
How to Use Claude's Dynamic Workflows for In-Depth Research
- Core Insight: Claude Code's Dynamic Workflows, through six built-in structured scheduling modes (such as routing, parallelization, adversarial verification, etc.), upgrade the AI research process from "intelligent conversation" to "automated research framework." This effectively addresses core deficiencies in traditional AI-powered research, such as goal drift, premature termination, and context pollution. However, fully replacing human in-depth research still requires continuous improvement in areas like verification mechanisms, cross-disciplinary thinking, and extreme information condensation.
- Key Elements:
- The core of dynamic workflows lies in AI's ability to automatically design workflows before executing tasks, encompassing steps like problem decomposition, credibility assessment, cross-referencing, and goal-oriented output. This compensates for the lack of convergence and decision-making orientation in traditional skills.
- The six modes include: Routing (precise allocation), Split & Merge (parallel acceleration), Adversarial Verification (eliminating self-evaluation bias), Generate & Filter (diversity prioritization), Tournament (competitive ranking), and Loop (adaptive iteration), covering complex research scheduling.
- The adversarial verification mode structurally eliminates the AI's "confirmation bias" of catering to users. It uses independent agents to contest conclusions through verification, but must be based on reproducible facts rather than opinions to prevent the verifier from biasing the workflow.
- Compared to the author's self-developed deep-research system, the official workflow offers more in areas like problem decomposition, information credibility assessment, voting-based cross-referencing, and consistently outputting around the original goal, significantly reducing redundant conversations (from over a dozen times to 3-4 times).
- AI still has three major limitations: In cutting-edge fields like blockchain technology, it defaults to relying on lagging official documentation rather than on-chain factual data; it lacks deep cross-disciplinary thinking, with mainstream thinking models struggling to address novel topics; solution verification requires balancing cost and mechanism trade-offs, creating a conflict with generality.
- Extreme information condensation depends on precise knowledge of the audience's background. AI finds it difficult to automatically switch between "anthropomorphic, easy-to-understand expressions" and "refined, professional summaries." This is an area where human researchers remain irreplaceable.
這三年下來,我已經離不開用 AI 輔助做產業研究,為此還搭建過一系列的 skill 和輔助系統,來解決資訊的篩選、歸納、連結、驗證與沉澱。
直到這週深度體驗了 Claude Code 的動態工作流之後,才發現「人不要和大時代做對抗」這句話的真正含義。
再次思考:什麼才是 AI 時代下人該做的深度研究,以及如何建構我與 AI 的協作互補關係。
一、從調研的陷阱說起
做技術調研其實是一件充滿陷阱的事(無論對人或 AI),畢竟從調研的開始,會接收到大量的資訊,資訊觀點越來越多,結論越來越模糊。所以時刻要懂得回歸目標本身。
這也一直以來,為什麼 AI 不夠優秀的地方,因為從注意力和聯想的角度看,他會比人類更困於當前的資訊量,並且對於真正有價值的跨界聯想很薄弱。
當然 AI 夠優秀的地方,則是他的執行力,會以 agent 的形式一層層地去尋找、歸納、總結,完全可以避免細節的損耗。
雖然我這半年都沒怎麼對外發公眾號了,但幾乎產業裡主流的戰場我都有在全面地關注和研究,而支撐這輸入輸出的,則是一套自己的 deep-research 系統。
而面對上週 Claude Code 上線了 Dynamic Workflows 這個功能,我想互相 battle 一下,看他的預設能力,能否完全超越我自己。
二、Dynamic Workflows 是什麼
Dynamic Workflows(動態工作流)它的核心思路是:在執行任務之前,先由 AI 自動設計這個任務應該用什麼工作流來完成,然後再啟動執行。
這和我們以前用的「計劃模式」和「skill」有本質區別。計劃模式是把任務拆得更細,但不一定符合某種合理的工作流,隨著你提示詞的安排,才有可能會加驗收指標(這對 Research 而言至關重要),同理你也只有在有提示詞的情況下,他才會更好地預設一些 harness 規則。
但是動態工作流則會自動把驗收邏輯、結果收斂、對抗驗證這些東西都組進來。
觸發方式很簡單,直接在 cc 裡使用 /deep-research 然後提供一些調研模板和入口資料即可,如果想單獨用動態工作流的能力則是提示詞或直接說 ultracode,使用前注意,token 消耗約為平常的數十倍。
三、內建的六種工作流模式
動態工作流的底層,是官方總結的六種核心調度模式,這是它為什麼比普通的對話/agent/skill 更強的原因。
其實這六種模式背後只有兩個核心問題:任務怎麼拆?結果怎麼合? 分開六種本質就是對這兩者的排列組合。
3.1 路由模式(Classify-And-Act)
先由一個 agent 分辨任務類型,再把任務分發給最適合的專門 agent 去做。核心邏輯是路由的選擇邏輯,而非並行或迭代。一個任務只走一條路徑,其他路徑完全不執行。
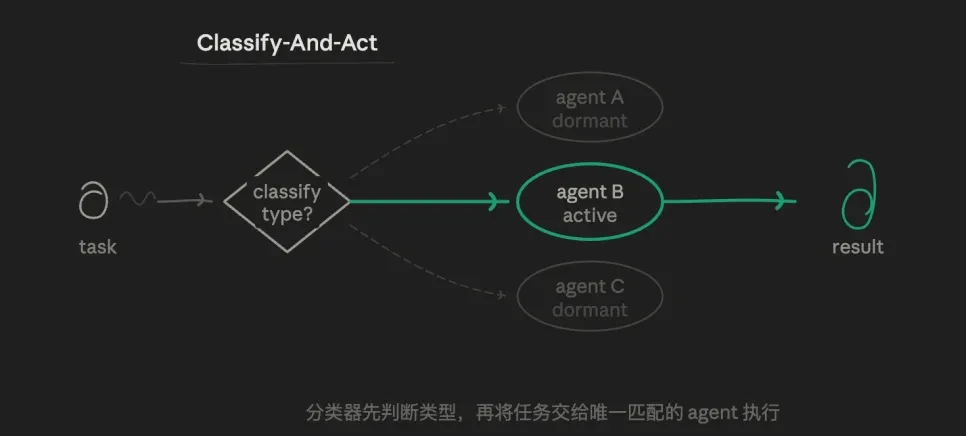
比如我可以先有三個預設 subagent 角色:一個嚴格驗證資料的分析 agent、一個擅長寫作的輸出 agent、一個專門找漏洞的挑戰 agent。讓路由層判斷當前子任務適合交給誰,而不是讓一個 agent 全包。
這種模式的價值在於:精準和節儉,每個 agent 的提示詞可以高度獨立,不被其他目標干擾,形成有垂直深度的探索。token 消耗最低,響應速度最快。職責邊界非常清晰。
缺點也很顯著,對邊界模糊的任務(比如「既是技術問題又是帳戶問題」)處理能力弱。
3.2 拆分合併(Fan-out & Merge)
也是我最常用的模式,核心邏輯是並行+合併。任務拆成 N 個獨立子任務同時跑,等所有完成後統一合併。

優勢在於速度和隔離。總耗時約等於最慢那個子任務,而非所有子任務之和。每個子任務有獨立 context,互不干擾,也不會因為某個子任務的雜訊污染其他子任務。
弱點是 token 成本是序列的 N 倍,合併層(Synthesize)本身也有難度——N 路結構不一致的輸出怎麼融合是個設計挑戰。子任務劃分不好會導致遺漏或重複覆蓋。
3.3 對抗驗證(Adversarial Verification)
核心邏輯是檢驗,對同一個結論,讓多個 agent 從「反駁」的角度去挑戰,票數過半才算通過。
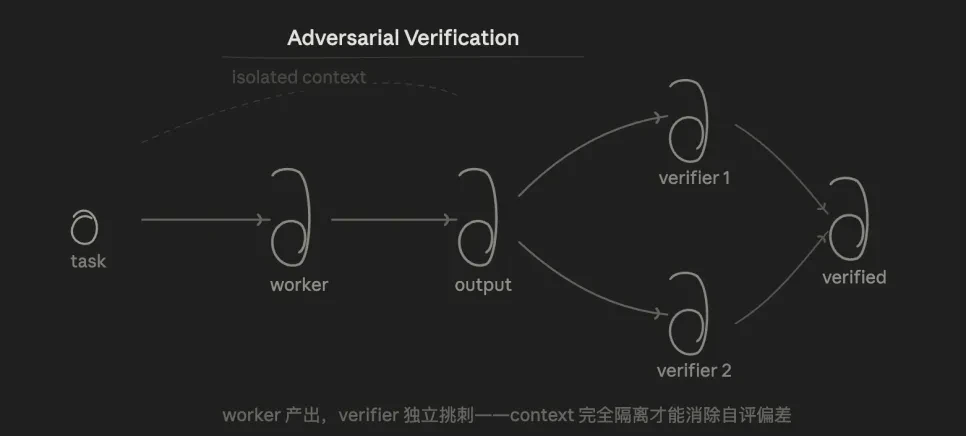
優勢在於,由於 Verifier 不知道 Worker 的思路,只看結果,從結構上消除了「讓模型檢查自己寫的程式碼」時的自評偏差。
這種模式,解決了一個長期困擾我的問題:我們經常使用口語化的方式跟 AI 聊,但 AI 傾向於順著你的預期去回答,容易產生「確認偏誤」。透過對抗驗證強迫 AI 去尋找反例,去基於數據和實驗來驗證,而不是迎合你的想法。
但是,驗證這件事,他如果給出錯誤的判斷,則會帶偏 Worker,去迎合 Verifier。所以優選要基於可重現的事實,而非藉助觀點。
開個玩笑地說,你如果讓 AI 找問題,他能無窮無盡地找出問題,所以你得限制他找問題的邊界。
3.4 生成與過濾(Generate & Filter)
核心邏輯是發散再收斂。先刻意產生過量的候選,再用 rubric 淘汰到精華,只保留高置信度的結果輸出。

與其讓一個 agent 輸出一個「還行」的答案,不如讓它生成十個,再用驗證層篩選。因此優勢在於多樣性。多個 Generator 可以用不同策略、不同提示詞,產出人工難以預想到的解法,過濾步驟讓最終輸出品質高度集中。
弱點則是,Filter 的 rubric 品質直接決定最終效果,rubric 設計錯誤等於整個流程報廢。
適合的場景是事先不知道正確答案的情況、需要從多種可能中擇優、對多樣性有明確需求。
和 Fanout-And-Synthesize 只是表面相似:兩者都是「多路並行 → 單一輸出」,最容易混淆。
關鍵差異在於意圖:Fanout 的每一路都處理任務的不同部分,結果是互補的,合併時所有路都有貢獻;Generate-And-Filter 的每一路處理的是同一個任務,結果是競爭的,合併時大部分會被丟棄。前者是「拼圖」,後者是「選美」。
3.5 錦標賽模式(Tournament)
核心邏輯是競爭淘汰。N個agent各自獨立做同一件事,透過 pairwise 對比逐輪淘汰,最終選出最優解。

這個我以前手動做過——同一份程式碼變更跑兩三個版本,再讓 AI 比對哪個更好。現在可以直接在工作流裡編排進來。
優勢在於評判穩定性。兩兩對比(「A 和 B 哪個更好?」)比絕對評分(「給 A 打分」)穩定得多,因為排除了評分標準漂移的問題。結果經過多輪競爭,最終勝者的可信度高。
和 Generate-And-Filter 也是表面相似: 兩者都是從多個候選中擇優。關鍵差異在於擇優機制:Tournament 用 pairwise judge 兩兩比較,是「讓候選者互相競爭」。當 rubric 難以量化、判斷本質上是相對的時候,會更可靠。
3.6 循環模式(Loop)
核心邏輯是自適應迭代,不斷嘗試,遇到阻力就收集錯誤資訊,補充上下文,重新嘗試,直到滿足驗收條件為止。

本質上是在對抗 AI 的隨機性:多試幾次,總會撞上更好的結果。但更成熟的做法是結合對抗驗證,讓每次循環都帶著更多資訊去執行,而不是純靠隨機。
優勢在於對工作量未知任務的處理能力。其他五種模式都假設任務邊界是確定的, Loop Until Done 是唯一能處理「不知道要做多少輪」的模式。
弱點是潛在的失控風險——停止條件設計不好會無限循環。每一輪的 agent 是全新的 context,無法積累跨輪狀態(除非顯式寫入檔案)。
四、我自己的 skill 和官方工作流的 Battle
在動態工作流出來之前,我專門設計過一套自己的 deep-research 。我那套 skill 的邏輯大概是這樣:
- 只給一個簡單的資訊(比如某項目新上了某功能)
- 讓 AI 去搜尋所有相關資料:官方文件、原始碼、市場輿論
- 把資訊壓縮成有意義的摘要
- 多個 agent 角色做對抗分析,生成報告
- 自動去重,因為多 agent 的內容重複率很高
用了一段時間,我覺得挺好用的。但它有一個根本性的缺陷:缺乏以目標為導向的收斂。
而且很多時候即使有第五步的去重,但這個時候,它經常刪除掉有價值的資訊,如果不做去重,又特別容易 skill 會給你一篇萬字長文,資訊很全,但沒有直接告訴你「這件事跟你有什麼關係、你應該怎麼做」。
然而,研究是為了「決策」服務的,這就是為什麼很多 skill 只能止步於研究本身,有80分,但少了最關鍵的20分。
以至於 AI 在初步完成了研究後,還需繼續十次的思考和對話,才能達成滿意的周全的結論。
官方動態工作流多做了什麼
透過這週幾次複雜調研任務的實驗,我發現,Claude Code 內建的 deep research 工作流(注意不只是 skill,而是編譯內嵌到 cc 裡的模組),對比我自己的 skill 的基礎上,多了幾個關鍵環節:
- 問題拆解層:它不會直接開始搜尋,而是先開始問問題,把我的問題拆成多個子問題:你真正想搞清楚什麼?這件事和你有什麼關係?哪些維度值得深究?這一步我以前是跳過的。
- 可信度評估:對每條資訊評估可證偽性,類似傳統 SEO 裡的權威性評分——來源是否可信?引用次數如何?這是我以前沒想到要加的環節。
- 交叉刪除而非平均合併:我過去的做法是平均選取所有結論,所以文件很大。動態工作流會對每個結論做多 agent 投票,票數不足的刪掉,不是簡單合併。
- 目標導向的輸出:最終的報告不是資訊堆砌,而是圍繞你的原始目標給出判斷和建議方案。而實現這點的關鍵在於他調度多子 agent 的預設能力,我之前之所以 skill 容易缺少最終目標導向,就是因為在海量資訊後,指令權重的衰減。
這些機制解決了什麼問題?
針對的就是 AI 做長任務的幾個典型問題:
目標漂移:任務開始時狀態好,到中間就不知道在幹什麼了,結束時又重新找回節奏——類似人類上課走神。任務越長越明顯。
過早停止:跑著跑著遇到困難,AI 認為自己「完成了」就停下了,實際上驗收標準根本沒過。
上下文污染:單個 agent 做複雜任務,前置的大量 prompt 會壓縮後續執行空間。更好的方式是把前置 prompt 控制在幾 k 以內,用多 agent 來分攤上下文。
輸出偏向:AI 傾向於順著你的預期回答,口語化提問更容易觸發這個問題。
而動態工作流用結構化的方式解決了這四個問題:自動加驗收指標防止過早停止;並行隔離上下文;對抗驗證抵消輸出偏向;拆解問題層層約束 AI 先理解目標再行動。
五、小結
最後,筆者作為個長年的研究工作者,對此 CC 新機制嘆為觀止,它內建的六種模式——路由選擇、拆分合併、對抗驗證、生成過濾、錦標競選、Loop 循環——覆蓋了絕大多數複雜研究任務的調度需求。
讓我不再需要手動設計 agent 調度,也不再需要自己做去重和交叉驗證,這些都被編進工作流本身了。
而且他特別適合在缺少資訊、開發性問題的探究上做思考,因為天然的 multi-agent 調度+任務目標的拆分,讓他在通用性上再次提升。其實早在3年前的 AI,對於一個層層約束、只讓他解決極為清晰的小問題上,已經做得很好了,但是 AI 真正的質變還是在於通用性,這點才是他的競爭對手,從簡單的程式碼變為真正成為 Agent,從固態解決一個問題,到適應任何問題。
所以 Dynamic Workflows 動態工作流不是「更聰明的單次對話」,而是把研究流程本身結構化。
原本我需要發起十幾次獨立對話的調研,現在壓縮到 3-4 次。雖然對應的 Token 消耗是數十倍的增長了。
那為什麼還需 3-4 次呢? 我覺得根因在於這些需求的差異。
第一是驗證機制的嚴苛度,我主要是對區塊鏈上的新技術做研究,很多事情,官方文件都是滯後的,有更值得參考的開源程式碼、鏈上交易等等數據,而目前 AI 預設還是以官方文件為準,而不是以事實性驗證為準。
第二是完全跨界的深度思考,這點雖然透過工作流預設可以解決一些(預定義各種維度的 subAgent)來對同一個問題進行思考。但是 AI 擅長的還是主流思考


