
2026 Tiến triển thực tế và Cơ hội đầu tư của Mạng lưới Điện toán AI Phi tập trung
- Quan điểm cốt lõi: Tính đến đầu năm 2026, lĩnh vực Mạng lưới Cơ sở hạ tầng Vật lý Phi tập trung (DePIN) đã chuyển từ thổi phồng khái niệm sang hiện thực hóa doanh thu, với doanh thu giao thức hàng năm vượt quá 200 triệu đô la Mỹ, chủ yếu phục vụ các khối lượng công việc AI nhạy cảm về chi phí như suy luận và tinh chỉnh, thay vì đào tạo các mô hình lớn tiên tiến.
- Các yếu tố then chốt:
- Tổng vốn hóa thị trường của lĩnh vực DePIN vào khoảng 9,423 tỷ đô la Mỹ, các giao thức hàng đầu như Aethir có doanh thu hàng năm khoảng 150 triệu đô la Mỹ, với khách hàng bao gồm các doanh nghiệp không phải bản địa của tiền điện tử, chứng minh khả năng tạo doanh thu thực tế.
- Lợi thế về giá của mạng GPU phi tập trung là có thật, có thể thấp hơn từ 60-80% so với AWS, nhưng các chi phí ẩn như độ ổn định của nút kém và thiếu SLA sẽ làm xói mòn lợi thế này.
- Bối cảnh thị trường có sự phân tầng rõ ràng: Aethir, io.net, Akash, Bittensor, Render chiếm giữ các vị thế sinh thái khác nhau trong các lĩnh vực doanh thu cấp doanh nghiệp, điều phối cụm ML, cơ chế định giá, khuyến khích mô hình AI và kết xuất.
- Kinh tế học token đang trở nên trưởng thành, các dự án đầu ngành như Render, io.net đang chuyển hướng gắn kết việc đốt/khai thác token với mức tiêu thụ sức mạnh tính toán thực tế, nhằm tránh rủi ro "vòng xoáy tử thần" của các token lạm phát giai đoạn đầu.
- Các doanh nghiệp không phải bản địa của tiền điện tử (ví dụ: khách hàng của KREA bao gồm Nike, Apple) đã bắt đầu mua sức mạnh tính toán phi tập trung, đại diện cho một bước đột phá thực chất trong việc thâm nhập thị trường, nhưng số lượng trường hợp vẫn còn hạn chế.
- Sự kết hợp với nền kinh tế Agent AI là điểm tăng trưởng trong tương lai, bản chất không cần cấp phép của sức mạnh tính toán phi tập trung hoàn toàn phù hợp với nhu cầu mua sức mạnh tính toán của các Agent tự trị.
Chúng ta phải thừa nhận rằng, mảng này đã vượt qua một rào cản lớn mà các câu chuyện tiền điện tử khác chưa từng làm được – nó đang tạo ra doanh thu thực tế từ những khách hàng không phải bản địa tiền điện tử.
Giới thiệu: Cơ hội phi tập trung hóa dưới mâu thuẫn sức mạnh tính toán AI
Năm 2026, thị trường sức mạnh tính toán AI toàn cầu đã bước vào một giai đoạn đầy căng thẳng. Một mặt, các công ty công nghệ hàng đầu đang tập trung tài nguyên GPU với tốc độ chưa từng có, ví dụ:
- Siêu máy tính Colossus của xAI đã tập hợp 550.000 GPU NVIDIA và đang tiến tới mục tiêu 1 triệu GPU theo lộ trình công khai;
- Dự án Stargate do OpenAI, Oracle và SoftBank đồng sáng lập đã triển khai hơn 450.000 GPU NVIDIA tại Texas, với tổng công suất mục tiêu đạt 1,2GW.
Mặt khác, nhiều công ty khởi nghiệp AI vừa và nhỏ, các nhóm nghiên cứu độc lập đang bị phong tỏa sức mạnh tính toán. Cụm H100 của AWS từng có thời gian chờ đợi lên tới 8 đến 12 tháng trong giai đoạn 2023-2024, hóa đơn điện toán đám mây thường xuyên vượt quá vài triệu đô la Mỹ.
Chính trong bối cảnh nguồn cung thiếu hụt nghiêm trọng này, mảng Mạng lưới cơ sở hạ tầng vật lý phi tập trung (DePIN) đã nhanh chóng trỗi dậy.
- Tính đến cuối tháng 3 năm 2026, tổng vốn hóa thị trường của mảng DePIN là khoảng 9,423 tỷ đô la Mỹ, với gần 250 dự án đang hoạt động được CoinGecko theo dõi.
- Mảng này đã đạt đỉnh vốn hóa thị trường khoảng 19,2 tỷ đô la Mỹ vào tháng 9 năm 2025, tăng trưởng khoảng 270% so với cùng kỳ năm 2024 là 5,2 tỷ đô la.
- Quan trọng hơn, theo tổng hợp dữ liệu trên chuỗi từ DeFiLlama và Dune Analytics, doanh thu giao thức hàng năm từ các giao thức tính toán GPU phi tập trung đã vượt quá 200 triệu đô la Mỹ vào đầu năm 2026.
Chúng ta phải thừa nhận rằng, mảng này đã vượt qua một rào cản lớn mà các câu chuyện tiền điện tử khác chưa từng làm được – nó đang tạo ra doanh thu thực tế từ những khách hàng không phải bản địa tiền điện tử.
I. Toàn cảnh ngành: Từ câu chuyện cuồng nhiệt đến hiện thực hóa doanh thu
Năm 2026, ngành công nghiệp sức mạnh tính toán DePIN bắt đầu có dữ liệu doanh thu có thể kiểm chứng, không còn chỉ là sự chồng chất của bảng vốn hóa thị trường và lịch trình phát hành token. Mảng này đã hình thành một cấu trúc phân tầng rõ ràng trong hai năm qua, tình hình hoạt động của các giao thức chính như sau:
Bảng 1: So sánh dữ liệu chính năm 2026 của các mạng lưới sức mạnh tính toán phi tập trung chủ đạo
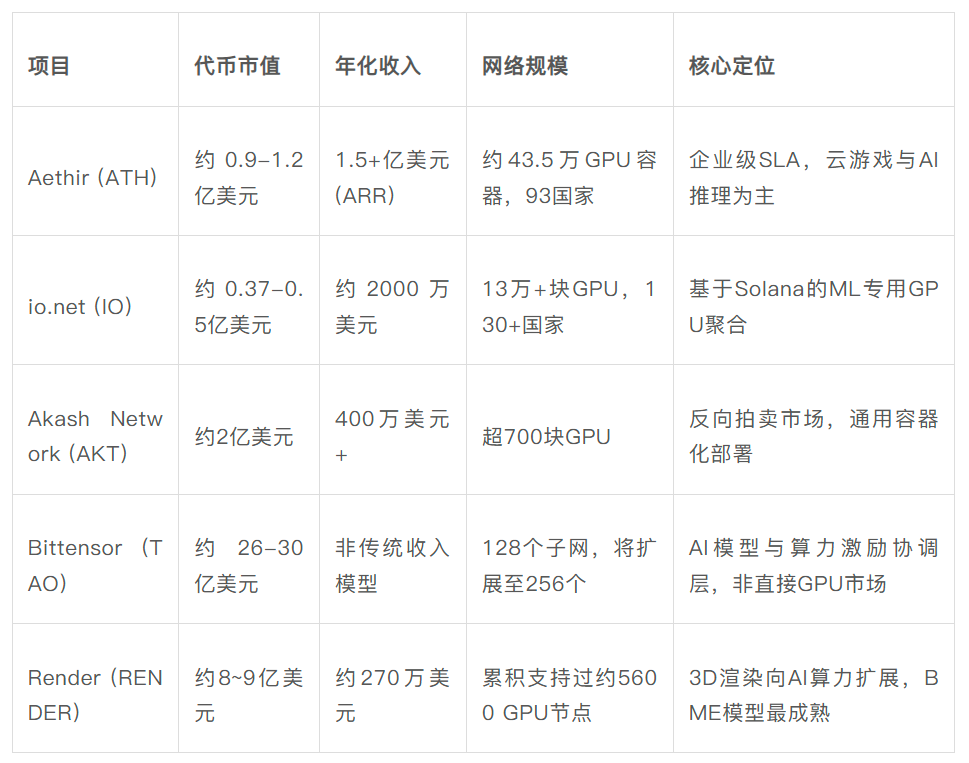
Nguồn dữ liệu: Công bố chính thức của các dự án, báo cáo hàng quý của Messari, CoinMarketCap, CoinGecko / Coinbase, dữ liệu tính đến tháng 5 năm 2026. Lưu ý: Bittensor không có "doanh thu giao thức" theo nghĩa truyền thống – nó là một lớp điều phối khuyến khích mô hình AI, thưởng cho người tham gia bằng cách phát hành token lạm phát và dựa vào từng subnet để tự tạo doanh thu.
Từ bảng trên có thể thấy, năm giao thức này chiếm giữ các vị trí sinh thái khác nhau.
- Aethir dẫn đầu về doanh thu cấp doanh nghiệp, với doanh thu định kỳ hàng năm khoảng 150 triệu đô la Mỹ, hiện là giao thức có quy mô doanh thu lớn nhất trong mảng điện toán phi tập trung. Khách hàng của nó bao gồm các studio game, nhà cung cấp suy luận AI và nhóm huấn luyện mô hình.
- io.net tập trung vào việc điều phối các cụm tính toán ML phân tán, với mạng lưới bao phủ hơn 130.000 thiết bị GPU tại hơn 130 quốc gia.
- Akash tạo ra sự cạnh tranh giá thực sự thông qua cơ chế định giá đấu giá ngược. Chi tiêu sức mạnh tính toán trong quý 1 năm 2026 đã vượt qua mức cao kỷ lục 5 triệu đô la Mỹ, token AKT đã tăng hơn 72% kể từ đầu năm.
- Bittensor hoàn toàn khác biệt, nó không cho thuê phần cứng GPU, mà khuyến khích đầu ra thông minh AI, hình thành một thị trường trí tuệ máy phi tập trung thông qua 128 subnet.
- Render bắt đầu từ kết xuất 3D, đã kết xuất tổng cộng hơn 67 triệu khung hình và đang mở rộng sang lĩnh vực tính toán AI đa năng.
II. Ranh giới năng lực: Mạng lưới GPU phi tập trung có thể làm gì và không thể làm gì
Các mạng lưới GPU phi tập trung từ lâu đã bị kẹt giữa hai luồng quan điểm cực đoan: một bên là những người quảng bá tuyên bố chi phí chỉ bằng 1/10 so với AWS, sắp lật đổ điện toán đám mây; bên kia là những người hoài nghi cho rằng GPU phân tán hoàn toàn không thể hỗ trợ khối lượng công việc AI thực sự. Cả hai nhận định đều phiến diện.
Chìa khóa để hiểu mảng này là nhìn nhận đặc điểm cấu trúc của GPU tiêu dùng.
Một mặt, nguồn cung sức mạnh tính toán của các mạng phi tập trung phần lớn đến từ GPU tiêu dùng, với dung lượng VRAM hạn chế và băng thông giữa các nút phụ thuộc vào băng thông rộng gia đình. Điều này quyết định một cách tự nhiên rằng nó không phù hợp để huấn luyện đồng thời các mô hình lớn tiên tiến – những nhiệm vụ đòi hỏi hàng nghìn GPU cao cấp kết nối với độ trễ cực thấp, một kịch bản được thiết kế riêng cho các đám mây siêu quy mô.
Mặt khác, đối với các khối lượng công việc có độ nhạy cảm với độ trễ cao và nhạy cảm với chi phí, lợi thế về chi phí-hiệu quả của các mạng phi tập trung là khá rõ ràng: sàng lọc phân tử song song trong khám phá thuốc AI, kết xuất hàng loạt văn bản thành hình ảnh và văn bản thành video, và các đường ống tiền xử lý dữ liệu quy mô lớn đều là những kịch bản phù hợp điển hình.
Ngoài ra, sự mở rộng liên tục của các mô hình nguồn mở và sự phát triển kỹ thuật của suy luận nhẹ đang mở rộng một cách có hệ thống thị trường có thể phục vụ của các mạng phi tập trung. Ngày càng nhiều mô hình có thể chạy hiệu quả trên một hoặc một vài GPU tiêu dùng, và rào cản đối với suy luận và tinh chỉnh đang giảm xuống, và đây chính xác là phạm vi cạnh tranh nhất của các mạng phi tập trung.
Biểu đồ 2: Mối quan hệ phù hợp giữa khối lượng công việc AI và cơ sở hạ tầng sức mạnh tính toán
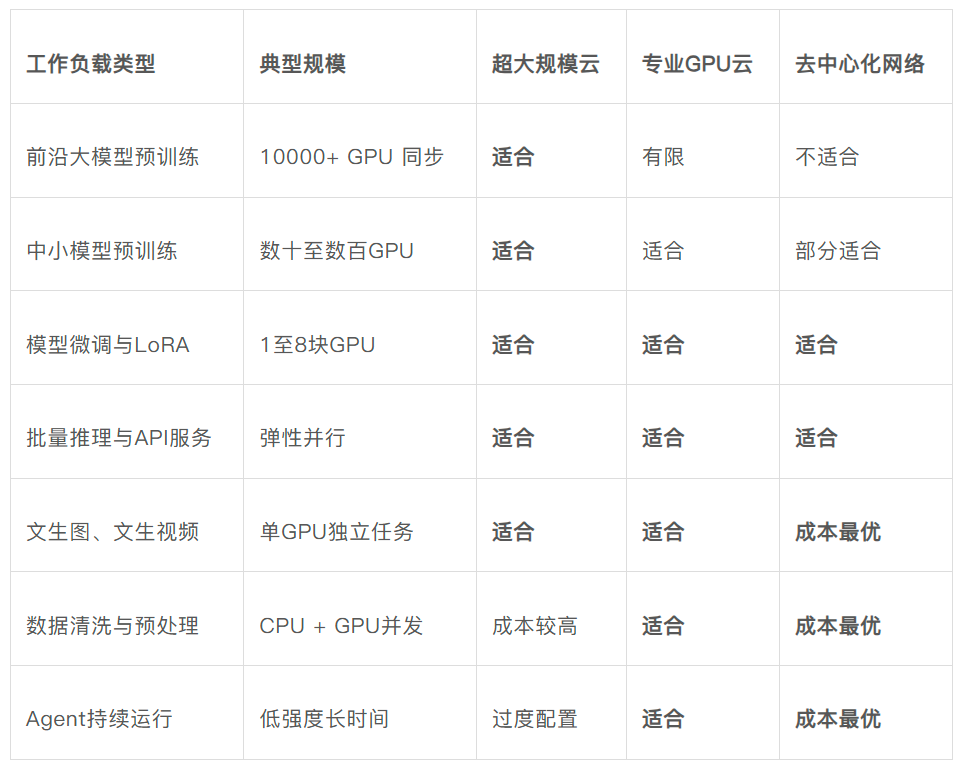
Nguồn dữ liệu: Tổng hợp từ báo cáo huấn luyện đa nút của Together AI (tháng 1 năm 2026), tài liệu kỹ thuật lưu lượng mạng cụm LLM của Dell (tháng 12 năm 2025), phân tích ngành của Cointelegraph (tháng 1 năm 2026).
Dựa trên điều này, cơ hội thực sự của GPU phi tập trung tập trung vào các kịch bản phân mảnh, phân tán và nhạy cảm về giá như suy luận, tinh chỉnh, tiền xử lý dữ liệu, và vận hành liên tục của Agent, chứ không phải cạnh tranh trực tiếp với các đám mây siêu quy mô trong thị trường huấn luyện tiên tiến.
Đáng chú ý, từ môi trường sản xuất AI hiện tại, tỷ lệ huấn luyện trong tổng mức tiêu thụ sức mạnh tính toán đã thấp hơn nhiều so với các nhiệm vụ suy luận và Agent, và loại sau mới là nguồn tăng trưởng chính cho nhu cầu sức mạnh tính toán. Điều này có nghĩa là thị trường mà các mạng phi tập trung nhắm đến không hề bên lề về quy mô – nó tương ứng chính xác với lớp có khối lượng lớn nhất và tốc độ tăng trưởng nhanh nhất trong cấu trúc nhu cầu sức mạnh tính toán AI.
III. Lợi thế về giá có thật không: Có thực sự rẻ hơn 60%?
Một lý do khiến sức mạnh tính toán phi tập trung được ưa chuộng là tuyên bố phổ biến "rẻ hơn 60%". Tuyên bố này xuất phát từ sự so sánh chi phí giữa hai bên. Giá niêm yết công khai trên trang web của Akash Network cho thấy giá thuê theo giờ của GPU H100 là khoảng 1,33 đô la Mỹ; sau khi AWS giảm giá khoảng 44% cho các phiên bản p5 vào tháng 6 năm 2025, giá thuê theo giờ cho một GPU khi chia đều 8 thẻ là khoảng 3,93 đô la Mỹ. Đây là sự so sánh xuất hiện thường xuyên nhất trong hầu hết các báo cáo và cũng là nguồn gốc của tuyên bố "phi tập trung rẻ hơn 60%".
Biểu đồ 3: So sánh giá thuê theo giờ GPU H100 (đầu năm 2026)
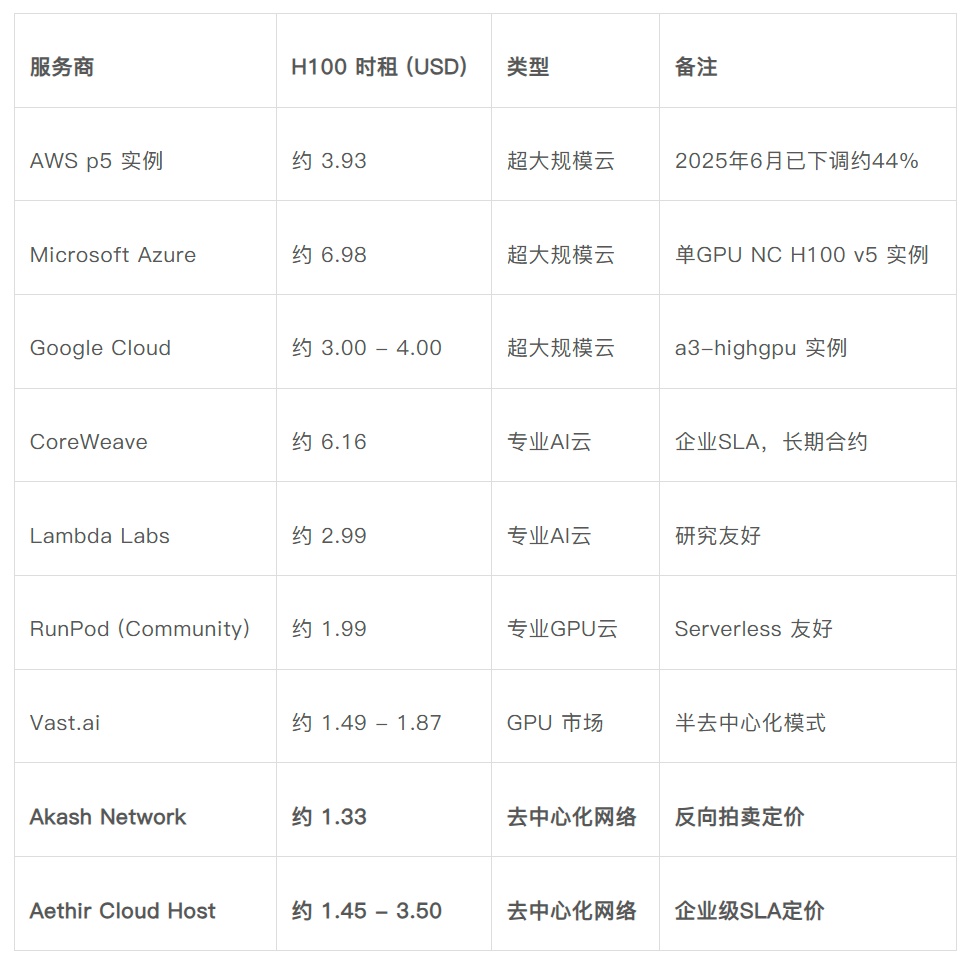
Nguồn dữ liệu: Giá niêm yết công khai của AWS, Azure, Google Cloud; trang web chính thức của Akash Network; tài liệu chính thức của Aethir; getdeploying.com (tháng 5 năm 2026); IntuitionLabs "So sánh giá thuê H100" (tháng 5 năm 2026); Silicon Data "Giá H100 tăng đột biến" (tháng 1 năm 2026).
Bảng trên so sánh sự khác biệt về giá thuê GPU H100 giữa các nền tảng tập trung và mạng phi tập trung. Qua so sánh, có thể rút ra các kết luận sau:
Thứ nhất, lợi thế về giá của các mạng GPU phi tập trung so với các đám mây siêu quy mô là có thật – thấp hơn khoảng 60% so với giá chia đều của AWS p5 và có thể thấp hơn tới 75% đến 80% so với các phiên bản GPU đơn lẻ (AWS/Azure).
Thứ hai, so với các đám mây GPU chuyên nghiệp đã cạnh tranh đầy đủ (RunPod, Vast.ai), khoảng cách giá của các mạng GPU phi tập trung sẽ thu hẹp xuống còn 15% đến 35%, và về cơ bản là ngang bằng trong một số kịch bản.
Thứ ba, điều thực sự tạo nên sự khác biệt là nhiều hơn các thuộc tính cấu trúc. Không cần tài khoản doanh nghiệp, không có cam kết sử dụng tối thiểu, bật tắt theo nhu cầu, phân bố nút linh hoạt về mặt địa lý, không bị khóa nhà cung cấp – đây mới là sức hấp dẫn thực sự của GPU phi tập trung.
Nhưng đồng thời cần chỉ ra một điểm: Chi phí tiềm ẩn cũng không thể bỏ qua. Sự ổn định của các nút trong mạng phi tập trung không đồng đều. Trong các kịch bản sản xuất, cần triển khai dự phòng hoặc tăng cơ chế chịu lỗi, và chi phí bổ sung này sẽ ăn mòn lợi thế giá danh nghĩa ở các mức độ khác nhau. Đây là một trong những rào cản thực tế chính mà doanh nghiệp phải đối mặt khi áp dụng GPU phi tập trung ở quy mô lớn vào năm 2026.
IV. Những thay đổi thực sự trong mảng vào năm 2026
Tổng hợp dữ liệu hiện có, mảng sức mạnh tính toán phi tập trung đang trải


