
Jensen Huang ระบุชื่อ? SN3 ขึ้น 5 เท่าในหนึ่งเดือน จริงๆ แล้วทำอะไรไปบ้าง?
- มุมมองหลัก: Bittensor Subnet SN3 (Templar) ประสบความสำเร็จในการฝึกโมเดลขนาดใหญ่ Covenant-72B ที่มีพารามิเตอร์ 72 พันล้านตัวผ่านเครือข่ายพลังการประมวลผลแบบกระจายศูนย์ที่ไร้การอนุญาต โดยประสิทธิภาพของมันเทียบเท่ากับ LLaMA-2-70B ของ Meta ในปี 2023 ซึ่งถือเป็นความก้าวหน้าทางเทคโนโลยีที่สำคัญในสาขาการฝึกฝน AI แบบกระจายศูนย์ และได้กระตุ้นความสนใจของตลาดอย่างมากต่อโทเคนที่เกี่ยวข้อง
- องค์ประกอบสำคัญ:
- ความก้าวหน้าทางเทคโนโลยี: Covenant-72B ได้คะแนน 67.1 ในการทดสอบมาตรฐาน MMLU ซึ่งโดดเด่นในสนามการฝึกแบบกระจายศูนย์ และพิสูจน์ความเป็นไปได้ของการฝึกโมเดลขนาดใหญ่แบบกระจายศูนย์
- การเข้าร่วมแบบไร้การอนุญาต: โหนดอิสระกว่า 70 โหนดเข้าร่วมการฝึกโดยไม่ต้องผ่านการตรวจสอบรายชื่อขาว (whitelist) ทำให้เกิดการมีส่วนร่วมแบบกระจายศูนย์อย่างแท้จริง
- กลไกหลัก: การใช้เทคโนโลยี SparseLoCo เพื่อบีบอัดเกรเดียนต์อย่างมีประสิทธิภาพ (อัตราการบีบอัดมากกว่า 146 เท่า) และกลไก Gauntlet เพื่อตรวจสอบคุณภาพการมีส่วนร่วมของโหนด ซึ่งแก้ไขปัญหาประสิทธิภาพและแรงจูงใจในการฝึกแบบกระจายศูนย์
- ปฏิกิริยาของตลาด: โทเคน SN3 เพิ่มขึ้นมากกว่า 440% ในเดือนที่ผ่านมา มูลค่าการเล่าเรื่องได้ส่งผ่านไปยังโทเคนหลักของ Bittensor คือ TAO และผลักดันให้ราคาของมันเพิ่มขึ้นอย่างรวดเร็ว
- ความสำคัญของอุตสาหกรรม: ผลลัพธ์นี้ท้าทายโครงสร้างการผูกขาดทรัพยากรในการฝึก AI และแสดงให้เห็นถึงศักยภาพทางการเมืองและเศรษฐกิจของการพัฒนา AI แบบกระจายศูนย์ แต่ประสิทธิภาพของโมเดลยังคงห่างชั้นจากโมเดลแนวหน้าปัจจุบัน
- ปัญหาที่อาจเกิดขึ้น: รวมถึงความทันเวลาของการเปรียบเทียบมาตรฐานโมเดล, อุปสรรคในการเข้าถึงข้อมูลคุณภาพสูง, ความเสี่ยงด้านความปลอดภัยและการปฏิบัติตามกฎระเบียบที่เกิดจากการเข้าร่วมแบบไร้การอนุญาต, และความเสี่ยงที่เกี่ยวข้องอย่างมากระหว่างมูลค่าโทเคนกับความยั่งยืนของผลผลิตโมเดล
ผู้เขียนต้นฉบับ: KarenZ, Foresight News
วันที่ 20 มีนาคม 2026 ในพอดแคสต์ All-In Venture Capital มีบทสนทนาที่ไม่ธรรมดาอยู่ช่วงหนึ่ง
นักลงทุนวีซีชื่อดัง Chamath Palihapitiya หันไปหา Jensen Huang CEO ของ NVIDIA และบอกว่ามีโปรเจกต์หนึ่งบน Bittensor ที่ "ทำความสำเร็จทางเทคนิคที่ค่อนข้างบ้าบิ่น" โดยใช้พลังคอมพิวเตอร์แบบกระจายศูนย์ฝึกฝนโมเดลภาษาขนาดใหญ่บนอินเทอร์เน็ต กระบวนการทั้งหมดเป็นแบบกระจายศูนย์โดยไม่มีศูนย์ข้อมูลแบบรวมศูนย์ใดๆ เข้ามาเกี่ยวข้อง
Jensen Huang ไม่ได้หลบเลี่ยง เขาเปรียบเทียบเรื่องนี้กับ "Folding@home เวอร์ชันสมัยใหม่" โครงการกระจายศูนย์ในยุค 2000 ที่ให้ผู้ใช้ทั่วไปบริจาคพลังคอมพิวเตอร์ที่ไม่ได้ใช้เพื่อร่วมต่อสู้กับปัญหาการพับตัวของโปรตีน
ก่อนหน้านั้น 4 วัน ในวันที่ 16 มีนาคม Jack Clark ผู้ร่วมก่อตั้ง Anthropic ในการเผยแพร่รายงานความก้าวหน้าด้านการวิจัย AI ฉบับหนึ่ง ก็ได้ใช้พื้นที่จำนวนมากแนะนำและอ้างอิงถึงความก้าวหน้าครั้งนี้: Templar (SN3) ซับเน็ตในระบบนิเวศ Bittensor ได้ทำการฝึกฝนโมเดลขนาดใหญ่ 72 พันล้านพารามิเตอร์ (Covenant 72B) แบบกระจายศูนย์เสร็จสิ้น โดยประสิทธิภาพของโมเดลเทียบเท่ากับ LLaMA-2 ที่ Meta เปิดตัวในปี 2023
Jack Clark ตั้งชื่อบทนี้ว่า "ท้าทายเศรษฐศาสตร์การเมืองของ AI ผ่านการฝึกฝนแบบกระจายศูนย์" และเน้นย้ำในการวิเคราะห์ว่านี่เป็นเทคโนโลยีที่ควรติดตามอย่างต่อเนื่อง - เขาจินตนาการถึงอนาคตที่ AI บนอุปกรณ์ใช้โมเดลที่ผลิตจากการฝึกฝนแบบกระจายศูนย์อย่างแพร่หลาย ในขณะที่ AI บนคลาวด์ยังคงทำงานด้วยโมเดลที่เป็นกรรมสิทธิ์
ปฏิกิริยาของตลาดล่าช้าไปเล็กน้อยแต่รุนแรงมาก: SN3 เพิ่มขึ้นกว่า 440% ในช่วงเดือนที่ผ่านมา เพิ่มขึ้นกว่า 340% ในช่วงสองสัปดาห์ที่ผ่านมา มูลค่าตลาดสูงถึง 130 ล้านดอลลาร์ การปะทุของเรื่องเล่าเกี่ยวกับซับเน็ตจะส่งผลโดยตรงต่อแรงกดดันในการซื้อ TAO ดังนั้น TAO จึงพุ่งสูงขึ้นอย่างรวดเร็ว แตะที่ 377 ดอลลาร์ในบางช่วง เพิ่มขึ้นเป็นสองเท่าในเดือนที่ผ่านมา FDV อยู่ที่ประมาณ 7.5 พันล้านดอลลาร์
คำถามคือ: SN3 ทำอะไรไป? ทำไมจึงถูกผลักดันให้อยู่ใต้แสงสปอตไลต์? เรื่องเล่าคุณค่าของการฝึกฝนแบบกระจายศูนย์และ AI แบบกระจายศูนย์จะวิวัฒนาการไปอย่างไร?
โมเดล 72B นั้น
เพื่อตอบคำถามนี้ ต้องมองให้เห็นผลงานที่ SN3 นำเสนอให้ชัดเจนก่อน
วันที่ 10 มีนาคม 2026 ทีม Covenant AI เผยแพร่รายงานทางเทคนิคบน arXiv ประกาศอย่างเป็นทางการว่าการฝึกฝน Covenant-72B เสร็จสิ้นแล้ว นี่คือโมเดลภาษาขนาดใหญ่ 72 พันล้านพารามิเตอร์ โดยมีโหนด peers อิสระกว่า 70 โหนด (แต่ละรอบมีโหนดประมาณ 20 โหนดที่ซิงโครไนซ์กัน แต่ละโหนดมี B200 8 ตัว) ทำการฝึกฝนล่วงหน้าโมเดล 72 พันล้านพารามิเตอร์บนคอร์ปัสข้อความประมาณ 1.1 ล้านล้านโทเค็น
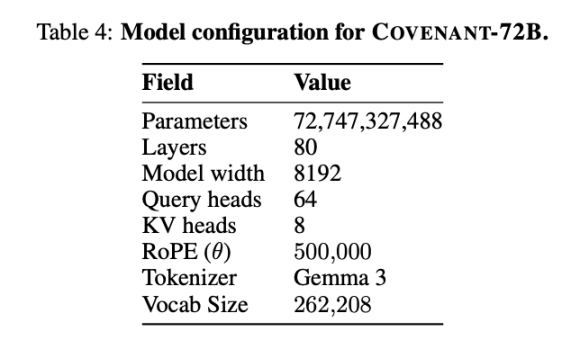
Templar นำเสนอข้อมูลบางส่วนเกี่ยวกับการทดสอบมาตรฐาน แน่นอนว่า LLaMA-2-70B ที่ใช้เปรียบเทียบคือโมเดลขนาดใหญ่ที่ Meta เปิดตัวในปี 2023 ดังที่ Jack Clark ผู้ร่วมก่อตั้ง Anthropic กล่าวว่า Covenant-72B อาจล้าสมัยไปบ้างในปี 2026 คะแนน 67.1 ของ Covenant-72B บน MMLU เทียบเคียงได้กับ LLaMA-2-70B (65.6 คะแนน) ที่ Meta เปิดตัวในปี 2023
ในขณะที่โมเดลล้ำสมัยของปี 2026 - ไม่ว่าจะเป็นซีรีส์ GPT, Claude หรือ Gemini - ได้ผ่านการฝึกฝนด้วยพารามิเตอร์ที่มากกว่าหนึ่งล้านล้านพารามิเตอร์บน GPU หลายแสนตัวแล้ว ความแตกต่างในด้านการให้เหตุผล โค้ด และความสามารถทางคณิตศาสตร์เป็นเรื่องของลำดับความมากน้อย ไม่ใช่เปอร์เซ็นต์ ความแตกต่างในความเป็นจริงนี้ไม่ควรถูกกลบด้วยอารมณ์ของตลาด
แต่เมื่อแปลงเป็นเงื่อนไข "ฝึกฝนด้วยพลังคอมพิวเตอร์แบบกระจายศูนย์บนอินเทอร์เน็ตแบบเปิด" ความหมายก็เปลี่ยนไปโดยสิ้นเชิง
ลองเปรียบเทียบดู: INTELLECT-1 (ผลงานของทีม Prime Intellect, 10 พันล้านพารามิเตอร์) ซึ่งเป็นการฝึกฝนแบบกระจายศูนย์เช่นกัน ได้คะแนน MMLU 32.7; โปรเจกต์การฝึกฝนแบบกระจายศูนย์อีกโครงการที่ดำเนินการในกลุ่มผู้เข้าร่วมที่ได้รับอนุญาตล่วงหน้า Psyche Consilience (40 พันล้านพารามิเตอร์) ได้คะแนน 24.2 Covenant-72B ด้วยขนาด 72B และคะแนน MMLU 67.1 เป็นตัวเลขที่โดดเด่นในสนามการฝึกฝนแบบกระจายศูนย์
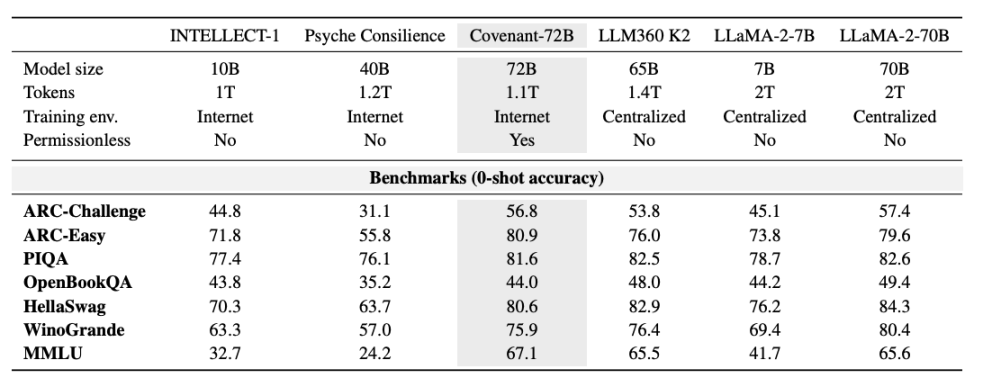
ที่สำคัญกว่านั้นคือ การฝึกฝนครั้งนี้เป็นแบบ "ไม่ต้องขออนุญาต" ใครก็ตามสามารถเชื่อมต่อเข้ามาเป็นโหนดผู้เข้าร่วมได้ ไม่จำเป็นต้องผ่านการตรวจสอบล่วงหน้า ไม่จำเป็นต้องอยู่ในรายชื่อที่ได้รับอนุญาต โหนดอิสระกว่า 70 โหนดมีส่วนร่วมในการอัปเดตโมเดล โดยเชื่อมต่อและบริจาคพลังคอมพิวเตอร์จากทั่วโลก
Jensen Huang กล่าวอะไร และไม่ได้กล่าวอะไร
การย้อนรอยรายละเอียดของการสนทนาในพอดแคสต์นั้น จะช่วยปรับการตีความของสาธารณชนต่อ "การรับรอง" ครั้งนี้ให้ถูกต้อง
Chamath Palihapitiya ในการสนทนาได้นำเสนอความสำเร็จทางเทคนิคของ Bittensor ให้ Jensen Huang ทราบ และอธิบายว่าฝึกฝนโมเดล Llama ด้วยพลังคอมพิวเตอร์แบบกระจายศูนย์ กระบวนการ "กระจายศูนย์อย่างสมบูรณ์ พร้อมทั้งรักษาสถานะไว้" การตอบสนองของ Jensen Huang คือการเปรียบเทียบสิ่งนี้กับ "Folding@home เวอร์ชันสมัยใหม่" และขยายความถึงความจำเป็นของการอยู่ร่วมกันแบบคู่ขนานของโมเดลโอเพ่นซอร์สและโมเดลที่เป็นกรรมสิทธิ์
สิ่งที่น่าสังเกตคือ Jensen Huang ไม่ได้กล่าวถึงโทเค็นของ Bittensor หรือความหมายด้านการลงทุนใดๆ โดยตรง และไม่ได้อภิปรายเพิ่มเติมเกี่ยวกับการฝึกฝน AI แบบกระจายศูนย์
ทำความเข้าใจซับเน็ต Bittensor และ SN3
เพื่อทำความเข้าใจความก้าวหน้าของ SN3 ก่อนอื่นต้องเข้าใจตรรกะการทำงานของ Bittensor และซับเน็ตของมัน กล่าวง่ายๆ Bittensor สามารถมองได้ว่าเป็นบล็อกเชนสาธารณะและแพลตฟอร์มสำหรับ AI และแต่ละซับเน็ตก็เปรียบเสมือน "สายการผลิต AI" อิสระ ที่กำหนดภารกิจหลักและออกแบบกลไกแรงจูงใจของตัวเอง ร่วมกันประกอบเป็นระบบนิเวศ AI แบบกระจายศูนย์
ขั้นตอนการทำงานมีความชัดเจนและเป็นแบบกระจายศูนย์: เจ้าของซับเน็ตกำหนดเป้าหมายซับเน็ตและเขียนโมเดลแรงจูงใจ; คนขุด (Miner) ในซับเน็ตจัดหาพลังคอมพิวเตอร์ ดำเนินงานที่เกี่ยวข้องกับ AI (เช่น การให้เหตุผล การฝึกฝน การจัดเก็บ ฯลฯ); ผู้ตรวจสอบ (Validator) ให้คะแนนผลงานของคนขุด และอัปโหลดคะแนนไปยังเลเยอร์ฉันทามติของ Bittensor; ในท้ายที่สุด อัลกอริธึมฉันทามติ Yuma ของ Bittensor จะจัดสรรผลตอบแทนที่สอดคล้องกันให้กับผู้เข้าร่วมซับเน็ตตามรางวัลสะสมของแต่ละซับเน็ต
ปัจจุบัน Bittensor มีซับเน็ต 128 ซับเน็ต ครอบคลุมงาน AI หลากหลายประเภท เช่น การให้เหตุผล บริการคลาวด์ AI แบบไม่มีเซิร์ฟเวอร์ ภาพ การติดป้ายกำกับข้อมูล การเรียนรู้แบบเสริมกำลัง การจัดเก็บ การคำนวณ
และ SN3 ก็คือหนึ่งในซับเน็ตเหล่านั้น มันไม่ได้ทำแค่เปลือกนอกในเลเยอร์แอปพลิเคชัน ไม่ได้เช่า API ของโมเดลขนาดใหญ่สำเร็จรูป แต่ตั้งเป้าไปที่หนึ่งในขั้นตอนหลักที่แพงที่สุดและปิดที่สุดของห่วงโซ่อุตสาหกรรม AI: การฝึกฝนล่วงหน้าของโมเดลขนาดใหญ่เอง
SN3 หวังที่จะใช้เครือข่าย Bittensor ในการประสานงานการฝึกฝนแบบกระจายศูนย์ของทรัพยากรการคำนวณที่ต่างกัน (heterogeneous) ผ่านการฝึกฝนโมเดลขนาดใหญ่แบบกระจายศูนย์ที่มีแรงจูงใจ เพื่อพิสูจน์ว่าสามารถฝึกฝนโมเดลพื้นฐานที่ทรงพลังได้โดยไม่จำเป็นต้องใช้คลัสเตอร์ซูเปอร์คอมพิวเตอร์แบบรวมศูนย์ที่มีราคาแพง แก่นของแรงดึงดูดอยู่ที่ "ความเท่าเทียม" - ทำลายการผูกขาดทรัพยากรของการฝึกฝนแบบรวมศูนย์ ทำให้บุคคลทั่วไปหรือองค์กรขนาดกลางและเล็กสามารถมีส่วนร่วมในการฝึกฝนโมเดลขนาดใหญ่ได้ พร้อมทั้งลดต้นทุนการฝึกฝนด้วยพลังคอมพิวเตอร์แบบกระจายศูนย์
พลังหลักที่ขับเคลื่อนการพัฒนาของ SN3 คือ Templar โดยทีมวิจัยเบื้องหลังคือ Covenant Labs ทีมนี้ยังดำเนินการซับเน็ตอีกสองแห่งพร้อมกัน: Basilica (SN39 มุ่งเน้นบริการการคำนวณ) และ Grail (SN81 มุ่งเน้นการฝึกฝนหลัง RL และการประเมินโมเดล) ซับเน็ตทั้งสามแห่งรวมตัวกันในแนวตั้ง ครอบคลุมกระบวนการทั้งหมดของโมเดลขนาดใหญ่ตั้งแต่การฝึกฝนล่วงหน้าจนถึงการปรับให้ตรงกัน (alignment) และการปรับให้เหมาะสม สร้างระบบนิเวศที่สมบูรณ์สำหรับการฝึกฝนโมเดลขนาดใหญ่แบบกระจายศูนย์
กล่าวโดยเฉพาะคือ คนขุดบริจาคทรัพยากรการคำนวณ อัปโหลดการอัปเดตเกรเดียนต์ (ทิศทางและความแรงของการปรับพารามิเตอร์โมเดล) ไปยังเครือข่าย; ผู้ตรวจสอบประเมินคุณภาพของผลงานของคนขุดแต่ละคน ให้คะแนนบนเชนตามระดับการปรับปรุงของข้อผิดพลาด ผลลัพธ์กำหนดน้ำหนักของรางวัล การจัดสรรเป็นไปโดยอัตโนมัติ โดยไม่ต้องไว้วางใจบุคคลที่สามใดๆ
ประเด็นสำคัญของการออกแบบกลไกแรงจูงใจคือ รางวัลเชื่อมโยงโดยตรงกับ "ผลงานของคุณทำให้โมเดลดีขึ้นแค่ไหน" ไม่ใช่แค่การเข้างานของพลังคอมพิวเตอร์เท่านั้น ซึ่งเป็นการแก้ปัญหาที่ยากที่สุดในสถานการณ์แบบกระจายศูนย์ตั้งแต่รากฐาน: จะป้องกันไม่ให้คนขุดทำงานลวกๆ ได้อย่างไร
แล้ว Covenant-72B แก้ไขปัญหาประสิทธิภาพการสื่อสารและความเข้ากันได้ของแรงจูงใจได้อย่างไร?
การให้โหนดหลายสิบโหนดที่ไม่ไว้วางใจกัน มีฮาร์ดแวร์ต่างกัน คุณภาพเครือข่ายไม่สม่ำเสมอ ร่วมฝึกฝนโมเดลเดียวกัน มีความท้าทายสองประการ: หนึ่งคือ ประสิทธิภาพการสื่อสาร โครงการฝึกฝนแบบกระจายศูนย์มาตรฐานต้องการการเชื่อมต่อระหว่างโหนดที่มีแบนด์วิธสูง ความหน่วงต่ำ; สองคือ ความเข้ากันได้ของแรงจูงใจ จะป้องกันไม่ให้โหนดที่เป็นอันตรายส่งเกรเดียนต์ที่ผิดพลาดได้อย่างไร? จะมั่นใจได้อย่างไรว่าผู้เข้าร่วมแต่ละคนกำลังฝึกฝนอย่างจริงจัง ไม่ใช่แค่คัดลอกผลงานของผู้อื่น?
SN3 ใช้สององค์ประกอบหลักแก้ไขปัญหาทั้งสองนี้: SparseLoCo และ Gauntlet
SparseLoCo แก้ไขปัญหาประสิทธิภาพการสื่อสาร การฝึกฝนแบบกระจายศูนย์แบบดั้งเดิมในแต่ละขั้นตอนต้องซิงโครไนซ์เกรเดียนต์ทั้งหมด ซึ่งมีปริมาณข้อมูลมหาศาล วิธีที่ SparseLoCo ใช้คือ: แต่ละโหนดรันการปรับให้เหมาะสมภายใน (AdamW) 30 ขั้นตอนในเครื่อง จากนั้นอัปโหลด "เกรเดียนต์เทียม" ที่เกิดขึ้น หลังจากบีบอัดแล้ว ให้โหนดอื่นๆ วิธีการบีบอัดรวมถึงการทำให้เบาบางแบบ Top-k (เก็บเฉพาะส่วนประกอบเกรเดียนต์ที่สำคัญที่สุด) การตอบสนองต่อข้อผิดพลาด (เก็บส่วนที่ถูกทิ้งไว้สะสมไปยังรอบถัดไป) และการควอนไทซ์ 2 บิต อัตราการบีบอัดสุดท้ายเกิน 146 เท่า
พูดอีกอย่างคือ สิ่งที่เดิมต้องส่ง 100MB ตอนนี้ใช้ไม่ถึง 1MB
สิ่งนี้ทำให้ระบบภายใต้ข้อจำกัดแบนด์วิธของอินเทอร์เน็ตทั่วไป (อัปโหลด 110Mbps, ดาวน์โหลด 500Mbps) รักษาอัตราการใช้การคำนวณไว้ที่ประมาณ 94.5% - 20 โหนด, แต่ละโหนดมี B200 8 ตัว, เวลาที่ใช้ในการสื่อสารแต่ละรอบเพียง 70 วินาที
Gauntlet แก้ไขปัญหาความเข้ากันได้ของแรงจูงใจ มันทำงานบนบล็อกเชน Bittensor (Subnet 3) รับผิดชอบในการตรวจสอบคุณภาพของเกรเดียนต์เทียมที่แต่ละโหนดส่งมา วิธีการเฉพาะคือ: ใช้ข้อมูลชุดเล็กๆ ทดสอบ "เมื่อใช้เกรเดียนต์ของโหนดนี้แล้ว ข้อผิดพลาดของโมเดลลดลงแค่ไหน" ผลลัพธ์เรียกว่า LossScore พร้อมกันนั้น ระบบยังตรวจสอบว่าโหนดกำลังฝึกฝนด้วยข้อมูลที่ตัวเองได้รับมอบหมายหรือไม่ - หากข้อผิดพลาดของโหนดบนข้อมูลสุ่มดีกว่าบนข้อมูลที่ตัวเองได้รับมอบหมาย จะได้รับคะแนนติดลบ
ในท้ายที่สุด แต่ละรอบการฝึกฝนจะเลือกเฉพาะเกรเดียนต์ของโหนดที่มีคะแนนสูงสุดมารวมกัน โหนดที่เหลือจะถูกคัดออกจากรอบนี้ ผู้เข้าร่วมที่เกินจะเข้ามาแทนที่ตลอดเวลา ทำให้ระบบมีความแข็งแกร่ง ในกระบวนการฝึกฝนทั้งหมด โดยเฉลี่ยแต่ละรอบมีเกรเดียนต์จาก 16.9 โหนดที่ถูกรวมเข้าสู่การรวมกัน โหนด ID เดียวที่เคยมีส่วนร่วมสะสมเกิน 70 โหนด
เรื่องเล่าคุณค่าของ AI แบบกระจายศูนย์ กำลังเปลี่ยนแปลงไปอย่างถึงราก
มองจากมุมมองทางเทคนิคและอุตสาหกรรม ทิศทางที่ Covenant-72B เป็นตัวแทนมีความหมายที่แท้จริงหลายประการ
ประการแรก ทำลายข้อสมมติฐานที่ว่า "การฝึกฝนแบบกระจายศูนย์เหมาะสำหรับโมเดลขนาดเล็กเท่านั้น" แม้ว่าจะยังห่างไกลจากโมเดลล้ำสมัย แต่ก็พิสูจน์ความสามารถในการขยายขนาดของทิศทางนี้ได้
ประการที่สอง การเข้าร่วมแบบ


