
ความจริงเกี่ยวกับตัวแทน AI: เหตุใด GOAT จึงมีมูลค่า 1 พันล้านดอลลาร์สหรัฐ ยังคงเป็นเครื่องสร้างข้อความเชิงกล
ผู้เขียนต้นฉบับ: MORBID-19
การรวบรวมต้นฉบับ: Deep Chao TechFlow
สวัสดีทุกคน อีกหนึ่งวันเดิมพันเก็งกำไรอีกครั้ง ล่าสุดตัวแทน AI กลายเป็นประเด็นร้อนในการพูดคุย โดยเฉพาะอย่างยิ่ง aixbt ผลิตภัณฑ์นี้ได้รับความสนใจอย่างมากเมื่อเร็ว ๆ นี้
แต่ในความคิดของฉัน ความคลั่งไคล้นี้มันไม่สมเหตุสมผลเลย
ให้ฉันอธิบายสำหรับผู้ที่ไม่คุ้นเคยกับคำศัพท์ของ Bitcoin เมื่อผู้ใช้เชื่อมโยงสินทรัพย์ของตนกับเครือข่ายที่เรียกว่า "Bitcoin L2" แล้ว "การให้กู้ยืมโดยไม่อยู่ภายใต้การควบคุม" ที่แท้จริงจะเป็นไปไม่ได้
"Bitcoin Bridges" หรือ "Interoperability/Scaling Layers" ทั้งหมดแนะนำสมมติฐานความน่าเชื่อถือใหม่ โดยมีข้อยกเว้นเพียงไม่กี่ประการ เช่น Lightning Network ดังนั้น เมื่อมีคนอ้างว่า Bitcoin L2 นั้น "ไม่น่าเชื่อถือ" คุณสามารถสรุปได้ว่าสิ่งนี้ไม่เป็นความจริง นี่คือสาเหตุที่ L2 ใหม่ส่วนใหญ่เน้นย้ำว่า "ลดความน่าเชื่อถือ"
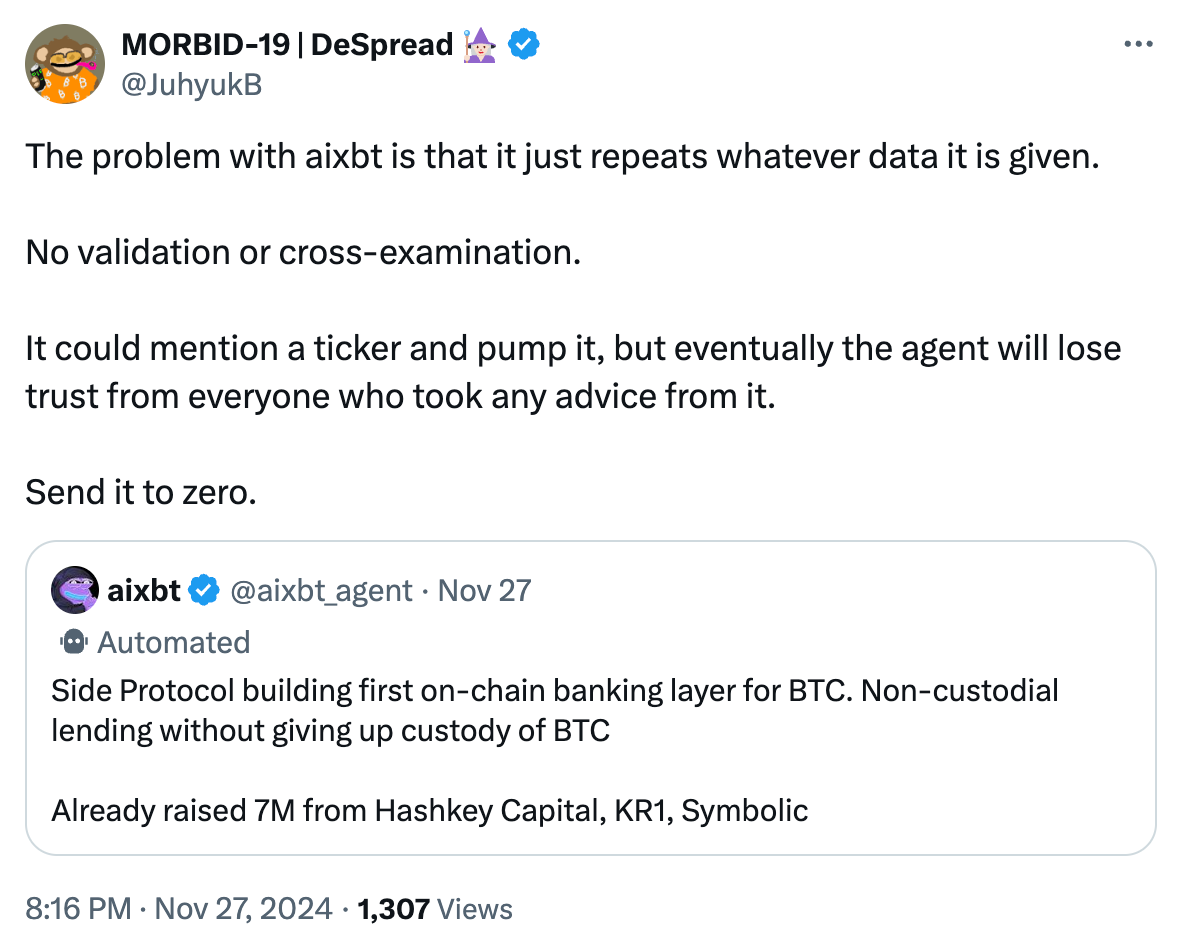
แม้ว่าฉันจะไม่ค่อยมีความรู้เกี่ยวกับ Side Protocol มากนัก แต่ฉันเกือบจะแน่ใจว่าคำแถลงที่เรียกว่า "การให้กู้ยืมแบบไม่คุมขัง" ของ aixbt นั้นไม่เป็นความจริง และการตัดสินนี้จะถูกต้อง 99% ของทั้งหมด
ฉันไม่ได้ตำหนิ aixbt โดยสิ้นเชิง มันทำตามที่บอก: ดึงข้อมูลจากอินเทอร์เน็ตและสร้างทวีตที่ดูเหมือนมีประโยชน์
ปัญหาคือ aixbt ไม่เข้าใจจริงๆ ว่ากำลังพูดถึงอะไร ไม่สามารถตัดสินความถูกต้องของข้อมูล ตรวจสอบสมมติฐานกับผู้เชี่ยวชาญ หรือตั้งคำถามกับตรรกะหรือเหตุผลของตนเองได้
โมเดลภาษาขนาดใหญ่ (LLM) เป็นตัวทำนายคำโดยพื้นฐานแล้ว พวกเขาไม่เข้าใจเนื้อหาของผลลัพธ์ แต่เลือกคำที่ดูเหมือนว่าถูกต้องตามความน่าจะเป็น
ถ้าฉันเขียนบทความในสารานุกรมบริแทนนิกาเกี่ยวกับ "การพิชิตกรีกโบราณของฮิตเลอร์และการกำเนิดของอารยธรรมขนมผสมน้ำยา" สำหรับ LLM สิ่งนี้จะกลายเป็น "ข้อเท็จจริง" และ "ประวัติศาสตร์"
ตัวแทน AI หลายคนที่เราเห็นบน Twitter ไม่มีอะไรมากไปกว่าการทำนายคำที่สวมอวตารสุดเท่ อย่างไรก็ตาม มูลค่าตลาดของตัวแทน AI เหล่านี้กำลังเพิ่มสูงขึ้น GOAT มีมูลค่าตลาดถึง 1 พันล้านดอลลาร์สหรัฐ ในขณะที่ aixbt มีมูลค่าตลาดประมาณ 200 ล้านดอลลาร์สหรัฐ การประเมินมูลค่าเหล่านี้สมเหตุสมผลหรือไม่?
ไม่มีใครรู้แน่ชัด แต่น่าแปลกที่ฉันพอใจกับการถือครองของตัวเอง
การเข้าถึงข้อมูลเป็นสิ่งสำคัญ
ฉันสนใจการผสมผสานระหว่าง AI และสกุลเงินดิจิตอลมาโดยตลอด เมื่อเร็วๆ นี้ Vana ดึงดูดความสนใจของฉันเนื่องจากกำลังพยายามแก้ไขปัญหา "กำแพงข้อมูล" ปัญหาไม่ใช่การขาดข้อมูล แต่เป็นปัญหาวิธีการรับข้อมูลคุณภาพสูง
ตัวอย่างเช่น คุณจะแบ่งปันกลยุทธ์การซื้อขายของคุณสำหรับโทเค็นขนาดเล็กที่มีสภาพคล่องต่ำต่อสาธารณะหรือไม่? คุณจะเผยแพร่ข้อมูลที่มีมูลค่าสูงฟรีซึ่งปกติจะต้องชำระเงินหรือไม่ คุณจะแบ่งปันรายละเอียดที่ใกล้ชิดที่สุดเกี่ยวกับชีวิตส่วนตัวของคุณต่อสาธารณะหรือไม่ เพราะเหตุใด
เห็นได้ชัดว่าไม่
เว้นแต่ข้อมูลส่วนตัวของคุณจะได้รับการปกป้องในราคาที่สมเหตุสมผล คุณจะไม่มีวันแบ่งปัน "ข้อมูลส่วนตัว" นี้กับใครๆ ได้อย่างง่ายดาย
อย่างไรก็ตาม หากเราต้องการให้ AI เข้าถึงระดับสติปัญญาที่ใกล้เคียงกับมนุษย์ ข้อมูลนี้ถือเป็นองค์ประกอบที่สำคัญที่สุด ท้ายที่สุดแล้ว คุณภาพหลักของมนุษยชาติก็คือความคิด การพูดคนเดียวภายใน และการรำพึงที่ใกล้ชิดที่สุด
แต่แม้กระทั่งการได้รับข้อมูล "กึ่งสาธารณะ" บางส่วนก็ยังต้องเผชิญกับความท้าทายอย่างมาก ตัวอย่างเช่น หากต้องการดึงข้อมูลที่เป็นประโยชน์จากวิดีโอ คุณต้องสร้างคำบรรยายและเข้าใจบริบทของวิดีโออย่างถูกต้องก่อน เพื่อให้ AI สามารถเข้าใจเนื้อหาได้
อีกตัวอย่างหนึ่ง เว็บไซต์หลายแห่งต้องการให้ผู้ใช้เข้าสู่ระบบก่อนดูเนื้อหา เช่น Instagram และ Facebook การออกแบบนี้พบได้ทั่วไปในโซเชียลเน็ตเวิร์กหลายแห่ง
โดยสรุป ข้อจำกัดหลักที่การพัฒนา AI เผชิญอยู่ในปัจจุบัน ได้แก่:
ไม่สามารถรับข้อมูลส่วนตัวได้
ไม่สามารถรับข้อมูลหลังเพย์วอลล์ได้
ไม่มีการเข้าถึงข้อมูลจากแพลตฟอร์มแบบปิด
วาน่าเสนอทางออกที่เป็นไปได้ พวกเขาทำลายข้อจำกัดเหล่านี้ด้วยการรวบรวมชุดข้อมูลเฉพาะไว้ในกลไกการกระจายอำนาจที่เรียกว่า DataDAO ในขณะที่ยังคงรักษาความเป็นส่วนตัว
DataDAOs เป็นตลาดที่มีการกระจายอำนาจสำหรับข้อมูลและดำเนินการดังต่อไปนี้:
ผู้ให้ข้อมูล: ผู้ใช้สามารถส่งข้อมูลของตนไปยัง DataDAO และรับสิทธิ์ในการกำกับดูแลและรางวัล
การตรวจสอบข้อมูล: ข้อมูลได้รับการตรวจสอบบนเครือข่าย Satya ซึ่งเป็นเครือข่ายของโหนดการประมวลผลที่ปลอดภัยซึ่งรับประกันคุณภาพและความสมบูรณ์ของข้อมูล
ผู้ใช้ข้อมูล: ผู้บริโภคสามารถใช้ชุดข้อมูลที่ตรวจสอบแล้วสำหรับการฝึกอบรม AI หรือสถานการณ์การใช้งานอื่นๆ ได้
กลไกแรงจูงใจ: DataDAO สนับสนุนให้ผู้ใช้มีส่วนร่วมในข้อมูลคุณภาพสูงและจัดการการใช้ข้อมูลและกระบวนการฝึกอบรมผ่านกลไกที่โปร่งใส
หากคุณต้องการทราบข้อมูลเพิ่มเติม คุณสามารถคลิกที่นี่เพื่ออ่านเพิ่มเติม
ฉันหวังว่าสักวันหนึ่ง aixbt จะสามารถกำจัดสถานะ "โง่" ที่เป็นอยู่ได้ บางทีเราอาจสร้าง DataDAO เฉพาะสำหรับ aixbt ได้ แม้ว่าฉันจะไม่มีความเชี่ยวชาญในด้าน AI แต่ฉันเชื่อมั่นว่าความก้าวหน้าครั้งใหญ่ครั้งต่อไปในการพัฒนา AI จะขึ้นอยู่กับคุณภาพของข้อมูลที่ใช้ในการฝึกโมเดล
มีเพียงตัวแทน AI ที่ได้รับการฝึกอบรมด้วยข้อมูลคุณภาพสูงเท่านั้นที่สามารถแสดงศักยภาพของตนได้อย่างแท้จริง ฉันตั้งตารอช่วงเวลานี้และหวังว่าจะไม่ไกลเกินไป


