
你的AI月费被谁分走了?一张图拆解20美元背后的算力供应链
- 核心观点:AI应用订阅费(如Claude Pro 20美元/月)与传统SaaS不同,其边际推理成本不为零。投资者需重新评估AI应用收入的价值,关注毛利率能否随使用量扩张而持续改善,而非简单套用高毛利SaaS估值逻辑。
- 关键要素:
- AI订阅的固定费用与可变推理成本存在结构性矛盾。用户每次提问、代码生成等操作均消耗GPU、电力等资源,使用量越大,成本链越重,直接挑战传统SaaS的高毛利假设。
- 市场流传的20美元成本拆分图显示,费用流向模型公司、云算力、GPU折旧、电力及供应链。核心价值在于揭示“使用量加权后的毛利率”才是AI公司估值的关键,而非单纯的用户付费意愿。
- 短期内,AI使用量增长更确定地流向了基础设施端(如英伟达、台积电、HBM厂商、电力公司),因其收入由刚性算力需求拉动,业绩验证更直接、更快速。
- 效率派观点认为,模型优化、小模型路由、缓存及自研芯片等技术进步将持续压低单位推理成本,为AI应用毛利率改善提供可能。
- 核心分歧在于:推理成本下降的速度能否超过用户平均使用量和任务复杂度的增长。若后者更快,AI应用公司的加权毛利率仍将承压。
- 对未上市模型公司(如OpenAI、Anthropic)的估值判断,需关注其用户构成(轻重度比例)、企业套餐定价、云成本结构及单位推理成本下降的实际传导效果,而非订阅用户总数。
TL;DR
- A breakdown chart of the $20 Claude subscription cost, splitting a monthly AI fee among the model company, cloud computing, GPUs, electricity, and supply chain.
- AI subscriptions have ongoing inference costs, so the high-margin assumptions of traditional SaaS cannot be directly applied.
- Related tickers: OpenAI, Anthropic, Microsoft, Amazon, Google, NVIDIA (NVDA), TSMC, SK Hynix, Samsung, Micron, data centers, and the power supply chain.
A chart estimating how the roughly $20 monthly US subscription fee for Claude Pro is distributed among the model company, cloud computing power, GPU depreciation, electricity, and supply chain is leading investors to rethink how to value AI application revenue.

This is not official revenue share data from Anthropic, AWS, or NVIDIA, nor should it be treated as any company's actual ledger. Its value lies in raising a more fundamental question: how much of the subscription fee paid by users to AI applications can be retained as software-like gross profit, similar to traditional SaaS?
The valuation logic for traditional SaaS is clear. Once software is written, the incremental cost of adding another account is typically low. Gross margins for mature pure-software companies are commonly 70% or even over 80%. Investors are willing to pay high multiples because profit margins tend to improve as revenue scales.
The trouble for AI applications is that every user query, code write, file analysis, or agent invocation consumes GPU time, electricity, memory bandwidth, and cloud resources. While the surface is a fixed monthly fee, the underlying reality is a cost chain that varies with usage. Light users might yield high margins, but heavy users running continuous tasks within quota limits or relevant tool packages can see costs rise rapidly.
Therefore, the challenge of the $20 breakdown chart isn't exactly how many dollars go to which company, but whether "AI application revenue is inherently equivalent to SaaS revenue." For an AI company to justify a high valuation multiple, it must not only prove users are willing to pay but also demonstrate that the usage-weighted gross margin can sustainably improve.
Behind the Subscription Fee Lies a Chain of Inference Costs
The biggest difference between AI subscriptions and standard software subscriptions is that the marginal cost of "one use" is no longer near zero.
In traditional SaaS, adding an account for a team incurs costs for servers, customer support, and bandwidth for the provider, but these costs typically don't rise linearly with every single click. The truly expensive parts are upfront R&D, sales, and customer acquisition. Once a product scales, a significant portion of new revenue can be retained.
Large language model products are different. A user inputs a question, and the model generates an answer. This process is called inference — the actual computation performed when the model is invoked by the user. Tokens are the basic unit of measurement for text read and written by the model. The more questions users ask, the longer the context, and the more complex the generated content, the more tokens and compute power are consumed.
This creates a contradiction between fixed subscriptions and variable costs. The US monthly price for Claude Pro is around $20, though this can vary by region, taxes, and Anthropic's adjustments. Users see a fixed price, but the model company faces vastly different usage behaviors. Some users only write emails and research information, while others process long documents, run code tasks, or invoke more complex automation workflows.
The breakdown chart circulating in the market attempts to visualize this: out of the $20, a portion goes to the model company, and another portion pays for cloud and compute providers. The computing cost includes electricity, operations, and GPU depreciation. GPU procurement then flows upwards to NVIDIA, TSMC, HBM suppliers, optical modules, ODMs, and power-related companies.
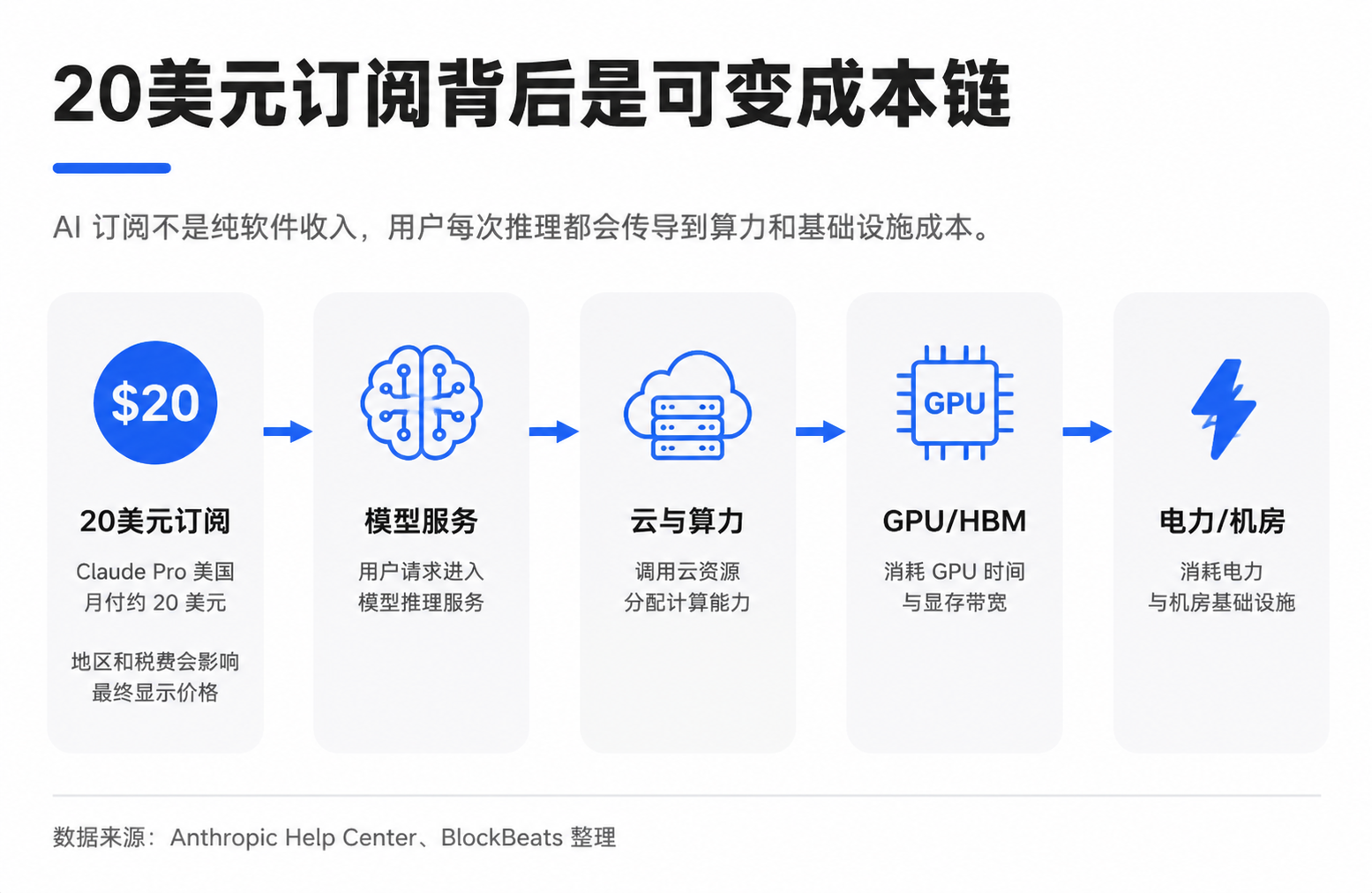
"GPU Depreciation" here can be understood as the expensive GPU cost not being expensed all at once but gradually allocated to AI services over its useful life, usage intensity, or accounting method. The actual allocation is affected by package limits, the ratio of light vs. heavy users, internal cloud provider settlement prices, reserved instance discounts, GPU utilization rates, and depreciation schedules. Average cost is also not equal to marginal cost.
The key direction investors need to watch is this: AI application companies cannot just disclose revenue growth; they must also answer whether the computing costs behind that revenue grow in tandem. If usage volume expands faster than model efficiency improves, higher subscription revenue could mean more pronounced margin pressure. Only if efficiency improvements are fast enough can model companies hope to approach the profit structure of software companies.
Infrastructure Secures More Certain Revenue First
Currently, the growth in AI usage flows more directly to infrastructure rather than fully settling in the application layer.
Whether a user interacts with a model via Claude, ChatGPT, Gemini, or an internal enterprise agent, the inference ultimately lands on computing power, electricity, memory, and the network. The application layer may see product churn, but the underlying resource consumption is more rigid. As long as AI usage continues to rise, cloud CapEx, GPU procurement, HBM demand, and data center electricity consumption will be pulled along.
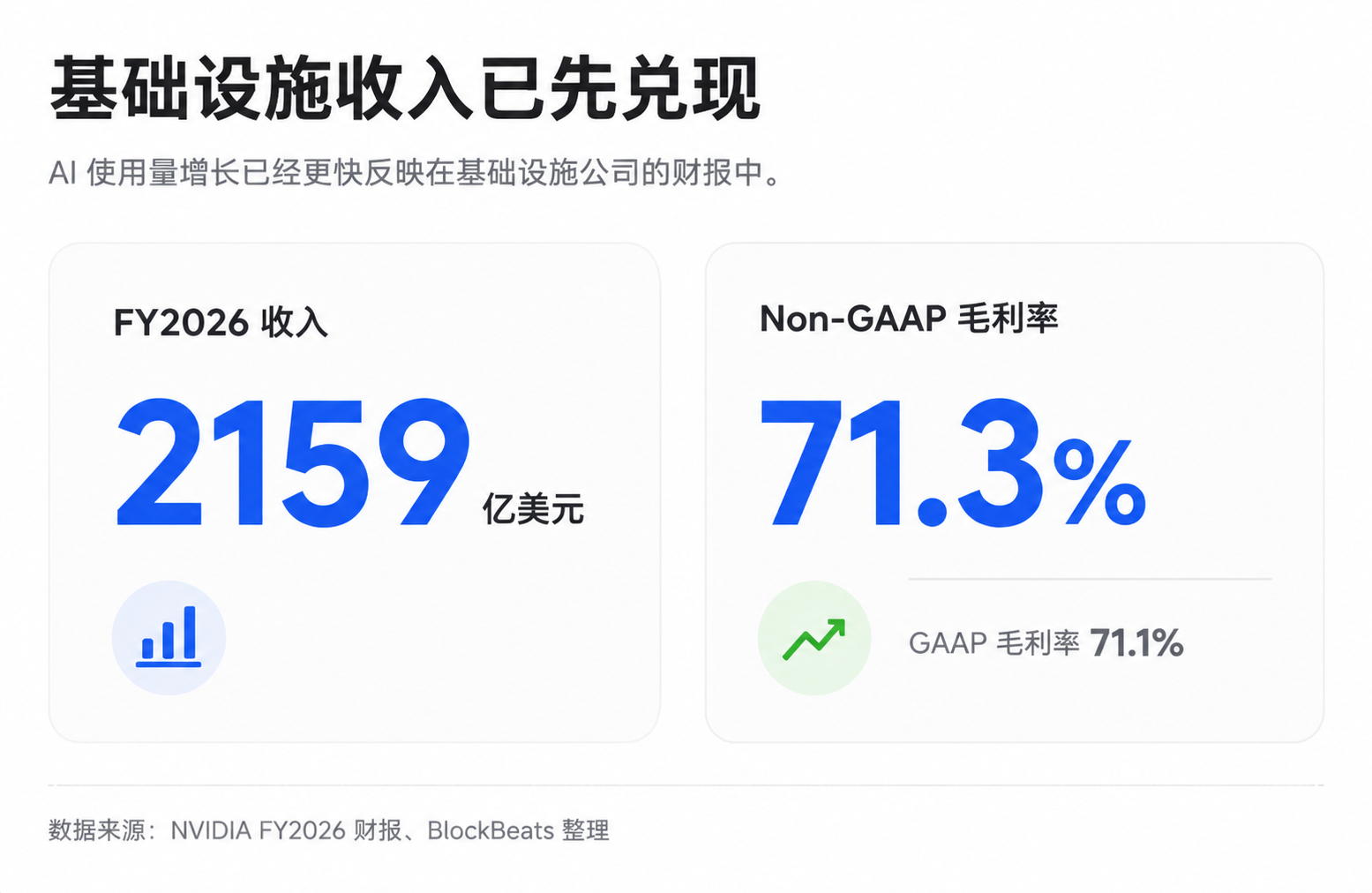
This is also why the infrastructure chain, including NVIDIA, TSMC, SK Hynix, etc., continues to be revalued by the market. NVIDIA's overall gross margin has been high recently. For FY2026, GAAP and non-GAAP gross margins are estimated around 71.1% and 71.3%, with subsequent quarterly guidance remaining high. It's important to note that specific quarters can be affected by certain expenses, and public financial reports don't always isolate the true gross margin structure of AI data centers, but the pricing power of scarce infrastructure is already reflected in the performance.
HBM is the most typical link in this chain. It's not ordinary memory but a critical component supporting high-throughput computation in AI accelerators. As model size, context length, and concurrent inference demands increase, AI chips rely more heavily on high-bandwidth memory. Supply chain estimates show HBM's share of the cost in next-gen AI chips is rising, a key reason why SK Hynix, Samsung, and Micron are being re-priced in this AI cycle.
Electricity and data centers have also shifted from background costs to investment themes. The energy consumption of a single text query might not be staggering, but complex agents, long contexts, code generation, and multi-turn tasks amplify the computation. For cloud providers and data center operators, the key isn't the power draw of one query, but that when massive volumes of inference requests occur continuously, cluster utilization, electricity prices, cooling, server room capacity, and grid connectivity all become costs and bottlenecks.
The advantage of the infrastructure side is that performance verification happens faster. Cloud providers' AI CapEx has already been spent; NVIDIA's revenue and profit are visible in its financial results; HBM manufacturers' orders and prices flow into their income statements relatively quickly. The model application layer trades more on future expectations: subscription conversion, enterprise penetration, API revenue, and profit release after future cost curves decline.
Efficiency Improvement Remains the Core Bull Case
Software investors and AI bulls have counterarguments. The core view of the efficiency camp is that today's high inference costs are just an early-stage phenomenon. Model optimization, caching, smaller models, custom chips, and higher cluster utilization will continuously drive down unit costs. If costs fall fast enough, AI applications can still return to a high-margin software logic.
This counterargument has a factual basis. Unit prices for some mainstream models with equivalent or better capabilities have dropped significantly. OpenAI disclosed that GPT-4o mini costs 99% less per token compared to the earlier text-davinci-003. The pace differs across companies; Anthropic has recently focused more on upgrading performance at the same price and model tiering. However, the industry direction remains providing stronger capabilities at lower costs.

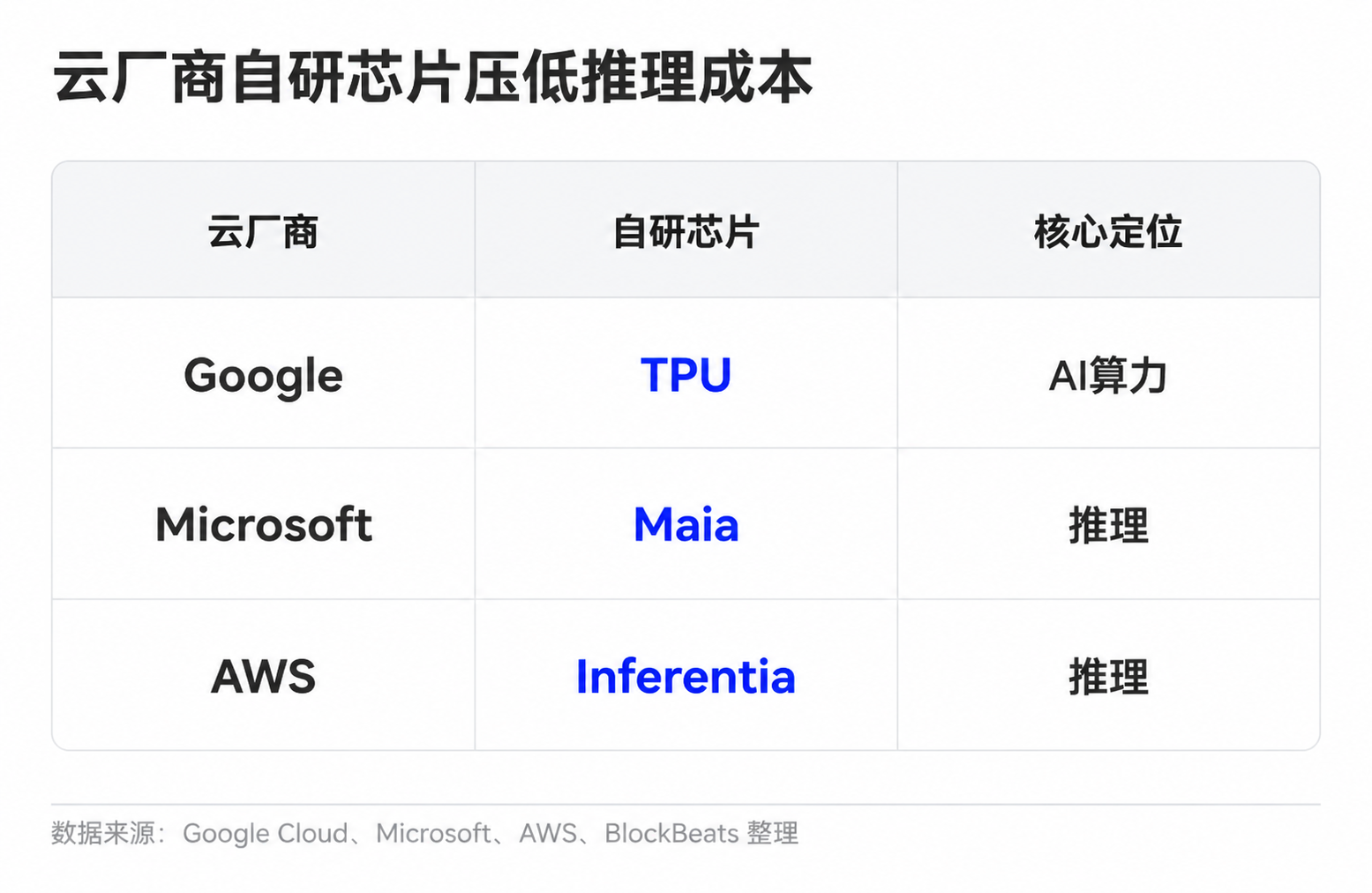
Model companies also have various ways to improve unit economics. Simple tasks can be routed to smaller models; common requests can be served from cache; long contexts and complex tasks go to more powerful models. Cloud providers reduce unit computing costs through custom chips and cluster scheduling. Google has TPUs, Microsoft has its Maia inference chip, and Amazon is advancing Trainium and Inferentia.
Looking purely at technological progress, there is room for improvement in AI application margins. Cheaper inference, better model routing, and stronger compression allow the same $20 subscription to support more usage. Light users, higher-priced enterprise plans, tiered API pricing, and stricter usage limits can also improve overall unit economics.
The difficulty is that cost reduction is not the only variable. AI applications are moving from simple chat to heavier workloads. In the past, users might just ask questions and rewrite text. Now, increasing demand comes from code agents, long document processing, video and multimodal generation, and enterprise automation workflows. These scenarios carry higher value but also come with higher consumption. The more useful the model, the more likely users are to entrust it with more complex and time-consuming tasks.
The divergence becomes more specific: Can the rate of inference cost decline outpace the growth in usage volume and task complexity? If unit costs fall quickly, but average user consumption grows faster, the model company's weighted gross margin may still be under pressure. Conversely, if model routing, caching, custom chips, and price tiering are effective enough, AI subscriptions may gradually shed today's cost-heavy characteristics.
Number of Subscribers is Not Gross Margin
The $20 breakdown chart should not be interpreted as the final outcome. It is more of a valuation reminder for the current phase: until the market sees sufficiently transparent gross margin data from model companies, investors need to discount the assumption that "AI applications are naturally equivalent to SaaS."
For unlisted model companies like OpenAI and Anthropic, external investors have difficulty seeing the complete ledger. Fundraising materials, partner disclosures, cloud cost structures, enterprise plan pricing, API revenue share, and usage limits all become clues for judgment. The truly valuable data isn't just the number of paying users, but the ratio of light to heavy users, whether enterprise customers are willing to pay more for high-intensity use, whether cloud settlement costs are declining, and whether falling unit inference costs trickle down to the company's gross margin.
Verification for the public company chain will appear faster in financial reports. NVIDIA's overall gross margin and data center revenue growth, TSMC's advanced process and packaging demand, HBM manufacturers' prices and margins, and cloud providers' CapEx intensity will continue to reflect whether AI usage is still transmitting to the infrastructure side. If these indicators remain strong, while the application layer shows a lack of margin improvement evidence, the market will continue to grant infrastructure a more certain valuation premium.
Ultimately, for model companies to reclaim a higher valuation anchor, they need to prove not just that users are willing to pay $20, but that these subscription fees can retain sufficient gross profit even after heavy usage. The next pricing divergence will likely be not in the headline ARR number, but in whether inference costs, package limits, and enterprise pricing can all work out simultaneously.


