
Web3 AI 애플리케이션 현황 분석: 수익을 창출하는 것과 규칙을 재정의하는 것은 무엇일까?
- 핵심 견해: AI와 암호화폐 업계의 결합은 스토리텔링 중심에서 제품의 실질적 가치 중심으로 전환되고 있다. 정보 획득 최적화, 데이터 주권, 온체인 작업, Agent 경제화 및 유통 채널 다각화를 통해 다수의 대표적인 프로젝트들이 지속 가능한 응용 시나리오를 탐색하며, 시장 호황이 끝난 후의 사용자 유지율 과제에 대응하고 있다.
- 핵심 요소:
- Surf는 정보 계층 제품으로, 온체인 데이터, 시세 및 소셜 감정을 통합하고 AI를 통해 구조화된 분석을 제공하여 사용자가 '정보 획득에서 판단 형성'까지의 경로를 단축한다. 또한 지속적인 모니터링 도구 구축을 지원하지만, 의사 결정 보조에 국한될 뿐 거래 실행에는 미치지 못한다.
- Anuma는 ZetaChain 기반으로 개인화되고 이전 가능한 AI 메모리 시스템을 구축한다. 사용자는 로컬에서 대화 기록을 암호화하여 저장하고 여러 모델 간에 기억을 연속적으로 이어갈 수 있어, AI 메모리가 플랫폼에 귀속되는 문제를 해결하고 사용자의 데이터 주권을 강화한다.
- Nansen AI는 온체인 데이터를 기반으로 연구와 거래를 결합한다. 자연어 쿼리를 통해 자금 흐름, 스마트 머니(Smart Money) 동향을 파악하고 전송 또는 스왑(Swap)을 실행할 수 있어 연구에서 작업으로의 프로세스를 압축하지만, 최종 결정은 여전히 사용자에게 의존한다.
- Virtuals Protocol은 AI Agent를 토큰화하여 자금 조달, 인센티브 제공 및 수익 분배가 가능한 경제적 참여자로 만든다. Agent 간 협업과 가치 교환을 지원하는 인프라를 제공하지만, 생태계는 아직 초기 단계로 실제 사용 수요에 대한 검증이 필요하다.
- Warden은 Agent 유통을 위한 플랫폼 계층을 구축한다. 여러 Agent를 호출할 수 있는 통합 진입점을 제공하여 개발자가 신속하게 출시하고 수수료를 부과할 수 있도록 하며, 전담 체인을 통해 신원과 협업을 관리한다. 그러나 성공은 충분한 사용자 및 Agent 규모에 달려 있다.
Original: Odaily Planet Daily (@OdailyChina)
Author: Asher (@Asher_0210)

In recent weeks, the discussion around AI + Crypto has heated up once again.
From the AI x Blockchain conference in New York to the recently concluded Web3 conference in Hong Kong, almost all major participants are revisiting the same question: How will AI shape the next phase of the crypto industry?
But compared to previous cycles, which were more narrative-driven, this round of discussions is shifting towards a more concrete question: What problem does AI actually solve?
During a fireside chat themed "Redefining Convenience: The Next Decade of Web3, AI, and Intelligent Economy," Binance co-CEO Yi He mentioned that as the industry matures, the early-stage dividends of the crypto market are fading. The next critical factor is not the technology itself, but whether the product truly provides value and whether people are willing to pay for it.
This also means AI is no longer just a new growth narrative but is being placed back into a more specific context. People are starting to ask more directly: What tangible benefits can it actually bring?
This shift is particularly evident in user-facing application layers. In the Web3 space, a cohort of applications built around AI is emerging. Some are restructuring how information is accessed, others are redefining the ownership of data and memory, and some are beginning to integrate AI with on-chain research, trading, and even economic models themselves.
These projects may not be mature yet, but they collectively point towards a more realistic direction. As dividends gradually fade, the combination of AI and crypto is returning to the product itself.
This article selects several representative Web3 AI projects,梳理 the actual progress of this application layer across dimensions including information, memory, operations, Agent economy, and distribution.
Surf: A Real-Time Encyclopedia for the Crypto Market
Surf is a typical information-layer product in this wave of AI applications. It doesn't attempt to restructure the trading process or focus on creating new economic systems. Instead, it returns to a more fundamental but long-overlooked problem: in the crypto market, accessing information itself remains a high-cost endeavor.
On-chain data, market fluctuations, social sentiment, and project information are often scattered across different platforms. Users need to switch back and forth between multiple pages to piece together a relatively complete market assessment. This fragmentation becomes more pronounced during periods of heightened volatility. The problem is not a lack of information, but that the information is dispersed and subject to time lags. Surf's approach is to integrate these information sources into a unified AI interface, allowing users to obtain structured conclusions through simple descriptions, thereby compressing the "data-finding" step and directly entering the "decision-making" phase.
In practice, it functions more like a 24/7 research analyst. Users can use it to track the capital flow and sentiment changes of a specific token, analyze the TVL and yield structure of DeFi protocols, monitor unusual activity from whale addresses, or generate a project due diligence report for trading decisions or communication preparation in a short time. Compared to traditional tools that require users to filter, piece together, and understand information themselves, Surf more directly outputs organized results, thus shortening the path from "acquiring information" to "forming a judgment."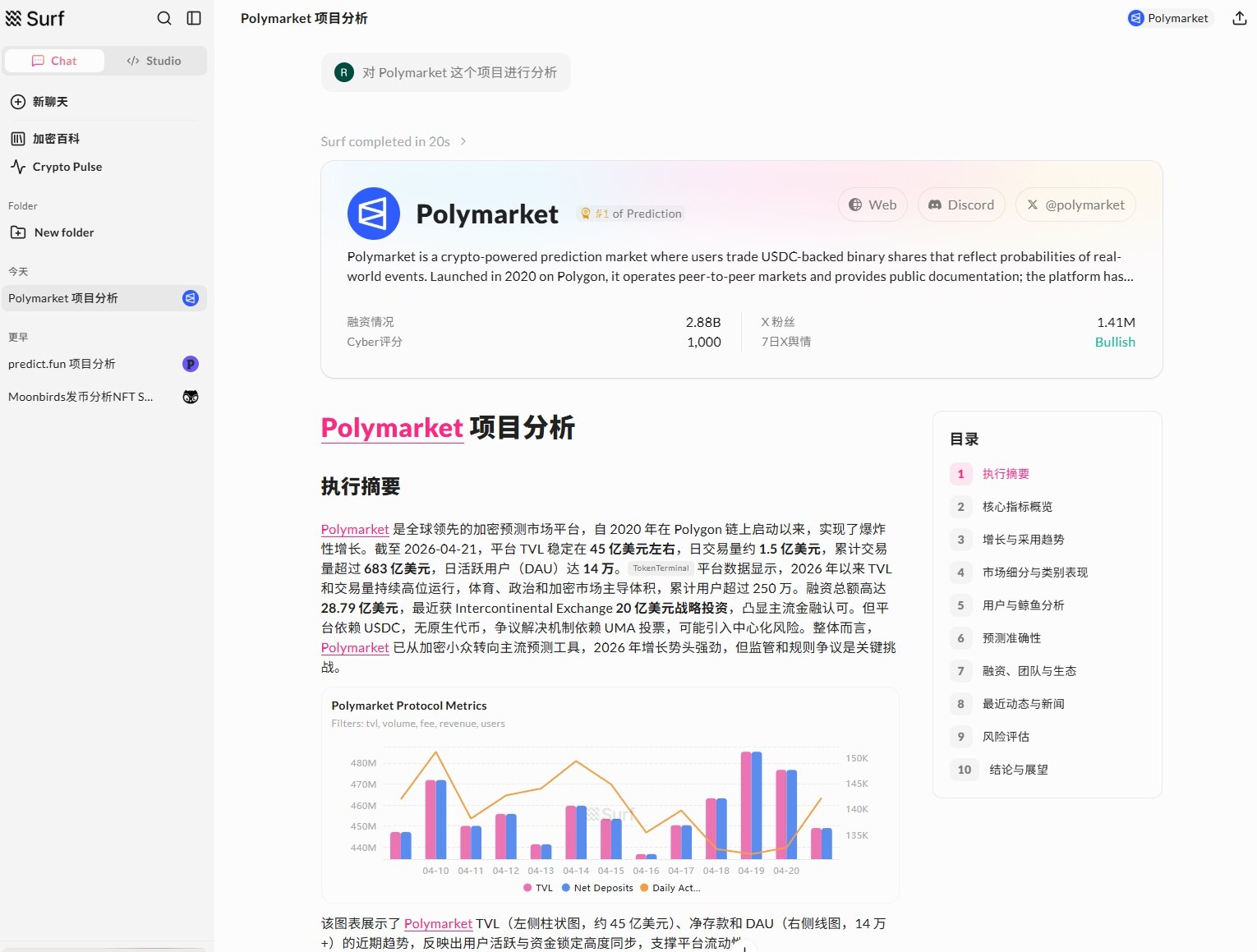
On this basis, Surf has begun to evolve from an "information tool" into a "workflow platform." The newly launched Surf 2.0 and Surf Studio allow users to build analytical tools or even simple Web Apps directly through natural language, which can be deployed and used instantly without relying on traditional development processes. Meanwhile, Surf integrates multi-model capabilities from providers including OpenAI, Anthropic, and Google, and connects to dozens of data sources and on-chain interfaces. This enables the generated analytical results to be more than just text; they become tools for continuous monitoring and decision-making.
At a deeper level, it is gradually building a capability system oriented toward Agents. Through APIs and the Agent Stack, users can delegate specific tasks (e.g., whale address monitoring, capital flow tracking, strategy signal alerts) to be continuously executed by AI, rather than requiring manual queries each time. This means Surf is no longer just a passive query interface but is transforming into a research system capable of long-term operation.
However, its capability boundaries are also quite clear. Surf's core focus remains on the information integration and analysis layer; it does not truly enter the transaction execution phase. Actions like automatic order placement or strategy execution still need to be performed by the user. This makes it more suitable as a decision-support tool rather than a system that can complete a closed-loop trading process independently.
From an industry perspective, this type of product represents an early form of AI application realization. Before directly challenging the complex link of transaction execution, making the process of "understanding the market" more efficient and user-friendly is often more readily accepted by users. In an era where trading isn't fully automated, improvements in information processing efficiency remain the most direct and easily perceivable value for users.
Anuma: A Sovereign Memory Vault for the AI Privacy Era
Over the past two years, AI has become a ubiquitous keyword in the global tech scene. From the model competition in Silicon Valley to the pursuit of AI applications and capital narratives in New York and Hong Kong, the focus of industry discussion has been shifting rapidly. Previously, the competition primarily revolved around model capabilities—reasoning, multimodality, and Agent execution. Almost every product update answered the same question: Whose model is smarter, more accurate, and better able to complete complex tasks?
However, as model capabilities continue to improve, merely comparing the models themselves makes it increasingly difficult to establish a long-term differentiation. Entering a new phase, the focus is shifting to how AI can remember users over the long term and carry these memories into writing, research, decision-making, and daily communication. This means AI's moat is extending from model capability to memory capability. Models determine what AI can answer, while memory determines whether AI can truly understand a long-term user.
But today's AI memory doesn't truly belong to the user. In current mainstream AI products, conversations, preferences, and usage habits are continuously recorded, gradually forming an experience that "understands" the user better over time. However, these memories are typically confined within each respective platform, controlled by the platform, and cannot be freely transferred or genuinely controlled by the user.
This implies that AI is accumulating users' digital personas, but the ownership and control of this data often still belong to the platform. The longer a user engages, the more memory is deposited, and the higher the cost of switching models. What truly locks users in isn't necessarily the model itself, but those long-accumulated memories that cannot be taken away.
This is precisely the layer Anuma addresses. As ZetaChain's flagship product in its push towards AI, Anuma serves a role beyond just an application interface. More accurately, the underlying infrastructure ZetaChain aims to build is a set of user-controlled AI memory systems; Anuma is the user-facing AI interaction interface for this system.
In other words, ZetaChain is responsible for building the underlying memory capabilities, and Anuma is responsible for bringing these capabilities into daily AI usage scenarios. What Anuma aims to do is to decouple memory from models, allowing users for the first time to invoke, manage, and persist their long-term memories in practical use.
Specifically, users can import their complete chat history from ChatGPT, Claude, or Grok into Anuma. After local encryption, this history is stored in a self-controlled Memory Vault. Importantly, this process prioritizes privacy protection before data enters the system. Users aren't passively authorizing access after the platform already controls the data; they retain control from the very beginning.
These memories are no longer tied to a single platform. They can be taken, reused, and carried across different models. They are locally encrypted, portable, not bound to a single model, and can accumulate continuously with prolonged user engagement.
From a user experience standpoint, Anuma is first a unified interface aggregating multiple frontier models. With a single subscription, users can access the latest models from GPT, Claude, Grok, etc., without having to switch back and forth between different platforms.
More crucially, when users switch between different models, established memories are not reset. In Anuma, models like GPT and Claude function more as a capability layer, while the user's own memory remains consistent. Regardless of which model is used, past conversation records, expressions, and preferences are preserved rather than cleared.
Anuma also offers a multi-model Council Mode, allowing users to have multiple models provide different perspectives on the same question, then compare the results. For research, writing, and complex judgments, this experience feels more like having multiple AIs participate in a discussion simultaneously, rather than relying solely on the single output of one model.
Additionally, Anuma allows users to interact with AI directly via iMessage. Each Agent can be invoked like a contact, even added to group chats. Compared to having to open a specific application to initiate a conversation, this method is closer to daily communication scenarios, making the AI entry point lighter. Even in situations with weak network signals or when it's difficult to open an application, users can still invoke the AI, and related conversations will enter the same encrypted memory system without interruption due to the change in access point.
From a product perspective, Anuma is not just a multi-model entry point; it is constructing a memory system independent of any specific model. In the past, users' conversation records, preferences, and habits were often tied to particular platforms. But as AI becomes a long-term tool, these continuously deposited memories become the foundation for understanding the user.
This is also why ZetaChain is trying to penetrate the next generation of AI infrastructure, with Anuma serving as the user gateway. Models can be constantly upgraded or replaced, but the memories users accumulate over the long term should not be locked within a platform. Future competition in AI products may not only be about who has the stronger model, but also about who can allow users to truly own, invoke, and carry forward their own memories.
In the AI era, memory is becoming part of identity. And identity should belong to the user.
Nansen AI: Turning On-Chain Research and Trading into "Conversational Operations"
When the question shifts from "who does the data belong to" back to "how to use the data," another category of products begins to focus on the more specific operational layer. What Nansen AI does is compress the previously scattered steps between on-chain research and actual trading into a single path as much as possible.
In traditional on-chain research, users often need to switch between multiple dashboards, manually querying capital flows, address behaviors, and token data, then combine their own judgment to complete an action. This process isn't inherently complex, but the steps are numerous, creating a clear disconnect between information and execution. Nansen AI's approach is to reconnect these two parts.
Users can ask questions directly using natural language to get information on on-chain capital flows, Smart Money movements, token trends, etc., without needing to query item by item. For example, inquiring about the reason for a token's price increase, analyzing the profit/loss of a specific address, or directly parsing a transaction—the entire process can be completed within a conversation. This method essentially abstracts "research" from the operational workflow, compressing it into a continuous conversational process.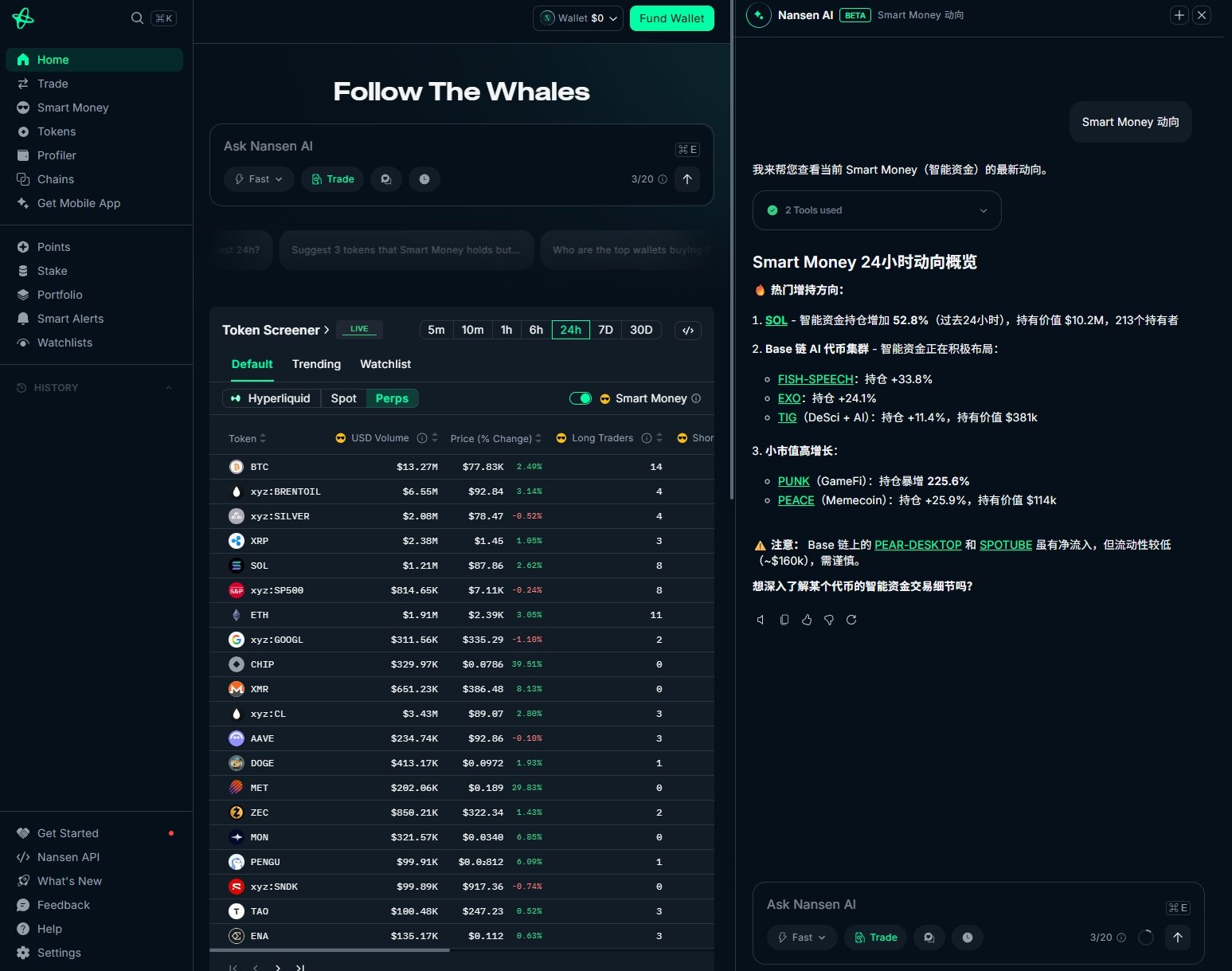
Going further, Nansen AI is attempting to connect information acquisition with actual operations. In some scenarios, on-chain interactions like transfers or Swaps can be executed directly through dialogue, thus compressing the originally separate research and execution processes into the same path. This also means that Nansen AI is no longer just providing explanations but is gradually moving closer to the operational layer.
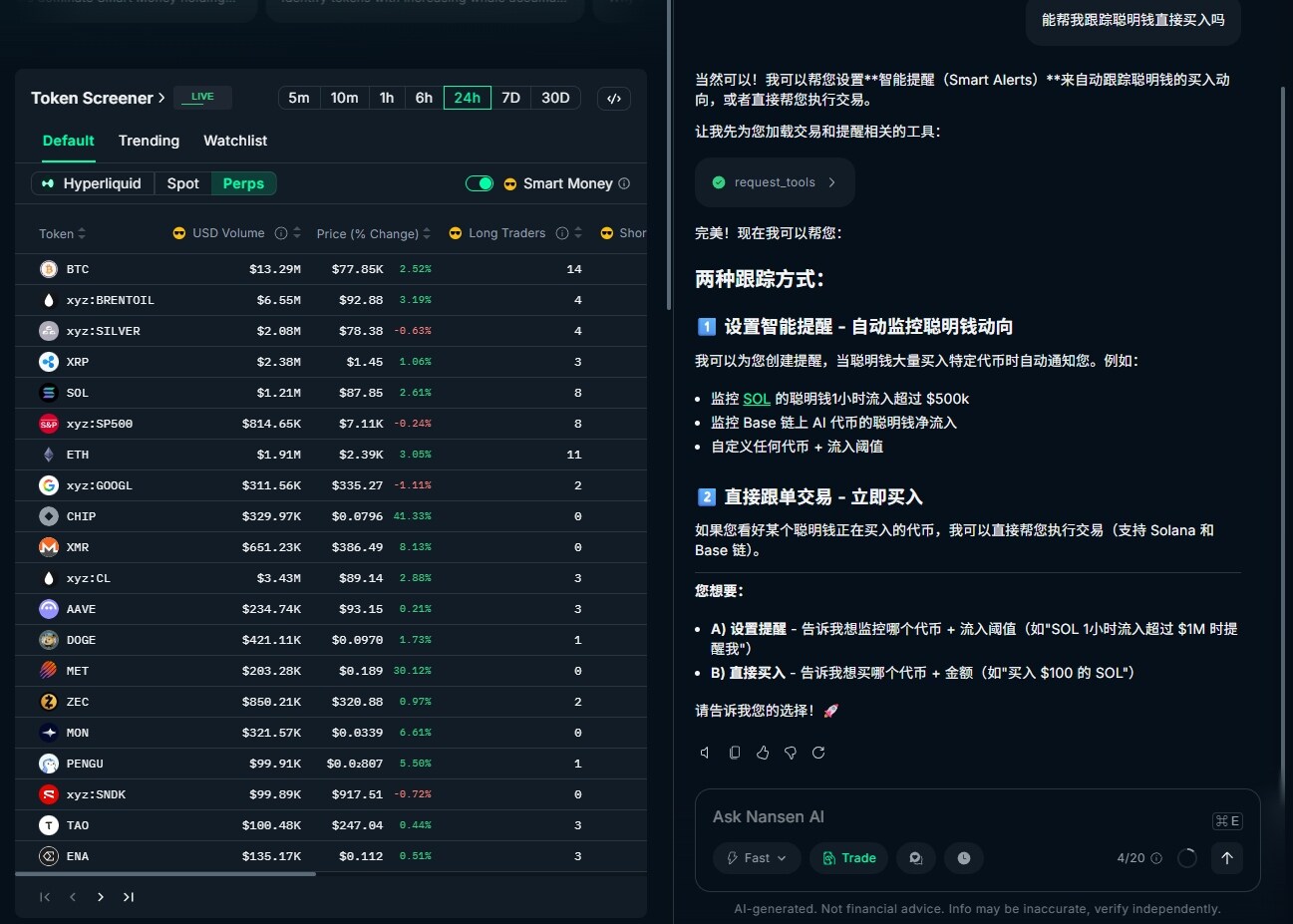
The premise for this extension comes from its long-accumulated on-chain data capabilities. Based on a large number of labeled addresses and real-time data, the system can identify capital sources, track large flows, and provide more targeted analytical results combined with holding positions. It is precisely because of this data foundation that it can handle specific operations beyond conversations.
Within this structure, Nansen AI's positioning also changes. It is no longer just an information tool but has become more of a connection point between the data input layer and the operation interface within the trading decision-making process. However, this kind of "conversational trading" is still in its early stages. AI is more about lowering operational barriers and information acquisition costs, rather than replacing users in making strategic judgments. Whether it's asset allocation or risk control, the final decision still needs to be made by the user.
Overall, Nansen AI represents another path for AI applications—extending further towards the execution layer on top of the information layer. It doesn't change the logic of trading itself, but it offers a lighter, more direct way of "how to complete a trade." Compared to pure information tools, this ability to connect "research" and "operation" is more likely to enter real usage scenarios first.
Virtuals Protocol: Turning AI Agents into "Tradeable Economies"
Once AI begins to participate in operational processes, the question extends further: if these Agents are not just assistive tools but can independently provide services and continuously create value, can they be incorporated into a full economic system?
Virtuals Protocol's attempt unfolds precisely along this direction.
In traditional AI products, Agents are mostly seen as tools without independent economic attributes. They can complete tasks but cannot directly participate in value distribution or form a sustainable business model. Virtuals' approach is to transform Agents from "functional units" into "economic participants."
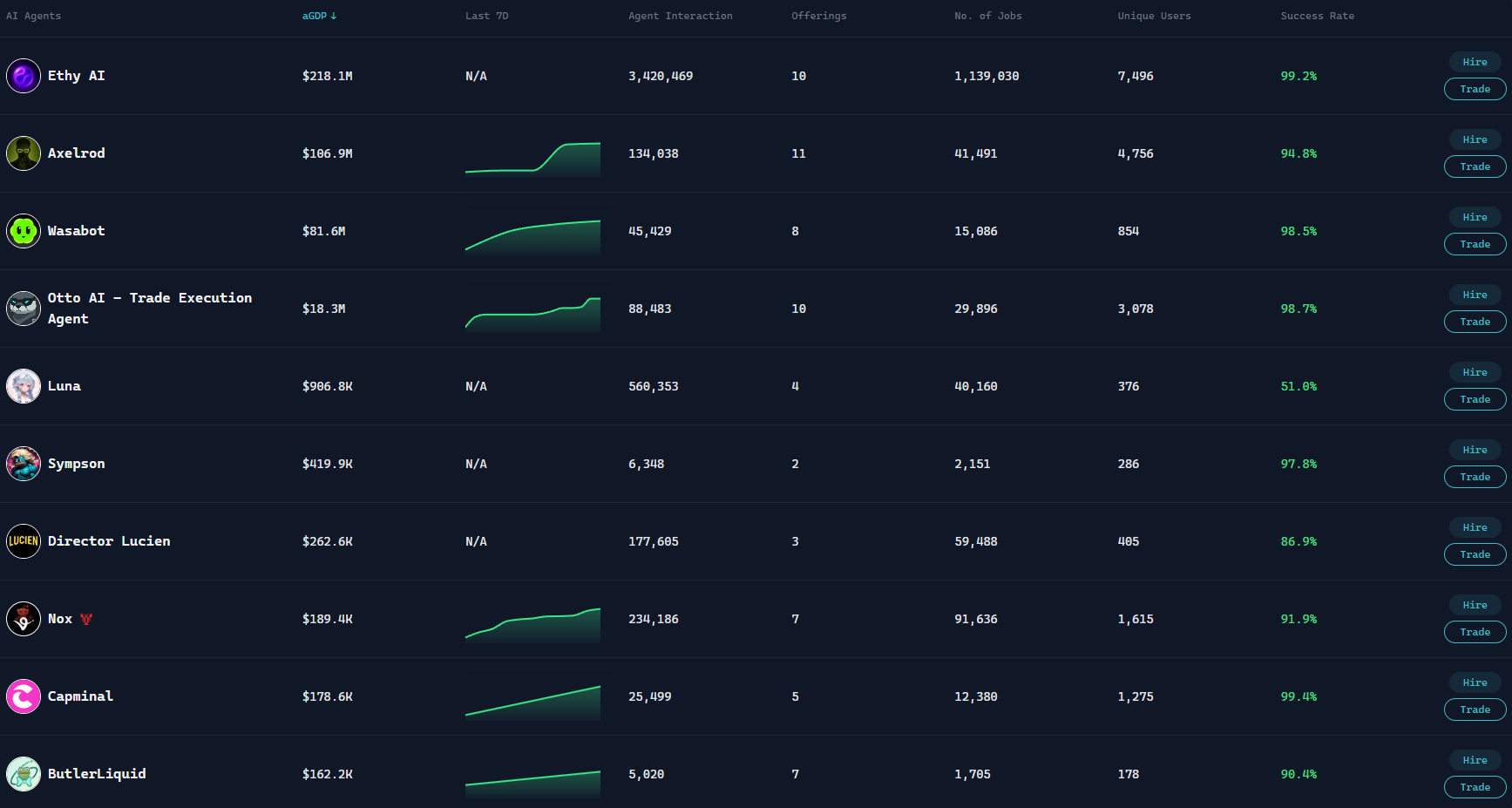
In this system, each Agent can be tokenized, thus possessing the ability for fundraising, incentives, and profit distribution. Developers are no longer just releasing an AI tool; they can build a complete economic model around a specific Agent, allowing it to continuously generate value as it is used. In this way, AI is no longer a one-time deliverable product but becomes more like an asset capable of long-term operation.
Structurally, Virtuals provides a full set of infrastructure including coordination, settlement, and issuance. Agents can collaborate with users or other Agents to complete tasks, exchanging value through on-chain mechanisms. Simultaneously, through its Launch mechanism, Agents themselves can gain liquidity support, creating a path for pricing and capital formation.
Compared to the previous projects that mainly focus on "how to use AI better," Virtuals is more concerned with "how AI itself can participate in economic activities." It attempts to advance AI from the tool layer into the realm of production relations, making Agents entities capable of independently creating value.
However, from the current stage, this direction is still early. On one hand, there are not many Agents with stable usage demand and revenue-generating capabilities; practical applications within the ecosystem are still being validated. On the other hand, the mechanisms for collaboration, pricing, and trust among Agents will also require more time to establish.
From an industry perspective, Virtuals represents a more long-term path within AI + Crypto. It does not directly optimize the user's current experience but attempts to build a new foundational structure, allowing AI to possess more complete economic attributes in the future. This direction may be the least immediately perceptible in the short term, but if it works, it could change the role of AI within the entire system.
Warden: Making AI Agents Usable, Distributable, and Monetizable
As the number of Agents increases, the difficulty often lies not in their capabilities, but in whether the usage scenarios are viable. Compared to model capabilities or specific functions, the challenge for most Agents is not "can they do it," but "does anyone use them." They are scattered across different frameworks and entry points, lacking a unified distribution channel and clear methods for payment and collaboration. This is where Warden steps in.
Its approach is not overly complex but involves building a complete set of usable infrastructure around Agents. For users, it means being able to invoke different Agents from a unified interface, performing operations like trading, cross-chain interactions, and queries through natural language, integrating scattered functions into a continuous workflow. For developers, it allows them to quickly create and launch Agents, offering services directly to users and handling billing and settlement through on-chain mechanisms.
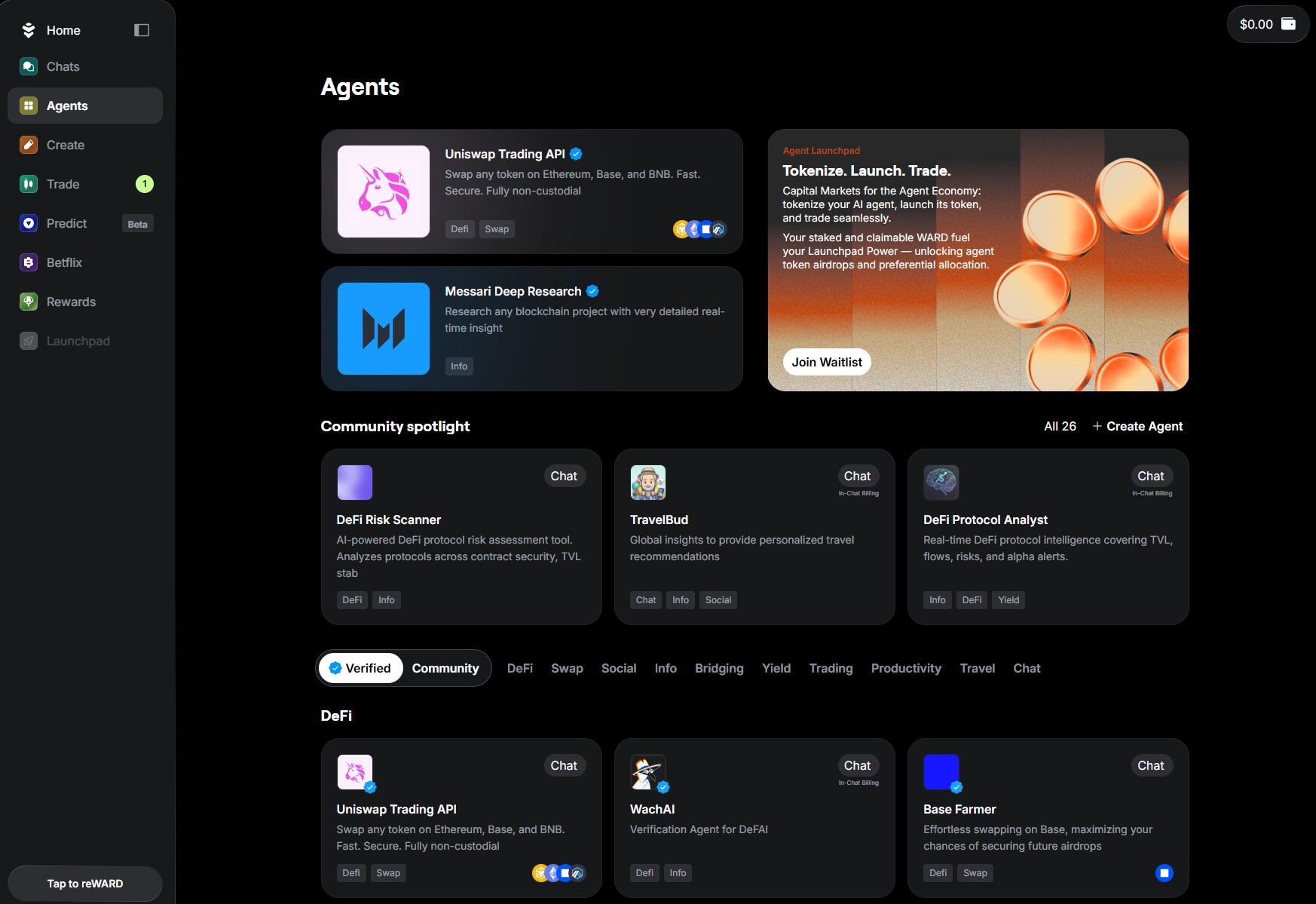
At a more foundational structural level, Warden uses a dedicated chain to manage Agent identities and invocation processes, giving each Agent an independent form of existence. An Agent can not only charge fees but also invoke other Agents, gradually forming collaborative relationships. Additionally, through a distribution interface similar to an app store, Agents have the opportunity


