
黄仁勳の「Agent工場」には、どんな新たなストーリーが詰まっているのか?
- 核心見解:エヌビディアはCOMPUTEX 2026において、「Agent AI」を軸に、チップ、モデルからロボットプラットフォームに至る包括的な技術体系を構築すると発表。Vera Rubinプラットフォームを量産し、Agentタスク向けに最適化することで、AI工場をインフラ段階から運用・展開の新時代へと押し上げることを目指す。
- 主要要素:
- Vera RubinプラットフォームはAgent向けに設計され量産。処理効率は前世代のGrace Blackwellの10倍で、初めてCPOネットワーク技術と機密計算を大規模に導入。
- 同社はAI時代向けに設計されたVera CPUを発表。Agentワークロード性能は同世代のx86サーバーの1.8倍で、すでに全面生産体制。
- DSX工場運用システムをリリース。MaxLPS(電力最適化)とDSX OS(運用管理)を含み、AIデータセンターの建設と運用の標準化を目指す。
- 5,500億パラメータのMoE(混合専門家)モデルNemotron 3 Ultraと、オープンソースのAgentフレームワークNemoClawを公開。企業向け「デジタル同僚」の構築を目指す。
- 第3世代物理AIモデルCosmos 3を発表。視覚推論、生成、動作予測を統合し、物理AIのトレーニングサイクルを数ヶ月から数日に短縮することを目指す。
- 宇樹科技(Unitree)と協業し、人型ロボットのリファレンスデザインH2 Plusを発表。物理AIの「スキル」ツールセットをオープンソース化し、ロボット開発のハードルを低減。
- Vera BlueField-4 STXはストレージセキュリティを強化。チップレベルでのポリシー実行により、Agentと企業データ間のインタラクションの安全性を確保。
原文作者:李海伦 苏扬
原文编辑:徐青阳
原文来源:腾讯科技
2026年6月1日、COMPUTEX 2026期間に開催されたNVIDIA GTC Taipeiで、NVIDIAの創設者兼CEOであるジェンスン・フアン(黄仁勲)氏が基調講演を行いました。
前回のGTCから、わずか3ヶ月です。
当時、NVIDIAはVera Rubinの「チップフルセット」を発表しました。これには、Vera CPU、Rubin GPU、Groq 3 LPU、ConnectX-9、BlueField-4 DPU、Spectrum-6スイッチが含まれ、6つのチップが1つのラックレベルのAIスーパーコンピューターを構成します。そして、大規模MoEモデルのトレーニングに必要なGPU数を4分の1に削減し、推論スループットをワットあたり10倍向上、単一トークンあたりのコストを10分の1にすると発表しました。
「チップフルセット」や「コンピューティングフルセット」といったシステムレベルのソリューションを強調した以前とは異なり、3ヶ月後のCOMPUTEXで、ジェンスン・フアン氏はこれらのインフラストラクチャが最終的にサービスを提供する対象であるエージェントに焦点を当てました。
ジェンスン・フアン氏は講演で、Vera Rubinが正式に量産段階に入ったこと、Vera CPUの全世界への出荷が開始されたこと、DGX Stationが初めてWindowsフォームで企業のデスクトップに登場したこと、Cosmos 3が物理AIの知覚フレームワークを再構築したこと、そしてDSXがAIファクトリーの運用オペレーティングシステムになったことを明らかにしました。NVIDIAはUnitreeと共同で、Isaac GR00Tに基づく初のヒューマノイドロボットリファレンスデザインであるH2 Plusも発表し、エージェントの境界をデジタル世界から物理的な形態へと拡張しました。
NVIDIAは、エージェントエコシステムを中心に、チップ、データセンター、モデル、ソフトウェア、ロボットプラットフォームに至る完全な技術スタックを再編成しつつあります。
ジェンスン・フアン氏は、「エージェントAIと実用的な人工知能の時代が到来しました。今やトークンは利益の単位であり、AIはGDPの『ジェネレーター』です。ソフトウェアエンジニアの数は増加しています。AIが雇用を減少させるという話は完全なナンセンスであり、実際にはより多くのソフトウェアエンジニアが雇用されています」と述べました。

同じAIファクトリーで、10倍のエージェントタスクを実行
Vera Rubinプラットフォームは完全に生産体制に入っています。
主に大規模言語モデルのトレーニングと推論を対象としていた以前とは異なり、Vera Rubinは設計の初期段階からエージェントを主要なワークロードとして考慮しています。
ジェンスン・フアン氏は講演で、エージェントタスクは多くの場合、単なるモデル推論ではなく、推論、検索、ツール呼び出し、コード実行、結果検証など複数のステップを含み、その背後には数千ものステップが関与する可能性があると述べました。将来のデータセンターが処理する必要があるのは、単一のモデルリクエストだけでなく、継続的に実行され相互に協調する大量のエージェントタスクです。
このプラットフォームは、推論、検索からツール使用に至るエージェントワークロードを処理するために構築された、巨大で統一されたコンピューティングユニットレベルのAIスーパーコンピューターとして定義されています。同規模の超大規模データセンターにおいて、新しいVera Rubinプラットフォームで自律型AIエージェントのタスクを実行する場合、その処理効率は前世代のGrace Blackwellプラットフォームの10倍になります。
コンピューティングプラットフォーム自体に加えて、ネットワークもVera Rubinアップグレードの重要な焦点の一つとなっています。
従来のデータセンターでは、GPU間のデータ転送は主に従来の光モジュールとスイッチアーキテクチャに依存していました。しかし、クラスターの規模が拡大し続けると、消費電力、放熱、導入の複雑さが急速に増大します。そのため、NVIDIAはVera RubinプラットフォームにSpectrum-X Ethernet Photonicsネットワークシステムを導入しました。
これは、NVIDIAが共同パッケージ光学(CPO)技術を大規模にAIデータセンターネットワークに導入する初めてのケースです。
簡単に言えば、従来のソリューションでは光モジュールをスイッチの外部に差し込む必要がありましたが、CPOは光学デバイスを直接スイッチ内部に統合することで、消費電力と信号損失を削減します。
さらに、セキュリティも今回のVera Rubinプラットフォームで重点的に強調された中核的な機能です。
このため、NVIDIAは機密コンピューティング機能をVera Rubinプラットフォーム全体に拡張しました。信頼できる実行環境、ハードウェアレベルの検証、エンドツーエンドの暗号化メカニズムを通じて、企業はプライベートデータ、業界の機密情報、重要なモデルを扱う際に、より高度なセキュリティ保証を得ることができます。
ジェンスン・フアン氏は、Vera Rubinが量産段階に入ったことを明らかにしました。第3世代のMGXラックレベルシステムとして、その背後には150以上のパートナー、350以上の工場、そして30以上の国と地域をカバーするサプライチェーンが関わっています。NVIDIAが発表した計画によれば、Vera Rubinは今年の秋から正式に出荷が開始される予定です。

「エージェントのために生まれた」プロセッサ
NVIDIAは、エージェント時代のために設計された新しいプロセッサVeraを発表し、完全に生産を開始しました。
ジェンスン・フアン氏は、メモリシステムの進歩がストレージシステムの革新と近代化を促進すると指摘しました。これまでのCPUはすべて人間のために作られてきましたが、VeraはAI時代のために設計され、エージェントのために作られたCPUです。
Graceの後継として、VeraはNVIDIAが自社設計した「Olympus」CPUコアアーキテクチャを採用し、コア数は72から88に増加し、メモリとデータ処理能力が大幅に向上しています。NVIDIAによると、エージェント関連のワークロードテストにおいて、Veraのタスク実行速度は同等のx86サーバーCPUの1.8倍に達します。
単なるパフォーマンス向上よりも重要な変化は、VeraとRubin GPUの関係にあります。Veraは第2世代NVLink-C2Cを介してRubin GPUに接続され、相互接続帯域幅は1.8TB/sに達し、エージェント実行中にCPUとGPU間でデータを転送する際のオーバーヘッドをさらに低減します。
ジェンスン・フアン氏は、Vera RubinがMicron、SK hynix、SamsungのHBMを使用しており、サプライチェーンの規模は前世代のBlackwellの「2倍」であると述べました。ただし、大規模なBlackwellラックの展開には2時間かかりますが、Vera Rubinの場合は5分レベルに短縮されました。
AIファクトリーを「建設」から「運用」へ
NVIDIAが今回発表したDSXは、「AIファクトリー建設・運用ツールボックス」と理解することができます。
これまでAIデータセンターを建設する際、顧客はサーバー、ネットワーク、電力、冷却、サーバールーム設計、運用保守システムをそれぞれ個別に考慮する必要があり、多くの部分が異なるサプライヤーの連携に依存していました。DSXが目指すのは、これらの従来は分散していた要素を単一のフレームワークに統合し、顧客が設計、シミュレーション、建設から運用に至るまで、参照・検証可能な標準ソリューションを提供することです。
ジェンスン・フアン氏は発表会で、「NVIDIAは単にチップを販売するのではなく、インフラ建設者に完全なAIファクトリーの青写真を提供する」と述べました。
今回のDSXで最も重要な新機能は主に2つあります。
1つ目はDSX MaxLPSです。これはAIファクトリーの最も現実的な問題を解決します。すなわち、電力予算が固定されている場合に、より多くのGPUを設置し、より多くのトークンを生成する方法です。
NVIDIAの説明によれば、MaxLPSは液冷とラック内の消費電力最適化を組み合わせることで、オペレーターは性能に大きな影響を与えることなく、最大40%多くのGPUを稼働させることができます。
2つ目はDSX OSです。これはAIファクトリーの運用ソフトウェアに相当し、ライフサイクル管理、インテリジェントスケジューリング、ヘルスモニタリング、障害復旧、マルチテナント管理などを担当します。簡単に言えば、AIファクトリーが複雑な工場である場合、DSX OSはこの工場を継続的かつ安定して稼働させる役割を担います。
DSXのプロダクトマトリックスにおいて、Reference DesignはAIファクトリーのリファレンスデザインを提供し、サーバールーム、ラック、ネットワーク、電力、冷却システムをどのように構築すべきかを顧客に示します。DSX Simはシミュレーションを担当し、顧客が建設前に設計の実現可能性を検証できるようにします。DSX FlexはAIファクトリーと電力網を接続し、データセンターが電気料金、負荷、需要応答信号に基づいてタスクを調整できるようにします。DSX Exchangeは、ITシステム、運用システム、エネルギー、冷却システム間のデータインターフェースを統合する役割を果たします。
エコシステム面では、CoreWeave、Crusoe、LambdaなどのクラウドパートナーがDSX Sim、MaxLPS、DSX OSを導入し、リスクを低減しGPU利用率を向上させています。Dell、HPE、Lenovo、Supermicro、そしてASUS、Foxconn、GIGABYTE、QCTなどのメーカーがDSXをサポートするシステムを構築しています。
WindowsおよびARMとの連携
基調講演で、ジェンスン・フアン氏は「DGX Station for Windows」ワークステーションを正式に発表し、NVIDIAはこれをWindowsエコシステム向けのデスクトップレベルのAIスーパーコンピューターと位置づけました。
ハードウェア面では、GB300 Grace Blackwell Ultra Desktop Superchipを搭載し、NVLink-C2Cを介してBlackwell Ultra GPUと72コアのGrace CPUを接続します。最大748GBのユニファイドメモリと20 PFLOPS FP4の性能を提供し、最大800Gb/sのネットワーク能力を備えています。
この製品の重点は、エージェントの展開方法の変化にあります。
NVIDIAは、企業がローカルかつ安全で管理可能なWindows環境で複数のエージェントを実行し、それらを設計、エンジニアリング、データサイエンス、推論、Physical AIなどのワークフローに統合できることを期待しています。同時に発表されたOpenShellはエージェントの実行セキュリティを担当し、分離されたサンドボックスとシステムレベルのポリシー制御を通じて、エージェントの権限昇格や資格情報・プライベートデータの漏洩を制限します。
企業向けデスクトップ製品に加えて、ジェンスン・フアン氏はシステムオンチップ(SoC)であるRTX Spark SoCも発表しました。これはN1X CPUとBlackwell GPUを1つのチップに統合し、ユニファイドメモリアーキテクチャを採用し、薄型軽量ノートPCや小型デスクトップ向けに設計されています。
N1Xは、NVIDIAとMicrosoftが共同で開発した初のPCプロセッサであり、Armアーキテクチャに基づき、MediaTekがカスタム設計し、TSMCの3nmプロセスで製造されます。今年の秋に、Microsoft、Dell、HP、ASUS、Lenovo、MSIのノートPCに初めて搭載され、初回は30以上のモデルがラインアップされ、主にハイエンドの薄型軽量ノートPCを対象としています。
これはNVIDIAがAI PC時代に向けて準備した「スーパーコア」であり、ジェンスン・フアン氏はこれをPCの形態における重要な再構築と見なしています。
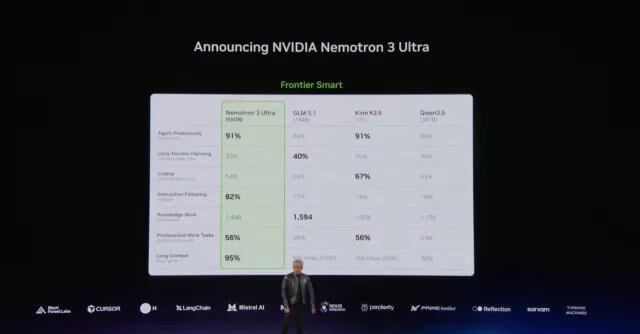
エージェントの「2つの頭脳」
今回の発表会で、NVIDIAは2つのコアモデル製品ラインの最新状況を発表しました。これらはエージェントの2つのシナリオに対応しています。1つは企業システム内で動作し、もう1つは物理世界で動作します。
NVIDIAは、5500億パラメータを持つ混合専門家モデルNemotron 3 Ultraを発表しました。これは、コード開発、科学研究、企業業務プロセスにおける長期稼働型エージェントに最先端のインテリジェンス能力を提供します。同等レベルの主要なオープンソースフロンティアモデルと比較して、このモデルは推論速度が最大5倍向上し、使用コストが最大30%削減され、エージェントがより効率的かつ低コストでタスクを完了できるようになります。
Nemotronオープンモデルを中心に、NVIDIAは一連の


