differences, choosing to pay, and then embedding the tool into workflows—each step filters users. Meta AI's path is almost the opposite: it's built into a social platform, free, low-friction, often encountered passively while browsing feeds, messaging, or viewing photos.
This is not a market of taste, but a market of distribution. Users seem to choose tools, but the tool's prices and access points also choose users.
Source: epoch.ai
III. The Second Divide: The Context of Use
Even if you find a good AI tool, the second分流 awaits you at the office.
In a typical workplace, AI's arrival rarely takes the form of "layoff notices." It first takes over meeting minutes, email drafts, spreadsheet organization, client classification, and report drafts. For managers, this automation frees up time for judgment. For newcomers and junior employees, however, this automation removes precisely the entry points where they prove themselves, practice judgment, and access higher-level work.
The data is colder than this scenario: A UK-US workforce AI tracking survey (Feb-Mar 2026, covering over 4,000 respondents) by the Financial Times and research bodies shows that 63% of workers in the highest salary bracket use AI on a typical workday, compared to only 17% and 16% for the two lowest brackets. This is not a gentle slope; it's a cliff.
The key finding lies in the drivers. A regression analysis of this workplace survey revealed that the influence of salary on AI usage almost disappears after controlling for other variables. The real drivers are four factors: age, seniority, industry, and training. Training has the largest effect: in companies offering formal AI training, daily AI usage is 37 percentage points higher than in comparable untrained companies. Even informal guidance provides a 24-point boost.
Yet the reality is: by early 2026, only 14% of employees reported receiving formal AI training from their employer, and two-thirds had received no training at all.
AI training is not a technology problem; it's an allocation problem. Who gets chosen for training is granted a ticket to the track of productivity growth. Those who don't are left with just an icon on a screen that hasn't been authorized to open.
On the consumer end, AI is an application. In the workplace, it's a permission. And permission is never evenly distributed.
Source: Focaldata
IV. The Final Divide: The Ability to Judge AI
This is the most insidious分流, and also the most fundamental.
Imagine a fresh graduate entering a consulting firm. Using AI, they produce a draft industry analysis report—complete structure, ample data, confident tone. Their boss, a ten-year industry veteran, glances at it and points out methodological flaws in the original sources for two pieces of data, and a problematic causal inference in the third conclusion. The boss isn't smarter because they worked harder; they possess that foundational layer—knowing where errors typically lurk, discerning when fluency is genuine versus when it's the machine just filling in blanks.
This is precisely the real meaning behind that counterintuitive finding in the workplace survey: the heaviest AI users at work are not the youngest employees, but those who have been in their current job for 2 to 10 years. The relationship between AI usage and seniority remains significant even after controlling for age. It's not that young people don't want to use it, but AI's value is highly dependent on the user's pre-existing judgment ability.
Experience is AI's most important complementary capital, and experience cannot be subscribed to.
AI lowers the cost of "sounding knowledgeable," without equally lowering the cost of "being knowledgeable." There's an even more dangerous consequence: the less foundational knowledge a user has, the more likely they are to accept AI's output uncritically. And the more uncritically they accept it, the harder it is for their judgment to grow. When an agent judges for you, you are consuming intelligence, not accumulating it.
Nobel Prize-winning economist and MIT professor Daron Acemoglu is blunt about this: using AI tools requires a certain level of education, abstract thinking, quantitative skills, and familiarity with technology. "It's almost certain that AI will increase inequality," he states.
This is where the new information poor take shape: they are not people without AI, but people who have AI, access, and answers, yet lack the training to judge those answers; they have tools and contexts, but lack the permission to turn tool outputs into opportunities; they consume intelligence daily, yet never accumulate it.
V. The Boundary of Equalizing Effects
But the relationship between AI and inequality is not one-sided widening.
Multiple experimental studies have found that, under controlled conditions, AI tends to benefit lower-skilled workers more—call center agents, junior writers, entry-level consultants. This isn't hard to understand: top experts get limited marginal gains from AI. For someone who could never afford professional services before, using AI to understand a contract for the first time is a qualitative leap.
However, a crucial distinction must be pointed out: experimental studies measure "improvement after use," while real-world data measures "who actually uses it," "who is allowed to use it," and "who can turn the results into opportunities after using it." Both sets of data are truthful; they measure entirely different things.
A technology can narrow gaps in the lab while widening them in the real world—if adoption itself is unequal, if contexts themselves are unequal, if judgment itself is unequal.
AI possesses the technical potential for equalization, yet operates within unequal social structures. Both facts are simultaneously true, and that is the real shape of the problem.
VI. Technology Spreads; Benefits Don't Arrive Simultaneously
Every generation tends to believe that its era's general-purpose technology will break the old order.
After the printing press, the literate benefited first, for centuries. When computers first spread, they amplified the capabilities of those who already knew office software and coding. The early benefits of the internet flowed to those proficient in English, skilled at searching, and with the time and motivation to arbitrage. In every technological wave, the cry "this time is different" is loud, yet structural divisions often take decades to become visible.
AI's dividing lines may form faster and cut deeper. Because it affects not just one type of task, but nearly all work reliant on judgment and language. And this is precisely the type of capability that is hardest to standardize and reallocate.
Some believe the gap will eventually narrow. Economic historian and Oxford Internet Institute professor Carl Benedikt Frey holds this view, based on historical precedent: the inequality from computer普及 dissipated over decades as usage barriers fell. This analogy has merit.
The problem is that even accepting this optimistic historical analogy, Frey himself acknowledges the key qualifier: "It depends on how long it takes for the gap to close. If it's ten or twenty years, that's more worrying."
Ten or twenty years is not a timeline to be taken lightly—especially for those who will need to find jobs, negotiate salaries, and accumulate experience during that period.
Conclusion
This is a peculiar historical moment: we have, for the first time, a technology that makes everyone feel like they are getting smarter.
Often, this feeling is the end point.
The problem is, in an era truly decided by judgment, mistaking a feeling for the end goal might be the most expensive mistake of all.


