
分散型AI推論の深掘り:セキュリティとパフォーマンスのバランスをとる方法
- 核心观点:去中心化AI推理可打破算力垄断。
- 关键要素:
- 利用闲置GPU算力降低AI成本。
- 区块链记录确保推理可验证。
- 声誉机制平衡安全与性能。
- 市场影响:挑战中心化云服务商定价权。
- 时效性标注:中期影响。
原作者:アナスタシア・マトヴェエワ - ゴンカ・プロトコル共同創設者
目次
- 真の「分散化」
- ブロックチェーンと推論の証明
- 実際の仕組み
- セキュリティとパフォーマンスのトレードオフ
- スペースを最適化する
Gonkaの開発を始めた頃、私たちにはこんなビジョンがありました。「誰でもAI推論を実行し、報酬を得られるとしたらどうだろう? 高価な中央集権型プロバイダーに頼るのではなく、使われていないコンピューティングパワーをすべて活用できたらどうだろう?」
現在のAI環境は、少数の大手クラウドプロバイダーによって支配されています。AWS、Azure、Google Cloudは、世界のAIインフラの大部分を掌握しています。この集中化は、私たちの多くが直接経験した深刻な問題を引き起こしています。AIインフラを少数の企業が支配することで、恣意的に価格設定したり、望ましくないアプリケーションを検閲したり、単一障害点を作り出したりすることが可能になります。OpenAIのAPIがダウンした際には、数千ものアプリケーションがクラッシュしました。AWSが停止した際には、インターネットの半分が機能停止しました。
「効率的な」最先端技術でさえ、安価ではありません。Anthropicは以前、Claude Sonnet 3.5のトレーニングに「数千万ドル」の費用がかかったと述べており、Claude Sonnet 4は現在一般提供されていますが、Anthropicはまだトレーニング費用を公表していません。CEOのDario Amodei氏は以前、最先端モデルのトレーニング費用は10億ドルに近づき、次世代モデルでは数十億ドルに達すると予測していました。これらのモデルで推論を実行するのも同様に費用がかかります。中程度のアクティブアプリケーションの場合、LLM推論を1回実行するだけで、1日あたり数百ドルから数千ドルの費用がかかることがあります。
一方、世界には膨大な量のコンピューティングパワーが眠ったまま(あるいは無意味に使われたまま)になっています。ビットコインマイナーが価値のないハッシュパズルを解くために電力を浪費したり、データセンターがキャパシティを下回って稼働している状況を想像してみてください。もしこのコンピューティングパワーが、AI推論のような真に価値のあることに活用できたらどうでしょうか?
分散型アプローチは、コンピューティングパワーをプールすることで、資本障壁を下げ、単一サプライヤーによるボトルネックを軽減します。少数の大企業に依存するのではなく、GPUを持つ誰もが参加でき、AI推論の実行に対して報酬を得られるネットワークを構築できます。
実用的な分散型ソリューションの構築は、非常に複雑になることは承知しています。コンセンサスメカニズムからトレーニングプロトコル、リソース割り当てまで、調整が必要な要素は無数にあります。今日は、特定のLLM上で推論を実行するという点に焦点を当てたいと思います。これはどれほど難しいのでしょうか?
真の分散化とは何でしょうか?
分散型AI推論について語るとき、私たちは非常に具体的な意味を持ちます。それは単にAIモデルを複数のサーバーで実行するということではなく、誰もが参加し、コンピューティング能力を提供し、誠実な作業に対して報酬を得られるシステムを構築することです。
重要な要件は、システムがトラストレスであることです。つまり、システムを正しく動作させるために、特定の個人や企業を信頼する必要はありません。インターネット上の見知らぬ人にAIモデルを実行させる場合は、彼らが主張する動作を実際に(少なくとも十分に高い確率で)実行していることを暗号的に保証する必要があります。
このトラストレス要件には、いくつか興味深い意味合いがあります。まず、システムが検証可能である必要があることを意味します。つまり、特定の出力を生成するために同一のモデルとパラメータが使用されたことを証明できる必要があります。これは、受信したAIの応答が正当であることを検証する必要があるスマートコントラクトにとって特に重要です。
しかし、課題があります。検証を追加すればするほど、検証にネットワークパワーが消費されるため、システム全体の速度が低下します。全員を完全に信頼すれば、検証の推論は不要になり、パフォーマンスは中央集権型プロバイダーとほぼ同じになります。しかし、誰も信頼せず、常にすべてを検証すると、システムは非常に遅くなり、中央集権型ソリューションとの競争力が失われます。
これが、私たちが解決に取り組んできた根本的な矛盾です。つまり、セキュリティとパフォーマンスの適切なバランスを見つけることです。
ブロックチェーンと推論の証明
では、誰かが正しいモデルとパラメータを実行したことを実際にどのように検証するのでしょうか?ブロックチェーンが当然の選択肢となります。ブロックチェーンには独自の課題はあるものの、イベントの不変の記録を作成するための、私たちが知る限り最も信頼性の高い方法であることに変わりはありません。
基本的な考え方は非常に単純です。推論を実行する際には、正しいモデルを使用したことの証明を提供する必要があります。この証明はブロックチェーンに記録され、誰でも検証できる永続的で改ざん不可能な記録が作成されます。
問題は、ブロックチェーンが遅いことです。本当に遅いのです。もしすべての推論ステップをオンチェーンで記録しようとすると、膨大なデータ量にすぐにネットワークが圧倒されてしまいます。この制約が、Gonkaネットワークの設計において多くの決定に影響を与えました。
ネットワークを設計し、分散コンピューティングを検討する際には、複数の戦略から選択できます。モデルを複数のノードに分割するか、モデル全体を単一のノードに常駐させるか、といった選択肢があります。主な制約は、ネットワーク帯域幅とブロックチェーンの速度です。私たちのソリューションを実現可能にするために、完全なモデルを単一のノードに収めることにしましたが、これは将来変更される可能性があります。各ノードはモデル全体を実行するのに十分な計算能力とメモリを必要とするため、ネットワークに参加するための最低限の要件が課せられます。ただし、モデルは同じノードに属する複数のGPUに分割できるため、単一ノードの制約内である程度の柔軟性が得られます。私たちはvLLMを使用しており、これによりテンソルとパイプラインの並列処理パラメータをカスタマイズして最適なパフォーマンスを実現できます。
実際の仕組み
そのため、各ノードが完全なモデルをホストし、完全な推論を実行することで、実際の計算中に複数のマシン間で調整を行う必要がなくなるという合意に達しました。ブロックチェーンは記録保存のみに使用されます。記録するのは、推論の検証に使用されたトランザクションとアーティファクトのみです。実際の計算はオフチェーンで行われます。
私たちは、推論リクエストをネットワークノードに送る単一の中央点を設けずに、システムを分散化したいと考えています。実際には、各参加者は少なくとも2つのノード、つまりネットワークノードと1つ以上の推論(ML)ノードを展開します。ネットワークノードは通信(ブロックチェーンに接続するチェーンノードとユーザーリクエストを管理するAPIノードを含む)を担当し、MLノードはLLM推論を実行します。
推論リクエストがネットワークに到着すると、APIノード(「転送エージェント」として機能)の1つに到達し、そこでランダムに「エグゼキュータ」(別の参加者のMLノード)が選択されます。時間を節約し、ブロックチェーンのロギングと実際のLLM計算を並列化するために、転送エージェント(TA)はまず入力リクエストをエグゼキュータに送信し、エグゼキュータのMLノードが推論を実行している間に入力をオンチェーンに記録します。計算が完了すると、エグゼキュータは出力をTAのAPIノードに送信し、自身のチェーンノードは検証アーティファクトをオンチェーンに記録します。TAのAPIノードは出力をクライアントに送り返し、これもオンチェーンに記録されます。もちろん、これらの記録は依然としてネットワーク帯域幅全体の制約に影響を及ぼします。
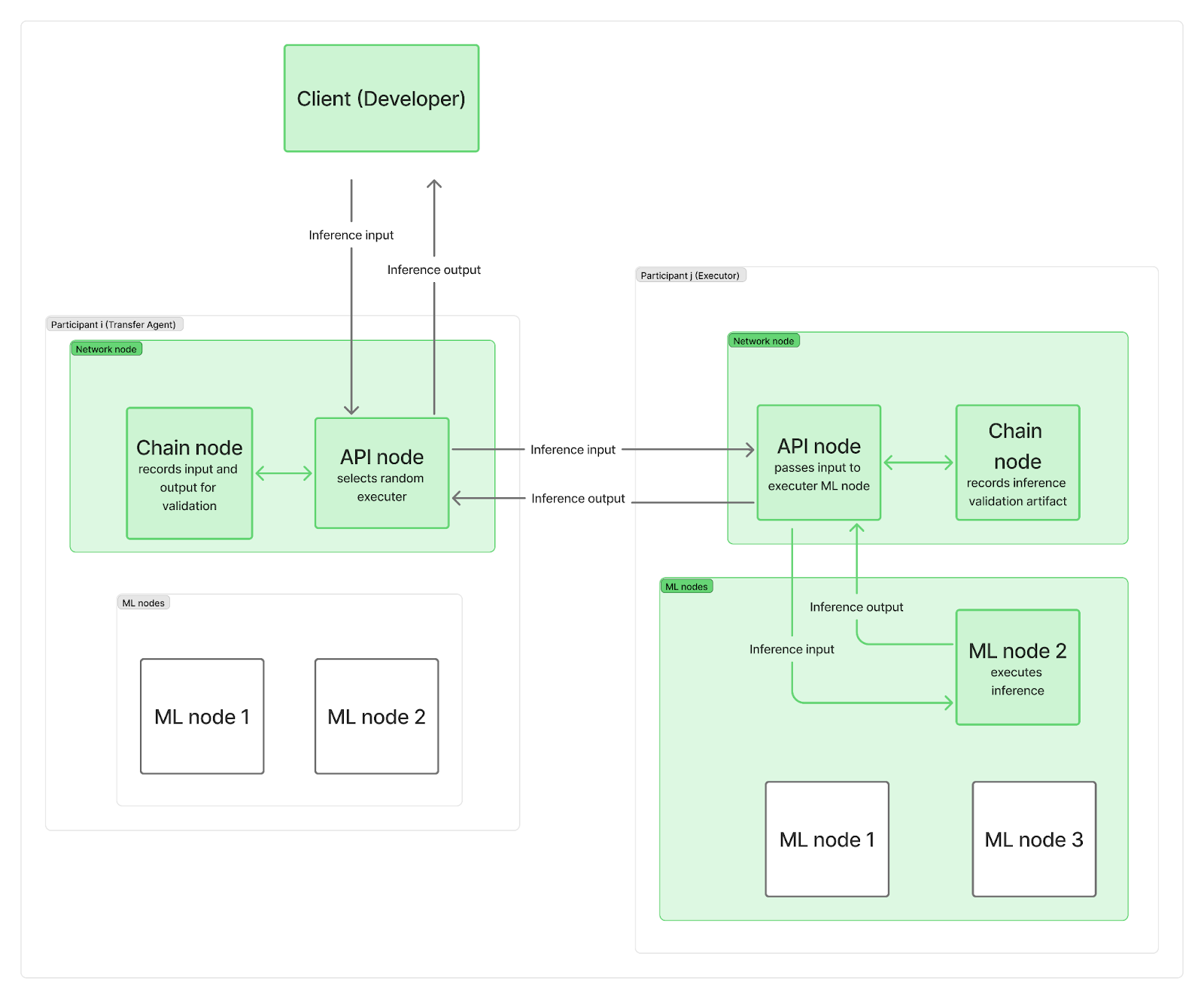
ご覧のとおり、ブロックチェーンへの記録は推論計算の開始を遅らせることも、最終結果をクライアントに返すまでの時間も遅らせることはありません。推論が正しく完了したかどうかの検証は、後ほど他の推論と並行して行われます。エグゼキューターが不正行為を行った場合、エポック全体の報酬を失い、クライアントに通知されて払い戻しを受けます。
最後の質問は、「成果物には何が含まれていますか?また、どのくらいの頻度で推論を検証しますか?」です。
セキュリティとパフォーマンスのトレードオフ
根本的な課題は、セキュリティとパフォーマンスが相反していることです。
最大限のセキュリティを求めるなら、すべてを検証する必要があります。しかし、それは時間と費用がかかります。最大限のパフォーマンスを求めるなら、全員を信頼する必要があります。しかし、それはリスクを伴い、あらゆる種類の攻撃にさらされることになります。
試行錯誤とパラメータ調整を繰り返した結果、これら2つの考慮事項のバランスをとるアプローチを見つけました。検証の量、検証のタイミング、そして検証プロセスを可能な限り効率的にする方法を慎重に調整する必要がありました。検証が多すぎるとシステムは使用できなくなり、検証が少なすぎるとシステムは安全ではなくなります。
システムの軽量化は極めて重要です。私たちは、上位k個の次トークン確率を保存することでこれを実現しています。これらの情報を用いて、特定の出力が実際に主張されたモデルとパラメータによって生成された可能性を測定し、より小さなモデルや量子化されたモデルの使用といった改ざんの試みを十分な信頼度で捕捉します。推論検証手順の実装については、別の投稿でより詳細に説明します。
同時に、どの推論を検証し、どの推論を検証しないかをどのように決定するのでしょうか。私たちは評判に基づくアプローチを選択しました。新しい参加者がネットワークに参加すると、評判は 0 となり、その参加者の推論の 100% が少なくとも 1 人の参加者によって検証される必要があります。問題が見つかった場合、最終的にコンセンサス メカニズムによって推論が承認されるか、評判が下げられ、ネットワークから排除される可能性があります。評判が高まるにつれて、検証が必要な推論の数は減少し、最終的には推論の1%がランダムに選択されて検証される可能性があります。この動的なアプローチにより、全体的な検証率を低く抑えながら、不正行為を試みる参加者を効果的に捕捉することができます。
各エポックの終了時に、参加者はネットワークにおける重みに応じて報酬を受け取ります。タスクにも重みが付けられるため、報酬は重みと完了した作業量の両方に比例することが期待されます。つまり、不正行為者を直ちに捕まえて罰する必要はありません。報酬を分配する前に、エポック内で捕まえれば十分です。
このトレードオフは、技術的パラメータと同様に、経済的インセンティブによっても左右されます。不正行為を高額にし、誠実な参加を利益にすることで、誠実な参加が合理的な選択となるシステムを構築できます。
スペースを最適化する
数ヶ月にわたる構築とテストを経て、ブロックチェーンの記録保持とセキュリティの利点を組み合わせながら、中央集権型プロバイダーの単発推論パフォーマンスに迫るシステムを構築しました。セキュリティとパフォーマンスの間には根本的な緊張関係があり、完璧な解決策はなく、異なるトレードオフが存在するだけです。
ネットワークが拡大するにつれ、完全な分散型コミュニティコントロールを維持しながら、中央集権型プロバイダーと競合できる真のチャンスが生まれると考えています。また、開発を進める中で最適化の余地も大きく残されています。このプロセスについてご興味をお持ちの方は、GitHubとドキュメントをご覧いただき、Discordでのディスカッションに参加し、ぜひご自身でネットワークにご参加ください。
Gonka.aiについて
Gonkaは、効率的なAIコンピューティングパワーを提供するために設計された分散型ネットワークです。その設計目標は、グローバルなGPUコンピューティングパワーを最大限に活用し、有意義なAIワークロードを完了することです。中央集権的なゲートキーパーを排除することで、Gonkaは開発者や研究者にコンピューティングリソースへのパーミッションレスなアクセスを提供し、参加者全員にネイティブGNKトークンを報酬として提供します。
Gonkaは、米国のAI開発会社Product Science Inc.によってインキュベートされました。Web 2業界のベテランであり、Snap Inc.の元コアプロダクトディレクターであるLibermans兄弟によって設立された同社は、2023年にOpenAIの投資家であるCoatue Management、Solanaの投資家であるSlow Ventures、K5、Insight、Benchmark Partnersなどの投資家から1,800万ドルの資金調達に成功しました。プロジェクトの初期段階からの貢献者には、6 Blocks、Hard Yaka、Gcore、Bitfuryなど、Web 2-Web 3分野の著名なリーダー企業が含まれています。


