
YBB Capital: ตัวอย่างเส้นทางที่มีศักยภาพ - ตลาดพลังงานคอมพิวเตอร์แบบกระจายอำนาจ (ตอนที่ 1)
ผู้เขียนต้นฉบับ: Zeke, YBB Capital

คำนำ
นับตั้งแต่การถือกำเนิดของ GPT-3 AI เจนเนอเรชั่นได้นำไปสู่จุดเปลี่ยนครั้งใหญ่ในด้านปัญญาประดิษฐ์ด้วยประสิทธิภาพที่น่าทึ่งและสถานการณ์การใช้งานที่หลากหลาย และยักษ์ใหญ่ด้านเทคโนโลยีก็เริ่มรวมตัวกันเพื่อก้าวเข้าสู่เส้นทาง AI แต่ปัญหาก็เกิดขึ้นเช่นกัน การฝึกอบรมและการอนุมานโมเดลภาษาขนาดใหญ่ (LLM) ต้องใช้พลังการประมวลผลจำนวนมาก การอัพเกรดโมเดลซ้ำ ๆ ความต้องการพลังการประมวลผลและต้นทุนจะเพิ่มขึ้นแบบทวีคูณ ยกตัวอย่าง GPT-2 และ GPT-3 ความแตกต่างในปริมาณพารามิเตอร์ระหว่าง GPT-2 และ GPT-3 คือ 1166 เท่า (GPT-2 คือ 150 ล้านพารามิเตอร์ และ GPT-3 คือ 175 พันล้านพารามิเตอร์) เซสชั่นการฝึกอบรมของ GPT-3 ต้นทุนคำนวณตามโมเดลราคาของ GPU Cloud สาธารณะในขณะนั้น ซึ่งมีมูลค่าสูงถึง 12 ล้านดอลลาร์สหรัฐ ซึ่งมากกว่า GPT-2 ถึง 200 เท่า ในการใช้งานจริง ทุกคำถามของผู้ใช้จำเป็นต้องมีการคำนวณแบบอนุมาน จากการเข้าชมของผู้ใช้ที่ไม่ซ้ำกัน 13 ล้านครั้งเมื่อต้นปีนี้ ความต้องการชิปที่สอดคล้องกันคือมากกว่า 30,000 A 100 GPU ต้นทุนการลงทุนเริ่มแรกจะมีมูลค่าสูงถึง 800 ล้านดอลลาร์ โดยมีค่าใช้จ่ายอนุมานแบบจำลองรายวันประมาณ 700,000 ดอลลาร์
พลังการประมวลผลที่ไม่เพียงพอและค่าใช้จ่ายสูงกลายเป็นปัญหาที่อุตสาหกรรม AI ทั้งหมดต้องเผชิญ แต่ปัญหาเดียวกันนี้ดูเหมือนจะรบกวนอุตสาหกรรมบล็อกเชนเช่นกัน ในอีกด้านหนึ่ง การลดครึ่งหนึ่งของ Bitcoin และการยอมรับ ETF ใกล้เข้ามาแล้ว เมื่อราคาสูงขึ้นในอนาคต ความต้องการของนักขุดสำหรับฮาร์ดแวร์คอมพิวเตอร์ก็จะเพิ่มขึ้นอย่างมากอย่างหลีกเลี่ยงไม่ได้ ในทางกลับกัน การพิสูจน์ความรู้เป็นศูนย์ ("Zero-Knowledge Proof"หรือเรียกสั้นๆ ว่า ZKP) เทคโนโลยีกำลังเฟื่องฟู และ Vitalik ได้เน้นย้ำซ้ำแล้วซ้ำเล่าว่าผลกระทบของ ZK ในด้านบล็อกเชนในอีกสิบปีข้างหน้าจะมีความสำคัญพอๆ กับตัวบล็อกเชนเอง แม้ว่าอุตสาหกรรมบล็อกเชนจะมีความหวังสูงสำหรับอนาคตของเทคโนโลยีนี้ แต่ ZK ยังใช้พลังการประมวลผลและเวลาจำนวนมากในการสร้างการพิสูจน์เนื่องจากกระบวนการคำนวณที่ซับซ้อน เช่นเดียวกับ AI
ในอนาคตอันใกล้ การขาดแคลนพลังการประมวลผลจะกลายเป็นสิ่งที่หลีกเลี่ยงไม่ได้ ดังนั้นตลาดพลังงานการประมวลผลแบบกระจายอำนาจจะเป็นธุรกิจที่ดีหรือไม่
คำจำกัดความของตลาดพลังงานคอมพิวเตอร์แบบกระจายอำนาจ
โดยพื้นฐานแล้วตลาดพลังการประมวลผลแบบกระจายอำนาจนั้นเทียบเท่ากับเส้นทางการประมวลผลแบบคลาวด์แบบกระจายอำนาจ แต่เมื่อเทียบกับการประมวลผลบนคลาวด์แบบกระจายอำนาจ โดยส่วนตัวแล้วฉันคิดว่าคำนี้เหมาะสมกว่าในการอธิบายโครงการใหม่ที่กล่าวถึงในภายหลัง ตลาดพลังงานการประมวลผลแบบกระจายอำนาจควรอยู่ในชุดย่อยของ DePIN (เครือข่ายโครงสร้างพื้นฐานทางกายภาพแบบกระจายอำนาจ) เป้าหมายคือการสร้างตลาดพลังงานการประมวลผลแบบเปิดและด้วยแรงจูงใจโทเค็นใครก็ตามที่มีทรัพยากรพลังงานการประมวลผลที่ไม่ได้ใช้งานสามารถจัดหาทรัพยากรของพวกเขาในตลาดนี้ได้ ให้บริการผู้ใช้ B-end และกลุ่มนักพัฒนาเป็นหลัก จากมุมมองของโปรเจ็กต์ที่คุ้นเคยมากกว่า เช่น Render Network เครือข่ายโซลูชันการเรนเดอร์ที่ใช้ GPU แบบกระจายอำนาจ และ Akash Network ซึ่งเป็นตลาดแบบ peer-to-peer แบบกระจายสำหรับการประมวลผลแบบคลาวด์ ทั้งสองอยู่ในเส้นทางนี้
ต่อไปนี้จะเริ่มต้นด้วยแนวคิดพื้นฐานแล้วหารือเกี่ยวกับตลาดเกิดใหม่สามตลาดภายใต้แนวทางนี้: ตลาดพลังงานการประมวลผล AGI, ตลาดพลังงานการประมวลผล Bitcoin และตลาดพลังงานการประมวลผล AGI ในตลาดการเร่งความเร็วด้วยฮาร์ดแวร์ ZK สองหลังจะมีการหารือ ใน ตัวอย่างเส้นทางที่มีศักยภาพ: ตลาดพลังงานคอมพิวเตอร์แบบกระจายอำนาจ (ตอนที่ 2) จะมีการหารือ
ภาพรวมของพลังการประมวลผล
ต้นกำเนิดของแนวคิดเรื่องพลังการประมวลผลสามารถย้อนกลับไปถึงจุดเริ่มต้นของการประดิษฐ์คอมพิวเตอร์ คอมพิวเตอร์เครื่องเดิมใช้อุปกรณ์ทางกลเพื่อทำงานด้านการคำนวณให้เสร็จสมบูรณ์ และพลังการประมวลผลหมายถึงพลังการคำนวณของอุปกรณ์ทางกล ด้วยการพัฒนาเทคโนโลยีคอมพิวเตอร์ แนวคิดเรื่องพลังการประมวลผลก็พัฒนาขึ้นเช่นกัน พลังการประมวลผลในปัจจุบันมักหมายถึงการทำงานร่วมกันของฮาร์ดแวร์คอมพิวเตอร์ (CPU, GPU, FPGA ฯลฯ) และซอฟต์แวร์ (ระบบปฏิบัติการ คอมไพเลอร์ โปรแกรมแอปพลิเคชัน ฯลฯ .) ความสามารถ
คำนิยาม
กำลังคอมพิวเตอร์หมายถึงปริมาณข้อมูลที่คอมพิวเตอร์หรืออุปกรณ์คอมพิวเตอร์อื่นสามารถประมวลผลได้ หรือจำนวนงานคอมพิวเตอร์ที่เสร็จสิ้นภายในระยะเวลาหนึ่ง โดยปกติแล้วพลังคอมพิวเตอร์จะใช้เพื่ออธิบายประสิทธิภาพของคอมพิวเตอร์หรืออุปกรณ์คอมพิวเตอร์อื่น ๆ เป็นตัวบ่งชี้ที่สำคัญของพลังการประมวลผลของอุปกรณ์คอมพิวเตอร์
เมตริก
พลังการประมวลผลสามารถวัดได้หลายวิธี เช่น ความเร็วการประมวลผล การใช้พลังงานในการประมวลผล ความแม่นยำในการคำนวณ และความขนาน ในสาขาคอมพิวเตอร์ การวัดกำลังการประมวลผลที่ใช้กันทั่วไป ได้แก่ FLOPS (การดำเนินการจุดลอยตัวต่อวินาที), IPS (คำสั่งต่อวินาที), TPS (ธุรกรรมต่อวินาที) เป็นต้น
FLOPS (การดำเนินการจุดลอยตัวต่อวินาที) หมายถึงความสามารถของคอมพิวเตอร์ในการประมวลผลการดำเนินการจุดลอยตัว (การดำเนินการทางคณิตศาสตร์กับตัวเลขที่มีจุดทศนิยมที่ต้องพิจารณาปัญหาด้านความแม่นยำและข้อผิดพลาดในการปัดเศษ) โดยจะวัดว่าคอมพิวเตอร์สามารถทำได้ต่อวินาทีมากเพียงใด การดำเนินการจุดลอยตัว FLOPS เป็นหน่วยวัดความสามารถในการประมวลผลประสิทธิภาพสูงของคอมพิวเตอร์ และมักใช้เพื่อวัดความสามารถในการประมวลผลของซูเปอร์คอมพิวเตอร์ เซิร์ฟเวอร์คอมพิวเตอร์ประสิทธิภาพสูง หน่วยประมวลผลกราฟิก (GPU) ฯลฯ ตัวอย่างเช่น ระบบคอมพิวเตอร์มี FLOPS เท่ากับ 1 TFLOPS (การดำเนินการจุดลอยตัวหนึ่งล้านล้านรายการต่อวินาที) ซึ่งหมายความว่าสามารถดำเนินการจุดลอยตัวได้ 1 ล้านล้านรายการต่อวินาที
IPS (คำสั่งต่อวินาที) หมายถึงความเร็วที่คอมพิวเตอร์ประมวลผลคำสั่ง ซึ่งเป็นการวัดจำนวนคำสั่งที่คอมพิวเตอร์สามารถดำเนินการต่อวินาที IPS เป็นตัววัดประสิทธิภาพคำสั่งเดียวของคอมพิวเตอร์ และโดยปกติจะใช้เพื่อวัดประสิทธิภาพของหน่วยประมวลผลกลาง (CPU) ฯลฯ ตัวอย่างเช่น CPU ที่มี IPS 3 GHz (300 ล้านคำสั่งต่อวินาที) หมายความว่าสามารถดำเนินการได้ 300 ล้านคำสั่งต่อวินาที
TPS (ธุรกรรมต่อวินาที) หมายถึงความสามารถของคอมพิวเตอร์ในการประมวลผลธุรกรรม โดยวัดจำนวนธุรกรรมที่คอมพิวเตอร์สามารถทำได้ต่อวินาที โดยทั่วไปจะใช้เพื่อวัดประสิทธิภาพของเซิร์ฟเวอร์ฐานข้อมูล ตัวอย่างเช่น เซิร์ฟเวอร์ฐานข้อมูลมี TPS อยู่ที่ 1,000 ซึ่งหมายความว่าสามารถรองรับธุรกรรมฐานข้อมูลได้ 1,000 รายการต่อวินาที
นอกจากนี้ ยังมีตัวบ่งชี้พลังการประมวลผลบางส่วนสำหรับสถานการณ์การใช้งานเฉพาะ เช่น ความเร็วในการอนุมาน ความเร็วในการประมวลผลภาพ และความแม่นยำในการรู้จำเสียงพูด
ประเภทของพลังการคำนวณ
พลังการประมวลผล GPU หมายถึงพลังการประมวลผลของโปรเซสเซอร์กราฟิก (หน่วยประมวลผลกราฟิก) GPU เป็นฮาร์ดแวร์ที่ได้รับการออกแบบมาโดยเฉพาะเพื่อประมวลผลข้อมูลกราฟิก เช่น รูปภาพ และวิดีโอ ต่างจาก CPU (หน่วยประมวลผลกลาง) มีหน่วยประมวลผลจำนวนมากและความสามารถในการคำนวณแบบขนานที่มีประสิทธิภาพ และสามารถดำเนินการจุดลอยตัวจำนวนมากพร้อมกันได้ . เนื่องจากเดิมที GPU ได้รับการออกแบบมาสำหรับการประมวลผลกราฟิกสำหรับเล่นเกม โดยทั่วไปแล้ว GPU จึงมีความถี่สัญญาณนาฬิกาที่สูงกว่าและแบนด์วิธหน่วยความจำที่มากกว่า CPU เพื่อรองรับการทำงานของกราฟิกที่ซับซ้อน
ความแตกต่างระหว่าง CPU และ GPU
สถาปัตยกรรม: CPU และ GPU มีสถาปัตยกรรมการประมวลผลที่แตกต่างกัน โดยทั่วไปแล้ว CPU จะใช้คอร์ตั้งแต่หนึ่งคอร์ขึ้นไป ซึ่งแต่ละคอร์เป็นโปรเซสเซอร์อเนกประสงค์ที่สามารถดำเนินการต่างๆ ได้อย่างหลากหลาย GPU มีสตรีมโปรเซสเซอร์และเชเดอร์จำนวนมาก ซึ่งใช้เป็นพิเศษในการดำเนินการที่เกี่ยวข้องกับการประมวลผลภาพ
คอมพิวเตอร์แบบขนาน: โดยทั่วไปแล้ว GPU มีความสามารถในการประมวลผลแบบขนานที่สูงกว่า CPU มีจำนวนคอร์ที่จำกัด และแต่ละคอร์สามารถดำเนินการคำสั่งได้เพียงคำสั่งเดียวเท่านั้น แต่ GPU สามารถมีสตรีมโปรเซสเซอร์นับพันตัวที่สามารถดำเนินการหลายคำสั่งและการทำงานพร้อมกันได้ ดังนั้น โดยทั่วไป GPU จึงเหมาะสมกว่า CPU ในการทำงานการประมวลผลแบบขนาน เช่น การเรียนรู้ของเครื่องและการเรียนรู้เชิงลึก ซึ่งต้องใช้การประมวลผลแบบขนานจำนวนมาก
การเขียนโปรแกรม: การเขียนโปรแกรม GPU มีความซับซ้อนมากกว่า CPU โดยต้องใช้ภาษาการเขียนโปรแกรมเฉพาะ (เช่น CUDA หรือ OpenCL) และการใช้เทคนิคการเขียนโปรแกรมเฉพาะเพื่อใช้ความสามารถในการประมวลผลแบบขนานของ GPU ในทางตรงกันข้าม การเขียนโปรแกรม CPU นั้นง่ายกว่าและสามารถใช้ภาษาการเขียนโปรแกรมสำหรับวัตถุประสงค์ทั่วไปและเครื่องมือการเขียนโปรแกรมได้
ความสำคัญของพลังการประมวลผล
ในยุคปฏิวัติอุตสาหกรรม น้ำมันถือเป็นเลือดของโลกและแทรกซึมเข้าไปในทุกอุตสาหกรรม พลังการประมวลผลอยู่ในบล็อกเชน และในยุค AI ที่กำลังจะมาถึง พลังการประมวลผลจะเป็น “น้ำมันดิจิทัล” ของโลก ตั้งแต่บริษัทยักษ์ใหญ่คว้าชิป AI อย่างบ้าคลั่งและหุ้นของ Nvidia เกินหนึ่งล้านล้าน ไปจนถึงการปิดล้อมชิประดับไฮเอนด์จากจีนเมื่อเร็ว ๆ นี้ของสหรัฐอเมริกา รายละเอียดต่างๆ ได้แก่ พลังการประมวลผล พื้นที่ของชิป และแม้แต่แผนที่จะแบนระบบคลาวด์ GPU ของมัน ความสำคัญปรากฏชัดในตัวเอง พลังการประมวลผล จะเป็นสินค้าในยุคหน้า

ภาพรวมของปัญญาประดิษฐ์ทั่วไป
ปัญญาประดิษฐ์ (Artificial Intelligence) เป็นศาสตร์ทางเทคนิคใหม่ที่ศึกษาและพัฒนาทฤษฎี วิธีการ เทคโนโลยี และระบบประยุกต์เพื่อจำลอง ขยาย และขยายปัญญาของมนุษย์ มีต้นกำเนิดในทศวรรษที่ 1950 และ 1960 หลังจากกว่าครึ่งศตวรรษของวิวัฒนาการ มันได้ประสบกับการพัฒนาที่เกี่ยวพันกันของคลื่น 3 ระลอกของสัญลักษณ์ การเชื่อมโยง และวิชาพฤติกรรม ในปัจจุบัน ในฐานะเทคโนโลยีทั่วไปที่เกิดขึ้นใหม่ มันกำลังส่งเสริมสังคม การเปลี่ยนแปลงครั้งใหญ่ใน ชีวิตและทุกสาขาอาชีพ คำจำกัดความที่เฉพาะเจาะจงมากขึ้นของ General generative AI ในขั้นตอนนี้คือ Artificial General Intelligence (AGI) ซึ่งเป็นระบบปัญญาประดิษฐ์ที่มีความสามารถในการทำความเข้าใจที่หลากหลายซึ่งสามารถทำงานได้ดีในงานและสาขาต่างๆ ที่หลากหลาย เหมือนมนุษย์หรือปัญญาที่เหนือกว่า . โดยพื้นฐานแล้ว AGI ต้องการองค์ประกอบ 3 ประการ ได้แก่ การเรียนรู้เชิงลึก (DL) ข้อมูลขนาดใหญ่ และพลังการประมวลผลขนาดใหญ่
การเรียนรู้อย่างลึกซึ้ง
การเรียนรู้เชิงลึกเป็นสาขาย่อยของการเรียนรู้ของเครื่อง (ML) และอัลกอริธึมการเรียนรู้เชิงลึกคือโครงข่ายประสาทเทียมที่จำลองมาจากสมองของมนุษย์ ตัวอย่างเช่น สมองของมนุษย์ประกอบด้วยเซลล์ประสาทที่เชื่อมต่อถึงกันหลายล้านเซลล์ซึ่งทำงานร่วมกันเพื่อเรียนรู้และประมวลผลข้อมูล ในทำนองเดียวกัน โครงข่ายประสาทเทียมสำหรับการเรียนรู้เชิงลึก (หรือโครงข่ายประสาทเทียม) ประกอบด้วยเซลล์ประสาทเทียมหลายชั้นที่ทำงานร่วมกันภายในคอมพิวเตอร์ เซลล์ประสาทเทียมเป็นโมดูลซอฟต์แวร์ที่เรียกว่าโหนดซึ่งใช้การคำนวณทางคณิตศาสตร์ในการประมวลผลข้อมูล โครงข่ายประสาทเทียมเป็นอัลกอริธึมการเรียนรู้เชิงลึกที่ใช้โหนดเหล่านี้เพื่อแก้ไขปัญหาที่ซับซ้อน
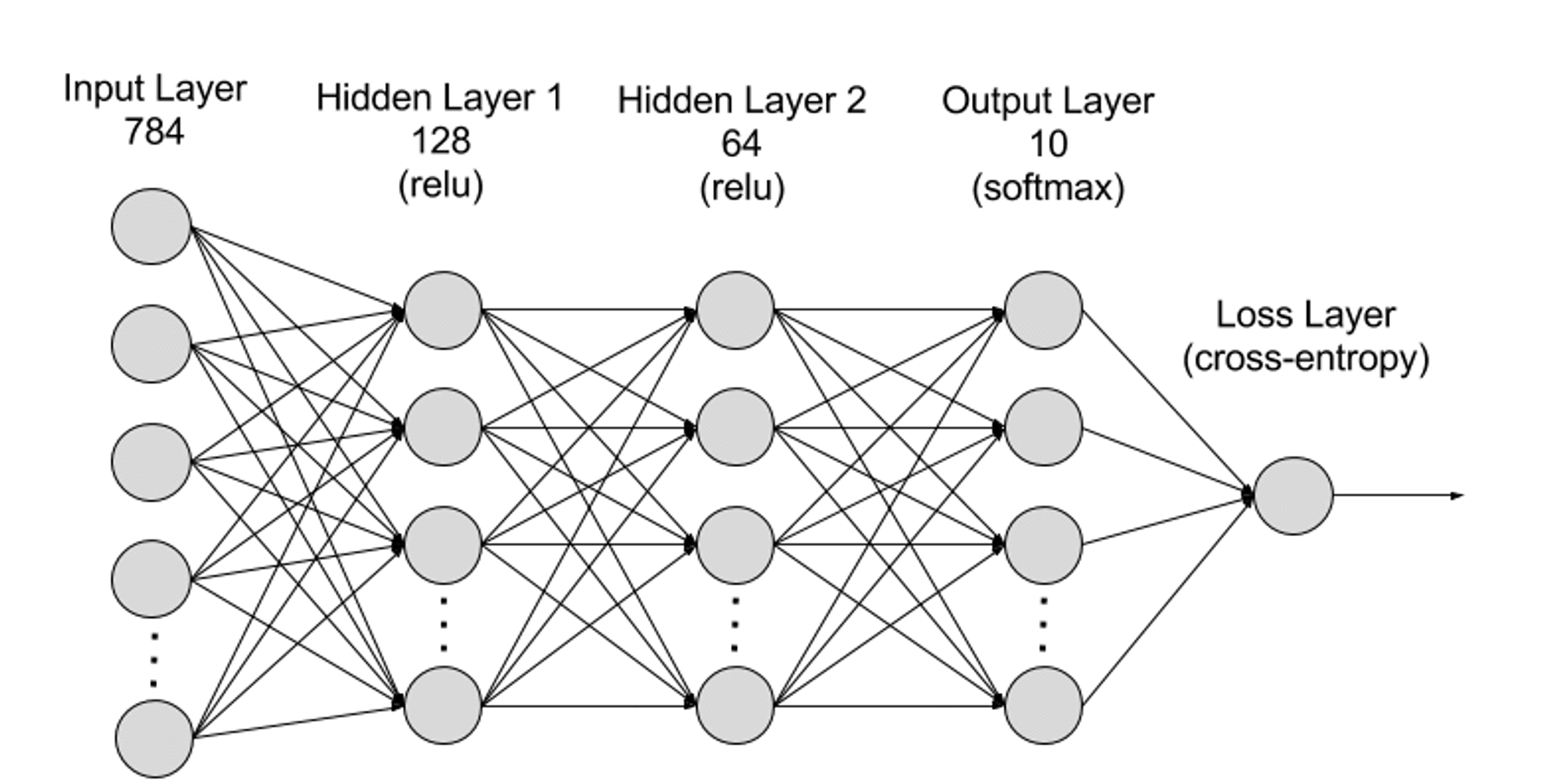
โครงข่ายประสาทเทียมสามารถแบ่งออกเป็นเลเยอร์อินพุต เลเยอร์ที่ซ่อนอยู่ และเลเยอร์เอาท์พุตจากระดับลำดับชั้น และพารามิเตอร์ต่างๆ จะเชื่อมต่อกันระหว่างเลเยอร์ต่างๆ
เลเยอร์อินพุต: เลเยอร์อินพุตเป็นเลเยอร์แรกของโครงข่ายประสาทเทียมและมีหน้าที่รับข้อมูลอินพุตภายนอก เซลล์ประสาทแต่ละอันในเลเยอร์อินพุตสอดคล้องกับคุณลักษณะของข้อมูลอินพุต ตัวอย่างเช่น เมื่อประมวลผลข้อมูลภาพ เซลล์ประสาทแต่ละอันอาจสอดคล้องกับค่าพิกเซลในภาพ
เลเยอร์ที่ซ่อนอยู่: เลเยอร์อินพุตจะประมวลผลข้อมูลและส่งผ่านไปยังเลเยอร์เพิ่มเติมในโครงข่ายประสาทเทียม เลเยอร์ที่ซ่อนอยู่เหล่านี้จะประมวลผลข้อมูลในระดับต่างๆ โดยจะปรับพฤติกรรมเมื่อได้รับข้อมูลใหม่ เครือข่ายการเรียนรู้เชิงลึกมีเลเยอร์ที่ซ่อนอยู่หลายร้อยชั้น และสามารถใช้เพื่อวิเคราะห์ปัญหาจากมุมมองที่แตกต่างกันมากมาย ตัวอย่างเช่น หากคุณได้รับภาพสัตว์ที่ไม่รู้จักซึ่งคุณต้องจำแนกประเภท คุณสามารถเปรียบเทียบกับสัตว์ที่คุณรู้จักอยู่แล้วได้ ตัวอย่างเช่น คุณสามารถบอกได้ว่ามันคือสัตว์ชนิดใดโดยดูจากรูปร่างหู จำนวนขา และขนาดของรูม่านตา เลเยอร์ที่ซ่อนอยู่ในโครงข่ายประสาทเทียมระดับลึกทำงานในลักษณะเดียวกัน หากอัลกอริธึมการเรียนรู้เชิงลึกพยายามจำแนกภาพของสัตว์ แต่ละเลเยอร์ที่ซ่อนอยู่จะประมวลผลลักษณะที่แตกต่างกันของสัตว์และพยายามจำแนกประเภทอย่างถูกต้อง
เลเยอร์เอาต์พุต: เลเยอร์เอาต์พุตเป็นเลเยอร์สุดท้ายของโครงข่ายประสาทเทียมและมีหน้าที่ในการสร้างเอาต์พุตของเครือข่าย เซลล์ประสาทแต่ละอันในเลเยอร์เอาท์พุตแสดงถึงหมวดหมู่หรือค่าเอาท์พุตที่เป็นไปได้ ตัวอย่างเช่น ในปัญหาการจำแนกประเภท เซลล์ประสาทในเลเยอร์เอาท์พุตแต่ละอันอาจสอดคล้องกับหมวดหมู่ ในขณะที่ในปัญหาการถดถอย เลเยอร์เอาท์พุตอาจมีเซลล์ประสาทเพียงเซลล์เดียวที่มีค่าแสดงถึงผลการทำนาย
พารามิเตอร์: ในโครงข่ายประสาทเทียม การเชื่อมต่อระหว่างเลเยอร์ต่างๆ จะแสดงด้วยพารามิเตอร์น้ำหนักและอคติ ซึ่งได้รับการปรับให้เหมาะสมในระหว่างกระบวนการฝึกอบรมเพื่อให้เครือข่ายสามารถระบุรูปแบบในข้อมูลได้อย่างแม่นยำและทำการคาดการณ์ การเพิ่มพารามิเตอร์สามารถปรับปรุงความจุของโมเดลของโครงข่ายประสาทเทียมได้ กล่าวคือ ความสามารถของโมเดลในการเรียนรู้และแสดงรูปแบบที่ซับซ้อนในข้อมูล แต่ในทางกลับกัน การเพิ่มขึ้นของพารามิเตอร์ก็จะเพิ่มความต้องการพลังการประมวลผลมากขึ้น
ข้อมูลใหญ่
เพื่อให้ได้รับการฝึกอบรมอย่างมีประสิทธิภาพ โครงข่ายประสาทเทียมมักต้องการข้อมูลที่หลากหลายและมีคุณภาพสูงจำนวนมากจากหลายแหล่ง เป็นพื้นฐานสำหรับการฝึกโมเดลการเรียนรู้ของเครื่องและการตรวจสอบ ด้วยการวิเคราะห์ข้อมูลขนาดใหญ่ โมเดลการเรียนรู้ของเครื่องสามารถเรียนรู้รูปแบบและความสัมพันธ์ในข้อมูลเพื่อทำการคาดการณ์หรือจำแนกประเภทได้
พลังการประมวลผลขนาดใหญ่
โครงสร้างที่ซับซ้อนหลายชั้นของโครงข่ายประสาทเทียม พารามิเตอร์จำนวนมาก ข้อกำหนดในการประมวลผลข้อมูลขนาดใหญ่ และวิธีการฝึกอบรมแบบวนซ้ำ (ในขั้นตอนการฝึกอบรม แบบจำลองจะต้องวนซ้ำซ้ำ ๆ และต้องมีการเผยแพร่ไปข้างหน้าและย้อนกลับ คำนวณสำหรับแต่ละเลเยอร์ในระหว่างกระบวนการฝึกอบรม รวมถึงการคำนวณฟังก์ชันการเปิดใช้งาน การคำนวณฟังก์ชันการสูญเสีย การคำนวณแบบไล่ระดับ และการอัปเดตน้ำหนัก) ข้อกำหนดการประมวลผลที่มีความแม่นยำสูง ความสามารถในการประมวลผลแบบขนาน เทคนิคการปรับให้เหมาะสมและการทำให้เป็นมาตรฐาน และการประเมินแบบจำลองและกระบวนการตรวจสอบได้ร่วมกันนำ ไปจนถึงความต้องการพลังการประมวลผลสูง ด้วย Deep Learning ด้วยความก้าวหน้าของ AGI ความต้องการพลังการประมวลผลขนาดใหญ่จึงเพิ่มขึ้นประมาณ 10 เท่าทุกปี จนถึงขณะนี้ GPT-4 รุ่นล่าสุดประกอบด้วยพารามิเตอร์ 1.8 ล้านล้านพารามิเตอร์ ค่าใช้จ่ายในการฝึกอบรมครั้งเดียวมากกว่า 60 ล้านดอลลาร์สหรัฐ และพลังการประมวลผลที่ต้องการ 2.15 e 25 FLOPS (การคำนวณจุดลอยตัว 21,500 ล้านล้านจุด) ความต้องการพลังการประมวลผลสำหรับการฝึกโมเดลครั้งต่อไปยังคงเพิ่มขึ้น และมีโมเดลใหม่ๆ เข้ามาด้วย
เศรษฐศาสตร์การคำนวณ AI
ขนาดของตลาดในอนาคต
จากการคำนวณที่เชื่อถือได้มากที่สุด รายงานการประเมินดัชนีพลังงานคอมพิวเตอร์ทั่วโลกปี 2022-2023 ที่รวบรวมโดย IDC (International Data Corporation), Inspur Information และสถาบันวิจัยอุตสาหกรรมทั่วโลกของมหาวิทยาลัย Tsinghua ระบุว่าขนาดตลาดคอมพิวเตอร์ AI ทั่วโลกจะเพิ่มขึ้นจากปี 2022 เป็น พ.ศ. 2565 จาก 19.50 พันล้านดอลลาร์สหรัฐเป็น 34.66 พันล้านดอลลาร์สหรัฐในปี 2569 ตลาดการประมวลผล AI แบบสร้างสรรค์จะเติบโตจาก 820 ล้านดอลลาร์สหรัฐในปี 2565 เป็น 10.99 พันล้านดอลลาร์สหรัฐในปี 2569 การประมวลผล AI แบบเจนเนอเรทีฟจะเติบโตจาก 4.2% เป็น 31.7% ของตลาดการประมวลผล AI โดยรวม
พลังคอมพิวเตอร์ผูกขาดทางเศรษฐกิจ
การผลิต AI GPU ได้รับการผูกขาดโดย NVIDA แต่เพียงผู้เดียวและมีราคาแพงมาก (H 100 ล่าสุดขายได้ในราคา 40,000 เหรียญสหรัฐต่อชิป) และ GPU ถูกแย่งชิงโดยยักษ์ใหญ่ใน Silicon Valley ทันทีที่เปิดตัว และบางส่วนของ อุปกรณ์เหล่านี้ใช้ในผลิตภัณฑ์ของตนเอง การฝึกอบรม โมเดลใหม่ อีกส่วนหนึ่งให้เช่าแก่นักพัฒนา AI ผ่านแพลตฟอร์มคลาวด์ แพลตฟอร์มการประมวลผลบนคลาวด์ เช่น Google, Amazon และ Microsoft มีทรัพยากรการประมวลผลจำนวนมาก เช่น เซิร์ฟเวอร์, GPU และ TPU พลังการประมวลผลกลายเป็นทรัพยากรใหม่ที่ถูกผูกขาดโดยยักษ์ใหญ่ นักพัฒนาที่เกี่ยวข้องกับ AI จำนวนมากไม่สามารถซื้อ GPU เฉพาะได้โดยไม่ขึ้นราคา ในการใช้อุปกรณ์ใหม่ล่าสุด นักพัฒนาจะต้องเช่าเซิร์ฟเวอร์คลาวด์ AWS หรือ Microsoft จากรายงานทางการเงิน ธุรกิจนี้มีกำไรสูงมาก บริการคลาวด์ของ AWS มีอัตรากำไรขั้นต้น 61% ในขณะที่อัตรากำไรขั้นต้นของ Microsoft ยังสูงกว่าที่ 72%

เราต้องยอมรับอำนาจและการควบคุมแบบรวมศูนย์นี้ และจ่ายค่าธรรมเนียมกำไร 72% สำหรับทรัพยากรคอมพิวเตอร์หรือไม่? ยักษ์ใหญ่ที่ผูกขาด Web2 จะยังคงผูกขาดในยุคหน้าหรือไม่?
ปัญหาของพลังการประมวลผล AGI แบบกระจายอำนาจ
เมื่อพูดถึงเรื่องการต่อต้านการผูกขาด การกระจายอำนาจ มักจะเป็นทางออกที่ดีที่สุด เมื่อพิจารณาจากโครงการที่มีอยู่ เราสามารถบรรลุพลังการประมวลผลขนาดใหญ่ที่จำเป็นสำหรับ AI ผ่านโครงการจัดเก็บข้อมูลใน DePIN รวมถึงโปรโตคอลการใช้งาน GPU ที่ไม่ได้ใช้งาน เช่น RDNR ได้หรือไม่ คำตอบคือไม่ เส้นทางสู่การสังหารมังกรไม่ใช่เรื่องง่าย โครงการแรกๆ ไม่ได้ออกแบบมาโดยเฉพาะสำหรับพลังการประมวลผล AGI และไม่สามารถทำได้ อย่างน้อยห้าความท้าทายต่อไปนี้จะต้องเผชิญเพื่อเพิ่มพลังการประมวลผลให้กับห่วงโซ่:
1. การตรวจสอบการทำงาน: เพื่อสร้างเครือข่ายคอมพิวเตอร์ที่ไร้ความน่าเชื่อถืออย่างแท้จริง และมอบสิ่งจูงใจทางเศรษฐกิจแก่ผู้เข้าร่วม เครือข่ายจะต้องมีวิธีการตรวจสอบว่ามีการดำเนินงานด้านคอมพิวเตอร์การเรียนรู้เชิงลึกจริงหรือไม่ แก่นของปัญหานี้คือการพึ่งพาสถานะของโมเดลการเรียนรู้เชิงลึก ในแบบจำลองการเรียนรู้เชิงลึก ข้อมูลเข้าของแต่ละเลเยอร์จะขึ้นอยู่กับผลลัพธ์ของเลเยอร์ก่อนหน้า ซึ่งหมายความว่าคุณไม่สามารถตรวจสอบเลเยอร์บางเลเยอร์ในโมเดลได้โดยไม่ต้องคำนึงถึงเลเยอร์ทั้งหมดก่อนหน้าเลเยอร์นั้นด้วย การคำนวณแต่ละเลเยอร์ขึ้นอยู่กับผลลัพธ์ของเลเยอร์ก่อนหน้าทั้งหมด ดังนั้น เพื่อตรวจสอบงานที่ทำ ณ จุดใดจุดหนึ่ง (เช่น เลเยอร์เฉพาะ) จะต้องดำเนินการงานทั้งหมดตั้งแต่จุดเริ่มต้นของแบบจำลองจนถึงจุดเฉพาะนั้น
2. ตลาด: ในฐานะตลาดเกิดใหม่ตลาดพลังงานคอมพิวเตอร์ AI ต้องเผชิญกับปัญหาอุปสงค์และอุปทานเช่นปัญหาการสตาร์ทเย็นสภาพคล่องของอุปสงค์และอุปทานจำเป็นต้องจับคู่กันคร่าวๆตั้งแต่เริ่มต้นเพื่อให้ตลาดเติบโตได้สำเร็จ . เพื่อดึงดูดศักยภาพของพลังการประมวลผล ผู้เข้าร่วมจะต้องได้รับสิ่งจูงใจที่ชัดเจนเพื่อแลกกับทรัพยากรพลังงานการประมวลผลของพวกเขา ตลาดต้องการกลไกในการติดตามงานด้านคอมพิวเตอร์ที่เสร็จสมบูรณ์และชำระเงินให้ผู้ให้บริการตามนั้นในเวลาที่เหมาะสม ในตลาดแบบดั้งเดิม ตัวกลางจะจัดการงานต่างๆ เช่น การจัดการและการเริ่มต้นใช้งาน ในขณะที่ลดต้นทุนการดำเนินงานโดยการกำหนดจำนวนเงินการชำระเงินขั้นต่ำ อย่างไรก็ตาม วิธีการนี้จะมีค่าใช้จ่ายสูงกว่าเมื่อขยายขนาดตลาด อุปทานเพียงส่วนเล็กๆ เท่านั้นที่สามารถกักเก็บได้อย่างมีประสิทธิภาพในเชิงเศรษฐกิจ ซึ่งนำไปสู่สภาวะสมดุลที่ตลาดสามารถกักเก็บและรักษาอุปทานที่มีจำกัดไว้เท่านั้น โดยไม่สามารถเติบโตต่อไปได้
3. ปัญหาการหยุดชะงัก: ปัญหาการหยุดชะงักเป็นปัญหาพื้นฐานในทฤษฎีการคำนวณ ซึ่งเกี่ยวข้องกับการพิจารณาว่างานการคำนวณที่กำหนดจะเสร็จสิ้นภายในระยะเวลาที่จำกัดหรือไม่เคยหยุดนิ่ง ปัญหานี้ไม่สามารถแก้ไขได้ ซึ่งหมายความว่าไม่มีอัลกอริธึมสากลที่สามารถคาดการณ์สำหรับงานประมวลผลทั้งหมดได้ว่างานเหล่านั้นจะหยุดภายในระยะเวลาอันจำกัดหรือไม่ ตัวอย่างเช่น การดำเนินการตามสัญญาอัจฉริยะบน Ethereum ก็ประสบปัญหาการหยุดทำงานที่คล้ายกันเช่นกัน นั่นคือ เป็นไปไม่ได้ที่จะระบุล่วงหน้าว่าต้องใช้ทรัพยากรการประมวลผลจำนวนเท่าใดในการดำเนินการตามสัญญาอัจฉริยะ หรือจะเสร็จสิ้นภายในระยะเวลาที่เหมาะสมหรือไม่
(ในบริบทของการเรียนรู้เชิงลึก ปัญหานี้จะซับซ้อนมากขึ้น เนื่องจากโมเดลและเฟรมเวิร์กจะเปลี่ยนจากการสร้างกราฟแบบคงที่ไปเป็นการสร้างและการดำเนินการแบบไดนามิก)
4. ความเป็นส่วนตัว: การออกแบบและการพัฒนาที่คำนึงถึงความเป็นส่วนตัวเป็นสิ่งจำเป็นสำหรับฝ่ายโครงการ แม้ว่าการวิจัยแมชชีนเลิร์นนิงจำนวนมากสามารถดำเนินการกับชุดข้อมูลสาธารณะได้ แต่เพื่อปรับปรุงประสิทธิภาพของโมเดลและปรับให้เข้ากับแอปพลิเคชันเฉพาะ โดยทั่วไปโมเดลจะต้องได้รับการปรับแต่งอย่างละเอียดจากข้อมูลผู้ใช้ที่เป็นกรรมสิทธิ์ กระบวนการปรับแต่งอย่างละเอียดนี้อาจเกี่ยวข้องกับการประมวลผลข้อมูลส่วนบุคคล ดังนั้นจึงจำเป็นต้องพิจารณาข้อกำหนดการคุ้มครองความเป็นส่วนตัว
5. การทำงานแบบขนาน: นี่เป็นปัจจัยสำคัญที่ทำให้โครงการปัจจุบันไม่สามารถทำได้ โดยปกติแล้ว โมเดลการเรียนรู้เชิงลึกจะได้รับการฝึกแบบขนานบนคลัสเตอร์ฮาร์ดแวร์ขนาดใหญ่ที่มีสถาปัตยกรรมที่เป็นเอกสิทธิ์และเวลาแฝงที่ต่ำมาก และ GPU ในเครือข่ายคอมพิวเตอร์แบบกระจายจะต้องมีการแลกเปลี่ยนข้อมูลบ่อยครั้ง เวลาแฝงและจะถูกจำกัดโดย GPU ประสิทธิภาพต่ำสุด เมื่อแหล่งพลังงานการประมวลผลไม่น่าเชื่อถือและไม่น่าเชื่อถือ วิธีการบรรลุ Parallelization แบบต่างกันเป็นปัญหาที่ต้องแก้ไข วิธีที่เป็นไปได้ในปัจจุบันคือการบรรลุการขนานผ่าน Transformer Model เช่น Switch Transformers ซึ่งปัจจุบันมีลักษณะแบบขนานสูง
วิธีแก้ปัญหา: แม้ว่าความพยายามในปัจจุบันในการกระจายอำนาจของตลาดพลังงานการประมวลผล AGI ยังอยู่ในช่วงเริ่มต้น แต่มีโครงการสองโครงการที่เริ่มแรกได้แก้ไขการออกแบบฉันทามติของเครือข่ายการกระจายอำนาจ และการใช้งานเครือข่ายพลังงานการประมวลผลแบบกระจายอำนาจในการฝึกอบรมแบบจำลองและการอนุมาน . กระบวนการ ต่อไปนี้จะใช้ Gensyn และ Together เป็นตัวอย่างในการวิเคราะห์วิธีการออกแบบและปัญหาของตลาดพลังงานการประมวลผล AGI แบบกระจายอำนาจ
Gensyn

Gensyn คือตลาดพลังการประมวลผล AGI ที่ยังอยู่ในขั้นตอนการก่อสร้าง และมีเป้าหมายเพื่อแก้ปัญหาความท้าทายต่างๆ ของการประมวลผลการเรียนรู้เชิงลึกแบบกระจายอำนาจ และลดต้นทุนในปัจจุบันของการเรียนรู้เชิงลึก Gensyn นั้นเป็นโปรโตคอล Proof-of-Stake ชั้นแรกที่ใช้เครือข่าย Polkadot ซึ่งให้รางวัลแก่นักแก้ปัญหาโดยตรง (Solver) ผ่านสัญญาอัจฉริยะเพื่อแลกกับอุปกรณ์ GPU ที่ไม่ได้ใช้งานสำหรับการประมวลผลและการปฏิบัติงานการเรียนรู้ของเครื่อง
กลับมาที่คำถามข้างต้น หัวใจสำคัญของการสร้างเครือข่ายคอมพิวเตอร์ที่ไม่น่าเชื่อถืออย่างแท้จริงอยู่ที่การตรวจสอบยืนยันงานการเรียนรู้ของเครื่องที่เสร็จสมบูรณ์ นี่เป็นปัญหาที่ซับซ้อนมากซึ่งจำเป็นต้องค้นหาสมดุลระหว่างจุดตัดของทฤษฎีความซับซ้อน ทฤษฎีเกม การเข้ารหัส และการเพิ่มประสิทธิภาพ
Gensyn เสนอโซลูชันง่ายๆ สำหรับนักแก้ปัญหาเพื่อส่งผลลัพธ์ของงานการเรียนรู้ของเครื่องที่พวกเขาทำเสร็จแล้ว เพื่อตรวจสอบว่าผลลัพธ์เหล่านี้ถูกต้อง ผู้ตรวจสอบอิสระอีกรายหนึ่งจะพยายามดำเนินการงานเดิมอีกครั้ง วิธีการนี้สามารถเรียกว่าการจำลองแบบเดี่ยวได้เนื่องจากมีตัวตรวจสอบความถูกต้องเพียงตัวเดียวเท่านั้นที่ดำเนินการซ้ำ ซึ่งหมายความว่ามีเพียงความพยายามเพิ่มเติมเพียงครั้งเดียวในการตรวจสอบความถูกต้องของงานต้นฉบับ อย่างไรก็ตาม หากบุคคลที่ตรวจสอบความถูกต้องของงานไม่ใช่ผู้ร้องของานต้นฉบับ ปัญหาด้านความน่าเชื่อถือก็ยังคงอยู่ เพราะผู้ตรวจสอบเองอาจจะไม่ซื่อสัตย์และงานของพวกเขาก็ต้องได้รับการตรวจสอบ สิ่งนี้นำไปสู่ปัญหาที่อาจเกิดขึ้นหากบุคคลที่ตรวจสอบงานไม่ใช่ผู้ร้องของานต้นฉบับ ก็จำเป็นต้องมีผู้ตรวจสอบอีกคนเพื่อตรวจสอบงานของพวกเขา แต่ก็อาจเป็นไปได้ด้วยว่าเครื่องมือตรวจสอบใหม่นี้ไม่น่าเชื่อถือ ดังนั้นจึงจำเป็นต้องมีเครื่องมือตรวจสอบอื่นเพื่อตรวจสอบงานของพวกเขา ซึ่งอาจดำเนินต่อไปตลอดไป โดยสร้างห่วงโซ่การจำลองแบบไม่มีที่สิ้นสุด ที่นี่เราจำเป็นต้องแนะนำแนวคิดหลักสามประการและผสมผสานเข้าด้วยกันเพื่อสร้างระบบผู้เข้าร่วมที่มีบทบาทสี่ประการในการแก้ปัญหาลูกโซ่ที่ไม่มีที่สิ้นสุด
ข้อพิสูจน์การเรียนรู้ความน่าจะเป็น: ใช้ข้อมูลเมตาของกระบวนการปรับให้เหมาะสมตามการไล่ระดับสีเพื่อสร้างใบรับรองของงานที่ทำเสร็จแล้ว ด้วยการจำลองขั้นตอนบางอย่าง ใบรับรองเหล่านี้จึงสามารถตรวจสอบได้อย่างรวดเร็วเพื่อให้แน่ใจว่างานเสร็จสมบูรณ์ตามที่คาดไว้
โปรโตคอลการแปลที่แม่นยำตามกราฟ: การใช้โปรโตคอลการแปลที่แม่นยำหลายระดับตามกราฟ และการดำเนินการของผู้ประเมินข้ามที่สอดคล้องกัน ซึ่งช่วยให้สามารถรันและเปรียบเทียบการตรวจสอบความถูกต้องอีกครั้งเพื่อให้มั่นใจถึงความสอดคล้องและได้รับการยืนยันจากบล็อกเชนในท้ายที่สุด
เกมสิ่งจูงใจสไตล์ Truebit: ใช้การปักหลักและฟันอย่างเจ็บแสบเพื่อสร้างเกมสิ่งจูงใจที่รับรองว่าผู้เข้าร่วมที่สมเหตุสมผลทางการเงินทุกคนจะกระทำการอย่างซื่อสัตย์และปฏิบัติงานตามที่ตั้งใจไว้
ระบบผู้เข้าร่วมประกอบด้วยผู้ส่ง ผู้แก้ปัญหา ผู้ตรวจสอบ และผู้รายงาน
ผู้ส่ง:
ผู้ส่งคือผู้ใช้ระบบที่จัดเตรียมงานที่จะคำนวณและชำระค่าหน่วยงานที่เสร็จสมบูรณ์
นักแก้ปัญหา:
โปรแกรมแก้ปัญหาคือผู้ปฏิบัติงานหลักของระบบ ดำเนินการฝึกอบรมโมเดลและสร้างการพิสูจน์ที่ได้รับการตรวจสอบโดยผู้ตรวจสอบ
ผู้ตรวจสอบ:
เครื่องมือตรวจสอบเป็นกุญแจสำคัญในการเชื่อมโยงกระบวนการฝึกอบรมที่ไม่ได้กำหนดไว้กับการคำนวณเชิงเส้นที่กำหนด โดยจำลองส่วนหนึ่งของการพิสูจน์ของนักแก้ปัญหา และเปรียบเทียบระยะทางกับเกณฑ์ที่คาดหวัง
ผู้แจ้งเบาะแส:
ผู้แจ้งเบาะแสเป็นแนวป้องกันสุดท้าย ตรวจสอบการทำงานของผู้ตรวจสอบความถูกต้อง และออกความท้าทายโดยหวังว่าจะได้รับเงินรางวัลมากมาย
การทำงานของระบบ
การทำงานของระบบเกมที่ออกแบบโดยโปรโตคอลจะประกอบด้วยแปดขั้นตอน ครอบคลุมบทบาทผู้เข้าร่วมหลักสี่บทบาท เพื่อให้กระบวนการทั้งหมดเสร็จสมบูรณ์ตั้งแต่การส่งงานไปจนถึงการตรวจสอบขั้นสุดท้าย
1. การส่งงาน: งานประกอบด้วยข้อมูลเฉพาะสามส่วน:
ข้อมูลเมตาที่อธิบายงานและไฮเปอร์พารามิเตอร์
ไบนารี่โมเดล (หรือสคีมาฐาน);
ข้อมูลการฝึกอบรมที่เข้าถึงได้แบบสาธารณะและประมวลผลล่วงหน้า
2. ในการส่งงาน ผู้ส่งจะระบุรายละเอียดของงานในรูปแบบที่เครื่องอ่านได้ และส่งไปยังห่วงโซ่พร้อมกับโมเดลไบนารี (หรือสคีมาที่เครื่องอ่านได้) และตำแหน่งที่สาธารณะเข้าถึงได้ของข้อมูลการฝึกอบรมที่ประมวลผลล่วงหน้า ข้อมูลสาธารณะสามารถจัดเก็บไว้ในพื้นที่จัดเก็บอ็อบเจ็กต์ธรรมดา เช่น AWS S3 หรือในพื้นที่จัดเก็บแบบกระจายอำนาจ เช่น IPFS, Arweave หรือ Subspace
3. การทำโปรไฟล์: กระบวนการจัดทำโปรไฟล์จะกำหนดเกณฑ์ระยะทางพื้นฐานสำหรับการพิสูจน์การยืนยันการเรียนรู้ เครื่องมือตรวจสอบจะรวบรวมข้อมูลงานการวิเคราะห์เป็นระยะ และสร้างเกณฑ์การเปลี่ยนแปลงสำหรับการเปรียบเทียบหลักฐานการเรียนรู้ ในการสร้างเกณฑ์ ผู้ตรวจสอบจะดำเนินการตามกำหนดและรันซ้ำส่วนหนึ่งของการฝึกอบรม โดยใช้เมล็ดสุ่มที่แตกต่างกัน และสร้างและตรวจสอบการพิสูจน์ของตัวเอง ในระหว่างกระบวนการนี้ ผู้ตรวจสอบจะกำหนดเกณฑ์ระยะทางที่คาดหวังโดยรวมสำหรับงานที่ไม่ได้กำหนดไว้ซึ่งสามารถใช้เป็นโซลูชันในการตรวจสอบได้
4. การฝึกอบรม: หลังจากการวิเคราะห์ งานจะเข้าสู่กลุ่มงานสาธารณะ (คล้ายกับ Mempool ของ Ethereum) เลือกโปรแกรมแก้ปัญหาเพื่อดำเนินงานและลบงานออกจากกลุ่มงาน โปรแกรมแก้ปัญหาดำเนินงานตามข้อมูลเมตาที่ส่งโดยผู้ส่ง รวมถึงแบบจำลองและข้อมูลการฝึกอบรมที่ให้ไว้ เมื่อปฏิบัติงานการฝึกอบรม โปรแกรมแก้ปัญหายังสร้างหลักฐานการเรียนรู้ด้วยการตรวจสอบและจัดเก็บข้อมูลเมตาจากกระบวนการฝึกอบรมเป็นระยะ รวมถึงพารามิเตอร์ เพื่อให้ผู้ตรวจสอบจำลองขั้นตอนการเพิ่มประสิทธิภาพต่อไปนี้อย่างถูกต้องที่สุด
5. การสร้างหลักฐาน: โปรแกรมแก้ปัญหาจะจัดเก็บน้ำหนักของแบบจำลองหรือการอัปเดตเป็นระยะๆ และดัชนีที่เกี่ยวข้องกับชุดข้อมูลการฝึกเพื่อระบุตัวอย่างที่ใช้ในการสร้างการอัปเดตน้ำหนัก ความถี่ของจุดตรวจสอบสามารถปรับได้เพื่อให้การรับประกันแข็งแกร่งขึ้นหรือเพื่อประหยัดพื้นที่จัดเก็บ การพิสูจน์สามารถ ซ้อนกัน ได้ ซึ่งหมายความว่าการพิสูจน์สามารถเริ่มต้นจากการแจกแจงแบบสุ่มที่ใช้ในการเริ่มต้นตุ้มน้ำหนัก หรือจากตุ้มน้ำหนักที่ได้รับการฝึกล่วงหน้าซึ่งสร้างขึ้นโดยใช้การพิสูจน์ของตัวเอง ซึ่งช่วยให้โปรโตคอลสามารถสร้างชุดโมเดลพื้นฐานที่ได้รับการฝึกอบรมล่วงหน้าที่ได้รับการพิสูจน์แล้ว (เช่น โมเดลพื้นฐาน) ซึ่งสามารถปรับแต่งอย่างละเอียดสำหรับงานที่เฉพาะเจาะจงมากขึ้นได้
6. การตรวจสอบหลักฐาน: หลังจากงานเสร็จสิ้น นักแก้ปัญหาจะลงทะเบียนงานเสร็จสิ้นด้วยห่วงโซ่ และแสดงหลักฐานการเรียนรู้ในตำแหน่งที่สาธารณะสามารถเข้าถึงได้เพื่อให้ผู้ตรวจสอบเข้าถึงได้ ตัวตรวจสอบจะดึงงานการตรวจสอบจากกลุ่มงานสาธารณะ และดำเนินการคำนวณเพื่อดำเนินการส่วนต่าง ๆ ของการพิสูจน์อีกครั้ง และดำเนินการคำนวณระยะทาง จากนั้นระยะทางที่ได้จะถูกนำมาใช้โดยห่วงโซ่ (พร้อมกับเกณฑ์ที่คำนวณระหว่างขั้นตอนการวิเคราะห์) เพื่อพิจารณาว่าการตรวจสอบตรงกับการพิสูจน์หรือไม่
7. ความท้าทายในการระบุตำแหน่งตามกราฟ: หลังจากตรวจสอบหลักฐานการเรียนรู้แล้ว ผู้แจ้งเบาะแสสามารถคัดลอกงานของผู้ตรวจสอบเพื่อตรวจสอบว่างานตรวจสอบนั้นดำเนินการอย่างถูกต้องหรือไม่ หากผู้แจ้งเบาะแสเชื่อว่าการตรวจสอบความถูกต้องได้ดำเนินการไม่ถูกต้อง (ไม่ว่าจะเป็นอันตรายหรือไม่ก็ตาม) พวกเขาสามารถท้าทายให้ทำสัญญาอนุญาโตตุลาการเพื่อรับรางวัลได้ รางวัลนี้อาจมาจากเงินฝากของ Solver และ Validator (ในกรณีที่ผลบวกจริง) หรือจากเงินรางวัลรวมของลอตเตอรี่ (ในกรณีผลบวกลวง) โดยอนุญาโตตุลาการจะดำเนินการโดยใช้ห่วงโซ่นั้นเอง ผู้แจ้งเบาะแส (ในกรณีของพวกเขาคือผู้ตรวจสอบ) จะตรวจสอบและท้าทายการทำงานในภายหลังเฉพาะในกรณีที่พวกเขาคาดหวังที่จะได้รับค่าตอบแทนที่เหมาะสม ในทางปฏิบัติ หมายความว่าผู้แจ้งเบาะแสถูกคาดหวังให้เข้าร่วมและออกจากเครือข่ายตามจำนวนผู้แจ้งเบาะแสอื่นๆ ที่ยังดำเนินการอยู่ (เช่น ด้วยเงินฝากจริงและการท้าทาย) ดังนั้น กลยุทธ์เริ่มต้นที่คาดหวังไว้สำหรับผู้แจ้งเบาะแสคือการเข้าร่วมเครือข่ายเมื่อจำนวนผู้แจ้งเบาะแสรายอื่นมีน้อย ฝากเงิน สุ่มเลือกงานที่ดำเนินการอยู่ และเริ่มกระบวนการตรวจสอบ หลังจากงานแรกสิ้นสุดลง พวกเขาจะคว้างานที่กำลังดำเนินการแบบสุ่มอีกงานหนึ่งและทำซ้ำจนกว่าจำนวนผู้แจ้งเบาะแสจะเกินเกณฑ์การจ่ายเงินที่กำหนด จากนั้นพวกเขาจะออกจากเครือข่าย (หรือมีแนวโน้มมากกว่าที่จะเปลี่ยนไปใช้เครือข่ายโดยขึ้นอยู่กับความสามารถของฮาร์ดแวร์ที่จะดำเนินการอื่น บทบาท - ผู้ตรวจสอบหรือตัวแก้ปัญหา) จนกว่าสถานการณ์จะกลับรายการอีกครั้ง
8. การอนุญาโตตุลาการตามสัญญา: เมื่อผู้ตรวจสอบความถูกต้องถูกท้าทายโดยผู้แจ้งเบาะแส พวกเขาจะเข้าสู่กระบวนการกับห่วงโซ่เพื่อค้นหาตำแหน่งของการดำเนินการหรืออินพุตที่ถูกโต้แย้ง และในที่สุดห่วงโซ่จะดำเนินการดำเนินการขั้นพื้นฐานขั้นสุดท้ายและพิจารณาว่าความท้าทายนั้นเกิดขึ้นหรือไม่ มีเหตุผล. เพื่อให้ผู้แจ้งเบาะแสมีความซื่อสัตย์และเพื่อเอาชนะภาวะที่กลืนไม่เข้าคายไม่ออกของผู้ตรวจสอบ จึงขอนำเสนอข้อผิดพลาดที่บังคับเป็นระยะและการจ่ายแจ็คพอตที่นี่
9. การชำระบัญชี: ในระหว่างกระบวนการชำระบัญชี ผู้เข้าร่วมจะได้รับเงินตามข้อสรุปของการตรวจสอบความน่าจะเป็นและความเชื่อมั่น สถานการณ์ที่แตกต่างกันจะมีการชำระเงินที่แตกต่างกันโดยขึ้นอยู่กับผลลัพธ์ของการตรวจสอบและความท้าทายครั้งก่อน หากถือว่างานได้รับการดำเนินการอย่างถูกต้องและผ่านการตรวจสอบทั้งหมดแล้ว ผู้ให้บริการโซลูชันและผู้ตรวจสอบจะได้รับรางวัลตามการดำเนินการที่ดำเนินการ
การทบทวนโครงการโดยย่อ
Gensyn ได้ออกแบบระบบเกมที่ยอดเยี่ยมบนชั้นการตรวจสอบและชั้นแรงจูงใจ การค้นหาจุดแตกต่างในเครือข่ายทำให้สามารถค้นหาข้อผิดพลาดได้อย่างรวดเร็ว แต่ยังมีรายละเอียดอีกมากมายที่ขาดหายไปในระบบปัจจุบัน เช่น จะตั้งค่าพารามิเตอร์อย่างไรเพื่อให้แน่ใจว่ารางวัลและการลงโทษสมเหตุสมผลโดยไม่ตั้งเกณฑ์สูงเกินไป คุณได้พิจารณาถึงสถานการณ์ที่รุนแรงและพลังการประมวลผลที่แตกต่างกันของนักแก้ปัญหาในเกมหรือไม่? ไม่มีคำอธิบายโดยละเอียดเกี่ยวกับการทำงานแบบขนานที่แตกต่างกันในเอกสารไวท์เปเปอร์เวอร์ชันปัจจุบัน ในปัจจุบัน Gensyn ยังคงมีหนทางอีกยาวไกล
Together.ai
Together เป็นบริษัทโอเพ่นซอร์สที่มุ่งเน้นไปที่โมเดลขนาดใหญ่และมุ่งมั่นที่จะกระจายอำนาจโซลูชันพลังการประมวลผล AI เราหวังว่าทุกคนจากทุกที่จะสามารถเข้าถึงและใช้ AI ได้ พูดอย่างเคร่งครัด Together ไม่ใช่โครงการบล็อคเชน แต่โครงการได้แก้ไขปัญหาความล่าช้าในเครือข่ายคอมพิวเตอร์ AGI แบบกระจายอำนาจในขั้นต้น ดังนั้น บทความต่อไปนี้จะวิเคราะห์โซลูชันของ Together เท่านั้น และไม่ได้ประเมินโครงการ
จะบรรลุการฝึกอบรมและการอนุมานโมเดลขนาดใหญ่ได้อย่างไร ในเมื่อเครือข่ายแบบกระจายอำนาจช้ากว่าศูนย์ข้อมูล 100 เท่า
ลองจินตนาการดูว่าการกระจายอุปกรณ์ GPU ที่เข้าร่วมในเครือข่ายจะเป็นอย่างไรในสถานการณ์ที่มีการกระจายอำนาจ อุปกรณ์เหล่านี้จะกระจายอยู่ในทวีปและเมืองต่างๆ และอุปกรณ์จะต้องเชื่อมต่อ และเวลาแฝงและแบนด์วิดธ์ของการเชื่อมต่อจะแตกต่างกันไป ดังแสดงในรูปด้านล่าง สถานการณ์แบบกระจายจะถูกจำลอง อุปกรณ์ต่างๆ มีการกระจายในอเมริกาเหนือ ยุโรป และเอเชีย และแบนด์วิธและดีเลย์ระหว่างอุปกรณ์ต่างกัน แล้วจะเชื่อมต่อเป็นอนุกรมต้องทำอย่างไร?
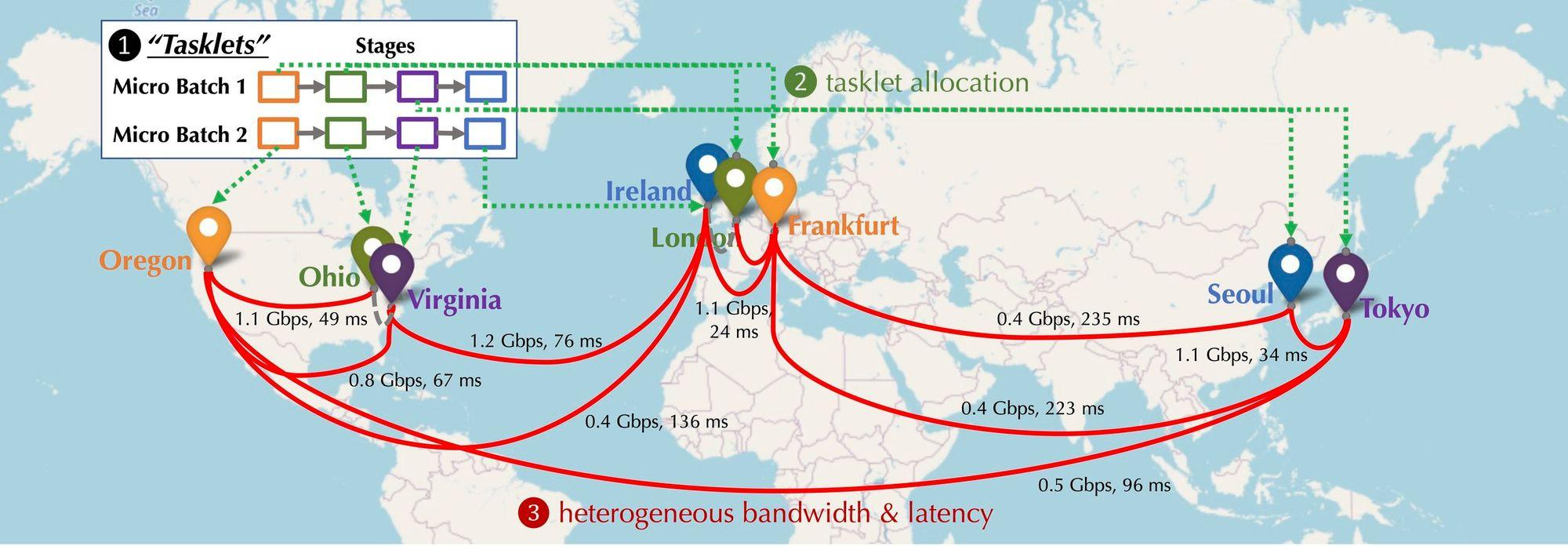
การสร้างแบบจำลองการคำนวณการฝึกอบรมแบบกระจาย:รูปด้านล่างแสดงการฝึกโมเดลพื้นฐานบนอุปกรณ์หลายเครื่อง จากมุมมองประเภทการสื่อสาร มีการสื่อสาร 3 ประเภท ได้แก่ การเปิดใช้งานไปข้างหน้า (การเปิดใช้งานไปข้างหน้า) การไล่ระดับสีย้อนกลับ (การไล่ระดับสีย้อนกลับ) และการสื่อสารในแนวนอน
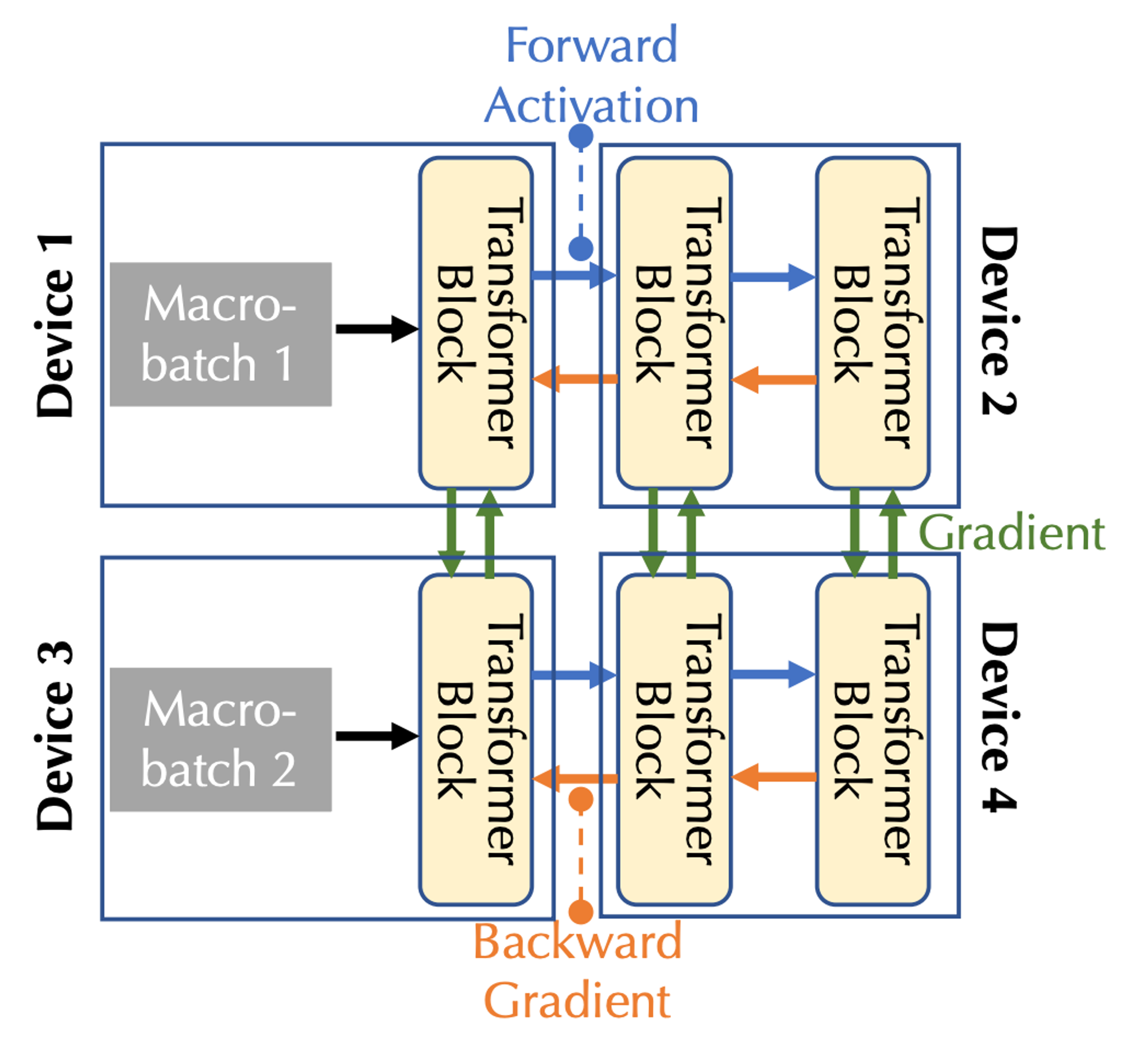
เมื่อรวมแบนด์วิธการสื่อสารและความหน่วงเข้าด้วยกัน จำเป็นต้องพิจารณาความขนานสองรูปแบบ: ความขนานของไปป์ไลน์และความขนานของข้อมูล ซึ่งสอดคล้องกับการสื่อสารสามประเภทในกรณีที่มีอุปกรณ์หลายเครื่อง:
ในไปป์ไลน์ขนานกัน ทุกเลเยอร์ของโมเดลจะถูกแบ่งออกเป็นสเตจ โดยแต่ละอุปกรณ์จะประมวลผลหนึ่งสเตจ ซึ่งเป็นลำดับชั้นที่ต่อเนื่องกัน เช่น บล็อก Transformer หลายบล็อก ในการส่งต่อ การเปิดใช้งานจะถูกส่งผ่านไปยังสเตจถัดไป ในขณะที่การย้อนกลับ ผ่าน การไล่ระดับการเปิดใช้งานจะถูกส่งผ่านไปยังขั้นตอนก่อนหน้า
ในระบบการทำงานคู่ขนานของข้อมูล อุปกรณ์จะคำนวณการไล่ระดับสีสำหรับไมโครแบทช์ต่างๆ อย่างอิสระ แต่ต้องมีการสื่อสารเพื่อซิงโครไนซ์การไล่ระดับสีเหล่านี้
การเพิ่มประสิทธิภาพการกำหนดเวลา:
ในสภาพแวดล้อมที่มีการกระจายอำนาจ กระบวนการฝึกอบรมมักมีข้อจำกัดด้านการสื่อสาร โดยทั่วไปอัลกอริธึมการจัดกำหนดการจะมอบหมายงานที่ต้องใช้การสื่อสารจำนวนมากไปยังอุปกรณ์ที่มีการเชื่อมต่อที่เร็วกว่า เมื่อพิจารณาถึงการพึ่งพาระหว่างงานและความหลากหลายของเครือข่าย ต้นทุนของกลยุทธ์การจัดกำหนดการเฉพาะจะต้องได้รับการสร้างแบบจำลองก่อน เพื่อจับต้นทุนการสื่อสารที่ซับซ้อนของการฝึกอบรมโมเดลพื้นฐาน ร่วมกันเสนอสูตรใหม่และแบ่งโมเดลต้นทุนออกเป็นสองระดับผ่านทฤษฎีกราฟ:
ทฤษฎีกราฟเป็นสาขาหนึ่งของคณิตศาสตร์ที่ศึกษาคุณสมบัติและโครงสร้างของกราฟ (เครือข่าย) เป็นหลัก กราฟประกอบด้วยจุดยอด (โหนด) และขอบ (เส้นที่เชื่อมต่อโหนด) วัตถุประสงค์หลักของทฤษฎีกราฟคือเพื่อศึกษาคุณสมบัติต่างๆ ของกราฟ เช่น ความเชื่อมโยงของกราฟ สีของกราฟ และคุณสมบัติของเส้นทางและวงจรในกราฟ
ระดับแรกคือการแบ่งพาร์ติชันกราฟที่สมดุล (การแบ่งชุดของจุดยอดของกราฟออกเป็นชุดย่อยที่มีขนาดเท่ากันหลายชุดหรือโดยประมาณ ในขณะเดียวกันก็ลดจำนวนขอบระหว่างชุดย่อย ในการแบ่งพาร์ติชันนี้ แต่ละชุดย่อยจะแสดงถึงพาร์ติชัน และลดต้นทุนการสื่อสาร โดยการลดขอบระหว่างพาร์ติชัน) ปัญหาซึ่งสอดคล้องกับต้นทุนการสื่อสารของข้อมูลแบบขนาน
ระดับที่สองคือปัญหาการจับคู่กราฟร่วมและปัญหาพนักงานขายเดินทาง (การจับคู่กราฟร่วมและปัญหาพนักงานขายเดินทางเป็นปัญหาการหาค่าเหมาะที่สุดแบบผสมผสานที่รวมองค์ประกอบของปัญหาการจับคู่กราฟและปัญหาพนักงานขายเดินทาง ปัญหาการจับคู่กราฟคือการหาการจับคู่ในกราฟในลักษณะที่ การลดต้นทุนหรือการเพิ่มต้นทุนบางประเภท และปัญหาของพนักงานขายที่กำลังเดินทางคือการหาเส้นทางที่สั้นที่สุดที่เข้าชมโหนดทั้งหมดในกราฟ) ซึ่งสอดคล้องกับต้นทุนการสื่อสารของไปป์ไลน์ขนานกัน
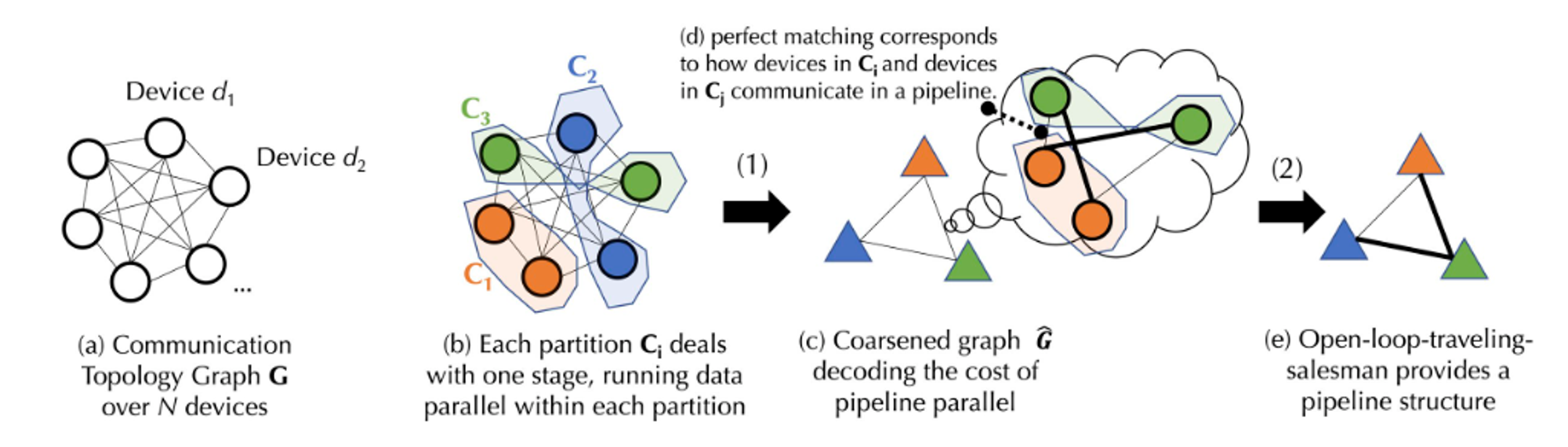 รูปภาพด้านบนเป็นแผนผังกระบวนการ เนื่องจากกระบวนการนำไปใช้งานจริงเกี่ยวข้องกับสูตรการคำนวณที่ซับซ้อนบางสูตร เพื่ออำนวยความสะดวกในการทำความเข้าใจกระบวนการในรูปจะอธิบายให้ง่ายขึ้นด้านล่าง สำหรับขั้นตอนการดำเนินการโดยละเอียดคุณสามารถดูเอกสารได้จากเว็บไซต์ทางการของ Together
รูปภาพด้านบนเป็นแผนผังกระบวนการ เนื่องจากกระบวนการนำไปใช้งานจริงเกี่ยวข้องกับสูตรการคำนวณที่ซับซ้อนบางสูตร เพื่ออำนวยความสะดวกในการทำความเข้าใจกระบวนการในรูปจะอธิบายให้ง่ายขึ้นด้านล่าง สำหรับขั้นตอนการดำเนินการโดยละเอียดคุณสามารถดูเอกสารได้จากเว็บไซต์ทางการของ Together
สมมติว่ามีอุปกรณ์ชุด D ที่มีอุปกรณ์ N รายการ ซึ่งการสื่อสารระหว่างกันมีความหน่วงที่ไม่แน่นอน (เมทริกซ์ A) และแบนด์วิธ (เมทริกซ์ B) จากชุดอุปกรณ์ D เราจะสร้างพาร์ติชันกราฟที่สมดุลก่อน จำนวนอุปกรณ์ในแต่ละพาร์ติชั่นหรือกลุ่มอุปกรณ์จะเท่ากันโดยประมาณ และทั้งหมดจัดการขั้นตอนไปป์ไลน์เดียวกัน เพื่อให้แน่ใจว่าเมื่อข้อมูลถูกขนาน กลุ่มอุปกรณ์แต่ละกลุ่มจะทำงานในปริมาณที่ใกล้เคียงกัน (ความขนานของข้อมูลหมายถึงอุปกรณ์หลายเครื่องที่ทำงานเดียวกัน ในขณะที่ขั้นตอนไปป์ไลน์หมายถึงอุปกรณ์ที่ดำเนินการขั้นตอนงานที่แตกต่างกันตามลำดับเฉพาะ) ขึ้นอยู่กับเวลาแฝงและแบนด์วิธของการสื่อสาร สามารถใช้สูตรในการคำนวณ ต้นทุน ของการส่งข้อมูลระหว่างกลุ่มอุปกรณ์ได้ กลุ่มอุปกรณ์ที่สมดุลแต่ละกลุ่มจะถูกผสานเข้าด้วยกัน ทำให้เกิดกราฟคร่าวๆ ที่เชื่อมต่อกันโดยสมบูรณ์ โดยแต่ละโหนดแสดงถึงระยะของไปป์ไลน์ และขอบแสดงถึงต้นทุนการสื่อสารระหว่างสองขั้นตอน เพื่อลดต้นทุนการสื่อสาร จึงมีการใช้อัลกอริธึมการจับคู่เพื่อกำหนดว่าอุปกรณ์กลุ่มใดควรทำงานร่วมกัน
สำหรับการเพิ่มประสิทธิภาพเพิ่มเติม ปัญหานี้ยังสามารถจำลองเป็นปัญหาพนักงานขายที่กำลังเดินทางแบบวงเปิด (open-loop หมายความว่าไม่จำเป็นต้องกลับไปยังจุดเริ่มต้นของเส้นทาง) เพื่อค้นหาเส้นทางที่เหมาะสมที่สุดในการส่งข้อมูลระหว่างอุปกรณ์ทั้งหมด สุดท้ายนี้ Together ใช้อัลกอริธึมการจัดกำหนดการที่เป็นนวัตกรรมใหม่เพื่อค้นหากลยุทธ์การจัดสรรที่เหมาะสมที่สุดสำหรับโมเดลต้นทุนที่กำหนด ซึ่งจะช่วยลดต้นทุนการสื่อสารและเพิ่มปริมาณงานการฝึกอบรมให้สูงสุด ตามการวัดจริง แม้ว่าเครือข่ายจะช้าลง 100 เท่าภายใต้การเพิ่มประสิทธิภาพการจัดกำหนดการนี้ ปริมาณงานการฝึกอบรมตั้งแต่ต้นทางถึงปลายทางจะช้าลงเพียงประมาณ 1.7 ถึง 2.3 เท่าเท่านั้น
การเพิ่มประสิทธิภาพการบีบอัดการสื่อสาร:
สำหรับการเพิ่มประสิทธิภาพการบีบอัดการสื่อสาร ร่วมกันแนะนำอัลกอริธึม AQ-SGD (สำหรับกระบวนการคำนวณโดยละเอียด โปรดดูเอกสาร โมเดลภาษาที่ปรับแต่งอย่างละเอียดบนเครือข่ายที่ช้าโดยใช้การบีบอัดการเปิดใช้งานพร้อมการรับประกัน) อัลกอริธึม AQ-SGD คือการแก้ปัญหา ของการขนานไปป์ไลน์บนเครือข่ายความเร็วต่ำเทคโนโลยีการบีบอัดแบบแอคทีฟใหม่ที่ออกแบบมาเพื่อแก้ปัญหาประสิทธิภาพการสื่อสารของการฝึกอบรม แตกต่างจากวิธีการก่อนหน้านี้ที่บีบอัดค่ากิจกรรมโดยตรง AQ-SGD มุ่งเน้นไปที่การบีบอัดการเปลี่ยนแปลงค่ากิจกรรมของตัวอย่างการฝึกเดียวกันในช่วงเวลาต่าง ๆ วิธีการที่เป็นเอกลักษณ์นี้นำเสนอไดนามิก การดำเนินการด้วยตนเอง ที่น่าสนใจ เมื่อการฝึกอบรมมีความเสถียร ประสิทธิภาพของอัลกอริทึมคาดว่าจะค่อยๆ ดีขึ้น อัลกอริธึม AQ-SGD ได้ผ่านการวิเคราะห์ทางทฤษฎีอย่างเข้มงวด และพิสูจน์แล้วว่ามีอัตราการลู่เข้าที่ดีภายใต้เงื่อนไขทางเทคนิคบางประการ และฟังก์ชันเชิงปริมาณที่มีข้อผิดพลาดแบบมีขอบเขต อัลกอริธึมนี้ไม่เพียงแต่สามารถนำไปใช้ได้อย่างมีประสิทธิภาพเท่านั้น แต่ยังเพิ่มค่าใช้จ่ายรันไทม์แบบ end-to-end เพิ่มเติมอีกด้วย แม้ว่าจะต้องใช้หน่วยความจำและ SSD มากขึ้นเพื่อจัดเก็บค่าความมีชีวิตชีวาก็ตาม ได้รับการตรวจสอบผ่านการทดลองที่ครอบคลุมเกี่ยวกับการจำแนกลำดับและชุดข้อมูลการสร้างแบบจำลองภาษา AQ-SGD สามารถบีบอัดค่ากิจกรรมเป็น 2-4 บิตโดยไม่ทำให้ประสิทธิภาพการลู่เข้าลดลง นอกจากนี้ AQ-SGD ยังสามารถบูรณาการเข้ากับอัลกอริธึมการบีบอัดแบบไล่ระดับที่ล้ำสมัยเพื่อให้ได้ การบีบอัดการสื่อสารแบบ end-to-end ซึ่งก็คือการแลกเปลี่ยนข้อมูลทั้งหมดระหว่างเครื่องจักร รวมถึงการไล่ระดับสีแบบจำลอง ค่ากิจกรรมการส่งต่อ และการไล่ระดับสีแบบย้อนกลับถูกบีบอัดให้มีความแม่นยำต่ำ จึงช่วยปรับปรุงประสิทธิภาพการสื่อสารของการฝึกอบรมแบบกระจายได้อย่างมาก เมื่อเปรียบเทียบกับประสิทธิภาพการฝึกอบรมแบบ end-to-end ที่ไม่มีการบีบอัดบนเครือข่ายคอมพิวเตอร์แบบรวมศูนย์ (เช่น 10 Gbps) ปัจจุบันทำงานได้ช้ากว่าเพียง 31% เท่านั้น เมื่อรวมกับข้อมูลเกี่ยวกับการเพิ่มประสิทธิภาพการกำหนดเวลา แม้ว่าจะยังมีช่องว่างบางอย่างระหว่างเครือข่ายพลังการประมวลผลแบบรวมศูนย์และเครือข่ายพลังการประมวลผลแบบรวมศูนย์ แต่ความหวังที่จะตามทันในอนาคตก็ค่อนข้างสูง
บทสรุป
ในช่วงเงินปันผลที่เกิดจากคลื่น AI ตลาดพลังงานประมวลผล AGI ถือเป็นตลาดที่มีศักยภาพสูงสุดและเป็นที่ต้องการมากที่สุดในบรรดาตลาดพลังงานประมวลผลจำนวนมากอย่างไม่ต้องสงสัย อย่างไรก็ตาม ความยากในการพัฒนา ข้อกำหนดด้านฮาร์ดแวร์ และข้อกำหนดทางการเงินก็สูงที่สุดเช่นกัน เมื่อพิจารณาจากสถานการณ์ของทั้งสองโครงการข้างต้น ยังมีระยะห่างอีกระยะหนึ่งก่อนที่ตลาดพลังงานประมวลผล AGI จะสามารถใช้งานได้ เครือข่ายแบบกระจายอำนาจอย่างแท้จริงนั้นซับซ้อนกว่าสถานการณ์ในอุดมคติมาก เห็นได้ชัดว่าไม่เพียงพอที่จะแข่งขันกับยักษ์ใหญ่ด้านคลาวด์ ในปัจจุบัน. ในขณะที่เขียนบทความนี้ ฉันยังสังเกตเห็นว่าโครงการขนาดเล็กบางโครงการในวัยเด็ก (ระยะ PPT) ได้เริ่มสำรวจจุดเริ่มต้นใหม่ๆ เช่น การมุ่งเน้นไปที่ขั้นตอนการอนุมานที่ยากน้อยกว่าหรือแบบจำลองขนาดเล็ก ในแง่ของการฝึกอบรม สิ่งเหล่านี้คือ ความพยายามในทางปฏิบัติมากขึ้น
ยังไม่ชัดเจนว่าในที่สุดตลาดพลังการประมวลผลของ AGI จะรับรู้ได้อย่างไร แม้ว่าจะเผชิญกับความท้าทายมากมาย ในระยะยาว การกระจายอำนาจและนัยสำคัญที่ไม่ได้รับอนุญาตของพลังการประมวลผลของ AGI นั้นมีความสำคัญ และไม่ควรเน้นถึงสิทธิในการให้เหตุผลและการฝึกอบรม ไปจนถึงยักษ์ใหญ่ที่รวมศูนย์ไม่กี่แห่ง เนื่องจากมนุษยชาติไม่ต้องการ ศาสนา ใหม่หรือ พระสันตปาปา ใหม่ ไม่ต้องพูดถึงการจ่าย ค่าธรรมเนียม อันแพง
การอ้างอิง
1.Gensyn Litepaper:https://docs.gensyn.ai/litepaper/
2.NeurIPS 2022: Overcoming Communication Bottlenecks for Decentralized Training :https://together.ai/blog/neurips-2022-overcoming-communication-bottlenecks-for-decentralized-training-12
3.Fine-tuning Language Models over Slow Networks using Activation Compression with Guarantees:https://arxiv.org/abs/2206.01299
4.The Machine Learning Compute Protocol and our future:https://mirror.xyz/gensyn.eth/_K2v2uuFZdNnsHxVL3Bjrs4GORu3COCMJZJi7_MxByo
5.Microsoft:Earnings Release FY 23 Q2:https://www.microsoft.com/en-us/Investor/earnings/FY-2023-Q2/performance
6. การแข่งขันชิงตั๋วเข้าชม AI: BAT, Byte และ Meituan แข่งขันกันเพื่อชิง GPU:https://m.huxiu.com/article/1676290.html
7.IDC: รายงานการประเมินดัชนีกำลังคอมพิวเตอร์ทั่วโลกปี 2022-2023:https://www.tsinghua.edu.cn/info/1175/105480.htm
8. การประมาณค่าการฝึกอบรมโมเดลขนาดใหญ่ของหลักทรัพย์ Guosheng:https://www.fxbaogao.com/detail/3565665
9. Wings of Information: อะไรคือความสัมพันธ์ระหว่างพลังการประมวลผลและ AI? : :https://zhuanlan.zhihu.com/p/627645270


