
นี่คือผลลัพธ์การแปลตามที่คุณต้องการ: วิธีการใช้ Dynamic Workflows ของ Claude เพื่อการวิจัยเชิงลึก
- ประเด็นหลัก: Dynamic Workflows ของ Claude Code ซึ่งผสานรูปแบบการจัดตารางงานที่มีโครงสร้าง 6 รูปแบบ (เช่น การกำหนดเส้นทาง การทำงานแบบขนาน การตรวจสอบแบบโต้แย้ง ฯลฯ) ได้ยกระดับกระบวนการวิจัยของ AI จาก "การสนทนาอัจฉริยะ" เป็น "กรอบงานวิจัยอัตโนมัติ" ช่วยแก้ปัญหาข้อบกพร่องหลักในการวิจัยแบบ AI ดั้งเดิม เช่น การเลื่อนเป้าหมาย การหยุดก่อนเวลาอันควร และการปนเปื้อนของบริบท แต่การทดแทนการวิจัยเชิงลึกของมนุษย์อย่างสมบูรณ์ยังคงต้องปรับปรุงอย่างต่อเนื่องในด้านกลไกการตรวจสอบ การคิดข้ามสาขา และการ浓缩ข้อมูลอย่างสุดขั้ว
- องค์ประกอบสำคัญ:
- หัวใจของ Dynamic Workflow คือการที่ AI ออกแบบเวิร์กโฟลว์โดยอัตโนมัติก่อนดำเนินงาน ซึ่งรวมถึงขั้นตอนต่างๆ เช่น การแยกย่อยปัญหา การประเมินความน่าเชื่อถือ การคัดกรองข้าม และผลลัพธ์ที่มุ่งเป้า ช่วยชดเชยข้อบกพร่องของทักษะดั้งเดิมที่ขาดการลู่เข้าและการตัดสินใจเชิงเป้าหมาย
- 6 รูปแบบครอบคลุม การกำหนดเส้นทาง (การมอบหมายที่แม่นยำ) การแยกและรวม (การเร่งความเร็วแบบขนาน) การตรวจสอบแบบโต้แย้ง (การขจัดอคติในการประเมินตนเอง) การสร้างและการคัดกรอง (การเลือกความหลากหลาย) การแข่งขัน (การจัดอันดับเชิงแข่งขัน) และการวนซ้ำ (การปรับตัวซ้ำ) ครอบคลุมการจัดตารางการวิจัยที่ซับซ้อน
- รูปแบบการตรวจสอบแบบโต้แย้งขจัด "การยืนยันอคติ" ของ AI ที่ประจบผู้ใช้โดยธรรมชาติ ผ่านการสรุปข้อสรุปโดยตัวแทนอิสระแบบโต้แย้ง แต่ต้องอิงตามข้อเท็จจริงที่สามารถจำลองซ้ำได้ ไม่ใช่ความคิดเห็น เพื่อหลีกเลี่ยงผู้ตรวจสอบที่นำเวิร์กโฟลว์ออกนอกเส้นทาง
- เมื่อเปรียบเทียบกับระบบ deep-research ที่ผู้เขียนพัฒนาขึ้นเอง เวิร์กโฟลว์อย่างเป็นทางการมีขั้นตอนเพิ่มเติม เช่น การแยกย่อยปัญหา การประเมินความน่าเชื่อถือของข้อมูล การคัดกรองข้ามตามการลงคะแนน และผลลัพธ์ที่มุ่งเน้นเป้าหมายดั้งเดิมเสมอ ซึ่งช่วยลดจำนวนการสนทนาซ้ำซ้อนลงอย่างมาก (จากสิบกว่าครั้งเหลือ 3-4 ครั้ง)
- AI ยังมีข้อจำกัดสามประการ: ในสาขาที่ล้ำสมัย เช่น เทคโนโลยีบล็อกเชน มักพึ่งพาเอกสารทางการที่ล้าหลังแทนข้อมูลข้อเท็จจริงบนเชน ขาดความสามารถในการคิดเชิงลึกข้ามสาขา โมเดลการคิดกระแสหลักยากที่จะรับมือกับประเด็นใหม่ทั้งหมด การตรวจสอบโซลูชันต้องผสานการ权衡ต้นทุนและกลไก ซึ่งขัดแย้งกับความทั่วไป
- การ浓缩ข้อมูลอย่างสุดขั้วขึ้นอยู่กับความเข้าใจที่แม่นยำเกี่ยวกับพื้นฐานของผู้ฟัง AI ยากที่จะสลับระหว่าง "การแสดงออก通俗เสมือนมนุษย์" กับ "การสรุปอย่างมืออาชีพที่กระชับ" โดยอัตโนมัติ ซึ่งเป็นพื้นที่ที่นักวิจัยมนุษย์ไม่สามารถถูกแทนที่ได้
After three years, I've become completely reliant on using AI for industry research, even building a series of skills and support systems to handle information filtering, summarization, connection, verification, and synthesis.
It wasn't until this week, after a deep experience with Claude Code's dynamic workflow, that I truly understood the meaning of "don't fight against the tide of the era."
Let me reconsider: what constitutes in-depth research for humans in the age of AI, and how to build a collaborative and complementary relationship between myself and AI.
1. Starting with the Pitfalls of Research
Conducting technical research is actually fraught with pitfalls (for both humans and AI). After all, from the very beginning, you receive a massive amount of information. As the volume of information and viewpoints grows, the conclusions become increasingly ambiguous. So, it's crucial to constantly return to the original goal.
This has always been an area where AI falls short. From the perspective of attention and association, it gets more bogged down by the current volume of information than a human would, and its ability for truly valuable cross-domain associations is weak.
Of course, where AI excels is in execution. It can act as an agent, layer by layer, searching, summarizing, and concluding, completely avoiding the loss of detail.
Although I haven't posted much on my public account in the last six months, I've been comprehensively tracking and researching almost every major battleground in the industry. Supporting this input and output is my own deep-research system.
Facing the launch of Dynamic Workflows feature in Claude Code last week, I wanted to do a battle test to see if its default capabilities could completely surpass my own system.
2. What is Dynamic Workflows?
The core idea of Dynamic Workflows is: Before executing a task, have AI automatically design the workflow for that task, and then start the execution.
This is fundamentally different from the "plan mode" and "skill" we used before. Plan mode just breaks down the task into finer pieces, but it doesn't necessarily conform to a logical workflow. Acceptance criteria (crucial for research) are only likely to be added based on your prompt instructions. Similarly, only with prompts will it better preset some harness rules.
However, dynamic workflows automatically integrate acceptance logic, result convergence, and adversarial verification.
The trigger method is simple: use `/deep-research` directly in cc, then provide some research templates and starting materials. If you want to use just the dynamic workflow capability, use the prompt or simply say "ultracode." Be aware that token consumption is roughly ten times higher than usual.
3. Six Built-in Workflow Modes
Underlying the dynamic workflow are six core scheduling modes summarized by the official team. This is why it's more powerful than ordinary conversations, agents, or skills.
Actually, behind these six modes are just two core questions: How to decompose the task? How to combine the results? The six modes are essentially permutations and combinations of these two.
3.1 Routing Mode (Classify-And-Act)
First, one agent identifies the task type, then distributes the task to the most suitable specialized agent to handle it. The core logic is the routing selection logic, not parallel execution or iteration. A task follows only one path; other paths are not executed at all.
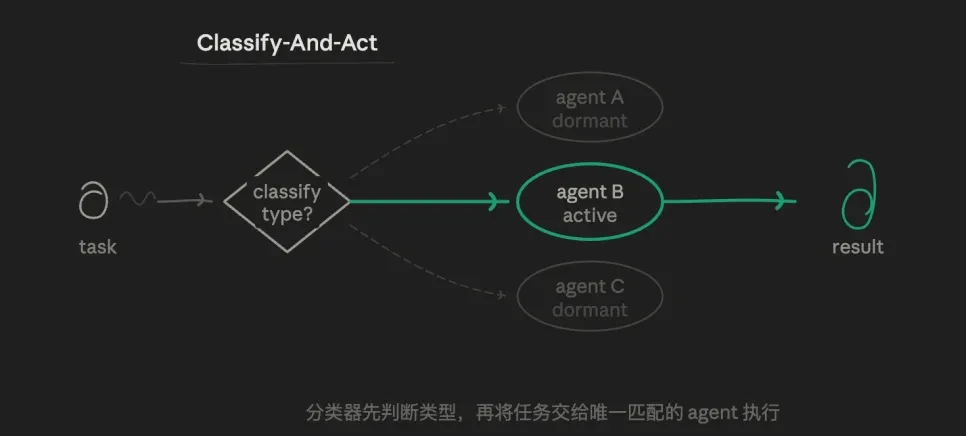
For example, I can preset three sub-agent roles: a strict data-verifying analysis agent, a skilled writing and output agent, and a challenge agent specializing in finding flaws. The routing layer then determines which agent a sub-task is best suited for, instead of having one agent do everything.
The value of this mode lies in precision and efficiency. Each agent's prompt can be highly independent, unaffected by other goals, allowing for deep, vertical exploration. Token consumption is lowest, response speed is fastest, and responsibility boundaries are very clear.
The obvious downside is its weak handling of tasks with ambiguous boundaries (e.g., "this is both a technical and an account issue").
3.2 Fan-out & Merge
This is also my most commonly used mode. The core logic is parallelism + merging. The task is broken down into N independent sub-tasks that run simultaneously, and only after all are completed are the results merged.

The advantage lies in speed and isolation. Total execution time is roughly equal to the longest sub-task, not the sum of all sub-tasks. Each sub-task has its own independent context, preventing interference or noise from one sub-task polluting others.
The weakness is that token cost is N times that of sequential processing. The merge layer (Synthesize) itself is challenging – fusing structurally inconsistent outputs from N paths is a design problem. Poor decomposition of sub-tasks can lead to omissions or overlapping coverage.
3.3 Adversarial Verification
The core logic is verification. For the same conclusion, multiple agents challenge it from a "rebuttal" perspective. The conclusion passes only if a majority votes in favor.
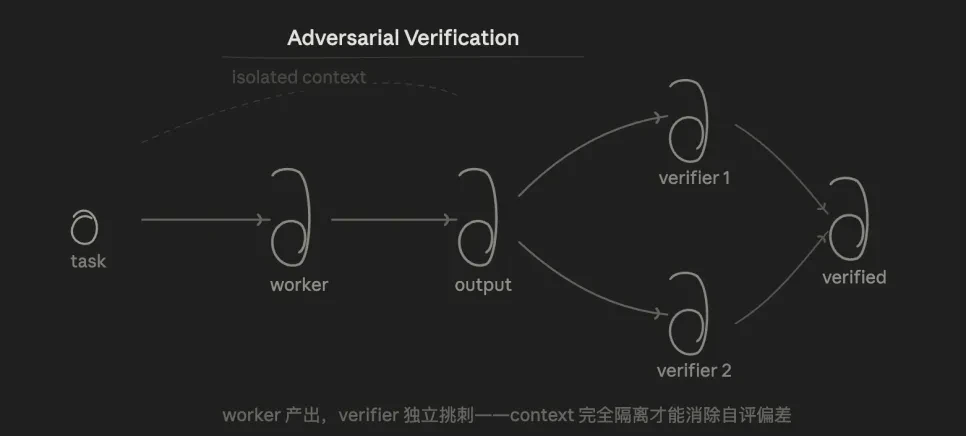
The advantage is that since the Verifier doesn't know the Worker's reasoning and only sees the result, it structurally eliminates the self-evaluation bias present when "asking a model to check its own code."
This mode solves a long-standing problem for me: we often chat with AI informally, and AI tends to answer in line with our expectations, easily creating "confirmation bias." Adversarial verification forces AI to actively seek counterexamples and validate based on data and experiments, rather than just pandering to your ideas.
However, if the Verifier makes an incorrect judgment, it can mislead the Worker into accommodating the Verifier. Therefore, it's best to base this on reproducible facts rather than opinions.
Jokingly speaking, if you ask AI to find problems, it can find an endless number of them, so you need to set boundaries on what it can look for.
3.4 Generate & Filter
The core logic is divergence then convergence. First, deliberately generate an excessive number of candidates, then use a rubric to eliminate down to the essence, outputting only high-confidence results.

Instead of having one agent output a single "okay" answer, it's better to have it generate ten and then use a verification layer to filter. Therefore, the advantage lies in diversity. Multiple Generators can use different strategies and prompts to produce solutions that humans might not anticipate. The filtering step ensures high concentration of quality in the final output.
The weakness is that the quality of the Filter's rubric directly determines the final outcome. A poorly designed rubric means the entire process is wasted.
Suitable scenarios include situations where the correct answer is unknown beforehand, where you need to select the best from multiple possibilities, or where diversity is explicitly required.
It only superficially resembles Fanout-And-Synthesize: Both involve "multi-path parallel → single output," which is the most common point of confusion.
The key difference is in intent: In Fanout, each path handles a different part of the task; results are complementary, and all paths contribute to the merge. In Generate-And-Filter, each path handles the same task; results are competitive, and most are discarded during merging. The former is a "jigsaw puzzle," the latter is a "beauty contest."
3.5 Tournament Mode
The core logic is competitive elimination. N agents independently work on the same task, undergo pairwise comparisons in successive rounds, and ultimately the best solution is selected.

I used to do this manually – run two or three versions of the same code change, then have AI compare which was better. Now it can be orchestrated directly into the workflow.
The advantage is evaluation stability. Pairwise comparison ("Is A or B better?") is much more stable than absolute scoring ("Score A /10") because it eliminates the problem of scoring criteria drift. After multiple rounds of competition, the credibility of the final winner is high.
It also only superficially resembles Generate-And-Filter: Both select the best from multiple candidates. The key difference is the selection mechanism: Tournament uses pairwise judges for comparison, letting "candidates compete against each other." This is more reliable when rubrics are difficult to quantify and judgment is inherently relative.
3.6 Loop Mode
The core logic is adaptive iteration. It keeps trying, collects error information when encountering obstacles, supplements context, and retries until the acceptance criteria are met.

Essentially, it's about countering AI's randomness: try more times, and you'll eventually stumble upon a better result. But a more mature approach is to combine it with adversarial verification, ensuring each loop executes with more information rather than relying purely on chance.
The advantage is its ability to handle tasks with unknown workloads. The other five modes assume the task boundary is fixed. Loop Until Done is the only mode that can handle "tasks where the number of required rounds is unknown."
The weakness is the potential risk of runaway behavior – a poorly designed stopping condition can lead to an infinite loop. Each round's agent operates in a completely new context and cannot accumulate state across rounds (unless explicitly written to a file).
4. Battle of My Skill vs. the Official Workflow
Before Dynamic Workflows came out, I had specifically designed my own deep-research system. The logic of my skill was roughly like this:
- Provide only simple information (e.g., a new feature launched by a project)
- Have AI search all related materials: official docs, source code, market sentiment
- Compress information into meaningful summaries
- Multiple agent roles perform adversarial analysis and generate a report
- Automatic deduplication, as content overlap between multiple agents is high
It worked well for a while. But it had a fundamental flaw: lack of goal-oriented convergence.
Moreover, even with the deduplication step, it would often delete valuable information. Without deduplication, the skill would easily produce a 10,000-word document – comprehensive in information, but failing to directly tell you "what does this mean for you, and what should you do about it?"
However, research serves "decision-making." This is why many skills stop at the research itself, reaching 80 points but missing the most critical 20 points.
This meant that even after AI completed the initial research, I still needed another ten rounds of thinking and dialogue to reach a satisfactory and thorough conclusion.
What More Did the Official Dynamic Workflow Do?
Through several complex research task experiments this week, I found that the deep research workflow built into Claude Code (note: not just a skill, but a module compiled and embedded into CC) adds several key steps compared to my own skill:
- Problem Decomposition Layer: It doesn't start searching directly. Instead, it first asks questions, breaking my problem into sub-questions: What exactly do you want to find out? How does this relate to you? Which dimensions are worth exploring? I used to skip this step.
- Credibility Assessment: It evaluates the falsifiability of each piece of information, similar to an authority score in traditional SEO – is the source trustworthy? How many citations does it have? This was a step I hadn't thought to add.
- Cross-Verification Deletion Rather Than Average Merging: My old approach was to average all conclusions, resulting in huge documents. Dynamic Workflows performs multi-agent voting on each conclusion, deleting those with insufficient votes instead of simply merging them.
- Goal-Oriented Output: The final report isn't an information pile-up. Instead, it provides judgment and suggestions around your original goal. The key to achieving this lies in its preset ability to schedule multiple sub-agents. The reason my skill lacked final goal orientation was due to instruction weight decay after processing massive amounts of information.
What Problems Do These Mechanisms Solve?
They target several typical issues of AI handling long tasks:
Goal Drift: AI does well at the start of a task, loses focus midway, and picks up the rhythm again at the end – similar to a human zoning out in class. The longer the task, the more prominent the issue.
Premature Stopping: When encountering difficulty during execution, AI might decide it has "finished" and stop, even though the acceptance criteria haven't been met.
Context Pollution: A single agent handling a complex task with a large amount of prior prompts compresses the execution space for subsequent steps. A better way is to keep prior prompts within a few k and use multiple agents to share the context load.
Output Bias: AI tends to answer in line with your expectations. Casual, conversational questions more easily trigger this problem.
Dynamic Workflows structurally solves these four problems: adding automatic acceptance metrics prevents premature stopping; parallel execution provides context isolation; adversarial verification counteracts output bias; problem decomposition constrains AI layer by layer to understand the goal before acting.
5. Summary
Finally, as a long-time research professional, I am amazed by this new mechanism in CC. Its six built-in modes – routing, fan-out & merge, adversarial verification, generate & filter, tournament, and loop – cover the scheduling needs of most complex research tasks.
I no longer need to manually design agent scheduling, nor do I need to handle deduplication and cross-verification myself. These are now integrated into the workflow itself.
Furthermore, it is particularly well-suited for thinking about open-ended problems with limited information. The natural multi-agent scheduling combined with task goal decomposition further enhances its generality. As early as three years ago, AI was already good at solving extremely clear, narrowly constrained problems. But the true qualitative leap for AI lies in its generality. This has changed its role from a simple tool for coding to a true Agent, from solving a single, fixed problem to adapting to any problem.
So, Dynamic Workflows isn't a "smarter single conversation." It structures the research process itself.
What previously required a dozen separate research conversations I can now compress into 3-4. Of course, the token consumption has increased tenfold.
So why do 3-4 conversations are still needed? I believe the root cause lies in the differences in these requirements.
First is the stringency of the verification mechanism. I primarily research new technologies on blockchain. For many things, official documentation lags behind, while source code, on-chain transactions, and other data are more valuable references. Currently, AI defaults to relying on official documentation rather than factual verification.
Second is truly deep, cross-domain thinking. While this can be somewhat addressed by pre-setting workflows (defining various dimensional sub-agents to think about the same problem), AI is still best at mainstream thinking models. It falls short for very novel, very profound topics that lack data to support them.
Third is solution design and verification. The value of a solution isn't just proposing it, but verifying and supporting it. It relies on assessing existing mechanisms, input costs, and trade-offs. With good fine-tuning, AI can certainly do this better, but this contradicts the principle of generality.
Finally, ultimate information concentration. This requires a deep understanding of the audience for the information. Some have no background and need anthropomorphic, vivid explanations, while others need a single sentence to convince them.


