The era of centralized computing power is over: AI training is moving from the "computer room" to the "network"
- 核心观点:低通信算法实现分布式AI训练。
- 关键要素:
- DiLoCo算法减少通信量500倍。
- 联邦优化解耦本地与全局计算。
- 成功预训练数十亿参数模型。
- 市场影响:降低AI训练门槛,促进行业民主化。
- 时效性标注:长期影响
Original article by Egor Shulgin, Gonka Protocol
The rapid development of AI technology has pushed its training process to the limits of any single physical location, forcing researchers to confront a fundamental challenge: how to coordinate thousands of processors distributed across continents (rather than within the same hallway of a computer room)? The answer lies in more efficient algorithms—those that work by reducing communication. This shift, driven by breakthroughs in federated optimization and culminating in frameworks like DiLoCo, enables organizations to train models with billions of parameters over standard internet connections, opening up new possibilities for large-scale collaborative AI development.
1. Starting Point: Distributed Training in a Data Center
Modern AI training is inherently distributed. It's widely observed that increasing the size of data, parameters, and computation significantly improves model performance, making it impossible to train basic models (with billions of parameters) on a single machine. The industry's default solution is a "centralized distributed" model: building dedicated data centers housing thousands of GPUs in a single location, interconnected by ultra-high-speed networks such as NVIDIA's NVLink or InfiniBand. These specialized interconnect technologies are orders of magnitude faster than standard networks, enabling all GPUs to operate as a cohesive, integrated system.
In this environment, the most common training strategy is data parallelism, which involves splitting the dataset across multiple GPUs. (Other approaches, such as pipeline parallelism or tensor parallelism, exist, which split the model itself across multiple GPUs. This is necessary for training the largest models, although it is more complex to implement.) Here's how a training step using mini-batch stochastic gradient descent (SGD) works (the same principles apply to the Adam optimizer):
- Replicate and distribute: Load a copy of the model onto each GPU. Split the training data into small batches.
- Parallel computing: Each GPU independently processes a different mini-batch and calculates the gradient — the direction in which the model parameters are adjusted.
- Synchronize and aggregate: All GPUs pause work, share their gradients, and average them to produce a single, unified update.
- Update: Apply this averaged update to each GPU’s copy of the model, ensuring all copies remain identical.
- Repeat: Move to the next small batch and start again.
Essentially, this is a continuous cycle of parallel computation and forced synchronization. The constant communication that occurs after each training step is only feasible with the expensive, high-speed connections within the data center. This reliance on frequent synchronization is a hallmark of centralized distributed training. It operates flawlessly until it leaves the "hothouse" of the data center.
2. Hitting the Wall: A Massive Communication Bottleneck
To train the largest models, organizations must now build infrastructure at an astonishing scale, often requiring multiple data centers across different cities or continents. This geographic separation creates a significant barrier. The step-by-step, synchronized algorithmic approaches that work well within a data center break down when stretched to a global scale.
The problem lies in network speed. Within a data center, InfiniBand can transmit data at speeds of 400 Gb/s or more. Wide Area Networks (WANs) connecting distant data centers, on the other hand, typically operate at speeds approaching 1 Gbps. This performance gap, several orders of magnitude, stems from fundamental limitations of distance and cost. The near-instantaneous communication assumed by small-batch SGD is at odds with this reality.
This disparity creates a severe bottleneck. When model parameters must be synchronized after each step, powerful GPUs sit idle most of the time, waiting for data to slowly crawl across slow networks. The result: the AI community is unable to leverage the vast computing resources distributed globally—from enterprise servers to consumer hardware—because existing algorithms require high-speed, centralized networks. This represents a vast, untapped reservoir of computing power.
3. Algorithm Transformation: Federated Optimization
If frequent communication is the problem, then the solution is to communicate less. This simple insight laid the foundation for an algorithmic shift that draws on techniques from federated learning—a field originally focused on training models on decentralized data on end devices (such as mobile phones) while preserving privacy. Its core algorithm , Federated Averaging (FedAvg), showed that by allowing each device to perform multiple training steps locally before sending an update, the number of required communication rounds can be reduced by orders of magnitude.
Researchers realized that the principle of doing more independent work between synchronization intervals is a perfect solution to address performance bottlenecks in geographically distributed settings. This led to the emergence of the Federated Optimization (FedOpt) framework, which adopts a dual-optimizer approach to decouple local computation from global communication.
The framework operates using two different optimizers:
- The internal optimizer (such as standard SGD) runs on each machine, performing multiple independent training steps on its local slice of data. Each model replica makes significant progress on its own.
- The external optimizer handles infrequent global synchronization. After multiple local steps, each worker node calculates the total change in its model parameters. These changes are aggregated, and the external optimizer uses this averaged update to adjust the global model for the next epoch.
This dual-optimizer architecture fundamentally changes the dynamics of training. Instead of frequent, step-by-step communication between all nodes, it becomes a series of extended, independent computation periods followed by a single aggregate update. This algorithmic shift, stemming from privacy research, provides a crucial breakthrough for enabling training on slow networks. The question is: can it be applied to large-scale language models?
The following is a diagram of the federated optimization framework: local training and periodic global synchronization 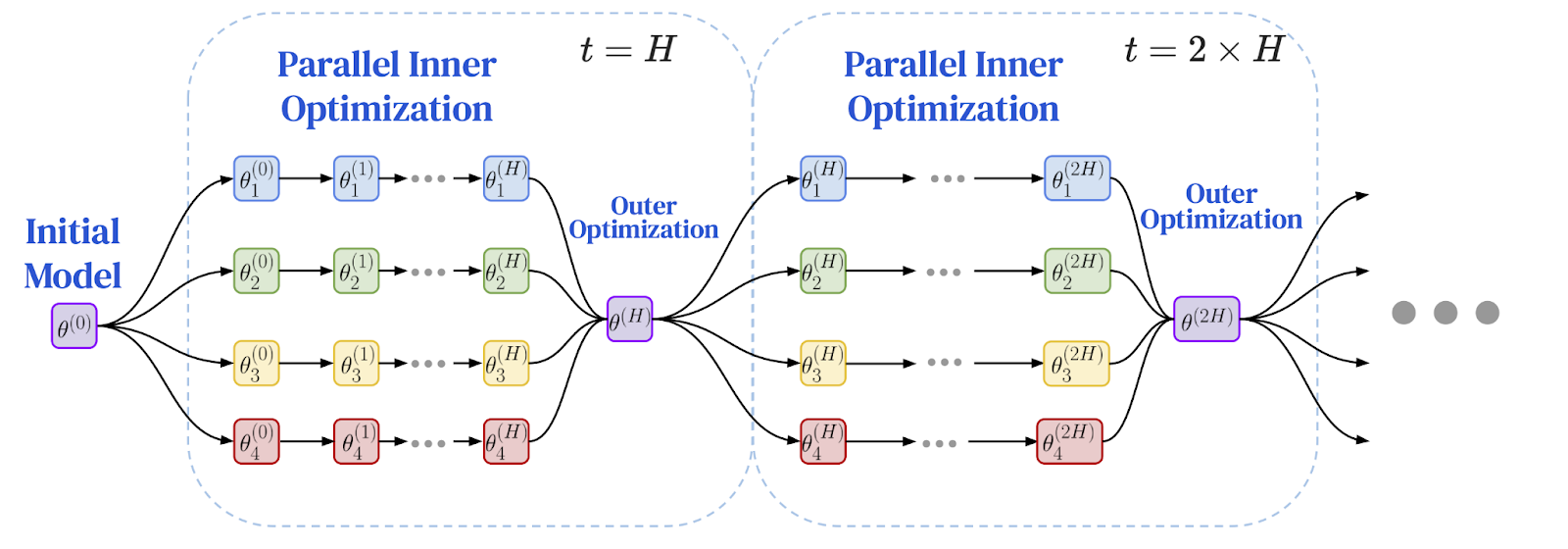
Image source: Charles, Z., et al. (2025). "Communication-Efficient Language Model Training Scales Reliably and Robustly: Scaling Laws for DiLoCo." arXiv:2503.09799
4. Breakthrough: DiLoCo proves its feasibility at scale
The answer comes in the form of the DiLoCo (Distributed Low Communication) algorithm, which demonstrates the practical feasibility of federated optimization for large language models. DiLoCo provides a specific, carefully tuned scheme for training modern Transformer models on slow networks:
- Internal optimizer: AdamW, a cutting-edge optimizer for large language models, runs multiple local training steps on each worker node.
- External optimizer: Nesterov Momentum, a powerful and well-understood algorithm that handles infrequent global updates.
Initial experiments show that DiLoCo can match the performance of fully synchronous datacenter training while reducing inter-node communication by up to 500x, demonstrating the feasibility of training large models over the internet.
This breakthrough quickly gained traction. The open-source implementation, OpenDiLoCo, replicated the original results and integrated the algorithm into a truly peer-to-peer framework using the Hivemind library, making the technology more accessible. This momentum ultimately led to successful large-scale pre-training efforts by organizations like PrimeIntellect , Nous Research , and FlowerLabs , which demonstrated successful pre-training of multi-billion-parameter models over the internet using low-communication algorithms. These pioneering efforts transformed DiLoCo-style training from a promising research paper into a proven method for building foundational models outside of centralized providers.
5. Frontier Exploration: Advanced Technologies and Future Research
The success of DiLoCo has spurred a new wave of research focused on further improving its efficiency and scale. A key step in the method's maturation was the development of DiLoCo scaling laws , which establish that DiLoCo's performance scales predictably and robustly with model size. These scaling laws predict that as models become larger, a well-tuned DiLoCo can outperform traditional data-parallel training for a fixed computational budget, while using orders of magnitude less bandwidth.
To handle models with over 100 billion parameters, researchers have extended the DiLoCo design with techniques like DiLoCoX , which combines a dual-optimizer approach with pipeline parallelism. DiLoCoX makes it possible to pre-train a 107 billion-parameter model over a standard 1 Gbps network. Further improvements include streaming DiLoCo (which overlaps communication and computation to hide network latency) and asynchronous approaches (which prevent a single slow node from becoming a bottleneck for the entire system).
Innovation is also happening at the core of the algorithms. Research on novel internal optimizers like Muon has led to MuLoCo , a variant that allows model updates to be compressed to 2 bits with negligible performance loss, achieving an 8x reduction in data transfer. Perhaps the most ambitious research direction is model parallelism over the internet, which involves splitting the model itself across different machines. Early research in this area, such as SWARM parallelism , developed fault-tolerant methods for distributing model layers across heterogeneous and unreliable devices connected by slow networks. Building on these concepts, teams like Pluralis Research have demonstrated the possibility of training multi-billion-parameter models where different layers are hosted on geographically diverse GPUs, opening the door to training models on distributed consumer hardware connected only by standard internet connections.
6. Trust Challenge: Governance in Open Networks
As training moves from controlled data centers to open, permissionless networks, a fundamental problem emerges: trust. In a truly decentralized system without a central authority, how can participants verify that the updates they receive from others are legitimate? How can malicious actors be prevented from poisoning the model, or lazy actors from claiming rewards for work they never completed? This governance issue is the final hurdle.
One line of defense is Byzantine fault tolerance —a concept from distributed computing that aims to design systems that can function even if some participants fail or actively act maliciously. In a centralized system, servers can apply robust aggregation rules to discard malicious updates. This is more difficult to achieve in a peer-to-peer environment, where there is no central aggregator. Instead, each honest node must evaluate updates from its neighbors and decide which to trust and which to discard.
Another approach involves cryptographic techniques that replace trust with verification. One early idea is Proof -of-Learning, which proposes that participants record training checkpoints to prove that they have invested the necessary computation. Other techniques, such as zero-knowledge proofs (ZKPs), allow worker nodes to prove that they have correctly executed the required training steps without revealing the underlying data, although their current computational cost remains a challenge for verifying the training of today's large-scale infrastructure models.
Outlook: The Dawn of a New AI Paradigm
The journey from walled data centers to the open internet marks a profound shift in how AI is created. We began at the physical limits of centralized training, where progress depended on access to expensive, co-located hardware. This led to communication bottlenecks, a wall that made training massive models across distributed networks impractical. However, this wall wasn't breached by faster cables, but by more efficient algorithms.
This algorithmic shift, rooted in federated optimization and embodied by DiLoCo, demonstrates that reducing communication frequency is key. This breakthrough is being rapidly advanced by a variety of techniques: establishing scaling laws, overlapping communication, exploring new optimizers, and even parallelizing the models themselves over the internet. The successful pre-training of multi-billion-parameter models by a diverse ecosystem of researchers and companies is a testament to the power of this new paradigm.
As trust challenges are addressed through robust defenses and cryptographic verification, the path is becoming clear. Decentralized training is evolving from an engineering solution to a foundational pillar of a more open, collaborative, and accessible AI future. It heralds a world where the ability to build powerful models is no longer limited to a few tech giants, but is distributed globally, unleashing the collective computing power and wisdom of all.
References
McMahan, HB, et al. (2017). Communication-Efficient Learning of Deep Networks from Decentralized Data . International Conference on Artificial Intelligence and Statistics (AISTATS).
Reddi, S., et al. (2021). Adaptive Federated Optimization . International Conference on Learning Representations (ICLR).
Jia, H., et al. (2021). Proof-of-Learning: Definitions and Practice . IEEE Symposium on Security and Privacy.
Ryabinin, Max, et al. (2023). Swarm parallelism: Training large models can be surprisingly communication-efficient . International Conference on Machine Learning (ICML).
Douillard, A., et al. (2023). DiLoCo: Distributed Low-Communication Training of Language Models .
Jaghouar, S., Ong, JM, & Hagemann, J. (2024). OpenDiLoCo: An Open-Source Framework for Globally Distributed Low-Communication Training .
Jaghouar, S., et al. (2024). Decentralized Training of Foundation Models: A Case Study with INTELLECT-1 .
Liu, B., et al. (2024). Asynchronous Local-SGD Training for Language Modeling .
Charles, Z., et al. (2025). Communication-Efficient Language Model Training Scales Reliably and Robustly: Scaling Laws for DiLoCo .
Douillard, A., et al. (2025). Streaming DiLoCo with overlapping communication: Towards a Distributed Free Lunch .
Psyche Team. (2025). Democratizing AI: The Psyche Network Architecture . Nous Research Blog.
Qi, J., et al. (2025). DiLoCoX: A Low-Communication Large-Scale Training Framework for Decentralized Cluster .
Sani, L., et al. (2025). Photon: Federated LLM Pre-Training . Proceedings of the Conference on Machine Learning and Systems (MLSys).
Thérien, B., et al. (2025). MuLoCo: Muon is a practical inner optimizer for DiLoCo .
Long, A., et al. (2025). Protocol Models: Scaling Decentralized Training with Communication-Efficient Model Parallelism .