
SignalPlus: 오토인코더(오토인코더)
원저자: 스티븐 왕

머리말
N.Coder와 D.Coder 두 형제가 미술관을 운영하고 있습니다. 어느 주말, 그들은 벽이 하나뿐이고 실제 예술품이 전혀 없었기 때문에 특히 이상한 전시회를 가졌습니다. N.Coder는 새 그림을 받으면 벽에 있는 한 지점을 그림을 나타내는 표시로 선택한 다음 원본 그림을 버립니다. 고객이 그림을 보여달라고 요청하자 D.Coder는 벽에 표시된 해당 표시의 좌표만을 사용하여 예술 작품을 재현하려고 시도했습니다.
전시벽은 아래 사진과 같으며, 각각의 검은 점은 N.Coder가 배치한 그림을 의미하는 표시입니다. N.Coder는 벽에 있는 좌표 [- 3.5, 1]에 숫자 6의 원본 그림을 재구성했습니다.
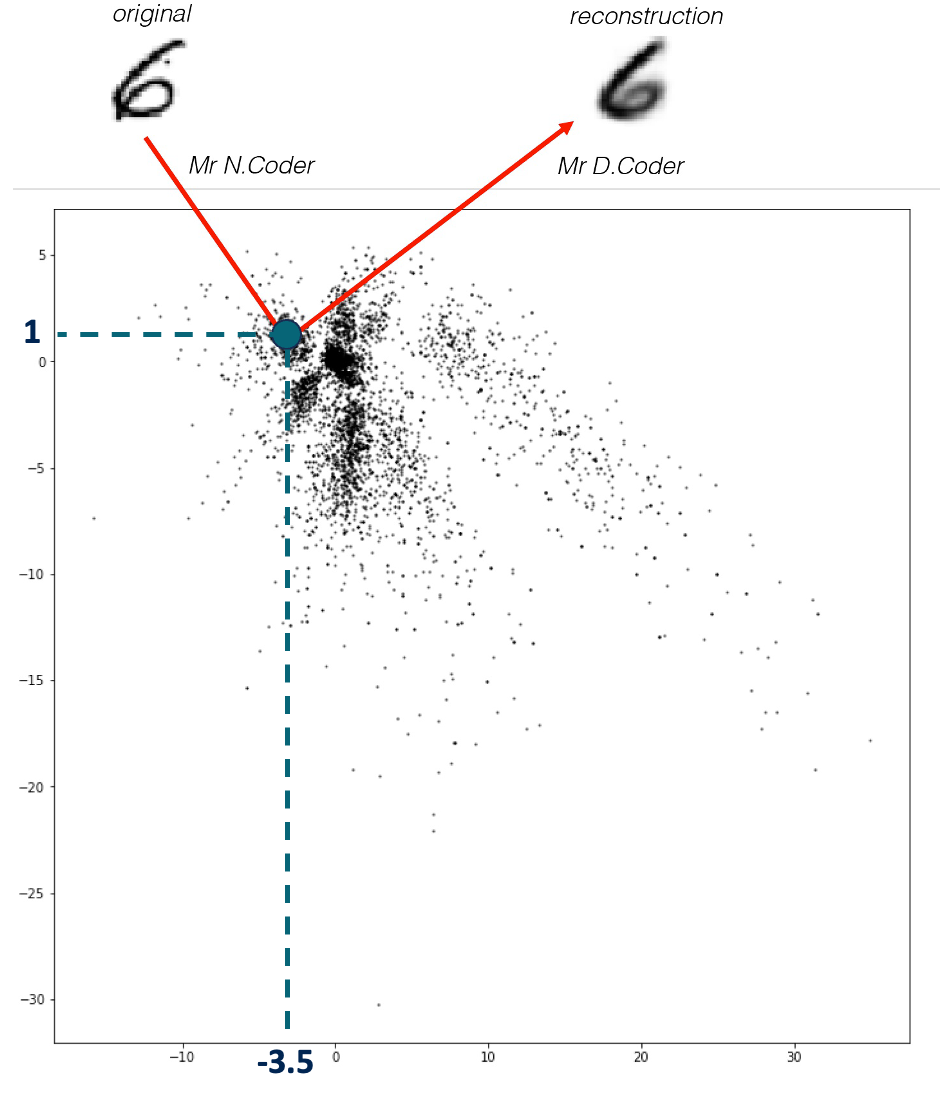
아래 사진에 더 많은 예시가 있는데, 윗줄의 숫자는 원본 사진, 가운데 줄의 좌표는 N.Coder가 그림을 벽에 걸었던 좌표, 아랫줄은 D.Coder가 재구성한 작품입니다. 좌표를 기준으로 합니다.

그렇다면 N.Coder는 어떻게 전시 벽에 걸린 각 그림의 해당 좌표를 결정하고, D.Coder가 이를 단독으로 사용하여 원본 그림을 재구성할 수 있을까요? 수년간의 훈련을 통해 점차적으로 마커 배치를 마스터하고 작품을 재구성 한 두 형제는 재구성 품질이 좋지 않아 환불을 요구하는 고객으로 인해 박스 오피스에서 수익 손실을 신중하게 모니터링 한 것으로 나타났습니다. 수익 손실을 최소화하면서 재구축하세요. 위 사진의 원본 이미지와 재구성한 이미지를 비교해 보면 알 수 있듯이, 두 형제의 런인은 꽤 좋습니다. 예술 작품을 보러 오는 고객은 D.Coder의 재현 그림이 자신이 보러 온 원본 작품과 매우 다르다는 불만을 거의 제기하지 않습니다.
어느 날 N.Coder는 전시벽을 보다가 과감한 생각을 하게 되었는데, 현재 표시가 되어 있지 않은 벽 부분을 D.Coder에게 재구성해 주면 어떤 작품이 나올 수 있을까? 성공하면 자신이 직접 그린 100% 원본 그림 전시회를 열 수 있습니다. 생각만 해도 신이 나서 D.Coder는 이전에 표시하지 않았던 좌표를 무작위로 선택했습니다(빨간 점)을 재구성한 결과는 아래 그림과 같다.
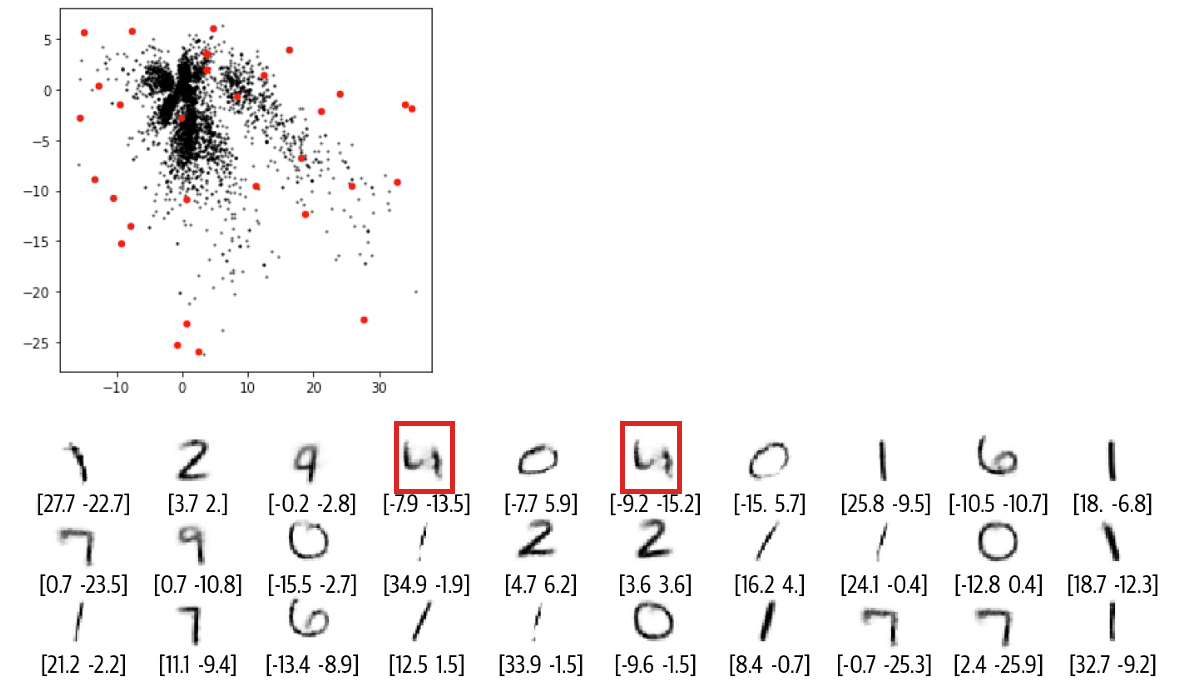
보시다시피 재구성이 열악하고 일부 수치에서는 숫자가 무엇인지조차 알 수 없습니다. 그러면 무엇이 잘못되었으며 Coder 형제는 어떻게 솔루션을 개선할 수 있었습니까?
1. 오토인코더
서문의 이야기는 실제로 비유입니다.오토인코더(오토인코더), D.Coder는 인코더로 음역됩니다.인코더, 그것이 하는 일은 그림을 좌표로 변환하는 것이고 N.Coder는 디코더로 음역됩니다.디코더, 그것이 하는 일은 좌표를 그림으로 복원하는 것입니다. 이전 섹션에서 두 형제가 모니터링한 소득 손실은 실제로 모델 훈련에 사용된 손실 함수입니다.
스토리는 스토리이므로 오토인코더에 대한 엄격한 설명을 살펴보겠습니다. 오토인코더는 본질적으로 다음을 포함하는 신경망입니다.
하나인코더(인코더): 고차원 데이터를 저차원 표현 벡터로 압축하는 데 사용됩니다.
하나디코더(디코더): 저차원 표현 벡터를 고차원 데이터로 복원하는 데 사용됩니다.
그 과정은 아래 그림과 같으며, 원본 입력 데이터는 고차원 이미지 데이터이고, 이미지는 많은 픽셀을 포함하므로 고차원인 반면 표현 벡터는 저차원 표현 벡터이다. -2.0, -0.5]는 저차원입니다.
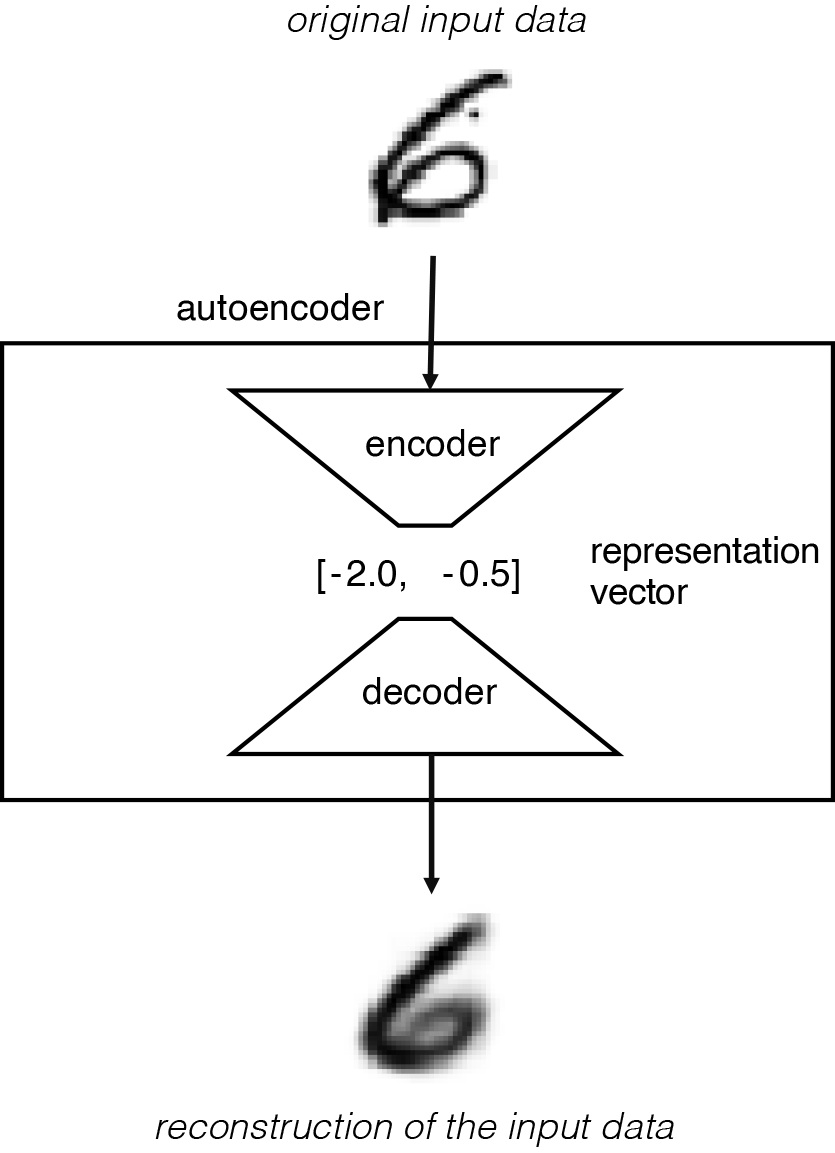
네트워크는 원래 입력과 인코더 및 디코더를 통과한 후 입력의 재구성 사이의 손실을 최소화하는 인코더 및 디코더 가중치를 찾도록 훈련됩니다. 표현 벡터는 원본 이미지를 낮은 차원의 잠재 공간으로 압축합니다. 선택에 의해잠재 공간(잠재 공간), 디코더가 잠재 공간의 점을 볼 수 있는 이미지로 변환하는 방법을 학습했기 때문에 해당 점을 디코더에 전달하여 새 이미지를 생성할 수 있어야 합니다.
서문 설명에서 N.Coder와 D.Coder는 2차원 잠재 공간(벽)을 나타내는 벡터를 사용하여 각 이미지를 인코딩합니다. 2차원을 사용하는 이유는 잠재공간을 시각화하기 위한 것인데, 실제로 이미지의 더 큰 뉘앙스를 보다 자유롭게 포착하기 위해 잠재공간은 일반적으로 2차원보다 높습니다.
2. 모델 분석
2.1 첫 번째 회의
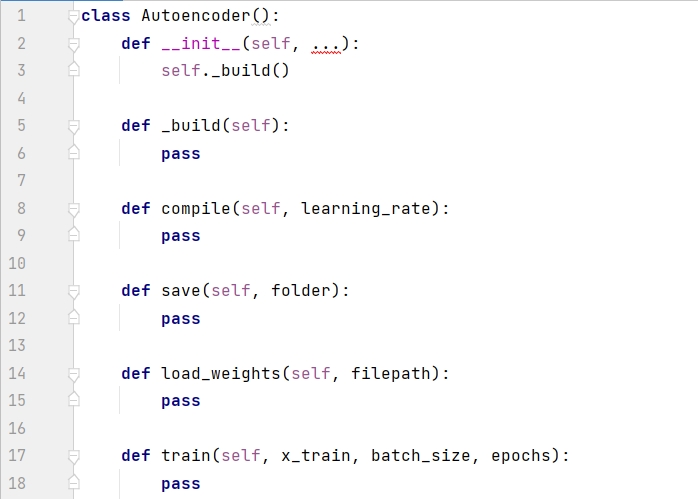
일반적으로 말하면, 아래의 Autoencoder 클래스와 같이 모델의 클래스를 별도의 파일로 생성하는 것이 가장 좋습니다. 이렇게 하면 다른 프로젝트에서 이 클래스를 유연하게 호출할 수 있습니다. 다음 코드는 먼저 Autoencoder의 프레임워크를 보여줍니다. __init__()는 생성자입니다. 모델은 _build()를 호출하여 생성됩니다. compile() 함수는 옵티마이저 설정에 사용됩니다. save() 함수는 모델 저장에 사용됩니다. load_weights() 함수는 다음에 모델을 사용할 때 가중치를 로드하는 데 사용되며, train() 함수는 모델을 훈련하는 데 사용됩니다.
구성 함수에는 필수 매개변수 8개와 기본 매개변수 2개가 포함됩니다. input_dim은 이미지의 차원, z_dim은 잠재 공간의 차원, 나머지 6개의 필수 매개변수는 필터(필터) 수와 인코더 및 디코더의 필터링입니다. 커널 크기(kernel_size), 스트라이드 크기(strides).
생성자 함수를 사용하여 자동 인코더를 만들고 이름을 AE로 지정합니다. 입력 데이터는 흑백 이미지이고 크기는 (28, 28, 1)이고 잠재 공간은 2D 평면이므로 z_dim = 2입니다. 또한 6개 매개변수의 값은 모두4 목록에 있으면 인코딩 모델과 디코딩 모델 모두에 다음이 포함됩니다.4 층.
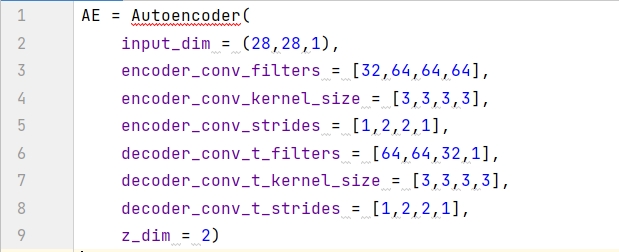
AutoEncoder 클래스에 _build() 함수를 정의하여 인코더와 디코더를 빌드하고 둘을 연결합니다. 코드 프레임워크는 다음과 같습니다(다음 세 섹션에서 하나씩 분석합니다).

다음 두 섹션에서는 오토인코더의 인코딩 모델과 디코딩 모델을 하나씩 분석해 보겠습니다.
2.2 코딩 모델
인코더의 임무는 입력 이미지를 잠재 공간의 한 점으로 변환하는 것입니다. _build() 함수에서 인코딩 모델의 구체적인 구현은 다음과 같습니다.

코드는 아래에 설명되어 있습니다.
2-3행은 이미지를 인코더에 대한 입력으로 정의합니다.
5-17행에서는 컨벌루션 레이어를 순서대로 쌓습니다.
19행은 x의 모양을 기록합니다. K.int_shape의 반환은 튜플(None, 7, 7, 64)입니다. 0번째 요소는 샘플 크기입니다. [1:]을 사용하여 데이터 모양(7, 7, 64).
20행에서는 마지막 컨벌루션 레이어를 1D 벡터로 평면화합니다.
21행의 Dense 레이어는 이 벡터를 z_dim 크기의 다른 1D 벡터로 변환합니다.
22행에서는 인코더 모델을 구축하고 Model() 함수에서 각각 인코더_input 및 인코더_출력 입력 매개변수를 결정합니다.
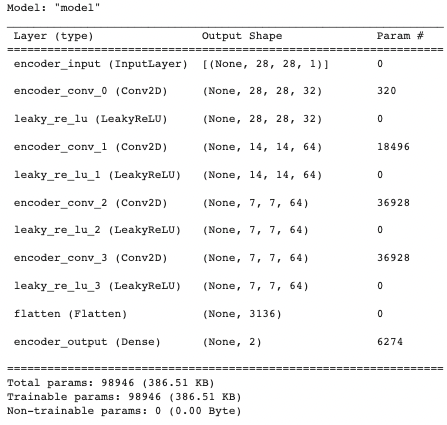
summary() 함수를 사용하여 각 레이어의 이름 유형(레이어(type)), 출력 모양(Output Shape) 및 매개변수 수(Param #)를 설명하는 데 사용되는 인코딩 모델의 정보를 인쇄합니다.

2.3 디코딩 모델
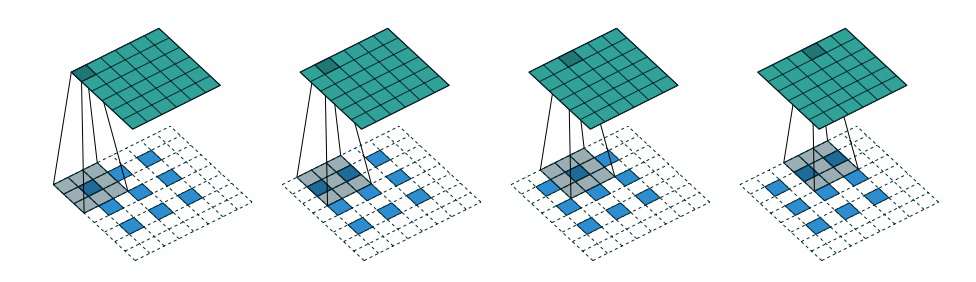
디코더는 컨벌루션 레이어를 사용하는 대신 컨벌루션 전치 레이어를 사용하여 구축된다는 점을 제외하면 인코더의 거울 이미지입니다. stride를 2로 설정하면 convolutional 레이어는 매번 이미지의 높이와 너비를 절반으로 줄이는 반면, convolutional transpose 레이어는 이미지의 높이와 너비를 두 배로 늘립니다. 구체적인 작업은 아래 그림을 참조하세요.
_build() 함수에서 디코더의 구체적인 구현은 다음과 같습니다.
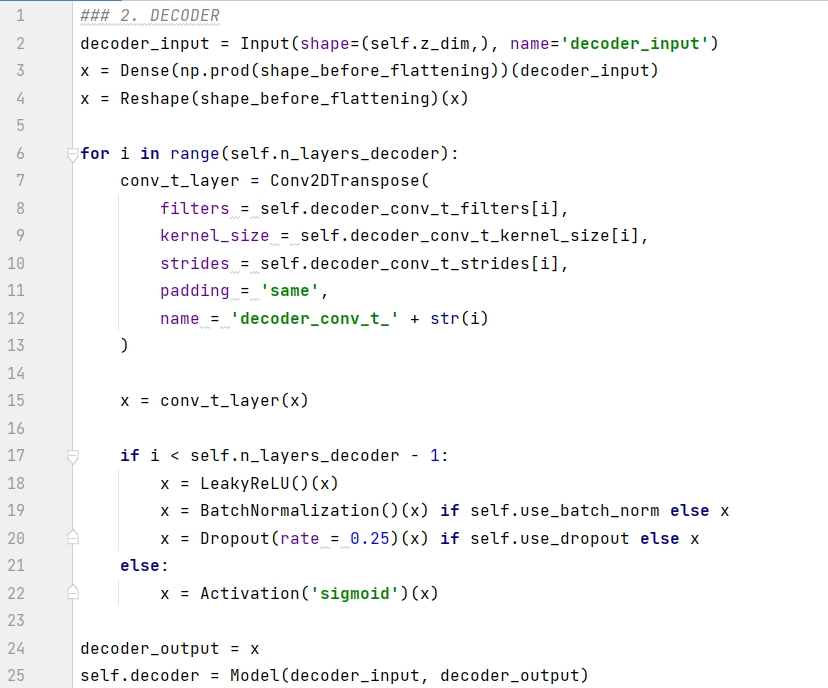
코드는 아래에 설명되어 있습니다.
라인 1은 인코더의 출력을 디코더의 입력으로 정의합니다.
2-3행은 1D 벡터를 (7, 7, 64) 모양의 텐서로 재구성합니다.
6-15행에서는 컨벌루션 전치 레이어를 순서대로 쌓습니다.
7-22행:
마지막 레이어인 경우 시그모이드 함수를 사용하여 변환하면 결과는 픽셀로 0~1 사이가 됩니다.
마지막 레이어가 아닌 경우 Leaky relu 함수를 사용하여 변환하고 배치 정규화 및 랜덤 드롭아웃 처리를 추가합니다.
라인 24-25는 디코더 모델을 구축하고 Model() 함수에서 각각 decoder_input 및 decoder_output 입력 매개변수를 결정합니다. 전자는 인코더의 출력, 즉 잠재 공간의 지점이고 후자는 재구성된 것입니다. 영상.
summary() 함수를 사용하여 디코딩 모델 정보를 인쇄합니다.


2.4 직렬 연결
인코더와 디코더를 동시에 훈련하려면 둘을 함께 연결해야 합니다.

코드는 아래에 설명되어 있습니다.
라인 1은 전체 모델의 입력 model_input으로 Encoder_input을 사용합니다(중간 제품인 Encoder_output은 인코더의 출력입니다).
라인 2는 디코더의 출력을 전체 모델의 출력 model_output으로 사용합니다(디코더의 입력은 인코더의 출력입니다).
3행에서는 오토인코더 모델을 구축하고 Model() 함수에서 입력 매개변수 model_input 및 model_output을 각각 결정합니다.
천 마디 말보다 한 장의 사진이 더 중요합니다.
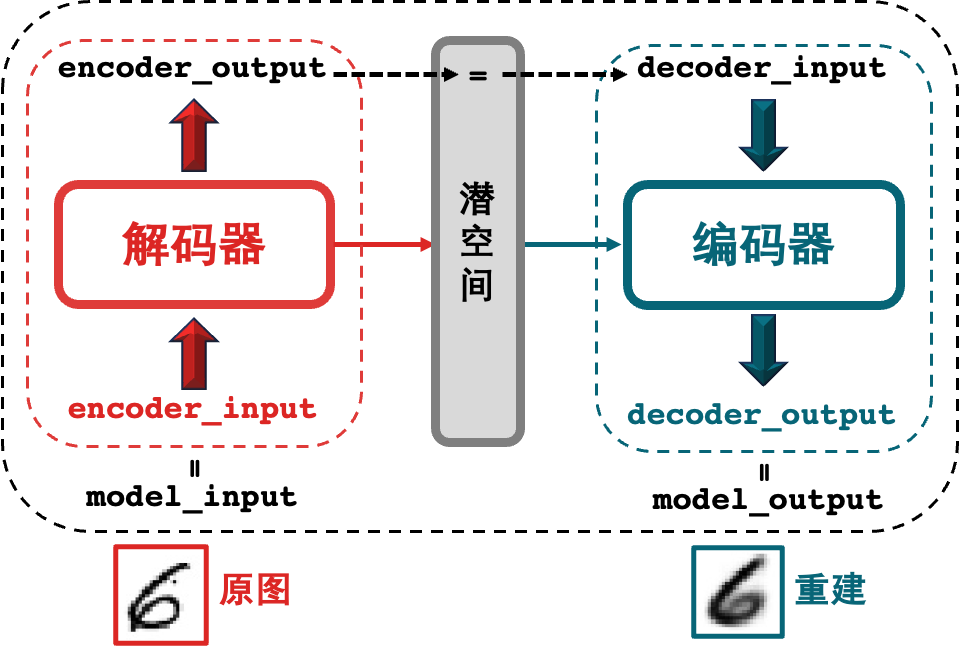
2.5 훈련 모델
모델을 구축한 후에는 손실 함수를 정의하고 최적화 프로그램을 컴파일하기만 하면 됩니다. 손실 함수는 일반적으로 평균 제곱 오차(RMSE)로 선택됩니다. compile() 함수의 구현은 Adam 최적화 프로그램을 사용하고 학습률을 0.0005로 설정하여 다음과 같습니다.


fit() 함수를 사용하여 모델을 훈련하고 배치 크기를 32로 설정하고 에포크를 200으로 설정합니다. 코드는 다음과 같습니다.


효과를 보려면 테스트 세트에서 10을 무작위로 선택하십시오.
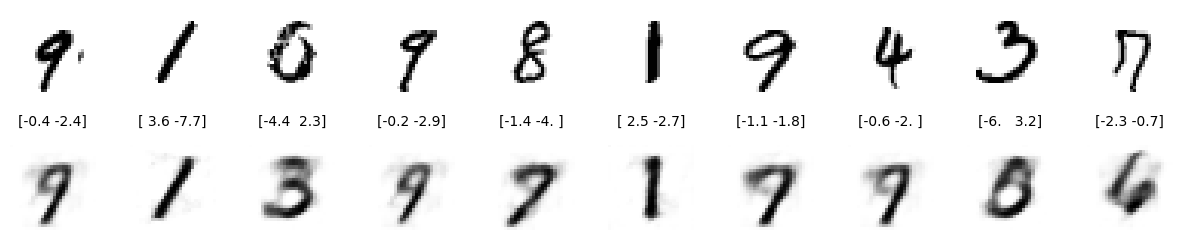
이미지 10개 중 4개만 적절한 재구성 결과를 얻었습니다.
3. 세 가지 주요 결함
모델이 훈련된 후에는 잠재 공간의 이미지를 시각화할 수 있습니다. 모델의 인코더에 의해 테스트 세트에서 생성된 좌표가 2D 산점도에 표시됩니다.
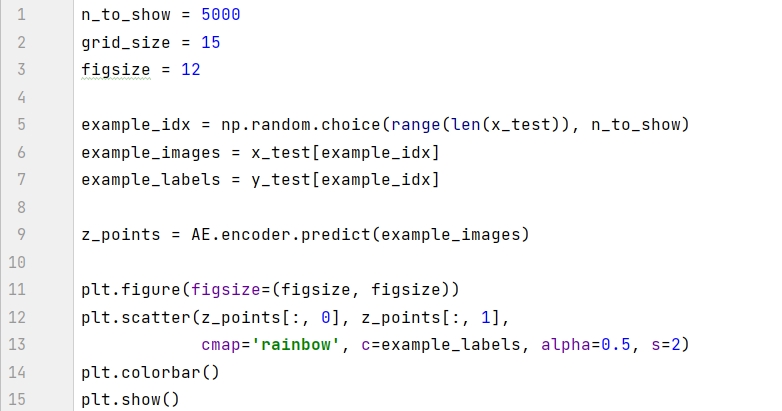
그림에는 주목할 만한 세 가지 현상이 있습니다.
일부 숫자는 빨간색 9와 같이 작은 영역을 차지하고 일부 숫자는 보라색 0과 같이 넓은 영역을 차지합니다.
그래프의 점은 (0, 0)에 대해 비대칭입니다. 예를 들어 x축에는 양수 값 점보다 음수 값 점이 더 많고, 일부 점은 x =-15에 도달하기도 합니다.
위 이미지의 왼쪽 상단처럼 아주 적은 수의 점을 포함하는 색상 사이에 큰 간격이 있습니다.
위의 세 가지 주요 결함으로 인해 잠재 공간에서 샘플링하는 것이 매우 어렵습니다.
결함 1의 경우 숫자 9가 0보다 더 큰 면적을 차지하므로 9를 샘플링하는 것이 더 쉽습니다.
결함 2의 경우 기술적으로 평면의 모든 지점을 샘플링할 수 있습니다. 그러나 각 숫자의 분포는 불확실하며 분포가 대칭적이지 않으면 무작위 샘플링이 작동하기 어렵습니다.
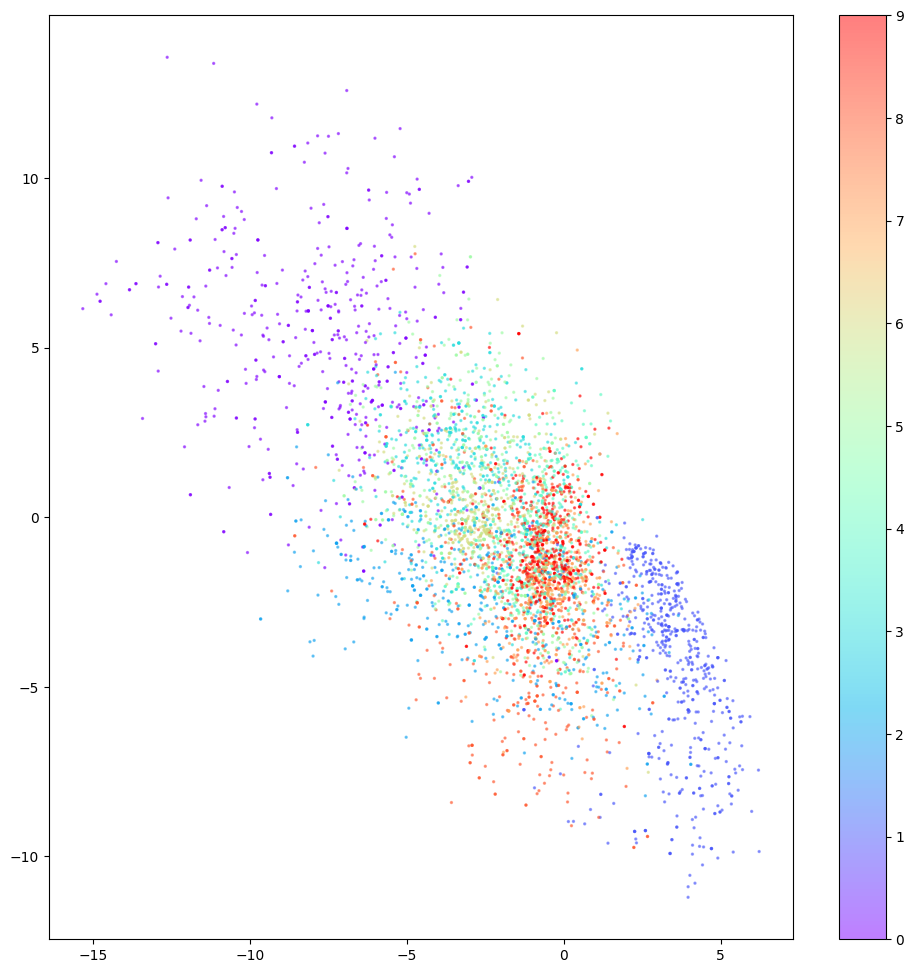
결함 3의 경우, 잠재 공간의 공백에서 일부 적절한 숫자를 재구성할 수 없음을 아래 그림에서 볼 수 있습니다.
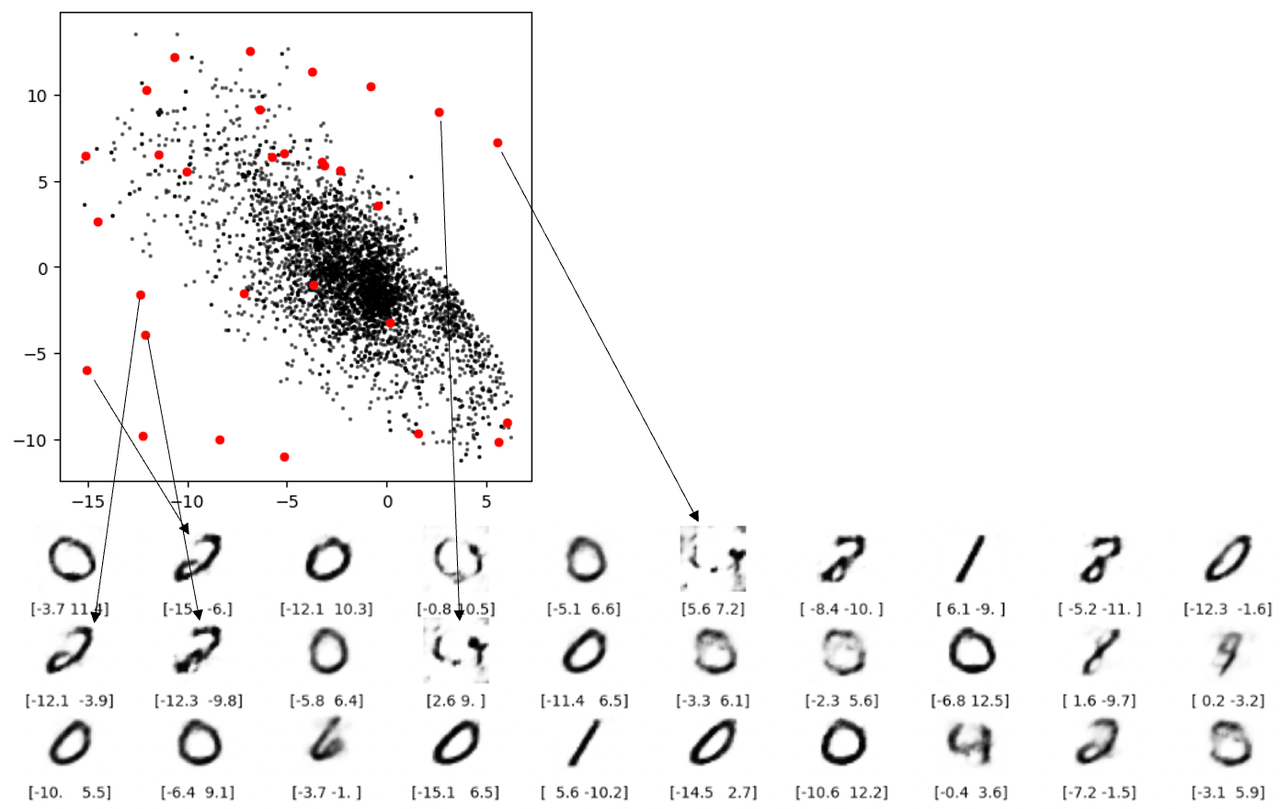
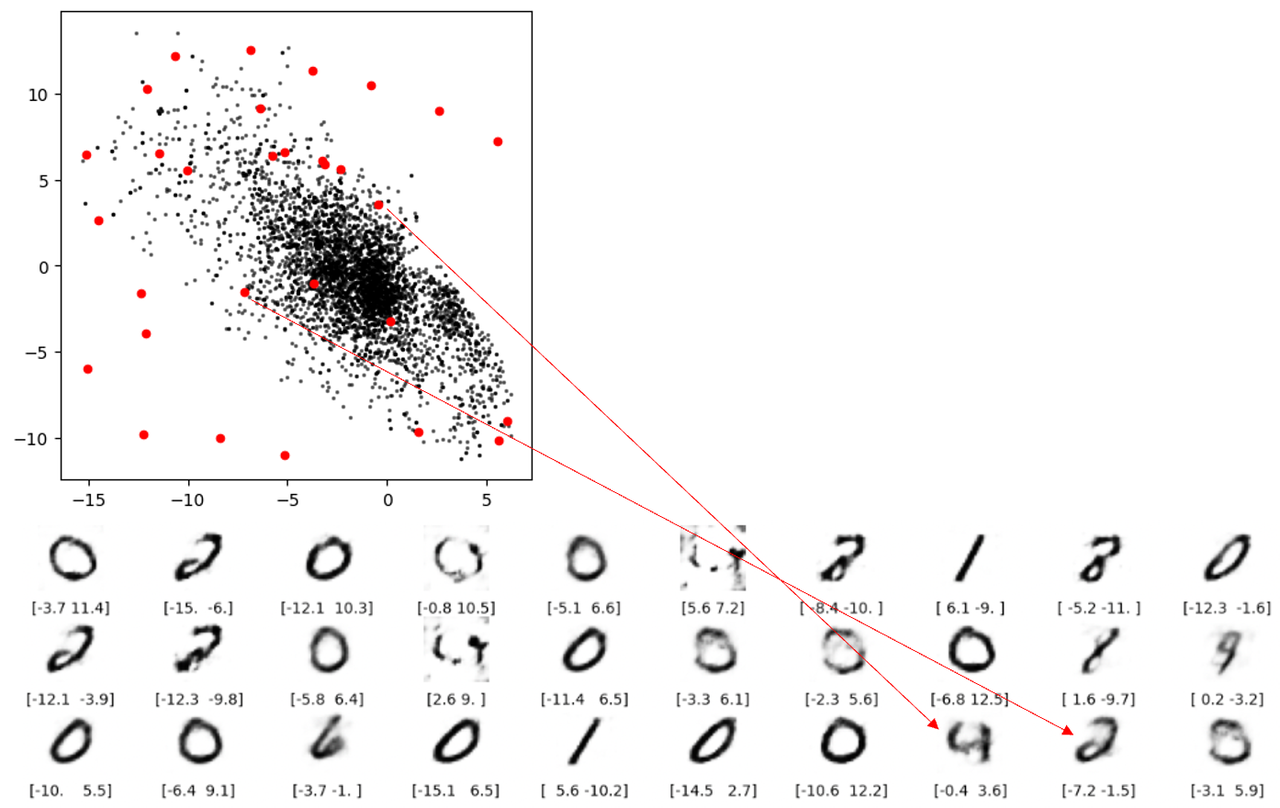
결함 3: 공백 상태에서는 재구성이 숫자를 생성할 수 없다는 것을 이해하기 쉽지만, 아래 그림에서 두 개의 빨간색 선으로 표시되는 재구성은 걱정스럽습니다. 두 지점 모두 여백에 없지만 여전히 적절한 숫자로 디코딩되지 않습니다. 근본적인 이유는 오토인코더가 생성된 잠재 공간이 연속적이라는 보장을 강제하지 않기 때문입니다. (2.1, – 2.1 )도 만족스러운 숫자 4를 생성합니다.
요약하다
오토인코더는 기능만 필요하고 레이블은 필요하지 않으며, 데이터를 재구성하는 데 사용되는 비지도 학습 모델입니다. 이 모델은 생성 모델이지만 이전 섹션에서 언급한 세 가지 주요 결함으로 인해 이 생성 모델은 저차원 흑백 숫자에는 적합하지 않으며 고차원 컬러 면에 대한 효과는 더욱 악화됩니다.
이 오토인코더 프레임워크는 훌륭하므로 강력한 오토인코더를 생성하려면 이 세 가지 결함을 어떻게 해결해야 할까요? 다음 글의 내용은 이렇습니다.변형 자동 인코더 (Variational AutoEncoder, VAE)。

ChatGPT 4.0 플러그인 스토어에서 SignalPlus를 검색하시면 실시간 암호화 정보를 얻으실 수 있습니다. 업데이트를 즉시 받으려면 Twitter 계정 @SignalPlus_Web 3을 팔로우하거나 WeChat 그룹(WeChat 보조자 추가: SignalPlus 123), Telegram 그룹 및 Discord 커뮤니티에 가입하여 더 많은 친구들과 소통하고 소통하세요.
SignalPlus Official Website:https://www.signalplus.com


