
In-depth analysis of decentralized AI reasoning: How to strike a balance between security and performance
- 核心观点:去中心化AI推理可打破算力垄断。
- 关键要素:
- 利用闲置GPU算力降低AI成本。
- 区块链记录确保推理可验证。
- 声誉机制平衡安全与性能。
- 市场影响:挑战中心化云服务商定价权。
- 时效性标注:中期影响。
Original author: Anastasia Matveeva - Co-founder of Gonka Protocol
Table of contents
- True "decentralization"
- Blockchain and Proof of Reasoning
- How it actually works
- Security and performance trade-offs
- Optimize space
When we started building Gonka , we had a vision: What if anyone could run AI inference and get paid for it? What if we could harness all that unused computing power instead of relying on expensive centralized providers?
The current AI landscape is dominated by a handful of large cloud providers: AWS, Azure, and Google Cloud control the majority of the world's AI infrastructure. This centralization creates serious problems that many of us have experienced firsthand. Control of AI infrastructure by a handful of companies means they can arbitrarily set prices, censor undesirable applications, and create a single point of failure. When OpenAI's API went down, thousands of applications crashed with it. When AWS experienced an outage, half the internet stopped functioning.
Even "efficient" cutting-edge technologies aren't cheap. Anthropic previously stated that training Claude 3.5 Sonnet cost "tens of millions of dollars," and while Claude Sonnet 4 is now generally available, Anthropic hasn't yet released its training costs. Its CEO, Dario Amodei, previously predicted that training costs for cutting-edge models will approach $1 billion, with the next wave of models reaching billions. Running inference on these models is equally expensive. For a moderately active application, a single LLM inference run can cost hundreds to thousands of dollars per day.
Meanwhile, the world has a vast amount of computing power sitting idle (or being used in meaningless ways). Think of Bitcoin miners burning electricity to solve worthless hash puzzles, or data centers running below capacity. What if this computing power could be used for something truly valuable, like AI inference?
A decentralized approach can pool computing power, lowering capital barriers and reducing single-supplier bottlenecks. Instead of relying on a few large companies, we can create a network where anyone with a GPU can participate and get paid for running AI inference.
We know that building a viable decentralized solution will be incredibly complex. From consensus mechanisms to training protocols to resource allocation, there are countless pieces that need to be coordinated. Today, I want to focus on just one aspect: running inference on a specific LLM . Just how difficult is that?
What is true decentralization?
When we talk about decentralized AI inference, we mean something very specific. It’s not just about having AI models running on multiple servers, but about building a system where anyone can join, contribute computing power, and be rewarded for honest work.
The key requirement is that the system must be trustless . This means you don't have to trust any single person or company to run the system correctly. If you're letting strangers on the internet run your AI model, you need cryptographic guarantees that they're actually doing what they claim to be doing (at least with a sufficiently high probability).
This trustless requirement has some interesting implications. First, it means the system needs to be verifiable : you need to be able to prove that the same model and the same parameters were used to generate a given output. This is particularly important for smart contracts that need to verify that the AI responses they receive are legitimate.
But there's a challenge: the more verification you add, the slower the entire system becomes, as network power is consumed by verification. If you completely trust everyone, there's no need for verification reasoning, and performance is almost identical to centralized providers. But if you trust no one and always verify everything, the system becomes incredibly slow and uncompetitive with centralized solutions.
This is the core contradiction we have been working to resolve: finding the right balance between security and performance .
Blockchain and Proof of Reasoning
So how do you actually verify that someone ran the correct model and parameters? Blockchain becomes an obvious choice — while it has its own challenges, it remains the most reliable way we know of to create an immutable record of events.
The basic idea is fairly straightforward. When someone runs inference, they need to provide proof that they used the correct model. This proof is recorded on the blockchain, creating a permanent, tamper-proof record that anyone can verify.
The problem is that blockchains are slow. Really, really slow. If we tried to record every step of reasoning on-chain, the sheer volume of data would quickly overwhelm the network. This constraint drove many of our decisions when designing the Gonka Network.
When designing a network and thinking about distributed computing, there are multiple strategies to choose from. Can you shard a model across multiple nodes, or keep the entire model resident on a single node? The primary limitations come from network bandwidth and blockchain speed. To make our solution feasible, we chose to fit a full model on a single node, though this may change in the future. This does impose a minimum requirement for joining the network, as each node needs sufficient computing power and memory to run the entire model. However, a model can still be sharded across multiple GPUs belonging to the same node, giving us some flexibility within the constraints of a single node. We use vLLM, which allows customization of tensor and pipeline parallelism parameters for optimal performance.
How it actually works
Therefore, we agreed that each node hosts a complete model and runs full inference, eliminating the need for coordination across multiple machines during the actual computation. The blockchain is used only for record-keeping. We only record transactions and artifacts used for inference verification. The actual computation occurs off-chain.
We want the system to be decentralized, without any single central point directing inference requests to network nodes. In practice, each participant deploys at least two nodes: a network node and one or more reasoning (ML) nodes. The network nodes are responsible for communication (including a chain node connecting to the blockchain and an API node managing user requests), while your ML nodes perform LLM inference.
When an inference request arrives on the network, it reaches one of the API nodes (acting as a "transfer agent"), which randomly selects an "executor" (an ML node from a different participant). To save time and parallelize blockchain logging with the actual LLM computation, the transfer agent (TA) first sends the input request to the executor and records the input on-chain while the executor's ML node is running inference. Once the computation is complete, the executor sends the output to the TA's API node, while its own chain node records a verification artifact on-chain. The TA's API node transmits the output back to the client, which is also recorded on-chain. Of course, these records still contribute to overall network bandwidth constraints.
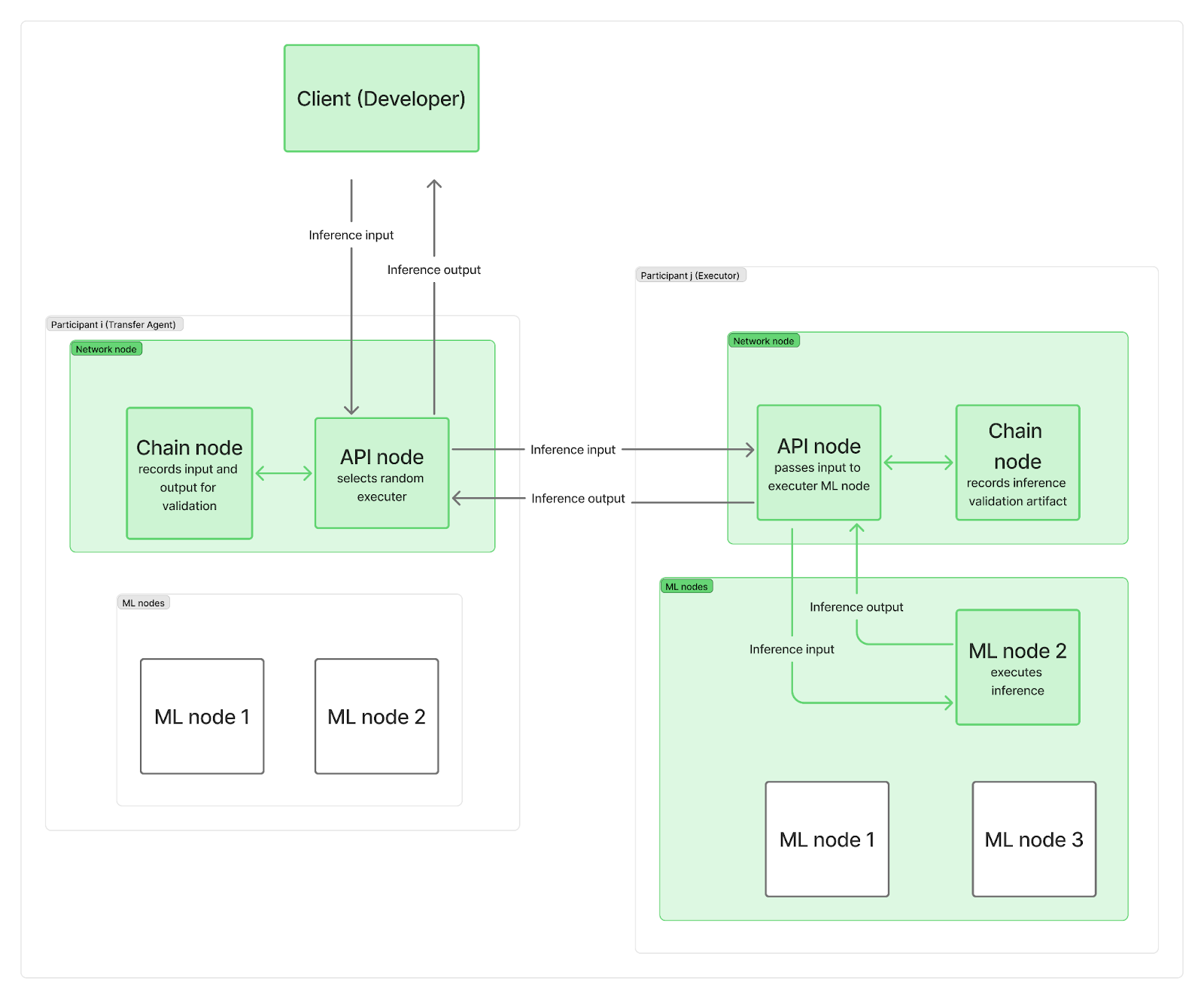
As you can see, blockchain recording neither slows down the start of the inference computation nor the time it takes for the final result to be returned to the client. Verification of whether the inference was completed honestly occurs later, in parallel with other inferences. If the executor is caught cheating, they lose the entire epoch's reward, and the client is notified and receives a refund.
The final question is: What is included in the artifact, and how often do we verify our reasoning?
Security and performance trade-offs
The fundamental challenge is that security and performance are at odds with each other.
If you want maximum security, you need to verify everything. But that's slow and expensive. If you want maximum performance, you need to trust everyone. But that's risky and opens you up to all sorts of attacks.
After some trial, error, and parameter tuning, we found an approach that attempted to balance these two considerations. We had to carefully tune the amount of verification, the timing of verification, and how to make the verification process as efficient as possible. Too much verification, and the system becomes unusable; too little verification, and the system becomes insecure.
Keeping the system lightweight is crucial. We maintain this by storing the top k next- token probabilities. We use these to measure the likelihood that a given output was indeed generated by the claimed model and parameters, and to capture any tampering attempts, such as using a smaller or quantized model, with sufficient confidence. We will describe the implementation of the inference verification procedure in more detail in another post.
At the same time, how do we decide which inferences to verify and which not? We chose a reputation-based approach. When a new participant joins the network, their reputation is 0, and 100% of their inferences must be verified by at least one participant . If a problem is found, the consensus mechanism will ultimately determine whether your inference is approved, or your reputation will be lowered, and you may be kicked off the network. As your reputation grows, the number of inferences that need verification decreases, and eventually 1% of inferences may be randomly selected for verification. This dynamic approach allows us to keep the overall verification percentage low while effectively catching participants who attempt to cheat.
At the end of each epoch, participants are rewarded in proportion to their weight in the network. Tasks are also weighted, so rewards are expected to be proportional to both weight and the amount of work completed. This means we don't need to catch and punish cheaters immediately; it's sufficient to catch them within the epoch before distributing rewards.
Economic incentives drive this trade-off as much as technical parameters. By making cheating expensive and honest participation profitable, we can create a system where the rational choice is honest participation.
Optimize space
After months of building and testing, we've built a system that combines the record-keeping and security advantages of blockchain while approaching the single-shot inference performance of centralized providers. The fundamental tension between security and performance is real, and there's no perfect solution, only different trade-offs.
We believe that as the network scales, it has a real opportunity to compete with centralized providers while maintaining full decentralized community control. There's also significant room for optimization as it develops. If you're interested in learning about this process, please visit our GitHub and documentation, join the discussion on Discord, and participate in the network yourself.
About Gonka.ai
Gonka is a decentralized network designed to provide efficient AI computing power. Its design goal is to maximize the use of global GPU computing power to complete meaningful AI workloads. By eliminating centralized gatekeepers, Gonka provides developers and researchers with permissionless access to computing resources while rewarding all participants with its native GNK token.
Gonka was incubated by US AI developer Product Science Inc. Founded by the Libermans siblings, Web 2 industry veterans and former core product directors at Snap Inc., the company successfully raised $18 million in 2023 from investors including OpenAI investor Coatue Management, Solana investor Slow Ventures, K5, Insight, and Benchmark Partners. Early contributors to the project include well-known leaders in the Web 2-Web 3 space, such as 6 Blocks, Hard Yaka, Gcore, and Bitfury.
Official Website | Github | X | Discord | Whitepaper | Economic Model | User Manual


