
การวิเคราะห์เชิงลึกของ IPFS: โปรโตคอลพื้นฐานของอินเทอร์เน็ตรุ่นใหม่
ผู้แต่ง: Xiang|W3.Hitchhiker
การอ่านที่เกี่ยวข้อง
นอกจากที่เก็บข้อมูลแล้ว คุณรู้อะไรอีกบ้างเกี่ยวกับ Filecoin
มีอะไรอีกที่ควรให้ความสนใจใน Filecoin?

ผู้แต่ง: Xiang|W3.Hitchhiker
ชื่อเรื่องรอง
การอ่านที่เกี่ยวข้อง
มีอะไรอีกที่ควรให้ความสนใจใน Filecoin?
HTTP
"IPFS"ชื่อระดับแรก"HTTP"IPFS คืออะไร
ขับเคลื่อนอินเทอร์เน็ตแบบกระจายอำนาจ (web3.0)
โปรโตคอลไฮเปอร์มีเดียแบบเพียร์ทูเพียร์ที่รักษาและพัฒนาความรู้ของมนุษย์โดยทำให้เครือข่ายปรับขนาดได้ ยืดหยุ่น และเปิดกว้างมากขึ้น
IPFS เป็นระบบกระจายสำหรับจัดเก็บและเข้าถึงไฟล์ เว็บไซต์ แอปพลิเคชัน และข้อมูล
เป้าหมายคือ ก
คุณอาจคุ้นเคยกับสิ่งนี้มากกว่าเมื่อคุณออนไลน์และเปิดหน้าค้นหาของ Baidu สิ่งที่คุณเห็นคือสิ่งที่คุณได้รับ
โปรโตคอลชั้นแอปพลิเคชันของเว็บคือโปรโตคอลการถ่ายโอนไฮเปอร์เท็กซ์ (HTTP) ซึ่งเป็นแกนหลักของเว็บแบบดั้งเดิม HTTP ถูกนำมาใช้โดยสองโปรแกรม: โปรแกรมไคลเอ็นต์และโปรแกรมเซิร์ฟเวอร์ โปรแกรมไคลเอนต์และโปรแกรมเซิร์ฟเวอร์ทำงานบนระบบปลายทางที่แตกต่างกันและแลกเปลี่ยนเซสชัน HTTP HTTP กำหนดโครงสร้างของข้อมูลนี้และวิธีที่ลูกค้าและเซิร์ฟเวอร์โต้ตอบ
หน้าเว็บประกอบด้วยวัตถุ และวัตถุเป็นเพียงไฟล์ เช่น ไฟล์ HTML, กราฟิก JPEG หรือคลิปวิดีโอขนาดเล็ก และสิ่งเหล่านี้สามารถระบุได้ด้วยที่อยู่ URL หน้าเว็บส่วนใหญ่มีไฟล์ฐาน html และวัตถุอ้างอิงหลายรายการ
HTTP กำหนดวิธีที่เว็บไคลเอ็นต์ร้องขอเว็บเพจจากเว็บเซิร์ฟเวอร์ และวิธีที่เซิร์ฟเวอร์ส่งเว็บเพจไปยังไคลเอ็นต์"หน้าที่ของเบราว์เซอร์คือดำเนินการและแยกวิเคราะห์โปรโตคอล HTTP และโค้ดส่วนหน้า จากนั้นจึงแสดงเนื้อหา เมื่อส่งแบบสอบถาม ฝั่งเว็บมักจะสอบถามฐานข้อมูลและส่งผลลัพธ์กลับไปยังผู้ร้องขอ ซึ่งก็คือเบราว์เซอร์ จากนั้นเบราว์เซอร์จะแสดงออกมา"。
ชื่อระดับแรก
ข้อเสียของโปรโตคอล HTTP
อินเทอร์เน็ตที่เราใช้ตอนนี้ทำงานภายใต้โปรโตคอล http หรือ https โปรโตคอล http ยังเป็นโปรโตคอลการถ่ายโอนไฮเปอร์เท็กซ์ เป็นโปรโตคอลการส่งข้อมูลที่ใช้ในการส่งไฮเปอร์เท็กซ์จากเซิร์ฟเวอร์เวิลด์ไวด์เว็บไปยังเบราว์เซอร์ภายในเครื่อง เป็นเวลากว่า 32 ปีแล้วที่อินเทอร์เน็ต ได้รับการเสนอชื่อในปี 1990 เขาได้มีส่วนร่วมอย่างมากต่อการเติบโตอย่างก้าวกระโดดของอินเทอร์เน็ตในปัจจุบัน และประสบความสำเร็จในด้านความเจริญรุ่งเรืองของอินเทอร์เน็ต
อย่างไรก็ตาม โปรโตคอล HTTP เป็นโปรโตคอลการสื่อสารทางอินเทอร์เน็ตที่ใช้สถาปัตยกรรม C/S และขึ้นอยู่กับกลไกการทำงานแบบรวมศูนย์ของเครือข่ายแกนหลัก ก็มีข้อเสียหลายประการเช่นกัน
ข้อผิดพลาด 404
ประสิทธิภาพการทำงานของเครือข่ายแบ็คโบนต่ำและต้นทุนการใช้งานสูง การใช้โปรโตคอล HTTP จำเป็นต้องดาวน์โหลดไฟล์ทั้งหมดจากเซิร์ฟเวอร์ส่วนกลางทุกครั้ง ซึ่งช้าและไม่มีประสิทธิภาพ
กลไกการทำงานพร้อมกันของเครือข่ายหลักจะจำกัดความเร็วของการเข้าถึงอินเทอร์เน็ต รูปแบบเครือข่ายหลักแบบรวมศูนย์นี้ยังนำไปสู่ความแออัดระหว่างการเข้าถึงเครือข่ายภายใต้การทำงานพร้อมกันสูง
ภายใต้โปรโตคอล http ที่มีอยู่ ข้อมูลทั้งหมดจะถูกจัดเก็บไว้ในเซิร์ฟเวอร์แบบรวมศูนย์เหล่านี้ ยักษ์ใหญ่ด้านอินเทอร์เน็ตไม่เพียงแต่มีอำนาจควบคุมและตีความข้อมูลของเราอย่างสมบูรณ์เท่านั้น แต่ยังมีการควบคุม การปิดล้อม และการตรวจสอบต่างๆ ในระดับหนึ่ง นอกจากนี้ยังจำกัดนวัตกรรมและการพัฒนาอย่างมาก
ค่าใช้จ่ายสูงและง่ายต่อการถูกโจมตี เพื่อรองรับโปรโตคอล HTTP บริษัทที่มีปริมาณการรับส่งข้อมูลจำนวนมาก เช่น Baidu, Tencent และ Ali ได้ลงทุนทรัพยากรจำนวนมากในการดูแลเซิร์ฟเวอร์และความเสี่ยงด้านความปลอดภัยเพื่อป้องกัน DDoS และการโจมตีอื่นๆ เครือข่ายหลักขึ้นอยู่กับปัจจัยต่างๆ เช่น สงคราม ภัยธรรมชาติ และการหยุดทำงานของเซิร์ฟเวอร์ส่วนกลาง ซึ่งอาจทำให้อินเทอร์เน็ตทั้งหมดหยุดชะงักบริการ
โซลูชั่น ipfs
โซลูชันสำหรับ IPFS
IPFS มีฟังก์ชันย้อนรอยเวอร์ชันประวัติของไฟล์ ซึ่งทำให้ง่ายต่อการดูเวอร์ชันย้อนหลังของไฟล์ และข้อมูลไม่สามารถลบได้และสามารถจัดเก็บอย่างถาวรได้
IPFS เป็นโหมดการจัดเก็บข้อมูลตามการกำหนดที่อยู่ของเนื้อหา ไฟล์เดียวกันจะไม่ถูกจัดเก็บซ้ำๆ โดยจะบีบทรัพยากรส่วนเกิน รวมถึงพื้นที่จัดเก็บ และลดค่าใช้จ่ายในการจัดเก็บข้อมูล หากคุณเปลี่ยนไปใช้การดาวน์โหลดแบบ P2P ค่าใช้จ่ายในการใช้แบนด์วิธจะลดลงเกือบ 60%
IPFS ขึ้นอยู่กับเครือข่าย P2P ซึ่งสามารถบันทึกข้อมูลได้จากหลายแหล่ง และสามารถดาวน์โหลดข้อมูลจากหลายโหนดพร้อมกันได้
IPFS ที่สร้างขึ้นบนเครือข่ายแบบกระจายศูนย์นั้นยากต่อการจัดการและจำกัดจากส่วนกลาง และอินเทอร์เน็ตจะเปิดกว้างมากขึ้น
พื้นที่จัดเก็บแบบกระจาย IPFS สามารถลดการพึ่งพาเครือข่ายแกนหลักส่วนกลางได้อย่างมาก
พูดอย่างรวบรัด:

HTTP อาศัยเซิร์ฟเวอร์แบบรวมศูนย์ซึ่งเสี่ยงต่อการถูกโจมตีและปริมาณการใช้งานเพิ่มขึ้น เซิร์ฟเวอร์มีแนวโน้มที่จะหยุดทำงาน ความเร็วในการดาวน์โหลดช้า และต้นทุนการจัดเก็บสูง
IPFS เป็นโหนดแบบกระจายซึ่งมีความปลอดภัยมากกว่าและมีแนวโน้มที่จะโจมตี DDoS น้อยกว่า ไม่พึ่งพาเครือข่ายหลัก ลดค่าใช้จ่ายในการจัดเก็บและมีพื้นที่จัดเก็บขนาดใหญ่ ความเร็วในการดาวน์โหลดรวดเร็ว และบันทึกเวอร์ชันในอดีตของไฟล์ได้ ถูกค้นหาได้และในทางทฤษฎีสามารถจัดเก็บได้อย่างถาวร
เทคโนโลยีใหม่มาแทนที่เทคโนโลยีเก่า ไม่เกิน 2 ประเด็นคือ
ประการแรก สามารถปรับปรุงประสิทธิภาพของระบบ
IPFS ทำทั้งสองอย่าง
เมื่อทำการพัฒนา ทีมงาน IPFS ใช้วิธีการบูรณาการแบบโมดูลาร์สูงเพื่อพัฒนาโครงการทั้งหมด เช่น แบบเอกสารสำเร็จรูป ทีม Protocol Labs ก่อตั้งขึ้นในปี 2558 และได้พัฒนาโมดูล 3 โมดูล ได้แก่ IPLD, LibP2P และ Multiformat เป็นเวลา 17 ปี ซึ่งให้บริการชั้นล่างสุดของ IPFSMultiformats เป็นชุดของชุดอัลกอริธึมการเข้ารหัสแฮชและวิธีการอธิบายตัวเอง (คุณสามารถรู้ได้ว่าค่านั้นถูกสร้างขึ้นจากค่านั้นอย่างไร) มีวิธีการเข้ารหัสหลัก 6 วิธี เช่น SHA1 \SHA256 \SHA512 \Blake3B เพื่อเข้ารหัสและอธิบาย nodeID และการสร้างข้อมูลลายนิ้วมือ
LibP2P เป็นแกนหลักของคอร์ IPFS เมื่อเผชิญกับโปรโตคอลเลเยอร์การขนส่งและอุปกรณ์เครือข่ายที่ซับซ้อนต่าง ๆ มันสามารถช่วยนักพัฒนาสร้างเลเยอร์เครือข่าย P2P ที่มีอยู่ได้อย่างรวดเร็วซึ่งรวดเร็วและคุ้มค่า นี่คือเหตุผลที่เทคโนโลยี IPFS ถูกนำมาใช้กันอย่างแพร่หลาย ในหลาย ๆ ด้าน เหตุผลที่โครงการบล็อกเชนได้รับความนิยมIPLD เป็นมิดเดิลแวร์การแปลงที่รวมโครงสร้างข้อมูลที่แตกต่างกันที่มีอยู่ให้เป็นรูปแบบเดียวเพื่ออำนวยความสะดวกในการแลกเปลี่ยนข้อมูลและการทำงานร่วมกันระหว่างระบบต่างๆ โครงสร้างข้อมูลที่ IPLD รองรับในปัจจุบัน เช่น ข้อมูลบล็อกของ Bitcoin และ Ethereum ยังรองรับ IPFS และ IPLD นี่เป็นเหตุผลที่สองที่ IPFS ได้รับการต้อนรับจากระบบบล็อกเชน มิดเดิลแวร์ IPLD สามารถรวมโครงสร้างบล็อกที่แตกต่างกันให้เป็นมาตรฐานเดียวสำหรับการส่งมอบ
ประโยชน์ของ ipfsประโยชน์ของ IPFSหนึ่งที่รวมแนวคิดของ Kademlia, BitTorrent, Git และอื่น ๆโปรโตคอลการกระจายไฮเปอร์มีเดีย
หลีกเลี่ยงความล้มเหลวของโหนดกลาง กระจายอำนาจอย่างสมบูรณ์โดยไม่มีการตรวจสอบและควบคุมเครือข่ายแบบจุดต่อจุด
ท่องไปในอินเทอร์เน็ตแห่งวันพรุ่งนี้——เบราว์เซอร์ใหม่รองรับโปรโตคอล IPFS (brave, Opera) เป็นค่าเริ่มต้นแล้ว เบราว์เซอร์แบบเดิมสามารถเยี่ยมชมเกตเวย์ IPFS สาธารณะที่มีที่อยู่ เช่น https://ipfs.io หรือติดตั้งคู่หู IPFSส่วนขยายเพื่อเข้าถึงไฟล์ที่จัดเก็บไว้ในเครือข่าย IPFS
——จำเป็นต้องเพิ่มไฟล์ไปยังโลคัลโหนดเท่านั้น เพื่อให้โลกสามารถรับไฟล์ผ่านที่อยู่แฮชเนื้อหาที่เป็นมิตรกับแคชและการกระจายแบนด์วิดท์เครือข่ายที่เหมือน BitTorrent
พึ่งพาการสนับสนุนจากชุมชนโอเพ่นซอร์สที่แข็งแกร่งสำหรับการสร้าง
กรอกแอปพลิเคชันและบริการแบบกระจาย
หนึ่งใน
ชุดเครื่องมือสำหรับนักพัฒนา
IPFS กำหนดวิธีการจัดเก็บ ทำดัชนี และส่งไฟล์ในระบบ กล่าวคือ ไฟล์ที่อัปโหลดจะถูกแปลงเป็นรูปแบบข้อมูลพิเศษสำหรับจัดเก็บ และ IPFS จะแฮชไฟล์เดียวกันเพื่อระบุที่อยู่เฉพาะ ดังนั้นไม่ว่าจะใช้อุปกรณ์ใด สถานที่ใด ไฟล์เดียวกันจะชี้ไปยังที่อยู่เดียวกัน (ต่างจาก URL ที่อยู่นี้เป็นแบบเนทีฟและรับประกันโดยอัลกอริทึมการเข้ารหัส คุณไม่สามารถเปลี่ยนได้ และคุณไม่จำเป็นต้องเปลี่ยน ). จากนั้นเชื่อมต่ออุปกรณ์ทั้งหมดในเครือข่ายผ่านระบบไฟล์ จากนั้นปล่อยให้ไฟล์ที่จัดเก็บบนระบบ IPFS สามารถรับได้อย่างรวดเร็วทุกที่ในโลกโดยไม่ได้รับผลกระทบจากไฟร์วอลล์ (ไม่ต้องใช้พร็อกซีเครือข่าย) พูดโดยพื้นฐานแล้ว IPFS สามารถเปลี่ยนกลไกการกระจายของเนื้อหาเว็บและทำให้การกระจายอำนาจสมบูรณ์
ชื่อระดับแรก
IPFS ทำงานอย่างไรIPFS เป็นเครือข่ายการจัดเก็บข้อมูลแบบเพียร์ทูเพียร์ (p2p) เนื้อหาสามารถเข้าถึงได้ผ่านโหนดที่อยู่ที่ใดก็ได้ในโลก ซึ่งอาจส่งข้อมูล เก็บข้อมูล หรือทั้งสองอย่าง IPFS รู้วิธีใช้ที่อยู่เนื้อหา ไม่ใช่ตำแหน่งเพื่อค้นหาเนื้อหาที่คุณขอทำความเข้าใจหลักการพื้นฐานสามประการของ IPFS:ตัวระบุที่ไม่ซ้ำผ่านการระบุเนื้อหาการเชื่อมโยงเนื้อหาผ่าน Directed Acyclic Graph (DAG)
หลักการทั้งสามนี้พึ่งพาซึ่งกันและกันเพื่อสร้างระบบนิเวศ IPFS เริ่มจาก
ที่อยู่เนื้อหา
และเนื้อหาของ
ระบุได้อย่างไม่ซ้ำใคร"เริ่ม"
การกล่าวถึงเนื้อหาและการระบุเนื้อหาที่ไม่ซ้ำใคร
การกล่าวถึงเนื้อหาและการระบุเนื้อหาที่ไม่ซ้ำใคร
https://en.wikipedia.org/wiki/Aardvark
/Users/Alice/Documents/term_paper.doc
C:\Users\Joe\My Documents\project_sprint_presentation.ppt
IPFS ใช้การระบุเนื้อหาเพื่อระบุเนื้อหาตามเนื้อหามากกว่าตำแหน่งที่ตั้ง การค้นหารายการตามเนื้อหาเป็นสิ่งที่ทุกคนทำอยู่ตลอดเวลาตัวอย่างเช่น ถ้าคุณกำลังมองหาหนังสือในห้องสมุด คุณมักจะมองหาจากชื่อเรื่อง นั่นคือการกล่าวถึงเนื้อหา เพราะคุณกำลังถามว่ามันคืออะไรหากคุณใช้การระบุตำแหน่งเพื่อค้นหาหนังสือ คุณจะพบตามตำแหน่งของหนังสือ:
ฉันต้องการหนังสือที่ชั้นสอง ชั้นสาม และชั้นสี่ สี่เล่มจากซ้าย
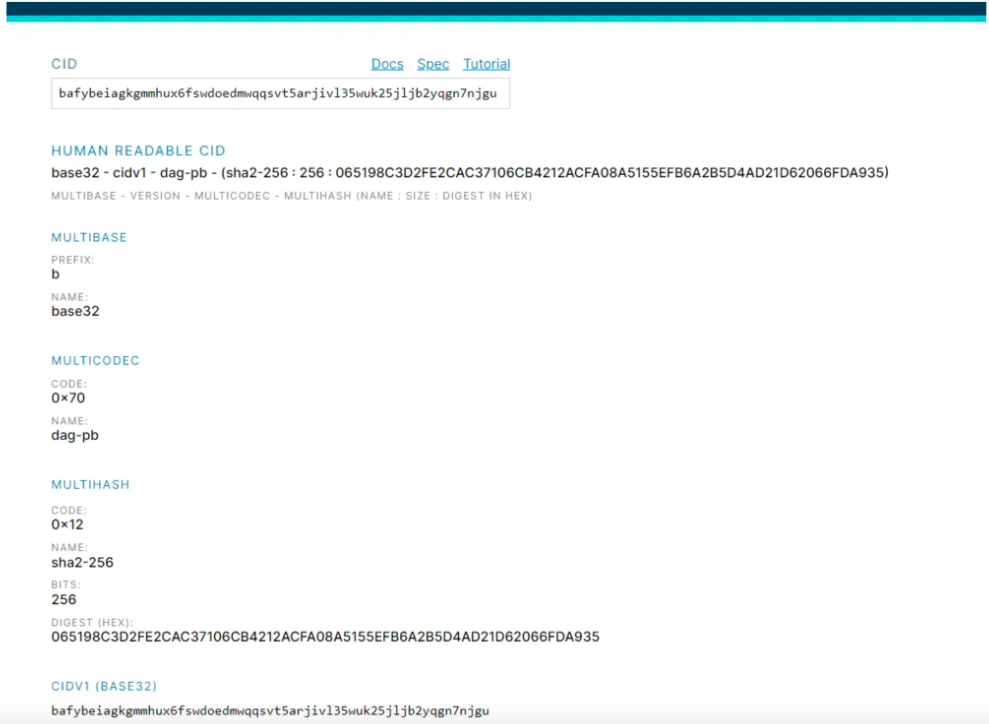
CID (Content Identifiers )
ถ้ามีคนย้ายหนังสือเล่มนั้น คุณโชคไม่ดี!ปัญหามีอยู่ทั้งบนอินเทอร์เน็ตและบนคอมพิวเตอร์ของคุณ! ขณะนี้เนื้อหาถูกค้นหาตามสถานที่ เช่น:
ในทางตรงกันข้าม เนื้อหาทุกชิ้นที่ใช้โปรโตคอล IPFS จะมีเครื่องหมาย *
ตัวระบุเนื้อหา
* นั่นคือ CID แฮชไม่ซ้ำกับเนื้อหาที่มาจาก แม้ว่ามันอาจจะดูสั้นเมื่อเทียบกับเนื้อหาต้นฉบับก็ตาม
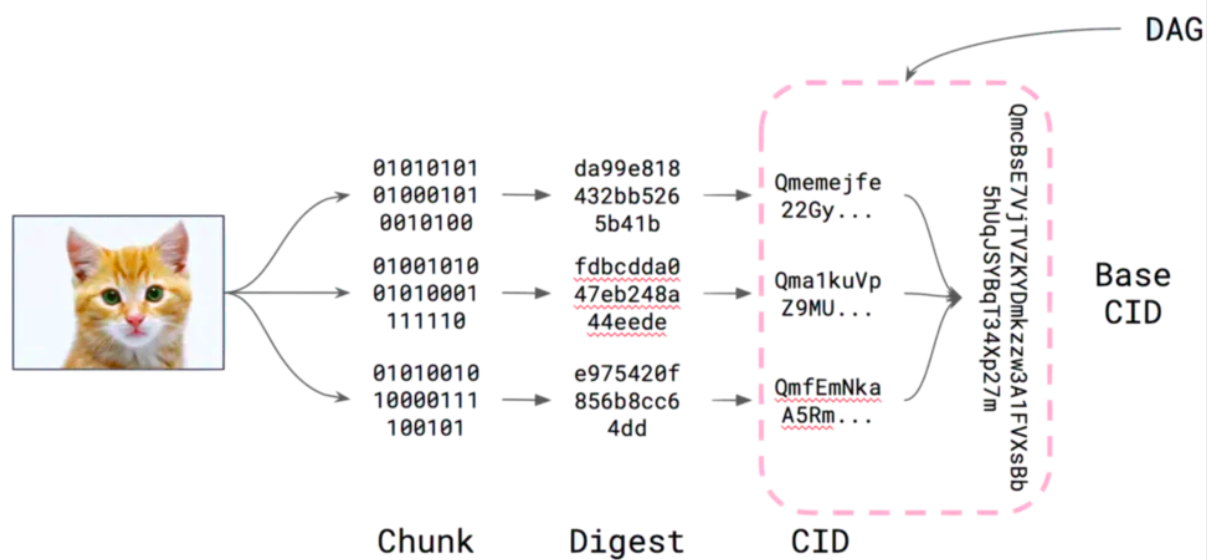
ระบบแบบกระจายหลายระบบใช้การระบุเนื้อหาผ่านการแฮชเพื่อไม่เพียงแต่ระบุเนื้อหาเท่านั้น แต่ยังเชื่อมโยงเนื้อหาเข้าด้วยกันอีกด้วย ทุกอย่างตั้งแต่การคอมมิตที่สนับสนุนโค้ดไปจนถึงบล็อกเชนที่เรียกใช้สกุลเงินดิจิทัลใช้ประโยชน์จากกลยุทธ์นี้ อย่างไรก็ตาม โครงสร้างข้อมูลพื้นฐานในระบบเหล่านี้ไม่จำเป็นต้องทำงานร่วมกัน
ข้อกำหนด CIDสร้างขึ้นใน IPFS ปัจจุบันมีหลายรูปแบบและรองรับโครงการที่หลากหลายรวมถึง IPFS, IPLD, libp2p และ Filecoin แม้ว่าเราจะแชร์ตัวอย่าง IPFS บางส่วนตลอดหลักสูตร แต่บทช่วยสอนนี้จะเกี่ยวกับกายวิภาคของ CID เอง ซึ่งระบบข้อมูลแบบกระจายทุกระบบจะใช้เป็นตัวระบุหลักสำหรับการอ้างอิงเนื้อหาตัวระบุเนื้อหาหรือ CID คือตัวระบุที่อยู่เนื้อหาที่อธิบายตัวเองได้ ไม่ได้ระบุว่า _where_ เนื้อหาถูกเก็บไว้ แต่สร้างที่อยู่ตามเนื้อหา จำนวนอักขระใน CID ขึ้นอยู่กับแฮชการเข้ารหัสของเนื้อหาที่อ้างอิง ไม่ใช่ขนาดของเนื้อหา เนื่องจากเนื้อหาส่วนใหญ่ใน IPFS ใช้แฮช sha2-256 ดังนั้น CID ส่วนใหญ่ที่คุณพบจะมีขนาดเท่ากัน (256 บิตซึ่งเท่ากับ 32 ไบต์) ทำให้จัดการได้ง่ายขึ้น โดยเฉพาะเมื่อต้องจัดการกับเนื้อหาหลายส่วน
ตัวอย่างเช่น หากเราเก็บภาพของอาร์ดวาร์กไว้ในเครือข่าย IPFS CID ของมันจะมีลักษณะดังนี้: QmcRD4wkPPi6dig81r5sLj9Zm1gDCL4zgpEj9CfuRrGbzFลิงค์ IPFS ของ uniswap แสดงก่อนหน้านี้
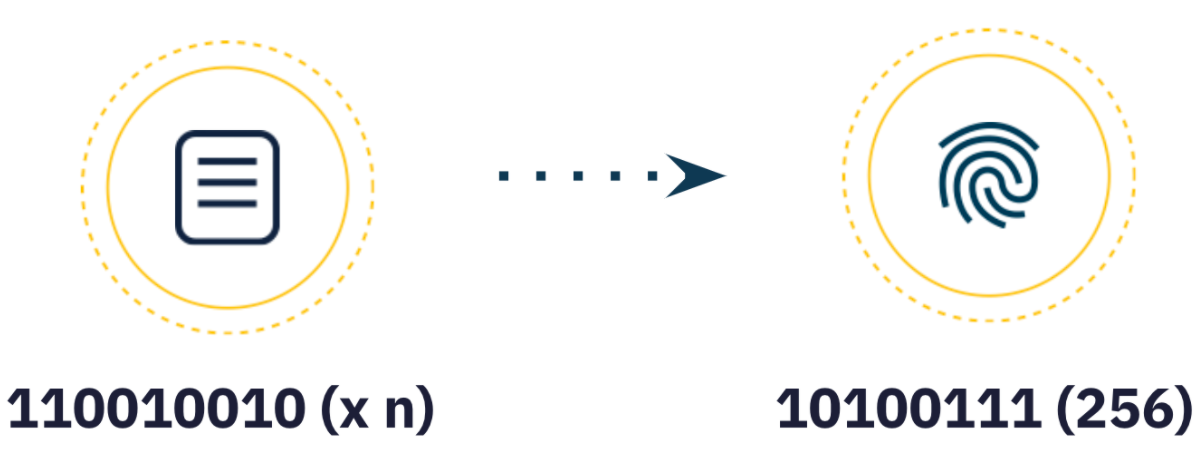
ขั้นตอนแรกในการสร้าง CID คือการแปลงข้อมูลอินพุต โดยใช้อัลกอริทึมการเข้ารหัสเพื่อแมปอินพุตขนาดตามอำเภอใจ (ข้อมูลหรือไฟล์) กับเอาต์พุตขนาดคงที่ การแปลงนี้เรียกว่าลายนิ้วมือดิจิทัลแบบแฮชหรือเรียกง่ายๆ ว่าแฮช (โดยค่าเริ่มต้นจะใช้ sha2-256)ใช้งานอยู่
อัลกอริทึมการเข้ารหัสต้องสร้างแฮชที่มีลักษณะดังต่อไปนี้:
ความมั่นใจ:อินพุตเดียวกันควรสร้างแฮชเดียวกันเสมอ
ไม่เกี่ยวข้อง:
การเปลี่ยนแปลงเล็กน้อยในข้อมูลอินพุตควรสร้างแฮชที่แตกต่างไปจากเดิมอย่างสิ้นเชิง
ทิศทางเดียว:
Multiformats
เป็นไปไม่ได้ที่จะพุชข้อมูลอินพุตกลับจากแฮช
เอกลักษณ์:
Multiformatsมีเพียงไฟล์เดียวเท่านั้นที่สามารถสร้างแฮชเฉพาะได้
โปรดทราบว่าหากเราเปลี่ยนพิกเซลเดียวในรูปภาพอาร์ดวาร์ก อัลกอริทึมการเข้ารหัสจะสร้างแฮชที่แตกต่างกันโดยสิ้นเชิงสำหรับรูปภาพ
เมื่อเราดึงข้อมูลโดยใช้ที่อยู่เนื้อหา เรารับประกันได้ว่าจะได้เห็นข้อมูลนั้นในเวอร์ชันที่คาดไว้ สิ่งนี้ค่อนข้างแตกต่างจากการระบุตำแหน่งบนเว็บแบบดั้งเดิม ซึ่งเนื้อหาของที่อยู่ (URL) หนึ่งๆ จะเปลี่ยนไปเมื่อเวลาผ่านไป
โครงสร้างของ CID
Multiformats รับผิดชอบหลักในการเข้ารหัสข้อมูลประจำตัวและคำอธิบายตัวเองของข้อมูลในระบบ IPFS
Multiformats คือชุดของโปรโตคอลสำหรับระบบรักษาความปลอดภัยในอนาคต รูปแบบ Self-Description ช่วยให้ระบบสามารถทำงานร่วมกันและอัปเกรดซึ่งกันและกันได้
multihash - แฮชที่อธิบายตนเอง
multiaddr - ที่อยู่เครือข่ายที่อธิบายตนเอง
multibase - การเข้ารหัสฐานที่อธิบายตนเอง
มัลติสตรีม - โปรโตคอลเครือข่ายสตรีมมิ่งที่อธิบายตนเอง
มัลติแกรม (WIP) - โปรโตคอลเครือข่ายแพ็กเก็ตที่อธิบายตนเอง
ลิงค์เนื้อหากำกับกราฟ Acyclic (DAG)
Merkle DAG สืบทอดความสามารถในการกำหนดของ CID การใช้การระบุเนื้อหาสำหรับ DAG มีความหมายที่น่าสนใจสำหรับการเผยแพร่ ก่อนอื่น ใครก็ตามที่เป็นเจ้าของ DAG สามารถทำหน้าที่เป็นผู้ให้บริการสำหรับ DAG นั้นได้ อย่างที่สองคือเมื่อเราดึงข้อมูลที่เข้ารหัสเป็น DAG เช่นไดเร็กทอรีของไฟล์ เราสามารถใช้ประโยชน์จากข้อเท็จจริงที่ว่าเราสามารถดึงข้อมูลย่อยทั้งหมดของโหนดแบบขนาน ซึ่งอาจมาจากผู้ให้บริการหลายราย! ประการที่สาม เซิร์ฟเวอร์ไฟล์ไม่จำกัดเฉพาะศูนย์ข้อมูลแบบรวมศูนย์ ทำให้ข้อมูลของเราครอบคลุมพื้นที่ที่กว้างขึ้น ประการสุดท้าย เนื่องจากแต่ละโหนดใน DAG มี CID ของตัวเอง ดังนั้น DAG ที่เป็นตัวแทนจึงสามารถใช้ร่วมกันและเรียกคืนโดยไม่ขึ้นกับ DAG ใดๆ ที่ฝังอยู่
ตรวจสอบได้
ตรวจสอบได้
เคยสำรองไฟล์แล้วพบไฟล์หรือไดเร็กทอรีทั้งสองนั้นในเดือนต่อมา และสงสัยว่าเนื้อหาของไฟล์นั้นเหมือนกันหรือไม่ คุณสามารถคำนวณ Merkle DAG สำหรับข้อมูลสำรองแต่ละไฟล์โดยไม่ต้องลำบากเปรียบเทียบไฟล์: หาก CID ของไดเร็กทอรีรูทตรงกัน คุณจะรู้ว่าไฟล์ใดสามารถลบได้อย่างปลอดภัย และเพิ่มพื้นที่ว่างในฮาร์ดไดรฟ์ของคุณ!
ความสามารถในการมอบหมาย
ความสามารถในการมอบหมาย
เช่น การกระจายข้อมูลขนาดใหญ่ บนเครือข่ายเว็บแบบดั้งเดิม:
ผู้พัฒนาไฟล์ที่ใช้ร่วมกันมีหน้าที่รับผิดชอบในการบำรุงรักษาเซิร์ฟเวอร์และค่าใช้จ่ายที่เกี่ยวข้อง
เซิร์ฟเวอร์เดียวกันมีแนวโน้มที่จะใช้เพื่อตอบสนองคำขอจากทั่วทุกมุมโลก
ข้อมูลสามารถกระจายแบบเสาหินเป็นไฟล์เก็บถาวรไฟล์เดียว
ความยากลำบากในการค้นหาผู้ให้บริการรายอื่นของข้อมูลเดียวกัน
ข้อมูลอาจอยู่ในกลุ่มใหญ่และต้องดาวน์โหลดแบบอนุกรมจากผู้ให้บริการรายเดียว
เป็นการยากที่ผู้อื่นจะแบ่งปันข้อมูล
Merkle DAG ช่วยเราบรรเทาปัญหาเหล่านี้ทั้งหมด โดยการแปลงข้อมูลเป็น DAG ที่ระบุเนื้อหา:
โหนดจากทั่วโลกสามารถเข้าร่วมในการให้บริการข้อมูล
แต่ละส่วนของ DAG มี CID ของตัวเองและสามารถแจกจ่ายได้อย่างอิสระ
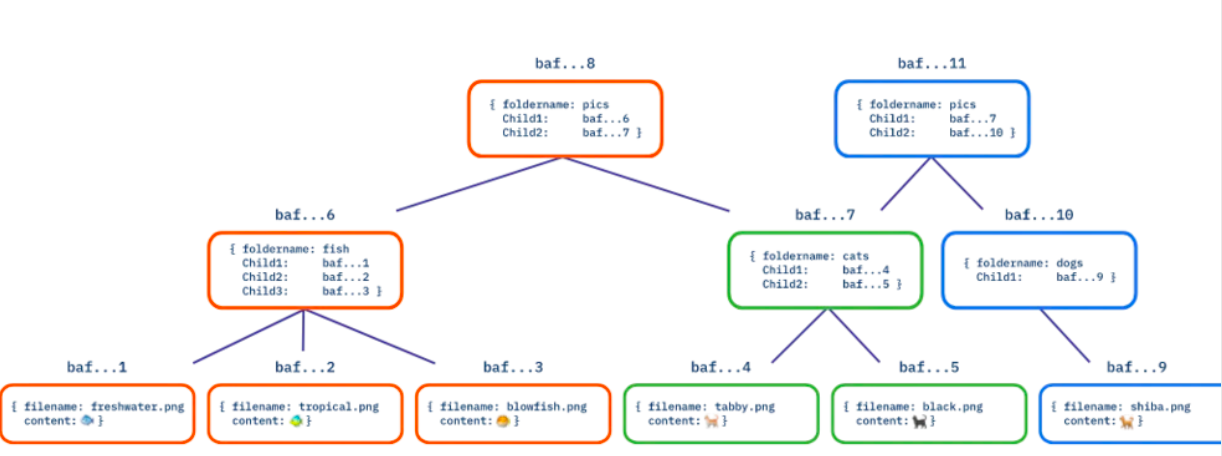
โหนดที่ประกอบเป็น DAG นั้นมีขนาดเล็กและสามารถดาวน์โหลดพร้อมกันได้จากผู้ให้บริการหลายราย
ทั้งหมดนี้มีส่วนทำให้ข้อมูลสำคัญสามารถปรับขยายได้
การขจัดความซ้ำซ้อน
Libp2p
libp2pตัวอย่างเช่น ท่องเว็บ! เมื่อมีผู้เยี่ยมชมหน้าเว็บโดยใช้เบราว์เซอร์ เบราว์เซอร์จะต้องดาวน์โหลดทรัพยากรที่เกี่ยวข้องกับหน้าเว็บก่อน ซึ่งรวมถึงรูปภาพ ข้อความ และสไตล์ อันที่จริงแล้ว หน้าเว็บหลายหน้าดูคล้ายกันมากจริงๆ แค่ใช้ธีมเดียวกันและหน้าอื่นๆ ที่มีการเปลี่ยนแปลงเล็กน้อย มีความซ้ำซ้อนมากมายที่นี่IPFSเมื่อเบราว์เซอร์ได้รับการปรับให้เหมาะสมเพียงพอ จะสามารถหลีกเลี่ยงการดาวน์โหลดคอมโพเนนต์นี้ได้หลายครั้ง เมื่อใดก็ตามที่ผู้ใช้เยี่ยมชมเว็บไซต์ใหม่ เบราว์เซอร์จะต้องดาวน์โหลดโหนดที่เกี่ยวข้องกับส่วนต่าง ๆ ใน DAG เท่านั้น และส่วนอื่น ๆ ที่ดาวน์โหลดมาก่อนหน้านี้ก็ไม่จำเป็นต้องดาวน์โหลดอีก! (นึกถึงธีม WordPress ไลบรารี Bootstrap CSS หรือไลบรารี JavaScript ทั่วไป)
ตารางแฮชแบบกระจาย (DHT) เป็นระบบแบบกระจายสำหรับการแมปคีย์กับค่าต่างๆ ใน IPFS จะใช้ DHT เป็นส่วนประกอบพื้นฐานของระบบการกำหนดเส้นทางเนื้อหา และทำหน้าที่เป็นจุดตัดระหว่างไดเร็กทอรีและระบบนำทาง โดยจะแมปสิ่งที่ผู้ใช้กำลังมองหาไปยังโหนดเพียร์ที่เก็บเนื้อหาที่ตรงกัน คิดว่ามันเป็นตารางขนาดยักษ์ว่าใครเป็นเจ้าของข้อมูลอะไร
เครือข่าย
ชื่อระดับแรก
เป็นสแตกเครือข่ายแบบโมดูลาร์ที่เริ่มต้นจากพัฒนาเป็นโครงการอิสระ นอกจากนี้ยังใช้ Polkadot และ eth2.0 ยังใช้บางส่วนอีกด้วย
NAT:เพื่ออธิบายว่าเหตุใด libp2p จึงเป็นส่วนสำคัญของเว็บแบบกระจายศูนย์ เราจำเป็นต้องถอยออกมาหนึ่งก้าวและเข้าใจว่ามันมาจากไหน การนำ libp2p ไปใช้งานครั้งแรกนั้นเริ่มต้นด้วย IPFS ซึ่งเป็นระบบการแชร์ไฟล์แบบเพียร์ทูเพียร์ เริ่มต้นด้วยการสำรวจปัญหาเครือข่ายที่ IPFS มุ่งแก้ไข
ชื่อระดับแรกเครือข่ายเป็นระบบที่ซับซ้อนมากโดยมีกฎและข้อจำกัดของตัวเอง ดังนั้น เราจำเป็นต้องพิจารณาหลายสถานการณ์และกรณีการใช้งานเมื่อออกแบบระบบเหล่านี้:
ความน่าเชื่อถือ:ไฟร์วอลล์:
แล็ปท็อปของคุณอาจติดตั้งไฟร์วอลล์ที่ปิดกั้นหรือจำกัดการเชื่อมต่อบางอย่างเราเตอร์ WiFi ที่บ้านของคุณพร้อม NAT (การแปลที่อยู่เครือข่าย) ที่แปลที่อยู่ IP ในเครื่องแล็ปท็อปของคุณเป็นที่อยู่ IP เดียวที่เครือข่ายนอกบ้านของคุณสามารถเชื่อมต่อได้
เครือข่ายแฝงสูง:เครือข่ายเหล่านี้มีการเชื่อมต่อที่ช้ามาก ทำให้ผู้ใช้ต้องรอนานเพื่อดูเนื้อหาของตน
ความน่าเชื่อถือ:มีเครือข่ายมากมายกระจายอยู่ทั่วโลก และผู้ใช้จำนวนมากมักประสบปัญหาเครือข่ายที่ช้าซึ่งไม่มีระบบที่แข็งแกร่งเพื่อให้การเชื่อมต่อที่ดีแก่ผู้ใช้ การเชื่อมต่อขาดการเชื่อมต่อบ่อยครั้ง และระบบเครือข่ายของผู้ใช้มีคุณภาพไม่ดี ดังนั้นจึงไม่สามารถให้บริการตามที่สมควรแก่ผู้ใช้ได้
โรมมิ่ง:การกำหนดที่อยู่มือถือเป็นอีกกรณีหนึ่งที่เราจำเป็นต้องรับประกันว่าอุปกรณ์ของผู้ใช้จะยังคงถูกค้นพบโดยไม่ซ้ำใครในขณะที่นำทางผ่านเครือข่ายต่างๆ ทั่วโลก ปัจจุบันพวกเขาทำงานในระบบกระจายที่ต้องการจุดประสานงานและการเชื่อมต่อจำนวนมาก แต่โซลูชันที่ดีที่สุดคือการกระจายอำนาจ
การเซ็นเซอร์:ในสถานะปัจจุบันของเว็บ หากคุณเป็นหน่วยงานของรัฐ ค่อนข้างง่ายที่จะบล็อกเว็บไซต์ในโดเมนเว็บไซต์เฉพาะ สิ่งนี้มีประโยชน์ในการหยุดกิจกรรมที่ผิดกฎหมาย แต่กลายเป็นปัญหาเมื่อระบอบเผด็จการต้องการกีดกันการเข้าถึงทรัพยากรของประชากร
รันไทม์: มีรันไทม์อยู่หลายประเภท เช่น อุปกรณ์ IoT (Internet of Things) (Raspberry Pi, Arduino เป็นต้น) และกำลังได้รับการนำไปใช้เป็นจำนวนมาก เนื่องจากพวกเขาสร้างด้วยทรัพยากรที่จำกัด รันไทม์มักจะใช้โปรโตคอลที่แตกต่างกันซึ่งตั้งสมมติฐานมากมายเกี่ยวกับรันไทม์
นวัตกรรมช้ามาก:
แม้แต่บริษัทที่ประสบความสำเร็จสูงสุดซึ่งมีทรัพยากรมหาศาลก็ยังต้องใช้เวลาหลายสิบปีในการพัฒนาและปรับใช้โปรโตคอลใหม่
ความเป็นส่วนตัวของข้อมูล:
Peer เมื่อเร็ว ๆ นี้ผู้บริโภคมีความกังวลมากขึ้นเกี่ยวกับจำนวนบริษัทที่ไม่เคารพความเป็นส่วนตัวของผู้ใช้ที่เพิ่มขึ้น
Peer-to-Peer (P2P) ปัญหาปัจจุบันเกี่ยวกับโปรโตคอล p2p
ปัญหาปัจจุบันเกี่ยวกับโปรโตคอล P2P
เครือข่ายแบบ Peer-to-Peer (P2P) เกิดขึ้นจากแนวคิดของอินเทอร์เน็ตว่าเป็นวิธีการสร้างเครือข่ายที่ยืดหยุ่นซึ่งจะทำงานได้แม้ว่าโหนดเพียร์จะถูกตัดการเชื่อมต่อจากเครือข่ายเนื่องจากภัยพิบัติทางธรรมชาติหรือที่มนุษย์สร้างขึ้น ทำให้ผู้คนสามารถ เพื่อติดต่อสื่อสารต่อไป
เครือข่าย P2P สามารถใช้กับกรณีการใช้งานที่หลากหลาย ตั้งแต่การโทรผ่านวิดีโอ (เช่น Skype) ไปจนถึงการแชร์ไฟล์ (เช่น IPFS, Gnutella, KaZaA, eMule และ BitTorrent)
แนวคิดพื้นฐาน
- ผู้เข้าร่วมเครือข่ายการกระจายอำนาจ โหนดเพียร์เป็นผู้เข้าร่วมที่ได้รับสิทธิ์เท่าเทียมกันและมีความสามารถเท่าเทียมกันในแอปพลิเคชัน ใน IPFS เมื่อคุณโหลดแอปพลิเคชันเดสก์ท็อป IPFS บนแล็ปท็อป อุปกรณ์ของคุณจะกลายเป็น Peer node ในเครือข่าย IPFS แบบกระจายอำนาจ
- เครือข่ายแบบกระจายอำนาจที่มีการแบ่งปันปริมาณงานระหว่างเพียร์โหนด ดังนั้นใน IPFS แต่ละโหนดเพียร์อาจโฮสต์ไฟล์ทั้งหมดหรือบางไฟล์เพื่อแบ่งปันกับโหนดเพียร์อื่น เมื่อโหนดร้องขอไฟล์ โหนดใดๆ ที่เป็นเจ้าของชิ้นส่วนของไฟล์เหล่านั้นสามารถมีส่วนร่วมในการส่งไฟล์ที่ร้องขอได้ ฝ่ายที่ร้องขอข้อมูลสามารถแบ่งปันข้อมูลกับฝ่ายอื่นได้ในภายหลัง
IPFS แสวงหาแรงบันดาลใจจากเว็บแอปพลิเคชันในปัจจุบันและในอดีตและการวิจัยเพื่อพยายามปรับปรุงระบบ P2P มีเอกสารทางวิทยาศาสตร์มากมายในสถาบันการศึกษาที่ให้แนวคิดเกี่ยวกับวิธีแก้ปัญหาเหล่านี้ แต่ในขณะที่การวิจัยให้ผลลัพธ์เบื้องต้น แต่ก็ยังขาดการนำรหัสไปใช้และปรับแต่งได้
การนำโค้ดไปใช้ในระบบ P2P ที่มีอยู่นั้นหายากมาก และเมื่อมีอยู่จริง ก็มักจะยากที่จะนำกลับมาใช้ใหม่หรือนำไปใช้ใหม่ด้วยเหตุผลดังต่อไปนี้:
ไฟล์เสียหรือไม่มีอยู่จริง
ใบอนุญาตที่ถูกจำกัดหรือไม่พบใบอนุญาต
รหัสเก่ามากอัปเดตล่าสุดเมื่อสิบกว่าปีที่แล้ว
ไม่มีจุดติดต่อ (ไม่มีผู้ดูแลที่จะติดต่อ)
รหัสแหล่งที่มาปิด (กรรมสิทธิ์)
ผลิตภัณฑ์ที่เลิกใช้แล้ว
ไม่มีข้อกำหนดให้
ไม่มีการเปิดเผย API ที่เป็นมิตร
การนำไปปฏิบัตินั้นเชื่อมโยงแน่นเกินไปกับกรณีการใช้งานเฉพาะ
ไม่สามารถใช้การอัปเกรดโปรโตคอลในอนาคตได้
libp2p เป็นสแต็กเครือข่ายของ IPFS แต่แยกออกจาก IPFS และกลายเป็นโปรเจ็กต์ชั้นหนึ่งอิสระและเป็นโปรเจ็กต์ที่ขึ้นต่อกันของ IPFSโมดูลาร์。

ด้วยวิธีนี้ libp2p สามารถพัฒนาต่อไปได้โดยไม่ต้องพึ่งพา IPFS ทำให้ได้ระบบนิเวศและชุมชนของตนเอง IPFS เป็นเพียงหนึ่งในผู้ใช้จำนวนมากที่กลายเป็น libp2p

ด้วยวิธีนี้ แต่ละโครงการสามารถมุ่งเน้นไปที่เป้าหมายของตนเองเท่านั้น:

IPFS ให้ความสำคัญกับการกำหนดที่อยู่ของเนื้อหา เช่น การค้นหา การดึงข้อมูล และการรับรองความถูกต้องของเนื้อหาใดๆ บนเครือข่าย

IPLD
libp2p ให้ความสำคัญกับการกำหนดแอดเดรสของกระบวนการ เช่น การค้นหา การเชื่อมต่อ และการรับรองความถูกต้องของกระบวนการถ่ายโอนข้อมูลใดๆ ในเครือข่าย แล้ว libp2p ทำอย่างไร?
Iคำตอบคือ:
โมดูลาร์
libp2p ได้ระบุส่วนเฉพาะที่ประกอบกันเป็นสแต็กเครือข่าย:การใช้งานหลายภาษา รองรับ 7 ภาษาในการพัฒนา การใช้งาน JavaScript ของ libp2p ยังเหมาะสำหรับเบราว์เซอร์และเบราว์เซอร์มือถือ! สิ่งนี้สำคัญมากเนื่องจากทำให้แอปพลิเคชันสามารถเรียกใช้ libp2p บนเดสก์ท็อปและอุปกรณ์เคลื่อนที่ได้เช่นกัน。
แอปพลิเคชันประกอบด้วยพื้นที่จัดเก็บไฟล์ การสตรีมวิดีโอ กระเป๋าเงินดิจิทัล เครื่องมือพัฒนา และบล็อกเชน โครงการชั้นนำในบล็อกเชนมีโมดูล libp2p ที่ใช้ IPFS อยู่แล้วIPLD ใช้เพื่อทำความเข้าใจและประมวลผลข้อมูล
PLD เป็นมิดเดิลแวร์การแปลง ซึ่งรวมโครงสร้างข้อมูลที่แตกต่างกันที่มีอยู่ให้เป็นรูปแบบเดียว อำนวยความสะดวกในการแลกเปลี่ยนข้อมูลและการทำงานร่วมกันระหว่างระบบต่างๆ แบบจำลองข้อมูลและการถอดรหัส และใช้ CID เป็นลิงค์ขั้นแรก เรากำหนด "แบบจำลองข้อมูล" ซึ่งอธิบายโดเมนและขอบเขตของข้อมูล สิ่งนี้มีความสำคัญเนื่องจากเป็นรากฐานของทุกสิ่งที่เราจะสร้าง (พูดกว้างๆ เราสามารถพูดได้ว่า data model คือ "like JSON" เช่น map, string, list เป็นต้น) หลังจากนี้ เราจะนิยาม "codecs" ซึ่งบอกว่าจะแยกวิเคราะห์จากข้อความและใช้มันเป็น ข้อความที่เราต้องการให้ออกแบบฟอร์ม IPLD มีตัวแปลงสัญญาณมากมาย คุณสามารถเลือกใช้ตัวแปลงสัญญาณที่แตกต่างกันโดยขึ้นอยู่กับแอปพลิเคชันอื่นที่คุณต้องการโต้ตอบด้วย หรือเพียงแค่ว่าแอปพลิเคชันของคุณชอบประสิทธิภาพเทียบกับความสามารถในการอ่านของมนุษย์ได้ดีเพียงใด
IPLD ใช้โปรโตคอลสามชั้นสูงสุด:
วัตถุ ไฟล์ ชื่อ
ชั้นวัตถุ
- ข้อมูลใน IPFS ถูกจัดระเบียบในโครงสร้างของ Merkle Directed Acyclic Graph (Merkle DAG) โหนดเรียกว่าออบเจกต์ซึ่งสามารถมีข้อมูลหรือลิงก์ไปยังออบเจ็กต์อื่น ๆ ลิงก์คือแฮชเข้ารหัสของข้อมูลเป้าหมายที่ฝังอยู่ในแหล่งที่มา โครงสร้างข้อมูลเหล่านี้มีคุณสมบัติที่เป็นประโยชน์มากมาย เช่น การกำหนดที่อยู่เนื้อหา การต่อต้านการงัดแงะข้อมูล การขจัดข้อมูลซ้ำซ้อน ฯลฯ
ชั้นไฟล์- ในการสร้างแบบจำลองระบบควบคุมเวอร์ชันที่เหมือน Git บน Merkle DAG, IPFS กำหนดวัตถุต่อไปนี้:
บล็อกข้อมูลหยด: หยดเป็นบล็อกข้อมูลขนาดแปรผัน (ไม่มีลิงก์) แทนบล็อกข้อมูล
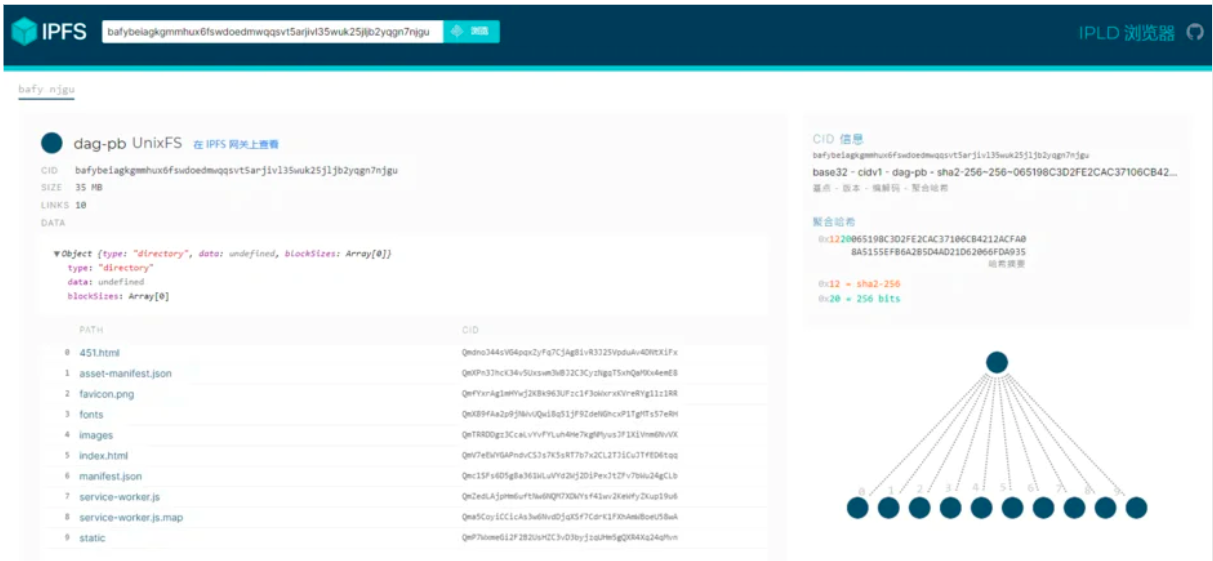
รายการ: ใช้เพื่อจัดระเบียบ blobs หรือรายการอื่น ๆ อย่างเป็นระเบียบ มักจะเป็นตัวแทนของไฟล์คอมมิท: คล้ายกับคอมมิทของ Git ซึ่งแสดงสแน็ปช็อตในประวัติเวอร์ชันของวัตถุ
Filecoin
ชั้นชื่อ- เนื่องจากการเปลี่ยนแปลงแต่ละครั้งของวัตถุจะเปลี่ยนค่าแฮช จึงจำเป็นต้องมีการแมปสำหรับค่าแฮช IPNS (Inter Planetary Namespace System) กำหนดเนมสเปซที่ไม่แน่นอนให้กับผู้ใช้แต่ละคน และวัตถุสามารถเผยแพร่ไปยังเส้นทางที่ลงนามโดยคีย์ส่วนตัวของผู้ใช้เพื่อตรวจสอบความถูกต้องของวัตถุ คล้ายกับ URL
สอดคล้องกับการแสดงผลของ IPLD:


