Blockchain เป็นเทคโนโลยีที่หลายฝ่ายร่วมกันทำกระบวนการบันทึกบัญชีแยกประเภทให้สมบูรณ์ ฝ่ายคอมพิวเตอร์ที่เข้าร่วมหลายฝ่ายเชื่อมต่ออุปกรณ์เข้ากับเครือข่ายเพื่อสร้างเครือข่ายบล็อกเชนแบบเปิด เช่น Bitcoin, Ethereum, Polkadot เป็นต้น ผู้เข้าร่วมคอมพิวเตอร์ทั้งหมดแบ่งปันทรัพยากรสำหรับการใช้งาน โดยนักพัฒนาและผู้ใช้ในกฎการปฏิบัติงานดังกล่าว "การไหลของข้อมูล" จะดำเนินไปในทุกขั้นตอนการทำงานตั้งแต่การสื่อสารของโหนดพื้นฐานจนถึงการบล็อกการบรรจุ การคัดลอก การยืนยัน และการโอนธุรกรรมที่ชั้นแอปพลิเคชัน ตั้งแต่ธุรกรรมการโอนในเครือข่ายไปจนถึงยอดคงเหลือของแต่ละโหนด ข้อมูลบัญชี และข้อมูลบนเครือข่ายด้วยเหตุนี้ กระบวนทัศน์ของบล็อกเชนสำหรับการประมวลผลข้อมูลจึงเป็นข้อได้เปรียบที่ใหญ่ที่สุดเหนือการประมวลผลข้อมูลในฐานข้อมูลแบบเดิมต้องบอกว่าในวัฏจักรอินเทอร์เน็ตที่ยาวนานนั้นองค์กรต่าง ๆ รับรู้ข้อมูลว่าเป็นคุณค่าหลักและในเวลาเดียวกันปัญหาการประมวลผลและการจัดการข้อมูลจำนวนมากจำเป็นต้องได้รับการแก้ไขอย่างเร่งด่วน โชคดีที่ blockchain จำนวนมาก โครงการต่างๆ กำลังพัฒนา พยายามใช้เทคโนโลยีบล็อกเชนและรวมเข้ากับเทคโนโลยีอื่นๆ เพื่อสร้างโซลูชันข้อมูลบนบล็อกเชนตัวอย่างเช่น มีการเพิ่มการออกแบบโครงสร้างหลายรูปแบบและรูปแบบการคำนวณต่างๆ ลงในโครงสร้างข้อมูลของบล็อกเชน1. พื้นฐานและขั้นสูงตามโครงสร้างข้อมูล blockchain
กระบวนการการไหลของข้อมูลของเครือข่าย blockchain เป็นเช่นนี้ โหนดค้นพบธุรกรรม (ข้อมูล) จากนั้นทำแพ็คเกจธุรกรรมเพื่อสร้างบล็อก จากนั้น โหนดบรรจุภัณฑ์จะเริ่มออกอากาศ และโหนดที่เข้าร่วมในฉันทามติจะเริ่มคัดลอก บล็อกและบันทึก (หรือโหนดฉันทามติยืนยัน หลังจากบันทึก โหนดแบบเต็มอื่นๆ จะเริ่มจำลองแบบ)ด้วยวิธีนี้ ข้อมูลบนบล็อกเชนจะน่าเชื่อถือ (เปิดเผยและโปร่งใส และไม่สามารถแก้ไขได้)ข้อมูลถูกเก็บไว้ในบล็อก เนื่องจากขนาดบล็อกมีจำกัด บล็อกจึงมักเต็มไปด้วยข้อมูลขนาดเล็ก เช่น ธุรกรรมการโอน Bitcoin การโอน Ethereum และข้อความการเรียกสัญญาเราสามารถแทนที่ข้อมูลการทำธุรกรรมเหล่านี้ด้วยข้อมูลอื่นๆ เช่น การตรวจสอบย้อนกลับของสินค้าและข้อมูลการหมุนเวียน นอกจากนี้ยังสามารถแทนที่ด้วยข้อมูลที่เปิดเผยได้ เช่น การคลิกโฆษณา การใช้เงินบริจาคเพื่อสวัสดิการสาธารณะ ข้อมูลบัญชีร่วมธนาคาร เป็นต้นอย่างไรก็ตาม เนื่องจากจำนวนไบต์ของข้อมูลอื่นๆ มีขนาดค่อนข้างใหญ่ จึงเหมาะสมกว่าที่จะเก็บข้อมูลขนาดเล็ก เช่น ข้อมูลการทำธุรกรรมเป็นบล็อกๆ หลังจากการยืนยันบล็อกเชนจากหลายฝ่าย ข้อมูลสาธารณะเหล่านี้มีความน่าเชื่อถือและสามารถอ่านและใช้งานได้2. โครงสร้างข้อมูลเครือข่าย oracle ของ Chainlink
โมเดลการประมวลผลราคาของ Chainlink
หลังจากประมวลผลบนเครือข่ายแล้วข้อมูลราคาที่น่าเชื่อถือจะถูกสร้างขึ้นซึ่งแอปพลิเคชัน DeFi สามารถค้นพบและใช้งานได้ ตามจำนวนครั้งที่ใช้ข้อมูล โทเค็น LINK จะจ่ายให้กับเครือข่ายเป็นค่าตอบแทน รายได้จูงใจในรูปแบบนี้ ข้อมูลที่ป้อนเข้าจากภายนอกเครือข่าย Chainlink จะถูกรวบรวมและประมวลผลในห่วงโซ่ และสุดท้ายจะไหลไปยังผู้ร้องขอเพื่อรับรู้มูลค่าในกระบวนการนี้มีส่วนสำคัญหลายส่วน เช่น การอัปเดตราคา Oracle สำหรับฟีดราคาแต่ละรายการ ฟีดราคาแต่ละรายการจำเป็นต้องได้รับราคาที่กระจายอยู่ในหลายๆ ที่ และสุดท้ายจะรวบรวมและประมวลผล และจำนวนเครื่อง Oracle ที่กระจัดกระจายสำหรับฟีดราคาแต่ละรายการจะแตกต่างกัน ตัวอย่างเช่น ในฟีดราคา ETH/USD มีฟีดออราเคิล 21 รายการในการอัปเดตข้อมูลที่ถูกต้องที่สุดได้ตลอดเวลา สัญญาอัจฉริยะที่ประมวลผลฟีดราคาจะต้องได้รับเครื่อง oracle อย่างน้อย 14 เครื่องจากทั้งหมด 21 เครื่องเพื่อให้ข้อมูลราคาก่อนที่จะอัปเดตข้อมูลได้อย่างราบรื่นการที่ข้อมูลในการดำเนินการข้างต้นถูกต้องและน่าเชื่อถือนั้นมีความสำคัญอย่างยิ่งหรือไม่ มิฉะนั้น จะเกิดเหตุการณ์การแย่งชิง Oracle เพื่อโจมตีราคาของแอปพลิเคชัน DeFiดังนั้น ต้องมีกฎบางอย่างสำหรับการจัดการข้อยกเว้น รวมถึง: การรับค่าเฉลี่ยของราคา การเริ่มการอัพเดตราคาใหม่หากค่าเบี่ยงเบนของราคามีมาก การระบุเวลาการรวมราคา เป็นต้น3. การไหลของข้อมูลขึ้นอยู่กับการได้มาซึ่งฮาร์ดแวร์
มีการใช้โมเดลของ Chainlink กันอย่างแพร่หลาย แต่ในโครงสร้างพื้นฐานส่วนใหญ่ข้างต้น หากเราพิจารณาอย่างถี่ถ้วน เราจะเห็นข้อบกพร่องบางอย่างได้อย่างชัดเจน เช่น ข้อมูลกลายเป็นความน่าเชื่อถือผ่านการประมวลผลแบบลูกโซ่ แต่กระบวนการของ "ข้อมูลบนลูกโซ่" นั้นไม่สามารถควบคุมได้มาก่อน ไปที่โซ่ ปัญหาที่ใหญ่กว่าคือ Chainlink จัดการกับข้อมูลธรรมดา ซึ่งก็คือข้อมูลที่มีไบต์ขนาดเล็กและการเผยแพร่ที่ชัดเจนดังนั้น แบบจำลองข้อมูลดังกล่าวสามารถทำการแปลงกระบวนการบางอย่างได้ และในที่สุดก็สร้างกระบวนการข้อมูลในลักษณะนี้:การเข้ารหัส Terminal (แหล่งสร้างข้อมูล)--การจัดเก็บข้อมูล--การจัดเก็บแฮชข้อมูลบนเชน--การไหลของข้อมูลบนเชนกระบวนการดังกล่าวสามารถอธิบายได้ว่าเป็นการไหลของข้อมูลโดยอิงจากการรวมกันของฮาร์ดแวร์ พื้นที่เก็บข้อมูลแบบกระจาย และเครือข่ายบล็อกเชน ในปัจจุบัน กระบวนการนี้เป็นที่รู้จักจากการประยุกต์ใช้แบบบูรณาการของเครือข่าย Internet of Things วันนี้ ตัวอย่างของเราคือ Jasmy ซึ่งเป็นอินเทอร์เน็ตของ เครือข่ายสิ่งต่าง ๆ ที่เกิดขึ้นในญี่ปุ่นเครือข่ายได้เสร็จสิ้นความร่วมมือกับ Toyota และ Witz ซึ่งเป็นผู้ให้บริการด้านการเดินทาง เพื่อประมวลผลข้อมูลเทอร์มินัลของรถยนต์อัจฉริยะผ่านโมเดลของแพลตฟอร์ม และเพื่อขุดคุณค่าของข้อมูลบนพื้นฐานของการหลีกเลี่ยงการปฏิบัติตามข้อมูลส่วนบุคคลมาวิเคราะห์กระบวนทัศน์การประมวลผลข้อมูลกัน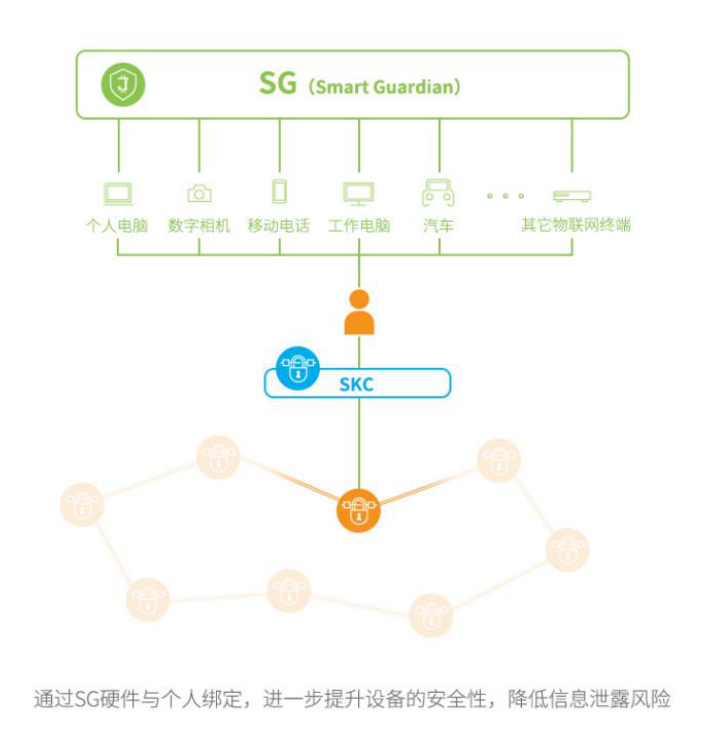 ตัวอย่างการจัดการเทอร์มินัลฮาร์ดแวร์ของ Jasmy
ตัวอย่างการจัดการเทอร์มินัลฮาร์ดแวร์ของ Jasmy
ในส่วนนี้ เนื่องจากต้องมีการจัดการอุปกรณ์ปลายทางจำนวนมาก จึงจำเป็นต้องเชื่อมต่ออุปกรณ์ IoT เพื่อสร้างแพลตฟอร์ม IoT ซึ่งมีหน้าที่หลักในการจัดการอุปกรณ์ขั้นตอนต่อไปเนื่องจากหมวดหมู่ข้อมูลมีความซับซ้อนและเข้ารหัสในฝั่งอุปกรณ์ เพื่อให้เรียกใช้ข้อมูลได้ จำเป็นต้องอัปโหลดข้อมูลไปยังสภาพแวดล้อมเครือข่ายแบบเปิดและตรวจสอบให้แน่ใจว่าสามารถตรวจสอบและดาวน์โหลดข้อมูลได้ตลอดเวลา แต่ความเป็นเจ้าของและสิทธิ์การใช้งานจำเป็นต้องมีการควบคุมดังนั้นในการประมวลผลข้อมูลจำนวนมากจะใช้พื้นที่เก็บข้อมูลแบบกระจายตัวอย่างที่สะดวกที่สุดคือโครงสร้างการจัดเก็บข้อมูลตาม IPFS4. กระบวนทัศน์การประมวลผลข้อมูลของการรวมเทคโนโลยี IoT
ความแตกต่างระหว่างกระบวนการนี้กับการใช้งานของ Oracle คือใช้เทอร์มินัล IoT เพื่อทำการเข้ารหัสด้านขอบและการเข้ารหัสปลายทางเพื่อให้การถ่ายโอนที่ตามมาเสร็จสมบูรณ์กระบวนการของ Jasmy มีดังนี้:1. แพลตฟอร์ม IoT มีหน้าที่จัดการอุปกรณ์ IoT ของเทอร์มินัล โดยใช้บริการ SKC ของ Jasmy และบริการ SG เพื่อให้เกิดการเข้ารหัสและการจัดการข้อมูลเทอร์มินัล2. ข้อมูลของเทอร์มินัลถูกจัดเก็บไว้ในตู้เก็บข้อมูลส่วนบุคคลของ Jasmy เพื่อการจัดเก็บแบบกระจาย เทคโนโลยี SKC และ SG สามารถค้นหาข้อมูลไปยัง ID ส่วนบุคคลหรือ ID อุปกรณ์ในระหว่างกระบวนการนี้3. แฮชไฟล์ของที่เก็บข้อมูลแบบกระจายถูกอัปโหลดไปยังเชน และ ID บนเชนนั้นเชื่อมโยงกับแฮชไฟล์4. แอปพลิเคชันธุรกรรมข้อมูลที่พัฒนาขึ้นบนเครือข่ายบล็อกเชนสามารถดำเนินการถ่ายโอนมูลค่าของข้อมูล ซึ่งก็คือการแลกเปลี่ยนความเป็นเจ้าของข้อมูลและสิทธิ์การใช้ข้อมูล5. ผู้ใช้ข้อมูลสามารถเรียกใช้ข้อมูลในตู้เก็บข้อมูลส่วนบุคคลแบบกระจายกระบวนการนี้ได้รับประโยชน์จากคุณสมบัติหลายประการของ Jasmy Jasmy มีเทคโนโลยีการเข้ารหัสของ Sony ผู้ผลิตฮาร์ดแวร์ของญี่ปุ่นในด้านฮาร์ดแวร์และความสามารถด้านห่วงโซ่อุปทานในด้าน Internet of Things ผู้ประกอบการบล็อกเชนทั่วไปรายอื่นไม่สามารถตระหนักถึงข้อดีของ Internet of Things . สำเร็จได้โดยง่าย. ตัวอย่างเช่น เทคโนโลยีหลักของ SKC คือ FeliCa ซึ่งเป็นเทคโนโลยีเข้ารหัสชิปแบบไม่สัมผัสซึ่งใช้ในญี่ปุ่นมาหลายปี เทคโนโลยีนี้ รับประกันความปลอดภัยสำหรับผลิตภัณฑ์ Sony นี่เป็นวิธีการคำนวณใหม่ที่เพิ่มเข้ามาในโครงสร้าง Jasmy อย่างแม่นยำนอกจากนี้ Jasmy สามารถร่วมมือกับผู้ผลิตฮาร์ดแวร์เพื่อเปิดตัวอุปกรณ์ที่มีความปลอดภัยของเทอร์มินัลและความสามารถในการประมวลผลเพื่อเข้าร่วมในเครือข่าย ตัวอย่างเช่น Jasmy ได้เปิดตัว Jasmy Secure PCโมเดลการรับรู้มูลค่าข้อมูลกำหนดโดย Jasmy
5. การไหลของข้อมูลขึ้นอยู่กับการคำนวณข้อมูลที่เชื่อถือได้
จากโมเดลการออกแบบของ Jasmy เราจะเห็นว่าโมเดลที่เรียบง่ายของ blockchain สามารถบรรลุผลลัพธ์ที่โดดเด่นได้หลังจากได้รับพรด้านเทคนิค หากรวมเทคโนโลยีมากขึ้น สิ่งที่สามารถทำได้สำหรับข้อมูล สิ่งที่ข้อมูลต้องการมากที่สุดคือการระบุแหล่งที่มาของความเป็นเจ้าของและโฟลว์ข้อมูลที่เชื่อถือได้ตามความเป็นเจ้าของข้อมูล นั่นคือ การตระหนักถึงความพร้อมใช้งานของข้อมูลและสิ่งที่มองไม่เห็น และชุดของข้อกำหนดเพื่อรับรองสิทธิ์และผลประโยชน์ของเจ้าของข้อมูลเราสามารถกำหนดกระบวนทัศน์นี้เป็นโฟลว์ข้อมูลตามแบบจำลองการคำนวณที่เชื่อถือได้ ซึ่งสามารถแบ่งออกเป็นพื้นที่จัดเก็บแบบกระจาย นิยามความเป็นเจ้าของข้อมูล และการดำเนินการที่เชื่อถือได้ เราใช้ PlatON เพื่ออธิบายส่วนนี้ตรรกะลำดับชั้นและการจัดสรรฟังก์ชันของ PlatON
ในรูปด้านบน เราจะเห็นว่าในเครือข่ายคอมพิวเตอร์ของเลเยอร์ 2 มีการจัดเก็บสถานะ ซึ่งเป็นโหนดพาหะของที่จัดเก็บข้อมูล และในโครงสร้างนี้ เป็นแอปพลิเคชันแบบบูรณาการของรูปแบบบัญชีและการจัดเก็บข้อมูลตามเอกสารทางเทคนิคของ PlatON ในการเข้าถึงสถานะ แม้ว่า PlatON จะยังคงใช้โมเดลบัญชีของ Ethereum เพื่อเก็บข้อมูล แต่ข้อมูลของสถานะนั้นไม่ได้ถูกจัดเก็บไว้ใน Patricia tree (โครงสร้างการจัดเก็บของ Ethereum) เนื่องจากข้อมูลจำนวนมาก มัน ถูกจัดเก็บแยกต่างหากใน SNAPDB (ฐานข้อมูล) อื่นที่ไม่ได้จัดเก็บสถานะในอดีตรูปแบบการจัดเก็บข้อมูลของ PlatON
ดังนั้นที่เก็บข้อมูลของ PlatON จึงแบ่งออกเป็นที่เก็บข้อมูลบัญชี (stateb) และที่เก็บข้อมูลสแน็ปช็อต (snapshotdb) เห็นได้ชัดว่าอันหนึ่งอยู่ในเลเยอร์ 1 ของเชนและอีกอันอยู่ในเลเยอร์ 2แต่ในเลเยอร์ 2 การประมวลผลเพิ่มเติมจะดำเนินการกับข้อมูลเพื่อให้มีลักษณะการประมวลผลข้อมูลอย่างเต็มที่ การประมวลผล ดำเนินการโดยอุปกรณ์และเทคโนโลยีการประมวลผลที่เชื่อถือได้ รวมถึง อัลกอริทึมการประมวลผลแบบตรวจสอบได้ (VC) ที่สามารถพิสูจน์การพิสูจน์ห่วงโซ่แบบไม่โต้ตอบได้ รูปแบบการขยายการประมวลผล การประมวลผลแบบหลายฝ่ายที่ปลอดภัย (MPC) รวมกับการใช้ข้อมูลลับร่วมกัน (SS) และการเข้ารหัสแบบโฮโมมอร์ฟิก (HE) เพื่อให้เกิดโปรโตคอลการประมวลผลความเป็นส่วนตัว ฯลฯนอกจากนี้ยังมีเครื่องเสมือน MPC เพื่อทำการคำนวณสัญญาอัจฉริยะที่น่าเชื่อถือ ซึ่งเป็นพื้นฐานสำหรับการดำเนินงานของสัญญาอัจฉริยะในเครือข่ายทั้งหมดด้วยการใช้เลเยอร์ 2 เลเยอร์เหล่านี้ เมื่อกระแสข้อมูลและแอปพลิเคชันข้อมูลได้รับการรับรู้ในที่สุด ข้อมูลดั้งเดิมจะไม่รั่วไหล และสามารถทำการคำนวณการคำนวณร่วมกันและการตรวจสอบผลลัพธ์ได้เป็นที่น่าสังเกตว่าอุปกรณ์คอมพิวเตอร์ที่เชื่อมต่อกับเลเยอร์ 2 จำเป็นต้องมีความสามารถในการคำนวณเฉพาะเพื่อให้สามารถดำเนินการตามข้อกำหนดของสถานการณ์แอปพลิเคชันบางอย่างได้ มันต้องการพลังการประมวลผลขั้นสูงและความสามารถที่น่าเชื่อถือ ดังนั้น PlatON จะช่วยให้อุปกรณ์คอมพิวเตอร์ประสิทธิภาพสูงที่พัฒนาขึ้น เช่น FPGA/ASIC สามารถเข้าถึงเครือข่ายเพื่อตอบสนองความต้องการของกระบวนการนี้ได้6. การวิเคราะห์การประยุกต์ใช้กระบวนทัศน์การประมวลผลข้อมูลสามแบบ
กระบวนทัศน์ทั้งสามข้างต้นเป็นวิธีการประมวลผลข้อมูลหลักที่ใช้บล็อกเชน แต่การประยุกต์ใช้กระบวนทัศน์ทั้งสามนี้เป็นอย่างไรการแสดงฟีดราคาโดยบางโหนดของ Chainlink
อย่างไรก็ตาม Oracle เป็นกระบวนทัศน์สำหรับข้อมูลความถี่สูงแบบธรรมดา โมเดลนี้เรียบง่ายและใช้งานง่าย แต่ไม่สามารถแก้ปัญหาดั้งเดิมของสังคมอินเทอร์เน็ตได้ตัวอย่างเช่น ในประเด็นความเป็นส่วนตัวของข้อมูล Oracle มีความน่าเชื่อถือมากกว่าในข้อมูลสาธารณะ แต่ไม่ดีในส่วนข้อมูลเฉพาะเลยการไหลของข้อมูลตาม Internet of Things เห็นได้ชัดว่าเป็นกระบวนทัศน์สำหรับชีวิตประจำวันและการประมวลผลข้อมูลเชิงพาณิชย์ ตัวอย่างเช่น แอปพลิเคชันของ Jasmy ได้กำหนดเป้าหมายข้อมูล Internet App ข้อมูลสำนักงานขององค์กรและข้อมูลของระบบนิเวศฮาร์ดแวร์บางอย่างแล้วนี่คือกระบวนทัศน์ที่ได้รับการออกแบบจากผู้ใช้ไปจนถึงแพลตฟอร์มและการไหลของระบบนิเวศทางธุรกิจ นี่เป็นโครงสร้างกระบวนทัศน์ที่ใช้กันอย่างแพร่หลายในปัจจุบันการประมวลผลที่เชื่อถือได้ขั้นสุดท้ายเป็นกระบวนทัศน์ที่มุ่งเน้นไปที่การทำการค้าของสินทรัพย์ข้อมูลเป็นหลัก ส่วนที่ยากที่สุดในการแก้ปัญหาคือข้อมูลที่มีอยู่และมองไม่เห็นในสถานการณ์ความร่วมมือของข้อมูลเชิงพาณิชย์ และน่าเชื่อถือสำหรับข้อมูลจำนวนมหาศาล ไม่เพียงแต่ต้องการเทคโนโลยีเท่านั้น แต่ยังต้องการการเน้นที่เท่าเทียมกันในเทคโนโลยีที่เชื่อถือได้ พลังการประมวลผล และพื้นที่เก็บข้อมูลดังนั้น กระบวนทัศน์ทั้งสามนี้จึงมีข้อดีและข้อเสียในตัวเอง และกระบวนทัศน์ของ Oracle นั้นเหมาะสมที่สุดสำหรับ DeFi ในฟิลด์ cryptocurrency ยกตัวอย่าง Jasmy มีขอบเขตแอปพลิเคชันที่กว้างที่สุด และสามารถตัดเข้าไปในช่องแอปพลิเคชันอื่นๆ นอกเหนือจากข้อมูลทางการเงินอย่างง่าย เทคโนโลยีค่อนข้างสมบูรณ์ แต่ยังต้องการคำจำกัดความและข้อมูลจำเพาะโดยละเอียดเพิ่มเติม สามารถพัฒนาไปสู่กระแสกระบวนทัศน์ที่สามได้7. เขียนในตอนท้าย
ปัญหาด้านข้อมูลนั้นรุนแรง แต่วิธีการแก้ปัญหาได้รับการเตรียมการอย่างเต็มที่ในแนวทางปฏิบัติของผู้ริเริ่ม เมื่อกระบวนการดำเนินการตามโครงการบล็อกเชนได้รับการเร่ง กระบวนทัศน์ทั้งสามข้างต้นจะสร้างมูลค่าทางธุรกิจมากขึ้นตัวอย่างเช่น Jasmy ใช้การออกแบบที่เป็นความลับและการจัดการข้อมูลเทอร์มินัลของข้อมูลองค์กร ซึ่งสามารถเพิ่มมูลค่าที่ใช้งานได้ของข้อมูล Edge และเพิ่มอัตราการใช้ข้อมูลขององค์กร PlatON ตระหนักถึงความพร้อมใช้งานและการมองไม่เห็นของข้อมูลซึ่งสามารถนำไปใช้ในด้านการประมวลผลความเป็นส่วนตัวของ AI เพื่อช่วยการประยุกต์ใช้ข้อมูลในกระบวนการการเรียนรู้ของเครื่อง กระบวนการนี้ถือเป็นความก้าวหน้าในหลายอุตสาหกรรม เช่น AI+การแพทย์, AI+การเดินทาง , แอปพลิเคชั่น AI+อินเทอร์เน็ต เป็นต้นไม่กี่ปีที่ผ่านมา เมื่อเราคร่ำครวญถึงการเกิดขึ้นของเทคโนโลยี AI เราจะพูดว่า "อนาคตมาถึงแล้ว" แต่ผู้เขียนเชื่อว่าตอนนี้หลังจากแก้ปัญหาข้อมูลแล้ว เราสามารถพูดได้ว่า "อนาคตมาแล้ว" ด้วยความมั่นใจ เพราะนี่คืออนาคตใหม่ที่ข้อมูลเป็นของเจ้าของ และเป็นอนาคตใหม่ที่ไม่สามารถแทนได้ด้วยยุคแห่งความสับสนวุ่นวายของข้อมูลบนอินเทอร์เน็ต 


