
ZKML และคอมพิวเตอร์แบบกระจาย: คำบรรยายการกำกับดูแลที่เป็นไปได้สำหรับ AI และ Web3
ชื่อระดับแรก
สถานะของ AI และเว็บ 3: ฝูงผู้ลี้ภัยและการเติบโตของเอนโทรปี

ใน Out of Control: The New Biology of Machines, Society, and the Economy เควิน เคลลี่ เคยเสนอปรากฏการณ์: อาณานิคมผึ้งจะดำเนินการตัดสินใจการเลือกตั้งด้วยการเต้นเป็นกลุ่มตามการจัดการแบบกระจาย และทั้งอาณานิคมผึ้งจะปฏิบัติตามสิ่งนี้ การเต้นรำกลุ่ม ฝูงผึ้งที่ใหญ่ที่สุดในโลกกลายเป็นเจ้าแห่งงาน สิ่งนี้เรียกว่า วิญญาณแห่งรัง ที่ถูกกล่าวถึงโดย Maurice Maeterlinck ผึ้งแต่ละตัวสามารถตัดสินใจได้เอง แนะนำผึ้งตัวอื่นให้ยืนยัน และการตัดสินใจขั้นสุดท้ายคือการเลือกกลุ่มอย่างแท้จริง
กฎของการเพิ่มขึ้นและความผิดปกติของเอนโทรปีนั้นเป็นไปตามกฎของอุณหพลศาสตร์ และการมองเห็นเชิงทฤษฎีในฟิสิกส์คือการใส่โมเลกุลจำนวนหนึ่งลงในช่องว่างและคำนวณโปรไฟล์การกระจายขั้นสุดท้าย โดยเฉพาะสำหรับคนกลุ่มม็อบที่สร้างโดยอัลกอริธึมสามารถแสดงกฎของกลุ่มแม้ว่าจะมีความแตกต่างในการคิดของแต่ละบุคคล มักถูกจำกัดไว้ในช่องว่างเนื่องจากปัจจัยต่างๆ เช่น เวลา และในที่สุดก็ตัดสินใจเป็นเอกฉันท์
แน่นอนว่ากฎของกลุ่มอาจไม่ถูกต้อง แต่ผู้นำทางความคิดที่สามารถเป็นตัวแทนฉันทามติและดึงฉันทามติได้ด้วยตนเองนั้นถือเป็นบุคคลชั้นยอดโดยเด็ดขาด แต่ในกรณีส่วนใหญ่ ฉันทามติไม่ได้ดำเนินการตามความยินยอมโดยสมบูรณ์และไม่มีเงื่อนไขจากทุกคน แต่เพียงกำหนดให้กลุ่มต้องมีเอกลักษณ์ทั่วไปเท่านั้น
เราไม่ได้พูดคุยกันที่นี่ว่า AI จะทำให้มนุษย์หลงทางหรือไม่ อันที่จริง มีการพูดคุยกันมากมายอยู่แล้ว ไม่ว่าจะเป็นขยะจำนวนมากที่เกิดจากแอปพลิเคชันปัญญาประดิษฐ์ที่ทำลายความถูกต้องของข้อมูลเครือข่าย หรือเนื่องจากการตัดสินใจของกลุ่ม ทำผิดพลาดจนนำไปสู่เหตุการณ์บางอย่างจนกลายเป็นสถานการณ์ที่อันตรายยิ่งขึ้น
สถานการณ์ปัจจุบันของ AI มีการผูกขาดโดยธรรมชาติ ตัวอย่างเช่น การฝึกอบรมและการปรับใช้โมเดลขนาดใหญ่ต้องใช้ทรัพยากรคอมพิวเตอร์และข้อมูลจำนวนมาก แต่มีองค์กรและสถาบันจำนวนไม่มากเท่านั้นที่มีเงื่อนไขเหล่านี้ ข้อมูลหลายร้อยล้านเหล่านี้ถือเป็นสมบัติของเจ้าของที่ผูกขาดแต่ละราย ไม่ต้องพูดถึงการแบ่งปันแหล่งข้อมูล แม้แต่การเข้าถึงร่วมกันก็เป็นไปไม่ได้
หลายๆ คนบอกว่า AI และ Web 3 เป็นสองสิ่งที่แตกต่างกันและไม่มีการเชื่อมโยงกัน ครึ่งแรกของประโยคนั้นถูกต้อง ซึ่งเป็นสองแทร็กที่แตกต่างกัน แต่ครึ่งหลังของประโยคนั้นเป็นปัญหา โดยใช้เทคโนโลยีแบบกระจายเพื่อจำกัดการสิ้นสุดการผูกขาด ของปัญญาประดิษฐ์ และการใช้เทคโนโลยีปัญญาประดิษฐ์เพื่อส่งเสริมการก่อตัวของกลไกฉันทามติแบบกระจายอำนาจเป็นเพียงสิ่งธรรมชาติ
ชื่อระดับแรก
การหักล้างด้านล่าง: ให้ AI สร้างกลไกฉันทามติของกลุ่มแบบกระจายที่แท้จริง
หัวใจสำคัญของปัญญาประดิษฐ์นั้นอยู่ที่ตัวมนุษย์เอง เครื่องจักรและแบบจำลองก็เป็นเพียงการคาดเดาและการเลียนแบบความคิดของมนุษย์ สิ่งที่เรียกว่ากลุ่มนั้นแท้จริงแล้วยากที่จะสรุปกลุ่มเพราะสิ่งที่เราเห็นทุกวันยังคงเป็นปัจเจกบุคคลที่แท้จริง แต่โมเดลคือการใช้ข้อมูลขนาดใหญ่เพื่อเรียนรู้และปรับเปลี่ยน และสุดท้ายคือการจำลองรูปแบบกลุ่ม อย่าประเมินว่าโมเดลนี้จะทำให้เกิดผลลัพธ์ประเภทใด เนื่องจากเหตุการณ์ของกลุ่มที่กระทำความชั่วไม่ได้เกิดขึ้นครั้งเดียวหรือสองครั้ง แต่แบบจำลองนี้เป็นตัวแทนของการสร้างกลไกฉันทามตินี้
ตัวอย่างเช่น สำหรับ DAO เฉพาะเจาะจง หากมีการนำกลไกการกำกับดูแลไปใช้ก็จะส่งผลกระทบต่อประสิทธิภาพอย่างหลีกเลี่ยงไม่ได้ เหตุผลก็คือ การสร้างฉันทามติของกลุ่มเป็นเรื่องที่ยุ่งยาก ไม่ต้องพูดถึงการลงคะแนน สถิติ ฯลฯ ชุดการดำเนินงาน หากการกำกับดูแลของ DAO รวมอยู่ในรูปแบบของโมเดล AI และการรวบรวมข้อมูลทั้งหมดมาจากข้อมูลคำพูดของทุกคนใน DAO การตัดสินใจเอาท์พุตก็จะใกล้เคียงกับมติของกลุ่มมากขึ้น
ฉันทามติกลุ่มของแบบจำลองเดียวสามารถได้รับการฝึกอบรมตามโครงการข้างต้น แต่ก็ยังคงเป็นเกาะสำหรับบุคคลเหล่านี้ หากมีระบบปัญญารวมที่จัดตั้งกลุ่ม AI โมเดล AI แต่ละโมเดลในระบบนี้จะทำงานร่วมกันเพื่อแก้ไขปัญหาที่ซับซ้อน ซึ่งจริงๆ แล้วจะส่งผลกระทบอย่างมากต่อการเพิ่มขีดความสามารถของระดับฉันทามติ
สมองอัจฉริยะระดับโลกสามารถสร้างโมเดลอัลกอริธึม AI แบบฟังก์ชันเดียวที่เป็นอิสระแต่เดิมและทำงานร่วมกัน ประมวลผลกระบวนการอัลกอริธึมอัจฉริยะที่ซับซ้อนภายใน และสร้างเครือข่ายฉันทามติกลุ่มแบบกระจายที่สามารถเติบโตได้อย่างต่อเนื่อง นี่เป็นความสำคัญที่ยิ่งใหญ่ที่สุดของการเพิ่มขีดความสามารถของ AI ให้กับ Web 3
ชื่อระดับแรก
ความเป็นส่วนตัวและการผูกขาดข้อมูล? การผสมผสานระหว่าง ZK และการเรียนรู้ของเครื่อง
มนุษย์ต้องใช้ความระมัดระวังแบบกำหนดเป้าหมาย ไม่ว่าจะเป็นการต่อต้าน AI ในการทำสิ่งชั่วร้าย หรือขึ้นอยู่กับการปกป้องความเป็นส่วนตัวและความกลัวการผูกขาดข้อมูล ปัญหาหลักคือเราไม่รู้ว่าข้อสรุปนั้นเกิดขึ้นได้อย่างไร เช่นเดียวกัน ผู้ดำเนินการแบบจำลองไม่ได้ตั้งใจที่จะตอบคำถามนี้ และสำหรับการรวมกันของสมองอัจฉริยะระดับโลกที่เรากล่าวถึงข้างต้น การแก้ปัญหานี้จึงมีความจำเป็นมากยิ่งขึ้น ไม่เช่นนั้นจะไม่มีฝ่ายข้อมูลใดยินดีแบ่งปันแกนกลางของมันกับผู้อื่น
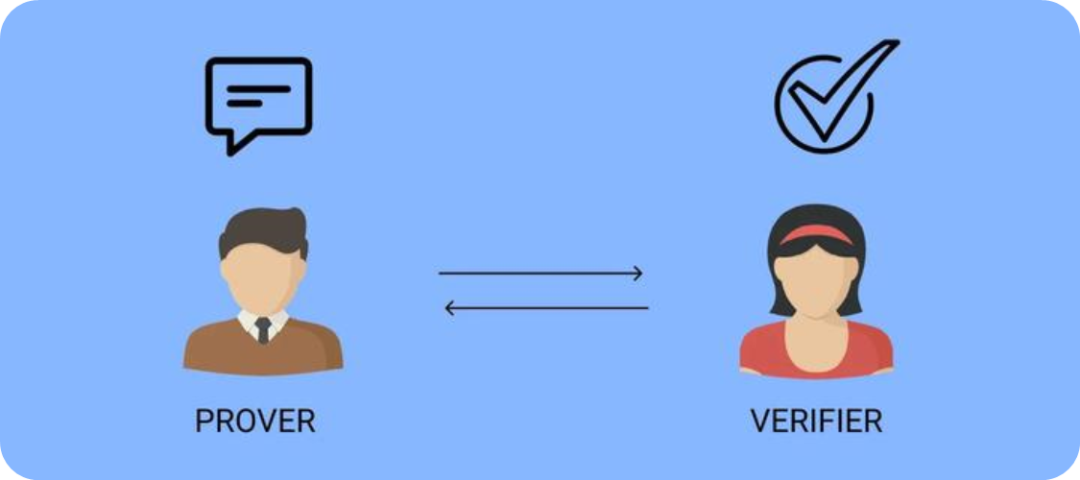
ZKML (Zero Knowledge Machine Learning) เป็นเทคโนโลยีที่ใช้การพิสูจน์ความรู้เป็นศูนย์สำหรับการเรียนรู้ของเครื่อง Zero-Knowledge Proofs (ZKP) กล่าวคือ ผู้พิสูจน์ (ผู้พิสูจน์) อาจโน้มน้าวผู้ตรวจสอบ (ผู้ตรวจสอบ) ถึงความถูกต้องของข้อมูลโดยไม่ต้องเปิดเผยข้อมูลเฉพาะ
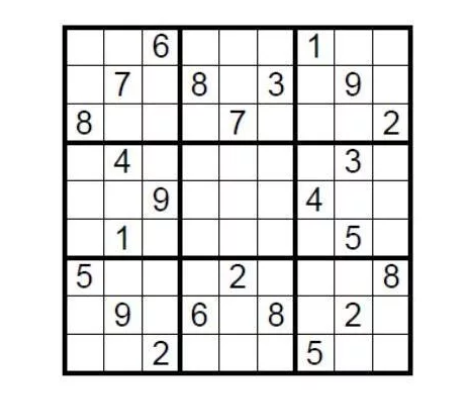
อ้างด้วยกรณีเชิงทฤษฎี มีซูโดกุมาตรฐานขนาด 9 × 9 เงื่อนไขในการกรอกตัวเลขตั้งแต่ 1 ถึง 9 ในตารางเก้าช่องเพื่อให้แต่ละหมายเลขปรากฏได้เพียงครั้งเดียวในแต่ละแถว คอลัมน์ และตาราง แล้วผู้ที่ไขปริศนานี้จะพิสูจน์ให้ผู้ท้าชิงเห็นว่าซูโดกุมีวิธีแก้ปัญหาโดยไม่เปิดเผยคำตอบได้อย่างไร
คุณเพียงแต่ต้องครอบคลุมคำตอบให้ครบทุกช่อง จากนั้นขอให้ผู้ท้าชิงสุ่มเลือกแถวหรือคอลัมน์ 2-3 คอลัมน์ สลับตัวเลขทั้งหมดและตรวจสอบว่าตัวเลขทั้งหมดเป็น 1 ถึง 9 นี่คือศูนย์รวมความรู้ที่เรียบง่ายที่พิสูจน์ได้
เทคโนโลยีพิสูจน์ความรู้เป็นศูนย์มีคุณลักษณะ 3 ประการ คือ ความสมบูรณ์ ความถูกต้อง และความรู้เป็นศูนย์ กล่าวคือ พิสูจน์ข้อสรุปโดยไม่เปิดเผยรายละเอียดใดๆ แหล่งที่มาของเทคโนโลยีสามารถสะท้อนถึงความเรียบง่าย ในบริบทของการเข้ารหัสแบบ Homomorphic ความยากในการตรวจสอบยังต่ำกว่าความยากในการสร้างการพิสูจน์มาก
การเรียนรู้ของเครื่องคือการใช้อัลกอริธึมและแบบจำลองเพื่อให้ระบบคอมพิวเตอร์เรียนรู้และปรับปรุงจากข้อมูล การเรียนรู้จากประสบการณ์ผ่านระบบอัตโนมัติทำให้ระบบสามารถทำงานต่างๆ ได้โดยอัตโนมัติ เช่น การทำนาย การจำแนกประเภท การจัดกลุ่ม และการเพิ่มประสิทธิภาพตามข้อมูลและแบบจำลอง

โดยแก่นแท้แล้ว แมชชีนเลิร์นนิงเป็นเรื่องเกี่ยวกับการสร้างแบบจำลองที่เรียนรู้จากข้อมูล ตลอดจนคาดการณ์และตัดสินใจได้โดยอัตโนมัติ การสร้างแบบจำลองเหล่านี้มักต้องใช้องค์ประกอบหลักสามประการ: ชุดข้อมูล อัลกอริธึม และการประเมินแบบจำลอง ชุดข้อมูลเป็นรากฐานของการเรียนรู้ของเครื่องและมีตัวอย่างข้อมูลที่ใช้ในการฝึกอบรมและทดสอบโมเดลการเรียนรู้ของเครื่อง อัลกอริธึมเป็นหัวใจสำคัญของโมเดลการเรียนรู้ของเครื่อง โดยกำหนดวิธีที่โมเดลเรียนรู้และคาดการณ์จากข้อมูล การประเมินโมเดลเป็นส่วนสำคัญของการเรียนรู้ของเครื่อง ซึ่งใช้ในการประเมินประสิทธิภาพและความแม่นยำของโมเดล และตัดสินใจว่าจำเป็นต้องปรับปรุงและปรับปรุงโมเดลหรือไม่
ในแมชชีนเลิร์นนิงแบบดั้งเดิม ชุดข้อมูลมักจะจำเป็นต้องรวบรวมไว้ในที่รวมศูนย์เพื่อการฝึกอบรม ซึ่งหมายความว่าเจ้าของข้อมูลจะต้องแบ่งปันข้อมูลกับบุคคลที่สาม ซึ่งอาจนำไปสู่ความเสี่ยงที่ข้อมูลจะรั่วไหลหรือรั่วไหลของความเป็นส่วนตัว ด้วย ZKML เจ้าของข้อมูลสามารถแบ่งปันชุดข้อมูลกับผู้อื่นโดยไม่ต้องเปิดเผยข้อมูล ซึ่งทำได้โดยใช้การพิสูจน์ความรู้แบบศูนย์
สถานการณ์นี้จะนำไปสู่การค้าประเวณีฐานข้อมูลขนาดเล็กสู่ฐานข้อมูลขนาดใหญ่หรือไม่? เมื่อคุณคิดถึงการกำกับดูแล มันจะย้อนกลับไปที่แนวคิด Web 3 ของเรา และแก่นแท้ของ Crypto คือการกำกับดูแล ไม่ว่าจะเป็นผ่านแอปพลิเคชั่นจำนวนมากหรือการแชร์ คุณควรได้รับสิ่งจูงใจที่สมควรได้รับ ไม่ว่าจะผ่านทาง Pow ดั้งเดิม, กลไก PoS หรือ PoR ล่าสุด (กลไกการพิสูจน์ชื่อเสียง) ทั้งหมดนี้ให้การรับประกันผลจูงใจ
ชื่อระดับแรก
พลังการประมวลผลแบบกระจาย: การเล่าเรื่องเชิงนวัตกรรมที่เกี่ยวพันกับการโกหกและความเป็นจริง
เครือข่ายพลังการประมวลผลแบบกระจายอำนาจเป็นสถานการณ์ที่ถูกกล่าวถึงอย่างถึงพริกถึงขิงมาโดยตลอดในแวดวงการเข้ารหัส ท้ายที่สุดแล้ว โมเดลขนาดใหญ่ของ AI ต้องการพลังการประมวลผลที่น่าทึ่ง และเครือข่ายพลังการประมวลผลแบบรวมศูนย์จะไม่เพียงทำให้สิ้นเปลืองทรัพยากรเท่านั้น แต่ยังก่อให้เกิดการผูกขาดที่สำคัญด้วย - หากเปรียบเทียบใน สุดท้ายเรื่องจำนวน GPU เป็นสิ่งสุดท้ายที่ต้องสู้ซึ่งน่าเบื่อเกินไป
สาระสำคัญของเครือข่ายพลังการประมวลผลแบบกระจายอำนาจคือการบูรณาการทรัพยากรการประมวลผลที่กระจัดกระจายอยู่ในสถานที่ต่างๆ และบนอุปกรณ์ที่แตกต่างกัน ข้อได้เปรียบหลักที่มักกล่าวถึงคือ: มอบความสามารถในการประมวลผลแบบกระจาย แก้ไขปัญหาความเป็นส่วนตัว เพิ่มความน่าเชื่อถือและความน่าเชื่อถือของโมเดลปัญญาประดิษฐ์ รองรับการใช้งานและการดำเนินการอย่างรวดเร็วในสถานการณ์แอปพลิเคชันต่างๆ และจัดเตรียมแผนการจัดเก็บและการจัดการข้อมูลแบบกระจายอำนาจ ถูกต้องแล้ว ด้วยพลังการประมวลผลแบบกระจายอำนาจ ทุกคนสามารถเรียกใช้โมเดล AI และทดสอบกับชุดข้อมูลออนไลน์จริงจากผู้ใช้ทั่วโลก เพื่อให้พวกเขาสามารถเพลิดเพลินกับบริการคอมพิวเตอร์ที่ยืดหยุ่น มีประสิทธิภาพ และต้นทุนต่ำมากขึ้น
ในขณะเดียวกัน พลังการประมวลผลแบบกระจายอำนาจสามารถแก้ไขปัญหาความเป็นส่วนตัวได้โดยการสร้างเฟรมเวิร์กที่แข็งแกร่งเพื่อปกป้องความปลอดภัยและความเป็นส่วนตัวของข้อมูลผู้ใช้ นอกจากนี้ยังมอบกระบวนการประมวลผลที่โปร่งใสและตรวจสอบได้ ช่วยเพิ่มความน่าเชื่อถือและความน่าเชื่อถือของโมเดลปัญญาประดิษฐ์ และมอบทรัพยากรการประมวลผลที่ยืดหยุ่นและปรับขนาดได้เพื่อการปรับใช้และดำเนินการอย่างรวดเร็วในสถานการณ์แอปพลิเคชันต่างๆ
ดังนั้น แม้ว่าเครือข่ายพลังการประมวลผลแบบกระจายอำนาจจะมีข้อดีและศักยภาพมากมาย แต่เส้นทางการพัฒนาก็ยังคงคดเคี้ยวตามต้นทุนการสื่อสารในปัจจุบันและความยากในการดำเนินงานจริง ในทางปฏิบัติ การตระหนักถึงเครือข่ายพลังการประมวลผลแบบกระจายอำนาจนั้นจำเป็นต้องเอาชนะปัญหาทางเทคนิคในทางปฏิบัติหลายประการ ไม่ว่าจะเป็นวิธีการรับประกันความน่าเชื่อถือและความปลอดภัยของโหนด วิธีการจัดการและกำหนดเวลาทรัพยากรการคำนวณแบบกระจายอย่างมีประสิทธิภาพ หรือวิธีบรรลุการรับส่งข้อมูลและการสื่อสารที่มีประสิทธิภาพ เป็นต้น ., กลัวว่ามันจะเป็นปัญหาใหญ่จริงๆ.
ชื่อระดับแรก
หาง: ความคาดหวังสำหรับนักอุดมคติ
เมื่อกลับไปสู่ความเป็นจริงเชิงพาณิชย์ในปัจจุบัน การเล่าเรื่องของการบูรณาการอย่างลึกซึ้งของ AI และ Web 3 ดูสวยงามมาก แต่ทุนและผู้ใช้บอกเรามากขึ้นด้วยการปฏิบัติจริงว่านี่ถูกกำหนดให้เป็นการเดินทางที่ยากมากของนวัตกรรม เว้นแต่ว่าโครงการจะสามารถทำได้ อย่าง OpenAI ในทำนองเดียวกัน เราควรยอมรับผู้สนับสนุนทางการเงินที่แข็งแกร่งในขณะที่เราเข้มแข็ง ไม่เช่นนั้นค่าใช้จ่ายด้าน R&D อย่างเหลือล้นและรูปแบบธุรกิจที่ไม่ชัดเจนจะบดขยี้เราโดยสิ้นเชิง
ไม่ว่าจะเป็น AI หรือ Web 3 ตอนนี้พวกเขายังอยู่ในช่วงเริ่มต้นของการพัฒนา เช่นเดียวกับฟองสบู่อินเทอร์เน็ตในช่วงปลายศตวรรษที่ผ่านมา และจนกระทั่งเกือบหนึ่งทศวรรษต่อมา ยุคทองที่แท้จริงก็เริ่มต้นอย่างเป็นทางการ McCarthy จินตนาการถึงการออกแบบปัญญาประดิษฐ์ด้วยปัญญาของมนุษย์ในช่วงวันหยุดเดียว แต่จนกระทั่งเกือบเจ็ดสิบปีต่อมา เราก็ได้ก้าวสำคัญสู่ปัญญาประดิษฐ์
เช่นเดียวกับ Web 3+AI เราได้กำหนดทิศทางที่ถูกต้องแล้ว และส่วนที่เหลือจะปล่อยให้เป็นไปตามกาลเวลา


