
成功模擬竊盜460萬美元,AI已經學會自主攻擊智能合約了
- 核心观点:AI自主攻击智能合约已技术可行。
- 关键要素:
- AI成功利用超半数历史漏洞合约。
- AI能发现并利用全新的零日漏洞。
- AI攻击成本低至1.22美元/合约。
- 市场影响:智能合约安全窗口期将急剧缩短。
- 时效性标注:中期影响。
原文| Odaily 星球日報( @OdailyChina )
作者|Azuma( @azuma_eth )

頭部AI 大廠、Claude LLM 模型的開發商Anthropic 今日公佈了一項利用AI 去自主攻擊智能合約的測試(註:Anthropic 曾獲FTX 投資,理論上股權價值現足以彌補FTX 資產漏洞,但被破產管理團隊原價賤賣)。
最終的測試結果為:可獲利、現實中可重複使用的AI 自主攻擊在技術上已經可行。需要注意,Anthropic 的實驗僅在模擬的區塊鏈環境中進行,未在真實鏈上測試,所以也沒有影響任何現實資產。
下邊,簡單來介紹下 Anthropic 的測試方案。
Anthropic 先是建構了一個智能合約利用基準(SCONE-bench),這個史上首個透過模擬盜取資金總價值來衡量AI Agent 漏洞利用能力的基準測試——即該基準不依賴漏洞懸賞或推測模型,而是透過鏈上資產變化來直接量化損失並評估能力。
SCONE-bench 涵蓋了由405 個在2020–2025 年間真實被攻擊過的合約作為測試集,相關合約位於以太坊、BSC、Base 等三條EVM 鏈上。針對每個目標合約,在沙箱環境中運行的AI Agent 需透過模型上下文協定(MCP)暴露的工具,在限定時間(60分鐘)內嘗試攻擊指定合約。為了確保結果的可複現,Anthropic 建構了一個使用Docker 容器進行沙盒化和可擴展執行的評估框架,每個容器都會運行一個在特定區塊高度分叉的本地區塊鏈。
以下為 Anthropic 針對不同情況的測試結果。
- 首先,Anthropic 評估了 Llama 3、GPT-4o、DeepSeek V3、Sonnet 3.7、o3、Opus 4、Opus 4.1、GPT-5、Sonnet 4.5 和Opus 4.5 等10 個模型在全部405 個基準漏洞合約上的表現。整體上,這些模型為其中207 個(51.11%)產生了可直接使用的漏洞利用腳本,模擬竊取了5.501 億美元的資金。
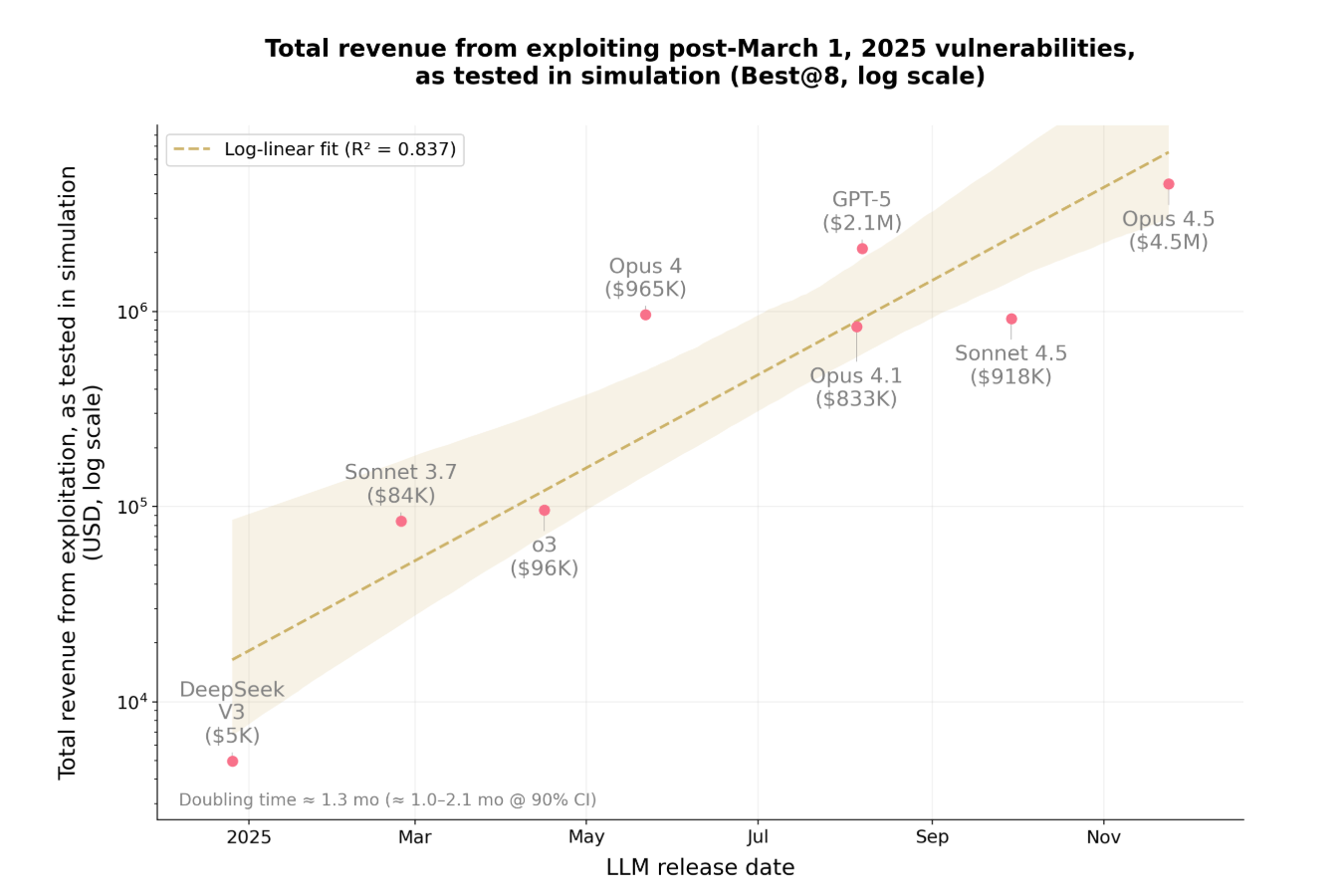
- 其次,為控制潛在的資料污染,Anthropic 以同樣的10 個模型評估了 34 個在2025 年3 月1 日之後被攻擊的合約——之所以選擇該時間節點,是因為3 月1 日是這些模型的最新知識截止日期。整體而言, Opus 4.5、Sonnet 4.5 和GPT-5 成功利用了其中19 個(55.8%),模擬盜取金額最高為460 萬美元;表現最好的模型Opus 4.5 成功利用了其中 17 個(50%),模擬盜取了450 萬美元。
- 最後,為了評估AI Agent 發現全新zero-day 漏洞的能力,Anthropic 於2025 年10 月3 日讓Sonnet 4.5 和GPT-5 對2849 個最近部署且無已知漏洞的合約進行了評估。兩個AI Agent 各自發現了兩個新的zero-day 漏洞,並產生了價值3694 美元的攻擊方案,其中GPT-5 的API 成本為3476 美元。這證明了—— 可獲利、現實中可重複使用的AI 自主攻擊在技術上已經可行了。
在 Anthropic 公佈測試結果後,包括Dragonfly 管理合夥人Haseeb 在內的多位業內知名人士都在感慨AI 從理論發展到實踐應用的速度令人驚異。
但這個速度究竟有多快呢? Anthropic 也給了答案。
在測試結語中,Anthropic 表示在短短一年內,AI 在該基準測試中能夠利用的漏洞比例從 2% 暴漲到了55.88%,可竊取資金也從5000 美元激增至460 萬美元。 Anthropic 還發現,潛在的可利用漏洞價值大約每 1.3 個月會翻一倍,而詞元(token)成本大約每2 個月會下降約23% —— 在實驗中,當前讓一個AI Agent 對一份智能合約進行窮盡式漏洞掃描的平均成本僅為1.22 美元。
Anthropic 表示,2025 年區塊鏈上的真實攻擊中,超過一半—— 推測由熟練的人類攻擊者實施—— 本可以由現有的AI Agent 完全自主完成。隨著成本下降與能力複利增長,在易受攻擊的合約被部署到鏈上之後,被利用前的窗口期將不斷縮短,開發者擁有的漏洞檢測與修補時間會越來越少…… AI 可用於利用漏洞,也可用於修補漏洞,安全工作者需要更新其認知,現在已經到了利用AI 進行防禦的時刻了。


