
Skillの理解から、Crypto Research Skillの構築方法まで
- 核心的な視点:本記事は、Anthropicが発表したAgent Skill技術を深く分析し、Claude専用機能からAI Agent分野における汎用的な基盤設計パターンへと進化した過程を説明し、MCPプロトコルとの本質的な違いと、暗号投資研究シナリオにおける相乗的な応用価値に重点を置いて解析している。
- 重要な要素:
- Agent Skillは2025年末にAnthropicによって発表され標準として公開され、AI能力をモジュール化し、「説明文書」形式を通じてタスク実行の安定性と効率を向上させ、プロンプト調整の冗長性を低減することを目的としている。
- その核心的な実行メカニズムは「段階的開示」であり、三層(メタデータ、指示、リソース)に分けて必要に応じてロードし、トークンを極限まで節約しながら効率を維持する。そのうち、Referenceは条件付きトリガーで外部知識を読み取るために、Scriptは外部コードを実行するために使用される。
- Agent SkillとMCPには本質的な違いがある:MCPは標準化された「データパイプライン」であり、外部データソースへの接続を担当する;一方、Skillは「行動規範(SOP)」であり、モデルがデータをどのように処理するかを規定する。
- 暗号投資研究の実戦において、両者は強力に連携し、「MCPが水を供給し、Skillが酒を醸す」というモードを形成できる。例えば、MCPを利用してオンチェーンデータとニュースを取得し、Skillを通じてワークフローを編成し、デューデリジェンスレポートを自動生成したり、取引シグナルを発見したりすることができる。
- この組み合わせにより、高度に自動化された専門的なワークフローを構築できる。例えば、新規トークンの迅速なデューデリジェンス(Twitter、世論、AI分析のクロス検証)や、リアルタイムイベント駆動の取引シグナル発見(WebSocketによるニュースストリームの監視とアラートのトリガー)などである。
原文著者: @BlazingKevin_ 、Blockboosterリサーチャー
1. Agent Skillの誕生背景と進化
2025年のAI Agent分野は、「技術コンセプト」から「エンジニアリング実装」への飛躍を遂げる重要な分岐点にある。このプロセスにおいて、Anthropicによる能力カプセル化の探求は、予期せず業界レベルのパラダイムシフトを引き起こした。
2025年10月16日、Anthropicは正式にAgent Skillをリリースした。当初、公式はこの機能に対して極めて控えめな位置づけを示していた——それは単にClaudeの特定の垂直タスク(複雑なコードロジック、特定のデータ分析など)におけるパフォーマンスを向上させる補助モジュールと見なされていた。
しかし、市場と開発者の反応は予想をはるかに超えるものだった。人々はすぐに、この「能力のモジュール化」設計が実際のエンジニアリングにおいて非常に高い分離性と柔軟性を発揮することに気づいた。これはプロンプトチューニングの冗長性を低減するだけでなく、Agentが特定タスクを実行する際の安定性を大幅に向上させた。この体験は、開発者コミュニティで連鎖反応を引き起こした。短期間のうちに、VS Code、Codex、Cursorを含む主要な生産性ツールと統合開発環境(IDE)が続々と追随し、Agent Skillアーキテクチャへのネイティブサポートを完了した。
エコシステムの自発的拡大に直面し、Anthropicはこのメカニズムの根本的な汎用価値を捉えた。2025年12月18日、Anthropicは業界のマイルストーンとなる決定を下した:Agent Skillを正式にオープンスタンダードとして公開する。
続いて、2026年1月29日、公式はSkillの詳細なユーザーマニュアルを正式に公開し、プロトコルレベルでクロスプラットフォーム、クロスプロダクト再利用の技術的障壁を完全に取り除いた。 この一連の動きは、Agent Skillが「Claude専属の付属品」というレッテルを完全に剥がし、AI Agent分野全体における汎用的な基盤設計パターンへと正式に進化したことを示している。
ここで、ひとつの疑問が浮かび上がる:大手企業とコア開発者がこぞって受け入れたこのAgent Skillは、基盤エンジニアリングにおいてどのような核心的な課題を解決したのか? そして現在ホットなMCPとは、本質的にどのような違いと相補関係にあるのか?
これらの問題を徹底的に解明し、最終的に暗号業界の投資リサーチの実践的構築に落とし込むため、本稿では以下の考察を段階的に展開する:
- 概念解析:Agent Skillの本質とその基盤アーキテクチャ構築。
- 基本ワークフロー:その基盤動作ロジックと実行フローの解明。
- 高度なメカニズム:ReferenceとScriptという2つの高度な用法の詳細な分析。
- 実践ケース:Agent SkillとMCPの本質的差異を解析し、Crypto投研シナリオにおける組み合わせ応用をデモンストレーション。
2. Agent Skillとは何か、およびその基本構築
Agent Skillとは一体何か? 最も平易に言えば、それは大規模言語モデルがいつでも参照できる「専用説明書」である。
AIを日常的に使用する際、よくある課題は:新しい会話を開始するたびに、長い要求を再度貼り付けなければならないことだ。Agent Skillは、この煩わしさを解決するために生まれた。

実際の例を挙げよう:仮に「インテリジェントカスタマーサポート」Agentを作りたい場合、Skillの中に明確にルールを記述できる:「ユーザーの苦情に遭遇した場合、まずは感情を落ち着かせ、絶対に安易に補償を約束してはならない。」 また、例えば「会議議事録」を頻繁に作成する必要がある場合、Skill内に直接テンプレートを設定できる:「会議議事録を出力する際は、必ず『参加者』、『核心議題』、『最終決定』の3つのセクションに厳密に従って構成すること。」
この「説明書」があれば、毎回の会話で長い指示を繰り返す必要はなくなる。大規模言語モデルはタスクを受けた時、自動的に対応するSkillを参照し、すぐにどの基準で作業すべきかを理解する。
もちろん、「説明書」は理解を容易にするための簡略化された比喩に過ぎない。実際、Agent Skillができることは、単純なフォーマット規範よりもはるかに強力であり、その「キラー級」の高度な機能については後の章で詳細に解説する。しかし、初期段階では、効率的なタスク説明書として捉えて全く問題ない。
次に、誰もが最も親しみやすい「会議議事録」というシナリオを用いて、実際にどのようにAgent Skillを作成するのかを見てみよう。このプロセス全体に複雑なプログラミング知識は必要ない。
現在の主流ツール(Claude Codeなど)の設定によると、コンピュータのユーザーディレクトリに.claude/skillという名前のフォルダを探す(または新規作成する)必要がある。ここが全てのSkillを格納する「本拠地」となる。
第一ステップ:このディレクトリ内に新しいフォルダを作成する。このフォルダの名前が、このAgent Skillの名前となる。 第二ステップ:先ほど作成したフォルダ内に、skill.mdという名前のテキストファイルを作成する。
全てのAgent Skillには、このskill.mdファイルが必須である。その役割は、AIに対して「私は誰か、何ができるか、そしてどのように私の要求に従って作業すべきか」を伝えることだ。このファイルを開くと、上下2つの部分に明確に分かれていることがわかる:

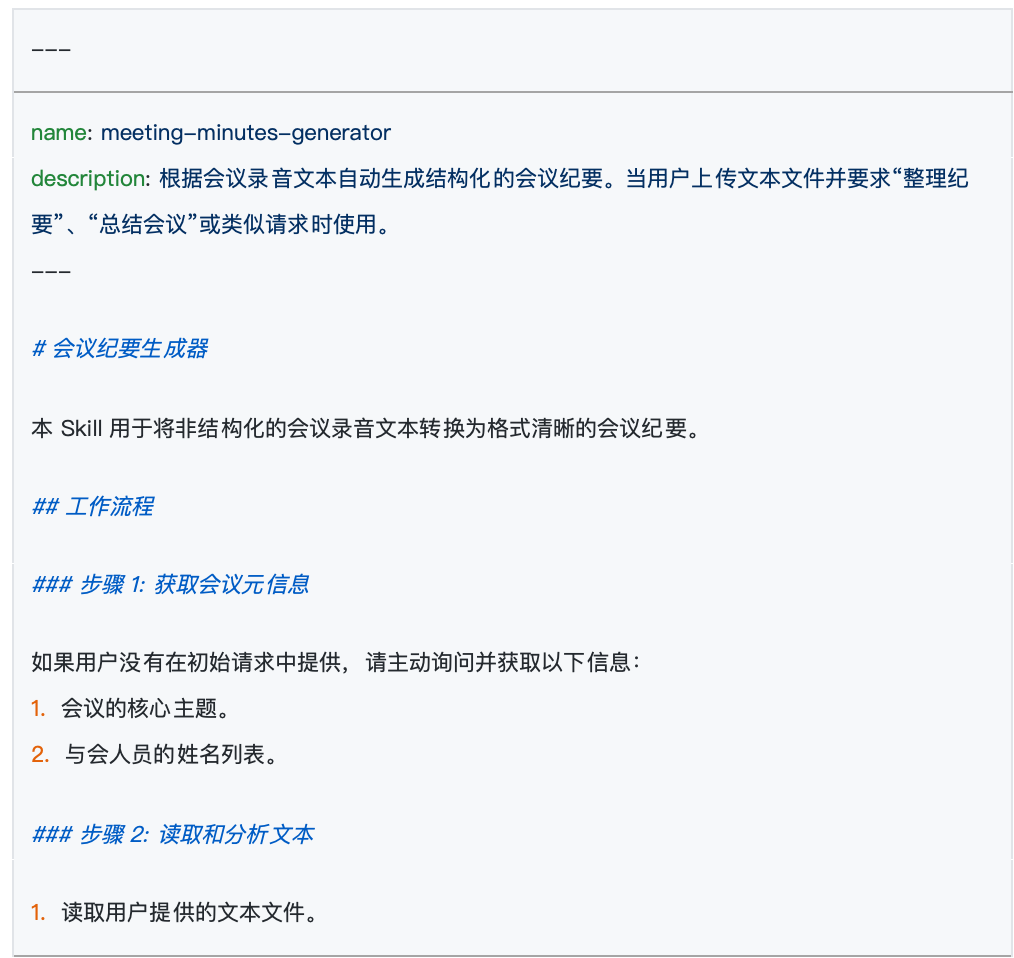
ファイルの冒頭は、通常2つの短いハイフン---で囲まれた領域である。ここには2つの核心属性のみを記述する:nameとdescription。
name:このSkillの名前。外部のフォルダ名と完全に一致させる必要がある。description:これは極めて重要な部分である。大規模言語モデルに対して、このSkillの具体的な用途を説明する役割を担う。AIはバックグラウンドで全てのSkillの説明を継続的にスキャンし、現在のユーザーの質問がどのSkillで解決すべきかを判断する。 したがって、正確で包括的な説明を書くことは、あなたのSkillがAIによって正確に呼び出されるための大前提である。
短いハイフンの下の残りの部分は、AIが見る具体的なルールである。公式はこの部分を「指示」と呼んでいる。 ここがあなたが力を発揮する場所であり、モデルが従うべきロジックを詳細に記述する必要がある。例えば、会議議事録の例では、ここで平易な言葉で規定できる:「参加者リスト、議論された議題、および最終的に決定された事項を必ず抽出すること。」

これらのステップを完了すれば、シンプルだが非常に実用的なAgent Skillが誕生する。
しかし、本当に使いやすいSkillは、周到な事前設計から始まることが多い。最初の1行をキーボードで打つ前に、目標、範囲、成功基準を明確に定義することで、構築プロセスが事半功倍となる。
Skill構築の第一ステップは、実際には「AIにどんなことをさせられるか」を考えるのではなく、自らに問いかけることである:「私は日常業務のどのような繰り返し発生する問題を解決する必要があるのか?」 最初は、このSkillがカバーすべき明確なシナリオを2〜3つ具体的に定義することをお勧めする。

次に、成功基準の定義である。作成したSkillが使いやすいかどうかをどのように判断するか? 着手前に、測定可能な基準をいくつか設定する。例えば、定量的基準としては「処理速度が向上したか」、定性的基準としては「抽出した会議決定が毎回十分に正確で見落としがないか」などが挙げられる。
3. Agent Skillの基本実行ワークフロー
Agent Skillの基本概要を理解した後、私たちは自然に疑問を持つ:実際の実行において、この「説明書」はどのように機能するのか?
最近Manus AIのような製品を体験したことがあれば、おそらく以下のようなシーンを経験したことがあるだろう:特定の問題を投げかけると、AIはすぐに「長文を生成」したり幻覚を起こしたりせず、鋭敏に「この件は特定のAgent Skillが管轄する」と認識する。そして、インターフェース上にプロンプトを表示し、そのSkillの呼び出しを許可するかどうかを尋ねる。
「同意」をクリックすると、AIはまるで別人のように、事前設定されたルールに厳密に従って完璧な結果を出力する。
この一見シンプルな「申請-同意-実行」のインタラクションの背後には、実は非常に精巧な基盤実行ワークフローが隠されている。このメカニズムを徹底的に説明するために、まずプロセス全体に関与する「3つの核心的な役割」を明確にする必要がある:
- ユーザー:タスクリクエストを発行する人。
- クライアントツール(Claude Codeなど):スケジューリングと調整を担当する「仲介者」。
- 大規模言語モデル:意図を理解し最終結果を生成する「頭脳」。
システムに一連の要求(例:「今朝のプロジェクト定例会の議事録をまとめてください」)を入力すると、これら3つの役割の間で以下の4ステップの精密な連携が発生する:
ステップ1:軽量スキャン(メタデータの受け渡し)
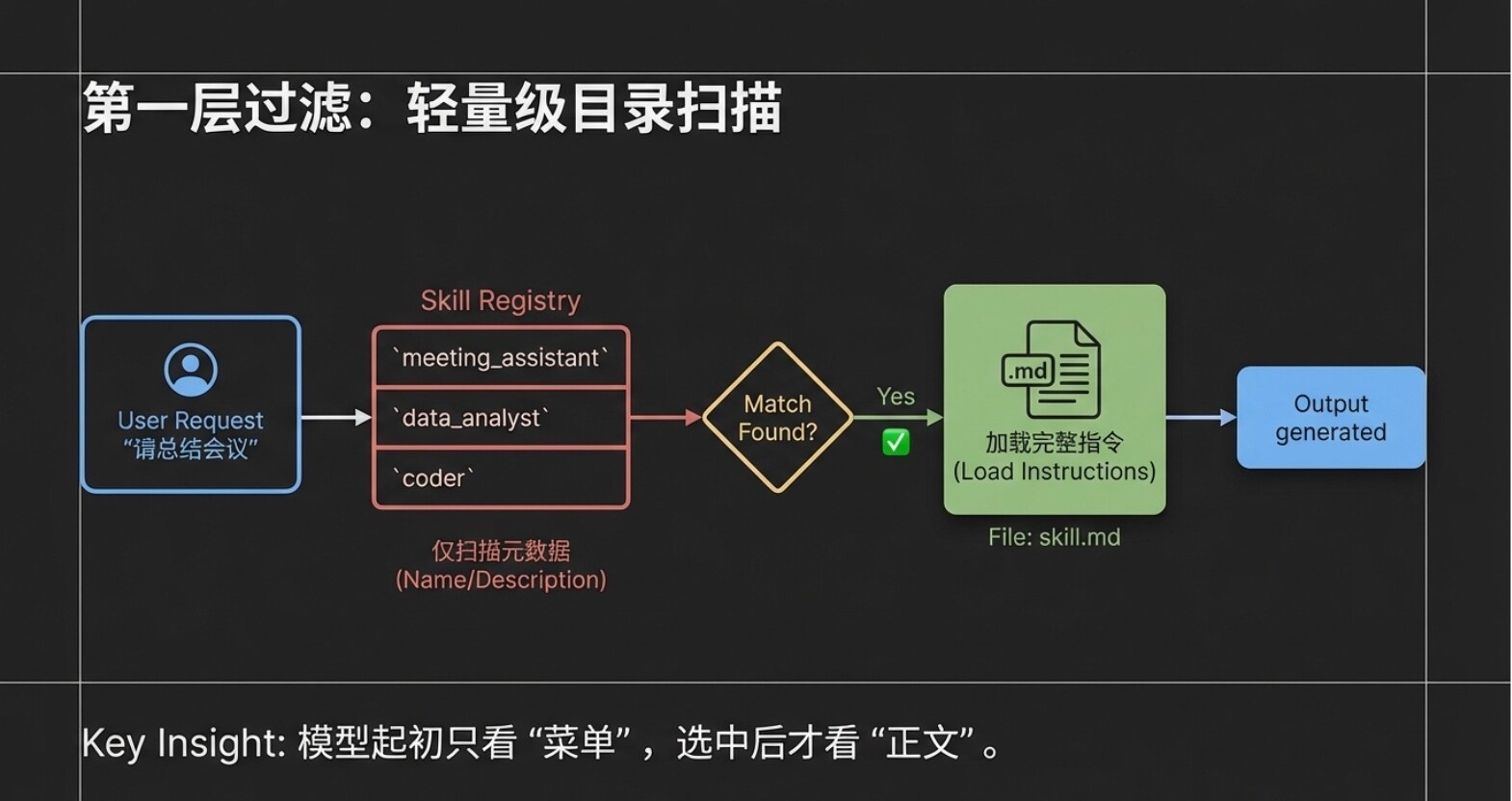
ユーザーがリクエストを入力すると、クライアントツール(Claude Code)は全ての説明書を大規模言語モデルに一気に投げることはしない。代わりに、ユーザーのリクエストと、現在のシステム内の全てのAgent Skillの「名称」と「説明」(前章で述べたメタデータ層)のみをパッケージ化して大規模言語モデルに送信する。 想像してほしい、たとえ10個以上、あるいは数十個のSkillをインストールしていたとしても、この時点で大規模言語モデルが受け取るのは「軽量な目次」だけである。この設計は、モデルの注意力を大幅に節約し、情報の相互干渉を回避している。
ステップ2:正確な意図マッチング 大規模言語モデルはユーザーリクエストとこの「Skill目次」を受け取ると、迅速な意味解析を行う。ユーザーの要求が「会議のまとめ」であることを発見し、目次の中に「会議議事録アシスタント」という名前のSkillがあり、その説明がこのタスクに完璧に適合していることを認識する。 この時点で、大規模言語モデルはこのマッチング結果をクライアントツールに伝える:「このタスクは『会議議事録アシスタント』で解決できることがわかりました。」
ステップ3:オンデマンドでの完全な指示のロード 大規模言語モデルのフィードバックを得た後、クライアントツール(Claude Code)は初めて「会議議事録アシスタント」の専用フォルダに入り、完全なskill.mdの本文を読み取る。 注意:これは極めて重要な設計である:この時点で初めて完全な指示内容が読み取られ、システムはこの選択されたSkillのみを読み取る。 他のマッチングされなかったSkillは依然として目次の中に静かに留まり、いかなるリソースも消費しない。
ステップ4:厳格な実行と出力応答 最後に、クライアントツールは「ユーザーのオリジナルリクエスト」と「会議議事録アシスタントの完全なskill.md内容」を一緒に大規模言語モデルに送信する。 今回は、大規模言語モデルは選択問題を解くのではなく、実行モードに入る。skill.mdに定められたルール(例:参加者、核心議題、最終決定を必ず抽出する)に厳密に従い、高度に構造化された応答を生成し、クライアントツールを通じてユーザーに表示する。
4. 核心メカニズムその1:オンデマンドロードとReference
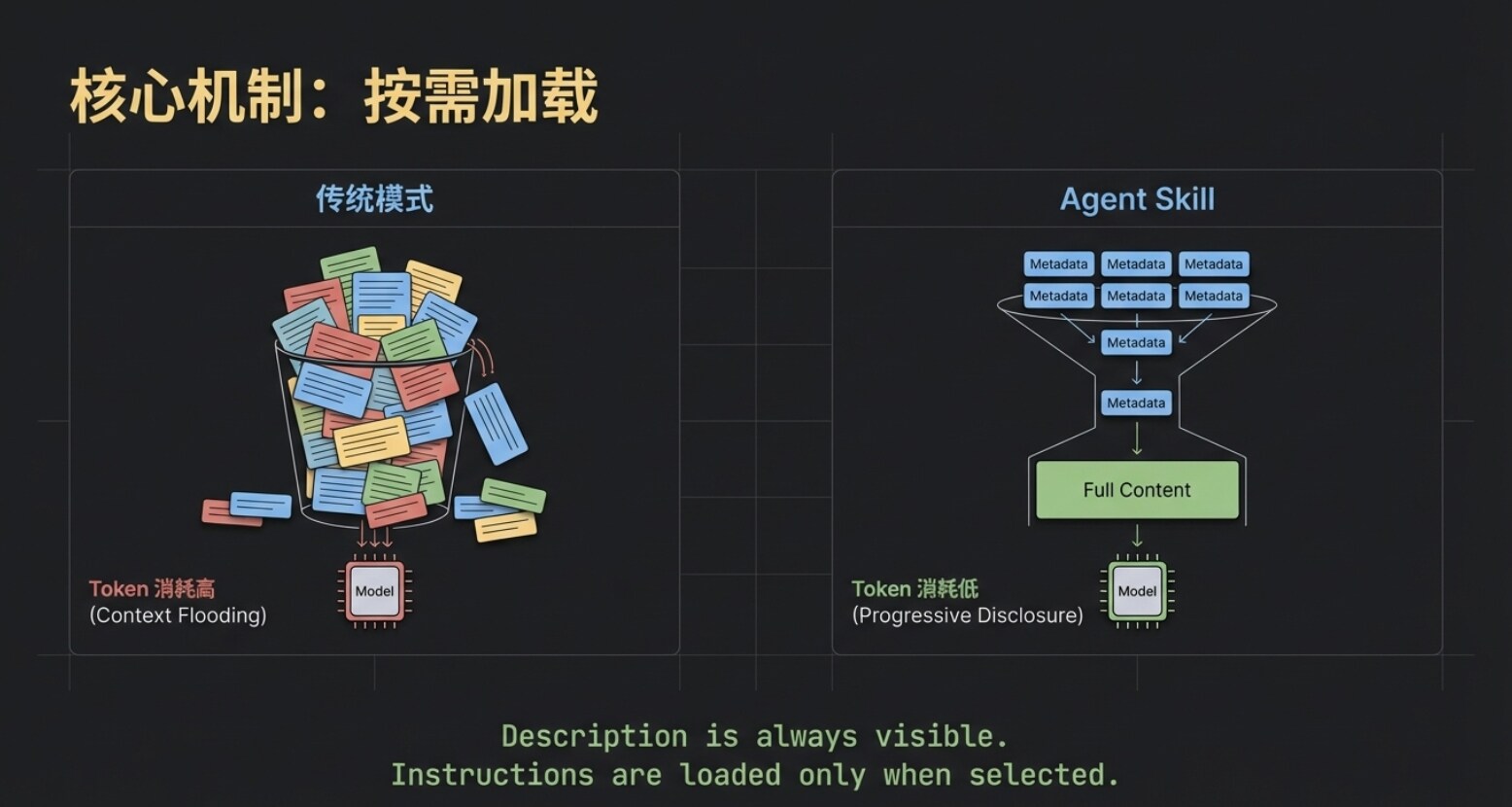
前章のワークフローは、Agent Skillの最初の核心的な基盤メカニズム——オンデマンドロード——を引き出した。
全てのSkillの名称と説明は常に大規模言語モデルから見えるが、具体的な指示内容は、そのSkillが正確にマッチングされた後に初めて、実際にモデルのコンテキストにロードされる。
これにより、貴重なトークンリソースが大幅に節約される。想像してほしい、「バズる記事作成」、「会議議事録」、「オンチェーンデータ分析」など十数個の大規模なSkillを同時にデプロイしていたとしても、モデルは最初に極めて低コストの「目次検索」を一度行うだけで済む。ターゲットが選択された後、初めてシステムは対応するskill.mdをモデルに与える。この「オンデマンドロード」こそが、Agent Skillが軽量かつ効率的であり続ける第一の秘訣である。
しかし、究極の効率を追求する上級ユーザーにとって、第一層のオンデマンドロードだけでは不十分である。
業務が深まるにつれ、私たちはSkillをもっと賢くしたいと考えることが多い。「会議議事録アシスタント」を例にとると、単に議題を復唱するだけでなく、付加価値のある洞察を提供してほしい:会議でお金を使う決定がなされた時、要約の中で直接、グループの財務コンプライアンスに適合しているかどうかを注記できるように;外部協力に関わる場合、潜在的な法務リスクを


