
IOSG Ventures: วิกฤตอุปทาน GPU หนทางสำหรับบริษัท AI ที่เริ่มต้นธุรกิจจะฝ่าฟันไปได้
ผู้เขียนต้นฉบับ: Mohit Pandit, IOSG Ventures

สรุป
การขาดแคลน GPU เป็นเรื่องจริง อุปสงค์และอุปทานมีจำกัด แต่จำนวน GPU ที่ใช้งานน้อยเกินไปสามารถตอบสนองความต้องการด้านอุปทานที่จำกัดในปัจจุบันได้
จำเป็นต้องมีเลเยอร์สิ่งจูงใจเพื่ออำนวยความสะดวกในการมีส่วนร่วมในการประมวลผลบนคลาวด์ จากนั้นจึงประสานงานงานการประมวลผลเพื่อการอนุมานหรือการฝึกอบรมในท้ายที่สุด รุ่น DePIN นั้นสมบูรณ์แบบสำหรับจุดประสงค์นี้
เนื่องจากสิ่งจูงใจด้านอุปทาน เนื่องจากต้นทุนการคำนวณต่ำกว่า ฝั่งอุปสงค์จึงพบว่าสิ่งนี้น่าสนใจ
ไม่ใช่ทุกอย่างจะดูสดใส แต่คุณต้องทำข้อเสียบางอย่างเมื่อเลือก Web3 cloud เช่น เวลาแฝง เมื่อเปรียบเทียบกับคลาวด์ GPU แบบเดิม ข้อเสียที่ต้องเผชิญยังรวมถึงการประกันภัย ข้อตกลงระดับการให้บริการ (ข้อตกลงระดับการให้บริการ) ฯลฯ
โมเดล DePIN มีศักยภาพในการแก้ปัญหาความพร้อมใช้งานของ GPU แต่โมเดลที่กระจัดกระจายจะไม่ทำให้สถานการณ์ดีขึ้น สำหรับสถานการณ์ที่ความต้องการเพิ่มขึ้นแบบทวีคูณ อุปทานที่กระจัดกระจายจะเหมือนกับการไม่มีอุปทาน
การบรรจบกันของตลาดเป็นสิ่งที่หลีกเลี่ยงไม่ได้เมื่อพิจารณาจากจำนวนผู้เล่นในตลาดรายใหม่
การแนะนำ
เรากำลังเข้าใกล้ยุคใหม่ของการเรียนรู้ของเครื่องและปัญญาประดิษฐ์ ในขณะที่ AI อยู่ในรูปแบบต่างๆ มาระยะหนึ่งแล้ว (AI คืออุปกรณ์คอมพิวเตอร์ที่ถูกบอกให้ทำสิ่งที่มนุษย์สามารถทำได้ เช่น เครื่องซักผ้า) เรากำลังได้เห็นการเกิดขึ้นของโมเดลการรับรู้ที่ซับซ้อนซึ่งสามารถปฏิบัติงานที่ต้องใช้ความชาญฉลาด งานพฤติกรรมของมนุษย์ ตัวอย่างที่โดดเด่น ได้แก่ GPT-4 และ DALL-E 2 ของ OpenAI และ Gemini ของ Google
ในสาขาปัญญาประดิษฐ์ (AI) ที่เติบโตอย่างรวดเร็ว เราต้องตระหนักถึงการพัฒนาสองด้าน: การฝึกอบรมแบบจำลองและการอนุมาน การอนุมานรวมถึงความสามารถและผลลัพธ์ของโมเดล AI ในขณะที่การฝึกอบรมรวมถึงกระบวนการที่ซับซ้อน (รวมถึงอัลกอริธึมการเรียนรู้ของเครื่อง ชุดข้อมูล และพลังการประมวลผล) ที่จำเป็นในการสร้างโมเดลอัจฉริยะ
ในกรณีของ GPT-4 สิ่งที่ผู้ใช้ปลายทางสนใจคือการอนุมาน: การรับเอาต์พุตจากโมเดลตามการป้อนข้อความ อย่างไรก็ตาม คุณภาพของอนุมานนี้ขึ้นอยู่กับการฝึกโมเดล เพื่อฝึกอบรมโมเดล AI ที่มีประสิทธิภาพ นักพัฒนาจำเป็นต้องเข้าถึงชุดข้อมูลพื้นฐานที่ครอบคลุมและพลังการประมวลผลมหาศาล ทรัพยากรเหล่านี้ส่วนใหญ่กระจุกตัวอยู่ในมือของยักษ์ใหญ่ในอุตสาหกรรม เช่น OpenAI, Google, Microsoft และ AWS
สูตรนั้นเรียบง่าย: การฝึกอบรมโมเดลที่ดีขึ้น >> นำไปสู่ความสามารถในการอนุมานที่เพิ่มขึ้นของโมเดล AI >> จึงดึงดูดผู้ใช้มากขึ้น >> นำไปสู่รายได้มากขึ้นและส่งผลให้มีทรัพยากรเพิ่มขึ้นสำหรับการฝึกอบรมเพิ่มเติม
ผู้เล่นหลักเหล่านี้สามารถเข้าถึงชุดข้อมูลพื้นฐานขนาดใหญ่ และควบคุมพลังการประมวลผลจำนวนมาก ทำให้เกิดอุปสรรคในการเข้าสู่นักพัฒนาหน้าใหม่ เป็นผลให้ผู้เข้ามาใหม่มักจะดิ้นรนเพื่อให้ได้ข้อมูลที่เพียงพอหรือใช้ประโยชน์จากพลังการประมวลผลที่จำเป็นในราคาและขนาดที่เป็นไปได้ทางเศรษฐกิจ เมื่อคำนึงถึงสถานการณ์นี้ เราจะเห็นว่าเครือข่ายมีคุณค่าอย่างมากในการเข้าถึงทรัพยากรที่เป็นประชาธิปไตย โดยหลักๆ แล้วเกี่ยวข้องกับการเข้าถึงทรัพยากรการประมวลผลในวงกว้างและลดต้นทุน
ปัญหาการจัดหา GPU
Jensen Huang ซีอีโอของ NVIDIA กล่าวในงาน CES 2019 ว่า กฎของมัวร์จบลงแล้ว GPU ในปัจจุบันมีการใช้งานน้อยเกินไปอย่างมาก แม้ในระหว่างวงจรการเรียนรู้/การฝึกอบรมเชิงลึก GPU ก็ยังใช้งานน้อยเกินไป
ต่อไปนี้เป็นตัวเลขการใช้งาน GPU โดยทั่วไปสำหรับปริมาณงานที่แตกต่างกัน:
ไม่ได้ใช้งาน (เพิ่งบูตเข้าสู่ระบบปฏิบัติการ Windows): 0-2%
งานผลิตภาพทั่วไป (การเขียน การท่องเว็บแบบเบา): 0-15%
การเล่นวิดีโอ: 15 - 35%
เกมพีซี: 25 - 95%
งานออกแบบกราฟิก/แก้ไขภาพ (Photoshop, Illustrator): 15 - 55%
การตัดต่อวิดีโอ (ใช้งานอยู่): 15 - 55%
ตัดต่อวีดีโอ(เรนเดอร์) : 33 - 100%
การเรนเดอร์ 3 มิติ (CUDA/OptiX): 33 - 100% (มักรายงานอย่างไม่ถูกต้องโดย Win Task Manager - โดยใช้ GPU-Z)
อุปกรณ์ผู้บริโภคส่วนใหญ่ที่มี GPU จัดอยู่ในสามหมวดหมู่แรก
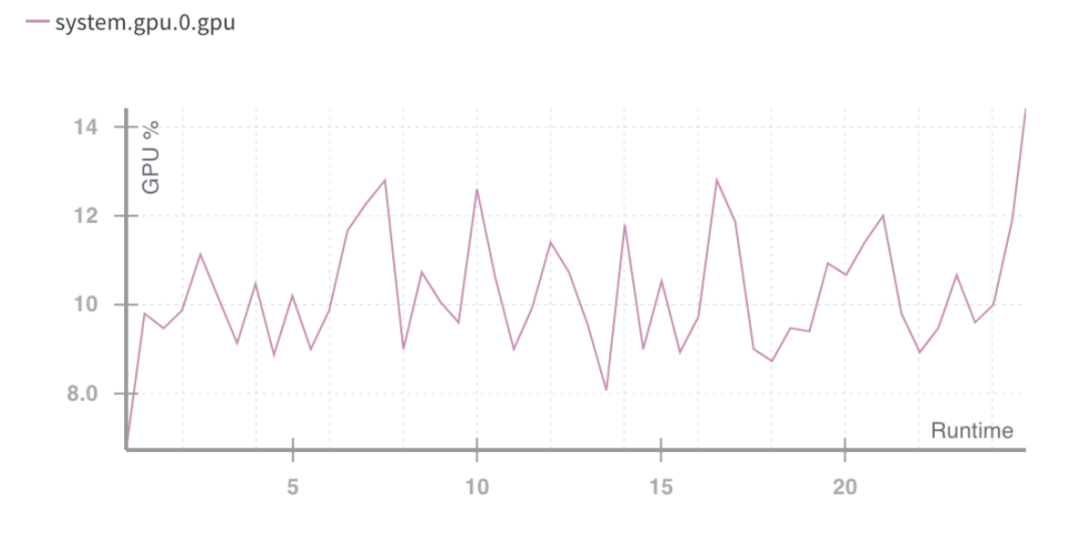
% การใช้งานรันไทม์ของ GPU ที่มา: น้ำหนักและอคติ
สถานการณ์ข้างต้นชี้ให้เห็นถึงปัญหา: การใช้ทรัพยากรคอมพิวเตอร์ไม่ดี
มีความจำเป็นที่จะต้องใช้ความจุของ GPU สำหรับผู้บริโภคให้ดีขึ้น ซึ่งยังไม่ค่อยเหมาะสม แม้ว่าการใช้งาน GPU จะเพิ่มสูงขึ้นก็ตาม สิ่งนี้ให้ความกระจ่างสองสิ่งที่จะต้องทำในอนาคต:
การรวมทรัพยากร (GPU)
การทำงานแบบขนานของการฝึกอบรม
ในส่วนของประเภทของฮาร์ดแวร์ที่สามารถใช้ได้นั้น ปัจจุบันมี 4 ประเภทที่นำเสนอ:
· GPU สำหรับศูนย์ข้อมูล (เช่น Nvidia A 100s)
· GPU สำหรับผู้บริโภค (เช่น Nvidia RTX 3060)
· ASIC แบบกำหนดเอง (เช่น Coreweave IPU)
· SoC ผู้บริโภค (เช่น Apple M 2)
นอกจาก ASIC แล้ว (เนื่องจากถูกสร้างขึ้นเพื่อวัตถุประสงค์เฉพาะ) ฮาร์ดแวร์อื่นๆ ยังสามารถนำมารวมกันเพื่อให้ใช้งานได้อย่างมีประสิทธิภาพสูงสุด เนื่องจากชิปเหล่านี้จำนวนมากอยู่ในมือของผู้บริโภคและศูนย์ข้อมูล โมเดล DePIN ฝั่งอุปทานแบบผสานรวมจึงอาจเป็นหนทางไป
การผลิต GPU เป็นปิรามิดปริมาณ โดย GPU สำหรับผู้บริโภคจะผลิตได้มากที่สุด ในขณะที่ GPU ระดับพรีเมียม เช่น NVIDIA A 100 และ H 100 จะผลิตได้น้อยที่สุด (แต่มีประสิทธิภาพสูงกว่า) ชิปขั้นสูงเหล่านี้มีราคาสูงกว่า GPU ทั่วไปถึง 15 เท่าในการผลิต แต่บางครั้งก็ไม่ได้ให้ประสิทธิภาพถึง 15 เท่า
ตลาดคลาวด์คอมพิวติ้งทั้งหมดมีมูลค่าประมาณ 483 พันล้านดอลลาร์ในปัจจุบัน และคาดว่าจะเติบโตที่อัตราการเติบโตต่อปีประมาณ 27% ในอีกไม่กี่ปีข้างหน้า ความต้องการการประมวลผล ML ประมาณ 13 พันล้านชั่วโมงภายในปี 2566 ซึ่งเท่ากับประมาณ 56 พันล้านดอลลาร์ในการใช้จ่ายด้านการประมวลผล ML ในปี 2566 ในอัตรามาตรฐานปัจจุบัน ตลาดทั้งหมดนี้เติบโตอย่างรวดเร็ว โดยเติบโต 2 เท่าทุกๆ 3 เดือน
ข้อกำหนดของ GPU
ความต้องการด้านคอมพิวเตอร์ส่วนใหญ่มาจากนักพัฒนา AI (นักวิจัยและวิศวกร) ความต้องการหลัก ได้แก่ ราคา (การประมวลผลต้นทุนต่ำ) ขนาด (การประมวลผล GPU จำนวนมาก) และประสบการณ์ผู้ใช้ (ความสะดวกในการเข้าถึงและใช้งาน) ในช่วงสองปีที่ผ่านมา GPU เป็นที่ต้องการอย่างมากเนื่องจากความต้องการที่เพิ่มขึ้นสำหรับแอปพลิเคชันที่ใช้ AI และการพัฒนาโมเดล ML การพัฒนาและใช้งานโมเดล ML ต้องการ:
การประมวลผลจำนวนมาก (จากการเข้าถึง GPU หรือศูนย์ข้อมูลหลายตัว)
ความสามารถในการฝึกอบรมโมเดล การปรับแต่งอย่างละเอียด และการอนุมาน โดยแต่ละงานจะถูกปรับใช้บน GPU จำนวนมากสำหรับการดำเนินการแบบขนาน
การใช้จ่ายด้านฮาร์ดแวร์ที่เกี่ยวข้องกับคอมพิวเตอร์คาดว่าจะเพิ่มขึ้นจาก 17 พันล้านดอลลาร์ในปี 2564 เป็น 285 พันล้านดอลลาร์ในปี 2568 (ประมาณ 102% CAGR) และ ARK คาดว่าการใช้จ่ายด้านฮาร์ดแวร์ที่เกี่ยวข้องกับคอมพิวเตอร์จะสูงถึง 1.7 ล้านล้านดอลลาร์ภายในปี 2573 (อัตราการเติบโตทบต้น 43% ต่อปี)
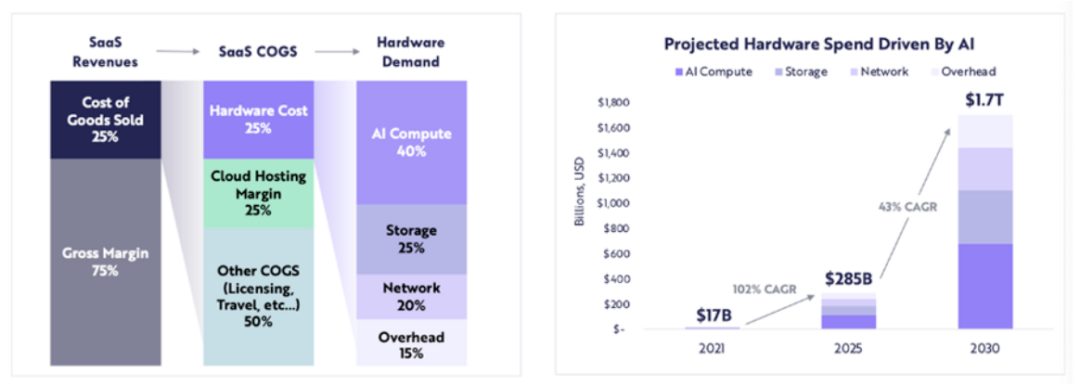
ARK Research
ด้วย LLM จำนวนมากในขั้นตอนนวัตกรรมและการแข่งขันที่ขับเคลื่อนความต้องการด้านการคำนวณสำหรับพารามิเตอร์ที่มากขึ้น ตลอดจนการฝึกอบรมใหม่ เราจึงสามารถคาดหวังความต้องการการประมวลผลคุณภาพสูงอย่างต่อเนื่องในปีต่อๆ ไป
เมื่ออุปทานของ GPU ใหม่เพิ่มมากขึ้น blockchain จะเข้ามามีบทบาทที่ไหน?
เมื่อทรัพยากรไม่เพียงพอ โมเดล DePIN จะให้ความช่วยเหลือ:
เริ่มต้นด้านการจัดหาและสร้างการจัดหาขนาดใหญ่
ประสานงานและทำงานให้เสร็จสิ้น
ตรวจสอบให้แน่ใจว่างานเสร็จสมบูรณ์อย่างถูกต้อง
ให้รางวัลแก่ผู้ให้บริการอย่างเหมาะสมเพื่อให้งานสำเร็จลุล่วง
การรวม GPU ทุกประเภท (ผู้บริโภค องค์กร ประสิทธิภาพสูง ฯลฯ) อาจทำให้เกิดปัญหาในการใช้งานได้ เมื่องานการคำนวณถูกแบ่งออก ชิป A 100 ไม่ควรทำการคำนวณง่ายๆ เครือข่าย GPU จำเป็นต้องตัดสินใจว่า GPU ประเภทใดที่พวกเขาคิดว่าควรรวมไว้ในเครือข่าย โดยพิจารณาจากกลยุทธ์การเข้าสู่ตลาด
เมื่อมีการกระจายทรัพยากรการประมวลผล (บางครั้งทั่วโลก) ผู้ใช้หรือโปรโตคอลจะต้องตัดสินใจเองว่าจะใช้เฟรมเวิร์กการประมวลผลประเภทใด ผู้ให้บริการอย่าง io.net อนุญาตให้ผู้ใช้เลือกจาก 3 เฟรมเวิร์กการประมวลผล: Ray, Mega-Ray หรือปรับใช้คลัสเตอร์ Kubernetes เพื่อทำงานการประมวลผลในคอนเทนเนอร์ มีเฟรมเวิร์กการประมวลผลแบบกระจายมากกว่า เช่น Apache Spark แต่ Ray ถูกใช้บ่อยที่สุด เมื่อ GPU ที่เลือกทำงานด้านการคำนวณเสร็จสิ้น เอาต์พุตจะถูกสร้างขึ้นใหม่เพื่อให้เป็นโมเดลที่ผ่านการฝึกอบรม
โมเดลโทเค็นที่ออกแบบมาอย่างดีจะอุดหนุนต้นทุนการประมวลผลสำหรับผู้ให้บริการ GPU และนักพัฒนาหลายราย (ฝั่งอุปสงค์) จะพบว่าโครงการดังกล่าวน่าสนใจยิ่งขึ้น ระบบคอมพิวเตอร์แบบกระจายมีเวลาแฝงโดยเนื้อแท้ มีการสลายตัวทางคอมพิวเตอร์และการสร้างเอาต์พุตใหม่ ดังนั้นนักพัฒนาจึงจำเป็นต้องแลกระหว่างความคุ้มค่าของการฝึกอบรมโมเดลกับเวลาที่ต้องใช้
ระบบคอมพิวเตอร์แบบกระจายจำเป็นต้องมีสายโซ่ของตัวเองหรือไม่?
เครือข่ายทำงานในสองวิธี:
คิดค่าบริการตามงาน (หรือรอบการคำนวณ) หรือตามเวลา
คิดตามหน่วยเวลา
ในแนวทางแรก เราสามารถสร้างห่วงโซ่การพิสูจน์การทำงานได้คล้ายกับสิ่งที่ Gensyn กำลังพยายาม โดยที่ GPU ที่แตกต่างกันจะแบ่งปัน งาน และได้รับค่าตอบแทนจากมัน สำหรับโมเดลที่ไม่น่าเชื่อถือมากขึ้น พวกเขามีแนวคิดเกี่ยวกับผู้ตรวจสอบและผู้แจ้งเบาะแส ซึ่งได้รับรางวัลสำหรับการรักษาความสมบูรณ์ของระบบ โดยอิงตามการพิสูจน์ที่สร้างโดยนักแก้ปัญหา
ระบบพิสูจน์การทำงานอีกระบบหนึ่งคือ Exabits ซึ่งแทนที่จะแบ่งพาร์ติชันงานจะถือว่าเครือข่าย GPU ทั้งหมดเป็นซูเปอร์คอมพิวเตอร์เครื่องเดียว ดูเหมือนว่ารุ่นนี้จะเหมาะกับ LLM ขนาดใหญ่มากกว่า
Akash Network เพิ่มการรองรับ GPU และเริ่มรวม GPU ไว้ในพื้นที่นี้ พวกเขามี L1 พื้นฐานเพื่อให้บรรลุฉันทามติเกี่ยวกับสถานะ (แสดงงานที่ทำโดยผู้ให้บริการ GPU) เลเยอร์ตลาด และระบบประสานคอนเทนเนอร์ เช่น Kubernetes หรือ Docker Swarm เพื่อจัดการการปรับใช้และการปรับขนาดแอปพลิเคชันผู้ใช้
หากระบบไม่น่าเชื่อถือ โมเดลลูกโซ่การพิสูจน์การทำงานจะมีประสิทธิภาพสูงสุด สิ่งนี้ทำให้มั่นใจได้ถึงการประสานงานและความสมบูรณ์ของโปรโตคอล
ในทางกลับกัน ระบบอย่าง io.net ไม่ได้จัดโครงสร้างตัวเองเป็นลูกโซ่ พวกเขาเลือกที่จะแก้ไขปัญหาหลักของความพร้อมใช้งานของ GPU และเรียกเก็บเงินลูกค้าต่อหน่วยเวลา (ต่อชั่วโมง) พวกเขาไม่ต้องการชั้นการตรวจสอบ เนื่องจากโดยพื้นฐานแล้วพวกเขาจะ เช่า GPU และใช้งานตามที่ต้องการตามระยะเวลาเช่าที่ระบุ ไม่มีการแบ่งงานในโปรโตคอล แต่นักพัฒนาทำโดยใช้เฟรมเวิร์กโอเพ่นซอร์ส เช่น Ray, Mega-Ray หรือ Kubernetes
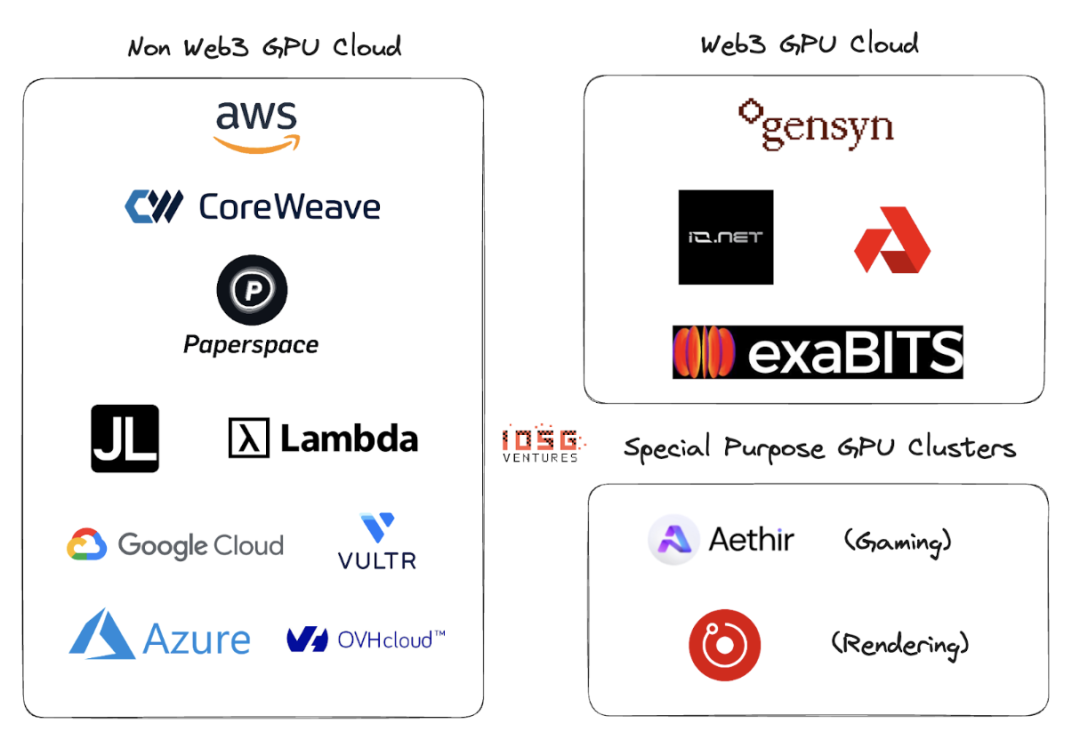
Web2 และ Web3 GPU คลาวด์
Web2 มีผู้เล่นจำนวนมากใน GPU cloud หรือ GPU เป็นพื้นที่ให้บริการ ผู้เล่นหลักในพื้นที่นี้ ได้แก่ AWS, CoreWeave, PaperSpace, Jarvis Labs, Lambda Labs, Google Cloud, Microsoft Azure และ OVH Cloud
นี่คือโมเดลธุรกิจคลาวด์แบบดั้งเดิมที่ลูกค้าเช่า GPU (หรือ GPU หลายตัว) ตามหน่วยเวลา (โดยปกติคือหนึ่งชั่วโมง) เมื่อพวกเขาต้องการการประมวลผล มีโซลูชันที่แตกต่างกันมากมายสำหรับกรณีการใช้งานที่แตกต่างกัน
ความแตกต่างที่สำคัญระหว่างคลาวด์ Web2 และ Web3 GPU คือพารามิเตอร์ต่อไปนี้:
1. ค่าใช้จ่ายในการติดตั้งระบบคลาวด์
เนื่องจากแรงจูงใจด้านโทเค็น ค่าใช้จ่ายในการตั้งค่าคลาวด์ GPU จึงลดลงอย่างมาก OpenAI กำลังระดมทุน 1 ล้านล้านดอลลาร์เพื่อสนับสนุนการผลิตชิปประมวลผล ดูเหมือนว่าหากไม่มีแรงจูงใจด้านโทเค็น จะต้องใช้เวลาอย่างน้อย 1 ล้านล้านดอลลาร์เพื่อเอาชนะผู้นำตลาด
2. เวลาในการคำนวณ
คลาวด์ GPU ที่ไม่ใช่ Web3 จะเร็วขึ้นเนื่องจากคลัสเตอร์ GPU ที่เช่านั้นตั้งอยู่ในพื้นที่ทางภูมิศาสตร์ ในขณะที่รุ่น Web3 อาจมีระบบที่กระจายอย่างกว้างขวางกว่า และเวลาแฝงอาจมาจากการแบ่งพาร์ติชันปัญหาที่ไม่มีประสิทธิภาพ โหลดบาลานซ์ และแบนด์วิดท์ที่สำคัญที่สุด .
3. คำนวณต้นทุน
เนื่องจากแรงจูงใจด้านโทเค็น ต้นทุนของการประมวลผล Web3 จึงต่ำกว่าโมเดล Web2 ที่มีอยู่อย่างมาก
การเปรียบเทียบต้นทุนการคำนวณ:
ตัวเลขเหล่านี้อาจเปลี่ยนแปลงเมื่อมีคลัสเตอร์อุปทานและการใช้งานเพิ่มมากขึ้นสำหรับ GPU เหล่านี้ Gensyn อ้างว่าเสนอ A 100 (และรายการเทียบเท่า) ในราคาเพียง 0.55 เหรียญต่อชั่วโมง และ Exabits ให้คำมั่นสัญญาว่าจะมีโครงสร้างการประหยัดต้นทุนที่คล้ายคลึงกัน
4. การปฏิบัติตาม
การปฏิบัติตามข้อกำหนดไม่ใช่เรื่องง่ายในระบบที่ไม่ได้รับอนุญาต อย่างไรก็ตาม ระบบ Web3 เช่น io.net, Gensyn ฯลฯ ไม่ได้วางตำแหน่งตัวเองเป็นระบบที่ไม่ได้รับอนุญาต จัดการปัญหาการปฏิบัติตามข้อกำหนด เช่น GDPR และ HIPAA ในระหว่างการเริ่มต้นใช้งาน GPU การโหลดข้อมูล การแบ่งปันข้อมูล และขั้นตอนการแชร์ผลลัพธ์
ระบบนิเวศ
Gensyn、io.net、Exabits、Akash
เสี่ยง
1. ความเสี่ยงด้านอุปสงค์
ฉันคิดว่าผู้เล่น LLM อันดับต้นๆ จะยังคงสะสม GPU ต่อไปหรือใช้คลัสเตอร์ GPU เช่น ซูเปอร์คอมพิวเตอร์ Selene ของ NVIDIA ซึ่งมีประสิทธิภาพสูงสุดที่ 2.8 exaFLOP/s พวกเขาจะไม่พึ่งพาผู้บริโภคหรือผู้ให้บริการคลาวด์หางยาวเพื่อรวม GPU ปัจจุบันองค์กร AI ชั้นนำแข่งขันกันในเรื่องคุณภาพมากกว่าต้นทุน
สำหรับโมเดล ML ที่ไม่หนัก พวกเขาจะมองหาทรัพยากรการประมวลผลที่ราคาถูกกว่า เช่น คลัสเตอร์ GPU ที่ใช้โทเค็นแบบบล็อกเชน ซึ่งสามารถให้บริการไปพร้อมๆ กับเพิ่มประสิทธิภาพ GPU ที่มีอยู่ได้ (ข้างต้นเป็นสมมติฐาน: องค์กรเหล่านั้นต้องการฝึกอบรมโมเดลของตนเอง แทนที่จะใช้ นิติศาสตร์มหาบัณฑิต)
2. ความเสี่ยงด้านอุปทาน
ด้วยการทุ่มทุนจำนวนมหาศาลให้กับการวิจัยของ ASIC และสิ่งประดิษฐ์ต่างๆ เช่น Tensor Processing Unit (TPU) ปัญหาการจัดหา GPU นี้อาจหายไปได้ด้วยตัวเอง หาก ASIC เหล่านี้สามารถให้ประสิทธิภาพที่ดี: การลดต้นทุน GPU ที่มีอยู่ซึ่งสะสมโดยองค์กร AI ขนาดใหญ่ก็อาจกลับคืนสู่ตลาดได้
คลัสเตอร์ GPU ที่ใช้บล็อกเชนสามารถแก้ปัญหาระยะยาวได้หรือไม่? แม้ว่าบล็อคเชนจะสามารถรองรับชิปอื่น ๆ ที่ไม่ใช่ GPU ได้ แต่สิ่งที่ฝ่ายดีมานด์ทำจะเป็นตัวกำหนดทิศทางของโปรเจ็กต์ในพื้นที่นี้อย่างสมบูรณ์
สรุปแล้ว
เครือข่ายกระจัดกระจายที่มีคลัสเตอร์ GPU ขนาดเล็กไม่สามารถแก้ปัญหาได้ ไม่มีที่สำหรับคลัสเตอร์ GPU แบบ หางยาว ผู้ให้บริการ GPU (ผู้เล่นคลาวด์รายย่อยหรือรายย่อย) จะหันไปหาเครือข่ายที่ใหญ่กว่าเพราะแรงจูงใจสำหรับเครือข่ายนั้นดีกว่า จะเป็นฟังก์ชันของโมเดลโทเค็นที่ดีและความสามารถของฝั่งซัพพลายเพื่อรองรับการประมวลผลหลายประเภท
คลัสเตอร์ GPU อาจเห็นชะตากรรมการรวมกลุ่มที่คล้ายคลึงกันกับ CDN หากผู้เล่นรายใหญ่ต้องแข่งขันกับผู้นำที่มีอยู่ เช่น AWS พวกเขาอาจเริ่มแบ่งปันทรัพยากรเพื่อลดเวลาแฝงของเครือข่ายและความใกล้ชิดทางภูมิศาสตร์ของโหนด
หากด้านอุปสงค์มีขนาดใหญ่ขึ้น (จำเป็นต้องฝึกอบรมโมเดลเพิ่มเติมและจำนวนพารามิเตอร์ที่ต้องได้รับการฝึกอบรมมากขึ้น) ผู้เล่น Web3 จะต้องกระตือรือร้นอย่างมากในการพัฒนาธุรกิจด้านอุปทาน หากมีคลัสเตอร์มากเกินไปที่แข่งขันจากฐานลูกค้าเดียวกัน อุปทานจะกระจัดกระจาย (ซึ่งทำให้แนวคิดทั้งหมดเป็นโมฆะ) ในขณะที่ความต้องการ (วัดเป็น TFLOP) จะเพิ่มขึ้นแบบทวีคูณ
Io.net มีความโดดเด่นจากคู่แข่งหลายราย โดยเริ่มจากโมเดลผู้รวบรวม พวกเขาได้รวบรวม GPU จาก Render Network และ Filecoin miners เพื่อจัดหาความจุ ในขณะเดียวกันก็ทำการบู๊ตอุปทานบนแพลตฟอร์มของพวกเขาเอง นี่อาจเป็นทิศทางชัยชนะสำหรับคลัสเตอร์ DePIN GPU


