
When reasoning becomes a scarce resource, who captures the value
- Core Thesis: The compute bottleneck in the AI industry has shifted from training to inference, and the market is repricing accordingly. Value will no longer solely accrue to companies owning the most GPUs, but will settle in the middle layer that can aggregate, route, and optimize fragmented inference compute—such as asset-light platforms like Hyperbolic.
- Key Elements:
- Inference Becomes the New Bottleneck: The market recognizes inference as a recurring cost (scaling with usage) rather than the one-time capital expenditure of training. J.P. Morgan estimates the inference market to be 10-50 times larger than training, evidenced by Anthropic taking over data centers dedicated to inference.
- Confirmation from Industry Giants: Nvidia has restructured its financial reporting around "serving tokens," dividing inference into two fronts (cloud and edge) and releasing chips with significantly improved inference performance. Cerebras' IPO was 20 times oversubscribed, driven by its chip architecture focused on inference acceleration.
- Answering the "600 Billion Dollar Question": The AI investment return gap identified by Sequoia will be filled by growing inference demand, not training. The normalized demand for inference will absorb the previous overbuilding of GPU capacity.
- Hyperbolic's Value Proposition: As the only company spanning GPU rental, deployment, and model APIs, Hyperbolic profits by aggregating multi-cloud compute resources and providing real-time pricing data. Its asset-light model allows it to capture spreads more effectively when compute is in surplus.
- Thin Margins in the Application Layer, Value in the Middle Layer: Inference applications like Venice are constrained by upstream compute costs, resulting in razor-thin profits. Their economic model reveals that underlying compute is the primary cost, reinforcing the value of the aggregation layer (like Hyperbolic) that controls compute routing and pricing.
原文著者:Frank Fu
原文出所:IOSG Ventures
2023年にDavid Cahn氏が指摘したあの「穴」は、トレーニング側では決して埋まらなかった。それが推論(inference)側で埋められ、市場がそれを価格に織り込み始めたのは、つい数週間前のことだ。NVIDIAが「トークンサービス」を軸に財務報告を再編し、CerebrasのIPOが20倍の需要超過となった今、ボトルネックを巡る議論は終結した。真の問いは次のものへと移った:推論が希少リソースとなったとき、その価値はコンピュートスタックのどの層に堆積するのか。
GPUの流れを追う:2000億ドルの問題から6000億ドルの問題へ
2023年、Sequoia CapitalのDavid Cahn氏は、AI構築全体に影を落とす「2000億ドルの問題」を提起した。GPUに1ドル投資するごとに、データセンターでの電力供給にも約1ドルが必要となる。つまり、毎年のGPUへの設備投資(CapEx)は、最終的にこれらのチップが約2000億ドルの収益を生み出さなければ、投資を回収できないことを意味する。AI収益に対して非常に楽観的な仮定を置いても、投資額とエンドユーザーが実際に支払う額との間には、1250億ドル以上のギャップが存在することが明らかになった。その懸念は率直だ:GPUは実際の需要を上回るペースで過剰に建設されている、というものだ。
1年後、そのギャップは縮まるどころか拡大した。Cahn氏は2024年の続編で、ハイパースケーラー企業のCapEx膨張に伴い、これを「6000億ドルの問題」と再定義した。弱気派の論理は、過剰建設が供給過剰を招き、供給過剰が資本を焼き尽くすという、おなじみの形に収束する。
両方の記事が問うているのは同じことだ:誰がこの穴を埋めるのか?その答えは、トレーニング側の帳簿には決して現れなかった。それは推論(inference)側に現れ、市場がそれを価格に織り込み始めたのは、つい数週間前のことなのである。
CerebrasのIPOと推論の逼迫
Cerebrasは木曜日に上場した。このIPOは20倍の需要超過となり、価格は水曜日の最終的な値上げの約2倍に設定された。その需要は、「次のNVIDIAキラー」への賭けから来たわけではない。もっと単純な理由、つまり市場がAIにおける真のボトルネックはトレーニングではなく推論であると認識し始めたことにある。
Cerebrasの最大の強みは、推論を極めて高速にするチップアーキテクチャである。トレーニングではなく、推論だ。これこそがウォール街を興奮させている点だ。推論市場は継続的なものであり、使用量とともに拡大する。Claudeが質問に答えるたび、エージェントがタスクを実行するたびに、コンピュートが消費される。トレーニングは一度だけ発生し、推論は決して止まらない。
J.P. Morganは、推論市場の規模をトレーニングの10倍から50倍と推定している。機械が他の機械から指示されたタスクを実行する、すなわちエージェンティック(agentic)な拡大が進むと、推論の需要はユーザー数ではなく、コンピュートそのものに応じて拡大する。
NVIDIAが地図を描き直す:推論がトップニュースに
Cerebrasが市場の覚醒だとすれば、NVIDIAの最新四半期決算は、産業チェーンの頂点からの確証である。最新の決算説明会で、Jensen Huang氏は誰もが心の中で思っていたことを明言した:AI需要は放物線的に成長している。その理由は単純だ:エージェンティックAIが到来したのである。主流のAIは、一度きりの推論から論理的推論へ、そして自らツールを呼び出しタスクを調整するエージェント段階へと移行した。Huang氏は「トークンは今や収益性がある」と述べた。AI時代において、コンピュートは収益であり利益である。
これにより業界全体が再編された。トレーニングはモデルを構築するための一度きりのコストであり、推論はそれを運用するための継続的なコストである。そして現在のボトルネックはトレーニングではなく、推論にある。
NVIDIAはこの判断を自社の決算報告の枠組みに書き込んだ。現在、同社は単一のプラットフォームではなく、Data Center(データセンター)とEdge Computing(エッジコンピューティング)の2つのプラットフォームで業績を開示している。データセンター(当四半期約750億ドル、前年同期比+92%)は、さらにHyperscale(ハイパースケール:約380億ドル、前期比+12%)とACIE(AIクラウド、産業・エンタープライズ:約370億ドル、前期比+31%)に区分される。新たに設けられたラインはEdge Computingである:64億ドル、前年同期比+29%を記録し、エージェンティックAIやフィジカルAIが実際に稼働するエンドポイント(PC、ワークステーション、AI-RAN基地局、ロボット、自動車など)をカバーする。
エッジは現在、総収益の8%未満を占めるに過ぎないが、NVIDIAはこれをデータセンターと並ぶ「第二のプラットフォーム」に格上げした。このシグナルは、推論が2つの戦線に分断されつつあることを示している:データセンター内のクラウド推論と、エッジ側のエンドポイント推論。AIは物理世界で認識し、移動し、行動しなければならない。ロードマップも同様の論理に従う:第3四半期から出荷が開始されるVera Rubinは、Blackwellと比較して最大35倍の推論スループットを実現する。Huang氏は、エージェンティックワークロード向けに設計されたVera CPUに対しても、新たに2000億ドルのTAM(製品市場規模)を見込んでいる。すべてのフロンティアモデル企業は、初日から全面的にこれに移行すると予想される。
地球上で最も価値のある企業が「トークンサービス」を軸に財務情報を再編した時点で、ボトルネックを巡る議論は決着した。本稿の残りの部分では、推論(トレーニングではなく)が希少リソースとなった後、その価値を誰が獲得するのかについて論じる。
最初に範囲を明確にする。これら2つの戦線のうち、本稿で論じるのはクラウド推論、すなわち外部にAPIトークンサービスを提供する、レンタルされたデータセンターGPUである。エンドポイント推論は、デバイス自体の内部にあるローカルチップ(NVIDIAのJetson、RTX、Drive、AI-RAN)上で動作し、その下層にあるGPUレンタル・集約スタックを一切経由しない。ここでは、これを推論経済全体を拡大し、ボトルネック論を補強する追い風として捉えていただきたい。HyperbolicやVeniceが属する市場(両社は完全にクラウド推論のライン上にある)とは区別される。
逼迫はすでに到来している
Anthropicは炭鉱のカナリアである。使用量があらかじめ設定されたキャパシティをはるかに超え、Claudeが「脳葉切除(lobotomized)」されたかのような苦情がネットを席巻している。制限された応答、遅くなる推論、圧縮されたコンテクストウィンドウ。その解決策は赤裸々なコンピュートである:2026年5月、AnthropicはSpaceXからColossus 1データセンター全体(22万枚以上のNVIDIA GPU、300+メガワット)を引き継ぎ、トレーニングではなく推論専用に割り当てた。
このキャパシティの解放により、一連の制限変更が相次ぎ、それぞれが一つのシグナルとなった。5月6日、AnthropicはClaude Codeの5時間制限を2倍に引き上げ、ピーク時のレート制限を撤廃し、OpusのAPIレート制限を大幅に引き上げた。5月13日には、Claude Codeの週間制限をさらに50%引き上げた(7月13日まで)。その後、6月15日からは、「寛大さ」とは逆の措置を取った:エージェンティックおよびプログラムによる使用(Agent SDK、ヘッドレスモード claude -p、CIパイプライン)を定額サブスクリプションから切り離し、独立した従量制のクレジットプール(月額20~200ドル、API価格で課金)に移行した。この最後の一手は、あらゆる論点を一つの動作に凝縮している:エージェントが推論を消費する速度は、定額サブスクリプションの設計が耐えられる範囲をはるかに超えており、したがって、本来の「継続的コスト」として価格設定されなければならない、ということである。
トレーニングは一度きりの設備投資である。推論は継続的な運用コストであり、新しいユーザー、新しいエージェントが増えるたびに複利的に累積する。
このスタック:6つの層、一つのボトルネック
すべてのAIアプリケーションは、TSMCのファブから始まりAPIエンドポイントで終わるサプライチェーンの上に成り立っている:

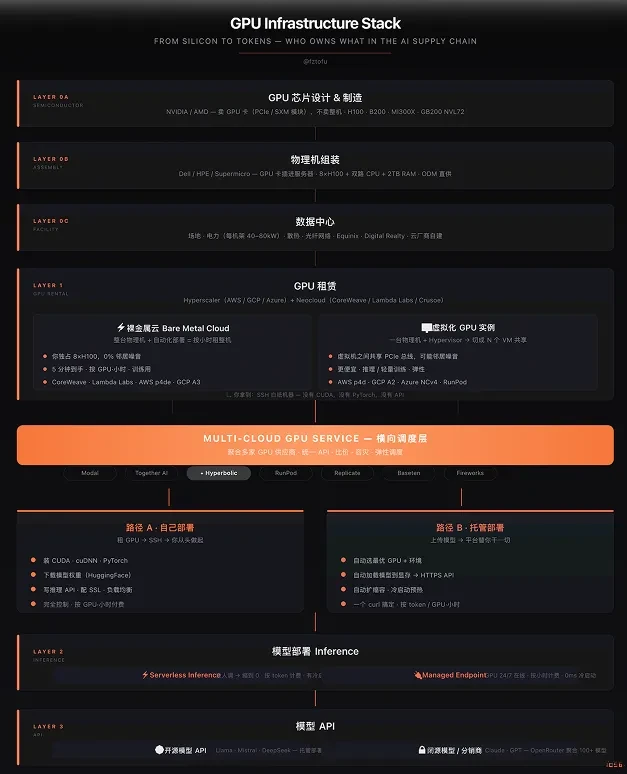
ほとんどの企業は、このうちの一層のみを所有している。NVIDIAはシリコンを、CoreWeaveはベアメタルを、Together AIは推論最適化を、OpenRouterはモデルAPIルーティングを所有する。
ただ一社だけ例外がいる。
Hyperbolic:3つのレイヤーにまたがる唯一の企業
Hyperbolicは2025年6月に、オンデマンドGPUマーケットプレイスを立ち上げた。最初の数ヶ月でデベロッパー数は20万以上に達し、導入企業はフロンティアAIラボ、検索エンジン、大手コンシューマープラットフォームにまで広がっている。
興味深いのはそのアーキテクチャだ。
Hyperbolicは自社では1枚のGPUも保有していない。すべてのカードは、CoreWeave、Lambda Labs、Nebius、そして遊休キャパシティを抱える小規模オペレーターを含む、neo-cloudやデータセンターから調達している。これは弱点のように聞こえるが、実際には参入障壁(護城河)である。
GPUの供給側と消費側の間に位置することで、Hyperbolicは他社には見えないリアルタイムデータを把握できる。誰が、いくらで、いつ、どのGPUを購入しているのかを知っている。供給過剰が表面化する前にそれを認識し、需要急増が市場を直撃する前にそれを察知する。
現在、この参入障壁こそがマルチクラウド集約そのものである。Hyperbolicは、数十の独立したクラウドやデータセンターからの断片化されたキャパシティを、標準化された統一プールに縫い合わせる。これにより、デベロッパーは個々のオペレーターと交渉したり、多数のアカウントを管理したりすることなく、どこでも最も安価な利用可能なGPUをレンタルできる。接続するクラウドが増えれば増えるほど、流動性は深まり、価格データは豊富になる。さらに、チームはこれらのデータを使ってGPU価格曲線をモデル化し、最終的には自己資本を投入して需給を平滑化し、物理的なコンピュートのマーケットメーカーとして機能することを模索している。しかし、この目標はまだ初期段階にあり、現在実際に複利効果を生み出しているのは集約レイヤーである。
これがフライホイールだ:
- より多くのクラウドに接続 → より多くの集約された供給
- より多くの供給 → より深い市場とリアルタイムの価格データ
- より良いデータ → 現在はよりスマートなルーティング、長期的には価格モデル
- より良い流動性と価格 → より多くのデベロッパー → より多くのクラウドが接続を望む
これに挑戦している他の企業はない。Hyperbolicは、GPUレンタル層、デプロイメント層、モデルAPI層の3層にまたがる唯一の企業である。
Veniceという鏡
Veniceは、推論経済のアプリケーション層における最も明確な具現化であり、Hyperbolicの位置づけを理解する上で有用な対照例である。Veniceはプライバシー優先の推論アプリケーションである:OpenAI互換のAPIと、コンシューマー向けのサブスクリプション(Free / Pro / Pro+ / Max)を備え、リクエストを約75のモデルにルーティングする。そのうち約3分の2はオープンソースまたはセルフホストモデル(Llama、Mistral、Qwen、DeepSeek)であり、残りはクローズドソースのフロンティアモデルへの匿名透過(パススルー)である。重要なのは、Venice自身は有意義なコンピュートを所有していないことだ。未公開のGPUパートナーや機密コンピューティングベンダー(NEAR AI Cloud、Phala)からレンタルし、フロンティアラボには透過アクセス料を支払っている。したがって、Veniceの真の売上原価(cost of revenue)は、SaaSホスティングではなく、推論コンピュートである。
Veniceが実際に販売しているのはプライバシーである。ここで言う「プライバシー化」とは、公共コンピュートを私有財産に変えることではなく、コモディティ化された推論に、データを保持しない、トレーニングに使用しない、リクエストを匿名化する、一部の負荷はTEE内で実行されオペレーター自身も平文を見ることができない、といった保証を付与することである。基盤となるコンピュートはありふれたものであり、値段が上乗せされるのはこのプライバシー包装である。そして、この保証は階層化されており、均質ではない:自社制御下またはTEE GPU上で実行されるオープンソースモデルに対しては、エンドツーエンドの機密コンピューティングに近いものを実現できる。しかし、ClaudeやGPTのようなクローズドソースモデルへの匿名透過の場合、プライバシーとは身元を剥奪することであり、フロンティアラボ側は依然として元のプロンプトを処理している。したがって、最も強力なプライバシーはオープンソース部分のみをカバーし、フロンティアモデル部分は「真の機密」ではなく「匿名」である。Veniceの粗利 = サブスクリプション価格 − 下流に支払う推論コストであり、裸のAPI価格よりも多く請求できる部分は、ほぼこのプライバシープレミアムによって支えられている。これが、Veniceの利益率が薄く、フロンティアモデルへの透過価格設定に制約される理由でもある。
トークン設計は、この推論需要を包装している。Veniceは2つのトークンで運用されている:VVV(ステーキングとプラットフォームアクセス)とDIEMで、後


