
Polymarket의 가격 책정이 틀렸다? 200개의 AI 에이전트가 위기를 시뮬레이션하여 예상치 못한 답변 제시
- 핵심 관점: MiroFish를 사용하여 200개의 AI 에이전트가 호르무즈 해협 위기에 대해 집단 토론을 시뮬레이션한 실험에서, 에이전트들이 자유 토론에서 자발적으로 형성한 예측(평균 47.9%)과 Polymarket 시장 예측(31%) 사이에 상당한 차이가 있었으며, 자유 토론에서 비관적인 태도를 보인 소수의 전문가 에이전트들의 예측(평균 22%)이 시장 가격 책정에 가장 근접했다. 이는 공개적인 입장 표명과 실제 위험 판단 사이의 체계적 편향을 드러낸다.
- 핵심 요소:
- 실험은 정부, 미디어, 금융 기관 등 200개의 역할을 포함한 시뮬레이션 소셜 네트워크를 구축했으며, 5800자의 브리핑 지식 그래프를 기반으로 7일간의 시뮬레이션 기간 동안 1888개의 게시물과 대량의 상호 작용 행동을 생성했다.
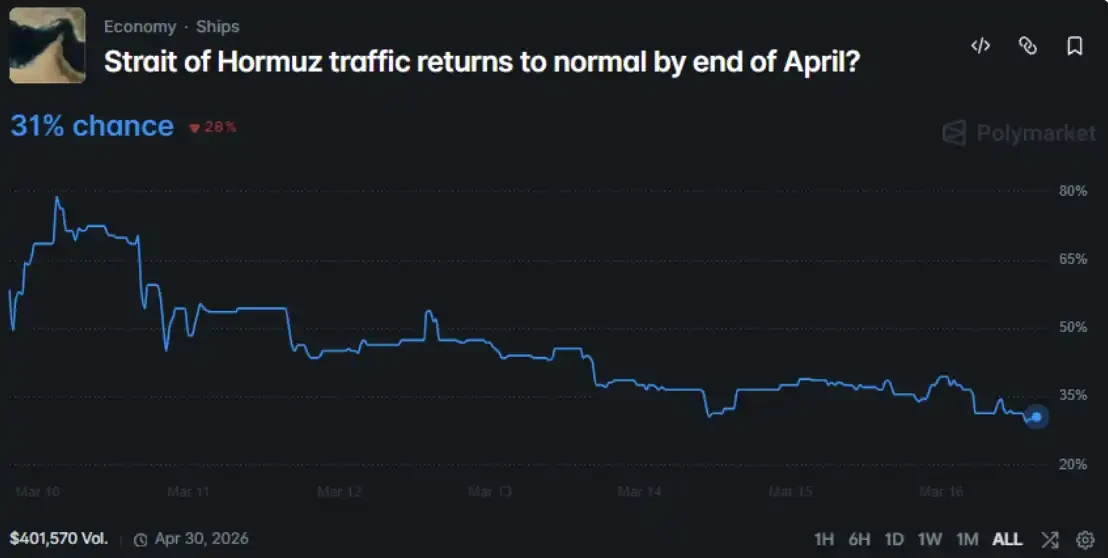
- 집단 자유 토론(유기적 결과)은 전체적으로 낙관적이었으며, 평균 예측 확률은 47.9%였던 반면, Polymarket 시장 가격 책정에 해당하는 확률은 31%로, 두 값은 16.9% 포인트 차이가 났다.
- 자유 토론에서, 비관적인 예측(≤30%)을 자발적으로 제시한 소수의 7개 전문가 에이전트들의 평균 예측값(22%)이 시장 결과에 가장 근접했으며, 오차는 10% 포인트 이내였다.
- 인터뷰 형식으로 에이전트에게 직접 질문했을 때, 거의 모든 에이전트가 더 낙관적이고 협력적인 예측(모든 범주의 평균값이 60% 이상)을 제시했으며, 이는 자유 토론에서의 모습과 뚜렷한 대비를 보였다.
- 실험은 현실 세계의 유사한 분열을 드러냈다: 공개 담론은 종종 안정적이고 낙관적인 쪽으로 흐르는 반면, 실제 위험 판단은 행동, 비공식적 표현 또는 시장 베팅 속에 숨겨져 있다.
원문 제목: how I run 200 AI agents on the hormuz crisis with Mirofish, and compare it to polymarket
원문 저자: The Smart Ape
원문 번역: Peggy, BlockBeats
편집자 주: AI가 여론장을 시뮬레이션하기 시작하면, 예측 자체도 은밀히 변화하고 있습니다.
이 글은 호르무즈 해협 정세를 둘러싼 한 번의 실험을 기록합니다: 저자는 MiroFish를 사용해 200개의 에이전트로 구성된 시뮬레이션 시스템을 구축하여, 정부, 미디어, 에너지 회사, 트레이더 및 일반인을 하나의 시뮬레이션된 소셜 네트워크에서 함께 생활하게 하고, 지속적인 상호작용, 논쟁 및 정보 전파 속에서 판단을 형성하도록 했으며, 이 집단 결과를 Polymarket의 시장 가격과 비교했습니다.
결과는 일치하지 않았습니다. 집단 토론은 전반적으로 낙관적이었던 반면, 시장은 현저히 더 비관적이었습니다; 자유 발언에서는 소수의 비관론자들이 오히려 실제 가격에 더 가까웠습니다; 그러나 일단 인터뷰 상황에 들어가면, 거의 모든 에이전트가 더 온건하고 협력적인 표현으로 수렴했습니다.
이런 분열은 낯설지 않습니다. 현실 세계에서 공개적인 입장 표명은 종종 안정적이고 낙관적인 쪽으로 향하는 반면, 진정한 위험 판단은 행동과 비공식적 표현 속에 숨겨져 있습니다. 다시 말해, 사람들이 '어떻게 말하는가'와 그들이 '어떻게 생각하는가', 그리고 돈으로 '어떻게 베팅하는가'는 종종 세 가지 다른 시스템입니다.
이런 구조 속에서 가장 가치 있는 신호는 종종 합의(컨센서스)에서 오는 것이 아니라, 소음 속에서 유별나 보이는 그 목소리들에서 옵니다.
이하 원문:
저는 MiroFish를 사용해 향후 몇 주간의 호르무즈 해협 정세를 시뮬레이션했습니다. 이 도구는 이런 유형의 문제를 처리하는 데 매우 뛰어난데, 그 이유는 고도로 복잡한 시나리오 추론을 할 수 있기 때문입니다: 동일 시스템 내에 다수의 참여 주체, 다양한 역할 및 각자의 인센티브 메커니즘을 도입하고, 이 에이전트들 사이에 끊임없는 게임과 논쟁을 벌이게 하여, 궁극적으로 합의에 가까운 결과를 점차 형성해 나갑니다.

다음은 제가 이 시뮬레이션을 실행한 구체적인 단계와, 제가 최종적으로 얻은 결과입니다. 누구나 재현할 수 있으며, 핵심은 어떤 단계를 따라야 하는지 아는 것뿐입니다.
먼저, MiroFish는 중국 연구팀의 오픈소스 프로젝트입니다. 여기에 일괄 문서를 입력하면, 먼저 지식 그래프를 구축한 후, 이 그래프를 기반으로 다양한 에이전트 페르소나를 생성하고, 이 에이전트들을 시뮬레이션된 트위터 환경에 투입합니다. 이 환경에서 그들은 게시물을 올리고, 리트윗하며 댓글을 달고, 좋아요를 누르고, 서로 논쟁합니다. 시뮬레이션이 끝난 후에는 각 에이전트를 개별적으로 인터뷰하여 그들의 입장과 추론 과정을 확인할 수도 있습니다.

위기 시나리오를 입력하면, 해당 사건을 둘러싼 논쟁을 생성합니다; 이 논쟁에서 예측 결과를 추출할 수 있습니다.
저는 이를 진행 중인 Polymarket 시장 질문에 맞춰봤습니다: 2026년 4월 말까지 호르무즈 해협의 해상 운송이 정상화될 것인가?
그래서 저는 이 모든 정보를 MiroFish에 입력하여 200개의 에이전트 역할을 생성했습니다—정부, 미디어, 군대, 에너지 회사, 트레이더, 그리고 일반 시민을 포함하여—그리고 그들을 시뮬레이션 환경에서 7개의 시뮬레이션 일 동안 논쟁하게 했습니다. 마지막으로, 그들이 출력한 결과를 시장 가격과 비교했습니다.
전체 구성은 다음과 같습니다:
· 모델: GPT-4o mini, 200개 에이전트 시나리오에서 비용 대비 효과 균형이 가장 좋음
· 메모리 시스템: Zep Cloud, 에이전트 메모리 및 지식 그래프 저장용
· 시뮬레이션 엔진: OASIS (Camel-AI가 제공하는 Twitter 클론 환경)
· 하드웨어: Mac mini M4 Pro, 24GB 메모리
· 실행 시간: 약 49분, 100라운드 시뮬레이션 완료
· 비용: API 호출 약 3~5달러
· 시드 자료: Wikipedia, CNBC, Al Jazeera, Forbes, Reuters에서 정리한 5800자 분량의 브리핑으로, 군사 타임라인, 봉쇄 상태, 유가, 경제적 손실, 외교적 노력 및 GCC 3.2조 달러 투자 관련 요소를 포함. 즉, 에이전트가 판단을 형성하는 데 필요한 핵심 정보가 모두 포함됨.
이 프로세스를 재현하는 방법 (단계별 설명)
만약 여러분도 직접 실행해보고 싶다면, 아래는 제가 실제로 수행한 전체 단계입니다. 전체 프로세스 구성에는 약 2시간이 소요되며, API 비용은 약 3~5달러입니다; 라운드 수나 에이전트 수를 늘리면 비용은 더 높아집니다.
준비해야 할 것들
· Python 3.12 (3.14 사용 금지, tiktoken이 이 버전에서 오류 발생)
· Node.js 22 이상 버전
· OpenAI API Key 하나 (GPT-4o mini가 충분히 저렴하여 이 시나리오에 적합)
· Zep Cloud 계정 하나 (소규모 시뮬레이션에는 무료 버전으로 충분)
· 메모리가 괜찮은 기계 하나. 저는 Mac mini M4 Pro, 24GB 메모리를 사용했지만, 16GB도 충분할 것임
첫 번째 단계: MiroFish 설치
그런 다음 .env 파일 구성
OPENAI_API_KEY=sk-your-key
OPENAI_BASE_URL=link
OPENAI_MODEL=gpt-4o-mini
ZEP_API_KEY=your-zep-key
두 번째 단계: 프로젝트 생성 및 시드 문서 업로드
시드 문서는 전체 프로세스에서 가장 중요한 부분으로, 에이전트가 현재 정세에 대해 어떤 정보를 알게 될지 결정합니다. 저는 당시 약 5800자 분량의 브리핑을 준비했으며, 내용은 군사 타임라인, 봉쇄 상태, 유가, 경제적 손실, 외교적 노력 및 GCC 투자 수준의 영향을 포함했고, 자료 출처는 Wikipedia, CNBC, Al Jazeera, Forbes 및 Reuters였습니다.
세 번째 단계: 온톨로지 생성
이 단계는 MiroFish에게 어떤 유형의 엔티티를 인식해야 하는지, 그리고 이 엔티티들 사이에 어떤 관계가 존재할 수 있는지 알려주는 것입니다.
저는 최종적으로 10가지 유형의 엔티티: 국가, 군대, 외교관, 비즈니스 엔티티, 미디어 기관, 경제 엔티티, 조직, 개인, 인프라, 예측 시장; 그리고 6가지 유형의 관계를 생성했습니다. 자동 생성 결과가 여러분의 시나리오에 잘 맞지 않는다면 수동으로 조정할 수도 있습니다.
네 번째 단계: 지식 그래프 구축
이 단계에서는 Zep Cloud가 사용됩니다. MiroFish는 시드 문서와 온톨로지를 함께 Zep에 전송하여, Zep이 엔티티 추출 및 그래프 구축을 담당합니다.
이 과정은 1~2분 정도 걸립니다. 저는 최종적으로 65개의 노드와 85개의 엣지를 포함한 그래프를 얻었으며, 여기에는 국가, 인물, 조직, 상품 등 요소들이 연결되어 있습니다.
다섯 번째 단계: 에이전트 생성
MiroFish는 지식 그래프를 기반으로 각 엔티티에 대해 완전한 페르소나 설정을 생성합니다. 여기에는 MBTI 성격 유형, 나이, 소속 국가, 게시 스타일, 감정 트리거 포인트, 금기 주제 및 기관 메모리 등이 포함됩니다.
저는 처음에 지식 그래프에서 43개의 코어 에이전트를 생성했습니다. 이후 시스템은 이 코어 역할을 원하는 총 수량으로 확장할 수 있습니다. 저는 최종적으로 총 에이전트 수를 200으로 설정하고, 암호화폐 트레이더, 항공사 조종사, 교수, 학생, 사회 활동가 등 더 다양화된 일반 시민 역할을 추가로 도입했습니다.
여섯 번째 단계: 시뮬레이션 환경 준비

이 단계에서는 에이전트의 행동 일정, 초기 시드 게시물 및 시간 매개변수를 포함한 완전한 시뮬레이션 구성을 생성합니다. MiroFish는 활성 피크 시간대, 수면 시간 및 다양한 유형의 에이전트별 게시 빈도와 같이 상대적으로 합리적인 기본 설정을 자동으로 선택합니다.
저의 구성은: 총 168시간(7일) 시뮬레이션, 100라운드(각 라운드는 1시간을 의미), Twitter 시나리오만 사용, 그리고 다양한 에이전트에 대해 각각의 활성 시간표를 설정했습니다.
일곱 번째 단계: 시뮬레이션 실행 시작.

그리고 기다립니다. 제 경우 GPT-4o mini로 200개 에이전트, 100라운드 시뮬레이션을 실행하는 데 약 49분이 걸렸습니다. API를 통해 진행 상황을 모니터링하거나 로그를 직접 확인할 수 있습니다.
전체 과정에서 에이전트는 자율적으로 실행됩니다: 그들은 타임라인을 관찰하고, 게시물을 올릴지, 리트윗하며 댓글을 달지, 리트윗할지, 좋아요를 누를지, 아니면 단순히 피드를 스크롤할지 결정하며, 이 과정에는 인위적 개입이 필요하지 않습니다.
여덟 번째 단계 (선택 사항): 에이전트 인터뷰
시뮬레이션이 끝나면 시스템은 명령 모드로 들어갑니다. 이때 특정 에이전트를 개별적으로 인터뷰하거나, 모든 에이전트를 한 번에 인터뷰할 수 있습니다:
분석
MiroFish는 먼저 시드 문서를 읽고 자동으로 온톨로지 구조(10가지 유형의 엔티티와 6가지 유형의 관계 포함)를 생성합니다; 그런 다음 이 정의를 기반으로 지식 그래프(65개의 노드와 85개의 엣지 포함)를 추출합니다. 이를 바탕으로 각 엔티티에 대해 MBTI 성격 유형, 나이, 소속 국가, 게시 스타일, 감정 트리거 포인트 및 제도적 메모리와 같은 요소를 포함한 완전한 페르소나 설정을 구축합니다.
최종적으로, 지식 그래프에서 43개의 코어 에이전트를 생성하고, 이를 기반으로 총 200개의 에이전트로 확장하여 더 다양화된 일반 시민 역할을 도입하여 전체 시뮬레이션의 다양성과 현실감을 강화했습니다.
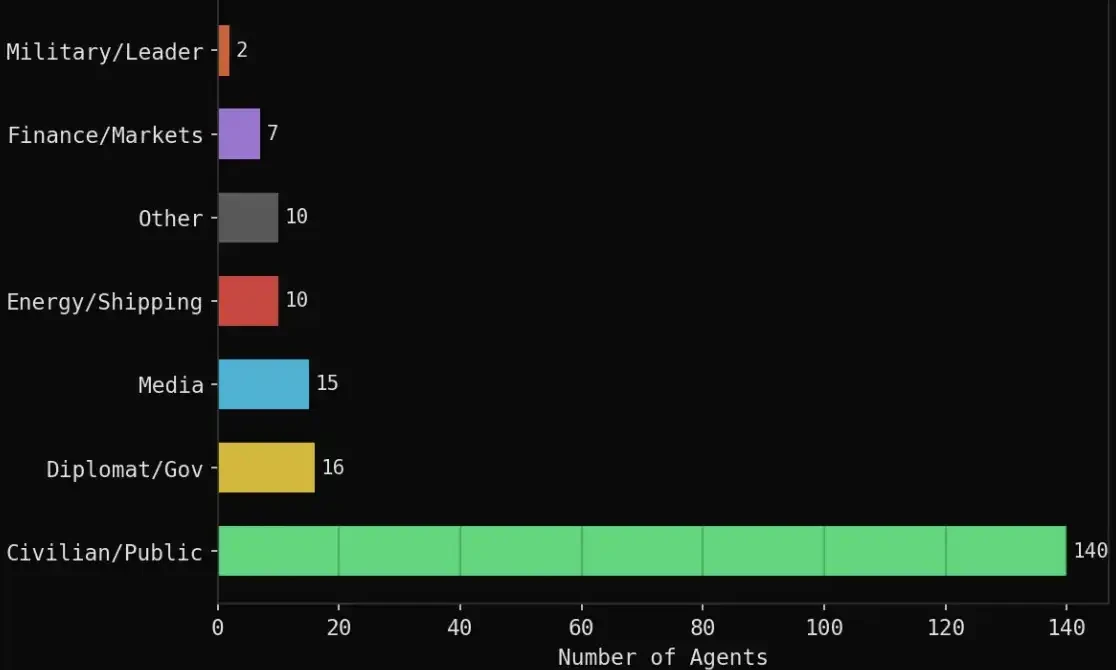
구체적인 구성은 다음과 같습니다:
· 140명의 일반 시민 에이전트: 암호화폐 트레이더, 항공 조종사, 공급망 관리자, 학생, 사회 활동가, 교수 등
· 16개의 외교/정부 역할: 이란 외무장관, 사우디아라비아 외무장관, 오만 외무장관, 바레인 총리, 중국 외무장관, EU, UN 등
· 15개의 미디어 기관: Reuters, CNN, Bloomberg, Al Jazeera, BBC, Fox, Wall Street Journal 등
· 10개의 에너지/해운 관련: OPEC, Platts, QatarEnergy, Aramco, Maersk 등
· 7개의 금융 기관: Polymarket, Kalshi, Goldman Sachs, JPMorgan Chase, Citadel, ADIA 등
· 2개의 군사/정치 역할: 트럼프, 이란 혁명수비대 사령관
7일(100라운드)의 시뮬레이션 과정에서 총 생성:
1,888개의 게시물
6,661개의 행동 트랙(모든 동작 기록)
1,611개의 인용 리트윗(에이전트 간 상호 응답 및 게임)
4,051번의 새로고침(피드 스크롤만)
311번의 아무것도 안 함(관망 선택)
208번의 좋아요, 207번의 리트윗
70개의 독창적 관점(새로운 독립적 입장 또는 판단)
전체적으로 이 시스템은 단순한 정보 생성을 보여주는 것이 아니라, 사회적 행동 시뮬레이션에 더 가깝습니다: 대부분의 시간 동안 에이전트는 관찰, 정보 소화 및 상호작용에 시간을 보내며, 지속적인 출력을 하지 않습니다. 이런 구조는 오히려 실제 여론장의 행동 분포—소량의 독창적 콘텐츠에 대량의 전달, 게임 및 감정적 피드백이 겹쳐진—에 더 가깝습니다.
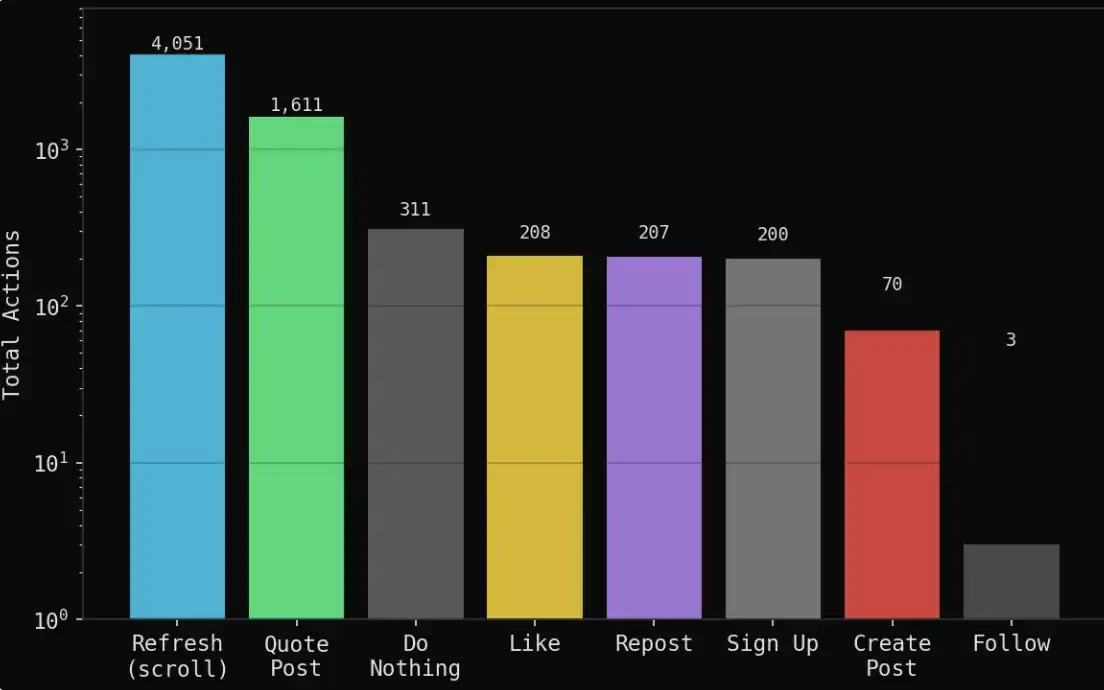
에이전트의 대부분 시간은 새로운 콘텐츠를 적극적으로 창조하기보다는 타인의 관점을 읽고 인용하는 데 소비됩니다.
전체 집


