
ผลงานบุกเบิกมองอนาคตของ AI จาก "Attention Is All You Need"
ผู้เขียนต้นฉบับ: hmalviya 9
การรวบรวมต้นฉบับ: Frank, Foresight News
หมายเหตุบรรณาธิการ: บทความ Attention Is All You Need ได้รับการตีพิมพ์ในปี 2560 และมีผู้อ้างอิงมากกว่า 110,000 ครั้ง นี่ไม่ได้เป็นเพียงหนึ่งในต้นกำเนิดของเทคโนโลยีโมเดลขนาดใหญ่ที่นำเสนอโดย ChatGPT ในปัจจุบัน แต่ยังแนะนำสถาปัตยกรรม Transformer และกลไกความสนใจ นอกจากนี้ยังใช้กันอย่างแพร่หลายในเทคโนโลยี AI มากมายที่อาจเปลี่ยนแปลงโลก เช่น Sora และ AlphaFold
บทความวิจัยเรื่อง Attention Is All You Need จะเปลี่ยนอนาคตของปัญญาประดิษฐ์ (AI) สมัยใหม่ไปอย่างสิ้นเชิง ในบทความนี้ ผมจะเจาะลึกเกี่ยวกับโมเดล Transformer และอนาคตของ AI
เมื่อวันที่ 12 มิถุนายน 2017 วิศวกรของ Google แปดคนตีพิมพ์รายงานการวิจัยชื่อ Attention Is All You Need บทความนี้กล่าวถึงสถาปัตยกรรมเครือข่ายประสาทเทียมที่จะเปลี่ยนแปลงอนาคตของ AI สมัยใหม่

ในการประชุม GTC เมื่อวันที่ 21 มีนาคม 2024 ที่ผ่านมา Huang Jensen ผู้ก่อตั้ง NVIDIA ได้จัดการสนทนากลุ่มกับวิศวกรของ Google ทั้ง 8 คน และขอบคุณพวกเขาที่แนะนำสถาปัตยกรรม Transformer เพื่อทำให้ AI สมัยใหม่เป็นไปได้ น่าแปลกที่ใช่ ผู้ก่อตั้ง NEAR อยู่ในรายชื่อนี้จริงๆ จำนวน 8 คน
หม้อแปลงไฟฟ้าคืออะไร?
Transformer เป็นโครงข่ายประสาทเทียม
โครงข่ายประสาทเทียมคืออะไร? ได้รับแรงบันดาลใจจากโครงสร้างและการทำงานของสมองมนุษย์ และประมวลผลข้อมูลผ่านเซลล์ประสาทเทียมจำนวนมากที่เชื่อมต่อถึงกัน แต่ไม่ใช่แบบจำลองสมองของมนุษย์ที่สมบูรณ์
พูดง่ายๆ ก็คือ สมองของมนุษย์ก็เหมือนกับป่าฝนอเมซอน ซึ่งมีพื้นที่ต่างๆ มากมายและมีเส้นทางเชื่อมต่อกันมากมาย เซลล์ประสาทเปรียบเสมือนตัวเชื่อมระหว่างทางเดินเหล่านี้ พวกมันสามารถส่งและรับสัญญาณไปยังส่วนใดส่วนหนึ่งของป่าฝนได้ ดังนั้น การเชื่อมต่อจึงเป็นทางเดินที่รับผิดชอบในการเชื่อมต่อพื้นที่สมองสองส่วนที่แตกต่างกัน

สิ่งนี้ทำให้สมองของเรามีความสามารถในการเรียนรู้ที่ทรงพลังมาก ซึ่งช่วยให้สามารถเรียนรู้ได้อย่างรวดเร็ว จดจำรูปแบบ และให้ผลลัพธ์ที่แม่นยำ โครงข่ายประสาทเทียมเช่น Transformer พยายามที่จะบรรลุความสามารถในการเรียนรู้เช่นเดียวกับสมองของมนุษย์ แต่ระดับเทคโนโลยีในปัจจุบันนั้นน้อยกว่า 1% ของสมองมนุษย์
Transformers มีความก้าวหน้าอย่างน่าประทับใจในด้าน Generative AI ในช่วงไม่กี่ปีที่ผ่านมา เมื่อมองย้อนกลับไปที่วิวัฒนาการของปัญญาประดิษฐ์สมัยใหม่ เราจะเห็นได้ว่าปัญญาประดิษฐ์ในยุคแรกนั้นมีลักษณะคล้ายกับ Siri และแอปพลิเคชันเสียง/การจดจำอื่นๆ เป็นหลัก
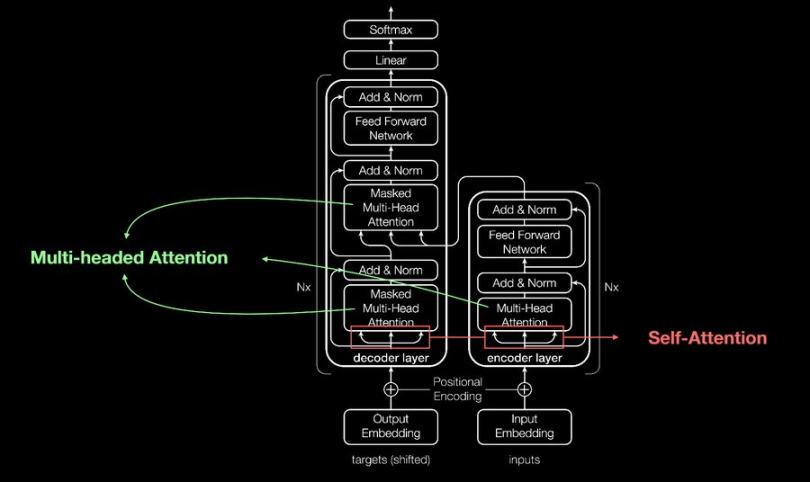
แอปพลิเคชันเหล่านี้สร้างขึ้นโดยใช้ Recurrent Neural Networks (RNN) RNN มีข้อจำกัดบางประการที่ Transformers แก้ไขและปรับปรุง ซึ่งแนะนำกลไกการเอาใจใส่ตนเองที่ช่วยให้สามารถวิเคราะห์ทุกส่วนของลำดับใดๆ ได้พร้อมๆ กัน จึงบันทึกการขึ้นต่อกันในระยะยาวและเนื้อหาตามบริบท

เรายังเร็วมากในวงจรนวัตกรรมของ Transformer Transformer มีอนุพันธ์ที่แตกต่างกันหลายอย่าง เช่น XLNet, BERT และ GPT
GPT เป็น GPT ที่เป็นที่รู้จักมากที่สุด แต่ก็ยังมีความสามารถที่จำกัดในการทำนายเหตุการณ์
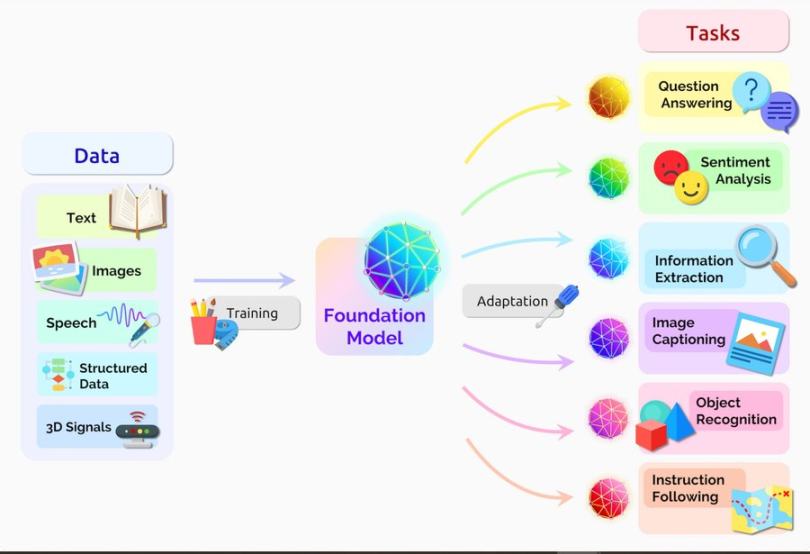
เมื่อโมเดลภาษาขนาดใหญ่ (LLM) สามารถทำนายเหตุการณ์ตามข้อมูลและรูปแบบในอดีตได้ นี่จะเป็นการก้าวกระโดดครั้งใหญ่ครั้งต่อไปใน AI สมัยใหม่ และจะเร่งการเดินทางของเราไปสู่ปัญญาประดิษฐ์ทั่วไป (AGI)
เพื่อให้บรรลุถึงพลังในการทำนายนี้ โมเดลภาษาขนาดใหญ่ (LLM) จึงใช้หม้อแปลงฟิวชั่นชั่วคราว (TFT) ซึ่งเป็นโมเดลที่คาดการณ์ค่าในอนาคตตามชุดข้อมูลที่แตกต่างกัน และยังสามารถอธิบายการคาดการณ์ที่เกิดขึ้นได้อีกด้วย
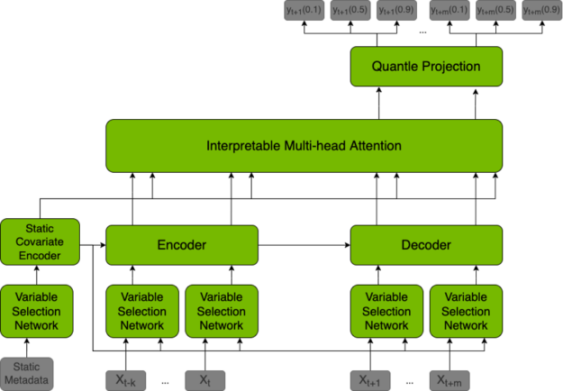
นอกจากจะใช้สำหรับการทำนายแล้ว TFT ยังสามารถนำมาใช้ในฟิลด์บล็อคเชนได้อีกด้วย ด้วยการกำหนดกฎเฉพาะในโมเดล TFT จึงสามารถดำเนินการต่อไปนี้ได้โดยอัตโนมัติ: จัดการกระบวนการฉันทามติอย่างมีประสิทธิภาพ เพิ่มความเร็วในการผลิตบล็อก ให้รางวัลแก่ผู้ตรวจสอบที่ซื่อสัตย์ และลงโทษผู้ตรวจสอบที่เป็นอันตราย
เครือข่ายบล็อคเชนสามารถให้รางวัลบล็อกที่ใหญ่กว่าแก่ผู้ตรวจสอบที่มีคะแนนชื่อเสียงที่สูงกว่าซึ่งสามารถขึ้นอยู่กับประวัติการโหวต ประวัติข้อเสนอบล็อก ประวัติสแลช จำนวนการเดิมพัน กิจกรรม และพารามิเตอร์อื่น ๆ อีกมากมาย สร้าง
กลไกฉันทามติของห่วงโซ่สาธารณะนั้นเป็นเกมระหว่างผู้ตรวจสอบ ซึ่งต้องใช้มากกว่าสองในสามของผู้ตรวจสอบเพื่อตกลงว่าใครจะเป็นผู้สร้างบล็อกต่อไป ในระหว่างกระบวนการนี้ อาจเกิดความขัดแย้งและการโต้แย้งมากมาย ซึ่งเป็นปัจจัยที่ทำให้เครือข่ายเชนสาธารณะ เช่น Ethereum ไร้ประสิทธิภาพของเครือข่ายเชนสาธารณะ
TFT สามารถใช้เป็นกลไกที่เป็นเอกฉันท์ในการปรับปรุงประสิทธิภาพโดยการปรับปรุงเวลาบล็อกและให้รางวัลแก่ผู้ตรวจสอบความถูกต้องตามชื่อเสียงในการผลิตบล็อก ตัวอย่างเช่น BaseAI ซึ่งใช้โมเดล TFT กับกระบวนการฉันทามติ จะใช้โมเดลนี้เพื่อจัดสรรการออกโทเค็นระหว่างผู้ตรวจสอบและผู้เข้าร่วมเครือข่าย

BasedAI ยังเสนอให้ใช้เทคโนโลยี FHE เพื่อให้นักพัฒนาสามารถโฮสต์โมเดลภาษาขนาดใหญ่ที่รักษาความเป็นส่วนตัว (Zk-LLMs) บนโครงสร้างพื้นฐาน AI แบบกระจายอำนาจที่เรียกว่า Brains ด้วยการรวมเทคโนโลยี FHE เข้ากับโมเดลภาษาขนาดใหญ่ จึงสามารถปกป้องผู้ใช้ได้ ข้อมูลส่วนบุคคลเมื่อพวกเขาเลือกที่จะเปิดใช้งานบริการ AI ส่วนบุคคล
เมื่อผู้คนเต็มใจที่จะให้ข้อมูลด้วยความมั่นใจว่าข้อมูลของพวกเขาจะถูกเข้ารหัสและเป็นส่วนตัวอย่างสมบูรณ์ บางที เราอาจประสบความสำเร็จในการพัฒนาปัญญาประดิษฐ์ทั่วไป (AGI) ช่องว่างนี้ถูกเติมเต็มด้วยเทคโนโลยีที่เน้นความเป็นส่วนตัว เช่น การคำนวณแบบตาบอดของเครือข่ายล้านล้าน , การเรียนรู้ของเครื่องแบบไม่มีความรู้ (ZkML) และเทคโนโลยีการเข้ารหัสแบบโฮโมมอร์ฟิก (FHE)
อย่างไรก็ตาม เทคโนโลยีที่เน้นความเป็นส่วนตัวทั้งหมดนี้ต้องการทรัพยากรการประมวลผลจำนวนมาก ซึ่งทำให้เทคโนโลยีเหล่านี้อยู่ในขั้นเริ่มต้นของการใช้งาน


