
ZONFF Research: เรากำลังพูดถึงอะไรเมื่อเราพูดถึงข้อมูล Web3?
ผู้เขียนต้นฉบับ: Lewis Liao,Zonff Partners
เรากำลังพูดถึงอะไรเมื่อเราพูดถึงข้อมูล Web3? ในการทำความเข้าใจนี้ ก่อนอื่นเราต้องทราบว่าข้อมูลใน Web2 มีลักษณะอย่างไร บทความนี้จะกล่าวถึงวงจรชีวิตทั้งหมดของการสร้างข้อมูล การรวบรวม การจัดเก็บ การจัดการ และการใช้งาน ก่อนหน้านั้น เราจะชี้แจงวิธีการกำหนดข้อมูลก่อน
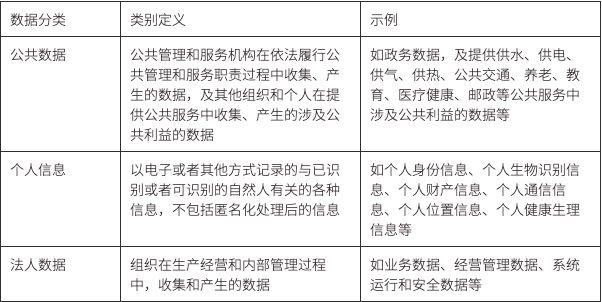
ใน "แนวทางปฏิบัติมาตรฐานความปลอดภัยเครือข่าย - แนวทางการจำแนกประเภทข้อมูลและการจัดระดับ" (ฉบับร่างสำหรับความคิดเห็น - v1.0 - 202109) ที่ออกโดยคณะกรรมการด้านเทคนิคมาตรฐานความปลอดภัยข้อมูลแห่งชาติของจีน ข้อมูลจะถูกจัดประเภทเป็นข้อมูลส่วนบุคคล ข้อมูลสาธารณะ และกฎหมาย ข้อมูลบุคคล
คำจำกัดความและตัวอย่างเฉพาะมีดังนี้:
ชื่อระดับแรก
1.1 การสร้าง รวบรวม และจัดเก็บข้อมูล
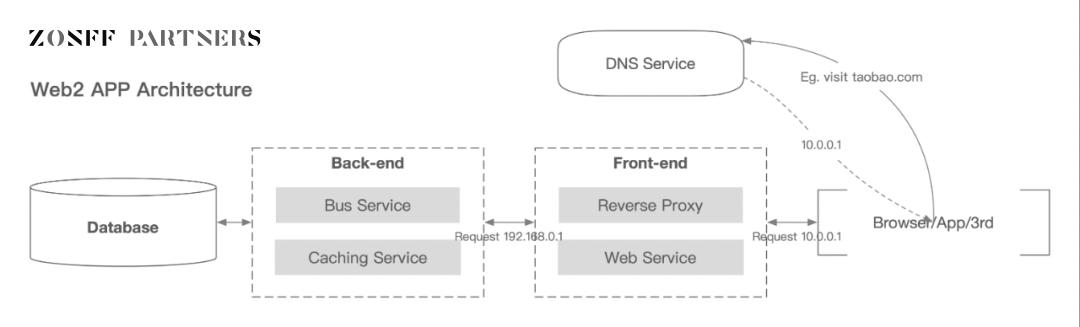
ข้อมูลสาธารณะ ข้อมูลส่วนบุคคล และข้อมูลนิติบุคคลส่วนใหญ่ถูกสร้างขึ้นเมื่อเราใช้แอปพลิเคชันคอมพิวเตอร์ในชีวิตประจำวัน ซึ่งข้อมูลส่วนบุคคลและข้อมูลนิติบุคคลมีความเกี่ยวข้องอย่างใกล้ชิดกับผู้ใช้ทั่วไป
คำอธิบายภาพ
เครดิตรูปภาพ: Zonff Partners
เครดิตรูปภาพ: Zonff Partners
ฐานข้อมูลระดับล่างสุดเก็บข้อมูลที่ส่งมาจากส่วนหลังและสร้างขึ้นโดยการโต้ตอบระหว่างผู้ใช้และส่วนหน้า กล่าวอย่างกว้าง ๆ นี่คือข้อมูลผู้ใช้
เท่าที่เกี่ยวข้องกับแอปพลิเคชันมือถือ ข้อมูลสามารถแบ่งออกเป็นประเภทต่อไปนี้อย่างคร่าว ๆ:
ข้อมูลผู้ใช้ ข้อมูลที่เกี่ยวข้องกับผู้ใช้ที่บันทึกโดยผู้ใช้ที่ใช้บริการแอปพลิเคชัน รวมถึงข้อมูลประจำตัวของผู้ใช้ อุปกรณ์ เครือข่าย ตำแหน่งทางภูมิศาสตร์ และแม้แต่รายการแอปพลิเคชันที่ติดตั้งบนอุปกรณ์มือถือ ฯลฯ จะถูกรวบรวมโดยเซิร์ฟเวอร์ ตารางข้อมูลและจุดฝัง
ข้อมูลเนื้อหา ข้อมูลที่สร้างโดยผู้ใช้ที่ใช้บริการแอปพลิเคชัน รวมถึงข้อมูลเนื้อหาที่ไม่ใช่ข้อมูลส่วนบุคคลที่ผู้ใช้เขียนแบบโต้ตอบบนแอปพลิเคชัน ซึ่งเป็นส่วนหนึ่งของบริการแอปพลิเคชันและโดยทั่วไปจะรวบรวมโดยตรงจากตารางข้อมูลฝั่งเซิร์ฟเวอร์
ข้อมูลพฤติกรรม ข้อมูลที่เกิดจากการโต้ตอบของผู้ใช้ระหว่างการใช้แอปพลิเคชัน ซึ่งรวมถึงพฤติกรรมพฤติกรรมของผู้ใช้ระหว่างการใช้แอปพลิเคชัน เช่น เวลาในการดู อัตราการคลิก อัตราการเจาะ สถานการณ์เลื่อน ฯลฯ โดยทั่วไปจะรวบรวมโดย จุดฝัง;
ข้อมูลบันทึก ข้อมูลที่สร้างขึ้นโดยแอปพลิเคชันเองในระหว่างที่ผู้ใช้ใช้แอปพลิเคชัน รวมถึงบันทึกข้อผิดพลาดของแอปพลิเคชัน ฯลฯ
ข้อมูลโค้ด ข้อมูลเชิงโต้ตอบที่ไม่ใช่ผู้ใช้รวมถึงโค้ดส่วนหน้าและส่วนหลัง ข้อมูลเหล่านี้ เช่น ข้อมูลผู้ใช้ จะถูกจัดเก็บไว้ในเซิร์ฟเวอร์ส่วนกลางที่ใดที่หนึ่ง
ในการจัดหมวดหมู่นี้ ข้อมูลผู้ใช้เป็นของข้อมูลส่วนตัว และข้อมูลบันทึกและรหัสเป็นของข้อมูลบุคคลตามกฎหมาย ข้อมูลเนื้อหาและข้อมูลพฤติกรรมเป็นสิ่งที่ควรค่าแก่การพูดถึง ในยุค Web2 ข้อมูลเหล่านี้ถูกแบ่งออกเป็นข้อมูลธุรกิจของตนเองมากขึ้นตามหน่วยงานส่วนกลาง นั่นคือ ข้อมูลบุคคลตามกฎหมาย
คำอธิบายภาพ
คำอธิบายภาพ
เครดิตภาพ: ปรีธี กษิเรศดี
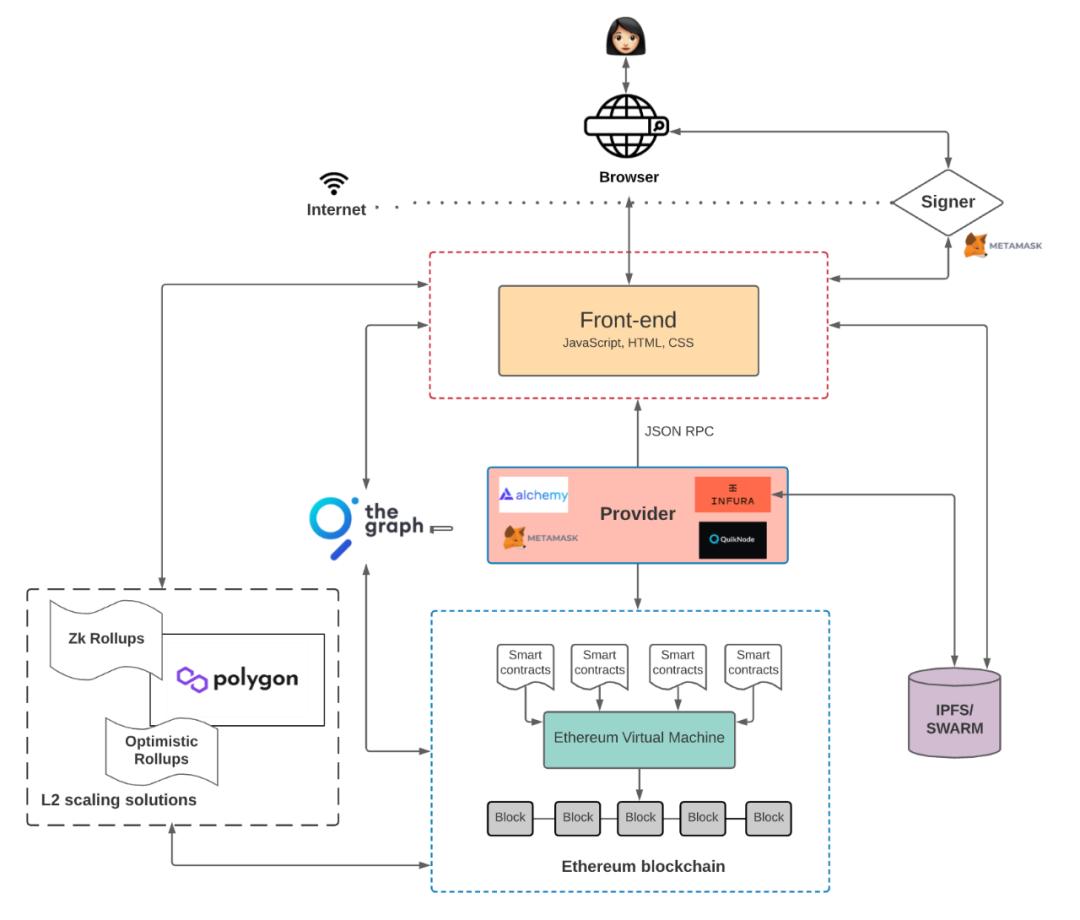
เมื่อเทียบกับแอปพลิเคชัน Web2 เทอร์มินัลผู้ใช้และส่วนหน้าแทบไม่เปลี่ยนแปลง ความแตกต่างอยู่ที่ส่วนหลังและฐานข้อมูล ผู้ใช้โต้ตอบกับผู้ให้บริการโหนดผ่านส่วนหน้า (แทนที่จะเป็นเซิร์ฟเวอร์ส่วนกลาง) เข้าถึงรหัสสัญญาที่จัดเรียงบนบล็อกเชน เช่น Ethereum (แทนที่จะเป็นสภาพแวดล้อมแบ็กเอนด์บนเซิร์ฟเวอร์) และโต้ตอบ ในกระบวนการนี้ ประเภทของข้อมูลที่กล่าวถึงข้างต้นจะถูกสร้างขึ้นด้วย เนื่องจากความแตกต่างของสถาปัตยกรรมทางเทคนิค ข้อมูลที่สร้างโดย Web3 จะไม่ถูกจัดเก็บโดยเซิร์ฟเวอร์ส่วนกลาง อาจมีความเหมือนและความแตกต่างในวิธีการจัดเก็บข้อมูลที่สร้างขึ้น ในทางที่แตกต่าง.
ในหมู่พวกเขา ข้อมูลทั้งหมดที่เกิดจากการโต้ตอบของสัญญาอัจฉริยะจะถูกเผยแพร่บนบล็อกเชนและทุกคนสามารถเข้าถึงได้ ดังนั้นจึงกลายเป็นผลิตภัณฑ์สาธารณะ รวมถึงข้อมูลสินทรัพย์ ข้อมูลธุรกรรม และรหัสสัญญา ตามทฤษฎีแล้ว ตราบใดที่พื้นที่บล็อกเชนใหญ่พอ ข้อมูลใดๆ ก็สามารถเก็บไว้ในบล็อกเชนได้ และบางโครงการพยายามใช้บล็อกเชนเป็นฐานข้อมูลเพื่อจัดเก็บข้อมูล
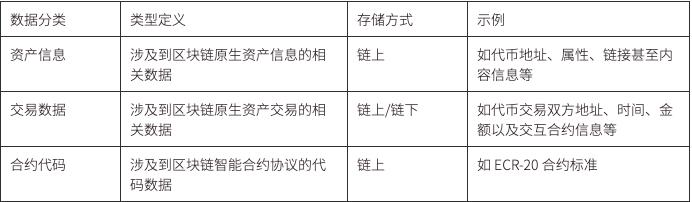
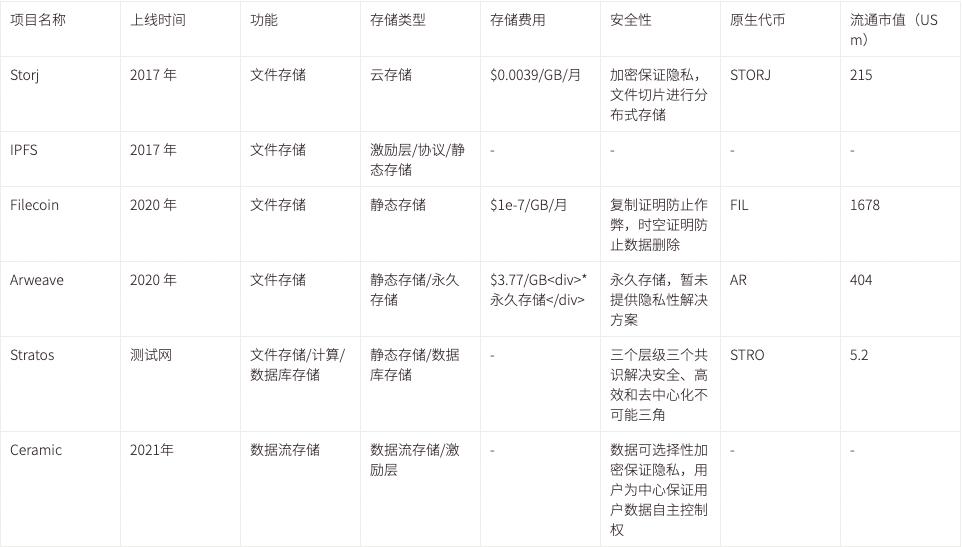
ในขั้นตอนปัจจุบัน ยกเว้นข้อมูลสามประเภทข้างต้น ข้อมูลส่วนใหญ่ที่สร้างโดยแอปพลิเคชัน Web3 ยังคงจัดเก็บไว้ในเซิร์ฟเวอร์ส่วนกลาง รวมถึงโค้ดส่วนหน้า ข้อมูลผู้ใช้ ข้อมูลเนื้อหา ข้อมูลพฤติกรรม และข้อมูลบันทึก เนื่องจากโครงสร้างพื้นฐานการจัดเก็บข้อมูลที่เกี่ยวข้องยังไม่สมบูรณ์แบบในปัจจุบัน และฝ่ายโครงการอาจถูกจำกัดด้วยปัญหาทางเทคนิค หรือได้นำโซลูชันแบบรวมศูนย์มาใช้ด้วยเหตุผลต่างๆ เช่น การรับประกันความเร็วในการเข้าถึง ด้วยการพัฒนาโครงสร้างพื้นฐานอย่างต่อเนื่อง ทำให้มีโครงสร้างพื้นฐานของสตอเรจที่ทรงพลังมากขึ้น เช่น IFPS, Stroj, Filecoin และ Ceramic เป็นต้น และแอปพลิเคชั่นจำนวนมากขึ้นเรื่อยๆ ได้เริ่มปรับใช้ตัวเองบนสตอเรจแบบกระจายอำนาจ เช่น การจัดเรียงส่วนหน้า- สิ้นสุดเว็บไซต์บน IPFS และเข้าถึงผ่าน ENS เพื่อสร้างเว็บไซต์ส่วนหน้าแบบกระจายศูนย์ และใช้ Arweave เพื่อจัดเก็บข้อมูลไฟล์อย่างถาวร เช่น รูปภาพที่เกี่ยวข้องกับโครงการ NFT เป็นต้น
โดยทั่วไป เมื่อสร้างแอปพลิเคชัน Web3 นักพัฒนามักจะมีสามตัวเลือกในการจัดเก็บข้อมูลแอปพลิเคชัน:
เก็บไว้ใน blockchain ตัวเลือกนี้มีราคาแพงมาก มันจะทำให้แอปพลิเคชันง่ายที่สุดเท่าที่จะเป็นไปได้ และข้อมูลเปิดอย่างสมบูรณ์ ข้อดีคือการปกป้องอธิปไตยของแอปพลิเคชันโดยตรงที่สุด
จัดเก็บลอจิกสัญญาอัจฉริยะบนบล็อกเชน และอื่นๆ บนแบ็กเอนด์แบบดั้งเดิม แนวทางนี้ยอมสละอำนาจอธิปไตยของผู้ใช้และความเสี่ยงจากการรวมศูนย์ นี่เป็นวิธีที่แอปพลิเคชัน Web3 ส่วนใหญ่ใช้อยู่ในปัจจุบัน
จัดเก็บลอจิกสัญญาอัจฉริยะบนบล็อกเชนและจัดเก็บอื่น ๆ ในที่เก็บข้อมูล เช่น IPFS, Arweave และเซรามิก จัดการและอัปเดตข้อมูลผ่านสัญญาอัจฉริยะ วิธีนี้มีราคาแพง (เซรามิกฟรีในขณะนี้) และช้าในขณะนี้ แต่วิธีนี้ วิธีการสามารถปกป้องอธิปไตยของแอปพลิเคชัน
ชื่อระดับแรก
1.2 แนวโน้ม: พื้นที่เก็บข้อมูลแบบกระจายอำนาจ - อำนาจอธิปไตยของข้อมูลและแอปพลิเคชัน
เมื่อพูดถึง 3 วิธีในการสร้างแอปพลิเคชัน Web3 มีคำสำคัญอยู่ที่นี่: อำนาจอธิปไตย คำนี้เป็นหัวข้อที่หลีกเลี่ยงไม่ได้เมื่อเราพูดถึงคุณลักษณะของ Web3 โดยทั่วไปจะรวมถึงอำนาจอธิปไตยของข้อมูลและอำนาจอธิปไตยของแอปพลิเคชัน อำนาจอธิปไตยมีความสำคัญหรือไม่? นี่เป็นอีกหัวข้อหนึ่งซึ่งไม่ได้กล่าวถึงในบทความนี้ หากคุณสนใจ คุณสามารถอ่านบทความที่เกี่ยวข้อง เช่น "Web3 Data Market Outlook" และ "Web3 - Let the"right to data"ตื่น". ในที่นี้ ฉันต้องการตัดเข้าสู่เส้นทางที่จำเป็นสำหรับการจัดตั้งอำนาจอธิปไตยของ Web3 จากมุมมองของข้อมูล และสรุปทิศทางและจุดเน้นของการพัฒนาโครงสร้างพื้นฐาน
เกี่ยวกับอำนาจอธิปไตยของข้อมูล ซึ่งรวมถึงอำนาจอธิปไตยของสินทรัพย์ดิจิทัลและอำนาจอธิปไตยของข้อมูลผู้ใช้ บทความ "Vertical Liquidity: How Values Are Interconnected" กล่าวว่าโทเค็นสามารถกำหนดอำนาจอธิปไตยของสินทรัพย์ดิจิทัลของผู้ใช้ (ตัวตน ความสัมพันธ์ และสิทธิ์ในทรัพย์สิน) ซึ่งถูกกำหนดโดย ฉันทามติในวงกว้างที่ยากจะแก้ไข ในระดับพื้นฐานที่สุด คำจำกัดความของสิทธิ์เหล่านี้สามารถดำเนินการให้สมบูรณ์ได้ด้วยบล็อกเชนเอง เช่น ที่อยู่ของโทเค็น อย่างไรก็ตาม เมื่อพูดถึงการเป็นเจ้าของสิทธิ์ผลิตภัณฑ์ดิจิทัลที่ซับซ้อนมากขึ้นแล้วจะมีปัญหามากมาย ปัญหาทั่วไปคือการจัดเก็บรูปภาพ (หรือบทความ ฯลฯ) ที่สอดคล้องกับ NFT ปัญหานี้ได้รับการกล่าวถึงใน "NFT: A ปฏิวัติการเป็นเจ้าของดิจิทัล". สถานะที่เป็นอยู่ของ NFT ส่วนใหญ่คือผลิตภัณฑ์ดิจิทัลที่เกี่ยวข้องนั้นถูกจัดเก็บไว้ในเซิร์ฟเวอร์ส่วนกลางที่ใดที่หนึ่ง เมื่อเซิร์ฟเวอร์ล่มหรือถูกแฮ็ก ผู้ใช้ทั้งหมดมีเพียงแค่สตริงของแฮชในห่วงโซ่ "รายการ" ที่แท้จริงที่อยู่เบื้องหลังแฮช ” สามารถถูกขโมยหรือเปลี่ยนได้ตลอดเวลาและไร้ค่า
นอกจากนี้ อำนาจอธิปไตยของข้อมูลผู้ใช้ซึ่งเป็นหนึ่งในเส้นแบ่งที่ชัดเจนที่สุดระหว่าง Web2 และ Web3 เป็นสัญลักษณ์แสดงนวัตกรรมและความก้าวหน้าของ Web3 ในเรื่องนี้ Ceramic มองเห็นจักรวาลของข้อมูล ซึ่งเป็นระบบนิเวศข้อมูลขนาดเว็บที่ประกอบขึ้นได้ซึ่งทุกคนเป็นเจ้าของแต่ไม่ได้จำกัดไว้สำหรับใครคนใดคนหนึ่ง ข้อมูลผู้ใช้ติดตามผู้ใช้จากแอปพลิเคชันหนึ่งไปยังอีกแอปพลิเคชันหนึ่ง และผู้ใช้จะทำหน้าที่เป็นศูนย์กลางในการควบคุมจักรวาลดิจิทัลของตนเอง ในปัจจุบัน แทบไม่มีแอปพลิเคชันใดที่สามารถทำได้ Cyberconnect ได้พยายามอย่างดี โดยได้สร้างโปรโตคอลกราฟสังคมแบบกระจายอำนาจ โดยหวังว่าจะตระหนักถึงความสามารถในการทำงานร่วมกันของข้อมูลความสัมพันธ์ทางสังคมของผู้ใช้ระหว่างแอปพลิเคชันต่างๆ แต่ปัจจุบัน แอปพลิเคชันไม่รับประกันอธิปไตยข้อมูลของผู้ใช้ แม้ว่าพวกเขาจะเริ่มถ่ายโอนไปยังเซรามิกเพื่อการก่อสร้าง แต่ทุกอย่างยังคงอยู่ในระหว่างทาง
เกี่ยวกับอำนาจอธิปไตยของแอปพลิเคชัน บางคนเรียกแอปพลิเคชันที่มีอำนาจอธิปไตยว่า "โครงสร้างเหนือ" ซึ่งมีลักษณะต่างๆ เช่น ไม่หยุดหย่อน ฟรี มีคุณค่า ปรับขนาดได้ ไม่ได้รับอนุญาต ความเป็นกลางในเชิงบวก และความเป็นกลางที่เชื่อถือได้ ซึ่งรวมกันเป็นโลกดิจิทัล สินค้าสาธารณะสร้างโครงสร้างพื้นฐานของ " metaverse" (ถ้าคุณเชื่อ) ในปัจจุบัน แอปพลิเคชัน Web3 ส่วนใหญ่ไม่มีอำนาจอธิปไตยของแอปพลิเคชันในระดับสูง แอปพลิเคชันเหล่านี้ไม่ใช่ผลิตภัณฑ์สาธารณะจริง และแอปพลิเคชันเหล่านั้นสามารถถูกลงโทษและเปลี่ยนแปลงได้ง่ายจากอำนาจ เหตุการณ์ Tornado Cash แสดงให้เห็นปัญหานี้โดยตรง สาเหตุหลักประการหนึ่งคือแม้ว่ารหัสสัญญาของเลเยอร์โปรโตคอลแอปพลิเคชันเหล่านี้จะเผยแพร่บนบล็อกเชน แต่ส่วนประกอบต่างๆ เช่น ส่วนหน้าและชื่อโดเมนยังคงถูกควบคุมโดยหน่วยงานส่วนกลางของบุคคลที่สาม
เพื่อให้บรรลุอำนาจอธิปไตยของข้อมูลและอำนาจอธิปไตยของแอปพลิเคชัน วิธีการสร้างแอปพลิเคชัน Web3 มีความสำคัญมาก จุดเริ่มต้นพื้นฐานคือการจัดเก็บ ข้อมูลมีอยู่ที่ใด และจะจัดเก็บอย่างไรเพื่อให้มั่นใจว่าผู้ใช้สามารถมีอำนาจอธิปไตยได้ โดยทั่วไป มีวิธีแก้ไขที่แตกต่างกันขึ้นอยู่กับประเภทข้อมูลของผู้ใช้:
ข้อมูลสินทรัพย์และข้อมูลธุรกรรมของผู้ใช้ควรเป็นข้อมูลบัญชีแยกประเภทสาธารณะ และเป็นสิ่งสำคัญที่สุดเพื่อให้แน่ใจว่าสามารถตรวจสอบได้บนเครือข่าย แต่สิ่งนี้มีประโยชน์มากสำหรับแอปพลิเคชันอย่าง Aztec ในการปกป้องความเป็นส่วนตัวของธุรกรรมบนเครือข่ายของผู้ใช้
ข้อมูลผู้ใช้ ข้อมูลเนื้อหา และข้อมูลพฤติกรรมถือเป็นข้อมูลส่วนบุคคล และเป็นสิ่งสำคัญมากเพื่อให้แน่ใจว่าผู้ใช้สามารถควบคุมได้ ด้วยความยินยอมของผู้ใช้ ข้อมูลเหล่านี้สามารถเลือกเปิดเผยเป็นผลิตภัณฑ์สาธารณะเพื่อค้นหาปัจจัยภายนอกในเชิงบวก
เนื่องจากข้อมูลบุคคลตามกฎหมาย ข้อมูลบันทึกและข้อมูลรหัสเป็นที่ยอมรับและจำเป็นต้องแปรรูป แต่เมื่อพูดถึงแอปพลิเคชันโครงสร้างพื้นฐาน Web3 เช่น "อาคารสูง" ควรมีลักษณะเฉพาะของโครงสร้างพื้นฐานสาธารณะ และการจัดเก็บรหัสแอปพลิเคชัน ควร เปิดกว้างและมีความสามารถในการต่อต้านการเซ็นเซอร์เกินระดับแพลตฟอร์ม
ในปัจจุบัน เหตุผลที่แอปพลิเคชัน Web3 ส่วนใหญ่ใช้ "การจัดเก็บตรรกะสัญญาอัจฉริยะบนบล็อกเชนและอื่นๆ ในแบ็กเอนด์แบบดั้งเดิม" คือขณะนี้ยังไม่มีโครงสร้างพื้นฐานแบบกระจายศูนย์ที่ดีพอที่จะแทนที่โซลูชันโครงสร้างพื้นฐานแบบรวมศูนย์แบบเดิม
ประการแรก ที่เก็บข้อมูลแบบกระจายศูนย์ เช่น IPFS, Filecoin และ Arweave ล้วนเป็นสตอเรจแบบสแตติก ซึ่งทำให้ขาดความสามารถในการคำนวณและการจัดการสถานะ และไม่สามารถใช้ฟังก์ชันขั้นสูงที่คล้ายกับฐานข้อมูลได้ (เช่น ความแปรปรวน การควบคุมเวอร์ชัน การควบคุมการเข้าถึง และ ตรรกะที่ตั้งโปรแกรมได้) ) และแม้ว่า Ceramic จะเป็นที่เก็บข้อมูลแบบไดนามิกซึ่งแก้ปัญหาเหล่านี้ได้ในระดับหนึ่ง แต่ความเร็วในการเข้าถึงของ Ceramic ในปัจจุบันยังค่อนข้างช้าและชุดพัฒนายังไม่สมบูรณ์แบบและระดับของการกระจายอำนาจนั้นได้รับเสมอ วิจารณ์.
หน้าที่หลักของสตอเรจแบบกระจายศูนย์ เช่น IPFS, Filecoin และ Arweave คือการจัดเก็บข้อมูลที่ไม่มีโครงสร้าง เช่น รูปภาพ เอกสาร และรหัสแบบคงที่แบบคงที่ เนื่องจากลักษณะเฉพาะที่ยากต่อการเปลี่ยนแปลงโดยรับประกันข้อมูลดิจิทัล เช่น NFT ในระดับหนึ่ง ขอบเขต อำนาจอธิปไตย เมื่อมีการสร้างการเชื่อมต่อระหว่างรหัสแฮชบนเชนและที่อยู่จัดเก็บแบบกระจายอำนาจบนเชนแล้ว มันยากที่จะได้รับอิทธิพลจากกองกำลังภายนอกด้วยวิธีพิเศษ โค้ดส่วนหน้าที่สร้างขึ้นบนโค้ดนี้ยังส่งเสริมความสมบูรณ์ของอำนาจอธิปไตยของแอปพลิเคชัน แต่เนื่องจากเทคโนโลยีการจัดเก็บข้อมูลในขั้นตอนปัจจุบันเป็นเพียงการจัดเก็บข้อมูล การขาดพลังในการประมวลผลทำให้การสนับสนุนการทำงานนั้นล้าหลังกว่าโซลูชันเซิร์ฟเวอร์แบบรวมศูนย์
คำอธิบายภาพ
คำอธิบายภาพ
เมื่อ: 23 สิงหาคม 2022
ชื่อระดับแรก
2.1 การจัดการข้อมูล
การสร้างแอปพลิเคชัน Web3 บนที่เก็บข้อมูลแบบกระจายอำนาจทำให้มีโอกาสน้อยที่จะถูกแทรกแซงจากแรงภายนอก และทำลายการผูกขาดและอำนาจ แต่สตอเรจเพียงอย่างเดียวไม่เพียงพอ นอกจากนี้ ยังต้องการการสนับสนุนการประมวลผลการประมวลผลข้อมูล การกำหนดค่า สิทธิ์ การปกป้องความเป็นส่วนตัว และเทคโนโลยีอื่น ๆ ในสภาพแวดล้อมสตอเรจเพื่อให้แน่ใจว่ามีอธิปไตยของแอปพลิเคชันและข้อมูลของผู้ใช้ อธิปไตยในโลกดิจิทัล โดยเฉพาะอย่างยิ่งประเด็นการควบคุมผู้มีอำนาจและการคุ้มครองความเป็นส่วนตัว ควรดำเนินการด้วยโซลูชันทางเทคนิคระดับสูง ข้อมูลระดับเหล่านี้ในแอปพลิเคชัน Web2 จะถูกจัดเก็บไว้ในเซิร์ฟเวอร์ส่วนกลางบางเซิร์ฟเวอร์ตามระดับการป้องกันความปลอดภัยต่างๆ กัน ความปลอดภัยได้รับการรับประกันโดยความปลอดภัยของเครือข่ายและอำนาจอธิปไตยได้รับการรับประกันโดยแพลตฟอร์ม (เช่น แพลตฟอร์มขององค์กร ในโหมดการจัดการข้อมูลนี้ ผู้ใช้อยู่ภายใต้การดูแลขั้นสูง และผู้ใช้ไม่มีสิทธิ์ในข้อมูลนั้น นอกจากนี้ ความปลอดภัยของข้อมูลยังขึ้นอยู่กับเอนทิตีแบบรวมศูนย์ของผู้ดูแลระบบระดับสูง ตัวอย่างเช่น ในเหตุการณ์การรั่วไหลของข้อมูลความปลอดภัยสาธารณะในบางพื้นที่เมื่อไม่นานมานี้ ของผู้คนนับล้านที่จะรั่วไหล
การจัดการข้อมูลของ Web3 ควรมีลักษณะ 2 ประการดังนี้
การปกป้องอธิปไตยของข้อมูล สิ่งนี้ควรไปไกลกว่าระดับแพลตฟอร์มหรือแม้แต่ระดับโลก และปกป้องสิทธิร่วมกันของผู้ใช้ในโลกดิจิทัลผ่านฉันทามติระดับโลก การป้องกันในแง่นี้ในโลกแบบดั้งเดิมนั้นอยู่ที่ระดับแพลตฟอร์มและกฎมาจากความไม่สอดคล้องกัน บริษัทระดับ Platform สามารถควบคุมกฎและระบบทั้งหมดและสามารถเปลี่ยนแปลงได้ตลอดเวลาเพื่อที่จะสามารถละเมิด อำนาจอธิปไตยส่วนบุคคลของผู้ใช้ได้ตลอดเวลา
การรับประกันความเป็นส่วนตัวของข้อมูล ความเป็นส่วนตัวของข้อมูลผู้ใช้ได้รับการรับประกันทางคณิตศาสตร์ผ่านการเข้ารหัสแทนที่จะผ่านการรักษาความปลอดภัยเครือข่ายฐานข้อมูล การเข้ารหัสแบบเลือกที่ควบคุมโดยผู้ใช้เป็นหนึ่งในสิทธิ์ขั้นพื้นฐานของอำนาจอธิปไตยของข้อมูลผู้ใช้
วิธีจัดการข้อมูล Web3 ขึ้นอยู่กับวิธีการจัดเก็บข้อมูล
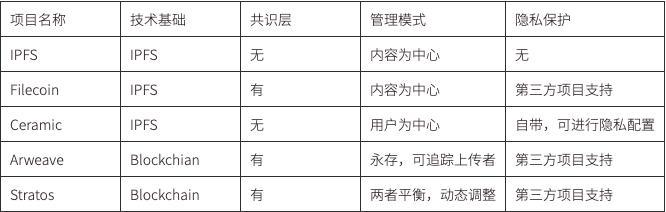
IPFS และ Filecoin เป็นศูนย์กลางของเนื้อหาและเข้าถึงเนื้อหาที่เก็บไว้ผ่าน Content ID (CID) บนพื้นฐานนี้ แอปพลิเคชันของบุคคลที่สามถูกสร้างขึ้นสำหรับการจัดการข้อมูล ตัวอย่างเช่น ผ่าน ChainSafe Files ปัญหาการลงชื่อเพียงครั้งเดียวสามารถแก้ไขได้ใน ลักษณะการแปล ข้อมูลสามารถเข้ารหัสและจัดเก็บได้อย่างสะดวกผ่านการเข้ารหัสแบบอสมมาตร โมเดลการจัดการเนื้อหาเป็นศูนย์กลางทำให้การจัดการผู้ใช้ทำได้ยาก และวิธีการกำหนดความเป็นเจ้าของให้กับข้อมูลจะซับซ้อนมากขึ้น นอกเหนือจากการจัดเตรียมพื้นที่จัดเก็บแล้ว ความสามารถในการปรับขนาดเชิงนิเวศน์ของ Filecoin จะสูงกว่าชั้นล่างสุดอื่นๆ มาก โดยเฉพาะอย่างยิ่งหลังจากการเปิดตัว FVM อาจมีเครื่องมือพิเศษบางอย่างสำหรับการจัดเก็บข้อมูลและการดึงข้อมูลในแนวดิ่ง ซึ่งสามารถช่วยผู้ใช้ในการช่วยให้องค์กรต่างๆ จัดการข้อมูลของตนได้ดียิ่งขึ้น รับประกันความปลอดภัยของข้อมูล และพัฒนาแอปพลิเคชันใหม่จำนวนมาก
Ceramic ยังใช้ IPFS เป็นหลัก แต่ผู้ใช้เป็นศูนย์กลางโดยใช้โปรโตคอล IDX วิธี 3ID DID (CIP-79) เพื่อสร้างระบบบัญชีแบบพื้นเมืองของ Ceramic ซึ่งสามารถใช้ในการรับรองความถูกต้องของ Ceramic และผู้ใช้สามารถใช้กระเป๋าเงิน blockchain เพื่อควบคุม 3ID DID ดำเนินการธุรกรรมบนสตรีมข้อมูลและจัดการข้อมูลของคุณเอง สิ่งนี้ทำได้โดยการเชื่อมโยง DID กับข้อมูลและจัดเก็บไว้ในแบบจำลองข้อมูล แบบจำลองข้อมูลกำหนดรูปแบบ (สคีมา) ของข้อมูลผู้ใช้ และแอปพลิเคชันทั้งหมดที่ใช้แบบจำลองข้อมูลเดียวกันจะใช้รูปแบบข้อมูลร่วมกัน
Arweave เป็นโครงการพื้นที่จัดเก็บแบบกระจายศูนย์สำหรับข้อมูลบนเครือข่ายด้วยการชำระเงินเพียงครั้งเดียวและการจัดเก็บถาวร ข้อมูลจะถูกจัดเก็บอย่างเปิดเผยและโปร่งใสบนเชน และทุกคนสามารถเข้าถึงได้ ข้อมูลที่จัดเก็บบนเชนสามารถเรียกดูผ่าน Arweave blockchain เบราว์เซอร์ การจัดการข้อมูลในโหมดนี้เหมือนกับข้อมูลในห่วงโซ่การจัดการทุกประการ ไม่มีการควบคุมการเข้าถึงและ "การอัปเดตด่วน" ของข้อมูลดั้งเดิม ทุกครั้งที่ข้อมูลถูกอัปเดต ที่อยู่ดัชนีจะเปลี่ยนไป ไม่มีปัญหา ด้วย IPFS และ Filecoin แต่ข้อดีของมันคือมีความชัดเจนมากว่าข้อมูลนั้นเป็นของผู้ใช้รายใดซึ่งเอื้อต่อการตรวจสอบย้อนกลับของสิทธิ์ในข้อมูล
ชื่อระดับแรก
2.2 แนวโน้ม: ตลาดข้อมูลแบบกระจายอำนาจ
ชื่อเรื่องรอง
ตลาดแบบจำลองข้อมูลของเซรามิก
เซรามิกกล่าวถึงในจักรวาลข้อมูลว่าพวกเขาต้องการสร้างตลาดแบบจำลองข้อมูลแบบเปิด เนื่องจากข้อมูลจำเป็นต้องทำงานร่วมกันได้ ซึ่งสามารถส่งเสริมการปรับปรุงประสิทธิภาพการทำงานได้อย่างมาก ตลาดโมเดลข้อมูลดังกล่าวเกิดขึ้นได้จากข้อตกลงฉุกเฉินเกี่ยวกับโมเดลข้อมูล ซึ่งคล้ายกับมาตรฐานสัญญา ETC ใน Ethereum ซึ่งนักพัฒนาสามารถเลือกเป็นเทมเพลตฟังก์ชันเพื่อให้มีแอปพลิเคชันที่สอดคล้องกับข้อมูลทั้งหมดของโมเดลข้อมูล . ปัจจุบันตลาดดังกล่าวไม่ใช่ตลาดการค้า
สำหรับโมเดลข้อมูลนั้น ยกตัวอย่างง่าย ๆ ในโซเชียลเน็ตเวิร์กแบบกระจายอำนาจ โมเดลข้อมูลสามารถถูกทำให้ง่ายขึ้นได้ถึง 4 พารามิเตอร์ ได้แก่
PostList: จัดเก็บดัชนีโพสต์ของผู้ใช้
โพสต์: เก็บโพสต์เดียว
โปรไฟล์: เก็บข้อมูลผู้ใช้
FollowList: เก็บรายการติดตามของผู้ใช้
แล้วโมเดลข้อมูลจะถูกสร้างขึ้น แชร์ และนำกลับมาใช้ใหม่บน Ceramic เพื่อเปิดใช้งานการทำงานร่วมกันของข้อมูลระหว่างแอปพลิเคชันได้อย่างไร
Ceramic มี DataModels Registry ซึ่งเป็นโอเพ่นซอร์ส ที่เก็บข้อมูลที่สร้างขึ้นโดยชุมชนของโมเดลข้อมูลแอปพลิเคชันที่นำมาใช้ซ้ำได้สำหรับ Ceramic ที่นี่ นักพัฒนาสามารถลงทะเบียนอย่างเปิดเผย ค้นพบและนำโมเดลข้อมูลที่มีอยู่กลับมาใช้ใหม่ ซึ่งเป็นพื้นฐานสำหรับแอปพลิเคชันการดำเนินงานของลูกค้าที่สร้างจากโมเดลข้อมูลที่ใช้ร่วมกัน ปัจจุบันใช้พื้นที่เก็บข้อมูล Github และในอนาคตจะเผยแพร่บน Ceramic
โมเดลข้อมูลทั้งหมดที่เพิ่มลงในรีจิสทรีจะได้รับการเผยแพร่โดยอัตโนมัติภายใต้แพ็คเกจ @datamodels npm นักพัฒนาทุกคนสามารถใช้ @datamodels/model-name เพื่อติดตั้งโมเดลข้อมูลตั้งแต่หนึ่งโมเดลขึ้นไป ทำให้พร้อมใช้งานสำหรับการจัดเก็บหรือดึงข้อมูลในขณะรันไทม์โดยใช้ไคลเอนต์ IDX รวมถึง DID DataStore หรือ Self.ID
ชื่อเรื่องรอง
ตลาดซื้อขายข้อมูลของมหาสมุทร
คำอธิบายภาพ
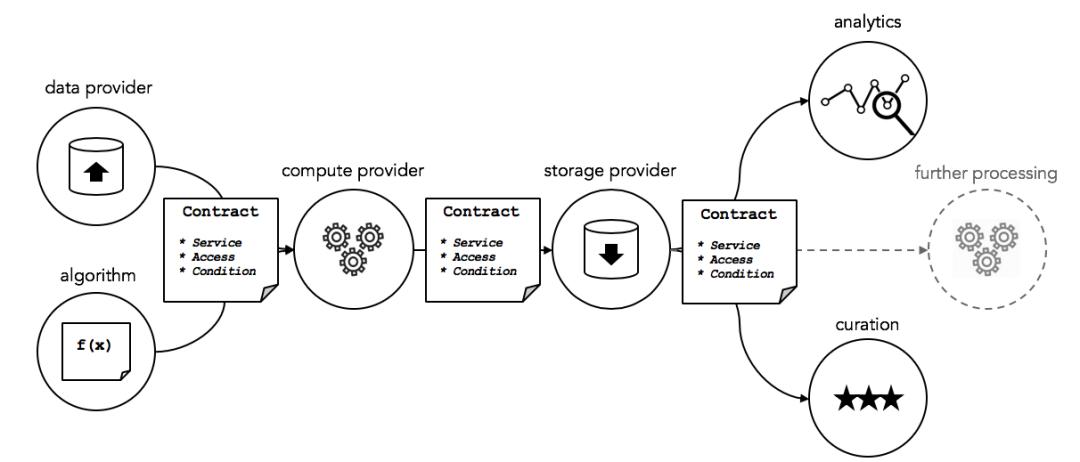
เครดิตรูปภาพ: Ocean Protocol
คำอธิบายภาพ
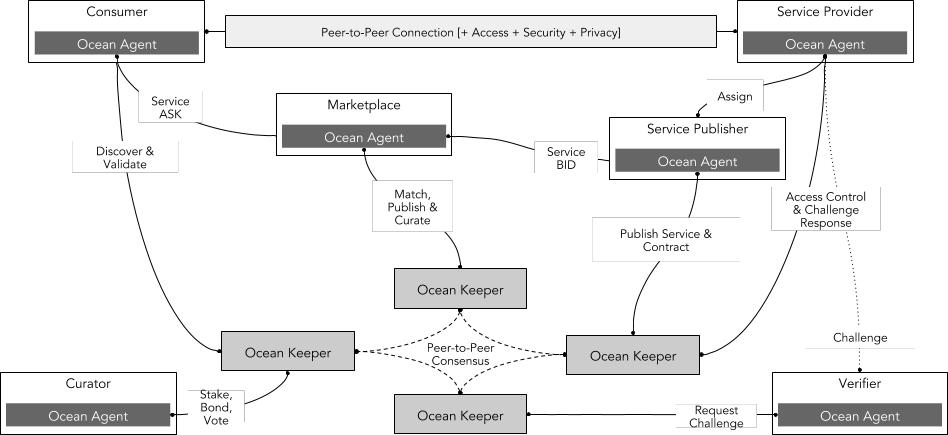
ที่มา: พิธีสารโอเชียน
ชื่อระดับแรก
3.1 การใช้ข้อมูลและสแตก
จากความเข้าใจในเนื้อหาข้างต้น เราขอเสนอกองข้อมูล Web3 ดังแสดงในรูปด้านล่าง
ชั้นล่างสุดเป็นที่จัดเก็บแหล่งข้อมูล รวมถึงที่เก็บข้อมูลแบบกระจายศูนย์ ข้อมูลแบบออนเชนและออฟเชน เป็นต้น
ประการที่สองคือแอปพลิเคชันการจัดการสำหรับข้อมูลเหล่านี้ รวมถึงฐานข้อมูล ตารางข้อมูล มิดเดิลแวร์ดัชนี และตลาดข้อมูล เป็นต้น
คำอธิบายภาพ

เครดิตรูปภาพ: Zonff Partners
เครดิตรูปภาพ: Zonff Partners
ในปัจจุบัน ข้อมูลส่วนใหญ่ที่ใช้บน Web3 ในอุตสาหกรรมเป็นข้อมูลแบบ on-chain และเครื่องมือวิเคราะห์ข้อมูลและเครื่องมือจัดทำดัชนีก็เกิดขึ้นเรื่อย ๆ เหมืองทองขนาดใหญ่ของข้อมูลแบบ on-chain ได้รับการเจาะอย่างเต็มที่ ตารางข้อมูล และ การจำแนกแอปพลิเคชันการวิเคราะห์ในรูปด้านบน ส่วนใหญ่เป็นการทำเหมืองข้อมูลบนเชน และมีเพียงส่วนน้อยเท่านั้นที่เกี่ยวข้องกับข้อมูลนอกเชน โดยทั่วไป ลิงก์การใช้ข้อมูลเป็นกระบวนการ ETLA (แยก แปลง โหลด วิเคราะห์) และแต่ละโหนดมีโปรเจ็กต์ตัวแทน ตัวแทนของโครงการ Extract (แยก) คือ The Graph ในขณะที่ตัวแทนของโครงการ Transform (แปลง) เป็นตารางข้อมูลที่ใช้งานได้และโหลด (Load) link คือ Dune และ Luabsae และตัวแทนของ Analysis (การวิเคราะห์) คือ Nansen และ NFTGO .
โครงการสนับสนุนสำหรับกระบวนการทั้งหมดของ ETLA เกือบจะถูกละทิ้งและมีเพียงบางโครงการเท่านั้นที่มีโอกาสและความท้าทายมากมายที่นี่ ชุมชนกราฟและเซรามิกเองก็กำลังทำงานเพื่อดึงข้อมูลบนเซรามิก และผู้ก่อตั้ง Orbis ก็ได้พยายามสร้าง Cerscan เพื่อเรียกดูข้อมูลบนเซรามิกด้วย Arweave สามารถอ่านและจัดการข้อมูลที่จัดเก็บไว้ใน Arweave ด้วยกราฟย่อยผ่าน The Graph และยังมีโครงการบุคคลที่สามที่เกี่ยวข้องใน Filecoin ที่กำลังดำเนินการนี้ อย่างไรก็ตาม ไม่มีใครสนใจเกี่ยวกับกระบวนการ TLA ในปัจจุบัน เหตุผลที่ใหญ่ที่สุดคือข้อมูลที่จัดเก็บไว้ในที่จัดเก็บแบบกระจายอำนาจที่แตกต่างกันนั้นมีความแตกต่างกันอย่างมากและเป็นการยากที่จะมีแบบจำลองที่รวมเป็นหนึ่งเดียวเพื่อขุดคุณค่าของข้อมูลเหล่านี้ ในหมู่พวกเขา มากที่สุด เซรามิกที่มีแนวโน้มจะใช้ขั้นตอนนี้ เนื่องจากการมีอยู่ของแบบจำลองข้อมูลช่วยลดความแตกต่างของข้อมูลบนเซรามิกแบบทวีคูณ จึงทำให้ความพร้อมใช้งานของข้อมูลสูงขึ้น
นอกจาก data on the chain แล้ว ยังมีอีกหลายโครงการที่พยายามเชื่อมโยง data on the chain กับ data off the chain โครงการดังกล่าวถือได้ว่าเป็นโครงการ "chain reform"
การจำแนกประเภทคือ:
อำนาจอธิปไตยของข้อมูล Web2 และตลาดการค้า: Itheum, Navigate, Swash, Phyllo เป็นต้น โครงการประเภทนี้ส่วนใหญ่รวมข้อมูลอินเทอร์เน็ตแบบดั้งเดิมเข้ากับข้อมูลแบบ on-chain โดยหวังว่าจะเปิดการโต้ตอบข้อมูลระหว่าง Web2 และ Web3 แนวทางปฏิบัติทั่วไปคือการส่งออกข้อมูล Web2 แล้วนำเข้าไปยังกลุ่มข้อมูลที่กำหนดหรือเชื่อมโยงอินเทอร์เน็ตโซเชียลแบบดั้งเดิมโดยตรง บัญชี ฯลฯ ;
ข้อตกลงข้อมูลองค์กร: Authtrail โครงการผสานรวมกับฐานข้อมูลภายในขององค์กรและเข้าร่วมชั้นฉันทามติเพื่อให้ได้ข้อมูลที่ป้องกันการปลอมแปลงและตรวจสอบย้อนกลับได้ภายในองค์กร
การรวมข้อมูลแบบ on-chain และ off-chain: Space และ Time เช่นเดียวกับ Authtrail โครงการนี้จะรวมฐานข้อมูลแบบ off-chain แต่ไม่มี Consensus Layer เป็นการคำนวณร่วมกันระหว่างข้อมูลแบบ off-chain และ on-chain นอกจากนี้ Pool ก็ทำเรื่องคล้ายๆ กัน;
กระบวนทัศน์การใช้ข้อมูลของ Web3 แตกต่างจากของ Web2 อย่างชัดเจน ส่วนใหญ่อยู่ที่วิธีการรวบรวมข้อมูล กล่าวคือ วิธีการจัดเก็บ การทำดัชนี การสกัด การรวม และการใช้ข้อมูลประเภทต่างๆ จะแตกต่างกัน ตามการจัดหมวดหมู่ก่อนหน้านี้ สรุปง่ายๆ ดังต่อไปนี้
ข้อมูลสาธารณะ: รวมถึงข้อมูลสาธารณะและข้อมูลนิติบุคคลบางส่วนที่จัดอยู่ใน "แนวทางปฏิบัติมาตรฐานความปลอดภัยเครือข่าย - แนวทางการจำแนกประเภทข้อมูลและการจัดระดับ" ในฐานะผลิตภัณฑ์สาธารณะ เป็นข้อมูลที่สามารถขุดได้แบบสาธารณะเพื่อมูลค่า การเข้าถึงไม่จำเป็นต้องได้รับอนุญาต แต่สามารถตรวจสอบความเป็นเจ้าของของผู้ใช้ได้ เพื่อติดตามกำไรจาก Airdrop ตัวอย่างทั่วไป ได้แก่ ข้อมูลแบบออนไลน์และข้อมูลแอปพลิเคชันที่ไม่ได้เข้ารหัสซึ่งจัดเก็บไว้ บนพื้นที่เก็บข้อมูลแบบกระจายอำนาจ (เช่น โพสต์ของผู้ใช้ ไลค์ และความคิดเห็น เป็นต้น) การสนับสนุนต้นน้ำที่สำคัญที่สุดสำหรับการใช้งานคือการจัดทำดัชนีแอปพลิเคชัน เช่น The Graph หรือแอปพลิเคชันฐานข้อมูลเนทีฟ Web3 เช่น Tableland
ข้อมูลส่วนตัว: รวมถึงข้อมูลส่วนบุคคลและข้อมูลนิติบุคคลบางส่วนที่จัดอยู่ใน "แนวทางปฏิบัติมาตรฐานความปลอดภัยเครือข่าย - แนวทางการจำแนกประเภทข้อมูลและการจัดระดับ" เนื่องจากเป็นประเภทข้อมูลที่ต้องใช้พื้นที่จัดเก็บที่เข้ารหัสและการกำหนดค่าสิทธิ์ความเป็นส่วนตัวบางอย่าง จึงอนุญาตให้เข้าถึงได้และไม่สามารถรับข้อมูลแบบสาธารณะได้ หากจัดเก็บในพื้นที่เก็บข้อมูลแบบกระจายศูนย์และบล็อกเชน จำเป็นต้องมีพื้นที่เก็บข้อมูลเข้ารหัสที่มีสิทธิ์กำหนดค่าได้ หรือผ่านวิธีการอื่น เช่น ZK, MPC และ TEE และการปกป้องเทคโนโลยีความเป็นส่วนตัวอื่นๆ การสนับสนุนขั้นต้นน้ำที่สำคัญที่สุดสำหรับการใช้งานคือแอปพลิเคชันฐานข้อมูล เช่น Kwil และ Ceramic


