
DeepSeekの10兆ドルへの道:オープンソースで兆ドル規模のハードウェアエコシステムを切り拓く
- コアポイント:DeepSeekの究極の目標は、短期的なアプリケーション層での収益化ではなく、一連の基盤アーキテクチャの革新(MoE、MLA、DSA、Engram等)を通じて、AIのトレーニングと推論のコスト構造を根本から変革し、10兆ドル規模の中国AIハードウェアエコシステムの形成を促進し、それによって1兆ドルの評価額を目指すことにある。
- 主要要素:
- DeepSeekの技術革新(MLA、DSA、mHC等)により、KV Cacheのサイズが大幅に圧縮され、HBMへの依存度が著しく低下し、長文脈推論のコストが大幅に削減された。
- KV CacheをSSDにオフロードし、LPDDRを使用したウェイトのストリーミング読み込みやEngramメモリストレージを活用することで、DeepSeekは中国における高性能GPU、HBM、先進パッケージングのボトルネックを効果的に緩和している。
- これらの革新は、中国の地場ハードウェアメーカー(長江ストレージ(NAND/SSD)、長鑫ストレージ(LPDDR))に直接的な恩恵をもたらし、多くの国産GPU/ASICチップメーカー(Moore Threads、M-Threadなど)に実現可能な市場空間を創出している。
- DeepSeekのTileLangへの投資は、一度コードを書けば複数プラットフォームで実行できるようにすることで、CUDAの堀を間接的に弱体化させ、中国AIハードウェアエコシステムの自立発展を促進することを目的としている。
- 大規模な強化学習(RSI)と自動研究を通じて、DeepSeekはより多くの選択可能なハードウェアとより低い計算コストを活用し、より野心的なトレーニングプロジェクトを推進し、AGIに備えることを目指している。
- DeepSeekはOpenAIモデルに倣い、中国のハードウェアメーカーと株式提携(ワラント)を結び、相手の成長を支援すると同時に、エコシステムの果実を通じて、サブスクリプション収入をはるかに超える大きなリターンを得る可能性がある。
原文タイトル:DeepSeekの10兆ドル戦略
原文著者:@bookwormengr
原文翻訳:Peggy、BlockBeats
編集者注:この1年間、DeepSeekに関する議論の大半は、モデルのパフォーマンス、オープンソース戦略、価格競争に集中してきました。しかし、もし「サブスクリプションを売るか」「マルチモーダルを持つか」「コーディングエージェントができるか」という観点だけでDeepSeekを理解しようとするなら、その真の狙いを見誤っているかもしれません。
この記事は、より大胆な仮説を提示しています。つまり、DeepSeekの目標は短期的にアプリケーション層で収益化することではなく、一連のアーキテクチャの根本的な革新を通じて、AIのトレーニングと推論のコスト構造を変革し、間接的に新しいハードウェアエコシステムを形成することだというのです。MoE、MLAからDSA、CSA、mHC、Engram、そしてDual PathやTileLangに至るまで、DeepSeekの技術ロードマップは常に一つの核心的な課題を中心に展開されてきました。すなわち、HBM、先端プロセス、パッケージング、CUDAエコシステムが制限されている状況下で、いかに少ないハイエンド演算リソースでより強力なモデルを実現するか、という課題です。
この記事で最も注目すべき点は、「DeepSeekがAPIやサブスクリプションで数億ドルを稼げるかどうか」ではなく、モデル能力、メモリシステム、そして国産ハードウェアエコシステムを結びつけようとしているかどうかです。KV Cacheの圧縮はHBMへの依存度を低減し、NANDやSSDは長時間のキャッシュを担い、LPDDRはウェイトのストリーミングロードやEngramストレージに利用され、TileLangはCUDAの堀を弱体化させようとしています。これらの革新が広がれば、恩恵を受けるのはDeepSeek自身だけでなく、ストレージ、ASIC、GPU、ネットワークチップ、そしてAIインフラストラクチャチェーン全体に及びます。
もちろん、「10兆ドルの産業エコシステム」や「1兆ドルの評価額」といった記事内の判断は、依然として推測の要素が強いものです。しかし、これはDeepSeekを理解するための重要な道筋を提供しています。すなわち、オープンソースは必ずしも商業化の放棄を意味せず、低価格も必ずしも市場への補助金提供だけを意味しないということです。DeepSeekにとって、本当のビジネスはアプリケーション層ではなく、より多くのハードウェアを利用可能にし、より低コストなAI供給を可能にすることにあるかもしれません。言い換えれば、彼らが売っているのはモデルそのものではなく、次世代AIインフラストラクチャの実現可能性なのです。
以下は原文です:

DeepSeekは一体どうやって収益を上げ、しかも莫大な利益を生み出すのでしょうか?考えたことはありますか?
GLM、MoonShot、MiniMaxのように、競争力のあるプログラミングサブスクリプションサービスを立ち上げているわけではありません。また、マルチモーダルモデル、音声モデル、動画モデルも持っていません。今のところ、モデル呼び出し、ツール連携、タスク実行のための外部実行フレームワークである「ハーネス」すら持っていません(ただし、最近になってこのシステムを構築するための関連ポジションの採用を開始しました)。
同時に、DeepSeekは長期間にわたりオープンソースの側に立つことを固く決意しているように見え、自らの「秘訣」を喜んで公開することさえあります。これは狂気の沙汰ではないでしょうか?単に無駄金を燃やしているだけではないのでしょうか?100億ドルの投資を検討している投資家たちは、下水道に金を投げ込んでいるのでしょうか?
個人的には、答えは全く逆だと考えています。
これから、DeepSeekがこれまでに行ってきたことに基づいて、いくつかの観察結果と、同社が従っていると思われる戦略を分析します。DeepSeekのCEOである梁文鋒氏の目標は、おそらく目先のモデル競争にとどまりません。彼が狙っているのは、もっと大きな賞品かもしれません。DeepSeekは1兆ドルの評価額を獲得し、同時に10兆ドル規模の新産業を形成するチャンスを持っているのです。

TechInAsiaによるDeepSeekの最新資金調達ラウンドに関する報道
DeepSeekの「英雄の旅」を再訪する
DeepSeekは常に逆風の中を進んできました。少しだけ強力なモデルを次々とリリースし、それをプログラミングサブスクリプションのようなすぐに収益化できるアプリケーションに急いでパッケージ化する道を選ばなかったのです。2025年1月27日、私はDeepSeekの「英雄の旅」について、広く拡散されたツイートを投稿しました。今、その物語はさらに興味深いものになっています。
他者が高密度モデルの構築を試みている一方で、DeepSeekはトレーニングがより困難なMoE(Mixture of Experts)モデルを選択しました。
彼らは「第一原理」のアプローチを採用し、当時主流であったが実装コストの高かったPPO強化学習アルゴリズムに代わる、新しいGRPOアルゴリズムを発明しました。
彼らは、検証可能な報酬に基づく強化学習(RLVR)が、モデルの推論能力を向上させるための重要な戦略であることを発見しました。
また、「マルチトークン予測」を通じて、シンプルな投機的復号戦略を提案すると同時に、トレーニング信号の密度を高めました。
限られたGPUリソースの利用効率を高めるために、「ゼロバブル」パイプラインを完成させました。
誰もがMoEモデルをより簡単にデプロイできるようにするため、エキスパードローバランサーを公開しました。特に「ワイドエキスパート並列」戦略により、モデルはより大きなバッチでサービスを提供できるようになり、推論コストを大幅に削減しました。
彼らは、KV Cacheの必要性を減らし、コンテキスト長の増加に伴う計算需要を可能な限り一定に保つために、MLA、DSA、CSA、HCAなどのメカニズムを発明しました。
彼らは、メモリと計算効率を交換するEngramを発明しました。
また、モデル規模が拡大しても安定したトレーニングを可能にするmHCも発明しました。このような例は他にもたくさんあります。
「英雄の旅」という最も普遍的な物語構造において、英雄は最初から自分の旅がどこへ向かうのかを決めているわけではありません。彼は学びながら、徐々に自分自身の真に偉大な使命を発見し、数多くの障害を乗り越えてそれを成し遂げます。彼には多くの疑問を呈する者たちが現れますが、彼はそれらを無視することを選びます。また、悪意のある行動者にも遭遇します。彼には明らかな欠点や弱点がありますが、最終的にはそれらを克服し、使命を果たします。彼は乗り越えられそうにない挑戦に直面しますが、同盟を結ぶ方法を見つけ、限られた貴重なリソースを賢く使う方法を学びます。観客が英雄を応援したくなるのは、まさにこの点です。これこそが、DeepSeekが支持者、世界的な尊敬、そして反対者を獲得した理由でもあります。
これから詳しく説明するように、DeepSeekはすでにこの道を長く歩み、徐々に自らの究極の運命を発見しつつあります。その目標はプログラミングサブスクリプションを販売することではなく、中国のAIハードウェアエコシステムを10兆ドル規模に押し上げ、自らは1兆ドルの評価額を実現することです。この過程で、西側のハードウェアエコシステムにおける多くの新規参入者にも機会を創造することになるでしょう。

まずは興味深いKV Cache計算から
@SemiAnalysis_ による、この非常にタイムリーなツイートをご覧ください:
DeepSeekは、この問題を誰よりもすでに解決しています!
では、いくつか興味深いKV Cacheの計算をしてみましょう。数学が苦手でも心配はいりません。最近公開されたKV Cache計算機を使って、DeepSeek V4 ProがどれだけKV Cacheを節約できるか、最新のGLMやQwenモデルと比較してみます。
ここでは、コンテキスト長100万、KV精度8ビット、インデクサー精度16ビットを仮定して計算します。この計算機はこちらから自分で試すこともできます:https://kvcache.ai/tools/kv-cache-calculator/
自分で計算機を試してみてください!
コンテキスト長100万の場合:
・DeepSeek V4: わずか5.48GBのHBM
・GLM-5: 60GBのHBM
・Qwen3-235B-A22B: 最大89GBのHBM
注意点:
・DeepSeekは1.6兆パラメータのモデル
・GLM-5は約7000億パラメータで、すでにDeepSeekのMLAとDSAを採用しているが、最新の圧縮アテンションメカニズムは未採用
・Qwen3-235B-A22Bは約2350億パラメータで、GQAアテンションメカニズムを採用
DeepSeekは、メモリプレッシャーを軽減する上で、基礎的な貢献をしてきました。この種の革新が広く採用されれば、長期間にわたるエージェントの実行コストを大幅に削減し、新たなアプリケーションの波を解き放つことになるでしょう。
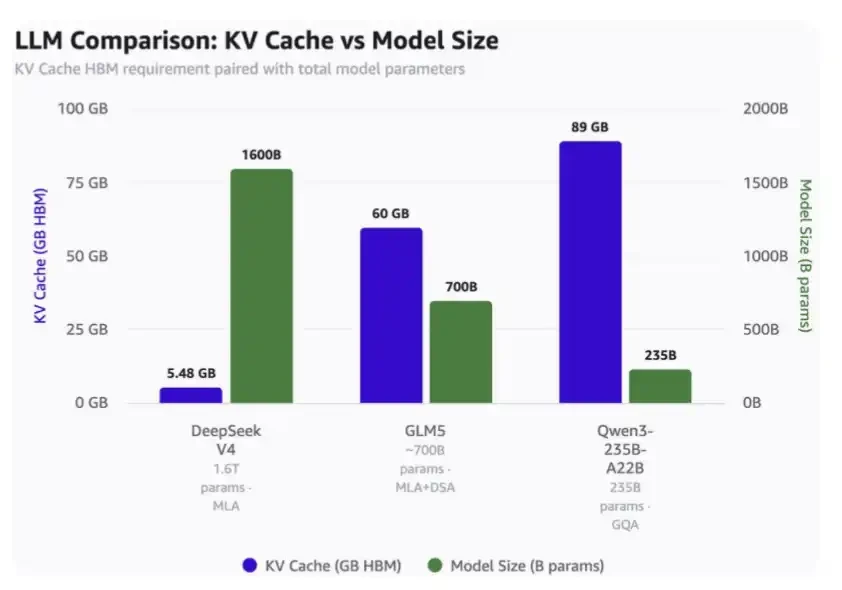
100万トークンコンテキストとモデル規模におけるKV Cache使用量の比較
「狂気」の背後にある方法論
KV Cacheのサイズがこれほど小さく、しかもモデルの品質を犠牲にしないのは、DeepSeekが長時間のキャッシュを非常に低価格で提供できる理由です。その価格はSonnet 4.6のキャッシュヒット価格の3%未満であり、DeepSeekはキャッシュを数時間保持することができます。
長時間のタスクにとって、KV Cacheが小さいということは、それをSSDに経済的にオフロードし、必要に応じて再ロードできることを意味します。これにより、HBMへの依存度を減らすことができます。中国のAIハードウェア産業の観点から見ると、HBMは供給が逼迫しているだけでなく、製造が最も困難なメモリタイプの一つでもあります。
さらにDeepSeekは、Dual Pathに関する論文で説明されているように、SSDからKV Cacheをより高速にロードする技術も開発しています。
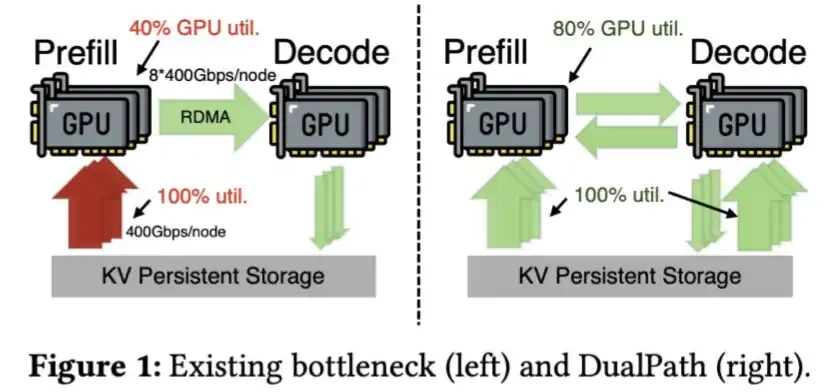
DeepSeek V4によるKV Cacheの圧縮は非常に大きいため、このステップ自体がもはや不要になるかもしれません。
では、KV Cache圧縮の最も直接的な受益者は誰でしょう?
誰が大規模にSSDを供給しているのでしょうか?YMTC(長江存儲)が3D NANDの巨人に成長しつつあることを忘れてはいけません。NANDはDeepSeekがKVを再計算するのを避けるのに役立ちます。逆に、DeepSeekはNANDとSSDに巨大な市場を創出しています。これはYMTCだけでなく、他の関連企業にも利益をもたらします。

しかし、これはNANDとSSDだけの話ではありません。
LPDDRメモリにも大きな可能性があります。これはモデルの重みを格納する場所として機能し、必要に応じてこれらの重みをHBMにストリーミングすることで、HBMへの需要圧力を軽減できます。SGLangチームはこの方式を紹介する優れたブログを公開しています。下の図は、この方式の仕組みを示しています。
DeepSeekがこの方式のために特別に設計をしたわけではありませんが、そのMoEアーキテクチャ、多数のエキスパートモデル、そして4ビットの重みという特性が、この方式の導入を容易にしています。
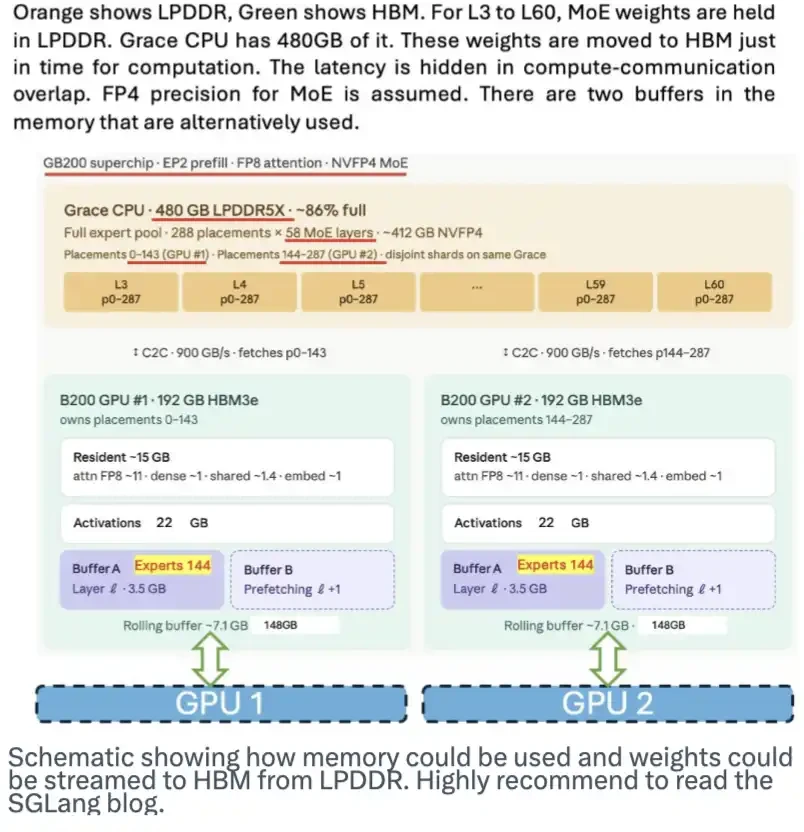
この図は、メモリがどのように使用されるか、そしてモデルの重みがどのようにLPDDRからHBMにストリーミングされるかを示しています。SGLangのブログをぜひお読みになることをお勧めします。
この革新が、非常にコンパクトでロスレスのKV Cacheと組み合わされば、HBMへの要求を大幅に削減できます。
では、中国でLPDDRを生産しているのはどこでしょうか?答えはCXMT、すなわち長鑫存儲です。彼らはLPDDRの速度で約半世代、密度で1世代遅れているだけで、その差はそれほど大きくありません。
豊富なNANDに加えて、中国のAIエコシステムは、近い将来、豊富なLPDDRの供給も得られるでしょう。これで演算能力のプレッシャーは軽減されるのでしょうか?答えは「イエス」です。さらに読み進めてください。

メモリをインテリジェントに使うことで、GPU / ASICの負荷も軽減できる
NANDをKV Cacheに使用するメリットは理解しやすいでしょう。KV Cacheをより長く保持し、HBMへの負荷を減らし、KV Cacheの再計算を避けることで、GPUやASICの計算負荷を軽減します。
では、LPDDRも同様の方法で機能するでしょうか?「オンデマンドで即座に」重みをHBMにストリーミングするためのストレージ場所としての役割に加えて、さらに計算負荷を軽減できるでしょうか?
答えは「イエス」です。


