
次の兆路の詳細な分析: ゼロ知識証明と分散コンピューティングの組み合わせ
1. 分散コンピューティングの歴史と市場展望
副題
1.1 開発の歴史
当初、各コンピュータは 1 つのコンピューティング タスクしか実行できませんでしたが、マルチコアおよびマルチスレッド CPU の出現により、1 台のコンピュータで複数のコンピューティング タスクを実行できるようになりました。
大規模なWebサイトのビジネスが増加するにつれて、シングルサーバーモデルでは容量を拡張することが難しく、ハードウェアコストが増加します。複数のサーバーで構成されるサービス指向のアーキテクチャが登場します。サービス登録者、サービスプロバイダー、サービス消費者で構成されます。
ただし、ビジネスとサーバーの増加に伴い、SOA モデルではポイントツーポイント サービスの保守性と拡張性がより困難になります。マイコンの原理と同様に、バス モードはさまざまなサービス ユニットを調整するように見えます。 Service Bus は、ハブのようなアーキテクチャを通じてすべてのシステムを接続します。このコンポーネントは ESB (Enterprise Service Bus) と呼ばれます。仲介の役割として、さまざまな形式または標準のサービス契約を翻訳し、調整します。
次に、アプリケーション プログラミング インターフェイス (API) ベースの REST モデル通信は、そのシンプルさと高い構成可能性で際立っています。各サービスはREST形式でインターフェースを出力します。クライアントが RESTful API を通じてリクエストを行うと、リソースの状態表現がリクエスターまたはエンドポイントに渡されます。この情報または表現は、JSON (JavaScript Object Notation)、HTML、XLT、Python、PHP、またはプレーン テキストのいずれかの形式で HTTP 経由で送信されます。 JSON は最も一般的に使用されているプログラミング言語で、その名前は英語で「JavaScript Object Notation」を意味しますが、さまざまな言語に適用でき、人間と機械の両方で読み取ることができます。
仮想マシン、コンテナ テクノロジー、Google の 3 つの論文:GFS: The Google File System
2003 年、MapReduce: Simplified Data Processing on Large Clusters
2004年、Bigtable: A Distributed Storage System for Structured Data
2006年、
分散システムの幕を開けた分散ファイルシステム、分散コンピューティング、分散データベースです。 Hadoop による Google 論文の再現、より高速で使いやすい Spark、リアルタイム コンピューティング用の Flink。
イーサリアムに代表されるスマートコントラクトパブリックチェーンは、抽象的には分散コンピューティングフレームワークとして理解できますが、EVMは命令セットが限定された仮想マシンであり、Web2で必要とされる一般的なコンピューティングを実行することはできません。そして、チェーン上のリソースも非常に高価です。それでも、イーサリアムは、ポイントツーポイント コンピューティング フレームワーク、ポイントツーポイント通信、ネットワーク全体の計算結果の一貫性、データの一貫性といったボトルネックも突破しました。
副題
1.2 市場の見通し
ビジネス ニーズから始めて、なぜ分散コンピューティング ネットワークが重要なのでしょうか?全体の市場規模はどれくらいですか?今はどの段階で、将来的にはどのくらいのスペースがあるのでしょうか?注目に値する機会はどれですか?お金を稼ぐ方法は?
文章
1.2.1 分散コンピューティングはなぜ重要ですか?
イーサリアムの当初のビジョンでは、それは世界のコンピューターになることでした。 2017 年に ICO が爆発的に増加した後、依然として資産発行が主な焦点であることに誰もが気づきました。しかし2020年にはDefiサマーが登場し、大量のDappsが登場し始めました。チェーン上のデータが爆発的に増加するにつれ、ますます複雑化するビジネス シナリオに直面して EVM はますます無力になってきています。 EVMでは実現できない機能を実現するにはオフチェーン拡張という形が必要です。オラクルなどの役割は、ある程度分散型コンピューティングです。
Dapp の開発は完了し、0 から 1 までのプロセスを完了するだけで済みました。現在は、より複雑なビジネス シナリオを完了するために、より強力な基盤となる機能が必要です。 Web3 全体はおもちゃのアプリケーションを開発する段階を過ぎており、将来的にはより複雑なロジックとビジネス シナリオに直面する必要があります。
文章
1.2.2 全体の市場規模はどれくらいですか?
市場規模を推定するにはどうすればよいですか? Web2分野の分散コンピューティングビジネスの規模から推計? Web3 市場の普及率を掛けたもの?現在市場に出ている対応する融資プロジェクトの評価額を合計しますか?
以下の理由により、分散コンピューティングの市場規模を Web2 から Web3 に移行することはできません。 1. Web2 分野の分散コンピューティングはほとんどのニーズを満たしており、Web3 分野の分散コンピューティングは市場の需要を満たすために差別化されています。それがコピーされた場合、それは市場の客観的な背景環境に反します。 2. Web3分野における分散コンピューティングは、今後成長する市場の事業範囲がグローバルになります。したがって、市場規模をより厳密に見積もる必要があります。
Web3 分野の潜在的なトラックの全体的な規模予算は、次の点に基づいて計算されます。
収益モデルは、トークン経済モデルの設計に基づいています。たとえば、現在人気のあるトークン収益モデルは、トークンが取引中の手数料の支払い手段として使用されるというものです。したがって、手数料収入は生態系の繁栄と取引活動を間接的に反映することができます。最終的には評価判断の基準となります。もちろん、モーゲージマイニングやトランザクションペア、アルゴリズムステーブルコインのアンカー資産など、トークンには他にも成熟したモデルがあります。したがって、Web3 プロジェクトの評価モデルは従来の株式市場とは異なり、むしろ国家通貨に似ています。トークンが採用されるシナリオは異なります。したがって、特定のプロジェクトについては、特定の分析を行います。 Web3 分散コンピューティング シナリオでトークン モデルをどのように設計すべきかを検討してみることができます。まず、分散コンピューティングのフレームワークを設計することを想定していますが、どのような課題に遭遇するでしょうか? a). ネットワークが完全に分散化されているため、このような信頼できない環境でコンピューティング タスクの実行を完了するには、オンライン速度とサービス品質を確保するようリソース プロバイダーを動機付ける必要があります。ゲームの仕組みとしては、インセンティブの仕組みが合理的であること、攻撃者による不正攻撃やシビル攻撃などの攻撃手段をどのように防ぐかが必要です。したがって、POS コンセンサス ネットワークに参加するための誓約方法としてトークンが必要であり、すべてのノードのコンセンサスの一貫性が最初に保証されます。リソース貢献者にとって、特定のインセンティブ メカニズムを実装するには、貢献した作業量が必要であり、トークン インセンティブは、ビジネスの成長とネットワーク効率の向上のために正の循環的成長を伴う必要があります。 b). 他のレイヤー 1 と比較して、ネットワーク自体も大量のトランザクションを生成しますが、大量のダストトランザクションに直面して、各トランザクションは手数料を支払います。市場。 c). トークンが実用的な目的のみで使用される場合、市場価値をさらに拡大することは困難です。資産ポートフォリオのアンカー資産として使用すると、何層もの資産のネストされた組み合わせが実行され、金融化の効果が大幅に拡大します。総合評価額 = 保証率 * ガス消費率 * (流通量の逆数) * 単一価格
文章
1.2.3 現在はどの段階にあり、将来的にはどれくらいのスペースが存在するのでしょうか?
2017 年から現在まで、多くのチームが分散コンピューティングの方向に開発を試みていますが、いずれも失敗に終わりました。失敗の理由については後ほど詳しく説明します。この探査パスは、もともとエイリアン探査プログラムに似たプロジェクトでしたが、その後、従来のクラウド コンピューティング モデルを模倣するように開発され、さらに Web3 ネイティブ モデルの探査へと発展しました。
トラック全体の現状は学術レベルで0から1まで検証された画期的なものであり、いくつかの大規模プロジェクトは工学的実践において大きな進歩を遂げた。たとえば、zkRollup と zkEVM の現在の実装は、製品をリリースしたばかりの段階です。
以下の理由により、将来の余地はまだ大きい。 1. 検証計算の効率を改善する必要がある。 2. 命令セットをさらに充実させる必要がある。 3. まったく異なるビジネス シナリオの最適化。 4. これまでスマートコントラクトでは実現できなかったビジネスシナリオが、分散コンピューティングによって実現可能となります。
もちろん、これは提案されたアプリケーション シナリオにすぎず、Web2 にはコンピューティング能力を必要とするビジネス シナリオが数多くあります。
1.2.4 注目に値する機会はどれですか?お金を稼ぐ方法は?
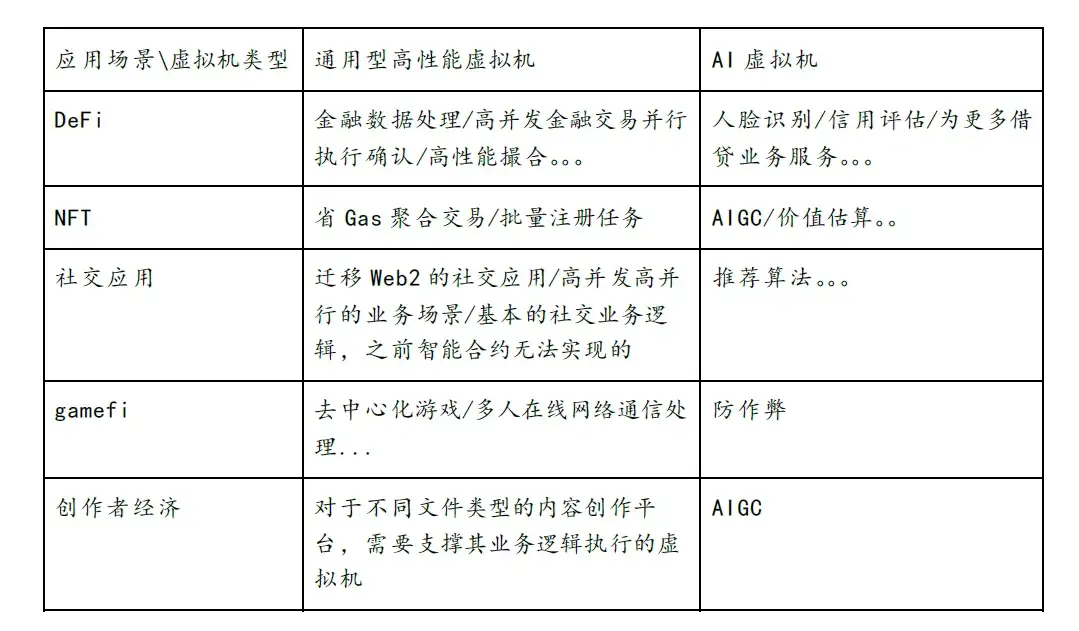
2. 分散型コンピューティングの試み
副題
2.1 クラウドサービスモデル
現在、イーサリアムには次の問題があります。
全体的なスループットが低い。大量の計算能力を消費しますが、スループットはスマートフォンと同等です。
検証度は低いです。この問題は検証者のジレンマとして知られています。パッケージ化権を獲得したノードには報酬があり、他のノードは検証する必要があるが報酬は得られず、検証熱も低い。時間が経つと計算が検証されなくなり、チェーン上のデータ セキュリティにリスクが生じる可能性があります。
計算量に制限(gasLimit)があり、計算コストが高くなります。
一部のチームは、Web2 で広く採用されているクラウド コンピューティング モデルを採用しようとしています。ユーザーは一定の料金を支払い、その料金は計算資源の使用時間に応じて計算されます。このようなモデルを採用する基本的な理由は、検出可能な時間パラメーターまたはその他の制御可能なパラメーターによってのみ、コンピューティング タスクが正しく実行されたかどうかを検証することが不可能であるためです。
最終的な結果は当初の意図とはまったく異なります。
副題
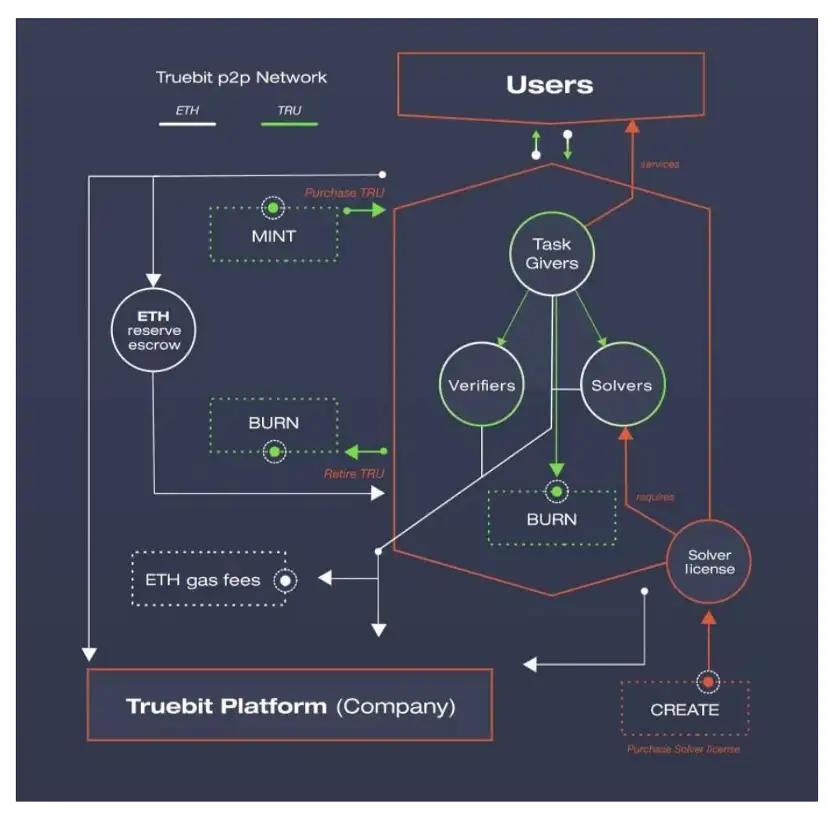
2.2 チャレンジャーモード
https://www.aicoin.com/article/256862.html
一方、TrueBit はゲーム システムを使用してグローバルな最適なソリューションを実現し、分散コンピューティング タスクが正しく実行されることを保証します。
当社の高速コンピューティング フレームワークの核となるポイントは次のとおりです。
役割: 問題解決者、挑戦者、裁判官
問題解決者は、コンピューティング タスクの受信に参加する前に資金を約束する必要があります
賞金稼ぎとして、挑戦者は問題解決者の計算結果が自分のローカルの計算結果と一致するかどうかを繰り返し検証する必要があります。
挑戦者は両者の計算状況と一致する最新の計算タスクを抽出し、乖離点がある場合は乖離点のマークルツリーハッシュ値を提出する
最後に審査員がチャレンジが成功したかどうかを判断します
挑戦者は、提出タスクを完了している限り、遅れて提出することができます。その結果、適時性が失われます。
副題
2.3 ゼロ知識証明を使用して計算を検証する
したがって、これをどのように達成するかによって、計算プロセスを確実に検証できるだけでなく、検証の適時性も確保できます。
たとえば、zkEVM の実装では、ブロック時間ごとに検証可能な zkProof を送信する必要があります。このzkProofにはロジックコンピューティングの業務コードによって生成されたバイトコードが含まれており、そのバイトコードが実行されて回路コードが生成される。このようにして、計算ビジネス ロジックが正しく実行され、検証の適時性が短時間かつ一定の時間で保証されることが実現されます。
十分な高性能のゼロ知識証明アクセラレーション ハードウェアと十分に最適化されたゼロ知識証明アルゴリズムがあるという前提の下では、汎用コンピューティング シナリオを完全に開発できます。 Web2 シナリオの多数のコンピューティング サービスは、ゼロ知識証明の汎用仮想マシンによって再現できます。前述したように、収益性の高い事業の方向性。
3. ゼロ知識証明と分散コンピューティングの組み合わせ
副題
3.1 学力レベル
ゼロ知識証明アルゴリズムの歴史的な開発と進化を振り返ってみましょう。
GMR 85 は、Goldwasser、Micali、Rackoff が共同出版した論文「The Knowledge Complexity of Interactive Proof Systems (つまり GMR 85)」に由来する最も初期のアルゴリズムであり、1985 年に提案され、1989 年に出版されました。この論文では、ステートメントが正しいことを証明するために、対話型システムでの K ラウンドの対話後にどれだけの知識を交換する必要があるかを主に説明します。
Yao の Garbled Circuit (GC) [89]。あらゆる関数を評価できる、有名な忘却転送ベースの二者間安全計算プロトコル。難読化回路の中心的な考え方は、計算回路 (AND 回路、OR 回路、NOT 回路を使用してあらゆる算術演算を実行できます) を生成フェーズと評価フェーズに分解することです。各当事者は回路が暗号化される段階を担当するため、どちらの当事者も他方から情報を取得することはできませんが、回路に基づいて結果を取得することはできます。難読化回路は、オブリビアス転送プロトコルとブロック暗号で構成されます。回路の複雑さは、入力内容に応じて少なくとも直線的に増加します。難読化回路が公開された後、Goldreich-Micali-Wigderson (GMW) [91] は悪意のある敵対者に対抗するために難読化回路を複数の当事者に拡張しました。
シグマ プロトコルは、正直な検証者のための (特別な) ゼロ知識証明としても知られています。つまり、検証者は正直であると想定されます。この例は、Schnorr 認証プロトコルに似ていますが、後者は通常非対話型である点が異なります。
2013 年の Pinocchio (PGHR 13): Pinocchio: Nearly Practical Verifiable Computation (証明と検証の時間を該当範囲まで圧縮する) は、Zcash で使用される基本プロトコルでもあります。
2016 年の Groth 16: ペアリングベースの非対話型引数のサイズについては、証明のサイズを簡素化し、検証効率を向上させるもので、現在最も広く使用されている ZK 基本アルゴリズムです。
Bulletproofs (BBBPWM 17) Bulletproofs: Short Proofs for Confidential Transactions and More は 2017 年に、信頼できる設定を必要としない非常に短い非対話型のゼロ知識証明である Bulletproof アルゴリズムを提案し、6 か月後に Monero に適用される予定です。理論からアプリケーションへの統合が非常に高速です。
2018年、zk-STARKs (BBHR 18) スケーラブル、透過的、ポスト量子安全な計算整合性により、信頼できる設定を必要としない ZK-STARK アルゴリズム プロトコルが提案され、これに基づいて最も重要な ZK プロジェクトである StarkWare が誕生しました。
防弾の特徴は次のとおりです。
1) 信頼できるセットアップのない短い NIZK
2) ペダーセンのコミットメントに基づいて構築する
3) 証明集約のサポート
4) 証明時間は次のとおりです: O ( N ⋅ log ( N ) ) O(N\cdot \log(N))O(N⋅log(N))、約 30 秒
5) 検証時間: O ( N ) O(N)O(N)、約 1 秒
6) 校正サイズは次のとおりです: O ( log ( N ) ) O(\log(N))O(log(N))、約 1.3 KB
7) 離散ログに基づくセキュリティの仮定
Bulletproof の適用可能なシナリオは次のとおりです。
2 )inner product proofs
1) 範囲証明 (約 600 バイトのみ)
4 )aggregated and distributed (with many private inputs) proofs
3) MPC プロトコルの中間チェック
Halo 2 の主な機能は次のとおりです。
1) 信頼できるセットアップを行わずに、累算スキームと PLONKish 算術演算を効率的に組み合わせます。
2) IPA のコミットメントスキームに基づく。
3) 豊かな開発者エコロジー。\log N)O(N∗logN)。
4) 証明者時間は次のとおりです: O ( N ∗ log N ) O(N*
5) 検証者の時間は次のとおりです: O ( 1 ) > O ( 1) > O ( 1) > Groth 16。\log N)O(logN)。
6) 証明サイズは次のとおりです: O ( log N ) O(
7) 個別のログに基づくセキュリティの前提。
Halo 2 に適切なシナリオは次のとおりです。
1) 検証可能な計算
2) 再帰的証明構成
3) ルックアップベースのシンセミラ関数に基づく回路最適化ハッシュ
Halo 2 が適さないシナリオは次のとおりです。
1) Halo 2 を KZG バージョンに置き換えない限り、イーサリアムでの検証にコストがかかります。
Plonky 2 の主な機能は次のとおりです。
1) 信頼できるセットアップを行わずに FRI と PLONK を組み合わせます。
2) SIMD を備えたプロセッサ用に最適化されており、64 バイトの Goldilocks フィールドを採用しています。\log N)O(logN)。
3) 証明時間は次のとおりです: O ( log N ) O(\log N)O(logN)。
4) 検証時間は次のとおりです: O ( log N ) O(\log N)O(N∗logN)。
5) 証明サイズは次のとおりです: O ( N ∗ log N ) O(N*
6) 衝突耐性のあるハッシュ関数に基づくセキュリティの仮定。
Plonky 2 が適しているシナリオは次のとおりです。
1) 任意の検証可能な計算。
2) 再帰的証明構成。
3) 回路の最適化にはカスタム ゲートを使用します。
Plonky 2 が適さないシナリオは次のとおりです。
現在、Halo 2 は zkvm で採用される主流のアルゴリズムとなっており、再帰的証明をサポートし、あらゆる種類の計算の検証をサポートします。これは、ゼロ知識証明タイプの仮想マシンの一般的なコンピューティング シナリオの基礎を築きます。
副題
3.2 エンジニアリングの実践レベル
ゼロ知識証明が学術レベルで飛躍的に進歩している今、実際の開発はどのように進んでいるでしょうか?
私たちは複数のレベルから観察します。
プログラミング言語: 現在、開発者が回路コードの設計方法を深く理解する必要がない専用のプログラミング言語が存在しており、開発の敷居が低くなります。もちろん、Solidity を回路コードに変換するサポートもあります。開発者の利便性はますます向上しています。
仮想マシン: 現在、zkvm の実装は多数あります。最初は独自に設計されたプログラミング言語で、独自のコンパイラーを通じて回路コードにコンパイルされ、最後に zkproof が生成されます。 2 つ目は、LLVM によってターゲット バイトコードにコンパイルされ、最終的に回路コードと zkproof に変換される Solidity プログラミング言語をサポートすることです。 3 つ目は真の EVM と同等の互換性で、最終的にバイトコードの実行を回路コードと zkproof に変換します。これは zkvm の最終局面でしょうか?いいえ、スマート コントラクト プログラミングを超えて拡張される汎用コンピューティング シナリオであっても、さまざまなスキームでの独自の基礎となる命令セットに対する zkvm の完成と最適化であっても、それはまだ 1 から N の段階にあります。道のりは長く、多くのエンジニアリング作業を最適化して実現する必要があります。各企業は学術レベルから工学的実現への着陸を達成しており、最終的に誰が王となり、血塗られた道を打ち破ることができるのか。パフォーマンスの向上において大幅な進歩を遂げる必要があるだけでなく、多くの開発者をエコシステムに参加させる必要もあります。タイミングは非常に重要な前提要素であり、最初に市場に投入すること、資金を集めて蓄積すること、エコシステムの中で自然発生的に現れるアプリケーションはすべて成功の要素です。
周辺機器のサポート ツールと機能: エディター プラグインのサポート、単体テスト プラグイン、Debug デバッグ ツールなど、開発者がゼロ知識証明アプリケーションをより効率的に開発できるようにします。
ゼロ知識証明アクセラレーションのためのインフラストラクチャ: FFT と MSM はゼロ知識証明アルゴリズム全体で多くの計算時間を占めるため、GPU/FPGA などの並列コンピューティング デバイス上で並列実行して時間の圧縮効果を実現できます。オーバーヘッド。
スター プロジェクトの出現: zkSync、Starkware、その他の高品質プロジェクトが、正式な製品リリースの時期を発表しました。これは、ゼロ知識証明と分散コンピューティングの組み合わせが、もはや理論レベルにとどまらず、エンジニアリングの実践において徐々に成熟していることを示しています。
4. 発生したボトルネックとその解決方法
副題
4.1 zkProofの生成効率が低い
市場のキャパシティ、現在の業界の発展、実際の技術の進歩について先ほど述べましたが、課題はありますか?
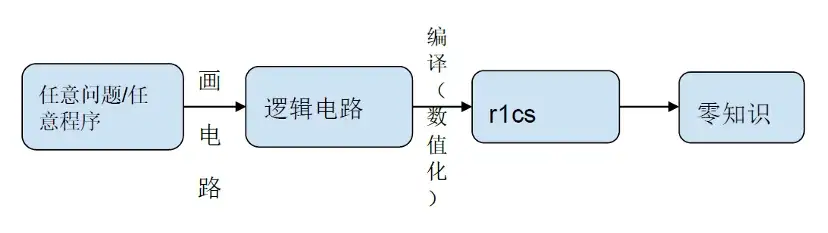
zkProof 生成プロセス全体を逆アセンブルします。
論理回路のコンパイルと数値化 r 1 cs の段階では、計算の 80% が NTT や MSM などのコンピューティング サービスで行われます。さらに、ハッシュ アルゴリズムは論理回路のさまざまなレベルで実行され、レベルの数が増加するにつれて、ハッシュ アルゴリズムの時間オーバーヘッドは直線的に増加します。もちろん、業界は現在、時間のオーバーヘッドを 200 分の 1 に削減する GKR アルゴリズムを提案しています。
ただし、NTT と MSM の計算時間のオーバーヘッドは依然として高いです。ユーザーの待ち時間を短縮し、ユーザー エクスペリエンスを向上させたい場合は、数学的実装、ソフトウェア アーキテクチャの最適化、GPU/FPGA/ASIC などのレベルで高速化する必要があります。
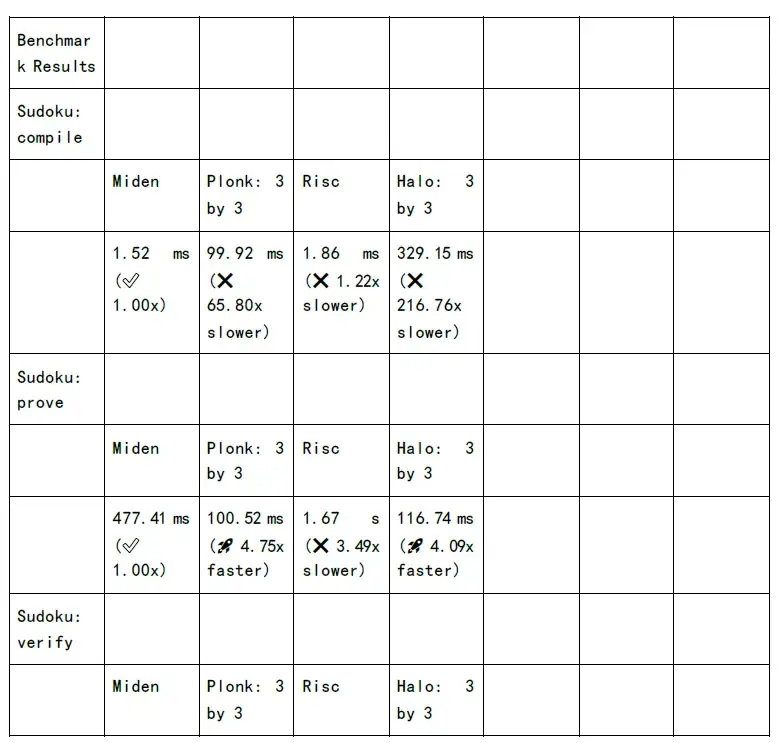
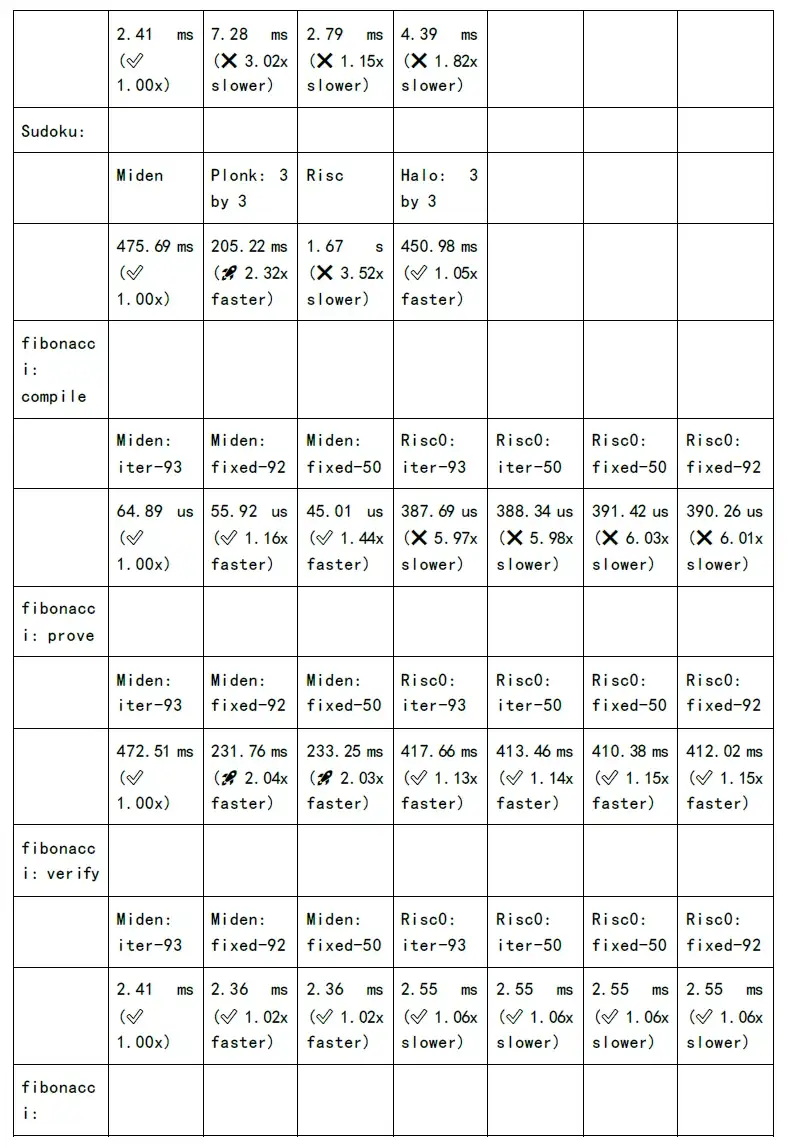
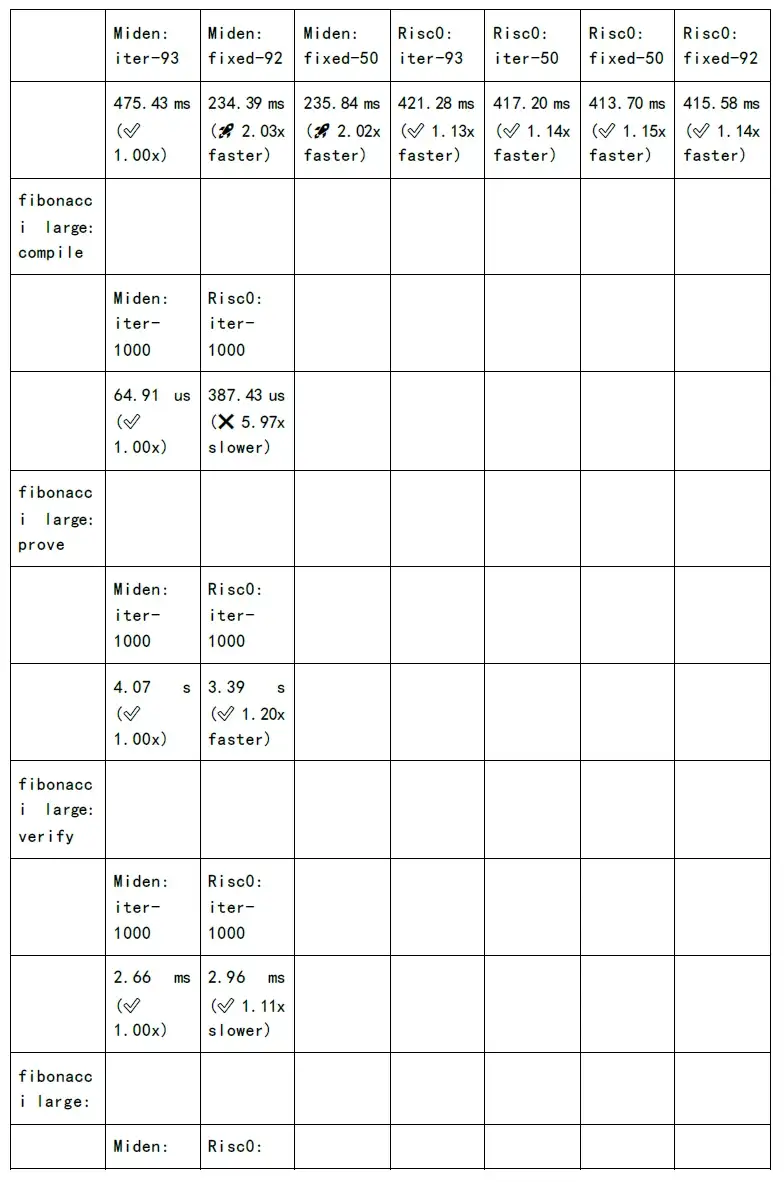
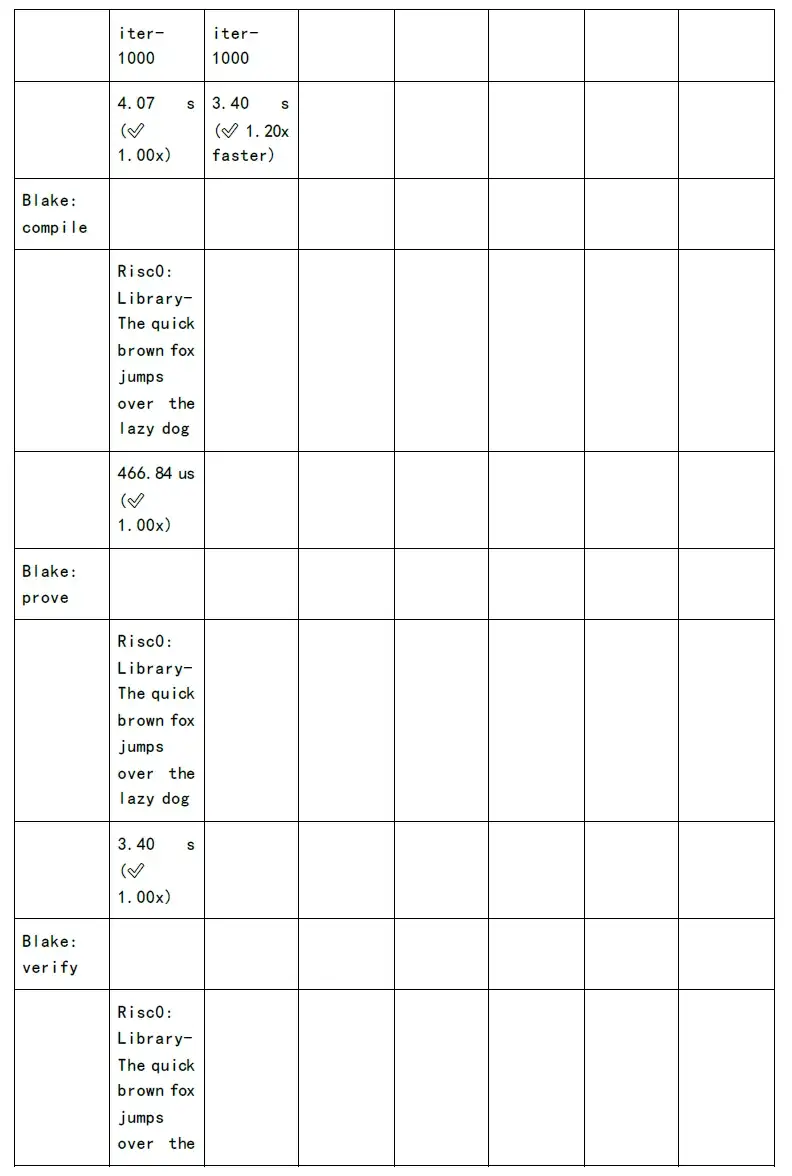
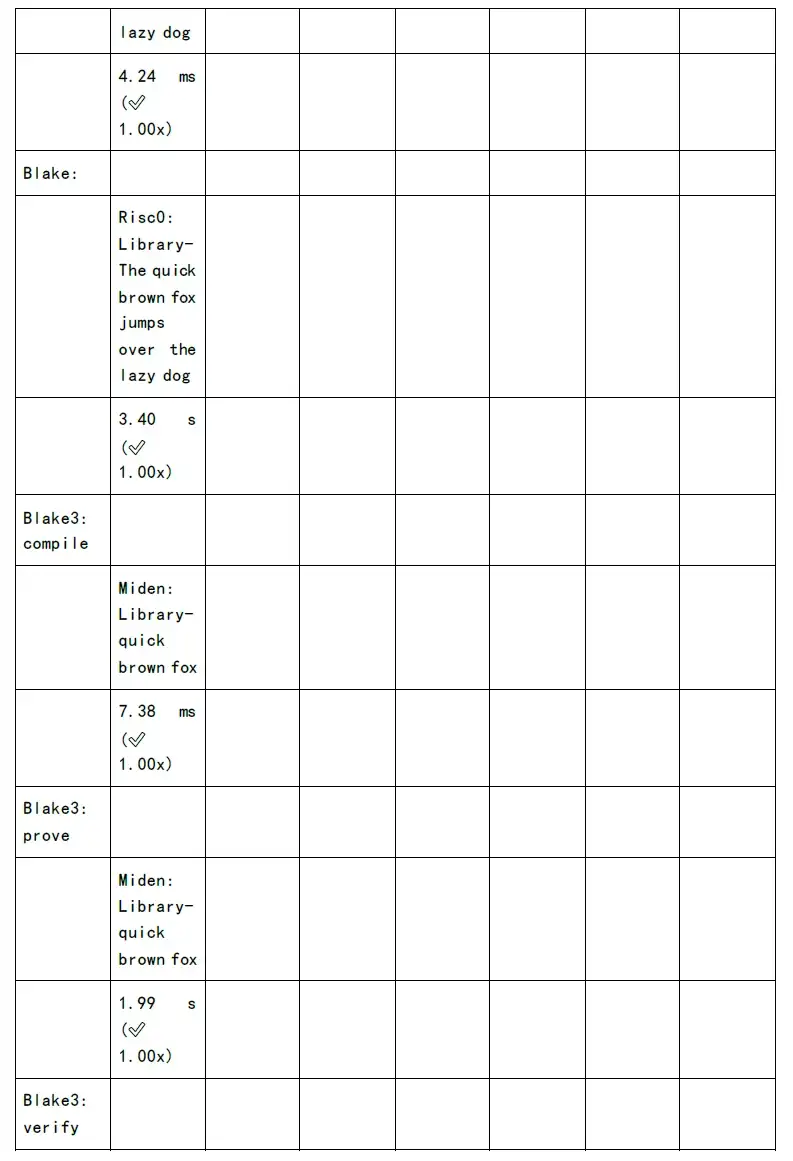
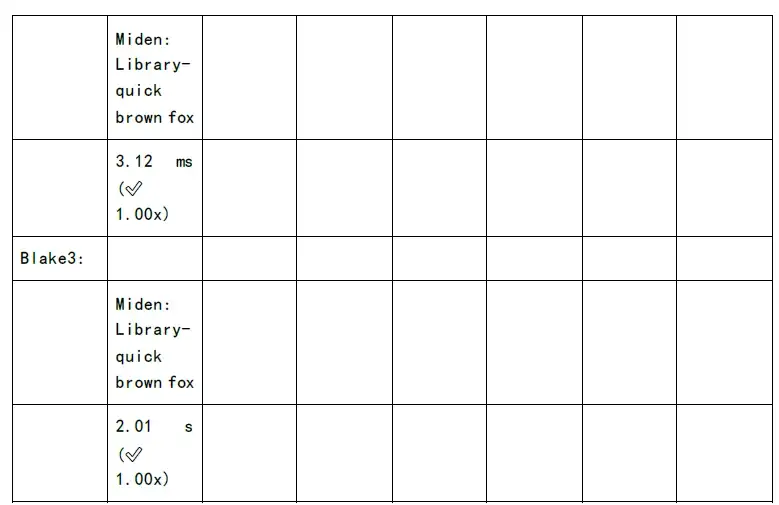
次の図は、各 zkSnark ファミリー アルゴリズムの証明生成時間と検証時間のテストを示しています。
落とし穴と課題が見えてきたということは、大きなチャンスがあることも意味します。
グラフィックスカードアクセラレーションSaasサービスは、アクセラレーションにグラフィックスカードを使用するため、ASIC設計よりもコストが低く、開発サイクルも短くなります。ただし、長期的には、ソフトウェアの革新はハードウェアの高速化によって最終的には排除されます。
副題
4.2 多くのハードウェア リソースを占有する
将来、zkSnark アプリケーションを大規模に普及させたい場合は、さまざまなレベルで最適化することが不可欠です。
副題
4.3 ガス消費コスト
したがって、多くの zkp プロジェクトは、再帰的証明圧縮を使用して送信されるデータ有効層と zkProof のすべてがガスコストを削減することを提案しています。
副題
現在、ほとんどの zkvm プラットフォームはスマート コントラクト プログラミングを指向していますが、より一般的なコンピューティング シナリオが必要な場合は、zkvm の基礎となる命令セットに対して多くの作業を行う必要があります。たとえば、zkvm 仮想マシンの最下層は、libc 命令、行列演算をサポートする命令、およびその他のより複雑な計算命令をサポートします。
最初のレベルのタイトル
5。結論


