
SemiAnalysis: The Fire and Ice of Nvidia's Rubin Platform
- Core Thesis: SemiAnalysis has published two contrasting analyses, indicating that Nvidia's performance in the second half of fiscal 2027 will exceed expectations due to the resolution of the HBM4 supply bottleneck. However, the flagship product, the Rubin Ultra, has been significantly downsized due to technical reasons, indirectly reflecting the erosion of its CUDA ecosystem by custom ASICs.
- Key Elements:
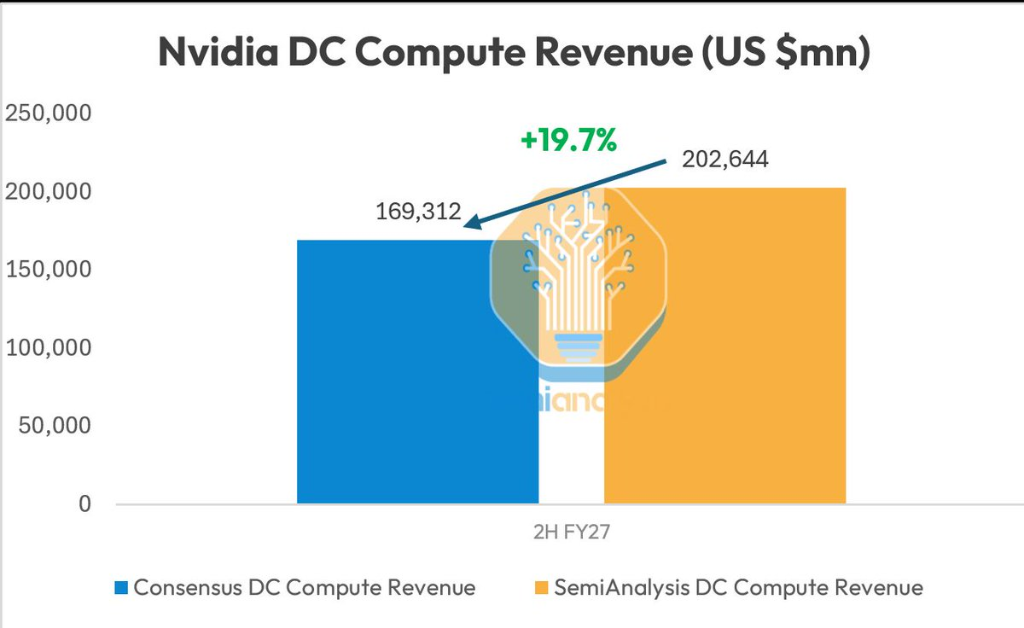
- SemiAnalysis predicts that Nvidia's data center revenue for the second half of fiscal 2027 will be approximately 20% higher than the Wall Street consensus, with the core driver being that both the HBM4 supply issues for the Rubin platform and the front-end wafer capacity reserves have been resolved.
- SemiAnalysis's forecasting model is based on primary research across the industry chain, covering materials, wafers, components, servers, and cloud service provider procurement data, differing from the conservative estimates of traditional sell-side analysts.
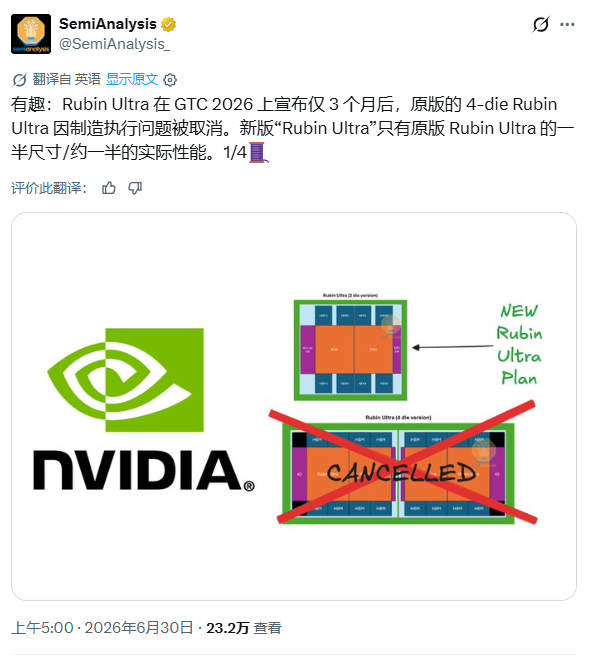
- Nvidia's originally planned 4-die Rubin Ultra was canceled about three months after its announcement at GTC 2026. The new version has been halved in size and performance, with the reason linked to the difficulty of advanced packaging manufacturing.
- Shift in Nvidia's competitive landscape: Hyperscalers and AI companies (e.g., Anthropic) are adopting custom ASICs (such as Google TPU, Amazon Trainium) for both training and inference, eroding the CUDA moat.
- Anthropic has already formed a multi-platform architecture using TPUs, Trainium, and Nvidia GPUs. The training and inference of the Claude model are gradually shifting from GPUs to TPUs and Trainium.
Original source: Wall Street CN
The semiconductor research firm SemiAnalysis has released two analyses, outlining a "fire and ice" picture for Nvidia's future, where opportunities and challenges coexist.
SemiAnalysis's latest forecast, posted on X platform on June 30, projects that Nvidia's data center computing revenue in the second half of fiscal year 2027 will be approximately 20% higher than the Wall Street consensus. The core support for this optimistic outlook lies in the fact that the HBM4 memory supply issue, which previously constrained the mass shipment of the Rubin platform, has been resolved. Additionally, front-end wafer production capacity has been reserved in place, clearing a substantial obstacle for the performance surge expected in the second half of the year.
However, earlier on the same day, SemiAnalysis disclosed another piece of bearish news: Nvidia's original 4-chip Rubin Ultra was canceled approximately three months after its launch at GTC 2026. The new "Rubin Ultra" has been scaled down by half in size, resulting in its actual performance also being halved.
On one hand, there is an optimistic upward revision of revenue following the resolution of supply bottlenecks; on the other, there is a pessimistic revision regarding the technology roadmap due to the shrinkage of the flagship product. These two contrasting judgments from SemiAnalysis anchor Nvidia in completely different narrative coordinates, analyzing from the two dimensions of performance delivery capability and technological moat.
HBM4 Bottleneck Resolved, Rubin Platform Poised for Volume Shipments in H2
Through its Accelerator Model, SemiAnalysis has made a new forecast, indicating that Nvidia is set for a significant surge in volume shipments in the second half of this year.
The firm estimates that, driven strongly by the Rubin platform, Nvidia's data center computing revenue in the second half of fiscal year 2027 will be approximately 20% higher than the market consensus. The HBM4 issue that previously impacted Rubin's progress has now been resolved, and front-end wafer supply has been prepared ahead of time. This means the once-delayed Rubin platform will enter a rapid ramp-up phase.
SemiAnalysis specifically notes that its forecasting logic differs significantly from traditional sell-side analysts. Most Wall Street institutions tend to build relatively conservative earnings forecasts, reserving room for companies to "beat expectations" later. In contrast, SemiAnalysis's conclusions are more grounded in front-line industry research, striving to be closer to real market dynamics.
Its Accelerator Model establishes a cross-verification system covering the entire chain, with data sources spanning supply chain links such as material suppliers, wafer manufacturing, key components, and server OEMs. It also cross-checks supply-demand relationships by incorporating actual procurement and deployment data from hyperscale cloud service providers and leading AI labs.
It is worth noting that this model focuses not only on Nvidia but also covers AI chip manufacturers like Broadcom, AMD, MediaTek, and Marvell. It continuously tracks the overall evolution of the AI computing power industry chain in conjunction with the HBM Model.
CUDA Moat Eroding, Shrinking Rubin Ultra Reflects the Rise of Custom ASICs
However, another earlier commentary from SemiAnalysis regarding Rubin Ultra sparked widespread market discussion.
The firm stated that approximately three months after the launch of Nvidia's Rubin Ultra, which originally featured a 4-compute-chip design at this year's GTC, the original plan was adjusted. The new version is significantly smaller than the original design, a change attributed to the challenges of advanced packaging manufacturing.
SemiAnalysis believes that what is more noteworthy than the shrinking of Rubin Ultra itself is the change in the competitive landscape of the industry reflected by this event. The firm points out that over the past year, Nvidia's biggest competitive pressure has no longer come solely from traditional GPU manufacturers like AMD. Instead, an increasing number of hyperscale cloud providers and AI model companies are adopting custom ASICs to build dedicated chip systems for specific scenarios like training or inference.
For example, Anthropic has now established a multi-platform computing architecture comprising Google TPUs, Amazon Trainium chips, and Nvidia GPUs. Notably, a significant portion of Claude model training runs on the TPU platform, while Claude Code inference is increasingly deployed on Trainium. Nvidia GPUs, in turn, bear more of the burden for general-purpose computing tasks like cutting-edge research. SemiAnalysis points out that a year ago, the idea of TPUs and Trainium growing to their current scale would have been hard to imagine, yet now Nvidia's CUDA moat is being slowly eroded.


