Kỷ nguyên của sức mạnh tính toán tập trung đã kết thúc: Đào tạo AI đang chuyển từ "phòng máy tính" sang "mạng"
- 核心观点:低通信算法实现分布式AI训练。
- 关键要素:
- DiLoCo算法减少通信量500倍。
- 联邦优化解耦本地与全局计算。
- 成功预训练数十亿参数模型。
- 市场影响:降低AI训练门槛,促进行业民主化。
- 时效性标注:长期影响
Bài viết gốc của Egor Shulgin, Gonka Protocol
Sự phát triển nhanh chóng của công nghệ AI đã đẩy quá trình đào tạo của nó đến giới hạn của bất kỳ địa điểm vật lý đơn lẻ nào, buộc các nhà nghiên cứu phải đối mặt với một thách thức cơ bản: làm thế nào để phối hợp hàng nghìn bộ xử lý phân tán trên khắp các châu lục (thay vì trong cùng một hành lang của một phòng máy tính)? Câu trả lời nằm ở các thuật toán hiệu quả hơn - những thuật toán hoạt động bằng cách giảm thiểu giao tiếp. Sự thay đổi này, được thúc đẩy bởi những đột phá trong tối ưu hóa liên bang và đạt đến đỉnh cao trong các khuôn khổ như DiLoCo, cho phép các tổ chức đào tạo các mô hình với hàng tỷ tham số qua kết nối internet tiêu chuẩn, mở ra những khả năng mới cho việc phát triển AI cộng tác quy mô lớn.
1. Điểm khởi đầu: Đào tạo phân tán trong trung tâm dữ liệu
Đào tạo AI hiện đại vốn dĩ mang tính phân tán. Người ta nhận thấy rộng rãi rằng việc tăng kích thước dữ liệu, tham số và tính toán sẽ cải thiện đáng kể hiệu suất mô hình, khiến việc đào tạo các mô hình cơ bản (với hàng tỷ tham số) trên một máy tính duy nhất trở nên bất khả thi. Giải pháp mặc định là mô hình "phân tán tập trung": xây dựng các trung tâm dữ liệu chuyên dụng chứa hàng nghìn GPU tại một địa điểm duy nhất, được kết nối với nhau bằng các mạng siêu tốc độ như NVLink hoặc InfiniBand của NVIDIA. Các công nghệ kết nối chuyên biệt này nhanh hơn gấp nhiều lần so với các mạng tiêu chuẩn, cho phép tất cả GPU hoạt động như một hệ thống tích hợp, gắn kết.
Trong môi trường này, chiến lược huấn luyện phổ biến nhất là song song dữ liệu, bao gồm việc chia tách tập dữ liệu trên nhiều GPU. (Các phương pháp khác, chẳng hạn như song song đường ống hoặc song song tenxơ, cũng có, chia tách chính mô hình trên nhiều GPU. Điều này cần thiết để huấn luyện các mô hình lớn nhất, mặc dù việc triển khai phức tạp hơn.) Dưới đây là cách thức hoạt động của một bước huấn luyện sử dụng phương pháp giảm dần gradient ngẫu nhiên mini-batch (SGD) (các nguyên tắc tương tự cũng áp dụng cho bộ tối ưu hóa Adam):
- Nhân rộng và phân phối: Tải một bản sao của mô hình lên mỗi GPU. Chia dữ liệu đào tạo thành các lô nhỏ.
- Tính toán song song: Mỗi GPU xử lý độc lập một lô nhỏ khác nhau và tính toán độ dốc — hướng mà các tham số mô hình được điều chỉnh.
- Đồng bộ hóa và tổng hợp: Tất cả GPU tạm dừng công việc, chia sẻ độ dốc của chúng và tính trung bình để tạo ra một bản cập nhật thống nhất duy nhất.
- Cập nhật: Áp dụng bản cập nhật trung bình này cho mỗi bản sao mô hình của GPU, đảm bảo tất cả các bản sao đều giống hệt nhau.
- Lặp lại: Chuyển sang lô nhỏ tiếp theo và bắt đầu lại.
Về cơ bản, đây là một chu trình liên tục của tính toán song song và đồng bộ hóa cưỡng bức. Việc giao tiếp liên tục diễn ra sau mỗi bước huấn luyện chỉ khả thi với các kết nối tốc độ cao, đắt tiền trong trung tâm dữ liệu. Sự phụ thuộc vào đồng bộ hóa thường xuyên này là một đặc điểm nổi bật của huấn luyện phân tán tập trung. Nó hoạt động hoàn hảo cho đến khi rời khỏi "nhà kính" của trung tâm dữ liệu.
2. Va vào tường: Một nút thắt giao tiếp lớn
Để đào tạo các mô hình lớn nhất, các tổ chức hiện phải xây dựng cơ sở hạ tầng ở quy mô đáng kinh ngạc, thường đòi hỏi nhiều trung tâm dữ liệu ở nhiều thành phố hoặc châu lục khác nhau. Sự phân chia địa lý này tạo ra một rào cản đáng kể. Các phương pháp tiếp cận thuật toán đồng bộ từng bước, vốn hiệu quả trong một trung tâm dữ liệu, sẽ bị phá vỡ khi mở rộng ra quy mô toàn cầu.
Vấn đề nằm ở tốc độ mạng. Trong một trung tâm dữ liệu, InfiniBand có thể truyền dữ liệu với tốc độ 400 Gb/giây hoặc hơn. Mặt khác, Mạng diện rộng (WAN) kết nối các trung tâm dữ liệu ở xa thường hoạt động ở tốc độ gần 1 Gbps. Khoảng cách hiệu suất này, theo cấp số nhân, bắt nguồn từ những hạn chế cơ bản về khoảng cách và chi phí. Khả năng truyền thông gần như tức thời của SGD lô nhỏ lại trái ngược với thực tế này.
Sự chênh lệch này tạo ra một nút thắt cổ chai nghiêm trọng. Khi các tham số mô hình phải được đồng bộ hóa sau mỗi bước, các GPU mạnh mẽ hầu như luôn ở trạng thái nhàn rỗi, chờ dữ liệu chậm chạp di chuyển qua các mạng chậm. Kết quả là: cộng đồng AI không thể tận dụng được nguồn tài nguyên điện toán khổng lồ được phân bổ trên toàn cầu - từ máy chủ doanh nghiệp đến phần cứng tiêu dùng - vì các thuật toán hiện tại đòi hỏi mạng tập trung tốc độ cao. Điều này đại diện cho một nguồn năng lực điện toán khổng lồ chưa được khai thác.
3. Chuyển đổi thuật toán: Tối ưu hóa liên bang
Nếu giao tiếp thường xuyên là vấn đề, thì giải pháp là giao tiếp ít hơn. Nhận thức đơn giản này đã đặt nền móng cho một sự thay đổi thuật toán dựa trên các kỹ thuật từ học liên bang - một lĩnh vực ban đầu tập trung vào việc đào tạo các mô hình trên dữ liệu phi tập trung trên các thiết bị đầu cuối (chẳng hạn như điện thoại di động) mà vẫn đảm bảo quyền riêng tư. Thuật toán cốt lõi của nó , Trung bình Liên bang (FedAvg), đã chứng minh rằng bằng cách cho phép mỗi thiết bị thực hiện nhiều bước đào tạo cục bộ trước khi gửi bản cập nhật, số vòng giao tiếp cần thiết có thể giảm đáng kể.
Các nhà nghiên cứu nhận ra rằng nguyên tắc thực hiện nhiều công việc độc lập hơn giữa các khoảng thời gian đồng bộ hóa là một giải pháp hoàn hảo để giải quyết các điểm nghẽn hiệu suất trong các môi trường phân tán về mặt địa lý. Điều này dẫn đến sự ra đời của khuôn khổ Tối ưu hóa Liên bang (FedOpt), áp dụng phương pháp tối ưu hóa kép để tách biệt tính toán cục bộ khỏi giao tiếp toàn cầu.
Khung hoạt động bằng cách sử dụng hai trình tối ưu hóa khác nhau:
- Bộ tối ưu hóa nội bộ (chẳng hạn như SGD tiêu chuẩn) chạy trên mỗi máy, thực hiện nhiều bước huấn luyện độc lập trên phần dữ liệu cục bộ của máy. Mỗi bản sao mô hình đều tự đạt được tiến bộ đáng kể.
- Bộ tối ưu hóa bên ngoài xử lý đồng bộ hóa toàn cục không thường xuyên. Sau nhiều bước cục bộ, mỗi nút công nhân sẽ tính toán tổng thay đổi trong các tham số mô hình của nó. Những thay đổi này được tổng hợp và bộ tối ưu hóa bên ngoài sử dụng bản cập nhật trung bình này để điều chỉnh mô hình toàn cục cho kỷ nguyên tiếp theo.
Kiến trúc tối ưu kép này về cơ bản thay đổi động lực của quá trình huấn luyện. Thay vì giao tiếp thường xuyên, từng bước giữa tất cả các nút, nó trở thành một chuỗi các chu kỳ tính toán độc lập, kéo dài, theo sau là một lần cập nhật tổng hợp duy nhất. Sự thay đổi thuật toán này, xuất phát từ nghiên cứu về quyền riêng tư, mang đến một bước đột phá quan trọng cho phép huấn luyện trên các mạng chậm. Câu hỏi đặt ra là: liệu nó có thể được áp dụng cho các mô hình ngôn ngữ quy mô lớn hay không?
Sau đây là sơ đồ của khuôn khổ tối ưu hóa liên bang: đào tạo cục bộ và đồng bộ hóa toàn cầu định kỳ 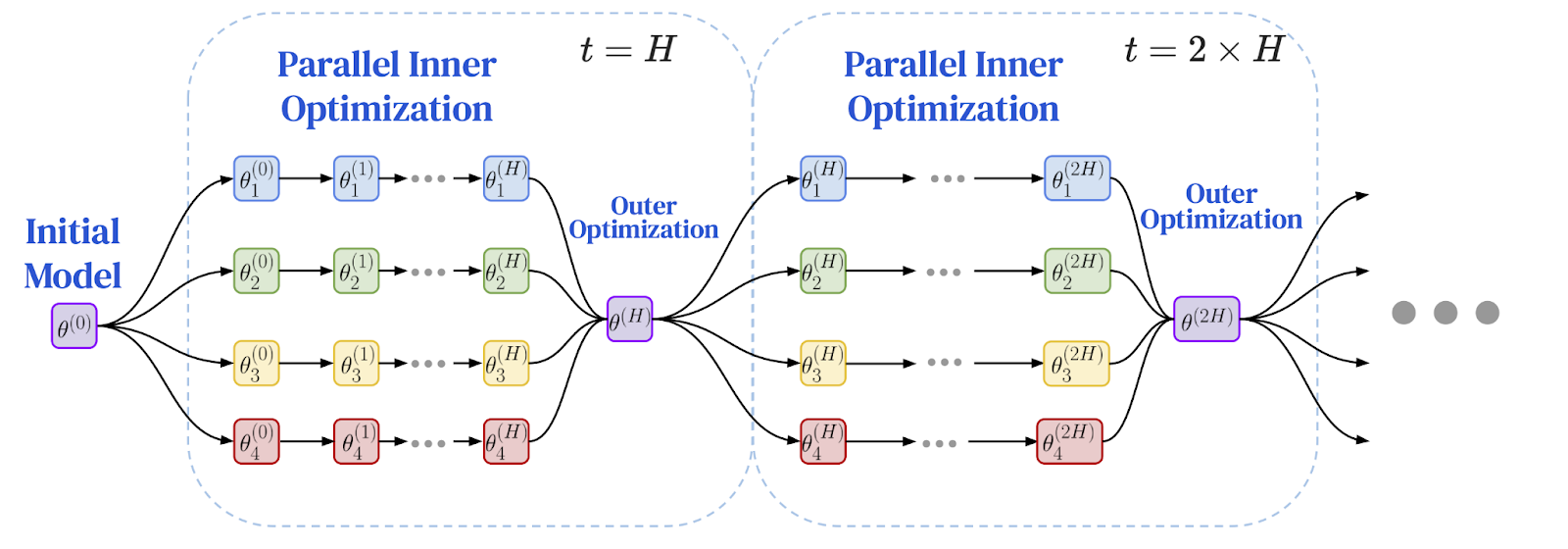
Nguồn hình ảnh: Charles, Z., và cộng sự (2025). "Mô hình Ngôn ngữ Hiệu quả Giao tiếp Đào tạo Quy mô Đáng tin cậy và Mạnh mẽ: Luật Quy mô cho DiLoCo." arXiv:2503.09799
4. Đột phá: DiLoCo chứng minh tính khả thi ở quy mô lớn
Câu trả lời nằm ở thuật toán DiLoCo (Truyền thông Phân tán Thấp) , minh họa tính khả thi thực tế của tối ưu hóa liên kết cho các mô hình ngôn ngữ lớn. DiLoCo cung cấp một lược đồ cụ thể, được tinh chỉnh cẩn thận để huấn luyện các mô hình Transformer hiện đại trên các mạng chậm:
- Bộ tối ưu hóa nội bộ: AdamW, một bộ tối ưu hóa tiên tiến cho các mô hình ngôn ngữ lớn, chạy nhiều bước đào tạo cục bộ trên mỗi nút công nhân.
- Công cụ tối ưu hóa bên ngoài: Nesterov Momentum, một thuật toán mạnh mẽ và dễ hiểu, xử lý các bản cập nhật toàn cầu không thường xuyên.
Các thử nghiệm ban đầu cho thấy DiLoCo có thể đạt được hiệu suất đào tạo trung tâm dữ liệu đồng bộ hoàn toàn trong khi giảm giao tiếp giữa các nút lên đến 500 lần, chứng minh tính khả thi của việc đào tạo các mô hình lớn qua Internet.
Bước đột phá này nhanh chóng thu hút sự chú ý. Việc triển khai mã nguồn mở, OpenDiLoCo, đã sao chép các kết quả ban đầu và tích hợp thuật toán vào một khuôn khổ ngang hàng thực sự bằng cách sử dụng thư viện Hivemind, giúp công nghệ này dễ tiếp cận hơn. Động lực này cuối cùng đã dẫn đến những nỗ lực tiền huấn luyện quy mô lớn thành công của các tổ chức như PrimeIntellect , Nous Research và FlowerLabs , những tổ chức đã chứng minh việc tiền huấn luyện thành công các mô hình hàng tỷ tham số qua internet bằng các thuật toán ít giao tiếp. Những nỗ lực tiên phong này đã biến đào tạo theo kiểu DiLoCo từ một bài báo nghiên cứu đầy hứa hẹn thành một phương pháp đã được chứng minh để xây dựng các mô hình nền tảng bên ngoài các nhà cung cấp tập trung.
5. Khám phá biên giới: Công nghệ tiên tiến và nghiên cứu tương lai
Thành công của DiLoCo đã thúc đẩy một làn sóng nghiên cứu mới tập trung vào việc cải thiện hơn nữa hiệu quả và quy mô của nó. Một bước quan trọng trong quá trình hoàn thiện phương pháp này là sự phát triển của các quy luật mở rộng DiLoCo , xác lập rằng hiệu suất của DiLoCo có thể mở rộng một cách dự đoán và mạnh mẽ theo kích thước mô hình. Các quy luật mở rộng này dự đoán rằng khi mô hình trở nên lớn hơn, một DiLoCo được tinh chỉnh tốt có thể vượt trội hơn so với phương pháp huấn luyện song song dữ liệu truyền thống với ngân sách tính toán cố định, trong khi sử dụng băng thông ít hơn hàng bậc độ lớn.
Để xử lý các mô hình với hơn 100 tỷ tham số, các nhà nghiên cứu đã mở rộng thiết kế DiLoCo bằng các kỹ thuật như DiLoCoX , kết hợp phương pháp tối ưu kép với cơ chế song song đường ống. DiLoCoX cho phép huấn luyện trước một mô hình 107 tỷ tham số trên mạng chuẩn 1 Gbps. Các cải tiến khác bao gồm truyền phát DiLoCo (chồng chéo giao tiếp và tính toán để ẩn độ trễ mạng) và các phương pháp bất đồng bộ (ngăn chặn một nút chậm duy nhất trở thành nút thắt cổ chai cho toàn bộ hệ thống).
Sự đổi mới cũng đang diễn ra ở cốt lõi của các thuật toán. Nghiên cứu về các trình tối ưu hóa nội bộ mới như Muon đã dẫn đến MuLoCo , một biến thể cho phép nén các bản cập nhật mô hình thành 2 bit với tổn thất hiệu suất không đáng kể, đạt được mức giảm 8 lần trong việc truyền dữ liệu. Có lẽ hướng nghiên cứu đầy tham vọng nhất là song song hóa mô hình trên internet, bao gồm việc chia tách chính mô hình trên các máy khác nhau. Nghiên cứu ban đầu trong lĩnh vực này, chẳng hạn như song song hóa SWARM , đã phát triển các phương pháp chịu lỗi để phân phối các lớp mô hình trên các thiết bị không đồng nhất và không đáng tin cậy được kết nối bằng mạng chậm. Dựa trên các khái niệm này, các nhóm như Pluralis Research đã chứng minh khả năng đào tạo các mô hình nhiều tỷ tham số trong đó các lớp khác nhau được lưu trữ trên các GPU đa dạng về mặt địa lý, mở ra cánh cửa cho việc đào tạo các mô hình trên phần cứng tiêu dùng phân tán chỉ được kết nối bằng các kết nối internet tiêu chuẩn.
6. Thách thức về lòng tin: Quản trị trong các mạng mở
Khi đào tạo chuyển từ các trung tâm dữ liệu được kiểm soát sang các mạng lưới mở, không cần cấp phép, một vấn đề cơ bản nảy sinh: lòng tin. Trong một hệ thống thực sự phi tập trung không có cơ quan quản lý trung ương, làm thế nào người tham gia có thể xác minh tính hợp lệ của các bản cập nhật họ nhận được từ người khác? Làm thế nào để ngăn chặn các tác nhân độc hại đầu độc mô hình, hoặc ngăn chặn các tác nhân lười biếng nhận phần thưởng cho công việc mà họ chưa hoàn thành? Vấn đề quản trị này chính là rào cản cuối cùng.
Một phương án phòng thủ là khả năng chịu lỗi Byzantine — một khái niệm từ điện toán phân tán, nhằm mục đích thiết kế các hệ thống có thể hoạt động ngay cả khi một số thành viên gặp sự cố hoặc chủ động hành động độc hại. Trong một hệ thống tập trung, máy chủ có thể áp dụng các quy tắc tổng hợp mạnh mẽ để loại bỏ các bản cập nhật độc hại. Điều này khó đạt được hơn trong môi trường ngang hàng, nơi không có bộ tổng hợp tập trung. Thay vào đó, mỗi nút trung thực phải đánh giá các bản cập nhật từ các nút lân cận và quyết định nên tin tưởng và loại bỏ bản cập nhật nào.
Một phương pháp khác liên quan đến các kỹ thuật mật mã thay thế niềm tin bằng xác minh. Một ý tưởng ban đầu là Proof -of-Learning (Bằng chứng Học tập), đề xuất rằng người tham gia ghi lại các điểm kiểm tra đào tạo để chứng minh rằng họ đã đầu tư các tính toán cần thiết. Các kỹ thuật khác, chẳng hạn như bằng chứng không kiến thức (ZKP), cho phép các nút công nhân chứng minh rằng họ đã thực hiện đúng các bước đào tạo cần thiết mà không tiết lộ dữ liệu cơ bản, mặc dù chi phí tính toán hiện tại của chúng vẫn là một thách thức đối với việc xác minh quá trình đào tạo của các mô hình cơ sở hạ tầng quy mô lớn hiện nay.
Triển vọng: Sự khởi đầu của một mô hình AI mới
Hành trình từ các trung tâm dữ liệu khép kín đến internet mở đánh dấu một bước chuyển mình sâu sắc trong cách thức tạo ra AI. Chúng ta bắt đầu từ những giới hạn vật lý của đào tạo tập trung, nơi tiến độ phụ thuộc vào việc tiếp cận phần cứng đắt tiền, đặt cùng vị trí. Điều này dẫn đến tình trạng tắc nghẽn giao tiếp, một rào cản khiến việc đào tạo các mô hình quy mô lớn trên các mạng phân tán trở nên không thực tế. Tuy nhiên, rào cản này không bị phá vỡ bởi cáp nhanh hơn, mà bởi các thuật toán hiệu quả hơn.
Sự thay đổi thuật toán này, bắt nguồn từ tối ưu hóa liên bang và được thể hiện bởi DiLoCo, chứng minh rằng việc giảm tần suất giao tiếp là chìa khóa. Bước đột phá này đang được thúc đẩy nhanh chóng nhờ nhiều kỹ thuật khác nhau: thiết lập các quy luật mở rộng, giao tiếp chồng chéo, khám phá các bộ tối ưu hóa mới, và thậm chí song song hóa các mô hình trên internet. Việc đào tạo trước thành công các mô hình hàng tỷ tham số bởi một hệ sinh thái đa dạng gồm các nhà nghiên cứu và công ty là minh chứng cho sức mạnh của mô hình mới này.
Khi các thách thức về lòng tin được giải quyết thông qua các biện pháp phòng thủ mạnh mẽ và xác minh mật mã, con đường đang trở nên rõ ràng hơn. Đào tạo phi tập trung đang phát triển từ một giải pháp kỹ thuật thành trụ cột nền tảng cho một tương lai AI cởi mở, hợp tác và dễ tiếp cận hơn. Nó báo hiệu một thế giới nơi khả năng xây dựng các mô hình mạnh mẽ không còn giới hạn ở một vài gã khổng lồ công nghệ, mà được phân phối trên toàn cầu, giải phóng sức mạnh tính toán và trí tuệ tập thể của tất cả mọi người.
Tài liệu tham khảo
McMahan, HB, và cộng sự (2017). Học tập hiệu quả về truyền thông của mạng lưới sâu từ dữ liệu phi tập trung . Hội nghị quốc tế về trí tuệ nhân tạo và thống kê (AISTATS).
Reddi, S., et al. (2021). Tối ưu hóa liên bang thích ứng . Hội nghị quốc tế về biểu diễn học tập (ICLR).
Jia, H., et al. (2021). Bằng chứng học tập: Định nghĩa và thực hành . Hội thảo IEEE về Bảo mật và Quyền riêng tư.
Ryabinin, Max, và cộng sự (2023). Song song bầy đàn: Việc huấn luyện các mô hình lớn có thể mang lại hiệu quả giao tiếp đáng kinh ngạc . Hội nghị Quốc tế về Học máy (ICML).
Douillard, A., et al. (2023). DiLoCo: Đào tạo mô hình ngôn ngữ giao tiếp thấp phân tán .
Jaghouar, S., Ong, JM, & Hagemann, J. (2024). OpenDiLoCo: Khung nguồn mở dành cho đào tạo giao tiếp thấp được phân phối trên toàn cầu .
Jaghouar, S., et al. (2024). Đào tạo phi tập trung các mô hình nền tảng: Nghiên cứu điển hình với INTELLECT-1 .
Liu, B., et al. (2024). Đào tạo SGD cục bộ không đồng bộ cho mô hình hóa ngôn ngữ .
Charles, Z., et al. (2025). Mô hình ngôn ngữ hiệu quả giao tiếp có quy mô đào tạo đáng tin cậy và mạnh mẽ: Luật mở rộng cho DiLoCo .
Douillard, A., et al. (2025). Truyền phát DiLoCo với giao tiếp chồng chéo: Hướng tới bữa trưa miễn phí phân tán .
Nhóm Psyche. (2025). Dân chủ hóa AI: Kiến trúc mạng Psyche . Blog nghiên cứu Nous.
Qi, J., et al. (2025). DiLoCoX: Khung đào tạo quy mô lớn, ít giao tiếp cho cụm phi tập trung .
Sani, L., và cộng sự (2025). Photon: Tiền đào tạo LLM Liên bang . Biên bản Hội nghị về Học máy và Hệ thống (MLSys).
Thérien, B., et al. (2025). MuLoCo: Muon là một trình tối ưu hóa bên trong thực tế cho DiLoCo .
Long, A., et al. (2025). Mô hình giao thức: Mở rộng quy mô đào tạo phi tập trung với tính song song của mô hình hiệu quả về giao tiếp .