
黄仁勲が指名?SN3は1ヶ月で5倍上昇、いったい何をしたのか?
- 核心的な見解:BittensorサブネットSN3(Templar)は、許可不要の分散型コンピューティングネットワークを通じて720億パラメータの大規模モデルCovenant-72Bのトレーニングに成功し、その性能はMetaの2023年のLLaMA-2-70Bと同等であり、これは分散型AIトレーニング分野における重要な技術的ブレークスルーと見なされ、関連するトークンに対する市場の強い関心を引き起こした。
- 重要な要素:
- 技術的ブレークスルー:Covenant-72BはMMLUベンチマークテストで67.1点を獲得し、分散型トレーニング分野で際立ったパフォーマンスを示し、大規模モデルの分散トレーニングの実現可能性を証明した。
- 許可不要の参加:70以上の独立ノードがホワイトリスト審査なしでトレーニングに参加し、真の分散型参加を実現した。
- コアメカニズム:SparseLoCo技術による効率的な勾配圧縮(圧縮率146倍超)、およびGauntletメカニズムによるノード貢献品質の検証を通じて、分散トレーニングの効率性とインセンティブの問題を解決した。
- 市場の反応:SN3トークンは過去1ヶ月で440%以上上昇し、そのナラティブ価値はBittensorメインネットトークンTAOに伝播し、その価格の急速な上昇を後押しした。
- 業界の意義:この成果はAIトレーニングのリソース独占構造に挑戦し、分散型AI開発の政治的・経済的潜在力を示したが、モデル性能は現在の最先端モデルとの間に依然として世代差がある。
- 潜在的な問題:モデルベンチマーク比較の時効性、高品質データの取得ボトルネック、許可不要参加によるセキュリティとコンプライアンスのリスク、およびトークン価値とモデル出力の持続性との強い関連リスクを含む。
原文著者:KarenZ、Foresight News
2026年3月20日、All-Inベンチャーキャピタルポッドキャストで、一風変わった会話が繰り広げられた。
ベンチャーキャピタルの大物、Chamath PalihapitiyaがNVIDIA CEOのJensen Huangに話を振り、Bittensor上にあるプロジェクトが「非常に驚くべき技術的成果を達成した」と述べた。それは分散コンピューティングリソースを用いてインターネット上で大規模言語モデルをトレーニングし、そのプロセスは完全に分散化されており、中央集権的なデータセンターは一切関与していないというものだった。
Jensen Huangはこの話題を避けなかった。彼はこの取り組みを「現代版のFolding@home」に例えた。Folding@homeは2000年代に一般ユーザーの遊休コンピューティングリソースを活用してタンパク質折り畳み問題の解決に取り組んだ分散プロジェクトである。
そのわずか4日前、3月16日には、Anthropicの共同創業者であるJack ClarkがAI研究進捗レポートを発表し、その中でこのブレークスルーについて多くの紙面を割いて紹介・引用した。BittensorエコシステムのサブネットであるTemplar(SN3)が720億パラメータの大規模モデル(Covenant 72B)の分散トレーニングを完了し、そのモデル性能はMetaが2023年にリリースしたLLaMA-2に匹敵するというものだ。
Jack Clarkはこの章に「分散トレーニングによるAI政治経済学への挑戦」と名付け、分析の中で、これは継続的に追跡する価値のある技術であると強調した。彼は、デバイス上のAIが分散トレーニングによって生成されたモデルを広く採用し、クラウド上のAIは引き続き独自の大規模モデルを実行するという未来を想像できると述べた。
市場の反応はやや遅れたが非常に激しいものだった。SN3は過去1か月で440%以上、過去2週間で340%以上上昇し、時価総額は1億3000万ドルに達した。サブネットのナラティブの爆発は、直接的にTAOの買い圧力に転嫁される。その結果、TAOも急騰し、一時377ドルに達し、過去1か月で2倍となり、完全希薄化時価総額(FDV)は約750億ドルとなった。
疑問が生じる。SN3は実際に何を成し遂げたのか?なぜスポットライトを浴びることになったのか?分散トレーニングと分散型AIの価値ナラティブは今後どのように展開していくのか?
あの72Bモデル
この質問に答えるには、まずSN3が提出した成績表をしっかりと見る必要がある。
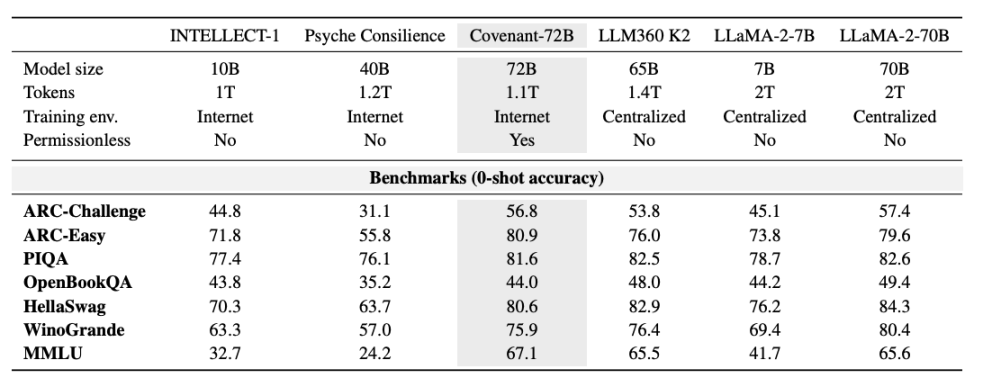
2026年3月10日、Covenant AIチームはarXivに技術報告を発表し、Covenant-72Bのトレーニング完了を正式に発表した。これは720億パラメータの大規模言語モデルであり、70以上の独立したノード(ピア)(各ラウンドで約20ノードが同期、各ノードは8枚のB200を搭載)が、約1.1兆トークンのコーパスを用いて720億パラメータモデルの事前トレーニングを完了した。
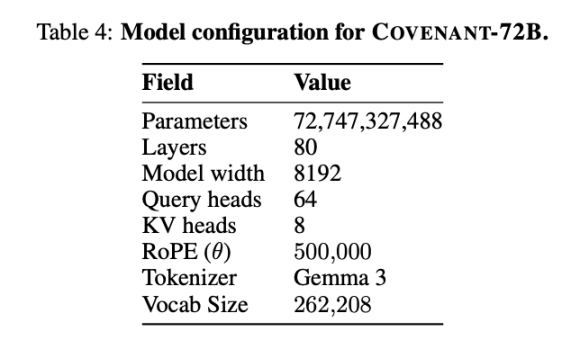
Templarはベンチマークテストに関するいくつかのデータを示している。もちろん、比較対象のLLaMA-2-70BはMetaが2023年にリリースした大規模モデルである。Anthropic共同創業者Jack Clarkが述べたように、Covenant-72Bは2026年の時点ではやや時代遅れかもしれない。Covenant-72BのMMLUスコア67.1は、Metaが2023年にリリースしたLLaMA-2-70B(65.6点)とほぼ同等である。
一方、2026年の最先端モデル——GPTシリーズ、Claude、Gemomiのいずれであれ——はすでに数十万枚のGPUを用いて1000億をはるかに超えるパラメータでトレーニングを完了しており、推論、コード、数学的能力の差はパーセンテージではなく桁違いの問題である。この現実の差は市場の熱狂に埋もれてはならない。
しかし、「オープンなインターネット上の分散コンピューティングリソースでトレーニングされた」という前提に換算すると、意味合いは全く異なる。
比較してみよう。同じく分散トレーニングによるINTELLECT-1(Prime Intellectチーム製、100億パラメータ)のMMLUスコアは32.7。ホワイトリスト参加者間で行われた別の分散トレーニングプロジェクト、Psyche Consilience(400億パラメータ)のスコアは24.2。Covenant-72Bは72Bの規模、67.1のMMLUスコアで、分散トレーニング分野においては際立った数字である。
さらに重要なのは、このトレーニングが「許可不要」であったことだ。誰でも十分なコンピューティングリソースを持っていれば参加ノードとして接続でき、事前審査もホワイトリストも必要ない。70以上の独立したノードがモデル更新に参加し、世界中から接続してコンピューティングリソースを提供した。
Jensen Huangが言ったこと、言わなかったこと
あのポッドキャストでの会話の詳細を再現することは、この「支持表明」に対する外部の解釈を修正するのに役立つ。
Chamath Palihapitiyaは会話の中で、Bittensorの技術的成果をJensen Huangに提示し、分散コンピューティングリソースを用いてLlamaモデルをトレーニングしたと説明し、そのプロセスを「完全に分散化され、同時に状態を維持している」と表現した。Jensen Huangの返答は、これを「現代版のFolding@home」に例え、オープンソースモデルと独自モデルが並行して共存する必要性について議論を展開した。
注目すべきは、Jensen HuangがBittensorのトークンや投資に関する含意には直接言及せず、分散型AIトレーニングについてもそれ以上議論しなかったことだ。
BittensorサブネットとSN3を理解する
SN3のブレークスルーを理解するには、まずBittensorとそのサブネットの動作ロジックを明確にする必要がある。簡単に言えば、BittensorはAIパブリックチェーンおよびプラットフォームと見なすことができ、各サブネットは独立した「AI生産ライン」に相当する。それぞれが明確なコアタスクを定義し、インセンティブメカニズムを設計し、協調して分散型AIエコシステムを構成する。
その動作プロセスは明確かつ分散化されている。サブネット所有者がサブネットの目標を定義し、インセンティブモデルを記述する。マイナーはサブネット内でコンピューティングリソースを提供し、推論、トレーニング、ストレージなどのAI関連タスクを完了する。バリデータはマイナーの貢献を評価し、そのスコアをBittensorコンセンサスレイヤーにアップロードする。最終的に、BittensorのYumaコンセンサスアルゴリズムは各サブネットに蓄積された報酬に基づき、サブネット参加者に相応の収益を分配する。
現在、Bittensorには128のサブネットがあり、推論、サーバーレスAIクラウドサービス、画像、データラベリング、強化学習、ストレージ、計算など、さまざまなAIタスクをカバーしている。
SN3はその中の1つのサブネットである。それはアプリケーションレイヤーのラッピングを行わず、既存の大規模モデルAPIをレンタルすることもなく、AI産業チェーン全体の中で最も高価で最も閉鎖的なコアセグメントの1つである大規模モデルの事前トレーニングそのものに直接狙いを定めている。
SN3は、Bittensorネットワークを用いて異種混合の計算リソースを調整する分散トレーニングを実現し、インセンティブベースの分散大規模モデルトレーニングを通じて、高価な中央集権型スーパーコンピュータクラスタがなくても、強力な基盤モデルをトレーニングできることを証明したいと考えている。その核心的な魅力は「平等化」——中央集権型トレーニングのリソース独占を打破し、一般の個人や中小機関も大規模モデルトレーニングに参加できるようにし、同時に分散コンピューティングリソースを活用してトレーニングコストを削減することにある。
SN3の発展を推進する中核的な力はTemplarであり、その背後にある研究チームはCovenant Labsである。このチームは同時に、他の2つのサブネットも運営している。Basilica(SN39、コンピューティングサービスに特化)とGrail(SN81、RL事後トレーニングとモデル評価に特化)である。3つのサブネットは垂直統合を形成し、大規模モデルの事前トレーニングからアライメント最適化までの全プロセスを完全にカバーし、分散型大規模モデルトレーニングの完全なエコシステムを構築している。
具体的には、マイナーが計算リソースを提供し、勾配更新(モデルパラメータの調整方向と強度)をネットワークにアップロードする。バリデータは各マイナーの貢献の質を評価し、誤差改善の度合いに応じてオンチェーンでスコアリングを行う。結果が報酬の重みを決定し、自動的に分配される。いかなる第三者の信頼も必要としない。
インセンティブメカニズム設計の鍵は、報酬が単純なコンピューティングリソースの提供時間ではなく、「あなたの貢献がモデルをどれだけ改善したか」に直接結びついていることだ。これにより、分散型シナリオで最も難しい問題——マイナーが手抜きをするのを防ぐ方法——が根本的に解決される。
では、Covenant-72Bは通信効率とインセンティブ整合性の問題をどのように解決したのか?
互いに信頼関係がなく、ハードウェアが異なり、ネットワーク品質もまちまちな数十のノードが協調して同じモデルをトレーニングすることには、2つの課題がある。1つ目は通信効率。標準的な分散トレーニングスキームでは、ノード間の高帯域幅、低遅延の相互接続が要求される。2つ目はインセンティブ整合性。悪意のあるノードが誤った勾配を提出するのを防ぐには?各参加者が真面目にトレーニングを行い、他人の結果をコピーしていないことを保証するには?
SN3は2つのコアコンポーネントを用いてこれらの問題を解決した。SparseLoCoとGauntletである。
SparseLoCoは通信効率の問題を解決する。従来の分散トレーニングでは、各ステップで完全な勾配を同期する必要があり、データ量が膨大になる。SparseLoCoが採用するアプローチは次の通り。各ノードはローカルで30ステップの内部最適化(AdamW)を実行し、その後、生成された「疑似勾配」を圧縮してから他のノードにアップロードする。圧縮方法には、Top-kスパース化(最も重要な勾配成分のみを保持)、誤差フィードバック(破棄された部分を保存して次のラウンドに累積)、および2ビット量子化が含まれる。最終的な圧縮率は146倍を超える。
言い換えれば、本来100MBを転送する必要があったものが、現在では1MB未満で済むようになった。
これにより、システムは通常のインターネット接続(上り110Mbps、下り500Mbps)の帯域幅制限下でも、計算利用率を約94.5%に維持できる——20ノード、ノードあたり8枚のB200、各ラウンドの通信時間はわずか70秒である。
Gauntletはインセンティブ整合性の問題を解決する。これはBittensorブロックチェーン(Subnet 3)上で動作し、各ノードが提出した疑似勾配の品質を検証する責任を負う。具体的な方法は次の通り。少量のデータバッチを用いて、「このノードの勾配を適用した後、モデルの損失がどれだけ減少したか」をテストし、その結果をLossScoreと呼ぶ。同時に、システムはノードが割り当てられたデータでトレーニングを行っているかどうかもチェックする——もしノードがランダムデータでの損失改善が、割り当てデータでのそれよりも良い場合、マイナス点が付けられる。
最終的に、各トレーニングラウンドでは、最も高い評価を受けたノードの勾配のみが集約に参加し、それ以外のノードはそのラウンドから排除される。不足する参加者は随時補充され、システムの堅牢性が維持される。トレーニングプロセス全体を通じて、平均して各ラウンドで16.9ノードの勾配が集約に組み込まれ、累積して参加したユニークなノードIDは70を超える。
分散型AIの価値ナラティブは、根本的な転換を遂げつつある
技術と業界の視点からこの出来事を見ると、Covenant-72Bが示す方向性にはいくつかの現実的な意義がある。
第一に、「分散トレーニングは小規模モデルにのみ適している」という前提を打ち破ったこと。 最先端モデルとはまだ大きな差があるものの、この方向性のスケーラビリティを証明した。
第二に、許可不要の参加が現実的に可能であること。 この点は過小評価されている。これまでの分散トレーニングプロジェクトはホワイトリストに依存していた——審査を受けた参加者のみがコンピューティングリソースを提供できた。SN3の今回のトレーニングでは、十分なコンピューティングリソースを持つ誰もが接続でき、検証メカニズムが悪意のある貢献をフィルタリングする。これは「真の分散化」に向けた具体的な一歩である。
第三に、BittensorのdTAOメカニズムにより、サブネット価値の市場発見が可能になったこと。 dTAOは各サブネットが独自のAlphaトークンを発行することを可能にし、AMMメカニズムを通じて市場がどのサブネットがより多くのTAOエミッションを得るかを決定する。これは、SN3のように具体的な成果を生み出したサブネットに対して、粗雑ではあるが効果的な価値捕捉メカニズムを提供する。もちろん、このメカニズムも同様にナラティブや感情に干渉されやすく、LLMトレーニング成果の質は一般の市場参加者が独立して評価するのは難しい。
第四に、分散型AIトレーニングの政治経済的意味合い。 Jack ClarkはImport AIの中で、この問題を「誰がAIの未来を所有するか」というレベルに引き上げた。現在、最先端モデルのトレーニングは大規模データセンターを所有する少数の機関によって独占されており、これは単なるビジネス上の問題ではなく、権力構造の問題でもある。分散トレーニングが技術的進歩を継続的に達成できれば、特定のモデルタイプ(例えば特定分野の小規模最先端モデル)において、真に分散化された開発エコシステムを形成する可能性がある。もちろん、この展望は


