
IOSG Ventures: Khủng hoảng nguồn cung GPU, con đường để các công ty khởi nghiệp AI bứt phá
Tác giả gốc: Mohit Pandit, IOSG Ventures

Bản tóm tắt
Tình trạng thiếu GPU là thực tế, cung cầu eo hẹp nhưng số lượng GPU không được sử dụng đúng mức có thể đáp ứng nhu cầu nguồn cung eo hẹp hiện nay.
Cần có một lớp khuyến khích để tạo điều kiện thuận lợi cho việc tham gia điện toán đám mây và sau đó điều phối các nhiệm vụ điện toán để suy luận hoặc đào tạo. Mô hình DePIN hoàn hảo cho mục đích này.
Do có sự khuyến khích từ phía cung, do chi phí tính toán thấp hơn nên phía cầu thấy điều này hấp dẫn.
Không phải mọi thứ đều màu hồng, bạn phải đánh đổi một số điều nhất định khi chọn đám mây Web3: như độ trễ. So với đám mây GPU truyền thống, những sự đánh đổi phải đối mặt còn bao gồm bảo hiểm, thỏa thuận cấp độ dịch vụ (Thỏa thuận cấp độ dịch vụ), v.v.
Mô hình DePIN có khả năng giải quyết vấn đề về tính khả dụng của GPU, nhưng mô hình phân mảnh sẽ không làm tình hình tốt hơn. Đối với những tình huống mà nhu cầu đang tăng theo cấp số nhân, nguồn cung bị phân tán cũng giống như không có nguồn cung.
Sự hội tụ của thị trường là không thể tránh khỏi do số lượng người chơi mới trên thị trường.
giới thiệu
Chúng ta đang tiến tới một kỷ nguyên mới của học máy và trí tuệ nhân tạo. Mặc dù AI đã xuất hiện dưới nhiều hình thức khác nhau một thời gian (AI là thiết bị máy tính được yêu cầu thực hiện những việc mà con người có thể làm, chẳng hạn như máy giặt), nhưng chúng ta hiện đang chứng kiến sự xuất hiện của các mô hình nhận thức phức tạp có khả năng thực hiện các nhiệm vụ đòi hỏi trí thông minh. Nhiệm vụ hành vi con người Các ví dụ đáng chú ý bao gồm GPT-4 và DALL-E 2 của OpenAI và Gemini của Google.
Trong lĩnh vực trí tuệ nhân tạo (AI) đang phát triển nhanh chóng, chúng ta phải nhận ra hai khía cạnh của sự phát triển: đào tạo mô hình và suy luận. Suy luận bao gồm các khả năng và đầu ra của mô hình AI, trong khi đào tạo bao gồm quy trình phức tạp (bao gồm thuật toán học máy, bộ dữ liệu và sức mạnh tính toán) cần thiết để xây dựng các mô hình thông minh.
Trong trường hợp GPT-4, tất cả những gì người dùng cuối quan tâm là suy luận: nhận đầu ra từ một mô hình dựa trên văn bản đầu vào. Tuy nhiên, chất lượng của suy luận này phụ thuộc vào việc huấn luyện mô hình. Để đào tạo các mô hình AI hiệu quả, các nhà phát triển cần truy cập vào các tập dữ liệu cơ bản toàn diện và sức mạnh tính toán khổng lồ. Những tài nguyên này chủ yếu tập trung vào tay những gã khổng lồ trong ngành bao gồm OpenAI, Google, Microsoft và AWS.
Công thức rất đơn giản: đào tạo mô hình tốt hơn >> dẫn đến tăng khả năng suy luận của mô hình AI >> từ đó thu hút nhiều người dùng hơn >> dẫn đến nhiều doanh thu hơn và do đó tăng nguồn lực cho việc đào tạo thêm.
Những người chơi chính này có quyền truy cập vào các tập dữ liệu cơ bản lớn và quan trọng là kiểm soát lượng lớn sức mạnh tính toán, tạo ra rào cản gia nhập cho các nhà phát triển mới nổi. Kết quả là, những người mới tham gia thường gặp khó khăn để có được đủ dữ liệu hoặc tận dụng sức mạnh tính toán cần thiết ở quy mô và chi phí khả thi về mặt kinh tế. Với kịch bản này, chúng tôi thấy rằng mạng có giá trị lớn trong việc dân chủ hóa quyền truy cập vào tài nguyên, chủ yếu liên quan đến việc truy cập tài nguyên máy tính trên quy mô lớn và giảm chi phí.
vấn đề cung cấp GPU
Giám đốc điều hành NVIDIA Jensen Huang cho biết tại CES 2019 rằng “Định luật Moore đã kết thúc”. GPU ngày nay được sử dụng rất ít. Ngay cả trong chu kỳ đào tạo/học sâu, GPU vẫn không được sử dụng đúng mức.
Dưới đây là con số sử dụng GPU điển hình cho các khối lượng công việc khác nhau:
Không hoạt động (vừa khởi động vào hệ điều hành Windows): 0-2%
Các tác vụ năng suất chung (viết, duyệt nhẹ): 0-15%
Phát lại video: 15 - 35%
Game PC: 25 - 95%
Khối lượng công việc thiết kế đồ họa/chỉnh sửa ảnh (Photoshop, Illustrator): 15 - 55%
Chỉnh sửa video (Hoạt động): 15 - 55%
Chỉnh sửa video (Rendering): 33 - 100%
Kết xuất 3D (CUDA/OptiX): 33 - 100% (thường được Win Task Manager báo cáo không chính xác - sử dụng GPU-Z)
Hầu hết các thiết bị tiêu dùng có GPU đều thuộc ba loại đầu tiên.
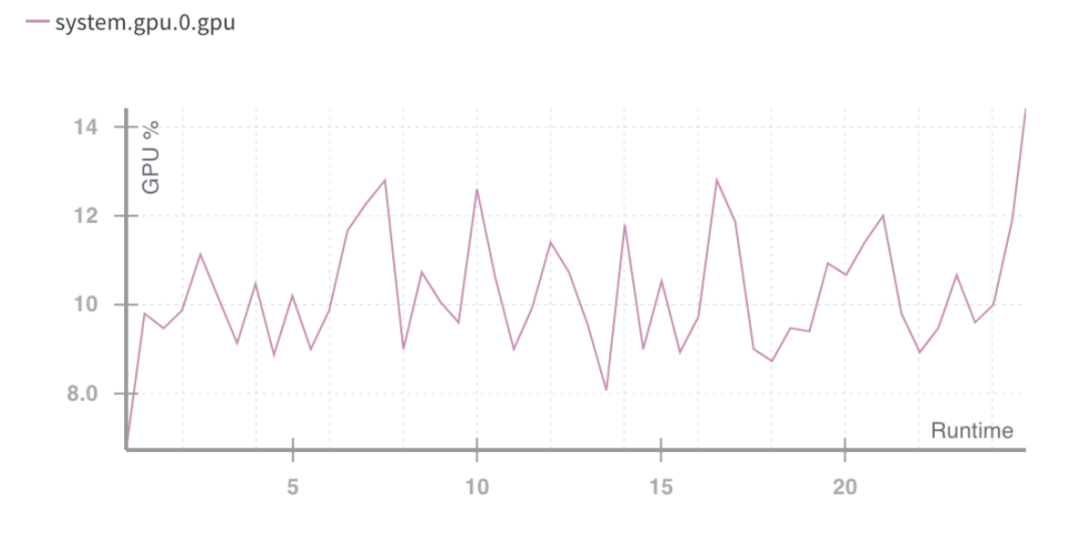
Tỷ lệ sử dụng thời gian chạy GPU %. Nguồn: Trọng lượng và thành kiến
Tình huống trên chỉ ra một vấn đề: việc sử dụng tài nguyên máy tính kém.
Cần phải tận dụng tốt hơn công suất của GPU tiêu dùng, vốn chưa tối ưu ngay cả khi mức sử dụng GPU tăng đột biến. Điều này làm rõ hai việc cần làm trong tương lai:
Tổng hợp tài nguyên (GPU)
Song song hóa nhiệm vụ đào tạo
Xét về loại phần cứng có thể sử dụng, hiện có 4 loại được cung cấp:
· GPU trung tâm dữ liệu (ví dụ: Nvidia A 100s)
· GPU tiêu dùng (ví dụ: Nvidia RTX 3060)
· ASIC tùy chỉnh (ví dụ: Coreweave IPU)
· SoC tiêu dùng (ví dụ: Apple M 2)
Ngoài ASIC (vì chúng được chế tạo cho một mục đích cụ thể), các phần cứng khác có thể được kết hợp với nhau để sử dụng hiệu quả nhất. Với nhiều con chip này trong tay người tiêu dùng và trung tâm dữ liệu, mô hình DePIN từ phía cung cấp hội tụ có thể là hướng đi phù hợp.
Việc sản xuất GPU là một kim tự tháp về số lượng; GPU tiêu dùng tạo ra nhiều nhất, trong khi các GPU cao cấp như NVIDIA A 100 và H 100 tạo ra ít nhất (nhưng có hiệu suất cao hơn). Những con chip tiên tiến này có chi phí sản xuất cao gấp 15 lần so với GPU thông thường nhưng đôi khi không mang lại hiệu suất gấp 15 lần.
Toàn bộ thị trường điện toán đám mây hiện nay trị giá khoảng 483 tỷ USD và dự kiến sẽ tăng trưởng với tốc độ tăng trưởng kép hàng năm khoảng 27% trong vài năm tới. Sẽ có khoảng 13 tỷ giờ nhu cầu điện toán ML vào năm 2023, tương đương với khoảng 56 tỷ USD chi tiêu cho điện toán ML vào năm 2023 theo mức tiêu chuẩn hiện tại. Toàn bộ thị trường này cũng đang phát triển nhanh chóng, tăng trưởng gấp 2 lần sau mỗi 3 tháng.
Yêu cầu về GPU
Nhu cầu điện toán chủ yếu đến từ các nhà phát triển AI (các nhà nghiên cứu và kỹ sư). Nhu cầu chính của họ là: giá cả (điện toán chi phí thấp), quy mô (số lượng lớn điện toán GPU) và trải nghiệm người dùng (dễ truy cập và sử dụng). Trong hai năm qua, GPU có nhu cầu rất lớn do nhu cầu về các ứng dụng dựa trên AI ngày càng tăng và sự phát triển của các mô hình ML. Việc phát triển và chạy các mô hình ML yêu cầu:
Tính toán nặng (từ quyền truy cập vào nhiều GPU hoặc trung tâm dữ liệu)
Khả năng thực hiện đào tạo mô hình, tinh chỉnh và suy luận, với mỗi tác vụ được triển khai trên một số lượng lớn GPU để thực thi song song
Chi tiêu cho phần cứng liên quan đến máy tính dự kiến sẽ tăng từ 17 tỷ USD vào năm 2021 lên 285 tỷ USD vào năm 2025 (tốc độ CAGR khoảng 102%) và ARK dự kiến chi tiêu cho phần cứng liên quan đến máy tính sẽ đạt 1,7 nghìn tỷ USD vào năm 2030 (tốc độ tăng trưởng kép hàng năm là 43%).
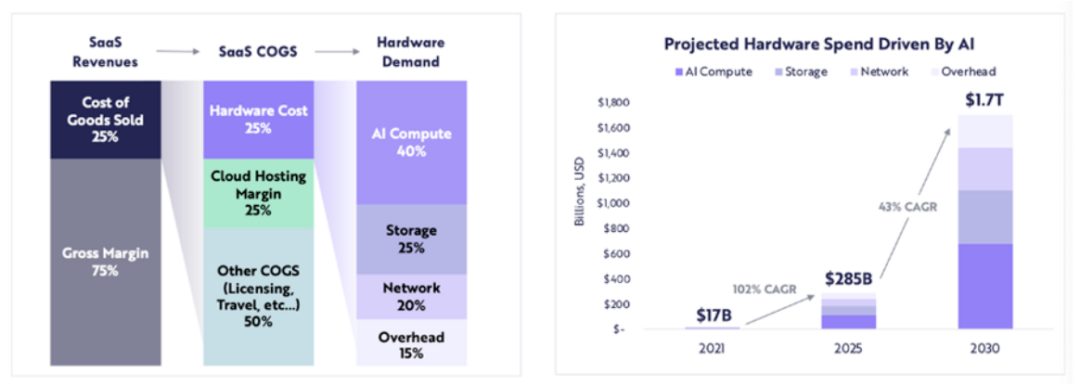
ARK Research
Với số lượng lớn LLM đang trong giai đoạn đổi mới và sự cạnh tranh thúc đẩy nhu cầu tính toán cho nhiều tham số hơn cũng như đào tạo lại, chúng ta có thể mong đợi nhu cầu tính toán chất lượng cao sẽ tiếp tục trong những năm tới.
Khi nguồn cung GPU mới thắt chặt, blockchain sẽ phát huy tác dụng ở đâu?
Khi tài nguyên không đủ, mô hình DePIN sẽ cung cấp trợ giúp:
Bắt đầu từ phía cung và tạo ra nguồn cung lớn
Điều phối và hoàn thành nhiệm vụ
Đảm bảo nhiệm vụ được hoàn thành chính xác
Khen thưởng xứng đáng cho những nhà cung cấp đã hoàn thành công việc
Việc tổng hợp bất kỳ loại GPU nào (người tiêu dùng, doanh nghiệp, hiệu suất cao, v.v.) đều có thể gây ra sự cố khi sử dụng. Khi các tác vụ điện toán được phân chia, chip A 100 không được phép thực hiện các phép tính đơn giản. Mạng GPU cần quyết định loại GPU nào họ nghĩ nên đưa vào mạng, dựa trên chiến lược tiếp cận thị trường của họ.
Khi bản thân các tài nguyên máy tính được phân phối (đôi khi trên toàn cầu), người dùng hoặc chính giao thức cần đưa ra lựa chọn về loại khung máy tính nào sẽ được sử dụng. Các nhà cung cấp như io.net cho phép người dùng chọn 3 framework tính toán: Ray, Mega-Ray hoặc triển khai cụm Kubernetes để thực hiện các tác vụ tính toán trong các container. Có nhiều khung tính toán phân tán hơn như Apache Spark, nhưng Ray được sử dụng phổ biến nhất. Sau khi GPU đã chọn hoàn thành nhiệm vụ tính toán, đầu ra sẽ được xây dựng lại để đưa ra mô hình được đào tạo.
Một mô hình mã thông báo được thiết kế tốt sẽ trợ cấp chi phí điện toán cho các nhà cung cấp GPU và nhiều nhà phát triển (phía cầu) sẽ thấy kế hoạch như vậy hấp dẫn hơn. Hệ thống máy tính phân tán vốn có độ trễ. Có sự phân rã tính toán và tái thiết đầu ra. Vì vậy, các nhà phát triển cần phải cân bằng giữa hiệu quả chi phí của việc đào tạo mô hình và thời gian cần thiết.
Một hệ thống máy tính phân tán có cần chuỗi riêng của nó không?
Mạng hoạt động theo hai cách:
Tính phí theo tác vụ (hoặc chu kỳ tính toán) hoặc theo thời gian
Tính theo đơn vị thời gian
Theo cách tiếp cận đầu tiên, người ta có thể xây dựng chuỗi bằng chứng công việc tương tự như những gì Gensyn đang cố gắng, trong đó các GPU khác nhau chia sẻ “công việc” và được thưởng cho nó. Đối với một mô hình không đáng tin cậy hơn, họ có khái niệm về người xác minh và người tố giác, những người được khen thưởng vì duy trì tính toàn vẹn của hệ thống, dựa trên bằng chứng do người giải quyết tạo ra.
Một hệ thống chứng minh công việc khác là Exabits, thay vì phân vùng tác vụ, hệ thống này sẽ xử lý toàn bộ mạng GPU của nó như một siêu máy tính duy nhất. Mô hình này có vẻ phù hợp hơn với các LLM lớn.
Akash Network đã thêm hỗ trợ GPU và bắt đầu tổng hợp GPU vào không gian này. Họ có L1 cơ bản để đạt được sự đồng thuận về trạng thái (hiển thị công việc được thực hiện bởi nhà cung cấp GPU), lớp thị trường và hệ thống điều phối vùng chứa như Kubernetes hoặc Docker Swarm để quản lý việc triển khai và mở rộng quy mô ứng dụng của người dùng.
Nếu một hệ thống không đáng tin cậy thì mô hình chuỗi bằng chứng công việc sẽ hiệu quả nhất. Điều này đảm bảo sự phối hợp và tính toàn vẹn của giao thức.
Mặt khác, các hệ thống như io.net không tự cấu trúc thành một chuỗi. Họ chọn giải quyết vấn đề cốt lõi về tính khả dụng của GPU và tính phí khách hàng theo đơn vị thời gian (mỗi giờ). Họ không cần lớp xác minh vì về cơ bản họ cho thuê GPU và sử dụng nó theo ý muốn trong một thời gian thuê cụ thể. Bản thân giao thức không có sự phân chia nhiệm vụ mà được thực hiện bởi các nhà phát triển bằng cách sử dụng các khung nguồn mở như Ray, Mega-Ray hoặc Kubernetes.
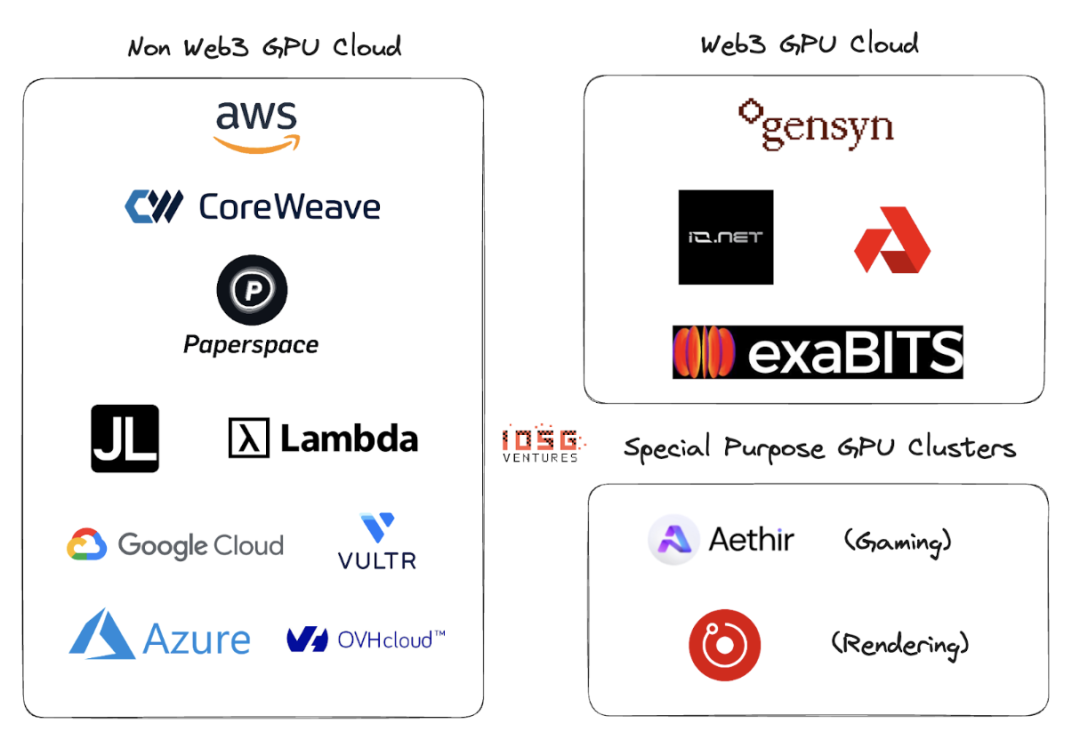
Đám mây GPU Web2 và Web3
Web2 có nhiều người chơi trong đám mây GPU hoặc GPU làm không gian dịch vụ. Những công ty lớn trong lĩnh vực này bao gồm AWS, CoreWeave, PaperSpace, Jarvis Labs, Lambda Labs, Google Cloud, Microsoft Azure và OVH Cloud.
Đây là mô hình kinh doanh đám mây truyền thống trong đó khách hàng thuê GPU (hoặc nhiều GPU) theo một đơn vị thời gian (thường là một giờ) khi họ cần tính toán. Có nhiều giải pháp khác nhau cho các trường hợp sử dụng khác nhau.
Sự khác biệt chính giữa đám mây GPU Web2 và Web3 là các thông số sau:
1. Chi phí thiết lập đám mây
Do ưu đãi mã thông báo, chi phí thiết lập đám mây GPU giảm đáng kể. OpenAI đang huy động 1 nghìn tỷ USD để tài trợ cho việc sản xuất chip điện toán. Có vẻ như nếu không có các ưu đãi về token, sẽ phải mất ít nhất 1 nghìn tỷ USD để đánh bại kẻ dẫn đầu thị trường.
2. Thời gian tính toán
Đám mây GPU không phải Web3 sẽ nhanh hơn vì các cụm GPU thuê nằm trong một khu vực địa lý, trong khi mô hình Web3 có thể có hệ thống phân tán rộng rãi hơn và độ trễ có thể đến từ việc phân vùng vấn đề, cân bằng tải không hiệu quả và quan trọng nhất là băng thông .
3. Tính toán chi phí
Do ưu đãi mã thông báo, chi phí tính toán Web3 sẽ thấp hơn đáng kể so với mô hình Web2 hiện tại.
So sánh chi phí tính toán:
Những con số này có thể thay đổi khi có nhiều cụm cung cấp và sử dụng hơn cho các GPU này. Gensyn tuyên bố cung cấp A 100 (và các sản phẩm tương đương của chúng) với giá chỉ 0,55 USD mỗi giờ và Exabits hứa hẹn một cơ cấu tiết kiệm chi phí tương tự.
4. Tuân thủ
Việc tuân thủ không hề dễ dàng trong một hệ thống không được phép. Tuy nhiên, các hệ thống Web3 như io.net, Gensyn, v.v. không tự coi mình là hệ thống không được phép. Xử lý các vấn đề tuân thủ như GDPR và HIPAA trong quá trình triển khai GPU, tải dữ liệu, chia sẻ dữ liệu và chia sẻ kết quả.
hệ sinh thái
Gensyn、io.net、Exabits、Akash
rủi ro
1. Rủi ro nhu cầu
Tôi nghĩ những người chơi LLM hàng đầu sẽ tiếp tục tích lũy GPU hoặc sử dụng cụm GPU như siêu máy tính Selene của NVIDIA, có hiệu suất cao nhất là 2,8 exaFLOP/s. Họ sẽ không dựa vào người tiêu dùng hoặc nhà cung cấp đám mây dài hạn để tập hợp GPU. Hiện tại, các tổ chức AI hàng đầu cạnh tranh về chất lượng hơn là chi phí.
Đối với các mô hình ML không nặng, họ sẽ tìm kiếm các tài nguyên điện toán rẻ hơn, như cụm GPU được khuyến khích bằng mã thông báo dựa trên blockchain có thể cung cấp dịch vụ trong khi tối ưu hóa GPU hiện có (ở trên là giả định: những tổ chức đó thích đào tạo mô hình của riêng họ thay vì sử dụng LLM)
2. Rủi ro nguồn cung
Với lượng vốn khổng lồ được đổ vào nghiên cứu ASIC và các phát minh như Bộ xử lý Tensor (TPU), vấn đề cung cấp GPU này có thể tự giải quyết. Nếu những ASIC này có thể mang lại hiệu suất tốt: đánh đổi chi phí, thì các GPU hiện có được các tổ chức AI lớn tích trữ có thể quay trở lại thị trường.
Các cụm GPU dựa trên blockchain có giải quyết được vấn đề lâu dài không? Mặc dù blockchain có thể hỗ trợ bất kỳ con chip nào ngoài GPU, nhưng những gì phía cầu làm sẽ hoàn toàn quyết định hướng đi của các dự án trong không gian này.
Tóm lại là
Một mạng bị phân mảnh với các cụm GPU nhỏ sẽ không giải quyết được vấn đề. Không có chỗ cho cụm GPU đuôi dài. Các nhà cung cấp GPU (nhà bán lẻ hoặc người chơi trên nền tảng đám mây nhỏ hơn) sẽ hướng tới các mạng lớn hơn vì các ưu đãi dành cho mạng tốt hơn. Sẽ là một chức năng của một mô hình mã thông báo tốt và khả năng của phía cung cấp để hỗ trợ nhiều loại máy tính.
Các cụm GPU có thể có số phận tổng hợp tương tự như CDN. Nếu những người chơi lớn cạnh tranh với những người dẫn đầu hiện có như AWS, họ có thể bắt đầu chia sẻ tài nguyên để giảm độ trễ mạng và khoảng cách địa lý của các nút.
Nếu phía cầu phát triển lớn hơn (cần đào tạo nhiều mô hình hơn và số lượng thông số cần đào tạo lớn hơn), người chơi Web3 phải rất tích cực trong việc phát triển kinh doanh phía cung. Nếu có quá nhiều cụm cạnh tranh từ cùng một cơ sở khách hàng, sẽ có nguồn cung bị phân mảnh (làm mất hiệu lực của toàn bộ khái niệm) trong khi nhu cầu (được đo bằng TFLOP) tăng theo cấp số nhân.
Io.net đã nổi bật so với nhiều đối thủ cạnh tranh, bắt đầu bằng mô hình tổng hợp. Họ đã tổng hợp GPU từ các công cụ khai thác Filecoin và Render Network để cung cấp công suất, đồng thời khởi động nguồn cung trên nền tảng của riêng họ. Đây có thể là hướng đi có lợi cho cụm GPU DePIN.


